一、浏览器常用操作(最大(小)化、刷新、初始位置和大小等)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import unittest
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import time
#设置浏览器,启动浏览器
def she():
#创建设置历览器对象,保证设备没有兼容性问题
q1 = Options()
#禁用沙盒模式
q1.add_argument('--no-sandbox')
#保持浏览器打开状态(默认是代码执行完毕自动关闭)
q1.add_experimental_option('detach', True)
#创建并启动浏览器
a1 = webdriver.Chrome(executable_path="chromedriver.exe", options=q1)
return a1
a1 = she()
#打开指定网址
a1.get("https://baidu.com/")
time.sleep(2)
#浏览器最大化
a1.maximize_window()
time.sleep(2)
#浏览器最小化
a1.minimize_window()
#浏览器打开位置
a1.set_window_position(0,0)
#浏览器打开尺寸
a1.set_window_size(600,600)
# 浏览器截图
a1.get_screenshot_as_file('1.png')
#刷新当前页面
time.sleep(3)
a1.refresh()
#关闭当前标签页
a1.close()
# #退出浏览器
# a1.quit()
二、元素定位 --- Selenium的灵魂
1)导入相关模块
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
2)创建一个谷歌浏览器驱动的句柄
#设置浏览器,启动浏览器
def she():
#创建设置历览器对象,保证设备没有兼容性问题
q1 = Options()
#禁用沙盒模式
q1.add_argument('--no-sandbox')
#保持浏览器打开状态(默认是代码执行完毕自动关闭)
q1.add_experimental_option('detach', True)
#创建并启动浏览器
