0. 引言
在越野机器人、无人车底盘、林地巡检与野外作业等场景中,自动驾驶系统面临着与城市道路截然不同的挑战。城市道路拥有清晰的车道线、交通规则和相对可预测的环境,而越野环境则充满了不确定性:泥地、草地、砂石、积雪、树林边缘、临时障碍物等复杂地形随处可见。更为严峻的是,在夜晚、雨雪、雾霾等恶劣天气条件下,传感器极易出现退化 ,导致单一模态的感知信息不可靠 。现有的大模型驱动的自动驾驶理解方法大多面向规则清晰的城市场景,一旦进入无车道、无规则、传感器更容易退化的越野环境,系统就很容易在黑夜、雨雪、雾霾等条件下出现单模态失效,导致场景描述不稳定、路径规划不准确。此外,传统的**"黑箱"决策方式**在越野场景中更难被信任,因为无法解释系统为什么选择某条路径,是否忽略了潜在风险。
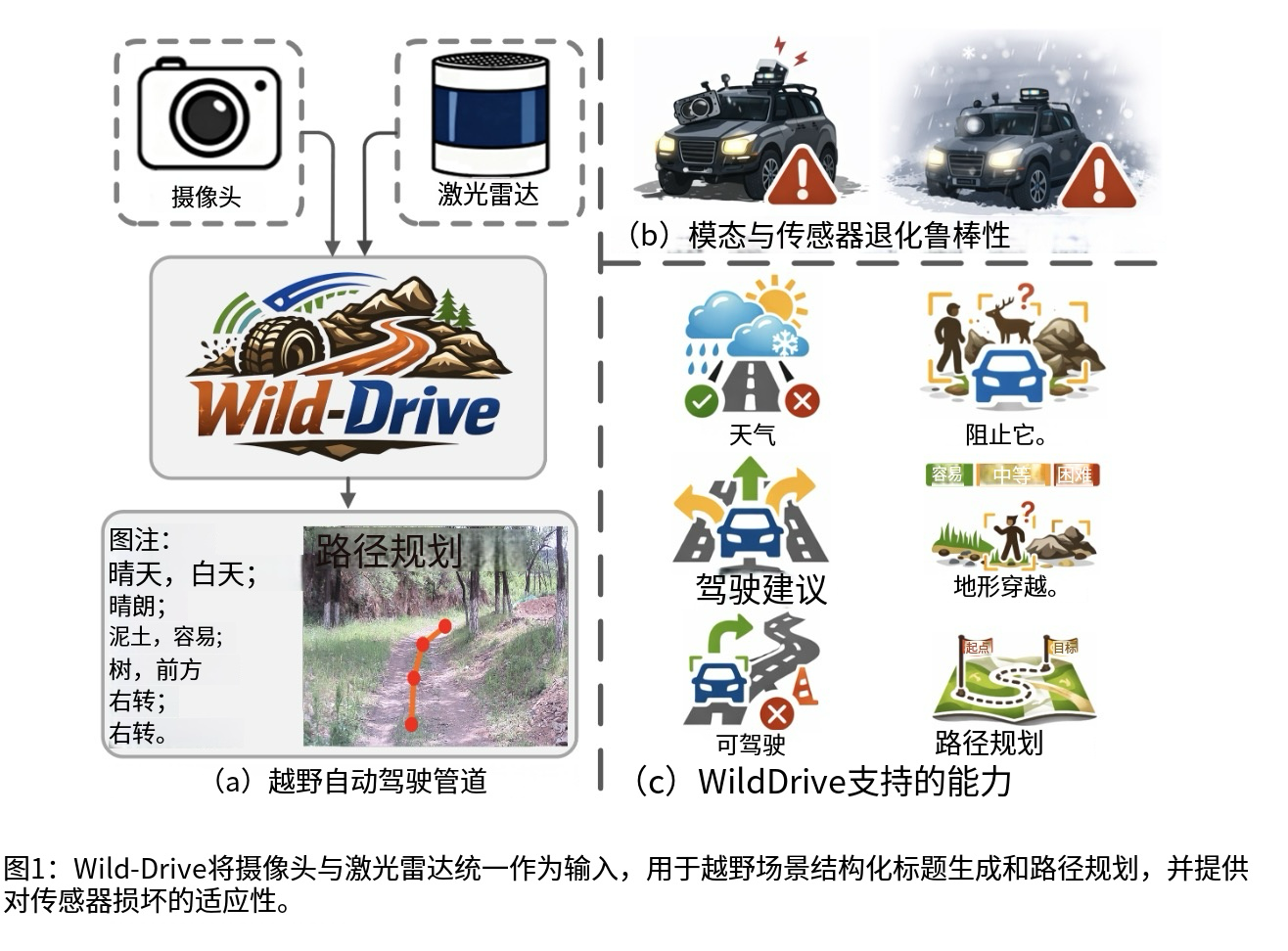
来自东南大学等机构的研究团队提出了Wild-Drive框架 ,首次将越野场景结构化描述与路径规划统一到一个高效的多模态大模型框架中 。该框架不仅能够用结构化语言解释当前环境,还能同时输出未来轨迹。通过引入MoRo-Former(模态路由Transformer) ,系统能够在摄像头、LiDAR、融合特征之间进行任务条件驱动的模态路由 ,在单模态退化时优先选择更可靠的信息源。与传统方法相比,Wild-Drive的创新之处在于将感知理解与运动规划深度耦合 ,形成了一个端到端的可解释决策系统 。系统通过轻量级大语言模型生成结构化的场景描述,这些描述不仅为人类操作员提供了透明的决策依据,更重要的是,它们作为中间语义表示直接指导下游的轨迹生成模块 。这种设计使得系统在面对复杂越野场景时,既能保持决策的可追溯性 ,又能实现实时的路径规划 ,为野外自主系统的安全部署提供了新的技术路径。论文:Wild-Drive: Off-Road Scene Captioning and Path Planning via Robust Multi-modal Routing and Efficient Large Language Model。代码仓库:https://github.com/wangzihanggg/Wild-Drive。
1. 核心问题:为什么城市场景的方法在越野环境失效?
