Day 16 --- 混合检索 + Reranker 重排序
一、先看效果
做完 Day 4 的纯向量检索之后,我发现一个问题:搜公司名字经常搜不到。比如知识库里明确写了"码哥科技",但 Embedding 模型从来没在训练数据里见过这个词,它只能瞎猜。
于是做了混合检索,效果对比如下:
| 搜什么 | Day 4(纯向量) | Day 16(混合+Rerank) |
|---|---|---|
| "码哥科技退款流程" | Top-1 不相关 | Top-1 精确命中 |
| "API_KEY 配置在哪" | 排名靠后 | Top-1,0.997 分 |
| "产品有哪些功能" | 还行 | 更准、排序更合理 |
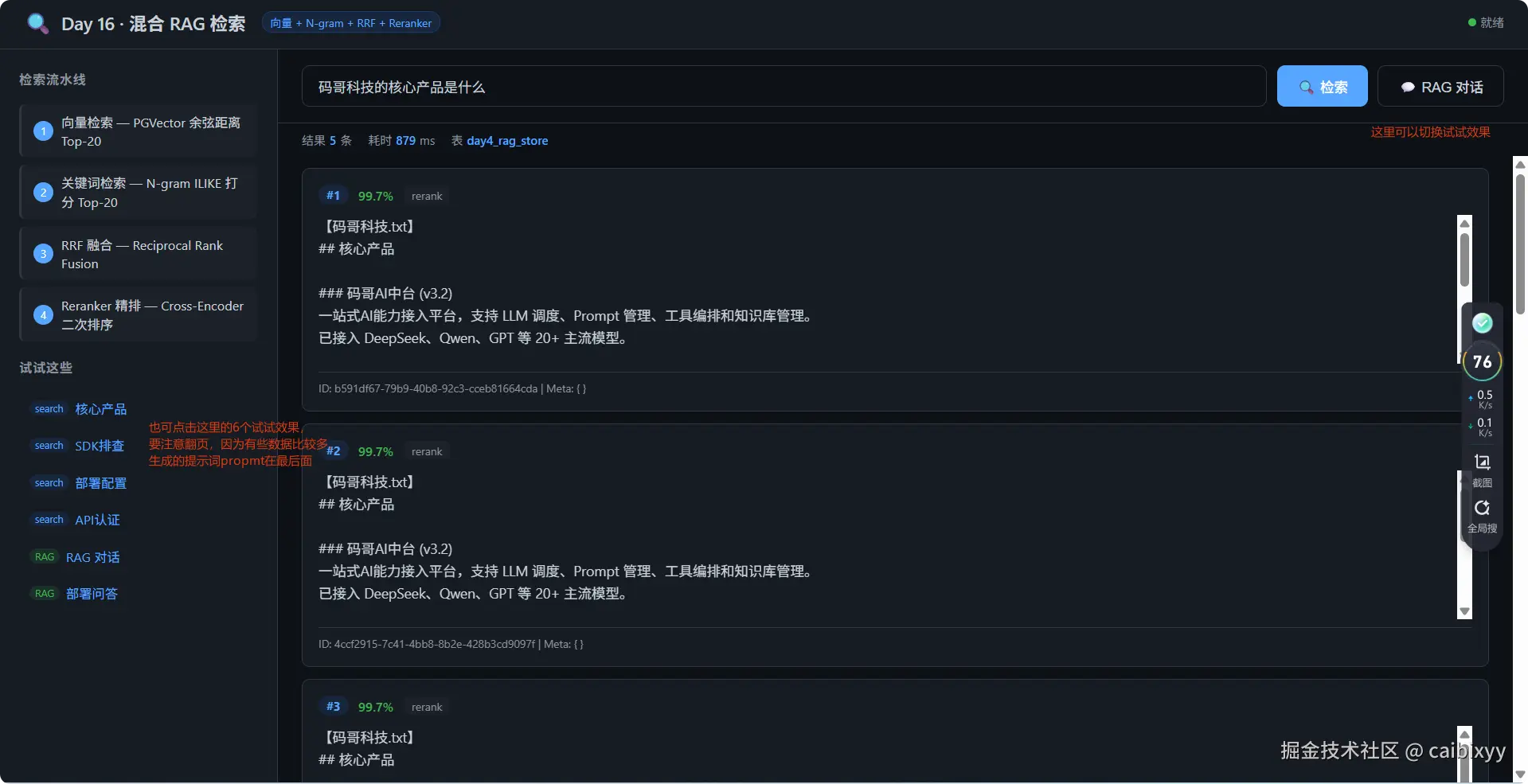
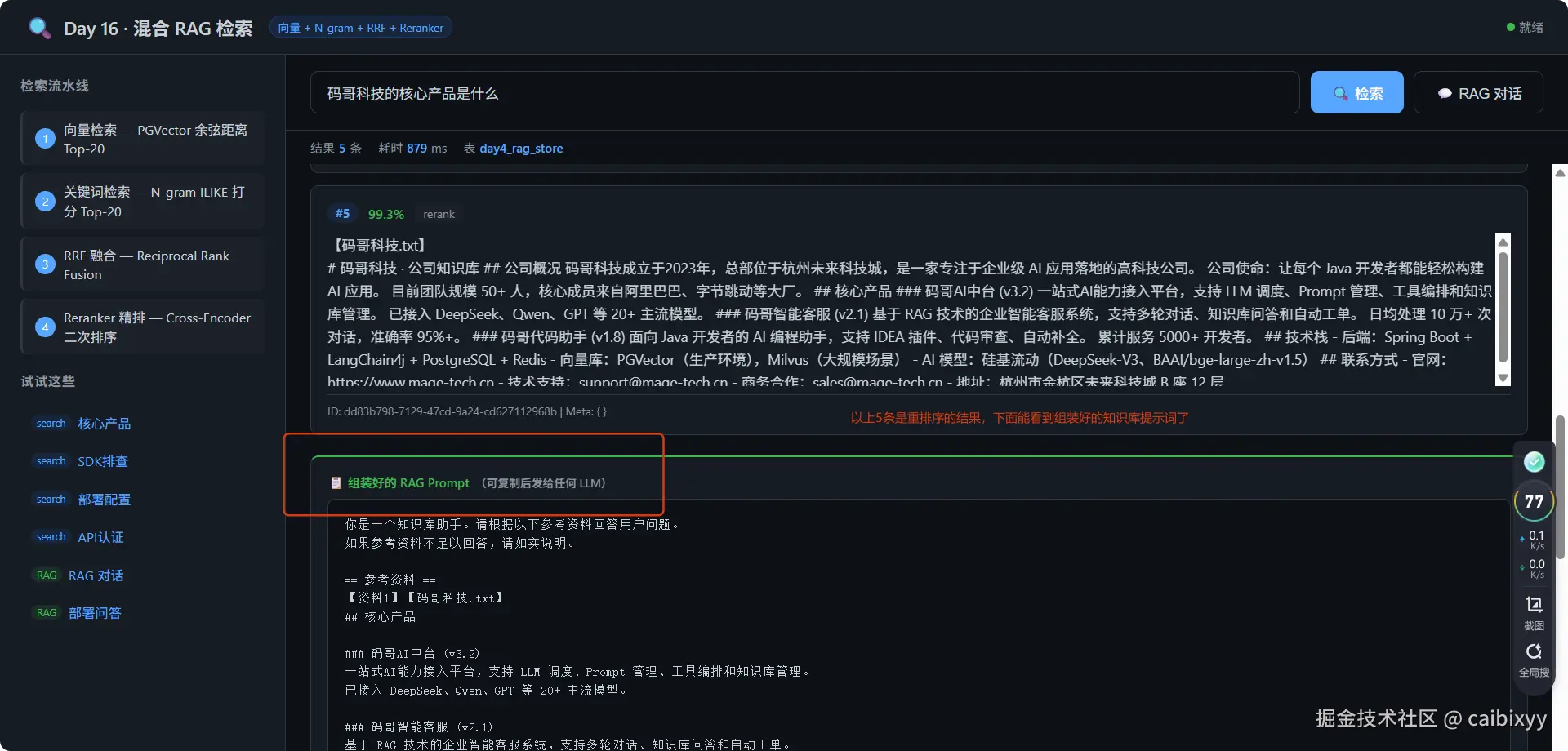
核心变化是:从"只靠一种方式找"变成"两种方式找 + 互相印证 + 裁判精挑"。下面拆开讲每一步。
二、为什么不只用向量检索
Day 4 用的是纯向量检索,流程很简单:
css
问句 → BGE Embedding → 1024 维向量 → PGVector 余弦距离 → Top-20问题出在 Embedding 这一步。拿"码哥科技退款流程"来说,模型把每个词都变成一组浮点数,但它根本没见过"码哥科技"这四个字。训练数据里没有你公司的名字,它只能拿语义相近的词去近似。近似对了算运气,近似错了是常态。