a1 = webdriver.Chrome(executable_path="chromedriver.exe", options=q1)
return a1
a1 = she()
3)按id定位:find_element(By.ID, "xxx")
1.以在百度输入"dafait"为例,打开百度网站,右击搜索框,点击"检查"

2.右侧会弹出网页的html代码,蓝色部分为搜索框对应的元素,可看到对应的id为"chat-textarea"

3.同理,对于按钮"百度一下"也用相同的方法实现,代码如下:
#元素定位 - id,id定位一般比较准确,但不一定每个元素都有id值
a1.get("https://baidu.com/")
#定位一个元素(找到的话返回结果,找不到的话报错)
a2 = a1.find_element(By.ID, 'chat-textarea')
#元素输入
a2.send_keys('dafait')
#元素清空
a2.clear()
a2 = a1.find_element(By.ID, 'chat-submit-button')
#元素点击事件
a2.click()
#定位多个元素(找到的话返回列表形式,找不到的话返回空列表)
a2 = a1.find_elements(By.ID, 'chat-textarea')
4)按name定位:find_element(By.NAME, "xxx")
1.和id查找类似,例如要点击登录,同样右击后选择"检查",右侧灰色部分可看到name为"tj_login"

2.代码如下:
#元素定位 - name,name定位也比较准确,但不一定每个元素都有name
a1.get("https://baidu.com/")
a2 = a1.find_element(By.NAME, 'tj_login')
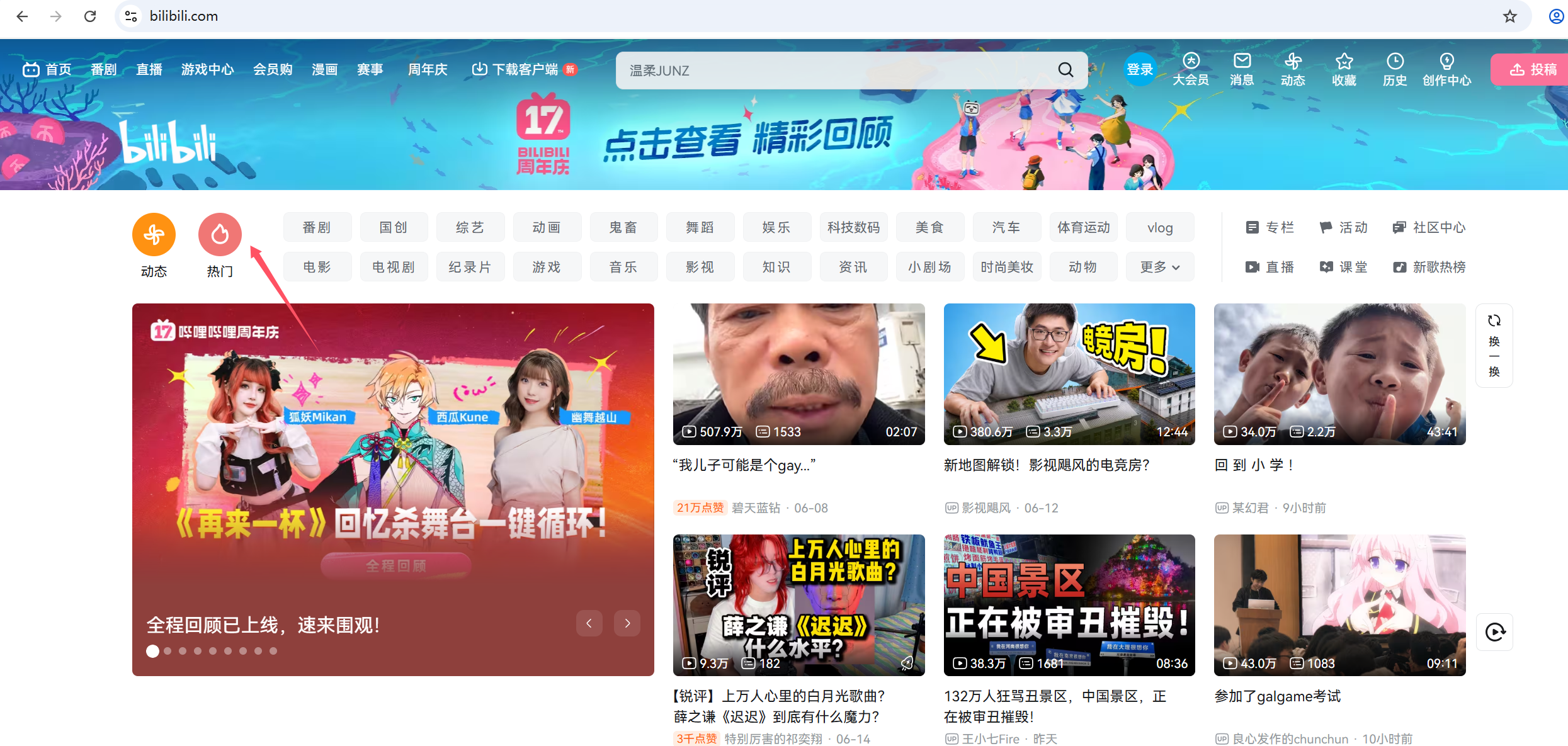
5)按class_name定位:find_element(By.CLASS_NAME, "xxx")
1.比如想点击哔哩哔哩网站中的"热门"模块,如图所示
2.找到热门对于的元素的class样式,由于channel-icons__item样式不止一个元素使用,所以要改用函数f**ind_elements来获取所有应用了"**channel-icons__item"样式的元素,然后再用切片精准地拿到对于的 元素
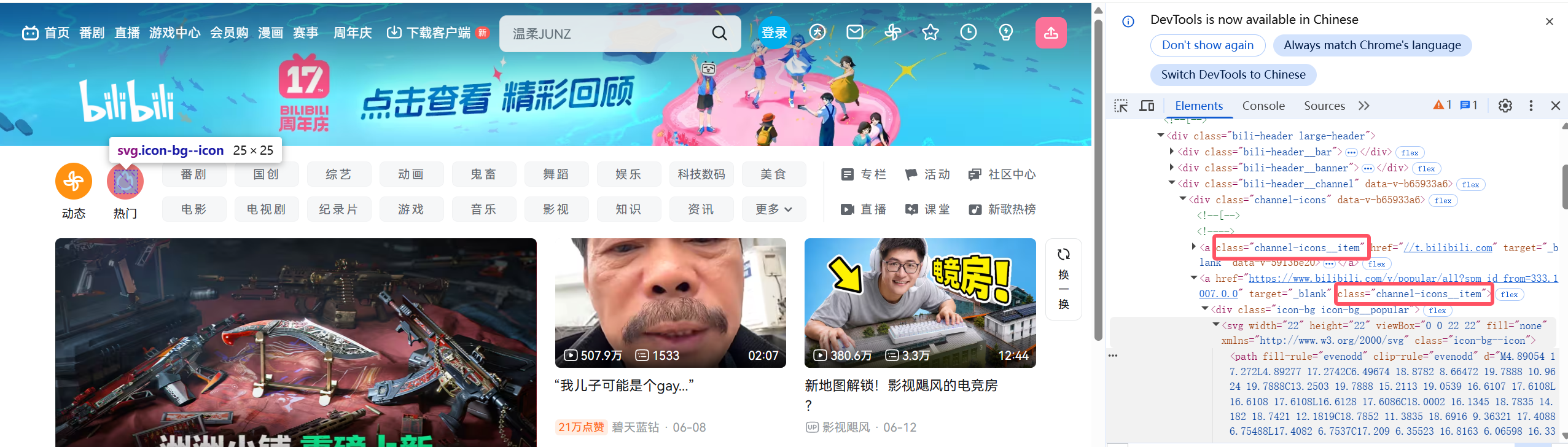