1.1 场景无规则、风险长尾
城市道路至少还有车道线、交通规则、目标类别先验作为约束,这些结构化信息为自动驾驶系统提供了清晰的决策边界。而越野环境中常常面对的是泥地、草地、砂石、积雪等多样化地形,树林边缘、临时障碍物等不规则物体,可通行区域边界模糊且缺乏明确标识 。更为棘手的是,长尾风险事件频发 ,如突然出现的野生动物、隐藏的坑洼、不稳定的斜坡等,这些都是传统感知系统难以预测的场景。在这种高度不确定的环境中,单纯输出一条轨迹并不能让操作人员或系统监督者知道模型为什么这么走、是否忽略了潜在风险。这种**"黑箱决策"在越野场景中尤其危险,因为错误的代价可能是车辆损坏、任务失败甚至人员安全问题。因此,系统不仅需要给出 "怎么走",更需要解释 "为什么这么走",这种 可解释性**对于建立人机信任、实现安全接管至关重要。
1.2 传感器退化更常见
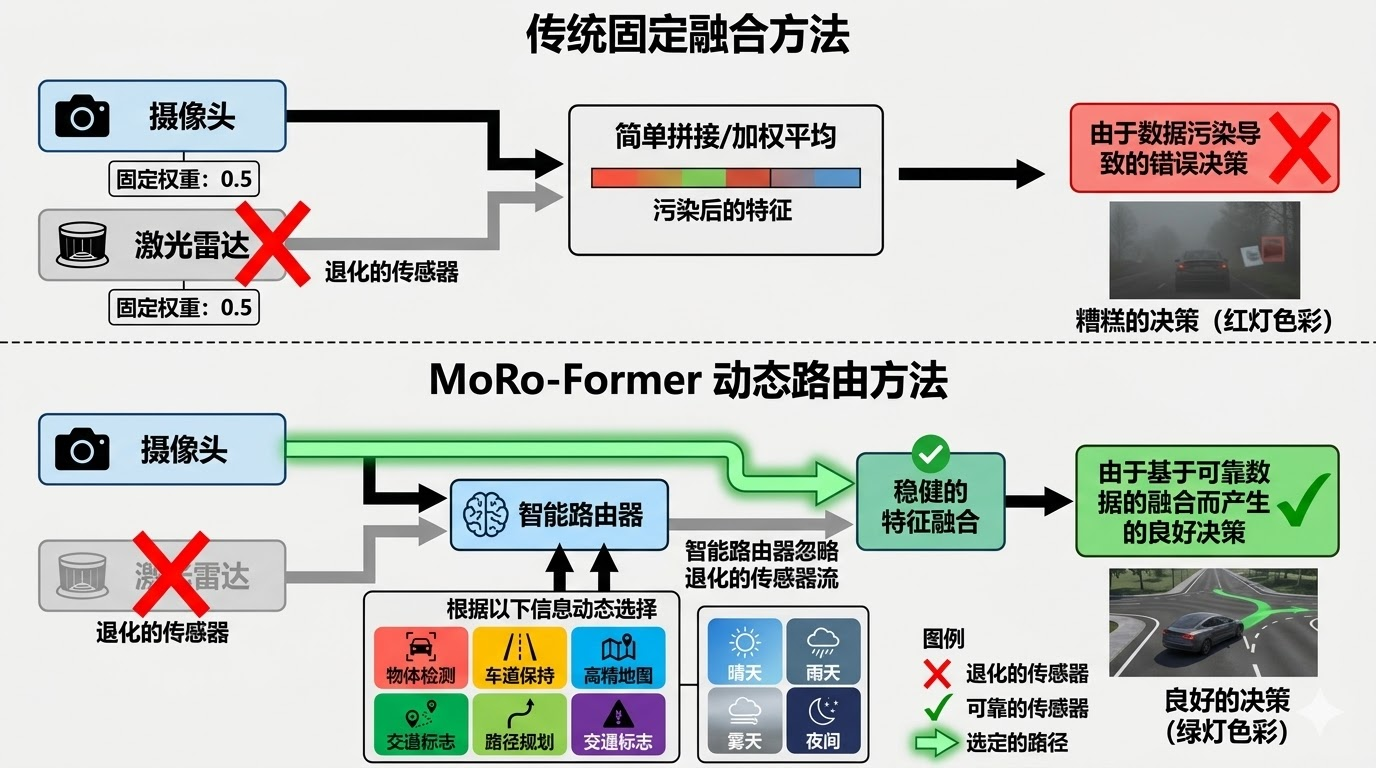
在越野场景下,传感器退化是一个普遍且严重的问题 。夜晚环境中,摄像头图像质量急剧下降,难以识别地形纹理和障碍物边界,色彩信息几乎完全丢失。雾天条件下,LiDAR点云变得稀疏 ,激光束在雾气中发生散射,导致距离测量不准确,远距离物体的检测能力显著下降。雨雪天气时,摄像头镜头被水滴遮挡,图像模糊不清,而LiDAR回波受到雨滴和雪花的干扰,产生大量噪点。强反光场景中,阳光直射导致摄像头过曝,局部区域完全失去细节信息。此外,越野作业中泥水遮挡传感器表面的情况时有发生,导致传感器性能持续退化。传统的**"无差别融合"策略默认所有模态都可靠,采用固定权重或简单拼接的方式组合多模态信息。然而,一旦其中一个模态失真,这种策略反而会把错误信息带入后续决策,导致系统性能整体下降。更糟糕的是,系统无法识别哪个模态出现了问题,也无法动态调整融合策略,这在传感器频繁退化的越野环境中是致命的缺陷**。
1.3 缺乏统一的"描述-规划"闭环
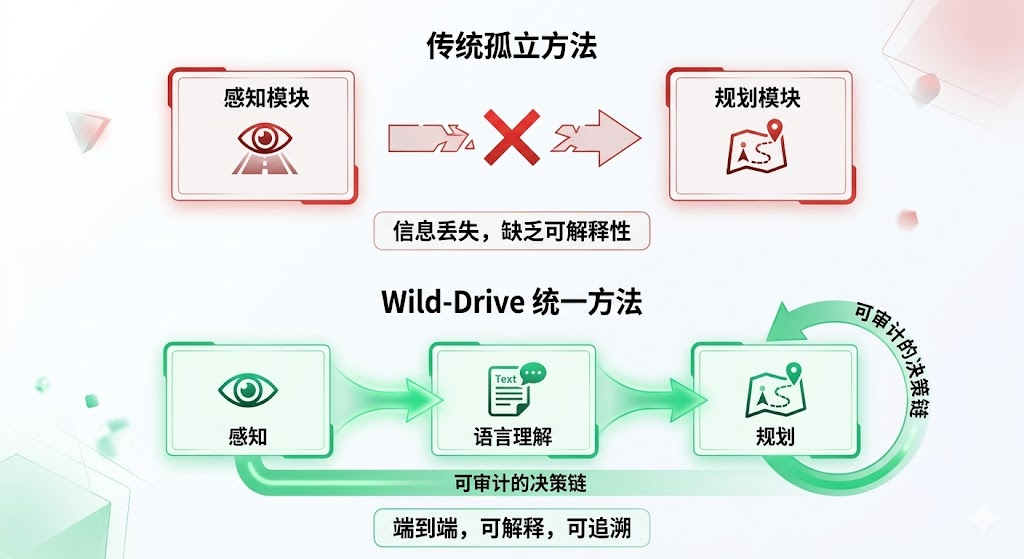
此前的相关方法通常只专注于感知或规划的某一个环节,缺少端到端的统一框架 。单模态场景描述方法,如LiDAR-LLM 只使用激光雷达进行3D场景理解,虽然能够生成场景描述,但这些描述往往是孤立的,无法直接指导下游的路径规划 。基于几何的规划方法,如TopoPath 直接从点云预测轨迹,虽然能够生成可执行的路径,但缺少语义层面的解释 ,无法回答"为什么选择这条路径"的问题。这种割裂导致了两个严重问题:一是场景理解的结果无法有效传递给规划模块,造成信息损失 ;二是规划决策缺乏可解释性 ,难以进行调试和优化。越野自动驾驶真正需要的是一个能够同时完成结构化环境理解 (天气、地形、障碍物)、高层驾驶建议生成 (直行、转向、停车)和可执行未来轨迹预测 (具体的路径点)的统一框架。这个框架应该让场景理解直接服务于规划决策,让规划结果能够追溯到具体的感知依据,形成一个完整的、可审计的决策闭环 。
1.4 缺少统一的评测基准