向量检索擅长"意思差不多"的匹配,不擅长"一模一样"的匹配。
所以我在向量检索旁边加了一条关键词路。关键词路不关心语义,只管字面:
arduino
问句 → 去标点 → "码哥科技退款流程"
→ 2-gram: [码哥, 哥科, 科技, 技退, 退款, 款流, 流程]
→ 3-gram: [码哥科, 哥科技, 科技退, ...]
→ ILIKE '%退款%' → 找到所有含"退款"的文档不管"退款"是什么意思,只要文档里出现了这两个字就算命中。公司名、API 名、编号、人名------这些向量模型搞不定的东西,字面匹配直接解决。
两条路各司其职:
- 搜"产品功能" → 向量路好(语义泛化,"功能"太泛关键词不好使)
- 搜"API_KEY" → 关键词路好(精确命中,向量没见过这个组合)
- 搜"李四退款" → 两条路都起作用,交叉印证
三、合并两条路的结果:RRF
两路都返回 Top-20,但分数完全不在一个量纲上:
- 向量路:0.6 ~ 0.9(余弦相似度)
- 关键词路:0 ~ 8(命中了几条 N-gram)
直接加权?0.6 × 权重 + 3 × 权重?权重怎么试都不稳定。
RRF(Reciprocal Rank Fusion)的做法简单粗暴:不看分数绝对值,只看排名位置。
举个例子。搜"码哥科技的产品":
ini
向量排名: 关键词排名:
第1名:文档A 第1名:文档C
第2名:文档B 第2名:文档A
第3名:文档D 第3名:文档B
文档A = 1/(60+1) + 1/(60+2) = 0.0325 → 两路都靠前,第一
文档B = 1/(60+2) + 1/(60+3) = 0.0320 → 第二
文档C = 1/(60+21)+ 1/(60+1) = 0.0287 → 向量路没排进去,第三
文档D = 1/(60+3) + 1/(60+21)= 0.0282公式就是 1/(k + 排名),两路累加。k=60,TREC 论文的经典常数,让分数曲线不会因为排名差异太大而跳跃。
这个思路的妙处:不管后面加几条路,都用排名位置对齐,不需要调权重。 后面 Day 18 加第三条路(ES BM25),RRF 公式一字不改就能用。
四、RRF 还不够,加 Reranker 精排
RRF 只是合并排名位置,完全不理解文档内容和问题的关系。排第一的可能只是"两条路都恰好没漏",不代表它真的相关。
这时候引入 Reranker。跟向量模型(Bi-Encoder)不同,Reranker 是 Cross-Encoder,把问题和文档成对喂进去,让模型"仔细读":
arduino
输入:
问题:"码哥科技的核心产品是什么"
文档:"码哥科技成立于2023年,核心产品包括码哥AI中台..."
Reranker 内部:问题里的"核心产品"直接注意到文档里的"AI中台",双向交互打分
输出:0.9974 分Bi-Encoder 把问题和文档分别编码,两人从未"见过面"。Cross-Encoder 让他们面对面交流,准确度自然高很多。
代价是速度。Bi-Encoder 可以提前把全库文档编码好,查的时候只算距离。Cross-Encoder 必须现场对每个(问题, 文档)对算一遍。所以只对 RRF 融合后的 Top-20 跑 Reranker(几百毫秒),不对全库跑(好几秒)。
调的是硅基流动的 /v1/rerank 接口,模型 BAAI/bge-reranker-v2-m3:
json
POST https://api.siliconflow.cn/v1/rerank
{
"model": "BAAI/bge-reranker-v2-m3",
"query": "码哥科技的核心产品是什么",
"documents": ["文档1", "文档2", ...],
"top_n": 5
}五、完整流水线
scss
用户问句
│
├─ 阶段1:双路召回
│ ├─ 向量路:Embedding → PGVector → Top-20
│ └─ 关键词路:N-gram → ILIKE → Top-20
│
├─ 阶段2:RRF 融合
│ score = 1/(60+向量排名) + 1/(60+关键词排名)
│ → 去重 → 排序
│
└─ 阶段3:Reranker 精排
POST /v1/rerank → relevance_score → Top-5如果 Reranker API 挂了怎么办?做了降级:API 调用失败时不抛异常,直接返回 RRF 结果截断到 Top-5。效果差一点,但至少不报 500。
java
try {
// 调 Reranker API → 解析响应
} catch (Exception e) {
log.error("[Rerank] 失败:{}", e.getMessage());
return candidates.stream().limit(topN).collect(Collectors.toList());
}六、中文关键词检索:不用分词器
做中文关键词检索,第一反应可能是接 jieba 或 HanLP 分词。但我不想引入额外依赖,就用了一个取巧的方案:滑动窗口 N-gram。
java
// 输入:"码哥科技的核心产品是什么"
// cleanQuery() → 去标点、英文、数字 → "码哥科技核心产品"
// generateNgrams() → 2-4 字窗口,取前 8 个:
// [码哥, 哥科, 科技, 技核, 核心, 心产, 产品, 码哥科]每条 N-gram 变成一条 SQL CASE WHEN:
sql
score = (CASE WHEN text ILIKE '%科技%' THEN 1 ELSE 0 END
+ CASE WHEN text ILIKE '%核心%' THEN 1 ELSE 0 END
+ CASE WHEN text ILIKE '%产品%' THEN 1 ELSE 0 END
+ ...) * (1.0 / (1 + length(text) / 500.0))加了一个长度惩罚 1/(1 + len/500):50 字的片段命中 3 个词条,应该排在 5000 字的文章命中 3 个词条前面。短片段更可能是精确答案。
当然这个方案有局限性------它会产生"哥科""技核"这种无意义片段,但这些片段在知识库文档里几乎不会出现,命中的大概率是"科技""核心""产品"这些有实际语义的。后续 Day 18 加了 ES BM25 之后,关键词路就退居二线了。
七、项目结构
bash
day16-hybrid-rag/
├── pom.xml # SB 3.4.3, LC4j 1.13.1, pgvector
├── docs/
│ ├── day16-reference.md # 代码速查
│ └── day16-ai-concepts-teaching.md # 概念拆解
└── src/main/
├── java/com/day16/demo/
│ ├── Day16Application.java # 启动入口,端口 8088
│ ├── config/
│ │ ├── ChatModelConfig.java # LLM + Embedding Bean
│ │ └── DataInitializer.java # 启动时自动向量化
│ ├── controller/
│ │ └── SearchController.java # /search + /rag/chat
│ ├── core/
│ │ └── HybridSearchResult.java # 结果 DTO
│ ├── dto/
│ │ └── ApiResult.java # 统一响应
│ └── rag/
│ ├── HybridSearchService.java # 三阶段编排
│ └── RerankService.java # Reranker API 调用
└── resources/
├── application.yml # 端口 8088, 硅基流动, PGVector
├── schema.sql # PGVector 建表
├── docs/ # 4 篇 .txt 知识库文档
└── static/index.html # 前端测试页面知识库初始化是 DataInitializer 在启动时自动做的:检查表里有没有数据 → 没有就扫描 classpath:docs/ 下的 txt → 按段落切成 ≤300 字的片段 → 调 Embedding API 向量化 → 批量写 PGVector。幂等的,启动多少次都不会重复写。
API Key 用 Jasypt 加密存在 application.yml 里:
yaml
siliconflow:
api-key: ENC(K1krO1oc+4nbWKTGQ/ZUQCVYs/HWQaD...)启动的时候设环境变量 JASYPT_PASSWORD 就行。
八、API
两个端点,都返回 {code, message, data} 格式:
GET /search --- 纯检索:
bash
curl "http://localhost:8088/search?query=码哥科技的核心产品&table=day4_rag_store"返回的每条结果里 source 字段标了来源:rerank 是 Reranker 精排后的,rrf 是融合但没重排的,vector 和 keyword 是单路的。
GET /rag/chat --- RAG 对话:
bash
curl "http://localhost:8088/rag/chat?message=码哥科技有多少员工&table=day4_rag_store"返回检索到的文档 + 拼好的 RAG Prompt,可以直接发给 DeepSeek 拿到回答。
九、技术栈
| 组件 | 版本/型号 | 用途 |
|---|---|---|
| Spring Boot | 3.4.3 | 应用框架 |
| Java | 17 | 运行语言 |
| LangChain4j | 1.13.1 | LLM/Embedding 调用 |
| PGVector | PostgreSQL 17 扩展 | 向量存储与相似度查询 |
| Embedding | BAAI/bge-large-zh-v1.5 | 文本向量化 |
| Reranker | BAAI/bge-reranker-v2-m3 | 精排 |
| DeepSeek-V3 | 硅基流动托管 | RAG 对话 |
| Jasypt | 3.0.5 | API Key 加密 |
十、踩坑记录
这几条坑都是真实跑出来的,每条都浪费了我至少半小时:
1. 启动报 NoSuchBeanDefinitionException: DataSource
pom.xml 里只引了 postgresql 驱动,忘了引 spring-boot-starter-jdbc。Spring Boot 看到 pg 驱动就自动配 DataSource,但没有 jdbc starter 就报找不到 Bean。加上 spring-boot-starter-jdbc 解决。
2. Reranker 返回 200,反序列化报错
硅基流动的 rerank 接口返回的 JSON 里多了一个 DTO 没定义的字段,Jackson 反序列化直接炸了。DTO 上加 @JsonIgnoreProperties(ignoreUnknown = true) 解决。教训:对接第三方 API,DTO 永远要加这个注解。
3. 关键词检索始终返回 0 条
一开始我用正则 \s+ 切词,发现中文没有空格,整个句子被当成了一个词,什么都匹配不出来。改成滑动窗口 N-gram(2-4 字)就好了。
4. String.format 用了 Python 语法
日志打了 %s 出来,查了半天发现写了 {:.4f}------Python 的格式字符串,Java 里是 %.4f。两种语言混着写就容易出这种低级错误。
5. IDE 自动导入 javax.naming.directory.SearchResult
我写了个 DTO 叫 SearchResult,IDEA 自动导了个 JDK 自带的同名类。编译不报错但逻辑全错。后来改名 HybridSearchResult 解决。给类起名的时候最好先查一下 JDK 和框架里有没有同名的。
6. LangChain4j 的 dev.langchain4j.service.Result 被误导入
同上,自定义 Result 类跟框架重名了。改成 ApiResult 彻底解决。
十一、怎么跑起来
bash
# 确认 PGVector 在跑
docker ps | grep ai-postgres
# 设密钥
export JASYPT_PASSWORD=day16-secret-key
# 编译启动
cd day16-hybrid-rag
mvn clean compile spring-boot:run -DskipTests
# 测一下
curl "http://localhost:8088/search?query=码哥科技&table=day4_rag_store"
# 浏览器打开前端
# http://localhost:8088代码在 gitee,day16-hybrid-rag 目录。配套速查手册和概念拆解在 docs/ 下面,需要的话直接看。