3.具体是哪一个元素可通过控制台查找,点击控制台,先输入"allow pasting"(否则此处的内容可能不能复制粘贴)
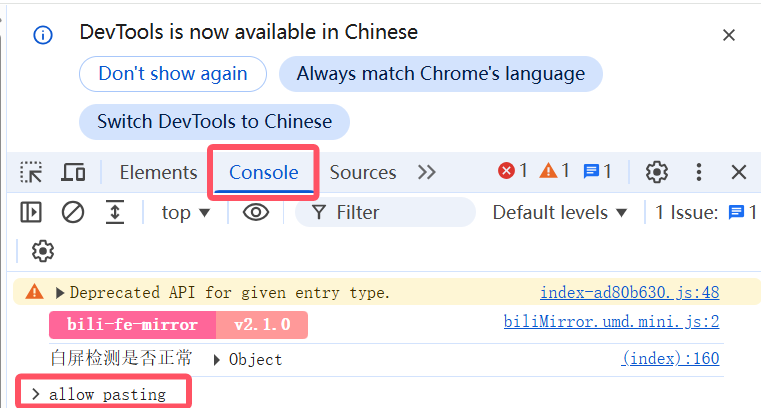
4.输入命令"document.getElementsByClassName("channel-icons__item")",回车后下方出现2个内容,表示有2个元素应用了该样式,当鼠标移动到下标1时"热门"处变色,表示下标1正是对应"热门"按钮
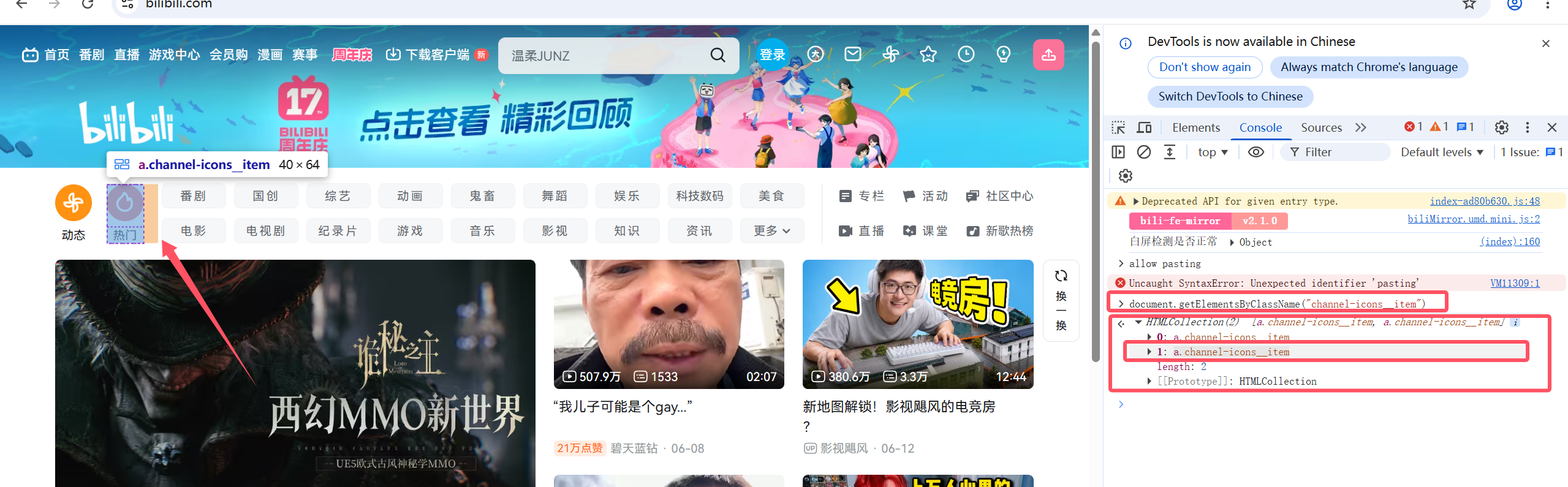
5.编写代码,如图所示:
#元素定位 - class_name,class_name可以应用的样式很多,不太准确,被多个元素使用时需要切片选择
#而且有的class值是随机的,会随着页面刷新而变化
a1.get("https://www.bilibili.com/")
a1.find_elements(By.CLASS_NAME, 'channel-icons__item')[1].click()
6)按tag_name定位:find_element(By.TAG_NAME, "xxx")
和class_name类似,tag_name是按照<>开头的标签来定位元素,代码如图所示:
#元素定位-tag_name
#找出<>开头的标签来定位元素,因重复的特别多,也需要用切片来准确定位
a1.get("https://baidu.com/")
a1.find_elements(By.TAG_NAME, 'textarea')[2].send_keys('dafait')
a1.find_elements(By.TAG_NAME, 'button')[0].click()
7)其他定位和上述类似,此处不一一举例,具体代码如图所示:
#元素定位-link_text
#通过精准链接文本找到标签a的元素
#可能有重复的链接文本,需要切片
a1.get("https://baidu.com/")
a1.find_element(By.LINK_TEXT, '新闻').click()
#元素定位- pratial_link_text
#通过模糊链接文本找到标签a的元素
#可能有重复的链接文本,需要切片
a1.get("https://baidu.com/")
a1.find_element(By.PARTIAL_LINK_TEXT, '新').click()