越野自动驾驶领域长期缺乏标准化的评测基准 ,这严重阻碍了技术进步和方法对比。如果没有标准化任务定义、标注模板和评测协议,研究者很难系统地回答一些关键问题:模型到底有没有真正理解天气、地形、障碍和可通行区域?文本解释是否真的帮助了规划,还是只是一个附加的展示功能?在模态退化下系统是否依然稳定,还是性能会急剧下降?不同方法之间的性能差异是来自模型架构的优势,还是数据集和评测方式的不同?这些问题的答案对于推动领域发展至关重要,但由于缺乏统一基准,不同研究工作往往使用各自的数据集和评测指标,导致结果无法直接对比。此外,现有的城市自动驾驶数据集(如nuScenes 、Waymo )虽然规模庞大,但主要关注结构化道路场景,无法反映越野环境的特殊挑战。因此,构建一个专门针对越野场景、涵盖多种传感器退化条件、包含场景描述和路径规划双重任务的基准数据集,成为推动该领域发展的迫切需求。
核心问题总结 :越野自动驾驶需要的不是一个"更大的黑箱模型",而是一个在退化感知条件下依然稳健、同时具备解释能力与规划能力的统一系统 。针对上述挑战,Wild-Drive提出了一套完整的解决方案。其核心思想是将多模态感知、语言理解和运动规划 三者有机融合,构建一个端到端的可解释决策系统 。系统通过任务驱动的模态路由机制 ,在传感器退化时自适应地选择可靠信息源;通过结构化的语言输出 ,为决策提供透明的中间表示;通过planning token的设计 ,将高层语义理解无缝转化为底层运动控制。这种设计不仅提升了系统在恶劣环境下的鲁棒性,更重要的是,它让越野自动驾驶系统的决策过程变得可追溯、可验证,为实际部署奠定了基础。
2. Wild-Drive整体架构:从感知到规划的统一流程
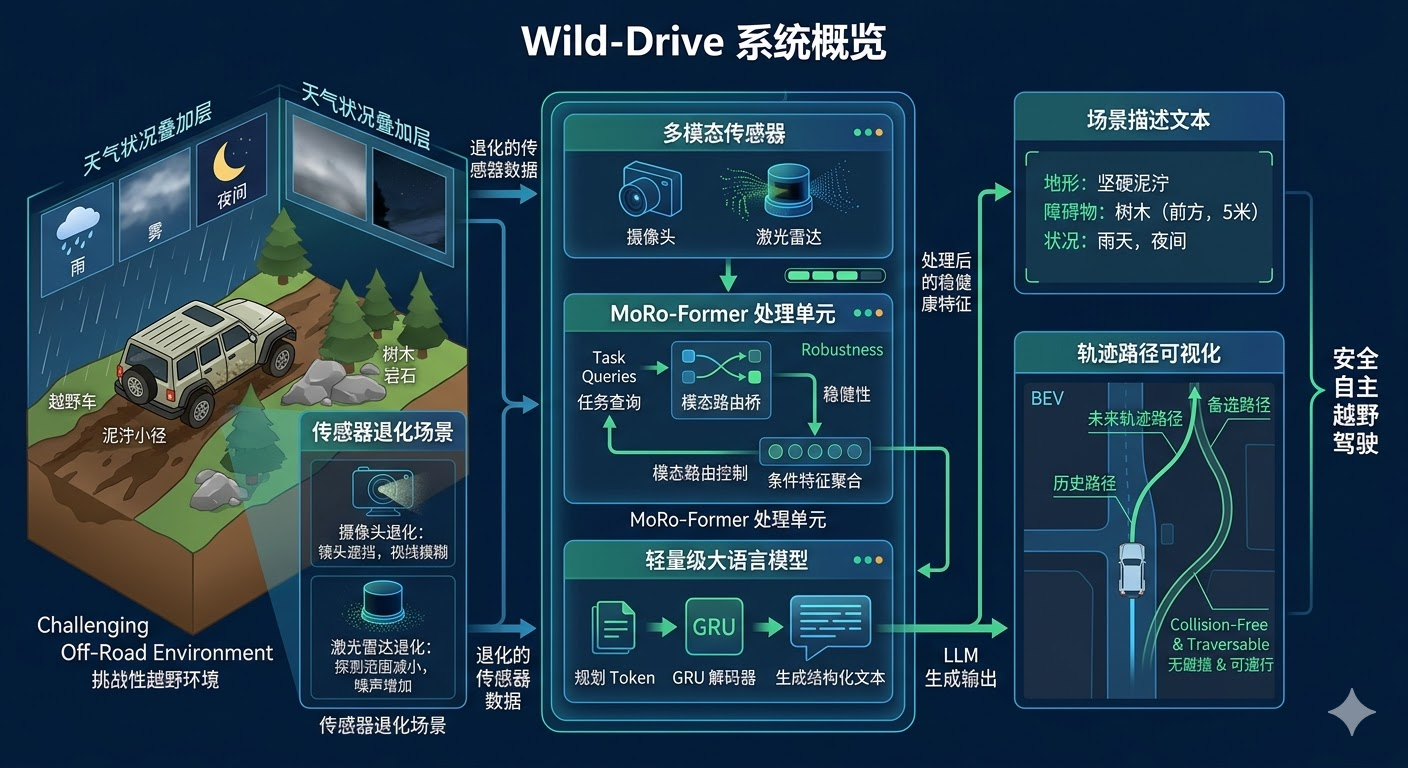
Wild-Drive的整体思路非常清晰:摄像头+LiDAR输入→任务驱动的模态路由与压缩→高效LLM生成结构化场景描述与规划token→GRU解码未来轨迹 。系统架构采用模块化设计 ,将复杂的感知-理解-规划流程分解为四个紧密耦合的关键模块。
2.1 系统流水线
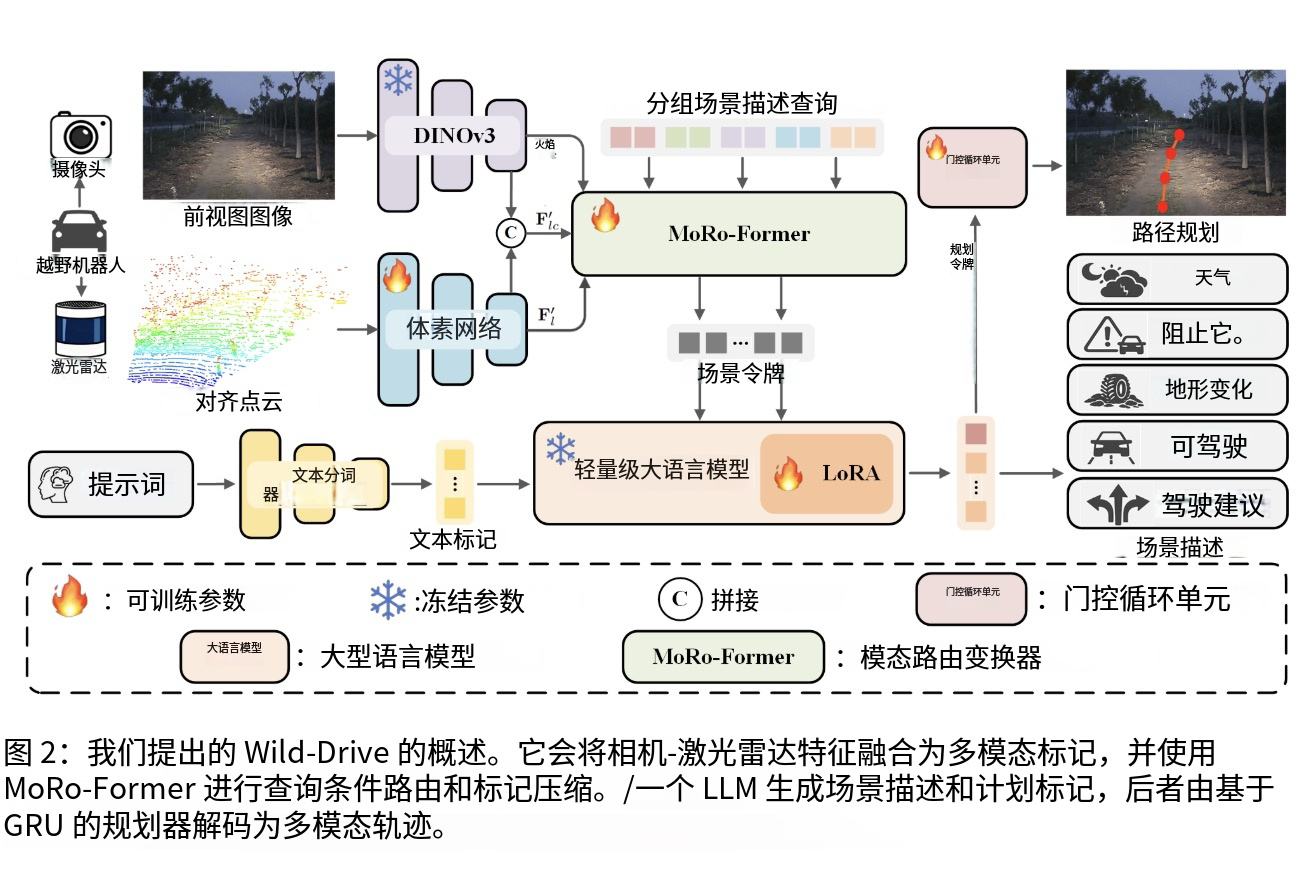
首先是多模态特征提取模块 ,该模块使用DINOv3 作为视觉编码器提取图像特征,DINOv3是一个自监督学习的视觉Transformer,能够捕捉丰富的语义信息。同时使用VoxelNet 提取LiDAR的BEV(鸟瞰图)特征,VoxelNet通过体素化点云并使用3D卷积网络,将稀疏的点云数据转换为密集的特征表示。这两种模态的特征在空间上对齐后,构建融合的多模态特征表示,为后续的智能路由提供基础。
第二个模块是MoRo-Former模态路由 ,这是Wild-Drive的核心创新 。系统定义了5类越野任务 (天气描述、可通行区域判断、地形通行性估计、障碍物检测、驾驶建议),每类任务分配64个可学习的query 。通过任务条件驱动的模态路由机制 ,系统能够为每个query动态选择最可靠的信息源:LiDAR专家、Camera专家或Fusion专家 。路由决策基于当前的环境条件和任务需求,在传感器退化时自动切换到更可靠的模态。随后,系统对路由后的token进行压缩,将每个任务的多专家表示压缩为紧凑的场景表示,总共生成60个token(5个任务×3个专家×4个token/分支)。
第三个模块是轻量级LLM场景理解 ,系统提供两种配置:Qwen2.5-0.5B (0.71B参数)和Qwen2.5-3B (3.25B参数)。考虑到野外机器人的计算资源限制,这些轻量级模型在保证性能的同时大幅降低了部署成本。LLM接收压缩后的场景token和用户指令,生成结构化的场景描述 ,包括天气、地形、障碍物等信息。更重要的是,LLM在生成过程中会输出特殊的planning token ,这些token的隐藏状态包含了模型对整个场景的理解和推理结果,是连接语言理解和动作生成的关键桥梁 。第四个模块是GRU轨迹解码器 ,该模块将planning token映射到动作潜在空间,然后通过GRU进行自回归解码 ,逐步生成未来4个路径点 (对应1s、2s、5s、10s的时间范围)。每个路径点包含**(x, y, z, yaw)四个维度,分别表示位置和朝向。自回归解码方式确保了轨迹的时序一致性和平滑性,后续路径点会考虑前面路径点的预测结果。这种设计使得Wild-Drive不是"先caption再另接一个planner"的松散拼接,而是 把场景解释和轨迹生成放进同一条条件化链路中**,让语言理解真正成为规划的中间桥梁,实现了从感知到规划的端到端优化。
2.2 配置文件解析
Wild-Drive的配置文件采用了清晰的模块化设计 ,通过VLMConfig类 统一管理所有超参数。这个配置类继承自Transformers库的PretrainedConfig,确保了与Hugging Face生态的兼容性。配置文件的设计体现了系统的三大核心组件:视觉-语言基础模型、多模态融合机制和规划模块 。在视觉-语言基础方面,系统使用预训练的DINOv3 作为视觉编码器,使用Qwen2.5系列 作为语言模型。为了在有限的计算资源下实现高效训练,配置中设置了freeze_vision_model 和freeze_llm_model 参数,冻结预训练模型的参数,只通过LoRA(低秩适应)技术微调少量参数。这种策略大幅降低了训练成本,同时保持了模型性能。在多模态融合方面,配置文件提供了灵活的选项。use_lidar 参数控制是否启用LiDAR分支,use_moroformer参数控制是否使用模态路由机制。当启用MoRo-Former时,系统会自动计算输出token数量(5个任务×3个专家×4个token=60个token),并更新image_pad_num_actual 参数。fusion_method 参数允许用户选择不同的融合策略,默认使用"moroformer",也可以选择简单的拼接或平均融合作为基线对比。lidar_feature_dim参数控制LiDAR特征的维度,需要与VoxelNet的输出维度匹配。
规划模块的配置同样灵活且易于调整。use_planning 参数控制是否启用规划头,num_planning_tokens 指定从LLM提取多少个planning token(默认4个),planning_waypoints 指定预测多少个未来路径点(默认4个,对应1s、2s、5s、10s),planning_waypoint_dim 指定每个路径点的维度(默认4维,包括x、y、z、yaw)。planning_gru_hidden 和planning_gru_layers 控制GRU解码器的容量,planning_loss_weight控制规划损失在总损失中的权重。这些参数的合理设置对于平衡场景描述和路径规划两个任务的性能至关重要。通过调整这些配置,研究者可以轻松地进行消融实验,验证不同组件的贡献。
3. 核心创新一:MoRo-Former - 任务驱动的模态路由机制
论文中最关键的设计是MoRo-Former(Modality Routing Transformer) 。它不是像常规Q-Former那样把所有query一视同仁,而是明确意识到:在越野环境中,不同任务、不同天气、不同照明条件下,真正可靠的模态并不相同。
3.1 设计理念
传统的多模态融合方法通常采用固定的融合策略 ,无论环境如何变化,都以相同的方式组合不同模态的信息。这种**"一刀切"的方法在城市道路等结构化场景中可能表现尚可,但在越野场景中存在明显缺陷。具体而言,在 夜晚或强弱光条件下,摄像头图像质量严重下降,此时地形可通行性和障碍定位可能更依赖 LiDAR的几何信息**,因为LiDAR不受光照条件影响,能够提供准确的距离和形状信息。相反,当LiDAR回波稀疏或局部失效 时(如在植被茂密区域或雨雪天气),模型需要更多借助相机的纹理与外观信息 来判断地形类型和可通行性。此外,某些任务本身更适合特定模态:天气识别 主要依赖视觉信息(云层、降水、光照),而地形通行性估计 则更需要几何信息(坡度、高度差、表面粗糙度)。MoRo-Former的核心创新在于引入了任务驱动的动态路由机制 ,让系统能够根据当前任务需求和环境条件,自适应地选择最可靠的信息源 。这种设计不是简单地为每个模态分配固定权重,而是为每个query学习一个路由决策,在LiDAR、Camera和Fusion三个专家 之间进行选择。在推理阶段采用硬路由策略 ,每个query只保留被选中的专家输出,从而**避免"坏模态把好模态拖下水"**的问题。这种机制使得系统在面对传感器退化时具有更强的鲁棒性,能够自动屏蔽不可靠的信息源,专注于可靠的模态进行决策。
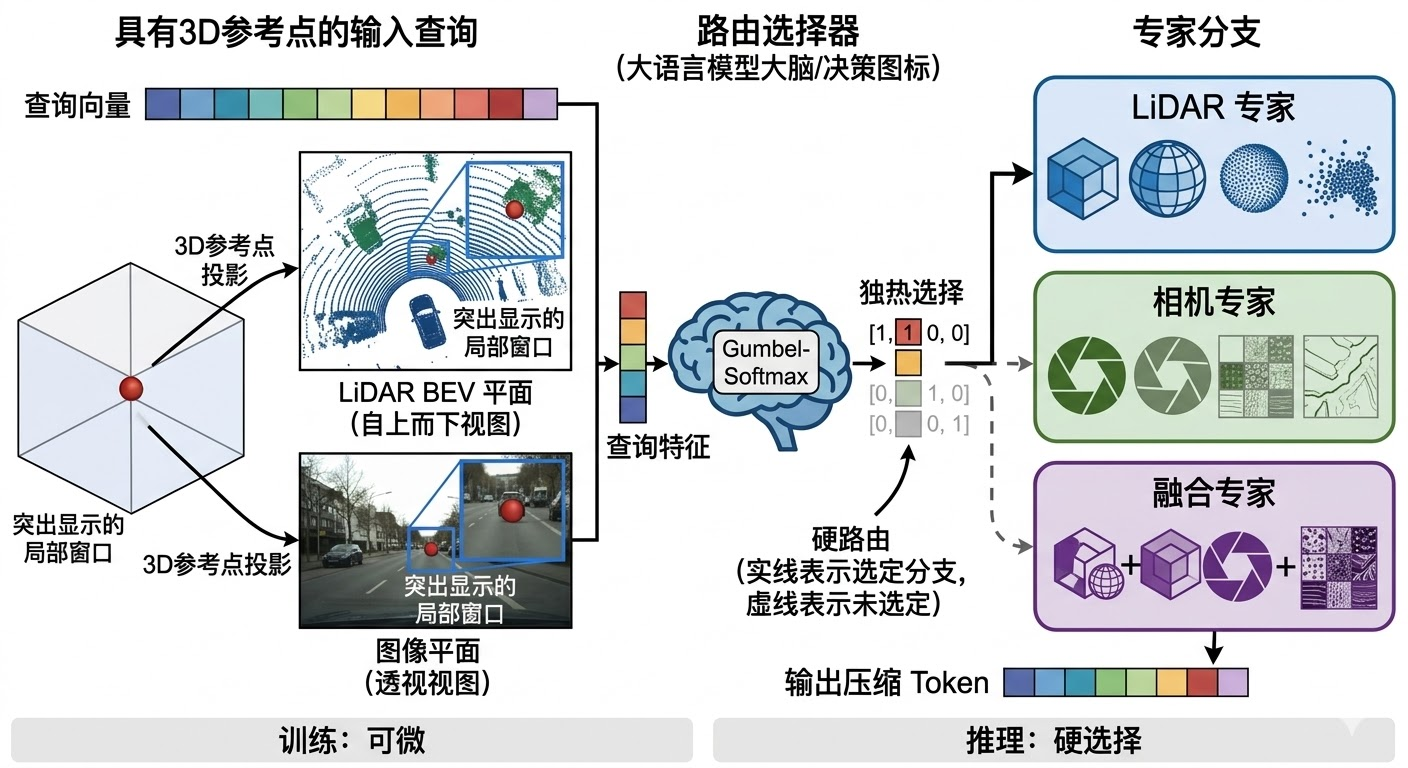
3.2 步骤1:按任务分组查询
Wild-Drive针对越野场景的特点,精心设计了5类核心任务 ,每类任务分配64个可学习的query ,形成总共320个任务专用查询向量 。这5类任务分别是:**天气描述(Weather Description)**用于识别当前的天气和光照条件;可通行区域判断(Drivable Area)用于确定前方哪些区域可以安全通过;地形通行性估计(Terrain Traversability)用于评估不同地形的通过难度;障碍物检测(Obstacle Detection)用于识别和定位各类障碍物;驾驶建议(Driving Suggestion)用于生成高层的驾驶决策。这种任务分组设计的核心优势在于,不同任务可以关注不同的感知信息,避免了将所有问题混在一起处理导致的信息干扰。为了进一步降低任务间干扰,系统引入了 任务组嵌入(task group embedding)机制。每个任务都有一个可学习的组嵌入向量,这个向量会被加到该任务的所有query上,为query注入任务身份信息。在前向传播时,系统首先将任务查询扩展到batch维度,然后将任务嵌入通过广播机制加到对应的query上。这种设计使得模型能够明确区分不同任务的query,每个query在进行交叉注意力时会携带其任务身份,从而为每类越野决策问题保留独立的感知通道。实验表明,这种任务分组机制显著提升了模型在多任务学习中的性能,避免了不同任务之间的负迁移现象。
3.3 步骤2:局部感知的模态路由
对于需要模态选择的任务,每个query会关联一个3D参考点 ,并被投影到LiDAR BEV和图像平面 ,只关注局部窗口内的信息。随后,路由器预测该query更应该交给哪个专家:LiDAR expert 处理几何和深度信息,Camera expert 处理纹理和外观信息,Fusion expert 综合两种模态的信息。路由器的实现使用了Gumbel-Softmax技巧 ,在前向传播时进行硬路由 (每个query只选择一个专家),在反向传播时保持可微分。这种设计的关键在于:在推理阶段采用硬路由,每个query只保留被选中的专家输出,从而避免"坏模态把好模态拖下水" 。
python
class ModalityRouter(nn.Module):
"""使用Gumbel-Softmax实现可微分的硬路由"""
def __init__(self, hidden_dim):
super().__init__()
self.router = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim // 4),
nn.ReLU(),
nn.Linear(hidden_dim // 4, 3), # 3个专家
)
def forward(self, query):
logits = self.router(query) # [B, N, 3]
if self.training:
# 训练时:Gumbel-Softmax实现硬路由但保持梯度
one_hot = F.gumbel_softmax(logits, tau=1.0, hard=True, dim=-1)
else:
# 推理时:纯硬路由
idx = torch.argmax(logits, dim=-1)
one_hot = F.one_hot(idx, num_classes=3).float()
assignments = torch.argmax(one_hot, dim=-1)
return one_hot, assignments这种设计的关键在于:在推理阶段采用硬路由,每个query只保留被选中的专家输出,从而避免"坏模态把好模态拖下水"。
3.4 步骤3:路由后压缩token
路由后的任务token会进一步压缩,再送入LLM。这样既提升了有效信息密度,也减轻了轻量级LLM的输入负担:
python
class BranchCompressor(nn.Module):
"""通过交叉注意力将可变长度的专家输出压缩为固定大小的token"""
def __init__(self, hidden_dim, num_compress_tokens, num_heads=8):
super().__init__()
self.compress_queries = nn.Parameter(
torch.randn(num_compress_tokens, hidden_dim) * 0.02
)
self.attn = nn.MultiheadAttention(hidden_dim, num_heads, batch_first=True)
self.norm = nn.LayerNorm(hidden_dim)
def forward(self, expert_output):
"""
Args:
expert_output: [B, N_variable, D] 可变长度的专家输出
Returns:
compressed: [B, num_compress_tokens, D] 固定长度的压缩token
"""
B = expert_output.shape[0]
queries = self.compress_queries.unsqueeze(0).expand(B, -1, -1)
if expert_output.shape[1] == 0:
return torch.zeros_like(queries)
compressed, _ = self.attn(queries, expert_output, expert_output)
return self.norm(compressed)最终,MoRo-Former输出的token数量为:5个任务 × 3个专家 × 4个token/分支 = 60个token,这些紧凑的token包含了所有任务的多专家表示。
3.5 MoRo-Former的优势
这套设计破解了越野场景中的一个核心矛盾:不是所有模态都该永远被同等对待,而应该让任务和环境共同决定"此刻最该信谁" 。相比传统方法的优势包括:自适应性 ,根据环境条件动态选择可靠模态;任务专用性 ,不同任务可以使用不同的模态组合;鲁棒性 ,单模态失效时不会污染整体决策;效率,通过压缩减少LLM的输入负担。
4. 核心创新二:轻量级LLM的结构化场景理解
很多人一提到LLM,就会自然想到开放式长文本生成。但Wild-Drive反而走了一个很务实的方向:不追求"会说很多",而追求"说得稳定、说得结构化、说得对规划有用" 。考虑到野外机器人的计算资源限制,Wild-Drive采用了两种轻量级配置:Wild-Drive-0.5B 使用Qwen2.5-0.5B-Instruct (仅0.71B参数 ),Wild-Drive-3B 使用Qwen2.5-3B-Instruct (3.25B参数 )。这些模型相比动辄70B+的大模型,在边缘设备上更容易部署,同时通过精心设计的结构化输出模板,依然能够达到很好的理解效果。
4.1 结构化Q&A模板设计
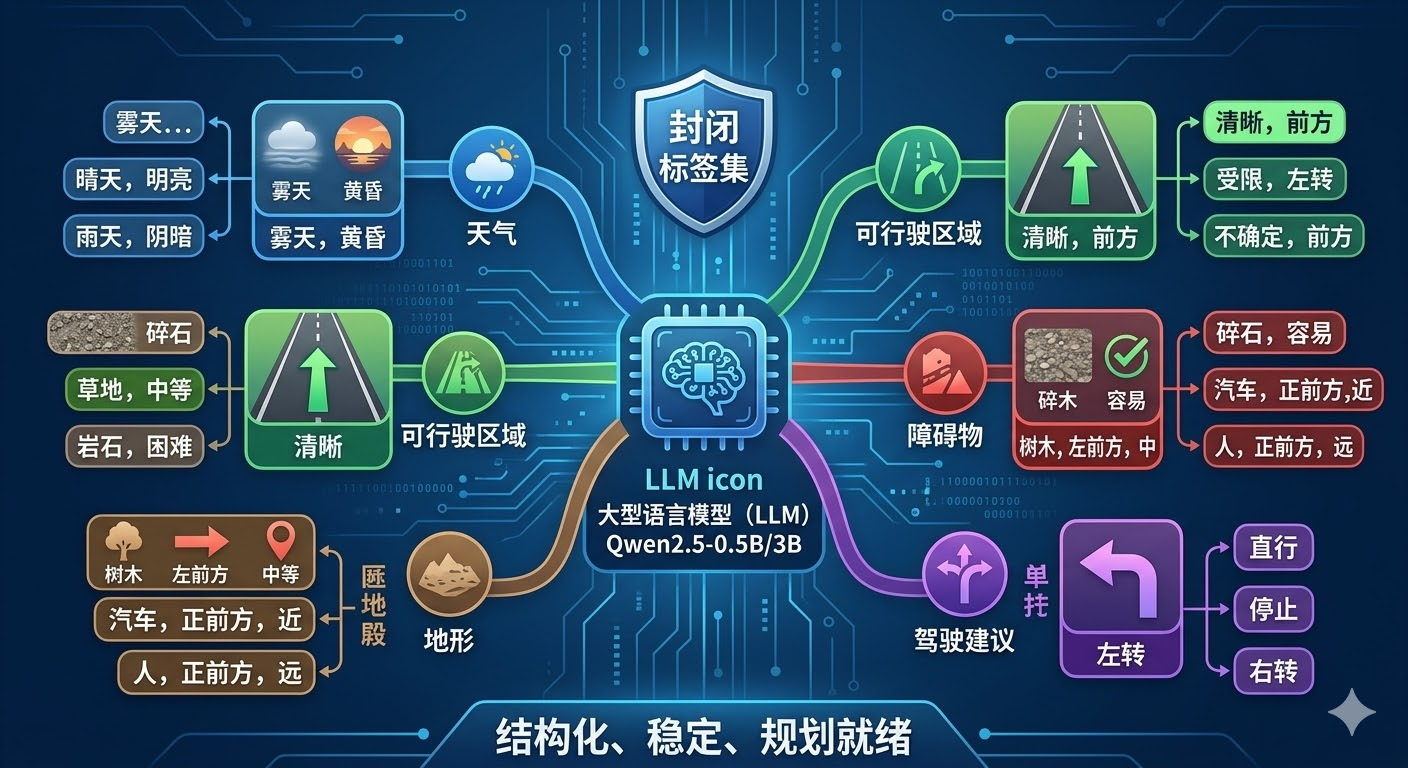
为适配轻量级LLM的容量,论文专门设计了结构化Q&A模板 ,把复杂越野理解问题压缩为有限标签空间 。天气描述 表示为"天气+光照"的配对标签,天气类型包括sunny、cloudy、rainy、snowy、foggy,光照条件包括bright_light、daylight、twilight、darkness,示例输出"foggy, dusk"表示黄昏时的雾天。可通行区域 判断前方区域的可通行性和方向,可通行状态包括clear、partially_blocked、blocked,可通行方向包括front、front_left、front_right、left、right,示例输出"clear, front"表示正前方可通行。地形通行性 识别地形类型和通行难度,地形类型包括dirt、gravel、grass、mud、sand、snow、rock,通行难度包括easy、moderate、hard、impassable,示例输出"gravel, easy"表示砂石路面容易通过。障碍物检测 包括障碍类别(vehicle、pedestrian、animal、rock、tree、pole、building、unknown)、方位(front、front_left、front_right、left、right)和距离(near、mid、far),示例输出"tree, front_left, mid"表示左前方中等距离有树木。驾驶建议 基于场景理解给出高层决策,动作类型包括go_straight、turn_left、turn_right、stop,示例输出"turn_left"表示建议左转。
4.2 LLM集成代码实现
在VLM模型中,LLM的集成非常巧妙。系统使用特殊token <|image_pad|> 和 <|plan_pad|> 来标记多模态输入和规划位置:
python
# 注册特殊token
special_tokens = {
"additional_special_tokens": ["<|image_pad|>", "<|plan_pad|>"]
}
num_added = self.tokenizer.add_special_tokens(special_tokens)
if num_added > 0:
self.llm_model.resize_token_embeddings(len(self.tokenizer))
# 前向传播:融合文本和图像嵌入
text_embeds = self.llm_model.get_input_embeddings()(input_ids)
inputs_embeds = self._merge_embeddings(text_embeds, image_embeds, input_ids)
# LLM生成(需要输出hidden states用于规划)
llm_outputs = self.llm_model(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
output_hidden_states=self.config.use_planning, # 关键:输出隐藏状态
)