目录
- 一、基本介绍
-
- [1.1 Hive基本概念与架构](#1.1 Hive基本概念与架构)
- [1.2 Hive日志和历史记录的配置](#1.2 Hive日志和历史记录的配置)
- [1.3 Hive数据类型与集合案例](#1.3 Hive数据类型与集合案例)
- [1.4 类型转化](#1.4 类型转化)
- [1.5 DDL](#1.5 DDL)
- [1.6 数据与Hive表映射的三种方式](#1.6 数据与Hive表映射的三种方式)
- [1.7 内部表 外部表](#1.7 内部表 外部表)
- [1.8 数据导入](#1.8 数据导入)
- [1.9 数据导出](#1.9 数据导出)
- 二、查询
-
- [2.1 查询语法和数据准备](#2.1 查询语法和数据准备)
- [2.2 比较运算符和逻辑运算符](#2.2 比较运算符和逻辑运算符)
- [2.3 Like和RLike](#2.3 Like和RLike)
- [2.4 分组查询案例](#2.4 分组查询案例)
- [2.5 join](#2.5 join)
-
- 总结与测试数据
- [内连接 取交集](#内连接 取交集)
- A(emp)表的所有数据
- B(dept)表的所有数据
- emp特有数据
- dept特有数据
- 满外连接
- A和B特有的数据
- 多表join
- [2.6 排序](#2.6 排序)
- 三、分区表和分桶表
-
- [3.1 分区表/分桶表大致概念](#3.1 分区表/分桶表大致概念)
- [3.2 分区表基本操作](#3.2 分区表基本操作)
- [3.3 二级(多级)分区](#3.3 二级(多级)分区)
- [3.4 先有数据 和分区表如何关联](#3.4 先有数据 和分区表如何关联)
-
- [手动创建分区目录 手动上传数据到分区目录 再手动修复](#手动创建分区目录 手动上传数据到分区目录 再手动修复)
- [手动创建分区目录 手动上传数据到分区目录 然后添加一个分区和它对应](#手动创建分区目录 手动上传数据到分区目录 然后添加一个分区和它对应)
- [手动创建分区目录 load数据到分区中](#手动创建分区目录 load数据到分区中)
- [3.5 动态分区](#3.5 动态分区)
- [3.6 分桶表](#3.6 分桶表)
- [3.7 抽样查询](#3.7 抽样查询)
- 四、函数
-
- [4.1 系统内置函数](#4.1 系统内置函数)
- [4.2 常用函数](#4.2 常用函数)
- [4.3 空字段赋值](#4.3 空字段赋值)
- [4.4 CASE和IF](#4.4 CASE和IF)
- [4.5 行转列](#4.5 行转列)
- [4.6 列转行](#4.6 列转行)
- [4.7 窗口函数/开窗函数](#4.7 窗口函数/开窗函数)
-
- 0.原始数据和相关函数
- 1.查询在2017年4月份购买过的顾客及总人数
- [2.查询顾客的购买明细 及 所有顾客的月购买总额](#2.查询顾客的购买明细 及 所有顾客的月购买总额)
- [3.查询顾客的购买明细 及 每个顾客的月购买总额](#3.查询顾客的购买明细 及 每个顾客的月购买总额)
- 4.将每个顾客的cost按照日期进行累加
- 5.将所有顾客的cost按照日期进行累加
- [6.查询每个顾客上次的购买时间 及 下一次的购买时间](#6.查询每个顾客上次的购买时间 及 下一次的购买时间)
- 7.查询前20%时间的订单信息
- 小结
- 关键字小结
- [4.8 排名函数](#4.8 排名函数)
一、基本介绍
1.1 Hive基本概念与架构
1.Hive是基于Hadoop的 一个数据仓库工具 可以将结构化的 数据文件映射为一张表 并提供类SQL查询功能
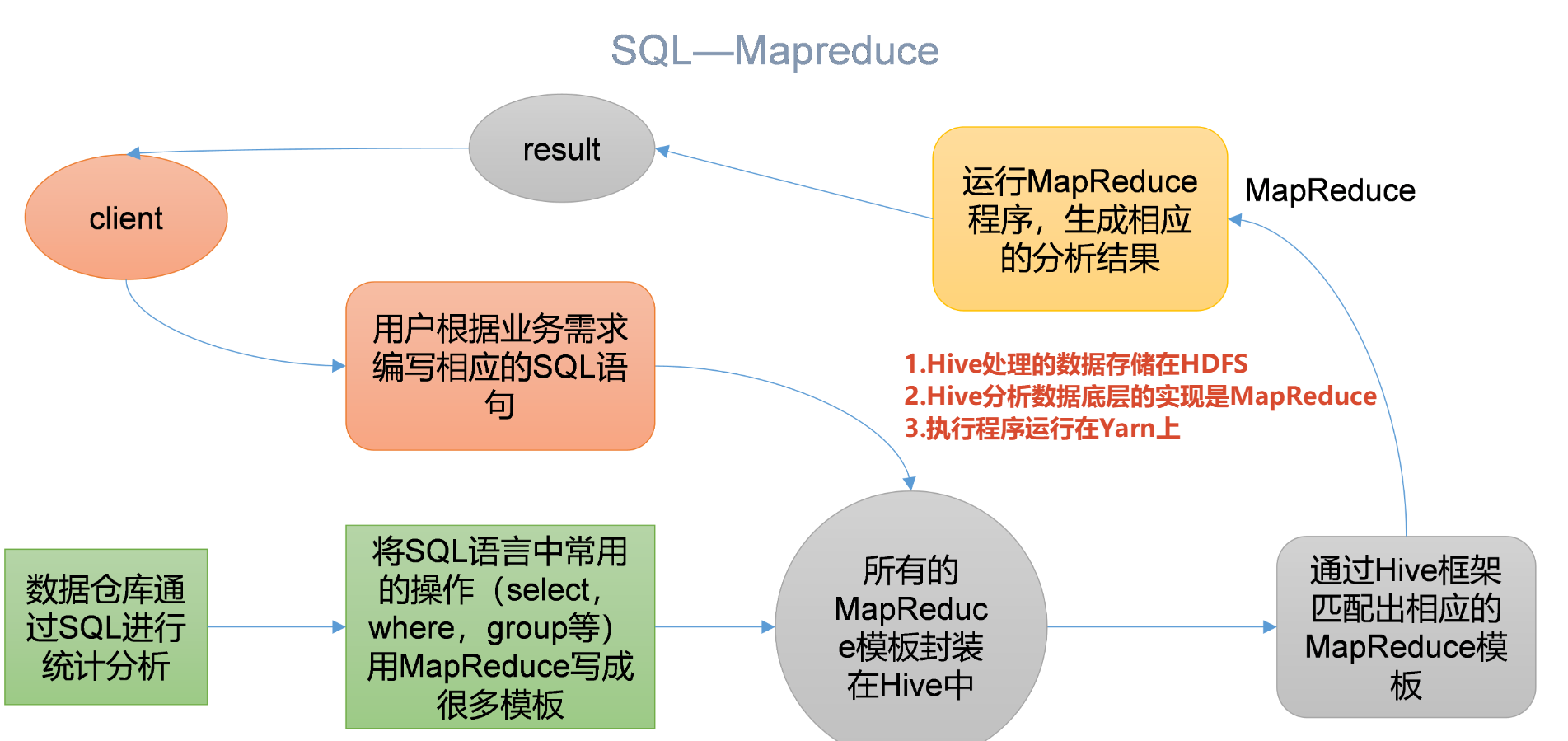
2.Hive本质:将HQL转化成MapReduce程序 自动生成的MR 通常情况下不够智能化
3.Hive不是数据库 他与数据库除了拥有类似的查询语言 再无类似之处
4.Hive是一个数据仓库分析工具 数仓读多写少 Hive是不建议对数据进行添加/修改操作的 所有的数据都是在加载的时候确定好的
5.Hive没有索引 需要扫描整个表 且底层执行的就是MR 因此会有较高的延迟(数据库的延迟一般很低的)
6.Hive基于大数据集群 支持大规模数据处理(数据规模较小的时候 建议使用数据库比如MySQL)
7.迭代式算法无法表达
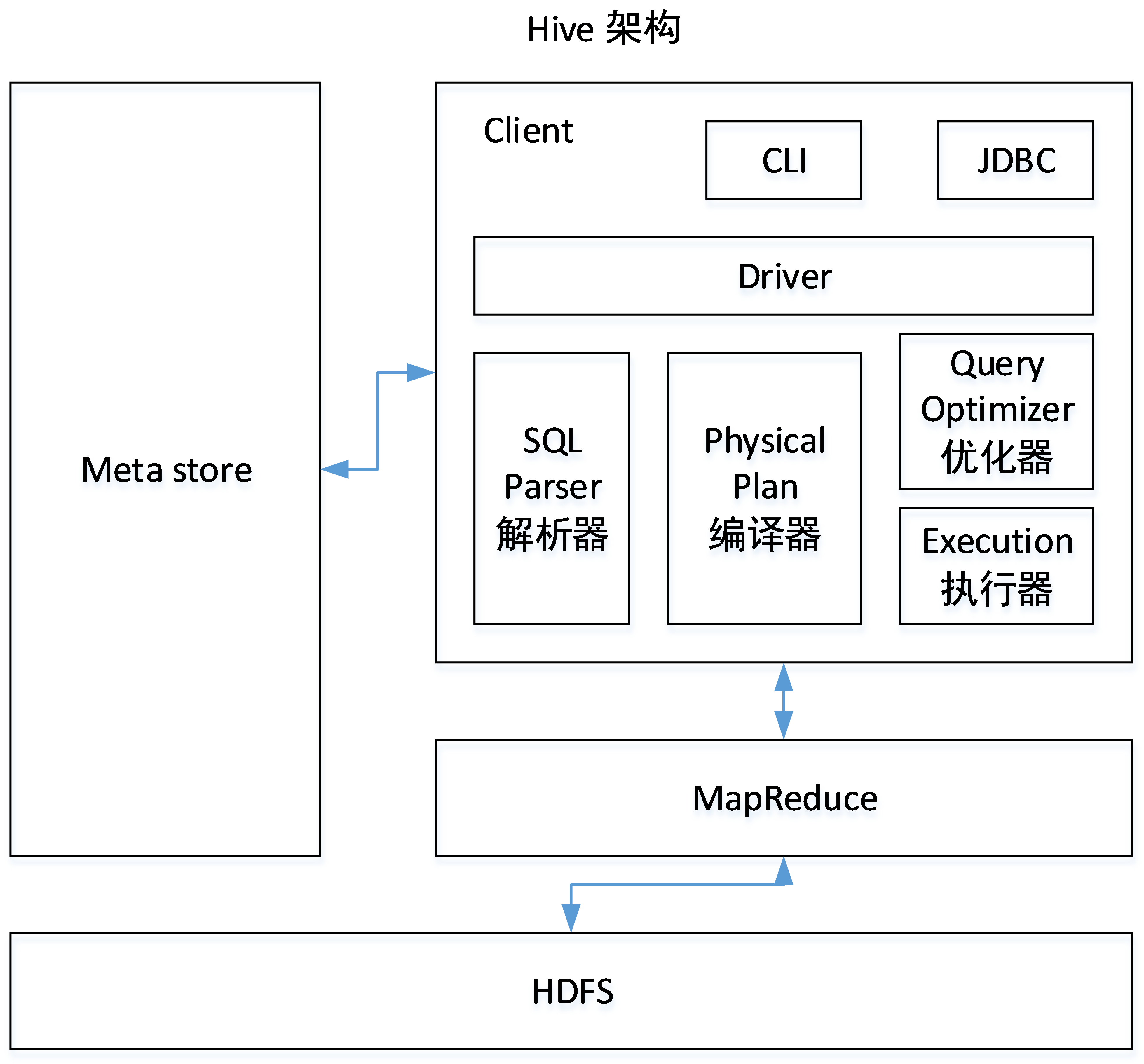
1.客户端Client:CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)2.元数据存储Metastore:表名、表所属的数据库、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等(默认存储在自带的derby数据库中 只支持一个客户端连接Hive 推荐使用MySQL存储Metastore )
3.使用HDFS进行存储 使用MapReduce交给Yarn进行计算
4.Driver:
(1)解析器(SQL Parser) 将SQL字符串转换成抽象语法树AST 这一步一般都用第三方工具库完成 对AST进行语法分析 比如表是否存在、字段是否存在、SQL语义是否有误
(2)编译器(Physical Plan) 将AST编译生成逻辑执行计划 比如大表join小表
(3)优化器(Query Optimizer) 对逻辑执行计划进行优化 比如→小表join大表(优化不允许影响结果)
(4)执行器(Execution)把逻辑执行计划 → 可以运行的物理计划 对于Hive来说 就是MR/Spark/Tez
1.2 Hive日志和历史记录的配置
mv 把模版后缀去掉 就可以指定log文件的位置了
这里可以查看执行的历史命令
1.默认配置文件hive-default.xml 用户自定义配置文件hive-site.xml 用户自定义配置会覆盖默认配置注意 Hive是作为Hadoop的客户端启动的 Hive的配置会覆盖Hadoop的配置
配置文件的设定对本机启动的所有Hive进程都有效
2.命令行参数方式 启动Hive时 可以在命令行添加-hiveconf param=value来设定参数
例如hive -hiveconf mapred.reduce.tasks=10 仅对本次hive启动有效
查看参数设置 set mapred.reduce.tasks
3.参数声明方式 可以在HQL中使用SET关键字设定参数
例如 set mapred.reduce.tasks=100 仅对本次hive启动有效
查看参数设置 set mapred.reduce.tasks
上述三种设定方式的优先级依次递增 配置文件<命令行参数<参数声明

1.3 Hive数据类型与集合案例
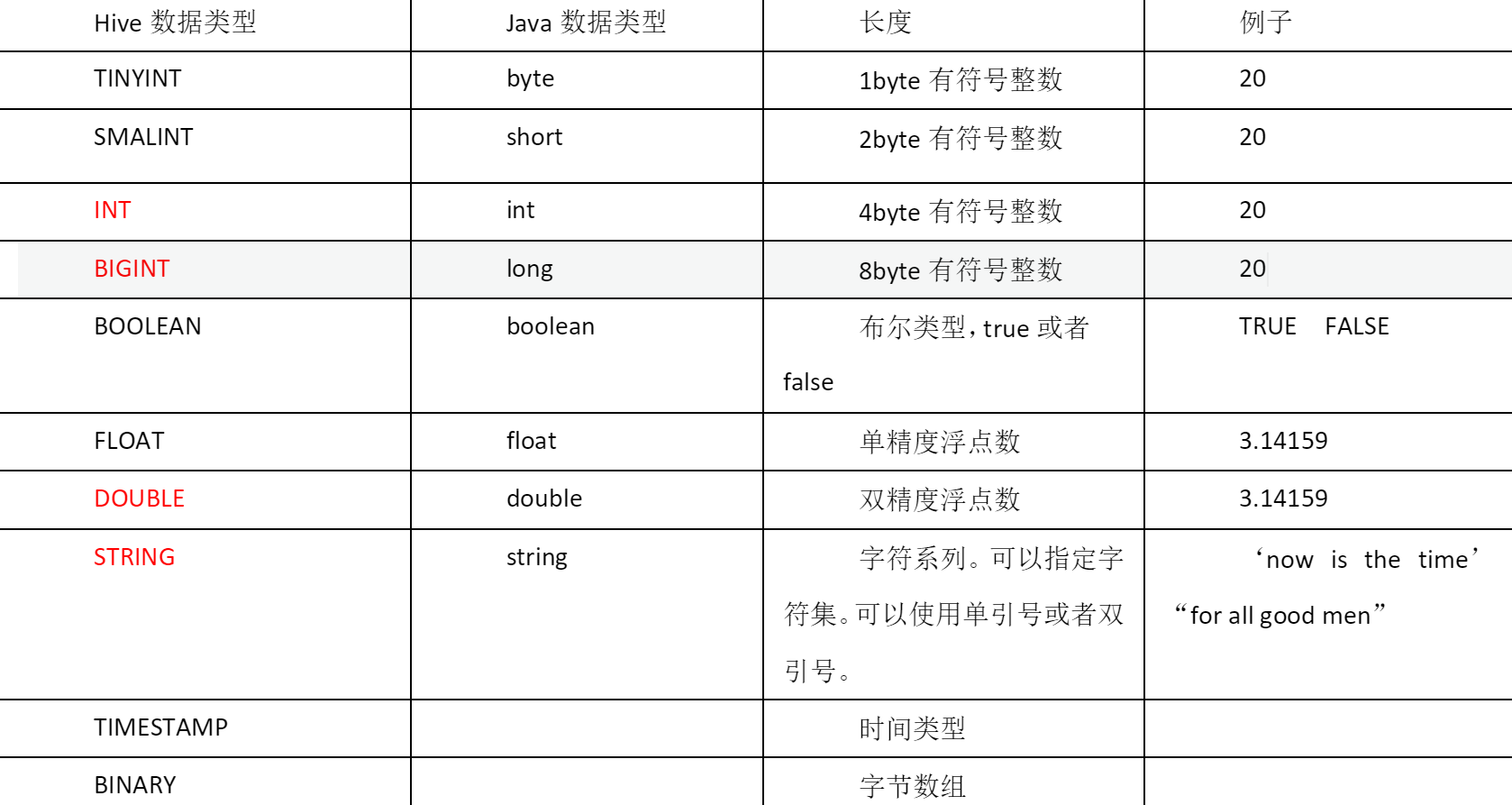
基本数据类型
Hive的String类型 相当于数据库的varchar类型 该类型是一个可变的字符串
不过它不能 声明最多能存储多少个字符 理论上它可以存储2GB的字符数
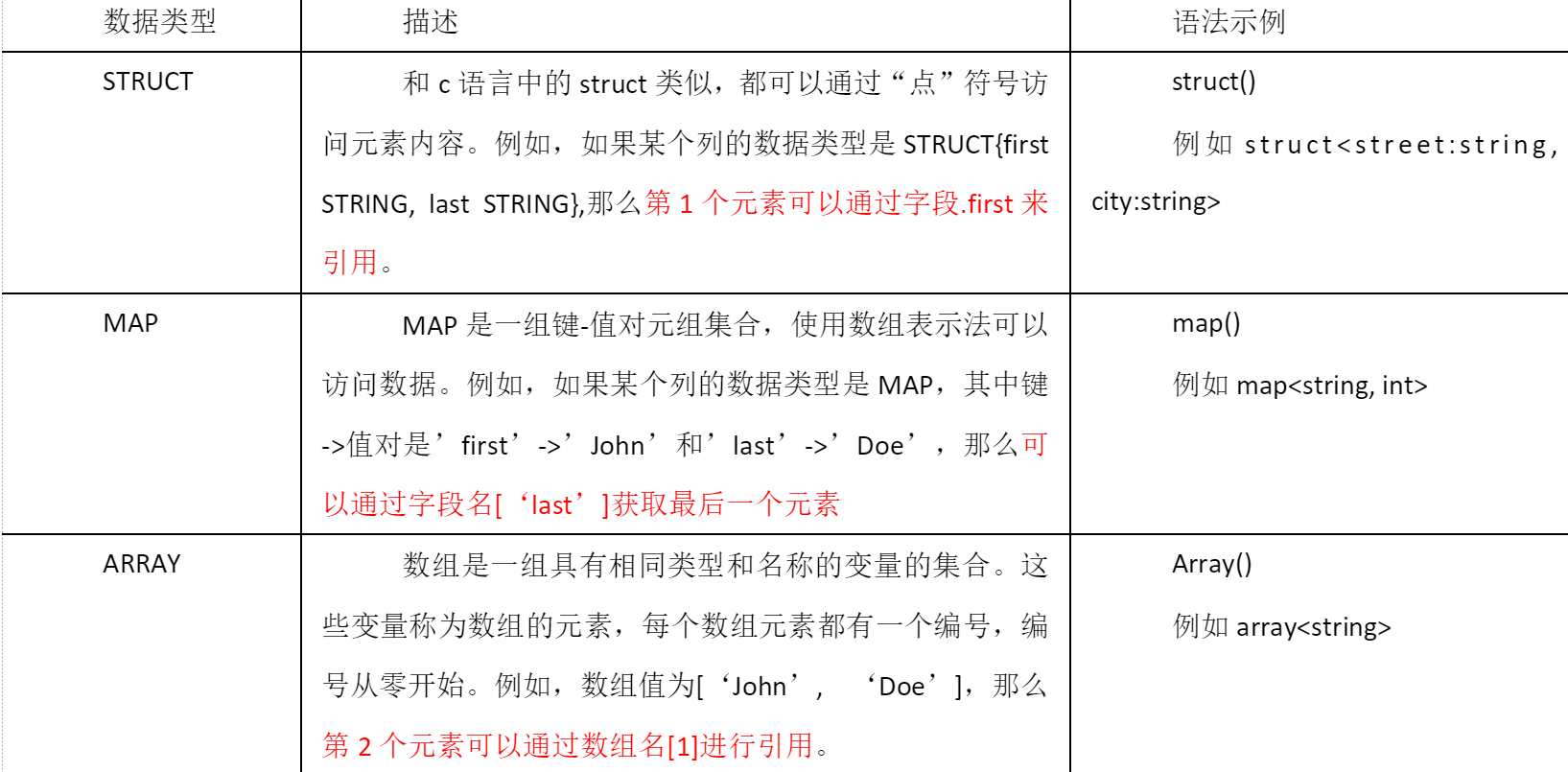
集合数据类型
集合的案列:1.假设某表有如下一行 用JSON格式来表示其数据结构
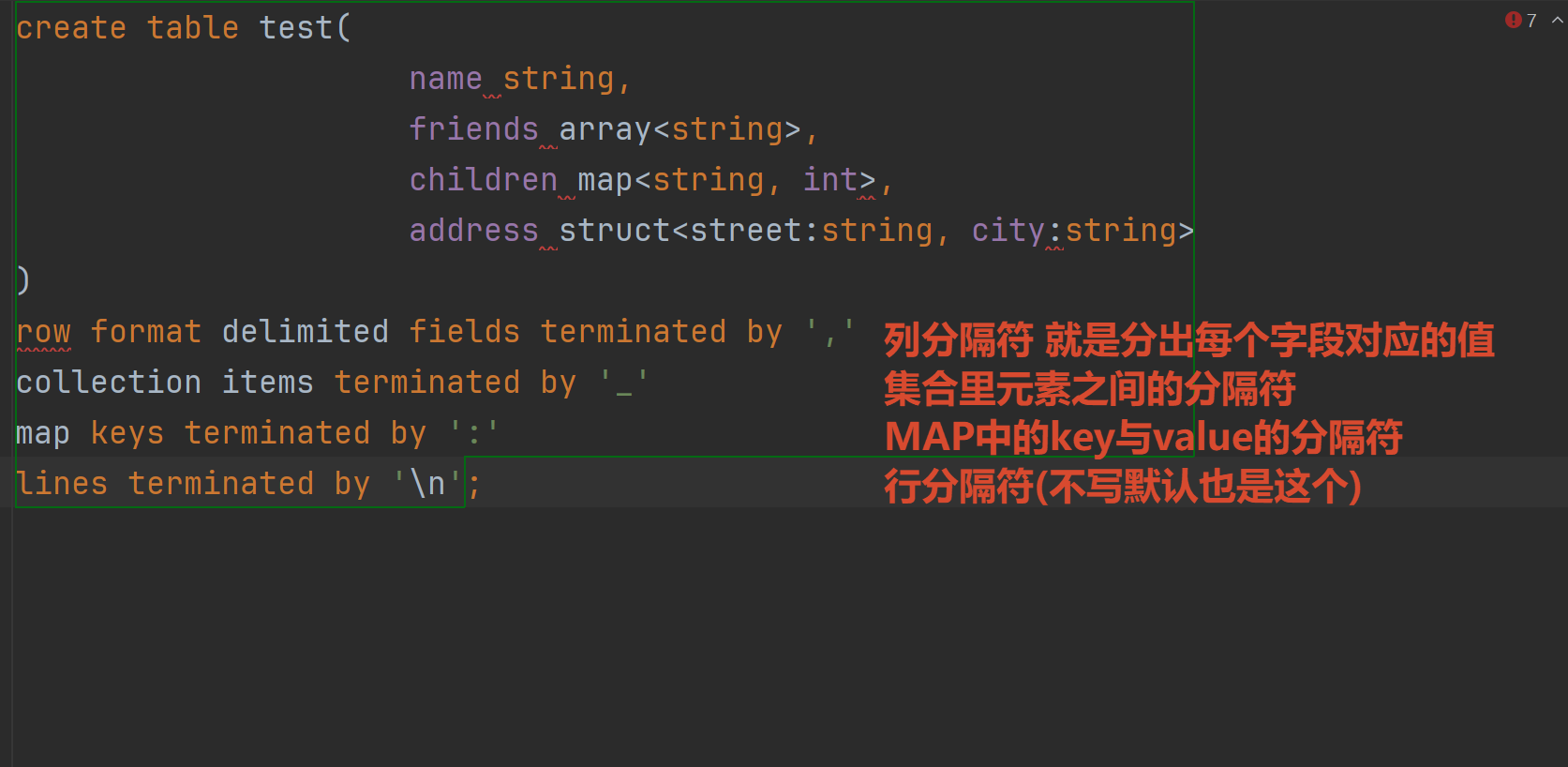
2.基于上述数据结构 在Hive里创建对应的表 并导入数据
创建本地测试文件person.txt 集合里的元素间用同一个字符表示 这里用"_"
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
3.Hive上创建测试表test
4.导入文本数据到测试表
load data local inpath '/home/tmp/person.txt' into table test666;
5.访问三种集合列里的数据 以下分别是ARRAY通过下标 MAP通过K找V STRUCT通过.
select friends1,children'xiao song',address.city from test666 where name='songsong';


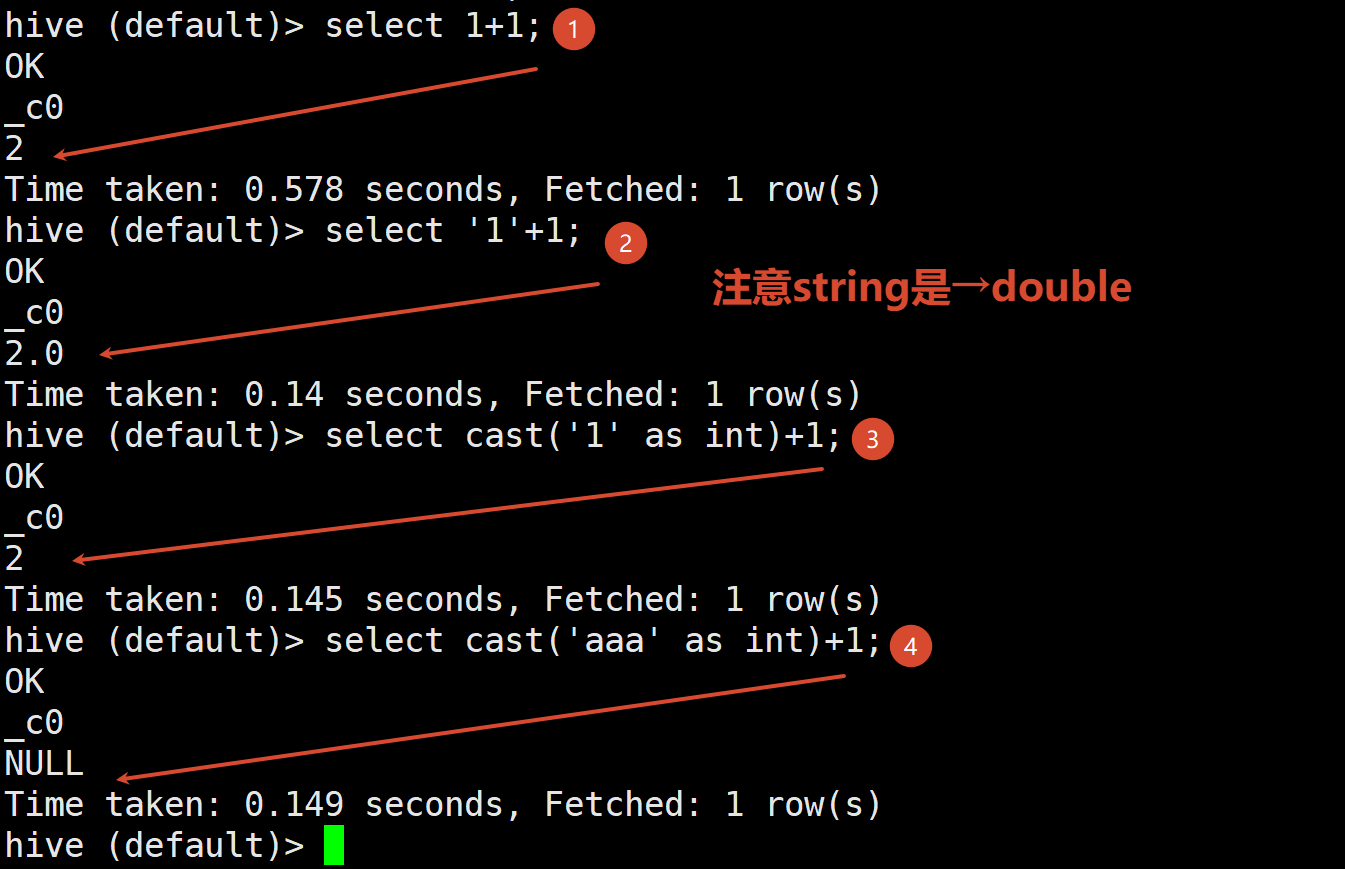
1.4 类型转化
Hive的原子数据类型是可以进行隐式转换的 TINYINT会自动转换为INT类型
但是Hive不会进行反向转化 INT不会自动转换为TINYINT类型 除非使用CAST操作

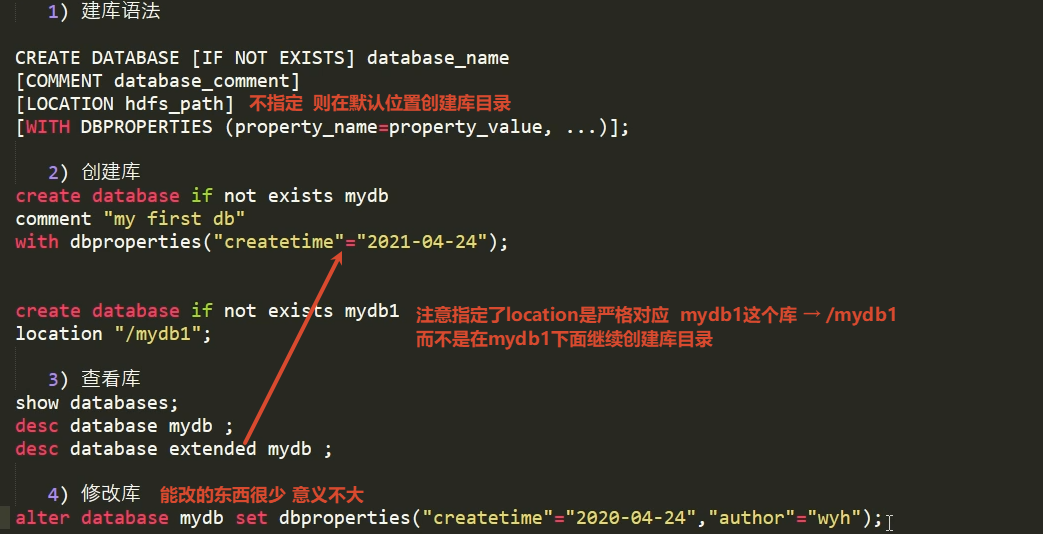
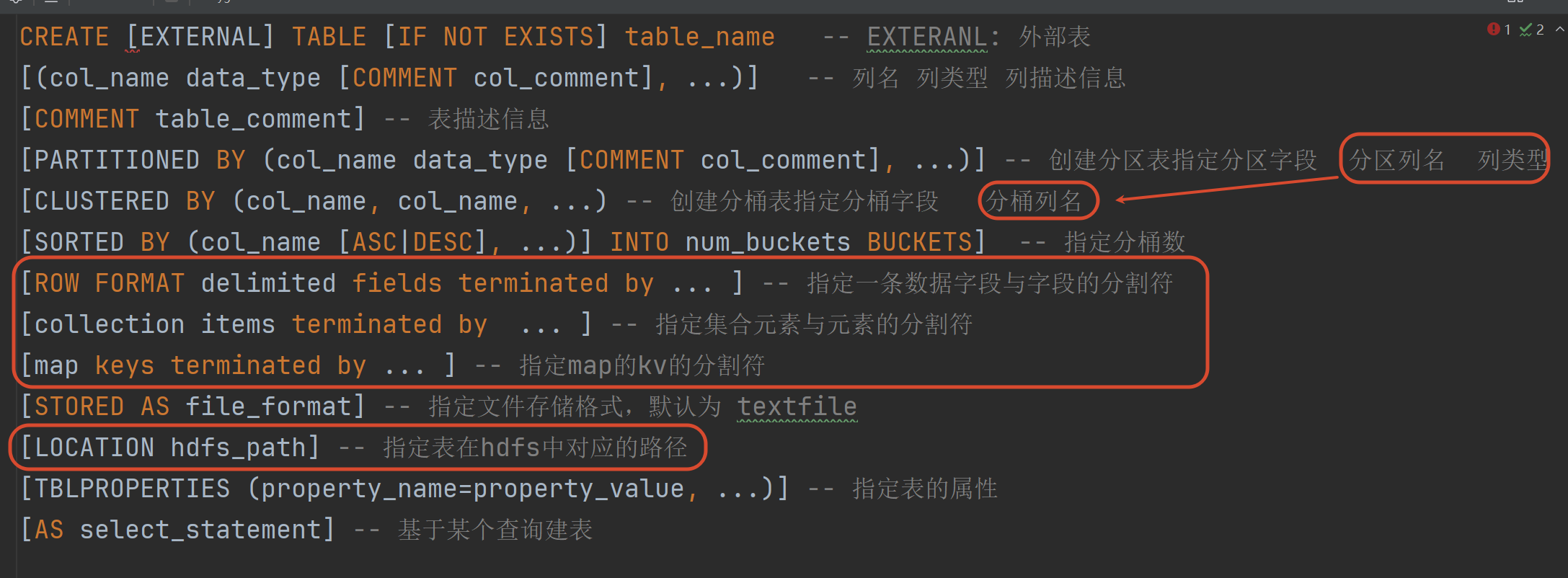
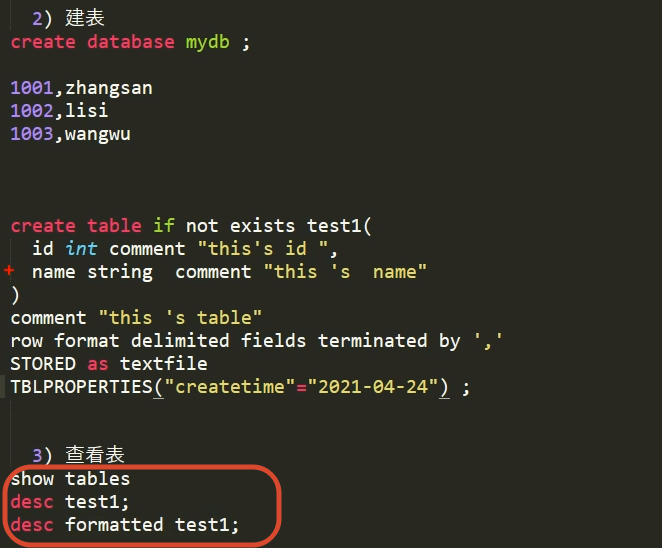
1.5 DDL
库
drop database mydb1; 空库可以直接删
drop database mydb cascade; 有表的库 需要级联
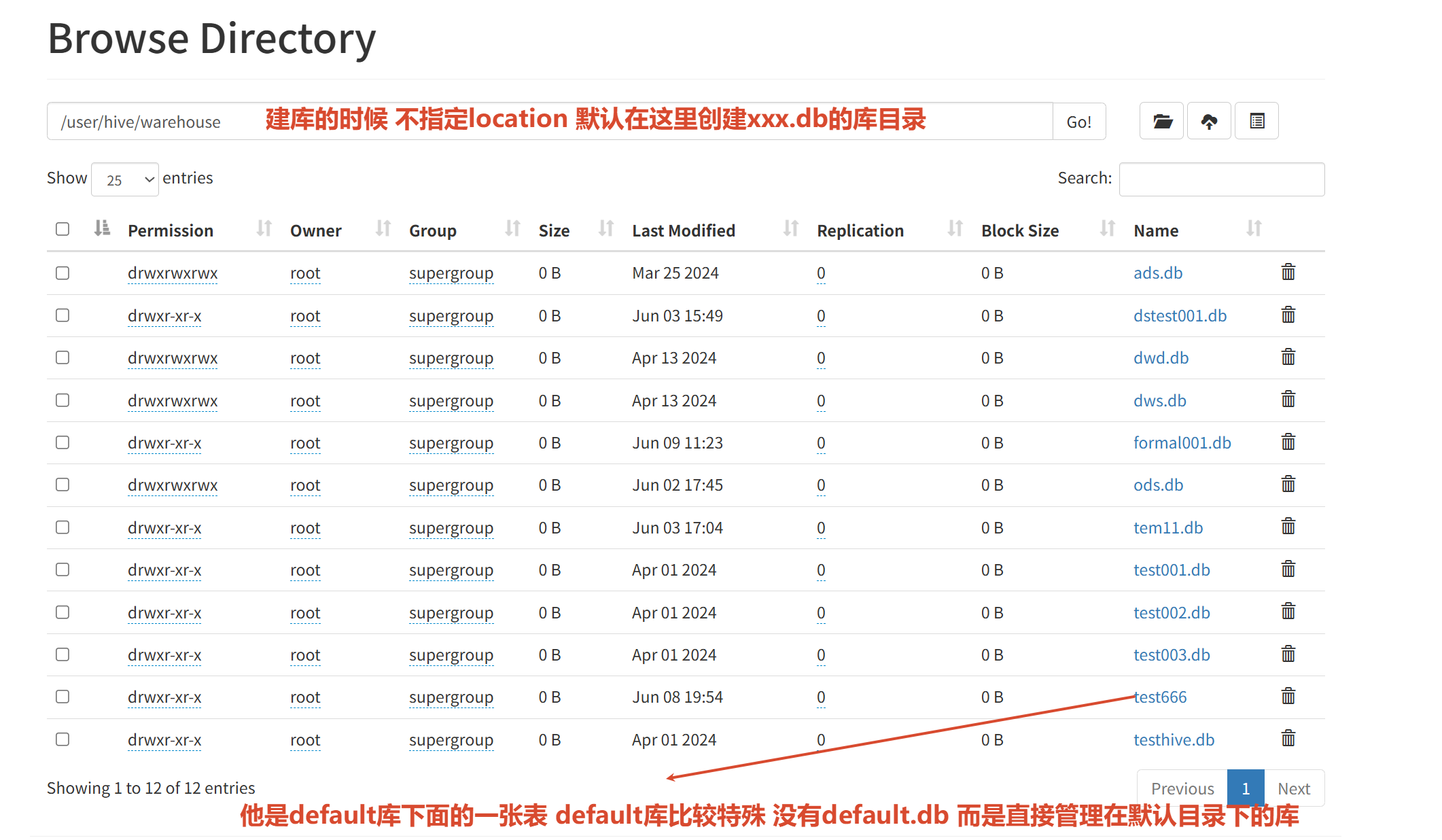
所以这个目录是:1.default库默认对应的库目录
2.不指定location 默认创建库目录的位置
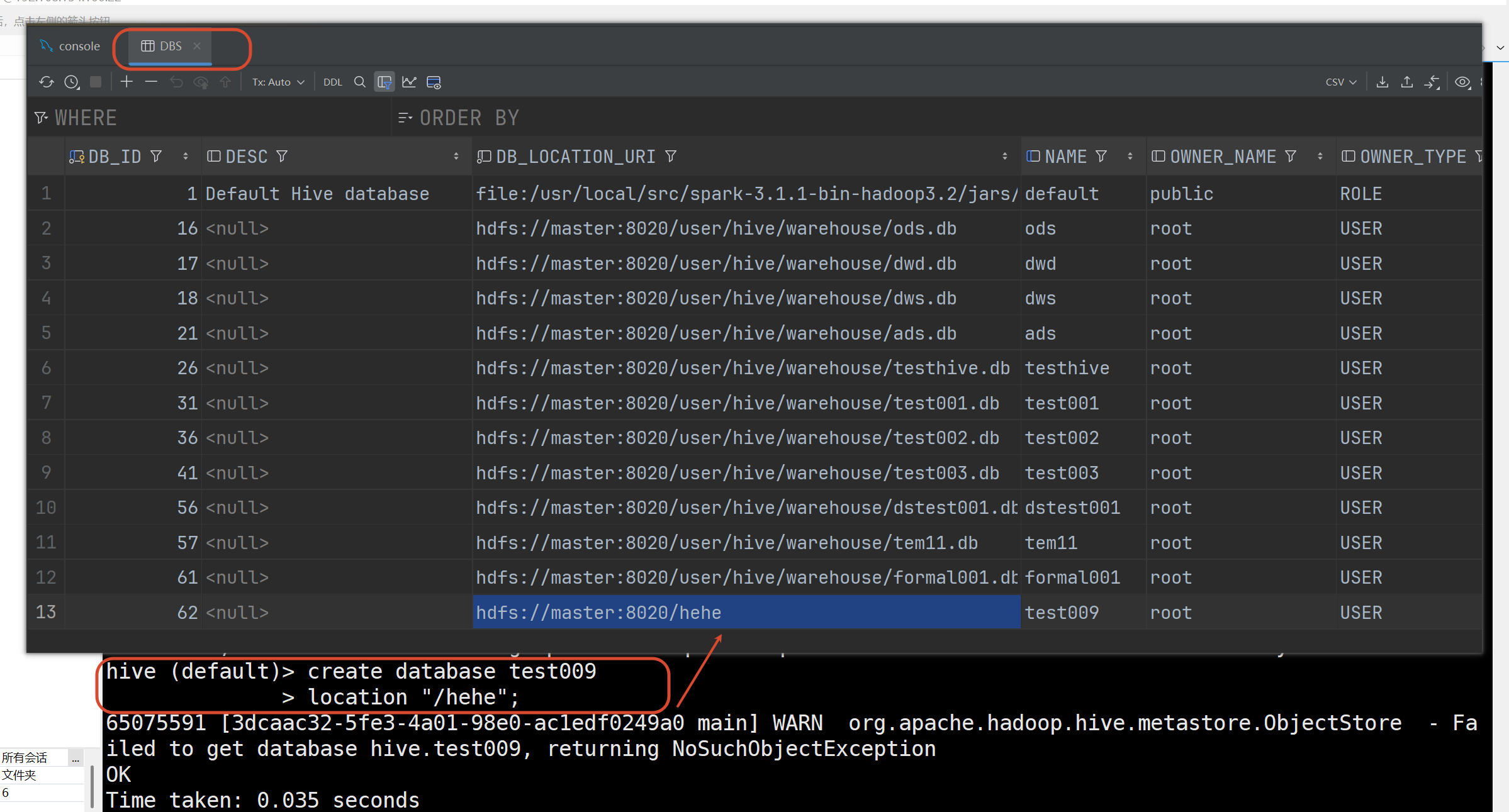
建库 其实就相当于在MySQL的DBS更新了一条元数据

表
建表语句
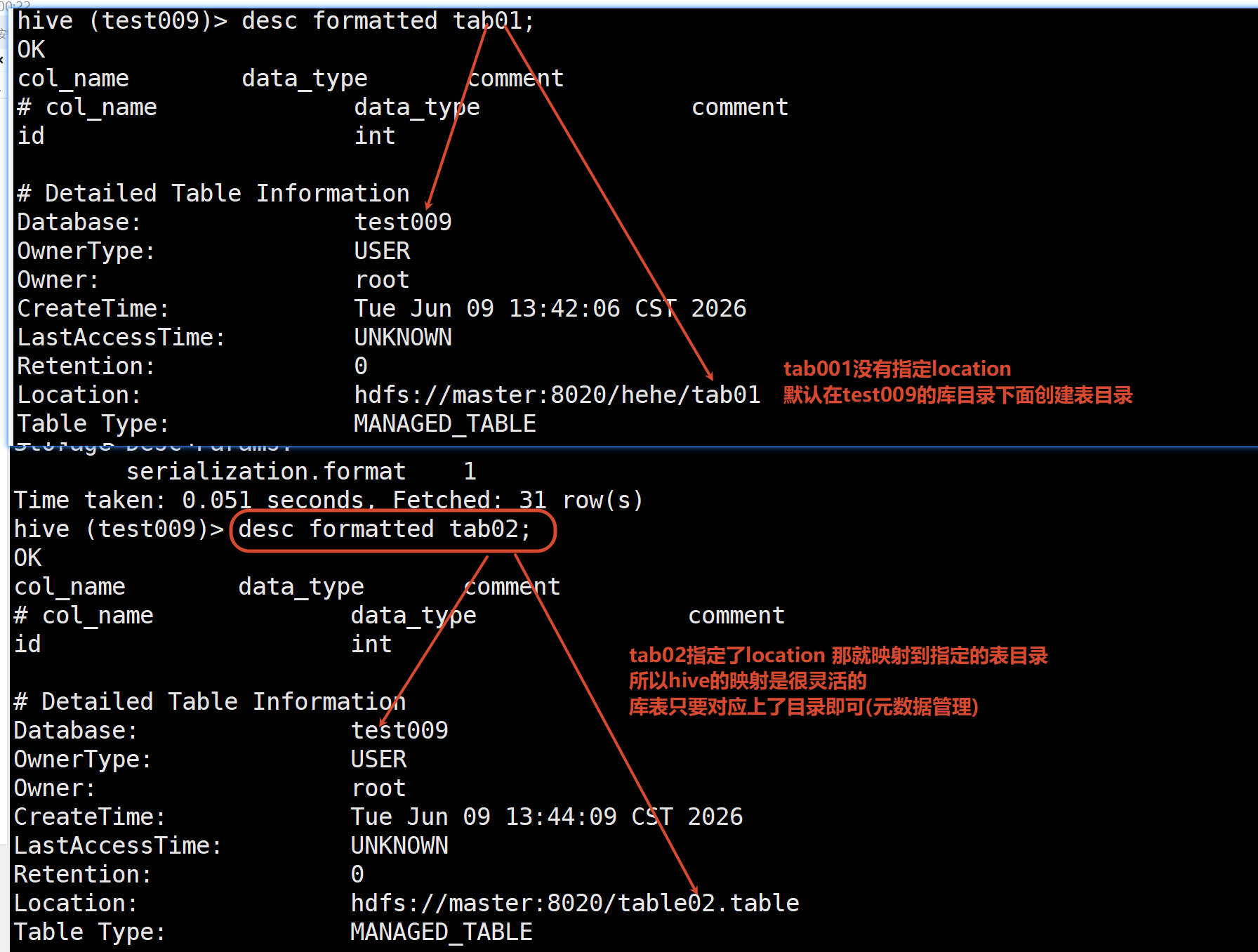
建表的时候 如果没有指定location 当前use哪个库 就在该库目录下创建表目录
表的元数据 在MySQL的TBLS表和SDS可以查到
desc formatted 表;
表不一定就非要在库目录下面不指定表的location 默认是在库目录下
指定了location 就跟location的目录映射
修改表修改列的的时候(第二个alter) 要确保列的新类型 ≥ 原来的类型
假设原始数据有5列 建表只建了3个字段 那就从左往右匹配三列(再alter增加一列 就再往右匹配一列)
如果数据只有3列 建表建了5个字段 匹配不上的就是NULL
删除表:drop table xxx


1.6 数据与Hive表映射的三种方式
方式1:把Linux本地数据load到Hive的表(相当于把数据文件上传到Hive对应的表目录下了 )
方式2:直接把对应的数据put到HDFS对应的hive表目录下 就相当于建立了映射关系了
方式3:数据已经在HDFS上了 那么在创建表的同时 直接把表关联到数据所在目录即可一个表→一个HDFS上的表目录 把数据放到这个表目录下 就相当于对应起来了
总而言之 只要能对应上(无论先有数据还是先有表) 数据就会按建表的规则映射给Hive
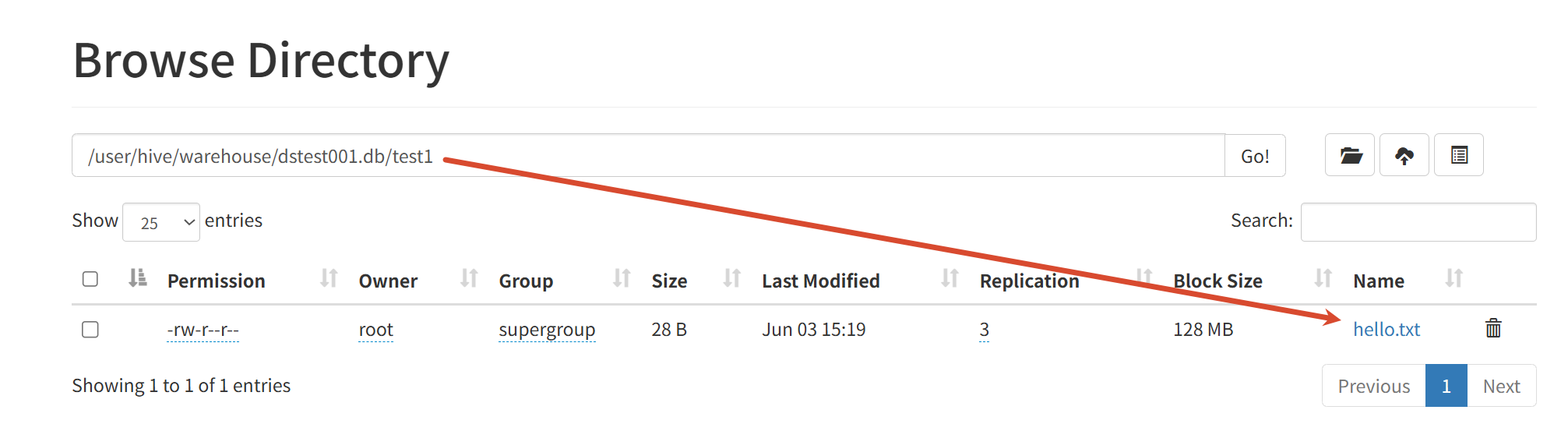
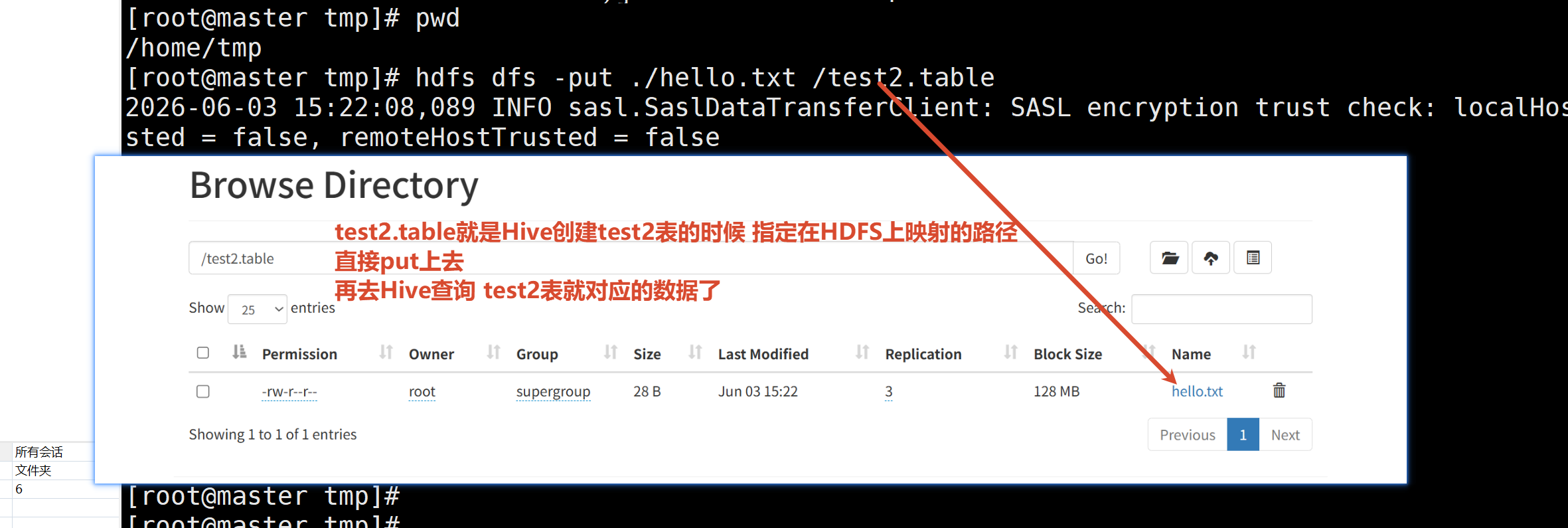
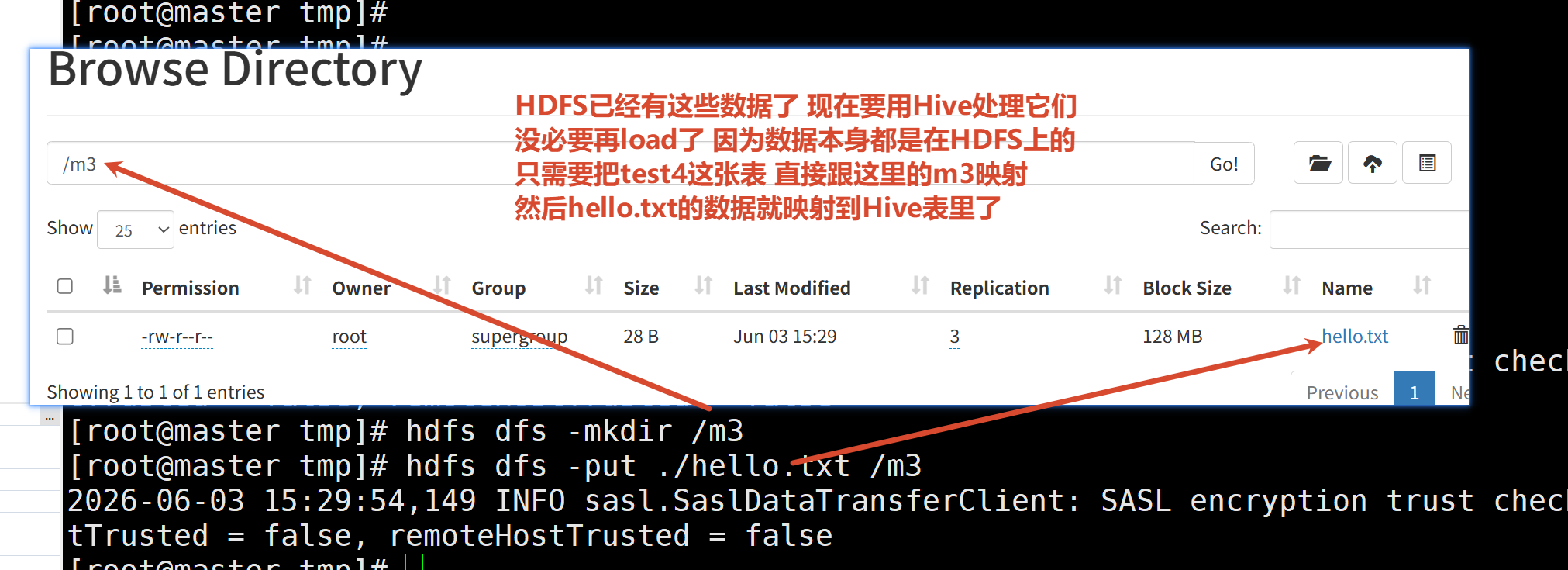
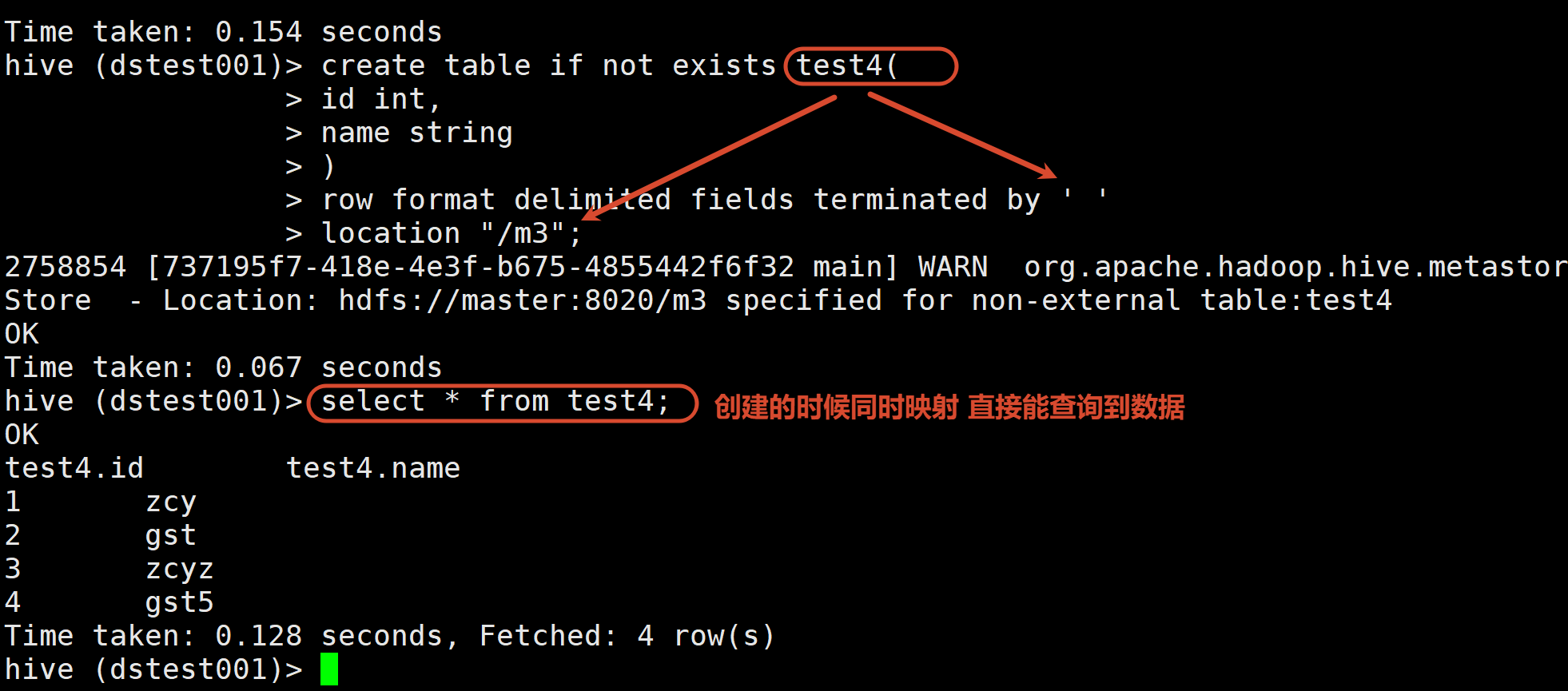
1.7 内部表 外部表
alter table xxx set tblproperties('EXTERNAL'='FALSE'); TRUE就是改为内部表desc formatted xxx 可以查看
drop table test5 删除管理表/内部表 HDFS上对应的目录和下面的数据 全都会被删除
drop table test4 删除外部表 只会把MySQL的元数据删掉(查不到此表了) HDFS上的目录和数据都保留(用的多)
因为一份数据在HDFS上 可能会被hive分析 也可能会被其他分析 hive分析完如果删表 肯定是只删元数据 不删数据本身的
Truncate只能清空管理表/内部表的数据不能删除外部表中数据(理解:外部表没有删除数据的权限)
删除之后 表还在 只是记录被清空了
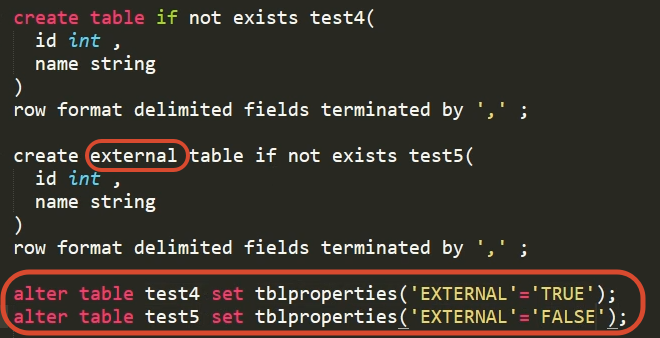

1.8 数据导入
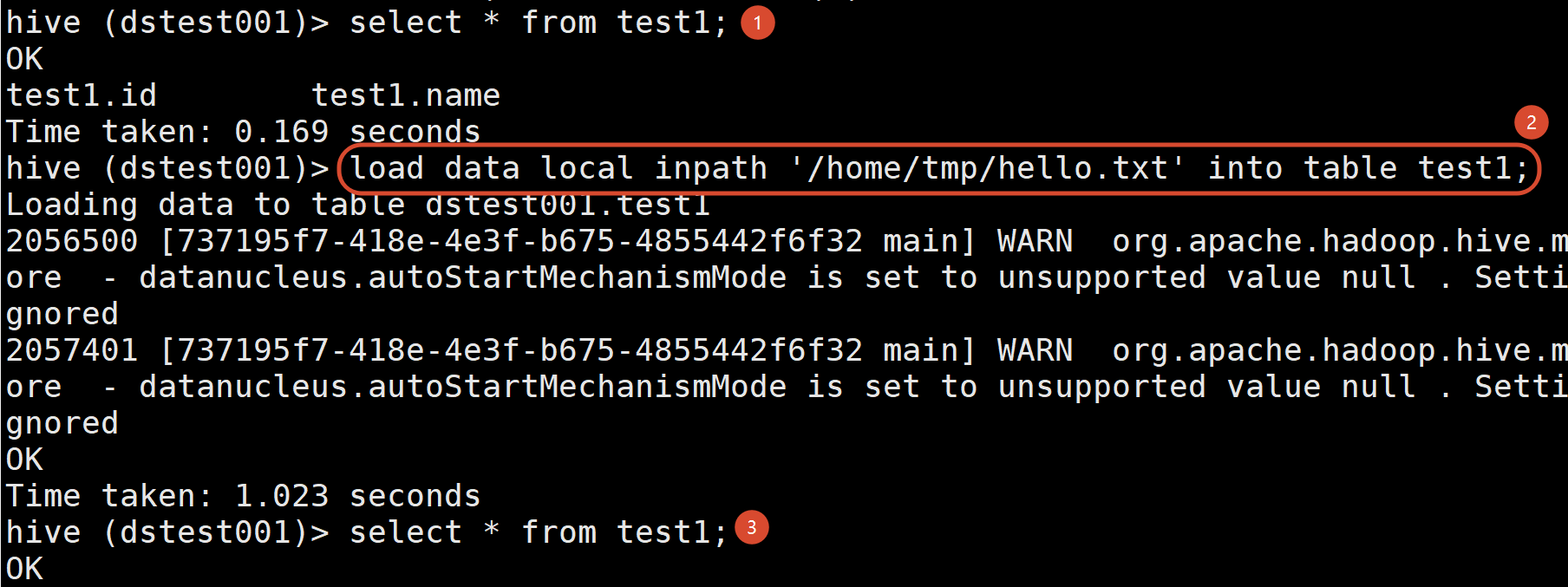
load
load data [local] inpath '数据的path' [overwrite] into table student [partition (partcol1=val1,...)];(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表(拷贝上传 本地还在);否则从HDFS加载数据到hive表(移动或剪贴)
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据 否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区

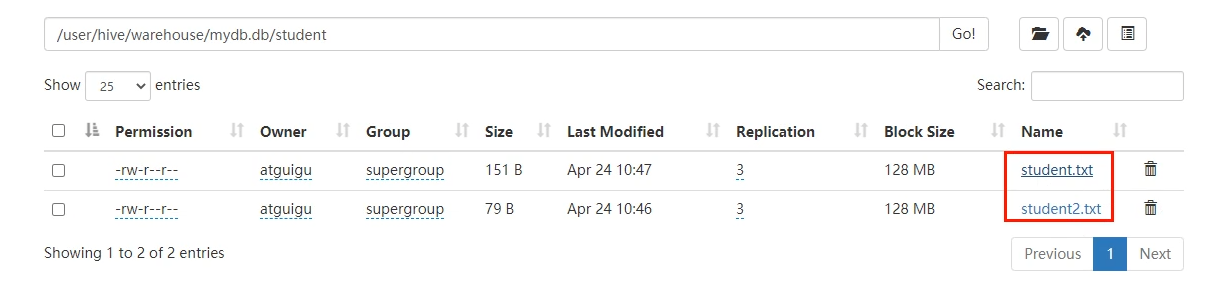
insert
不常用 会跑MR
insert不支持插入部分字段 假如要插入数据到表test test有两个字段id name 则插入的数据必须是1 'aaa'这种的
insert into:以追加数据的方式插入到表或分区 原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
insert into student values(1017,'ss17'),(1018,'ss18'),(1019,'ss19');
insert into student2 select id, name from student ; 把后面的查询结果插入到前面的表(在HDFS上的体现 其实是表目录下多了一个文件)

as select
根据查询结果创建表 查询的结果会添加到新创建的表中
create table student3 as select id, name from student ; 建表的具体字段/内容 根据后面的查询结果
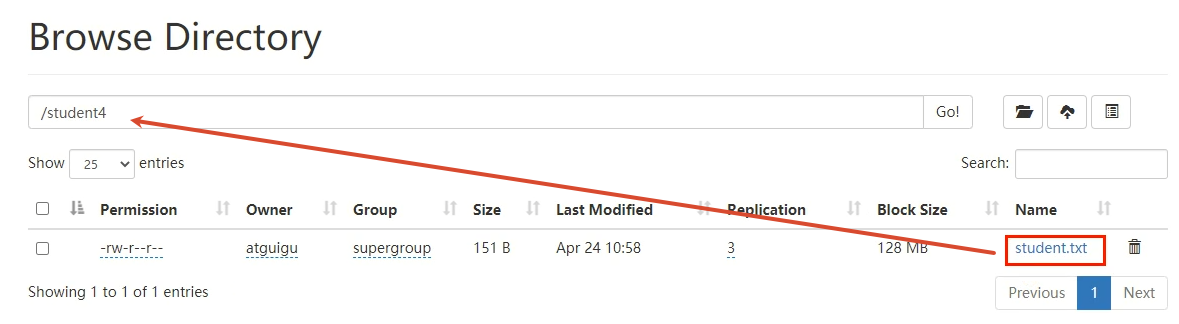
location
建表的时候指定location(HDFS上) 而该location下面已经有数据了 直接建立映射关系
create table student4(id string, name string)
row format delimited fields terminated by '\t'
location '/student4' ;
import
注意:先用export导出后 再将数据导入
import table emptest2 from '/emptest';
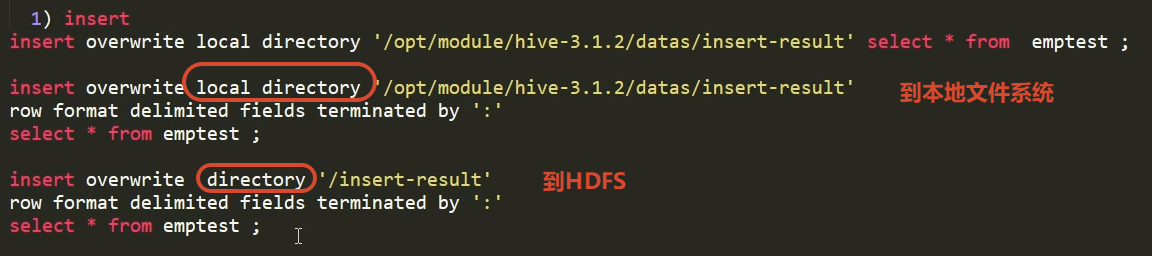
1.9 数据导出
insert
insert overwrite local directory '/insert-result1'
row format delimited fields terminated by ':'
select * from emptest ;
如果表中的列的值为null 导出到文件中以后通过\N来表示
hadoop命令
在hive中可以直接用 把HDFS的文件→本地文件系统
hive (default)> dfs -get /user/hive/warehouse/student/student.txt /opt/module/datas/export/student3.txt;
这就相当于是在Linux本地执行hdfs dfs -get XXX
hive -e并重定向
hive -e 'select * from tem11.test1' > /home/tmp/0.txt;
这里的SQL查到什么 就是什么 不会NULL解析成\N

export
元数据和数据都会被导出 但是只能导出到HDFS
导出表到HDFS
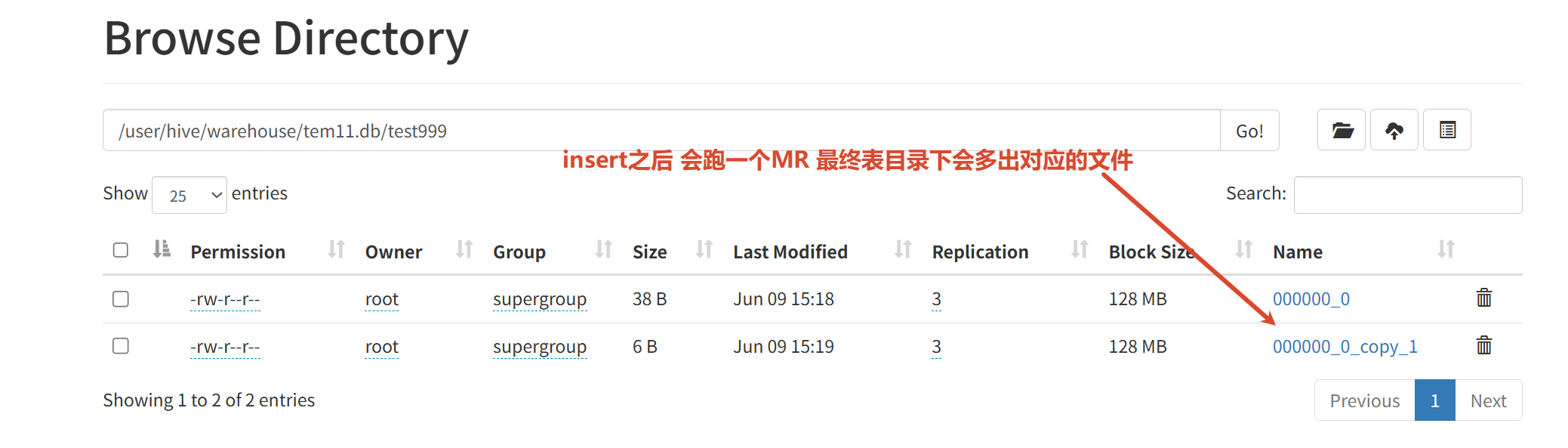
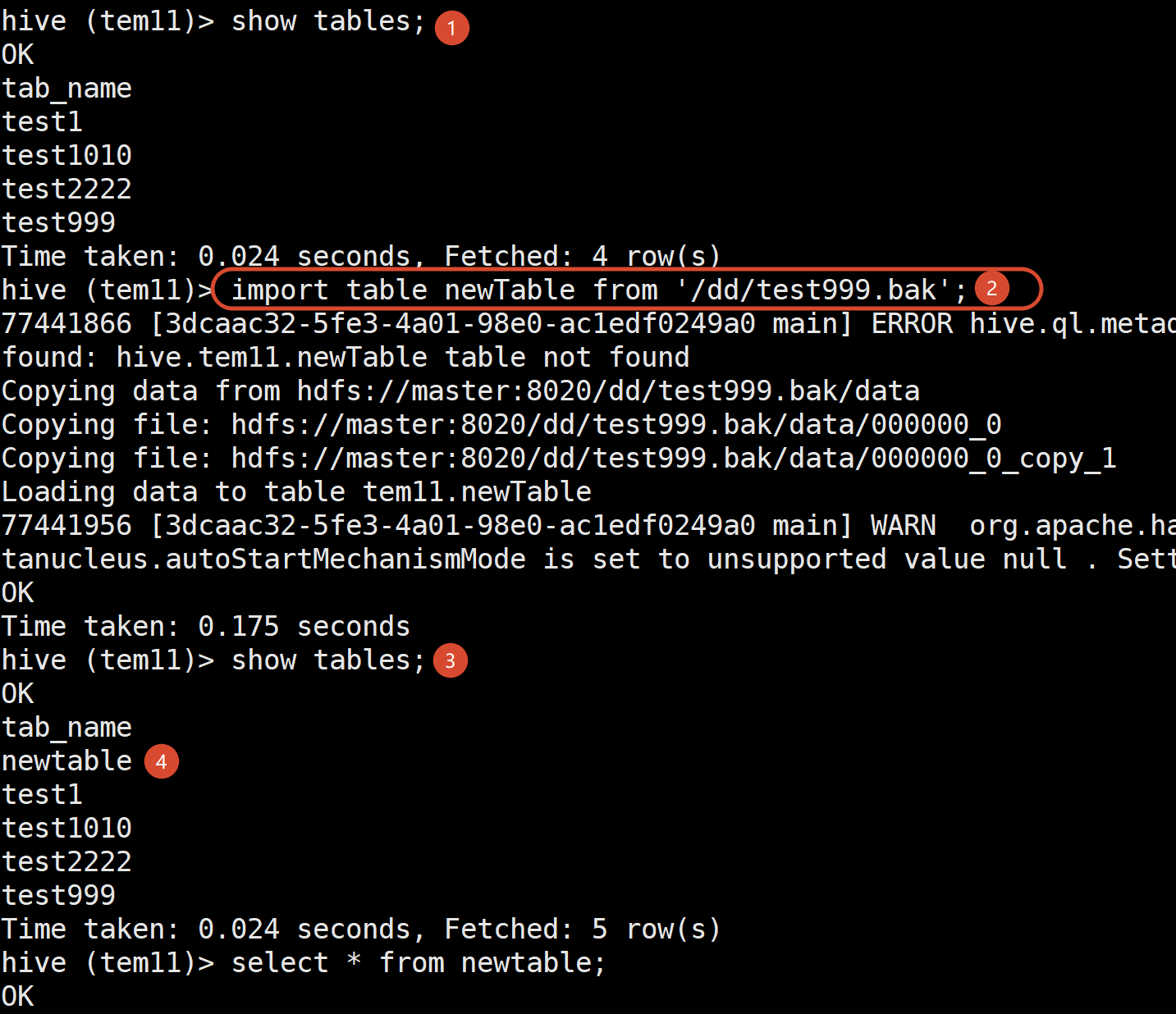
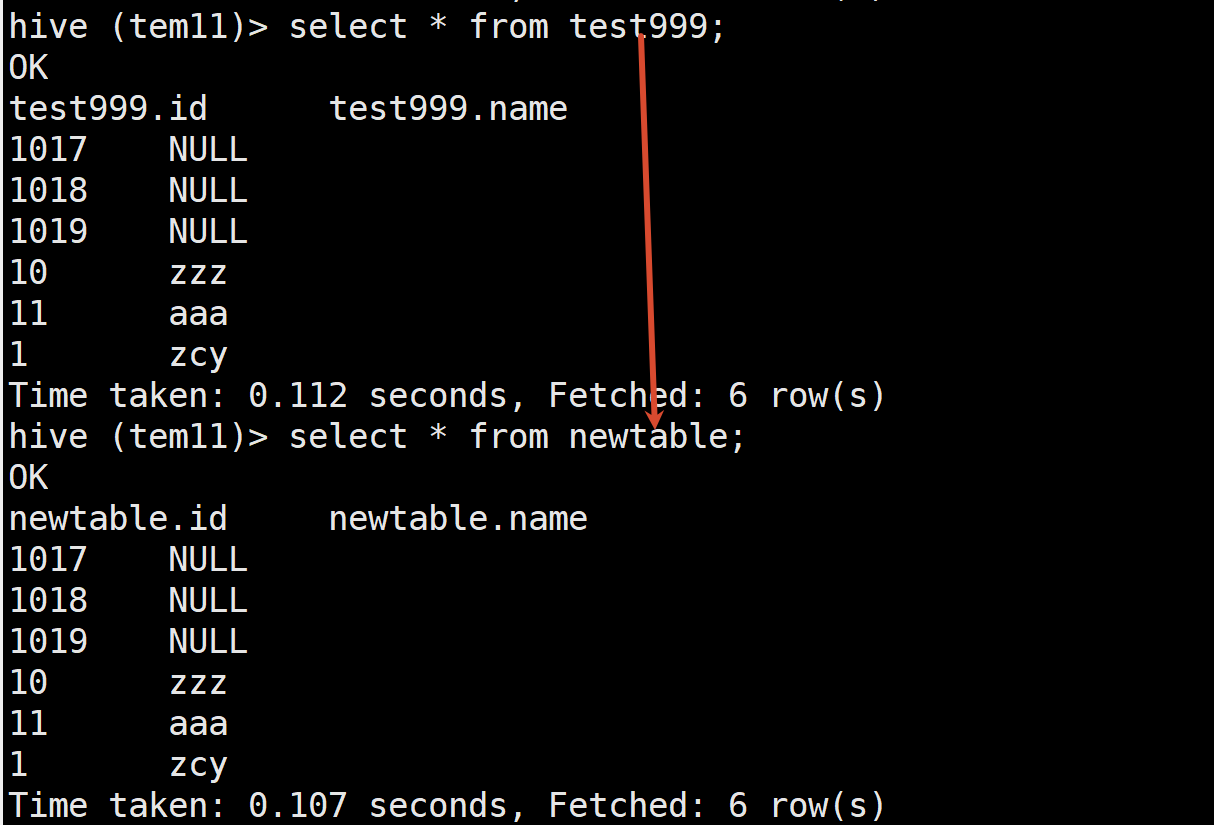
export table test999 to '/dd/test999.bak';再导入这张表到某个库下面
import table newTable from '/dd/test999.bak';
二、查询
2.1 查询语法和数据准备
1.HQL语言大小写不敏感
2.SQL可以写在一行或者多行
3.关键字不能被缩写也不能分行
4.各子句一般要分行写 使用缩进提高语句的可读性
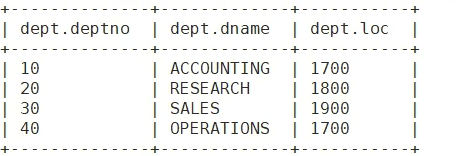
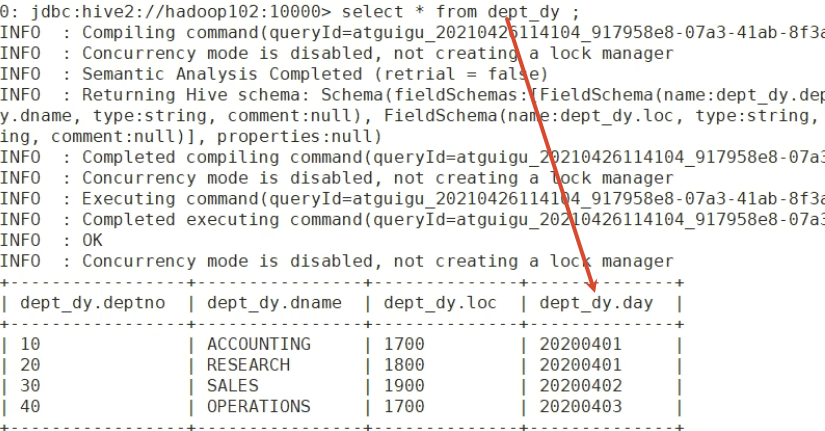
dept:10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
create table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by ' ';
load data local inpath '/opt/module/datas/dept.txt' into table dept;
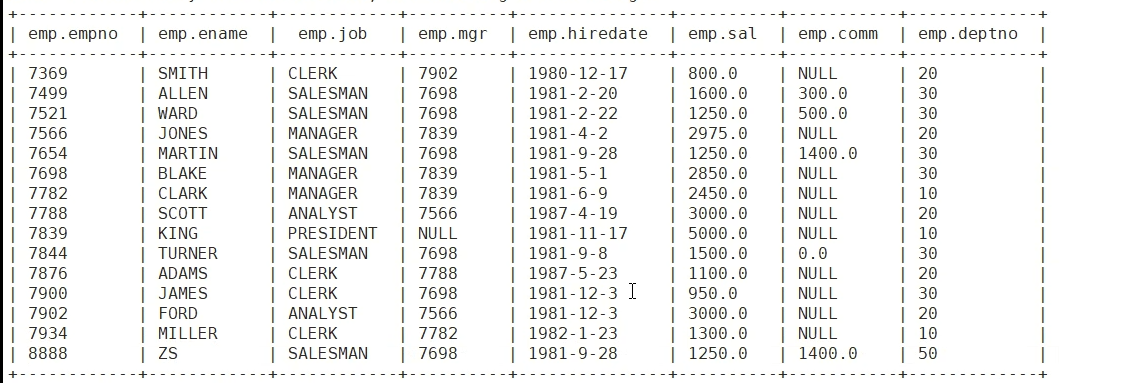
emp:7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by ' ';
load data local inpath '/opt/module/datas/emp.txt' into table emp;
2.2 比较运算符和逻辑运算符
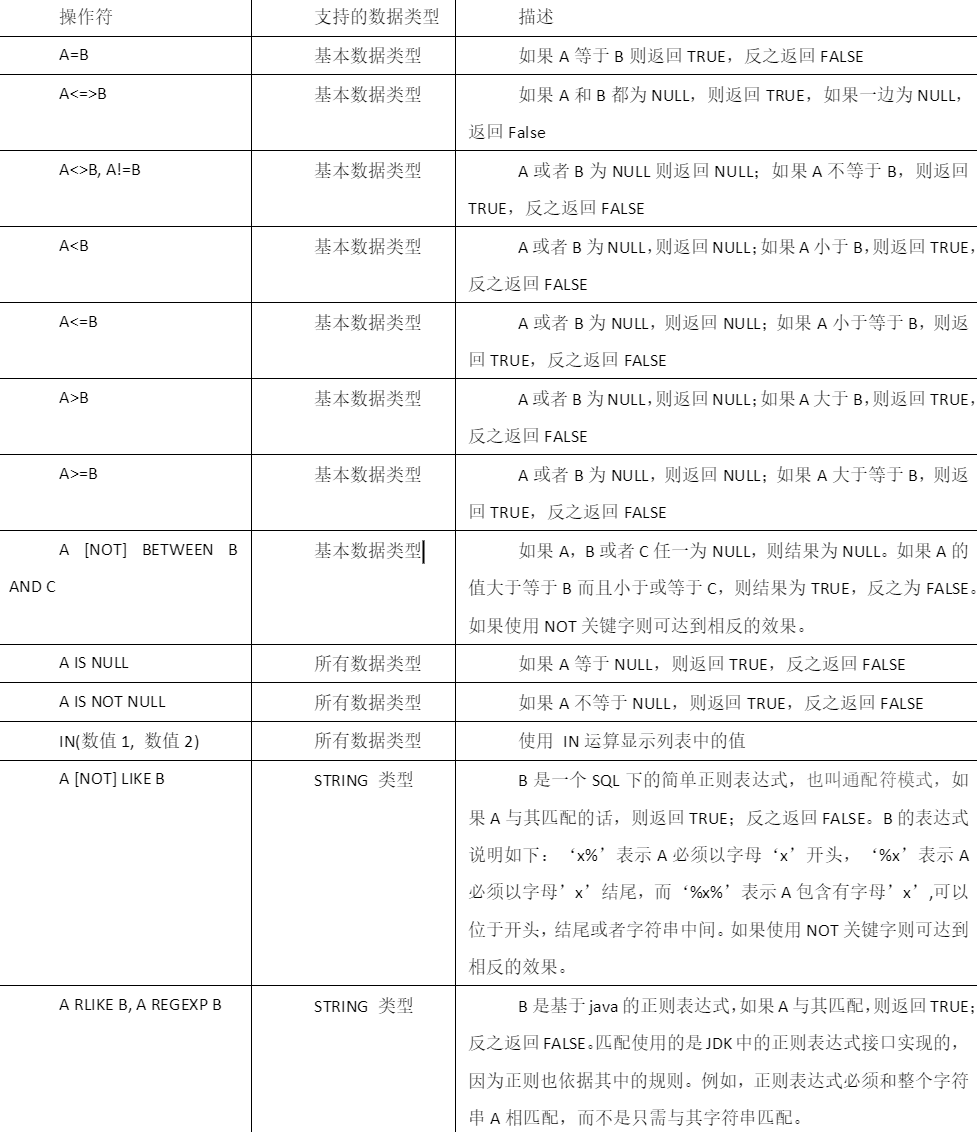
可以用于JOINON/HAVING/WHERE语句中
查询薪水大于1000 部门是30hive (default)> select * from emp where sal>1000 and deptno=30;
查询薪水大于1000 或者部门是30
hive (default)> select * from emp where sal>1000 or deptno=30;
查询除了20部门和30部门以外 的员工信息
hive (default)> select * from emp where deptno not IN(30, 20);
2.3 Like和RLike
like:%代表零个或多个字符 _代表一个字符
RLIKE子句是Hive中这个功能的一个扩展 支持正则表达式
案例:
(1)查找名字以A开头的员工信息
hive (default)> select * from emp where ename LIKE 'A%';
(2)查找名字中第二个字母为A的员工信息
hive (default)> select * from emp where ename LIKE '_A%';
(3)查找名字中带有A的员工信息
hive (default)> select * from emp where ename RLIKE 'A';
+:A出现1-n次
*:0-n次
?:0or1次
2.4 分组查询案例
GROUP BY语句通常会和聚合函数一起使用 按照一个或者多个列队结果进行分组 然后对每个组执行聚合操作
也就是分组之后 select后面只能跟组标识(分组字段) 和 聚合函数(分组函数)
计算emp表每个部门的平均工资
hive (default)>
select deptno , avg(sal) from emp group by deptno;计算emp每个部门中每个岗位的最高薪水
hive (default)>
select deptno,job,max(sal) from emp group by deptno,job;计算emp中每个部门最高薪水的那个人
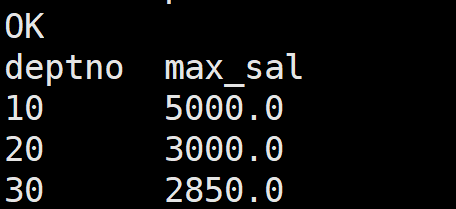
S1.先查下每个部门最高薪水是多少
select deptno , max(sal) max_sal from emp group by deptno;S2.写法一
隐式内连接 用where过滤(不再建议这么写)
select e.ename,e.sal,e.deptno from emp e , (select deptno , max(sal) max_sal from emp group by deptno) m where e.deptno=m.deptno and e.sal = m.max_sal;S2.写法二
在连接后过滤 先按deptno连接 得到各部门每个员工的工资情况 再过滤出sal=max_sal的记录
select e.ename,e.sal,e.deptno from emp e join (select deptno , max(sal) max_sal from emp group by deptno) m on e.deptno=m.deptno where e.sal = m.max_sal;S3.写法三最好
在连接时匹配 emp表的员工 只有工资等于该部门最高工资时才算连接成功
先匹配deptno 再匹配sal=max_sal 都匹配成功才产生结果
写法二三执行计划通常相同
但是e.sal = m.max_sal本质是 e表与m表之间的关联关系 不是单独对某张表的筛选 因此写成on and更可读
select e.ename,e.sal,e.deptno from emp e join (select deptno , max(sal) max_sal from emp group by deptno) m on e.deptno=m.deptno and e.sal = m.max_sal;
where后面不能写分组函数 而having后面可以使用分组函数having只用于group by分组统计语句
求每个部门的平均薪水大于2000的部门
S1.求每个部门的平均工资
select deptno, avg(sal) from emp group by deptno;S2.求每个部门的平均薪水大于2000的部门
select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;计算emp中除了CLERK岗位的员工之外 剩下的员工的所在部门的平均工资>1000的部门和平均工资
where在分组前过滤 having在分组后过滤
select deptno,avg(sal) avg_sal from emp where job != 'CLERK' group by deptno having avg_sal >1000;



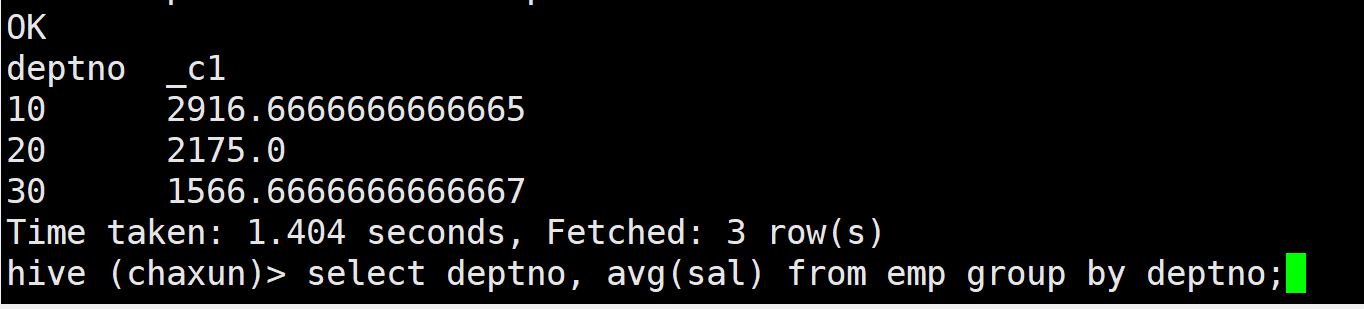


2.5 join
总结与测试数据
内连接
A inner join B on ... 内连接的结果集取交集
外连接 主表(驱动表) 和 从表(匹配表)
外连接的结果集 = 主表的所有数据 + 从表中与主表匹配的数据
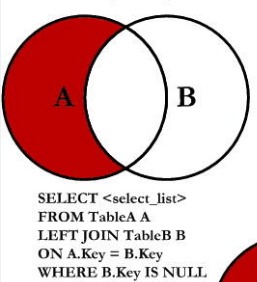
左外连接 A 主 B 从
A left outer join B on ...
B right outer Join A on...
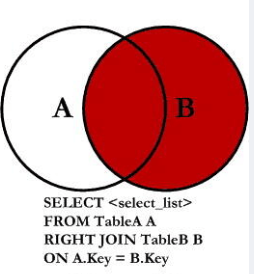
右外连接 A 从 B 主
A right outer join B on ...
B left outer join A on ...
下图是原始数据
内连接 取交集
1.emp 和 dept共有的数据(内连接)
select e.ename, d.deptno from emp e inner join dept d on e.deptno = d.deptno;
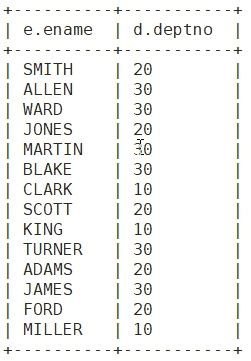
A(emp)表的所有数据
2.emp所有的数据 和 dept中与emp匹配的数据(理解成emp特有的+emp和dept的交集更合适)
下图前面部分是匹配的数据 最后的ZS是emp的 必须要有 匹配不上就给NULL
select e.ename, d.deptno from emp e left outer join dept d on e.deptno = d.deptno;
select e.ename, d.deptno from dept d right outer join emp e on e.deptno = d.deptno;
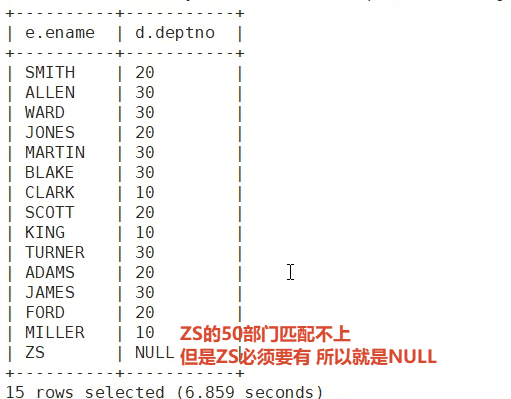
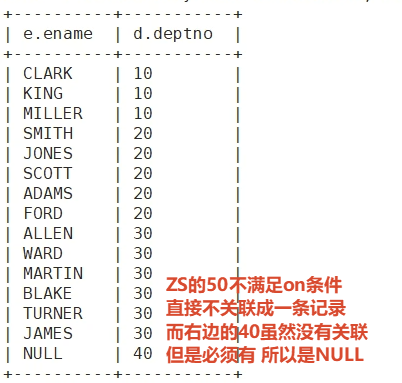
B(dept)表的所有数据
3.dept中所有的数据 和 emp中与dept匹配的数据
select e.ename, d.deptno from dept d left outer join emp e on d.deptno = e.deptno;
select e.ename, d.deptno from emp e right outer join dept d on d.deptno = e.deptno;
emp特有数据
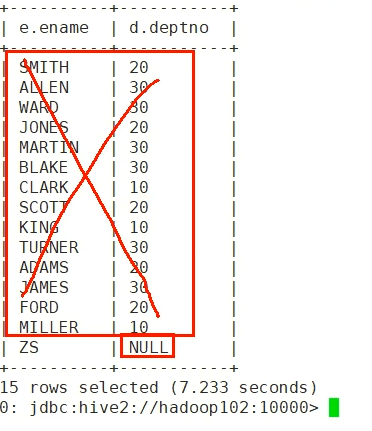
4.emp表独有的数据
先emp左连接 然后去掉交集(交集就是AB都有 通过只要B is null就能去掉交集) 剩下的就是emp所特有的
select e.ename, d.deptno from emp e left outer join dept d on e.deptno = d.deptno where d.deptno is null;
dept特有数据
5.dept表独有的数据
先dept左连接 然后去掉交集 剩下的就是dept所特有的
注意过滤的时候一定要用on的关联条件(如果用e.ename is null过滤 有可能某条关联的记录的ename 恰好是null)
select e.ename, d.deptno from dept d left outer join emp e on d.deptno = e.deptno where e.deptno is null;
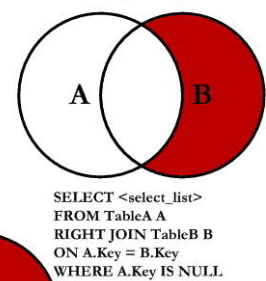

满外连接
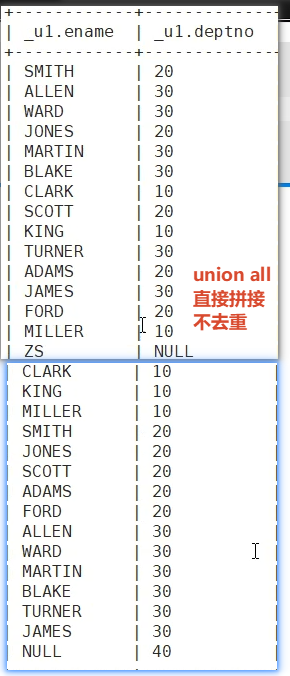
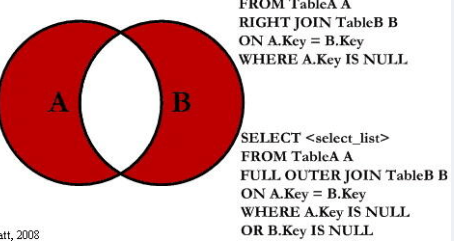
6.emp和dept 所有的数据(Hive直接支持全外连接/满外连接 但是MySQL是不支持的 需要用union)
union all将结果集拼接到一起 不去重
union 将结果集拼接到一起 去重
S1:把A的所有 和 B的所有拼接起来 union all 中间的交集的14条记录 会重复出现2次
select e.ename, d.deptno from emp e left outer join dept d on e.deptno = d.deptno
union all
select e.ename, d.deptno from dept d left outer join emp e on d.deptno = e.deptno;S2:union 去重 就完成了
select e.ename, d.deptno from emp e left outer join dept d on e.deptno = d.deptno
union
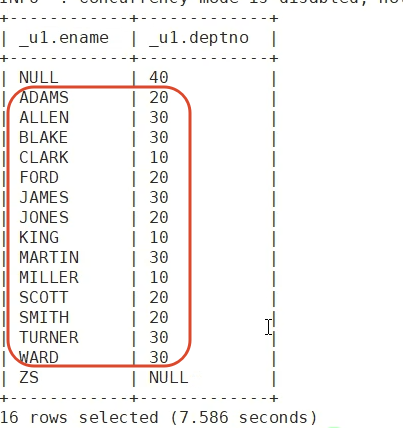
select e.ename, d.deptno from dept d left outer join emp e on d.deptno = e.deptno;S3:或者直接用Hive支持的满外连接
select e.ename, d.deptno from emp e full outer join dept d on e.deptno = d.deptno;
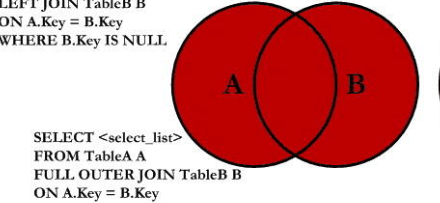
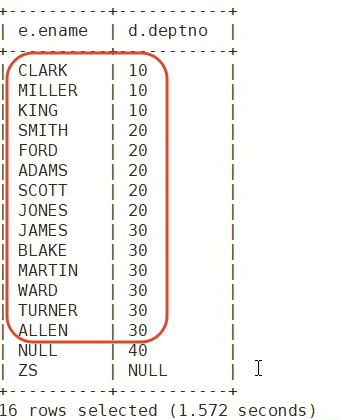
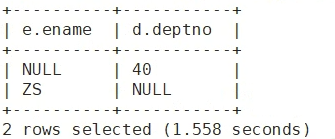
A和B特有的数据
7.emp和dept独有的数据
S1:把A独有的 和 B独有的 直接union拼起来
S2:或者 先full 再去掉中间的交集部分(用is null去掉交集 关联条件是null的 那就是特有的)
select e.ename, d.deptno from emp e full outer join dept d on e.deptno = d.deptno
where e.deptno is null or d.deptno is null;
多表join
数据准备
查询 员工名 部门名 位置名

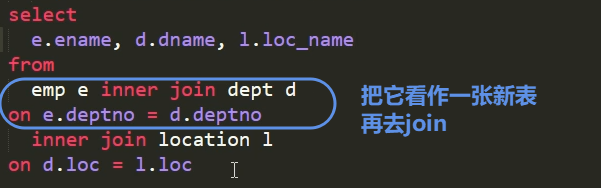
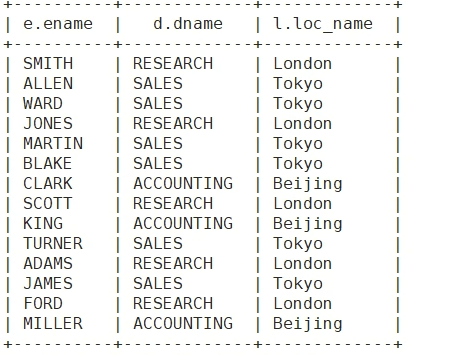
2.6 排序
全局排序oder by (只有一个分区 哪怕设置了三个分区 也只用一个)
select ename, sal*2 twosal from emp order by twosal;
select ename, deptno, sal from emp order by deptno, sal ;
区内排序Sort By 如果不先分区 结果是随机的
set mapreduce.job.reduces=3;
insert overwrite local directory '目录' select * from emp sort by deptno desc;
distribute by类似MR中partition(自定义分区) 结合sort by使用1.distribute by根据分区字段的hash码 与 reduce的个数进行模除后 余数相同的分到一个区
2.Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前
set mapreduce.job.reduces=3;
insert overwrite local directory '目录' select * from emp distribute by deptno sort by empno desc;
当distribute by和sort by字段相同时 可以使用cluster by方式但是排序只能是升序排序 不能指定排序规则为ASC或者DESC
select * from emp cluster by deptno;等价于
select * from emp distribute by deptno sort by deptno;

三、分区表和分桶表
3.1 分区表/分桶表大致概念
1.分区表:分的是目录(细分表目录) 分区其实就是在HDFS上分目录
2.分桶表:分的是一整个数据文件(一整个数据文件 → 拆分成几个文件 也就是几个桶)


3.2 分区表基本操作
创建分区表
注意 分区字段不能 是表中已经存在的数据 可以将分区字段看作表的伪列
create table dept_partition(deptno int, dname string, loc string)
partitioned by (day string)
row format delimited fields terminated by ' ';
数据准备
加载数据到分区表中
load data local inpath '/home/tmp/logs/dept_20200401.log' into table dept_partition partition(day='20200401');
load data local inpath '/home/tmp/logs/dept_20200402.log' into table dept_partition partition(day='20200402');
load data local inpath '/home/tmp/logs/dept_20200403.log' into table dept_partition partition(day='20200403');
多分区联合查询
select * from dept_partition where day='20200401'
union
select * from dept_partition where day='20200402'
union
select * from dept_partition where day='20200403';or
select * from dept_partition where day='20200401' or day='20200402' or day='20200403' ;
查看分区表有多少分区
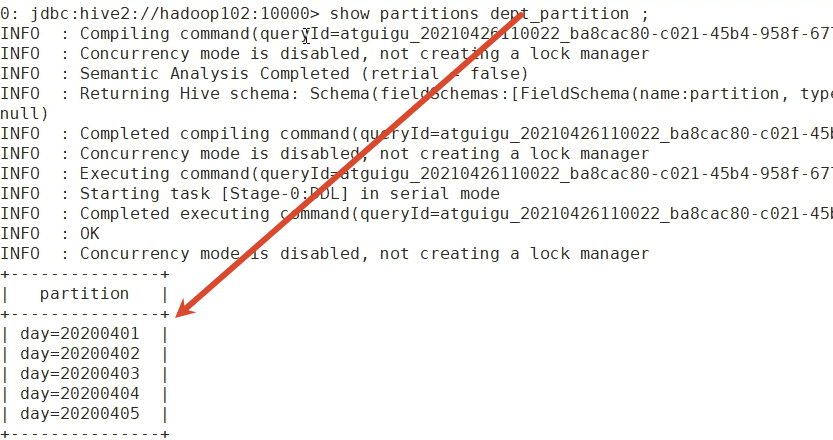
show partitions dept_partition;
加分区 HDFS对应会新增几个目录
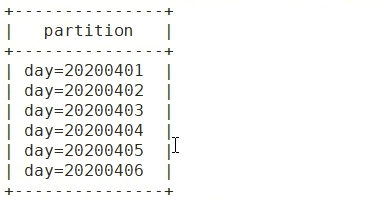
alter table dept_partition add partition(day='20200404');
alter table dept_partition add partition(day='20200405') partition(day='20200406') ;删分区 如果是一个内部分区表 HDFS的数据都会被删 否则HDFS的数据不会被删
alter table dept_partition drop partition(day='20200404');
alter table dept_partition drop partition(day='20200405') , partition(day='20200406');

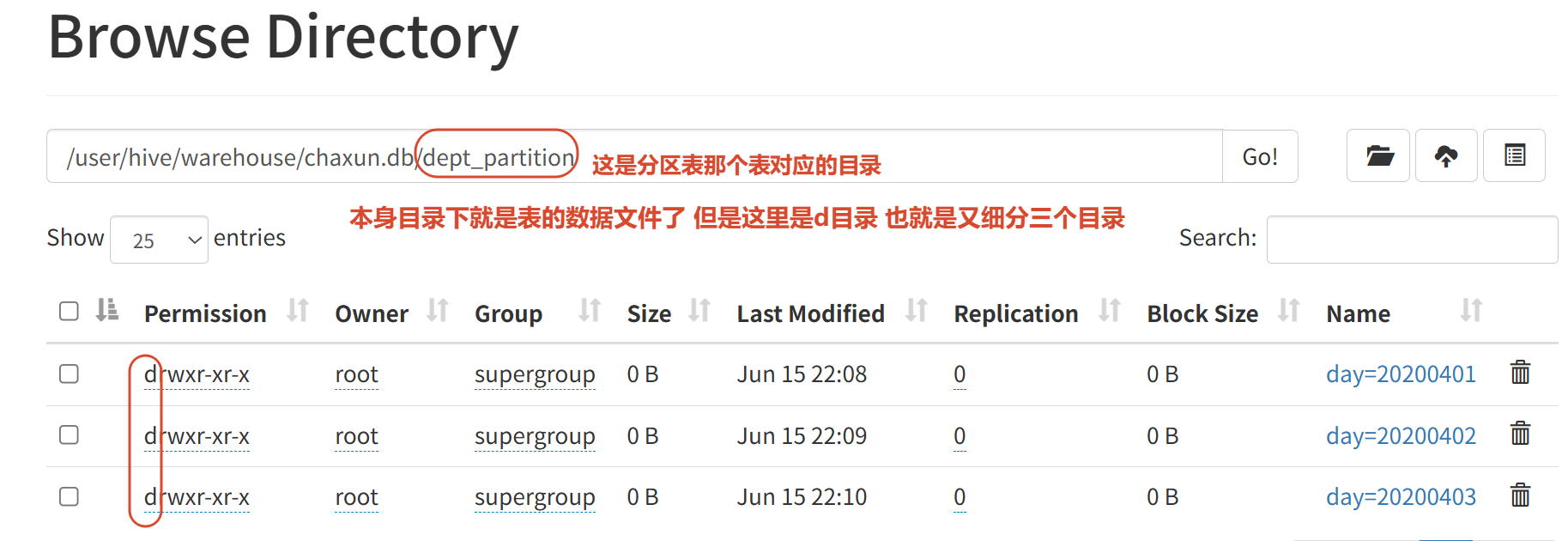
3.3 二级(多级)分区
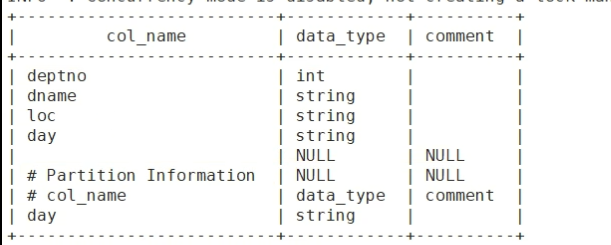
create table dept_partition2(deptno int, dname string, loc string)
partitioned by (day string ,hour string )
row format delimited fields terminated by '\t' ;show partitions dept_partition2;
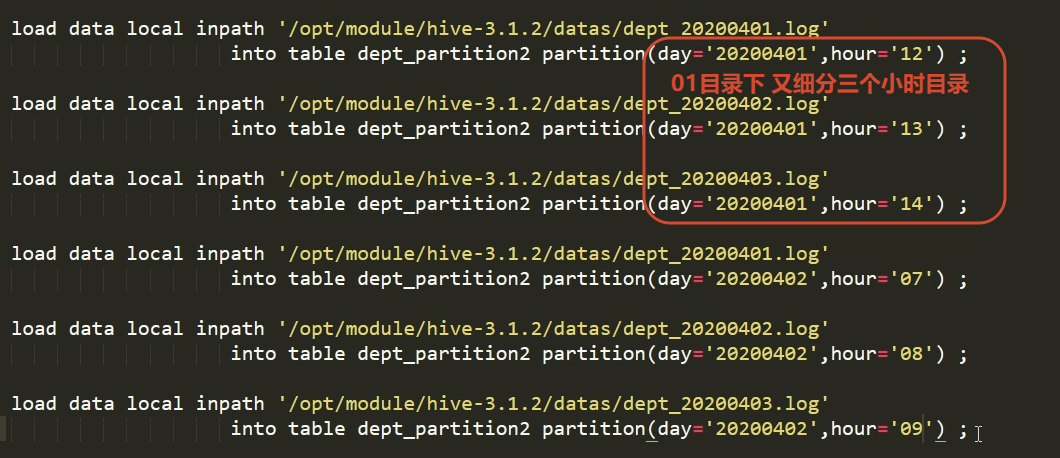
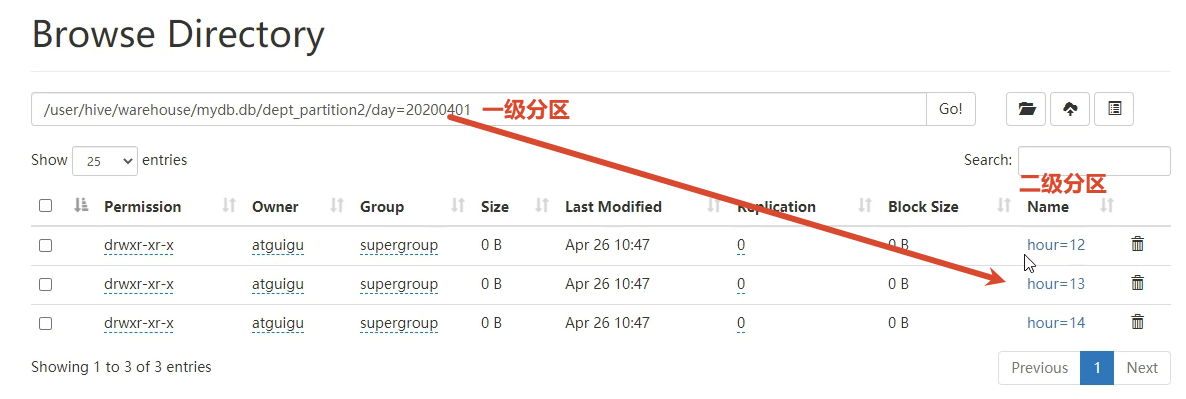
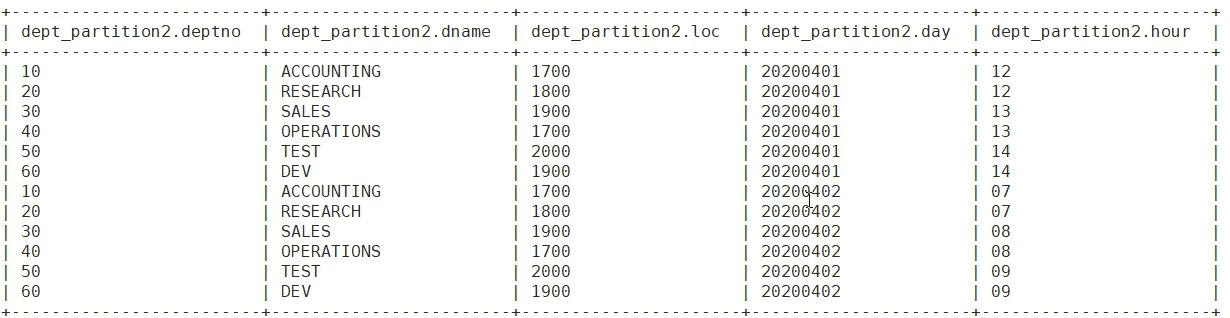
3.4 先有数据 和分区表如何关联
手动创建分区目录 手动上传数据到分区目录 再手动修复
按照下图的已知分区规则 去创建对应的目录
hadoop fs -mkdir /user/hive/warehouse/mydb.db/dept_partition/day=20200404
hadoop fs -put /opt/module/hive-3.1.2/datas/dept_20200403.log /user/hive/warehouse/mydb.db/dept_partition/day=20200404手动修复分区
msck repair table dept_partition;
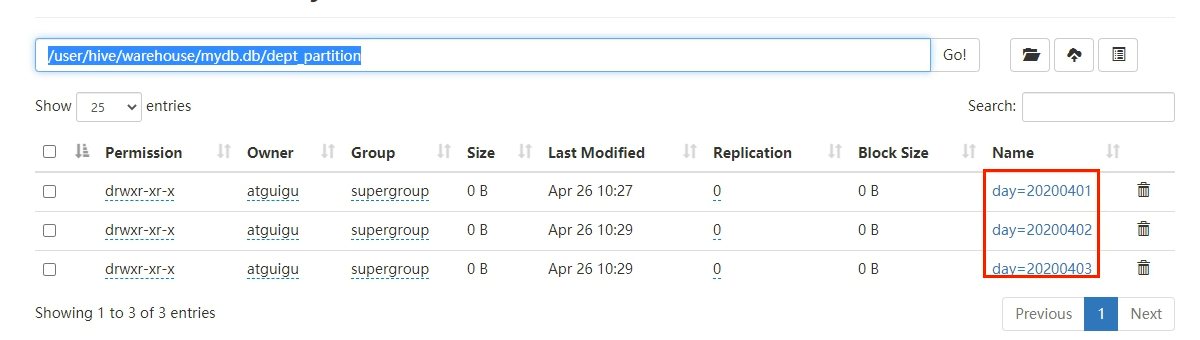
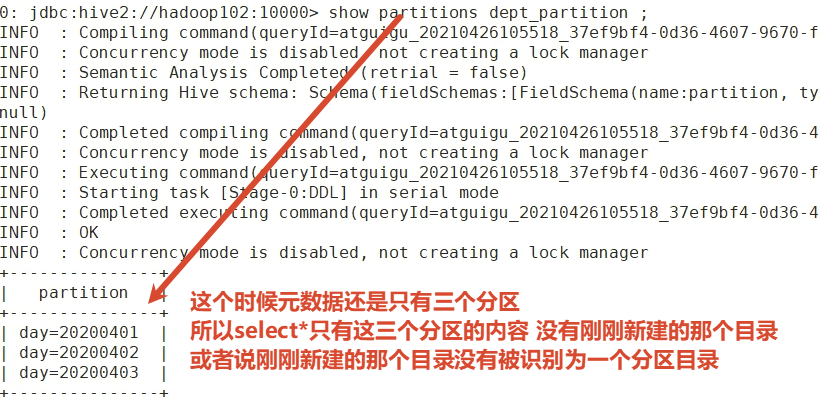
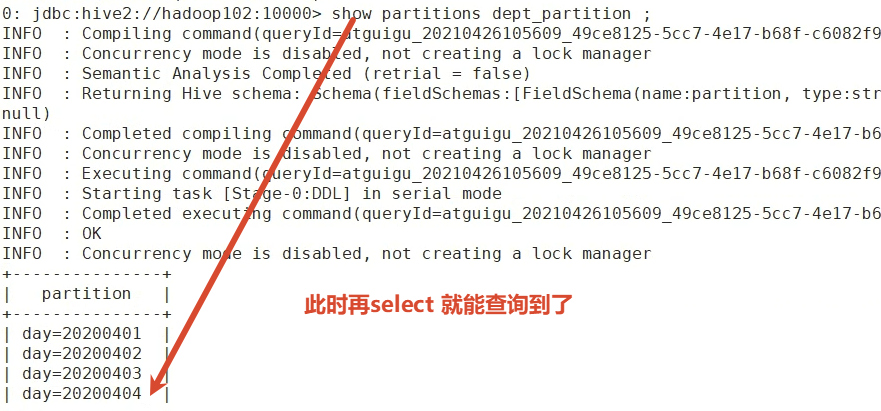
手动创建分区目录 手动上传数据到分区目录 然后添加一个分区和它对应
创建目录 上传文件
hadoop fs -mkdir /user/hive/warehouse/mydb.db/dept_partition/day=20200405
hadoop fs -put /opt/module/hive-3.1.2/datas/dept_20200403.log /user/hive/warehouse/mydb.db/dept_partition/day=20200405添加一个对应的分区(主要是要让元数据认识这个分区 就能select到)
alter table dept_partition add partition(day='20200405');
show partitions dept_partition;
手动创建分区目录 load数据到分区中
创建目录 即使和分区目录的规则一模一样 show partitions看元数据的时候 也是没有识别到这个分区的
hadoop fs -mkdir /user/hive/warehouse/mydb.db/dept_partition/day=20200406load 就可以加载元数据 就能查到元数据 也能select到了
load data local inpath '/opt/module/hive-3.1.2/datas/dept_20200403.log' into table dept_partition partition(day='20200406')
3.5 动态分区
开启动态分区参数设置
关系型数据库中 对分区表Insert数据时候 数据库自动会根据分区字段的值 将数据插入到相应的分区中
Hive中也提供了类似的机制 即动态分区
1.开启动态分区参数设置
hive.exec.dynamic.partition=true2.动态分区的模式默认strict 必须指定至少一个分区为静态分区
hive.exec.dynamic.partition.mode=nonstrict3.在所有执行MR的节点上 最大一共可以创建多少个动态分区
hive.exec.max.dynamic.partitions=10004.在每个执行MR的节点上 最大可以创建多少个动态分区
比如:源数据中包含了一年的数据 即day字段有365个值 那么该参数就需要设置成大于365
hive.exec.max.dynamic.partitions.pernode=1005.整个MR Job中 最大可以创建多少个HDFS文件
hive.exec.max.created.files=1000006.当有空分区生成时 是否抛出异常 一般不需要设置 默认false
hive.error.on.empty.partition=false
load数据到动态分区
其实就是根据分区字段来匹配 判断到哪个分区
匹配上了 就插入该分区 否则就新建一个分区 再插入
create table dept_partition_dy(deptno int, dname string, loc string)
partitioned by (day string)
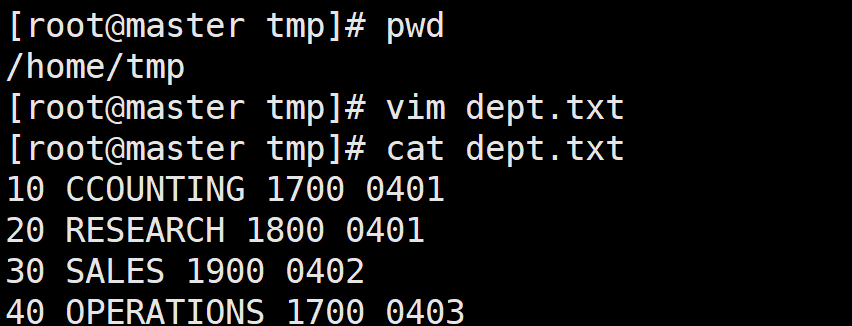
row format delimited fields terminated by ' ';下图是数据样本
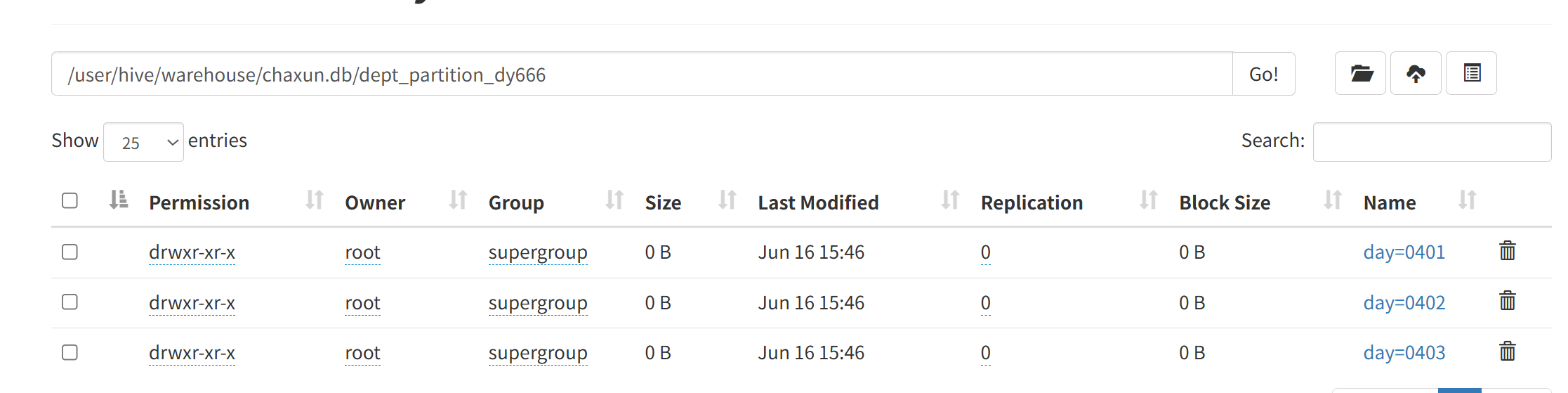
1.load本地数据到动态分区表 这里的load 会根据分区字段计算到哪个分区 所以会跑一个MR
分区字段是伪列 不写入HDFS数据文件 只存在于HDFS目录名 + Hive元数据中
load data local inpath '/home/tmp/dept.txt' into table dept_partition_dy666;2.也可以直接把DHFS上的数据load到动态分区
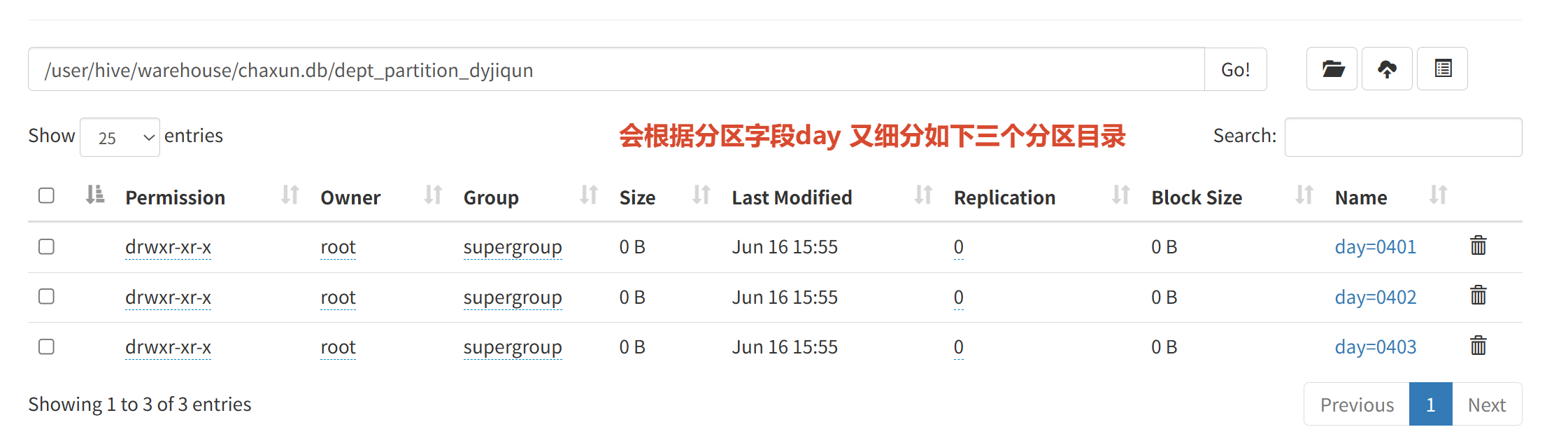
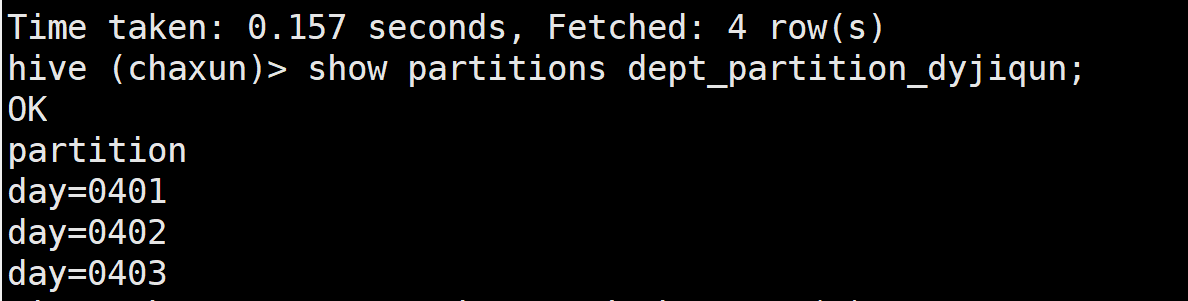
hdfs dfs -put ./dept.txt /
load data inpath '/dept.txt' into table dept_partition_dyjiqun;
insert数据到动态分区
现在的load功能更强了 会根据不同的表判断是直接上传数据 还是要跑一个MR
老版本的load 功能非常单一 单纯就是上传数据 不会跑MR去动态分区 如何解决?
创建一个含有分区字段的中间表(普通表) → 把数据load到普通表 → 把普通表的数据insert到分区表 跑MR 数据去对应分区
创建普通表 但是包含了day这个字段(也就是分区字段 但这里仅作为一个普普通通的字段 )
create table dept_dy(deptno int, dname string, loc string,day string) row format delimited fields terminated by '\t';load数据到普通表
load data local inpath 'XXX.txt' into table dept_dy ;创建一个干净的分区表 把普通表的数据insert进来
dept_partition_dy 分区表 建表时指定了分区字段
dept_dy 普通无分区表 表内包含分区字段
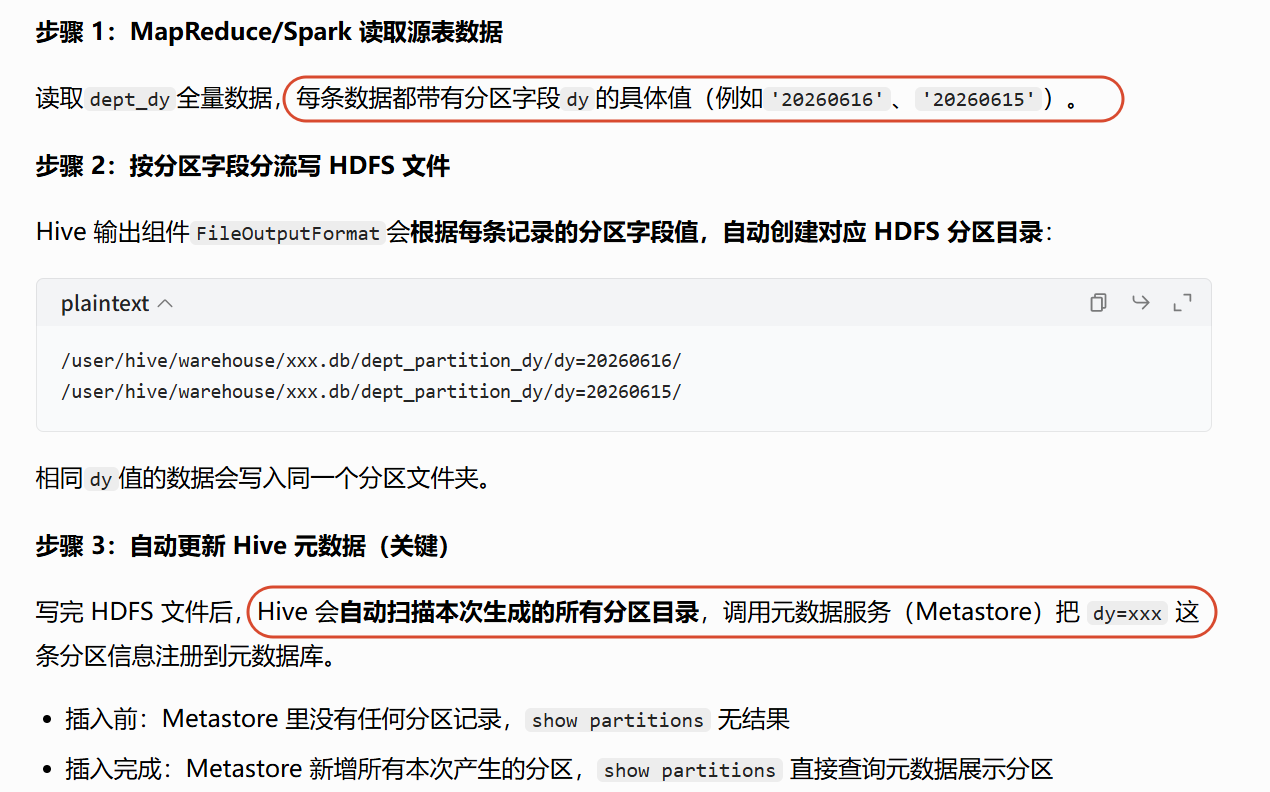
insert into 分区表 select * from 普通表 执行时 Hive会自动根据分区字段的值创建对应的分区目录、写入分区元数据
所以插入前空分区 插入后show partitions就能看到分区

3.6 分桶表
数据准备
分桶的字段必须是表中的某个字段 而不能单独再去指定
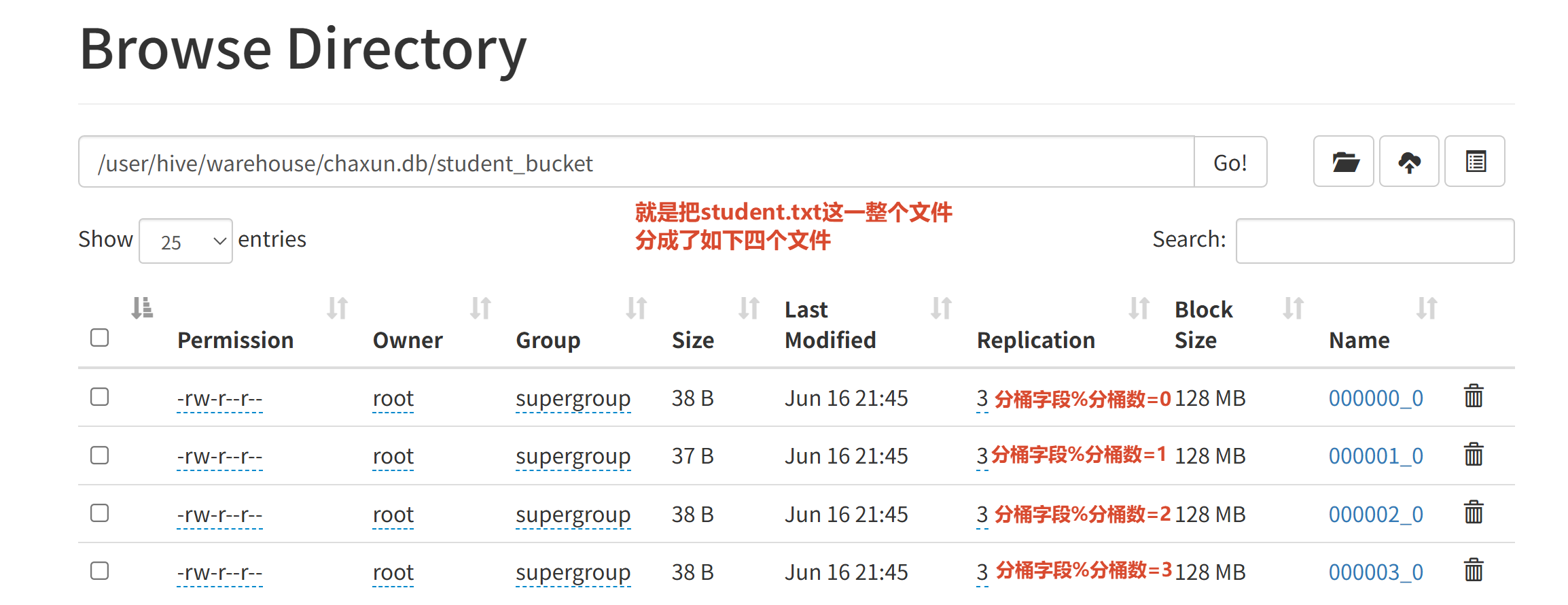
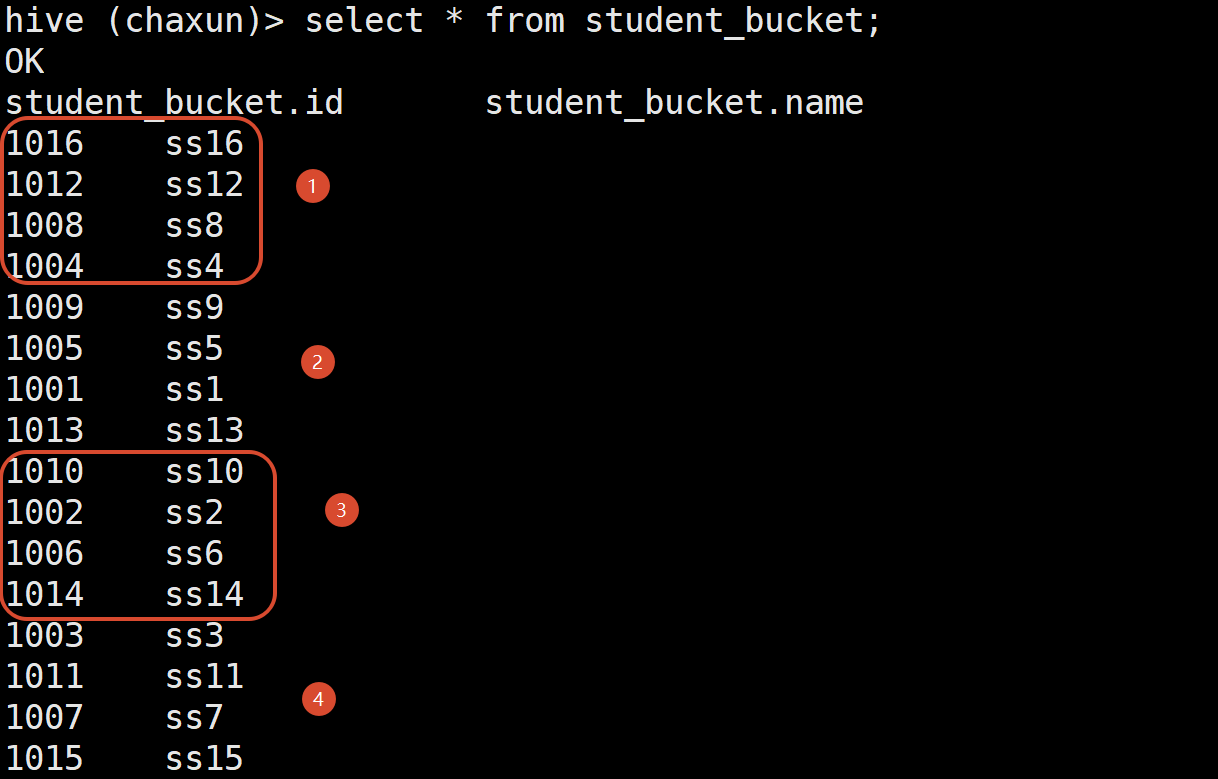
create table student_bucket(id int, name string )
clustered by (id)
into 4 buckets
row format delimited fields terminated by ' ' ;
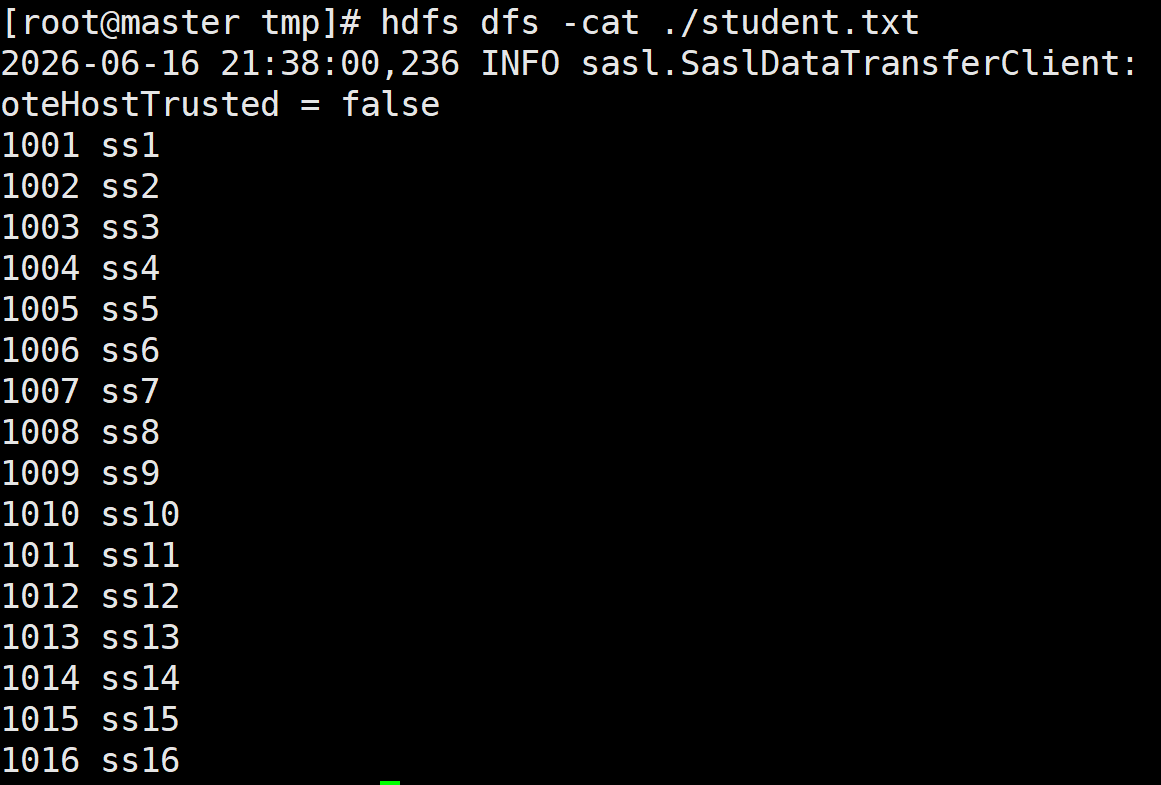
load data inpath '/student.txt' into table student_bucket;
3.7 抽样查询
对于非常大的数据集 有时用户需要使用的是一个具有代表性的查询结果 而不是全部结果
Hive可以通过对表进行抽样来满足这个需求 TABLESAMPLE(BUCKET x OUT OF y)
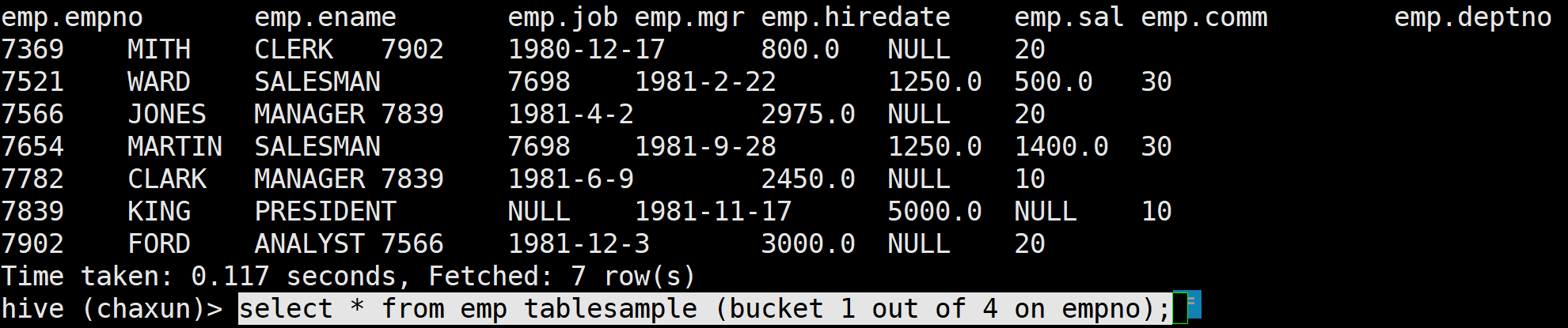
按照empno分成四个桶 抽样其中的一个(这样抽出来的数据就是原数据里到处抽一点的感觉 很均匀 不失真)
select * from emp tablesample (bucket 1 out of 4 on empno);=x的值必须小于等于y的值 否则
FAILED: SemanticException Error 10061: Numerator should not be bigger than denominator in sample clause for table stu_buck
四、函数
4.1 系统内置函数
查看系统自带的函数
show functions;显示自带的函数的用法
desc function upper;详细显示自带的函数的用法
desc function extended upper;
4.2 常用函数
常用日期函数
-
unix_timestamp:返回当前或指定时间的时间戳
select unix_timestamp();select unix_timestamp("2020-10-28",'yyyy-MM-dd'); -
from_unixtime:将时间戳转为日期格式
select from_unixtime(1603843200); -
current_date:当前日期
select current_date; -
current_timestamp:当前的日期加时间
select current_timestamp; -
to_date:抽取日期部分(2020-10-28)
select to_date('2020-10-28 12:12:12'); -
year:获取年
select year('2020-10-28 12:12:12'); -
month:获取月
select month('2020-10-28 12:12:12'); -
day:获取日
select day('2020-10-28 12:12:12'); -
hour:获取时
select hour('2020-10-28 12:13:14'); -
minute:获取分
select minute('2020-10-28 12:13:14'); -
second:获取秒
select second('2020-10-28 12:13:14'); -
weekofyear:当前时间是一年中的第几周
select weekofyear('2020-10-28 12:12:12'); -
dayofmonth:当前时间是一个月中的第几天
select dayofmonth('2020-10-28 12:12:12'); -
months_between: 两个日期间的月份
select months_between('2020-04-01','2020-10-28'); -
add_months:日期加减月
select add_months('2020-10-28',-3); -
datediff:两个日期相差的天数
select datediff('2020-11-04','2020-10-28'); -
date_add:日期加天数
select date_add('2020-10-28',4); -
date_sub:日期减天数
select date_sub('2020-10-28',4); -
last_day:日期的当月的最后一天
select last_day('2020-02-30'); -
date_format(): 格式化日期
select date_format('2020-10-28 12:12:12','yyyy/MM/dd HH:mm:ss');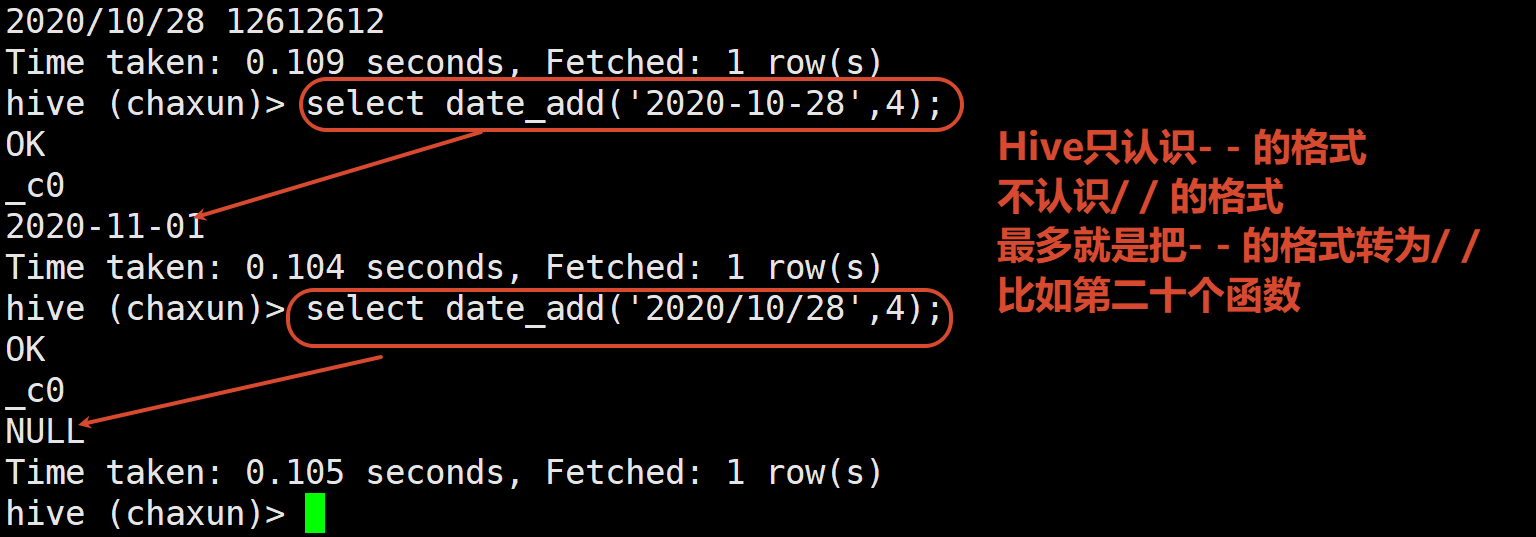
常用取整函数
-
round: 四舍五入
select round(3.14);select round(3.54); -
ceil: 向上取整
select ceil(3.14);select ceil(3.54); -
floor: 向下取整
select floor(3.14);select floor(3.54);
常用字符串操作函数
-
upper: 转大写
select upper('low'); -
lower: 转小写
select lower('low'); -
length: 长度
select length("zcy"); -
trim: 前后去空格
select trim(" zcy "); -
lpad: 向左补齐,到指定长度
select lpad('zcy',9,'g'); -
rpad: 向右补齐,到指定长度
select rpad('zcy',9,'g'); -
regexp_replace:使用正则表达式匹配目标字符串 匹配成功后替换
SELECT regexp_replace('2020/10/25', '/', '-');
集合操作

-
size: 集合中元素的个数
select size(friends) from test3; -
map_keys: 返回map中的key
select map_keys(children) from test3; -
map_values: 返回map中的value
select map_values(children) from test3; -
array_contains: 判断array中是否包含某个元素
select array_contains(friends,'bingbing') from test3; -
sort_array: 将array中的元素排序
select sort_array(friends) from test3;
多维分析
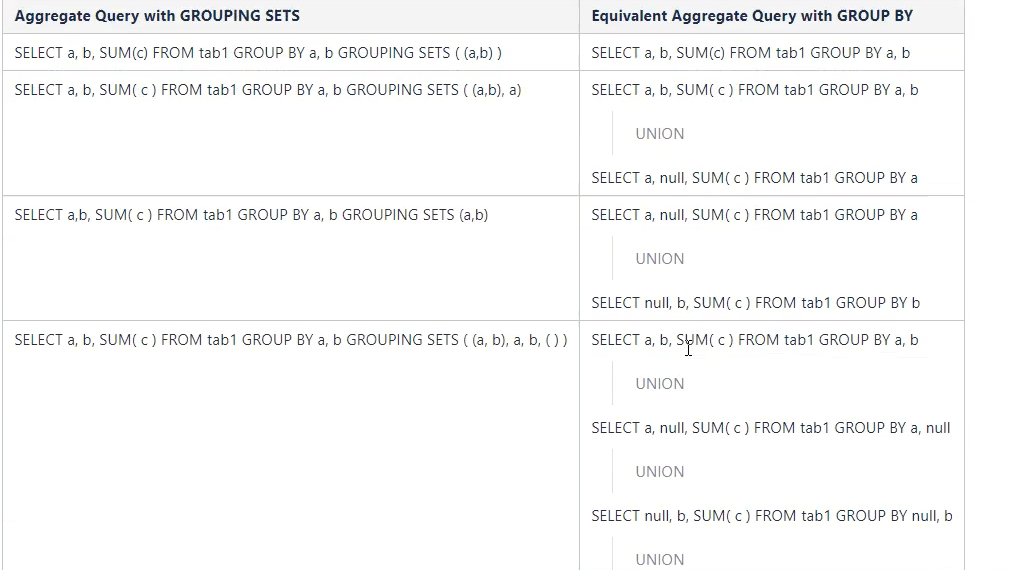
grouping sets:多维分析
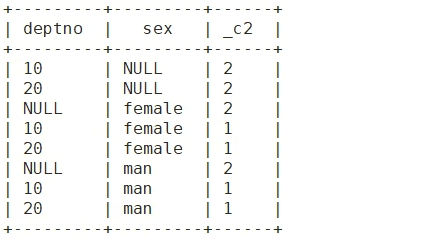
需求: 统计每个部门各多少人, 男女各多少人, 每个部门中男女各多少人
select deptno, sex ,count(id) num from testgrouping group by deptno,sex
grouping sets( (deptno,sex), sex , deptno )

4.3 空字段赋值
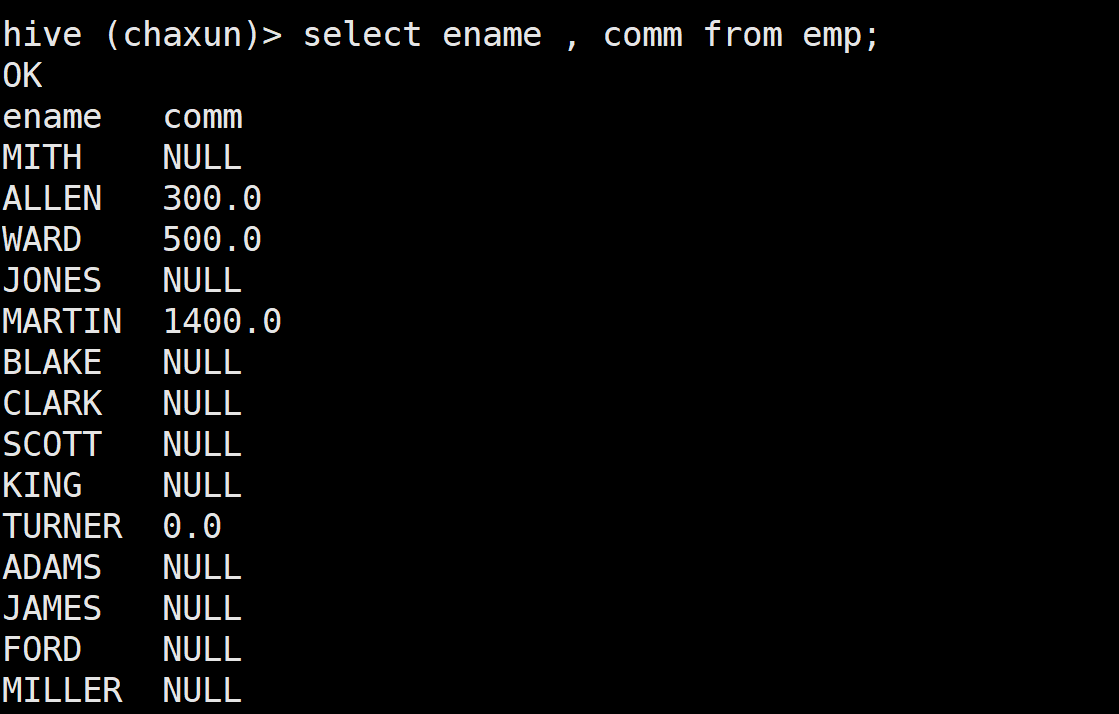
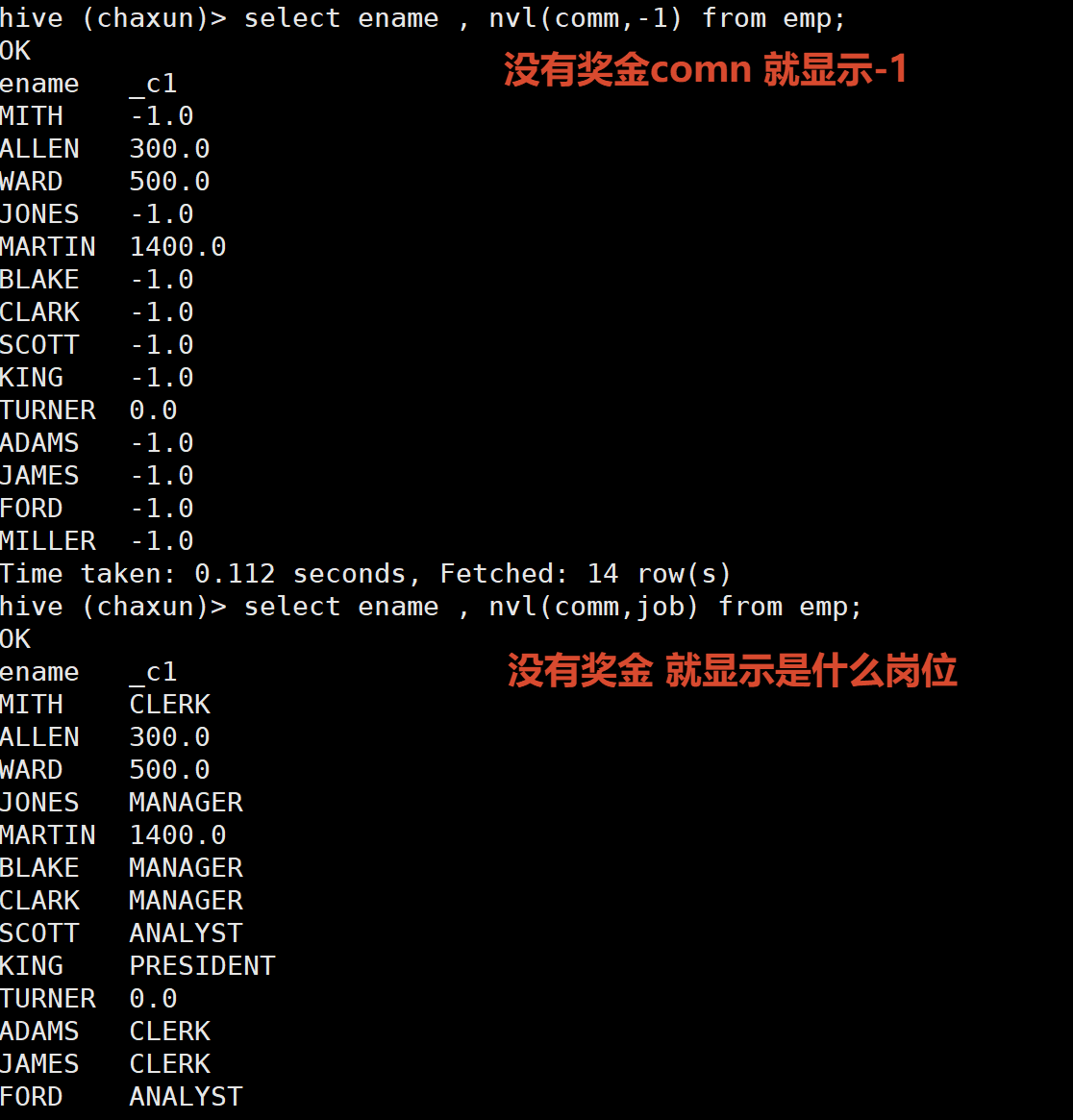
NVL
给值为NULL的数据赋值 它的格式是NVL( value,default_value)
如果value为NULL 则NVL函数返回default_value的值 否则返回value的值
如果两个参数都为NULL 则返回NULL
4.4 CASE和IF
数据
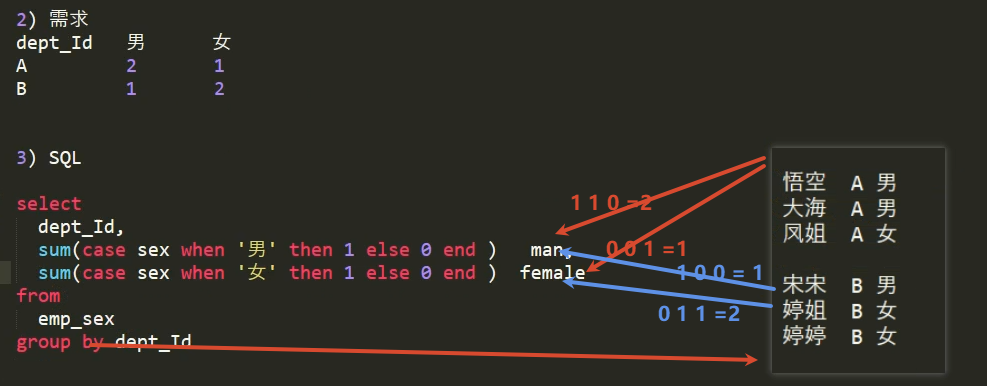
需求 求出不同部门男女各多少人
先按照部门分组是确定的分组之后 再按照需求 在每个组内用sum
根据当前值 给一个对应的结果
select
dept_Id,
sum(case sex when '男' then 1 else 0 end ) man,
sum(case sex when '女' then 1 else 0 end ) female
from emp_sex
group by dept_Id ;
只有两个分之 可以直接用if
select
dept_Id,
sum(if(sex='男',1,0)) man,
sum(if(sex='女',1,0)) female
from emp_sex
group by dept_Id;


4.5 行转列
相关函数
concat(): 字符串拼接
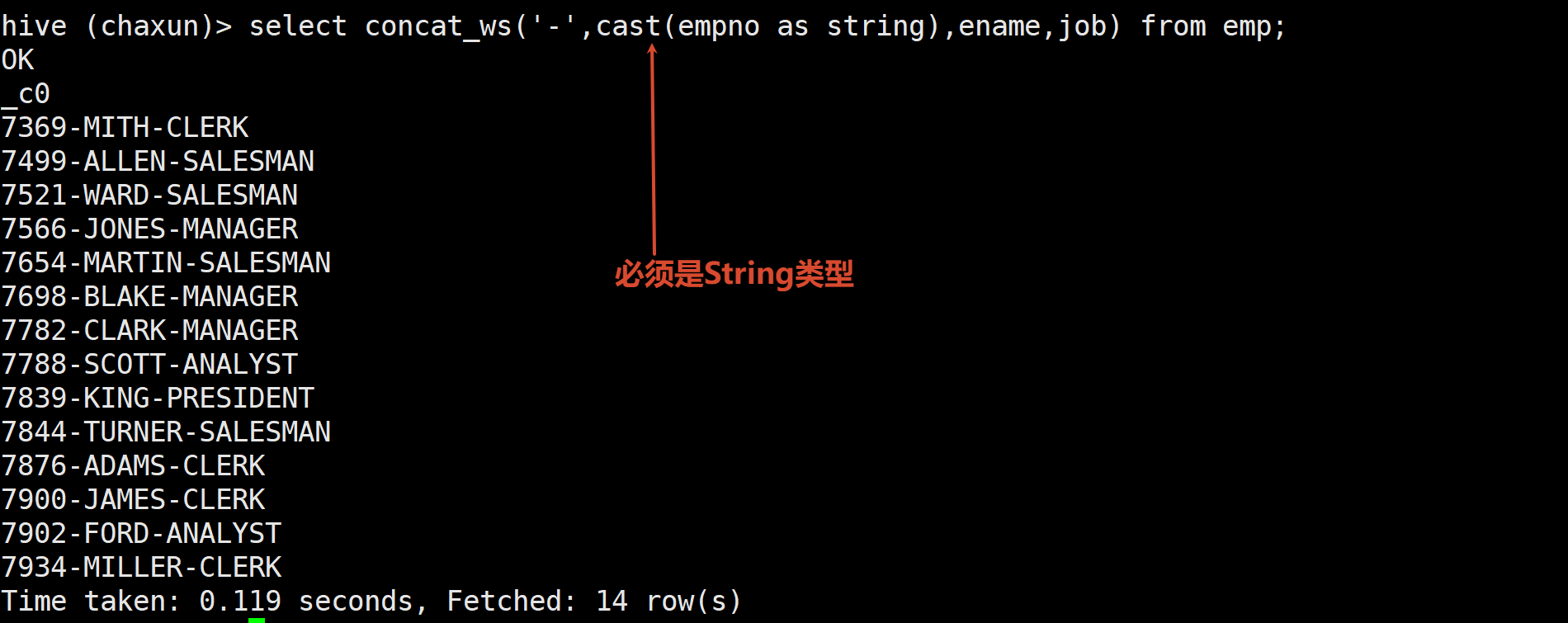
concat_ws(): 字符串拼接 但必须是String类型的字段或者数组
collect_set(): 去重汇总某一列
collect_list(): 汇总 但是不会去重
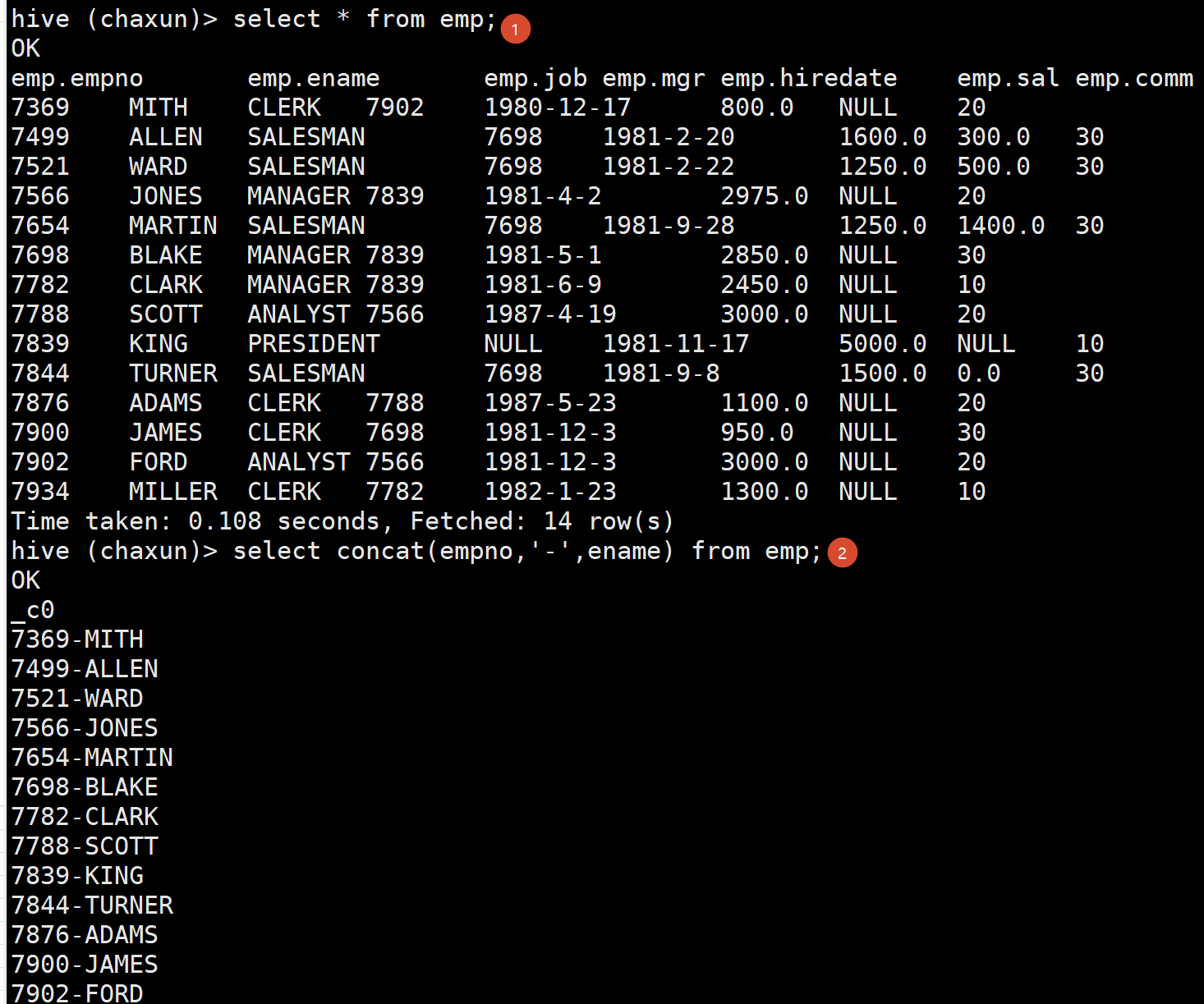

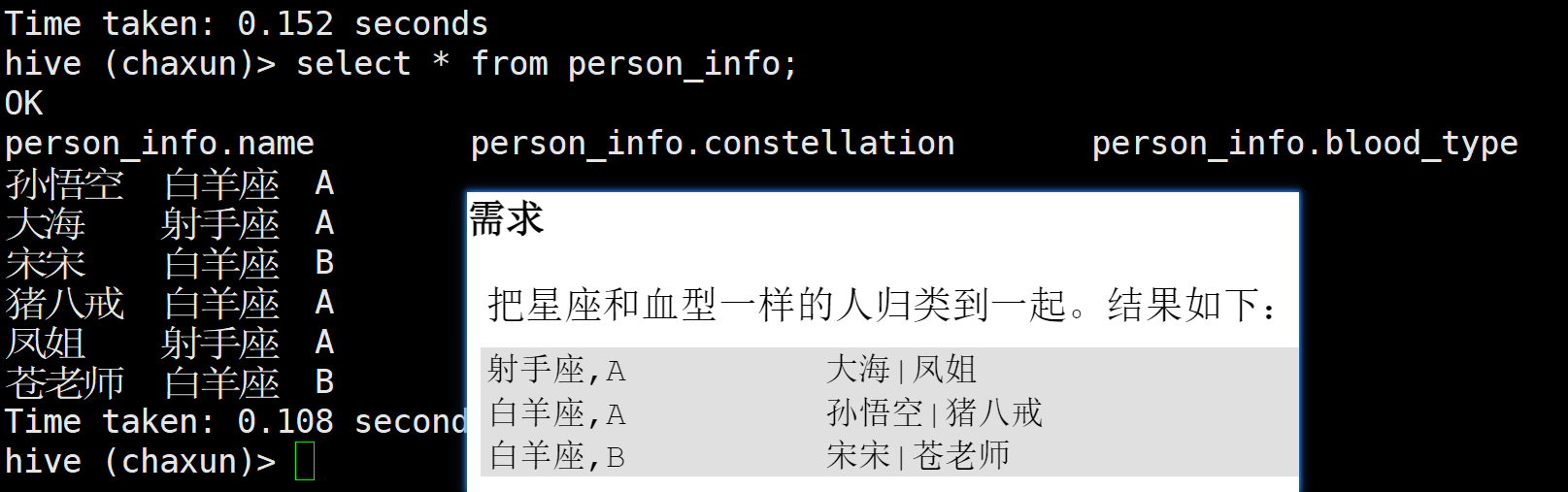
行转列案例
看到这个需求 首先想到的就是先把星座和血型拼在一起
select name,concat_ws(',',constellation,blood_type) c_b from person_info;然后自然会想到要把c_b作为一个分组字段 先分好组 这个时候上面那个就要作为一个临时表了(子查询)
对于同一个c_b组的(也就是同一个星座,血型的) 再把他们的名字汇总起来即可 → 对名字collect_set
select tmp.c_b , collect_set(tmp.name) as names
from
(select name,concat_ws(',', constellation,blood_type) c_b from person_info) as tmp
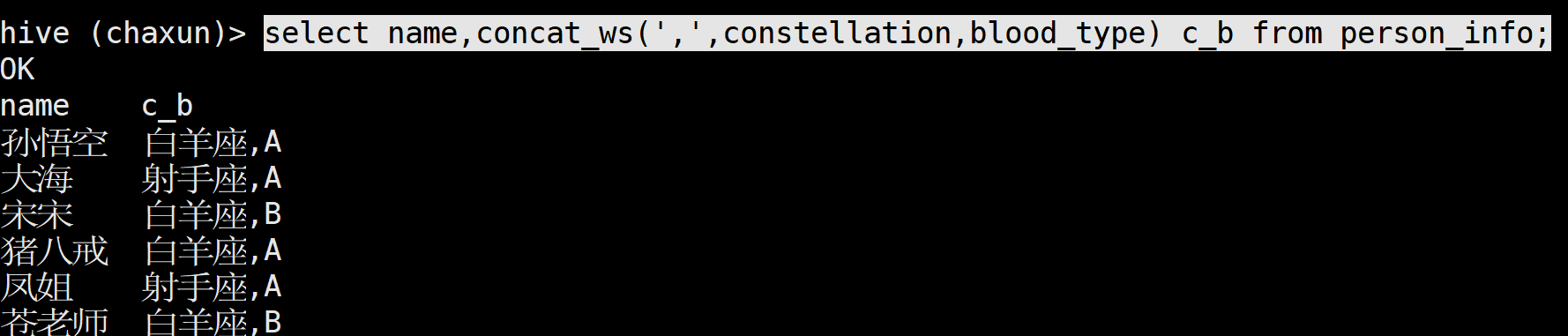
group by tmp.c_b;进一步地 需求想要的分隔符是|
也就是把name汇总成一行的时候 间隔符要用| → 想到用concat_ws('|',汇总的name行)
select tmp.c_b , concat_ws('|' , collect_set(tmp.name) )as names
from
(select name,concat_ws(',', constellation,blood_type) c_b from person_info) as tmp
group by tmp.c_b;


4.6 列转行
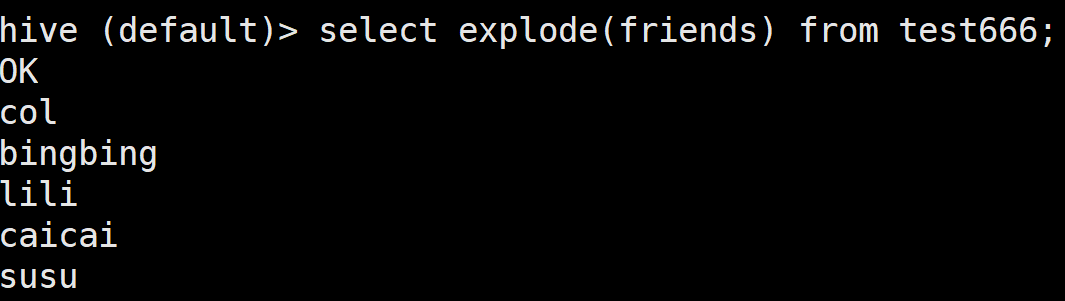
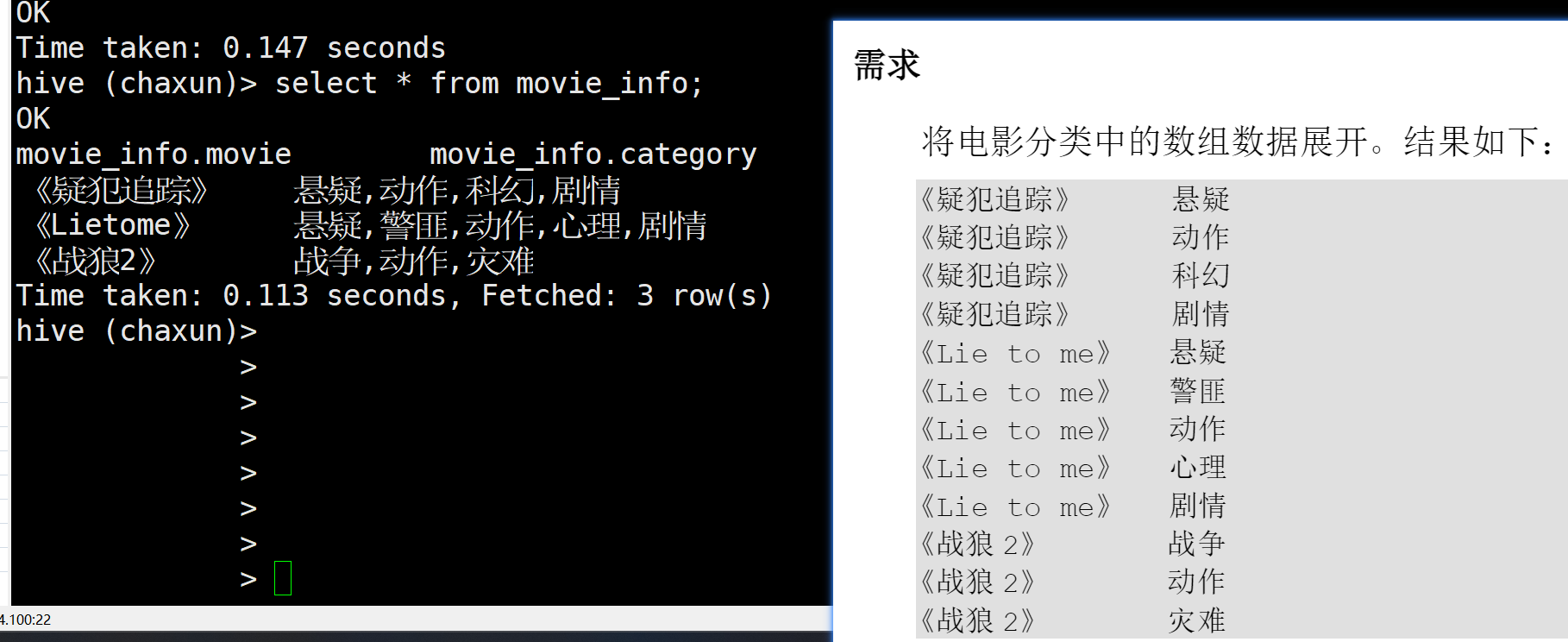
explode() 将数组或者map 拆分成多行
lateral view 侧写表(虚拟表) 它能记录拆分前的对应关系
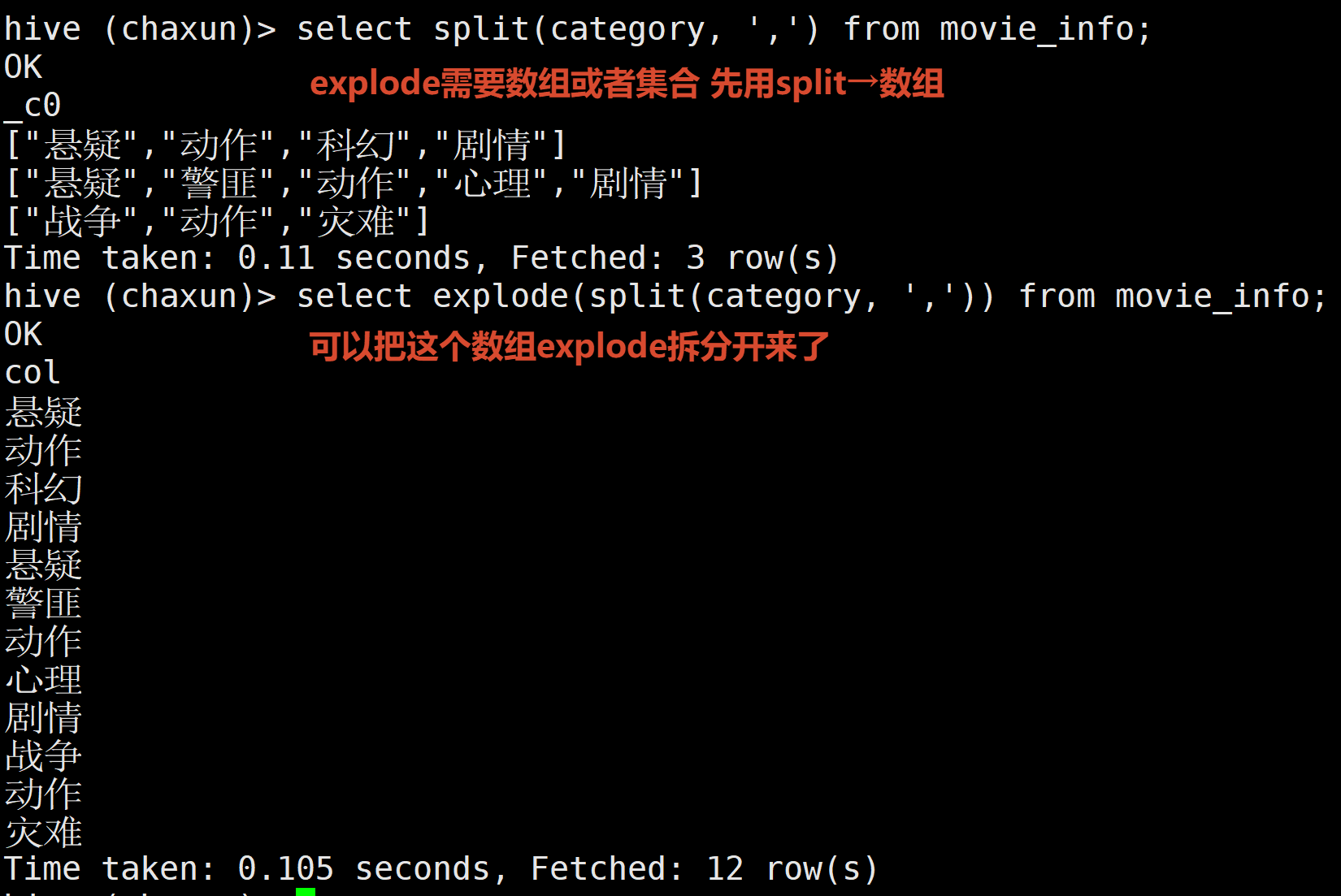
这个需求 首先是能想到先把category这一列拆开的 但是explode只支持数组 集合 → 先用split
select explode(split(category, ',')) from movie_info;如果直接查询movie 可能出现 一行记录 就要有一个电影对多个拆分的category的情况 错误
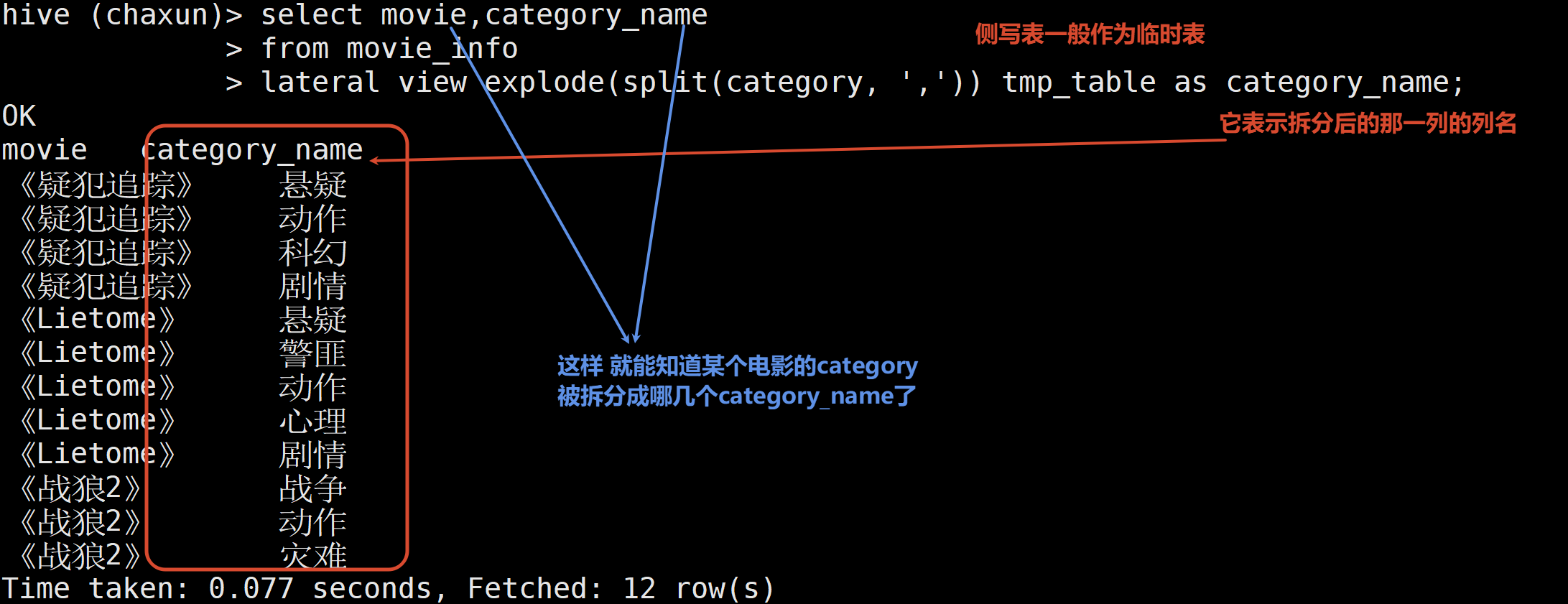
需要让侧写表记住 某个电影对应的category 被拆分成了哪几个
select movie,category_name
from movie_info
lateral view explode(split(category, ',')) tmp_table as category_name;

4.7 窗口函数/开窗函数
0.原始数据和相关函数
load data local inpath '/home/tmp/business.txt' into table business;
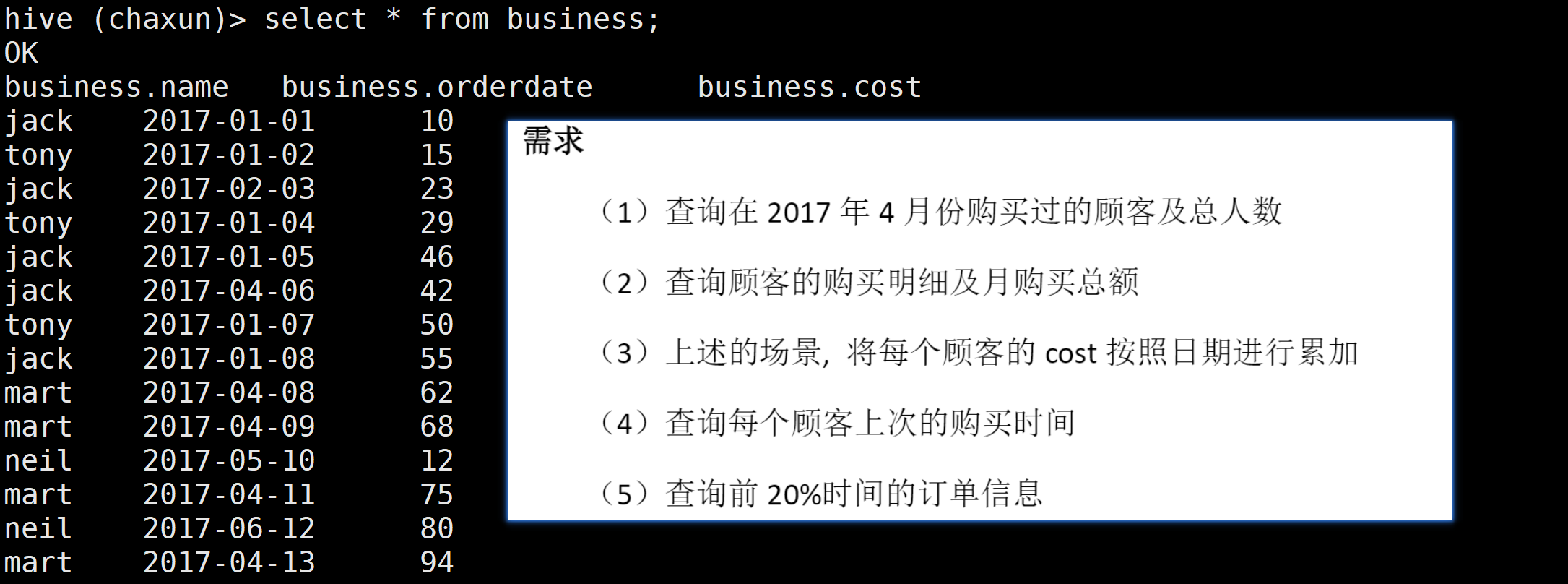

1.查询在2017年4月份购买过的顾客及总人数
① 查出2017年4月份购买过的顾客
select name, orderdate, cost from business where month(orderdate) = '4'or
select name, orderdate, cost from business where substring(orderdate,0,7) = '2017-04'② 按照name分组,求count 还是不对 这是对每个组内的聚合
select t1.name,count(t1.name)
from (select name, orderdate, cost from business where month(orderdate) = '4') t1
group by t1.name;第一种方式:继续顺着一开始的思路往下写
select t1.name, count(t1.name) over()
from
(select name, orderdate, cost from business where substring(orderdate,0,7) = '2017-04') t1
group by t1.name;第二种方式:分析函数count 不一定非要作用在组内 可以作用于窗口
select distinct(t1.name)
from (select name, orderdate, cost from business where substring(orderdate,0,7) = '2017-04') t1开窗之前 得到的就是上图这个数据集结果
则每条数据的默认窗口大小 就是当前数据集的大小
所以每个数据基于开窗函数求count的时候 就都的到2
select t2.name, count(t2.name) over() from
(
select distinct(t1.name) from
(select name, orderdate, cost from business where substring(orderdate,0,7) = '2017-04') t1
) t2

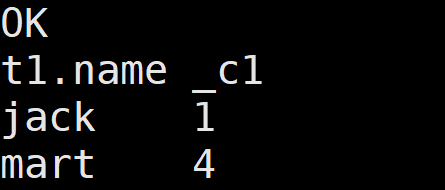

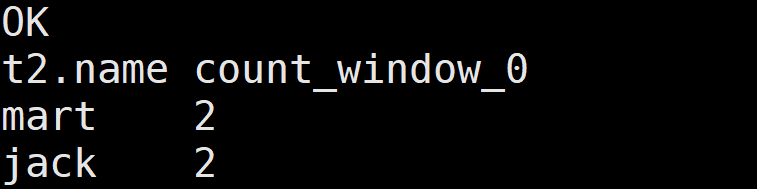
2.查询顾客的购买明细 及 所有顾客的月购买总额
在窗口里按月份分区
select
name, orderdate, cost , sum(cost) over(partition by substring(orderdate,0,7)) month_cost
from business
3.查询顾客的购买明细 及 每个顾客的月购买总额
按照人 然后按照月份 进行分区
select
name, orderdate, cost , sum(cost) over(partition by name , substring(orderdate,0,7)) everyone_month_cost
from business
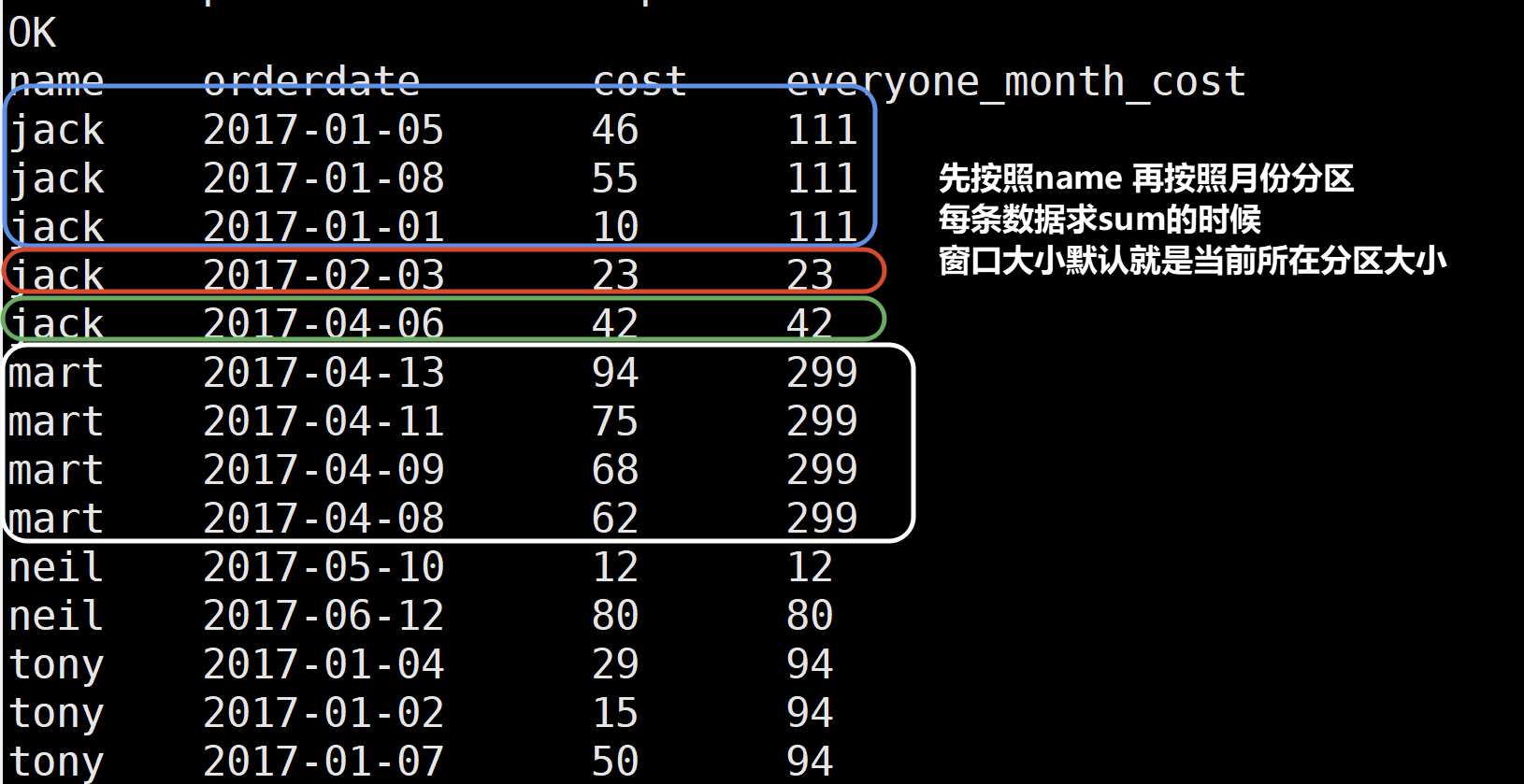
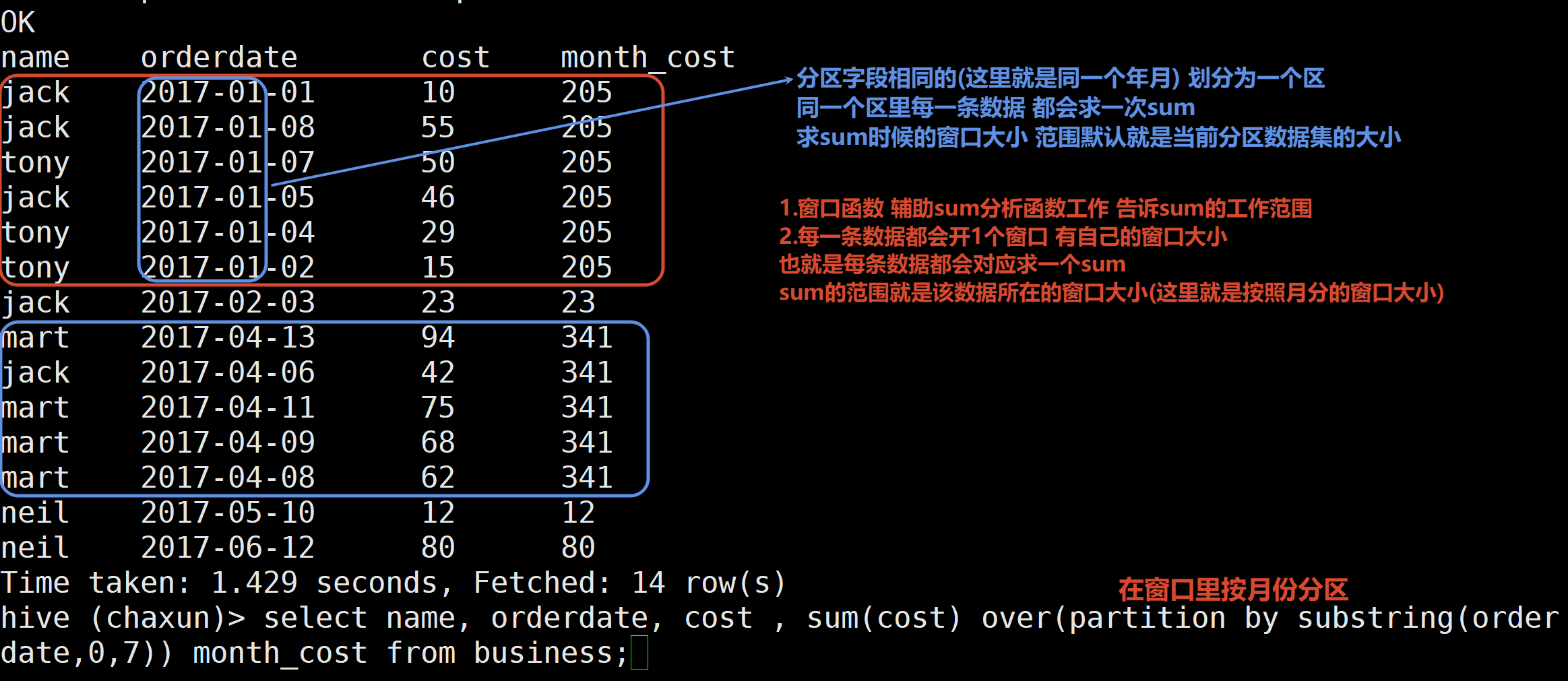
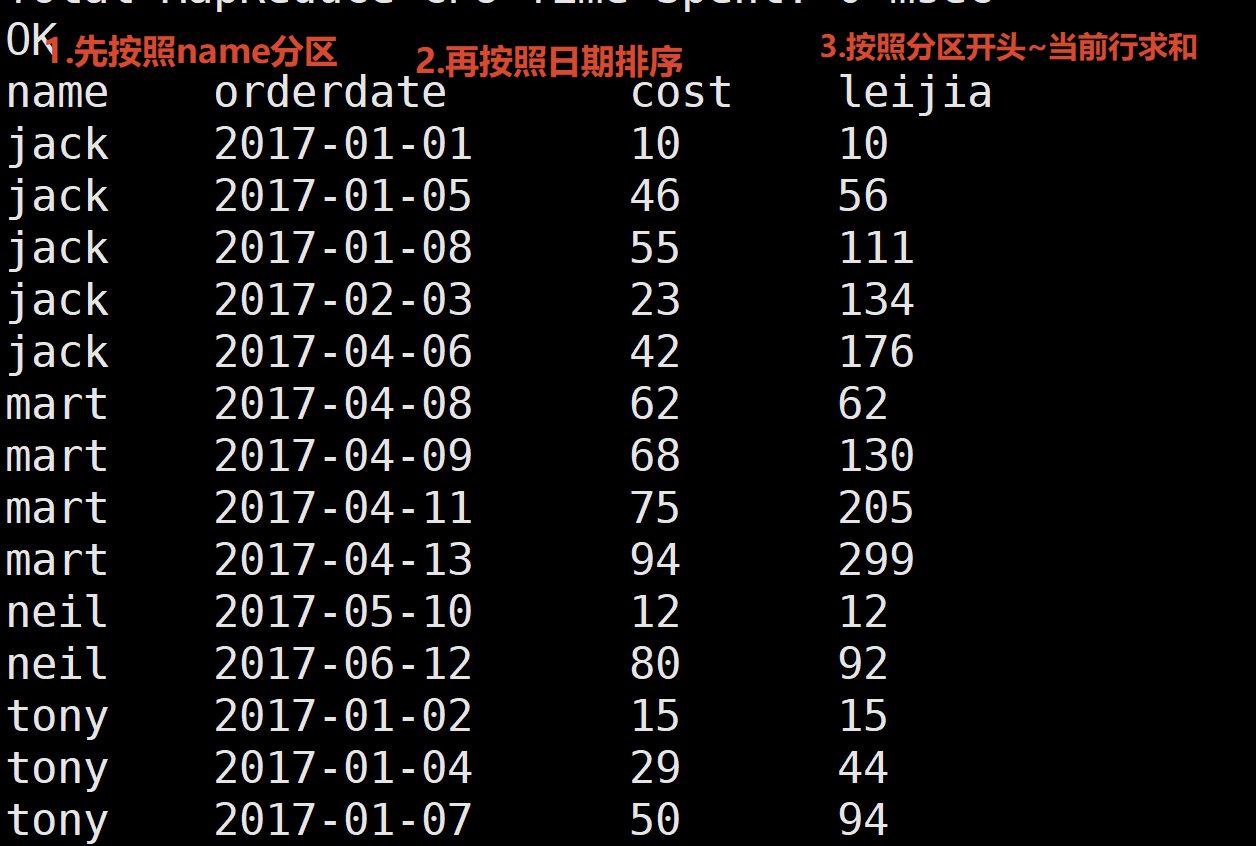
4.将每个顾客的cost按照日期进行累加
按照顾客name分区 再排序
每条数据的窗口大小指定为 当前行所属分区的开始~当前行
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and CURRENT ROW) leijia
from business;or 省略指定的rows 有了order by默认就是当前分区的开始到当前行
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate) leijia
from business;

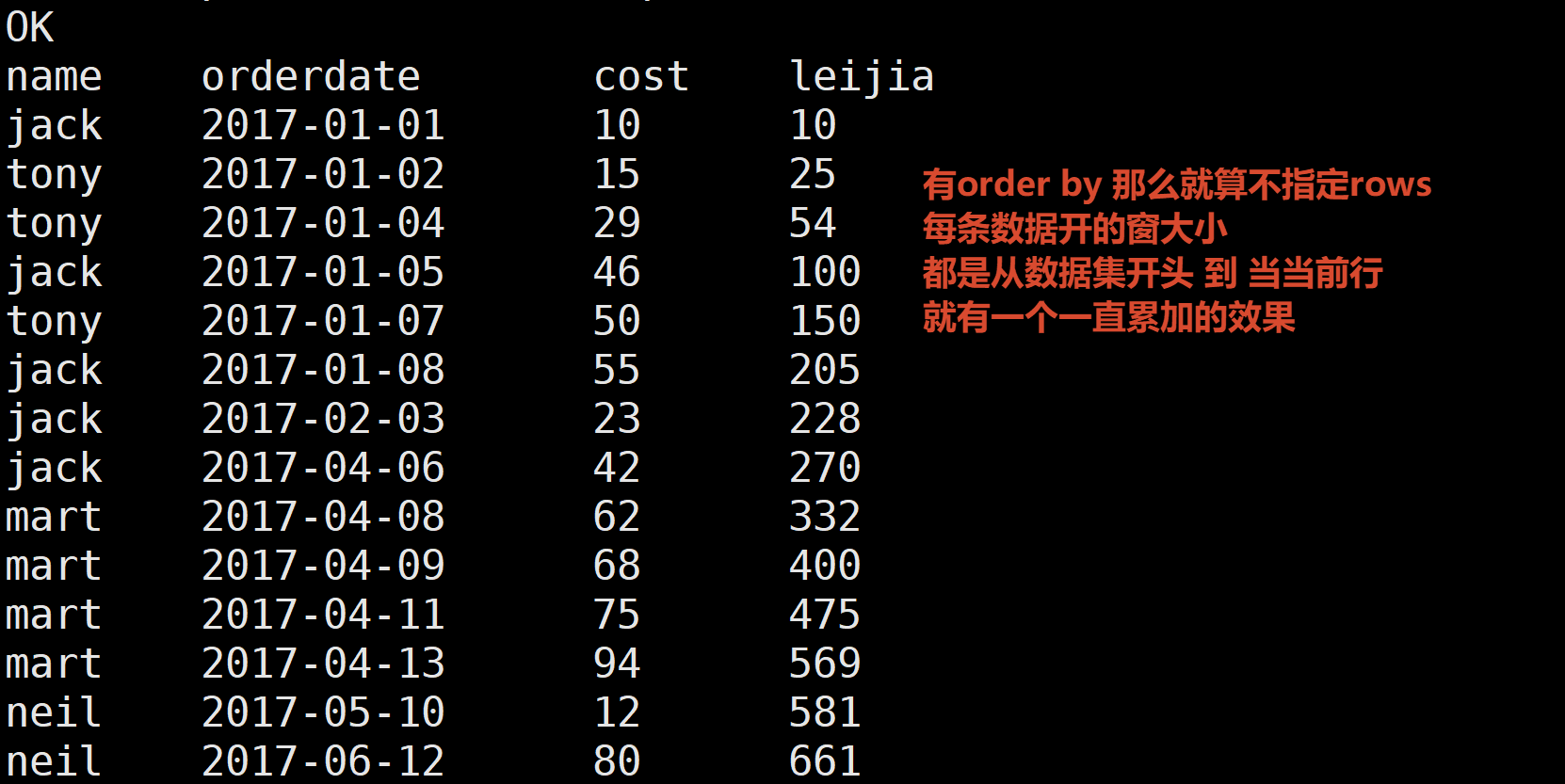
5.将所有顾客的cost按照日期进行累加
所有顾客了 那就不需要按照name分区 直接按日期排序 然后累加cost即可
这里因为有order by 所以可以省略指定rows
每条数据的窗口大小 默认从当前数据集的开始 到 当前行
select
name,
orderdate,
cost,
sum(cost) over(order by orderdate) leijia
from business;
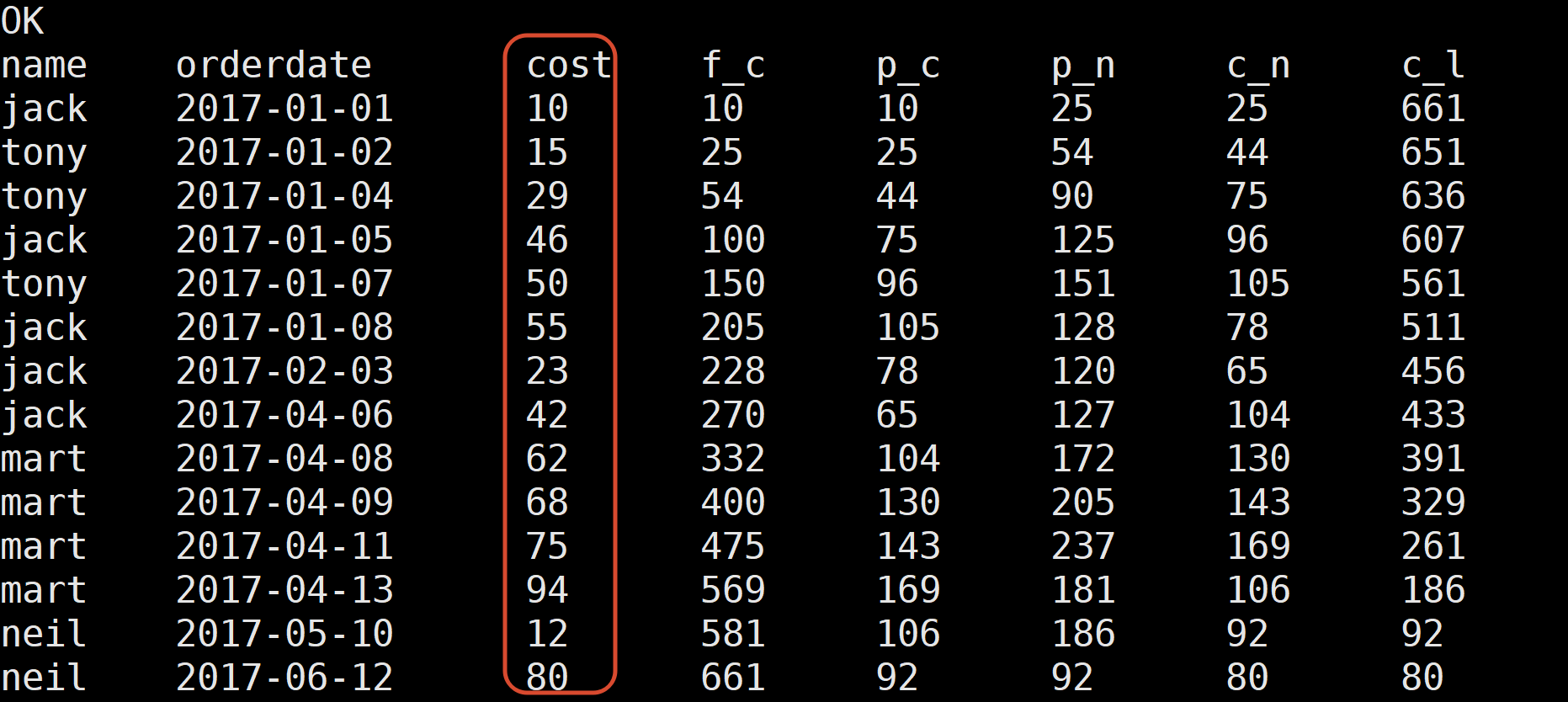
补充:
select
name,
orderdate,
cost,
sum(cost) over(order by orderdate rows between UNBOUNDED PRECEDING and CURRENT ROW) f_c,
sum(cost) over(order by orderdate rows between 1 PRECEDING and CURRENT ROW ) p_c,
sum(cost) over(order by orderdate rows between 1 PRECEDING and 1 FOLLOWING ) p_n,
sum(cost) over(order by orderdate rows between CURRENT ROW and 1 FOLLOWING ) c_n,
sum(cost) over(order by orderdate rows between CURRENT ROW and UNBOUNDED FOLLOWING ) c_l
from business

6.查询每个顾客上次的购买时间 及 下一次的购买时间
lag lead就是把某个字段的前第几行或者后第几行的数据 提取到当前行
select
name,
cost,
orderdate current_orderdate,
lag(orderdate ,1 ,'1970-01-01') over(partition by name order by orderdate) p_orderdate,
lead(orderdate ,1 ,'9999-01-01') over(partition by name order by orderdate) f_orderdate
from business;
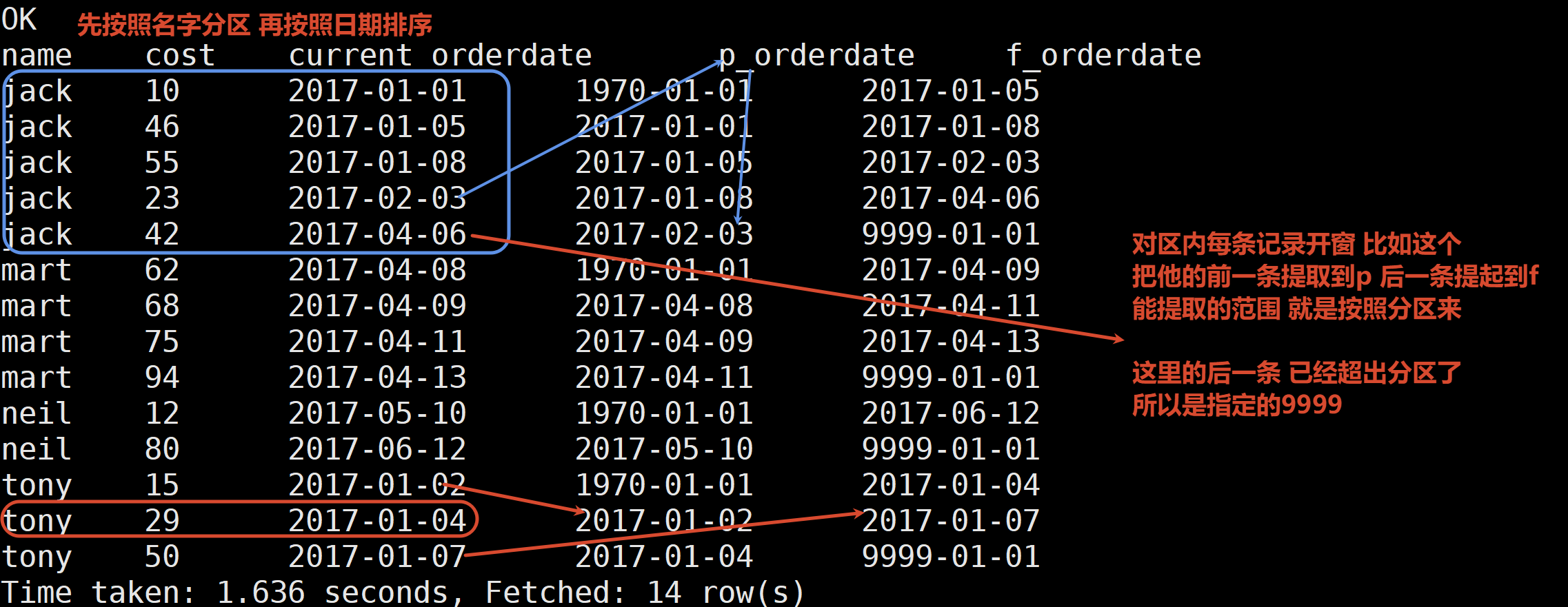
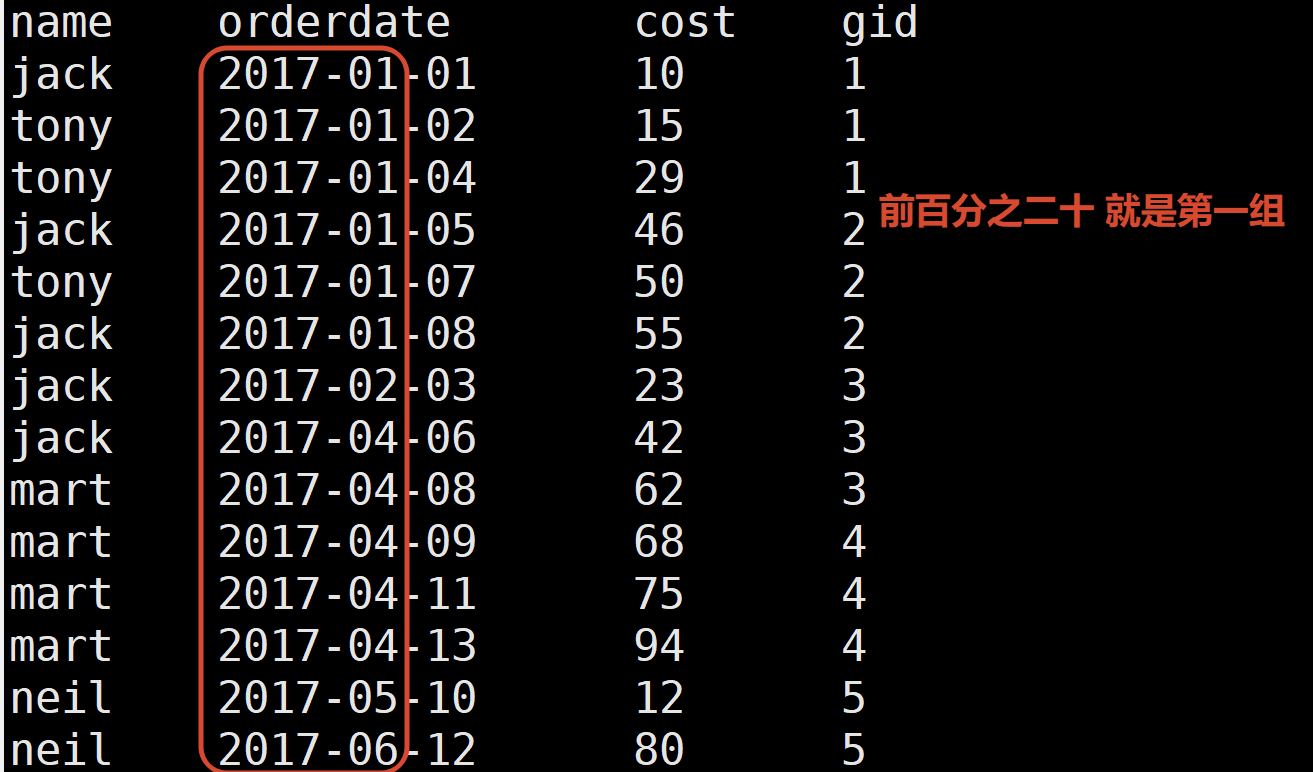
7.查询前20%时间的订单信息
NTILE(n) 把有序窗口的行分发到指定数据的组中 各个组有编号 编号从1开始
对于每一行 NTILE返回此行所属的组的编号
先排好序 然后分成五组
select
name,
orderdate,
cost,
ntile(5) over(order by orderdate ) gid
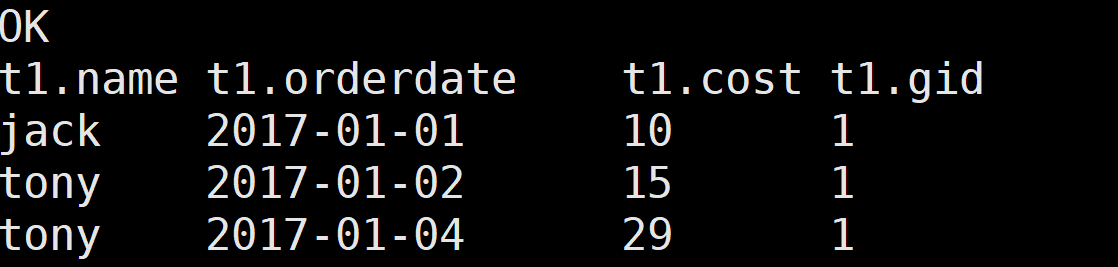
from business;把上图的表作为一个子查询 查询where gid = 1
select t1.name, t1.orderdate,t1.cost ,t1.gid
from
(select name, orderdate, cost, ntile(5) over(order by orderdate ) gid from business) as t1
where t1.gid = 1 ;
小结
1.over(): 会为每条数据都开启一个窗口 默认的窗口大小就是当前数据集的大小 →需求1
2.over(partition by ...) : 会按照指定的字段进行分区 将分区字段相同的数据划分到同一个区
每个区中的每条数据 都会开启一个窗口 每条数据的窗口大小默认为当前分区数据集的大小 →需求23
3.over(order by ...) : 会在窗口中按照指定的字段对数据进行排序 会为每条数据都开启一个窗口 默认的窗口大小为 从数据集开始 到 当前行 → 需求45
4.over(partition by ... order by ...) :先按照指定的字段进行分区 再在每个区中会按照指定的字段进行排序
最后为每条数据都开启一个窗口 默认的窗口大小为 当前分区从数据集开始到当前行 → 需求45
5.over(partition by ... order by ... rows between ... and ...) : 自己指定每条数据的窗口大小 → 需求45
关键字小结
order by 全局排序 or 窗口中排序
distribute by 分区
sort by 区内排序
cluster by 分区排序(distribute by 和 sort by 是同一个字段 )
partition by 窗口中分区
partitioned by 建表指定分区字段
clustered by 建表指定分桶字段
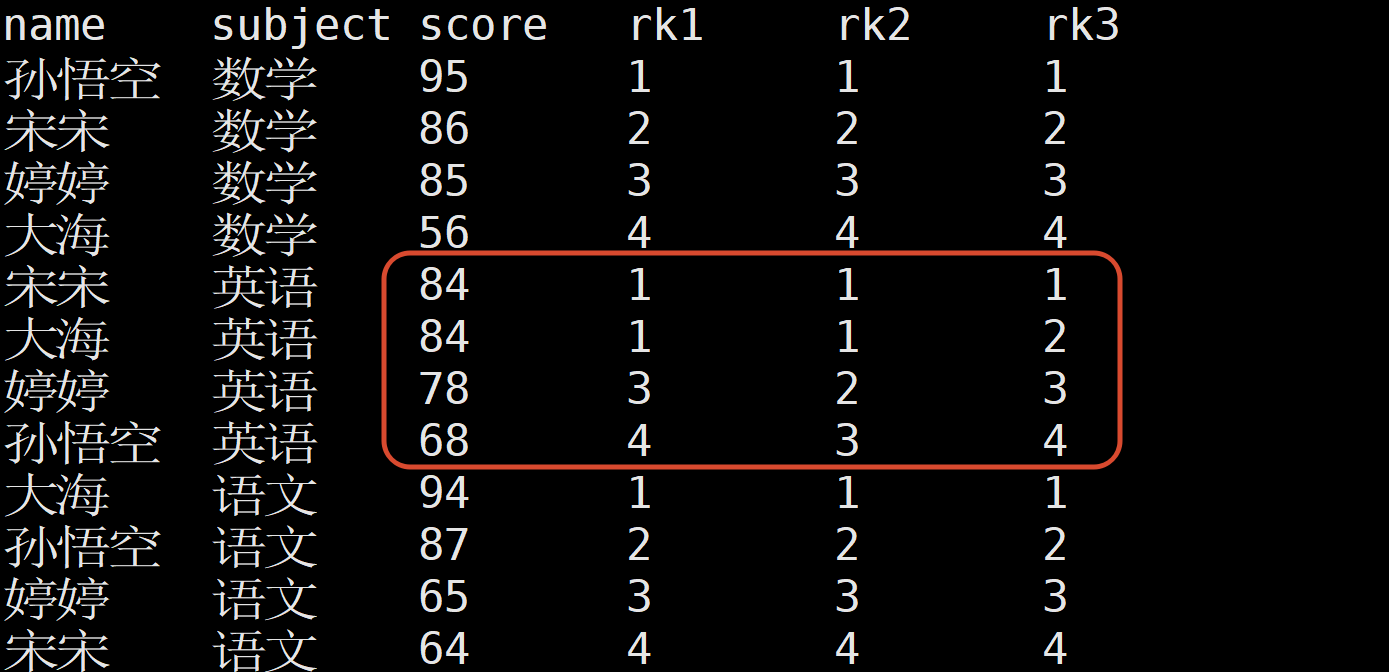
4.8 排名函数
RANK() 排序相同时会重复 总数不会变
DENSE_RANK() 排序相同时会重复 总数会减少
ROW_NUMBER() 会根据顺序计算
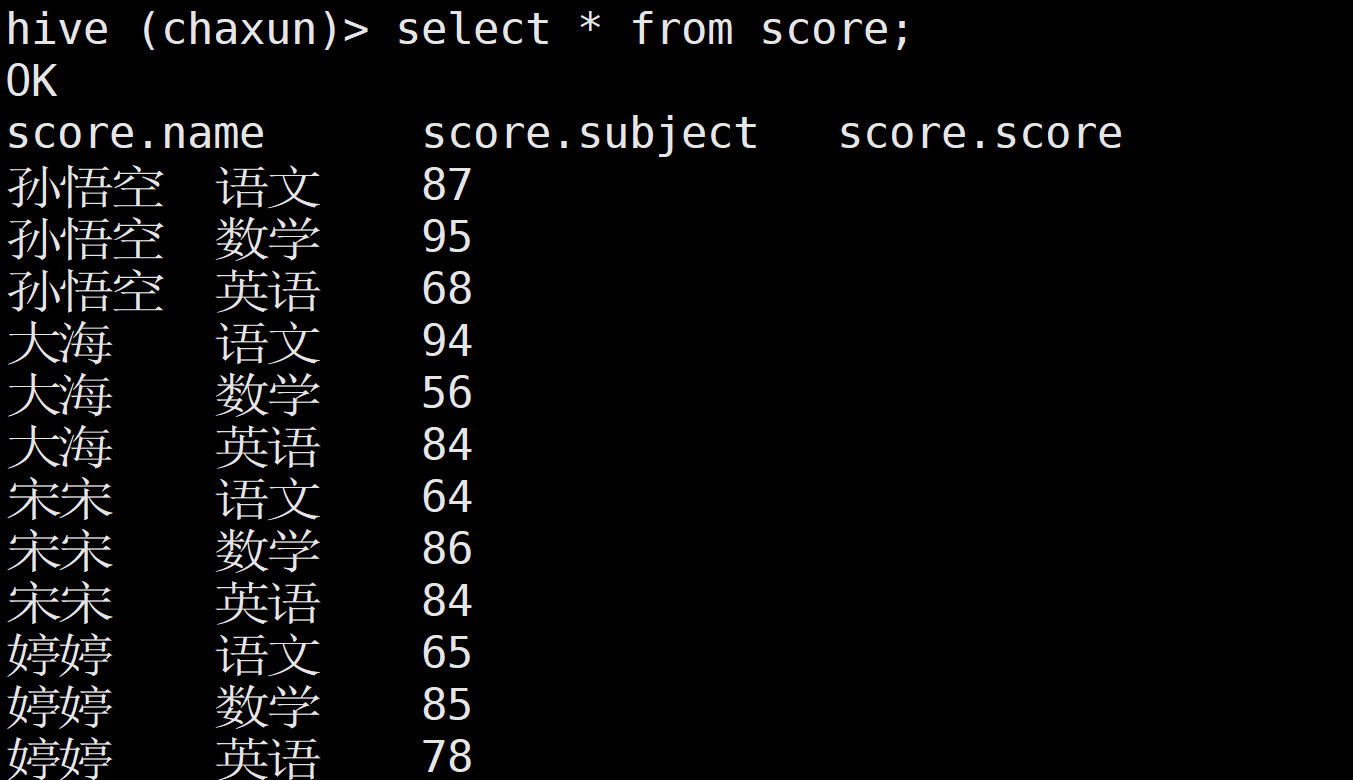
需求: 按照学科进行排名
select
name,
subject,
score,
rank() over(partition by subject order by score desc ) rk1,
dense_rank() over(partition by subject order by score desc ) rk2,
row_number() over(partition by subject order by score desc ) rk3
from score;