# 元素定位- css_selector
# 1. #id = 井号 + id值 通过id值定位
# 2. .class = . +class值
# 3. 不加修饰符 = 标签头
# 4. 通过任意类型定位: "[类型='精准值']"
# 5. 通过任意类型定位: "[类型*='模糊值']"
# 6. 通过任意类型定位: "[类型^='开头值']"
# 7. 通过任意类型定位: "[类型$='结尾值']"
a1.get("https://baidu.com/")
a1.find_element(By.CSS_SELECTOR, '#chat-textarea').send_keys('dafait')
a1.find_element(By.CSS_SELECTOR, '.chat-input-textarea').send_keys('dafait')
a1.find_elements(By.CSS_SELECTOR, "[autocomplete='off']")[0].send_keys('dafait')
a1.find_elements(By.CSS_SELECTOR, "[autocomplete*='of']")[0].send_keys('dafait')
a1.find_elements(By.CSS_SELECTOR, "[autocomplete^='o']")[0].send_keys('dafait')
a1.find_elements(By.CSS_SELECTOR, "[autocomplete$='f']")[0].send_keys('dafait')
# 以上这些方法都属于理论定位法
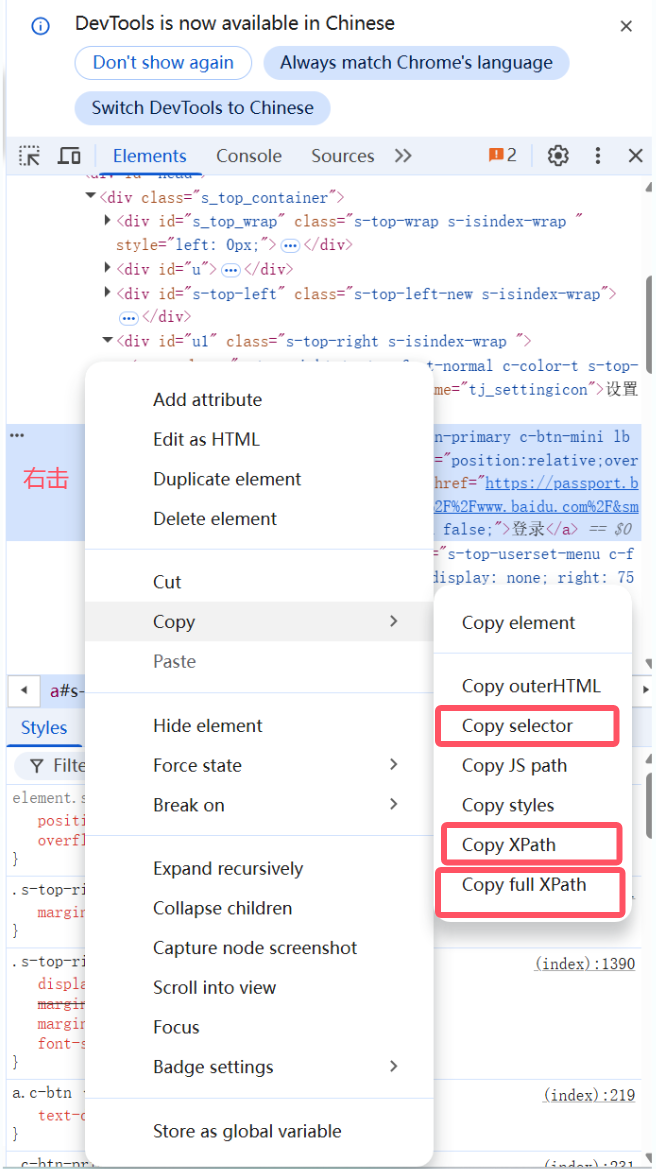
# 更简单的定位方式(重点):在谷歌控制台直接复制 SELECTOR
a1.find_element(By.CSS_SELECTOR, "#chat-textarea").send_keys('dafait')
# 元素定位 - xpath
# 1.复制谷歌浏览器Xpath(通过属性+路径定位,属性如果是随机的就定位不到了)
# 2.复制谷歌 Xpath 完整路径
a1.find_element(By.XPATH, '//*[@id="s-top-left"]/a[1]').click()
a1.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[3]/a[1]').click()
selector和xpath快速复制: