一、引言
Apache Hudi 的核心竞争力之一在于对数据的高效 Upsert(更新/插入)能力,而 Index(索引)正是支撑这一能力的关键,索引的本质使命是:在写入时快速定位一条记录是否已存在,以及存在于哪个文件中,从而避免全表扫描。
sql
┌─────────────────────────────────────────────────────────────────┐
│ Hudi Upsert 写入流程 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Incoming Records │
│ │ │
│ ▼ │
│ ┌─────────┐ ┌──────────────────┐ ┌───────────────┐ │
│ │ Tag阶段 │────▶│ Index Lookup │────▶│ 标记INSERT / │ │
│ │(Tagging) │ │ (索引查找) │ │ UPDATE │ │
│ └─────────┘ └──────────────────┘ └───────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ INSERT → 写入新 FileGroup │ │
│ │ UPDATE → 定位已有 FileGroup 合并 │ │
│ └─────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘二、索引核心原理
1.索引在写入链路中的位置
Hudi 写入的核心流程可抽象为以下阶段:
sql
┌────────────────────────────────────────────────────────────────────────┐
│ Hudi Write Pipeline │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────────┐│
│ │ Dedup │───▶│ Index │───▶│Partition │───▶│ Write & Commit ││
│ │(去重) │ │ Tagging │ │ Assign │ │ (写入并提交) ││
│ └──────────┘ └──────────┘ └──────────┘ └──────────────────┘│
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 判断每条Record: │ │
│ │ • 已存在 → UPDATE│ │
│ │ • 不存在 → INSERT│ │
│ │ • 标记目标FileID │ │
│ └─────────────────┘ │
└────────────────────────────────────────────────────────────────────────┘2.索引的核心抽象
在代码层面,Hudi 索引的核心接口(以 Spark 引擎为例)抽象为:
swift
/**
* HoodieIndex 核心接口(简化表示)
*/
public abstract class HoodieIndex {
/**
* 为传入的记录打标(Tag),标记其对应的 FileGroup 位置
* 如果记录已存在于某个文件中,则标记为 UPDATE 并关联 fileId
* 如果不存在,则标记为 INSERT
*/
public abstract <R> HoodieData<HoodieRecord<R>> tagLocation(
HoodieData<HoodieRecord<R>> records,
HoodieEngineContext context,
HoodieTable table);
/**
* 索引类型枚举
*/
public enum IndexType {
BLOOM,
SIMPLE,
BUCKET,
RECORD_INDEX,
// ... 其他类型
}
}核心语义:给定一批 RecordKey,快速返回每个 Key 对应的 FileGroupId + PartitionPath(如果存在的话)。
3.Global Index vs Non-Global Index
| 维度 | Non-Global Index | Global Index |
|---|---|---|
| 唯一性保证范围 | 分区内唯一 | 全表唯一 |
| 查找范围 | 仅在 Record 所属分区内查找 | 跨所有分区查找 |
| 写入性能 | 高(范围小) | 较低(范围大) |
| 典型场景 | 分区键不变的增量更新 | 记录可能跨分区迁移 |
三、索引分类详解
Hudi 提供了多种索引实现,以适应不同的数据规模和场景需求:
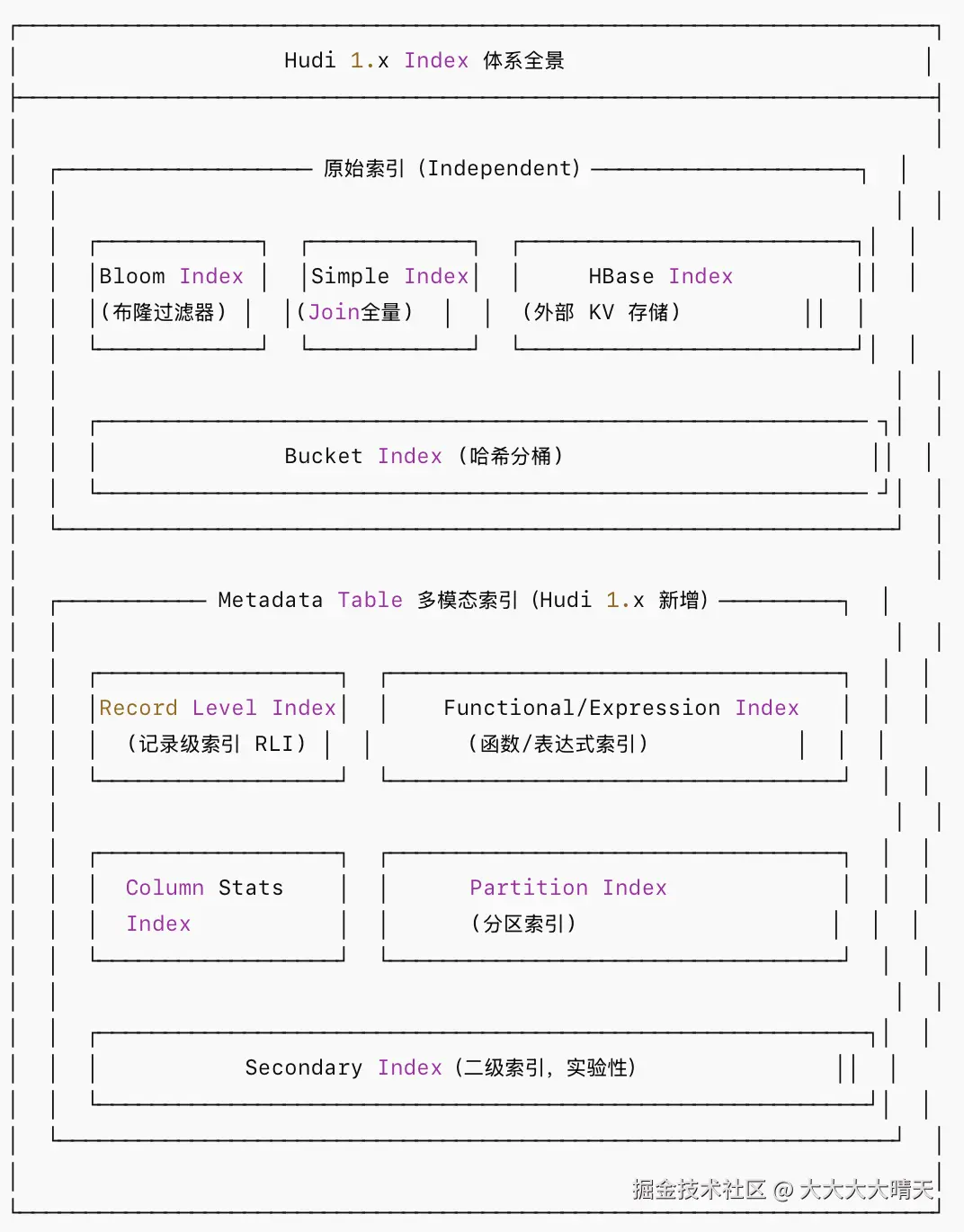
1.Bloom Index(布隆过滤器索引)
每个 Parquet 数据文件的 footer 中内嵌一个 Bloom Filter,记录了该文件包含的所有 Record Key 的指纹。查找时:
- 加载候选文件的 Bloom Filter(从 footer 或 Metadata Table 中读取)
- 对 incoming RecordKey 进行 Bloom Filter 探测
- 若 Bloom Filter 判定"可能存在",则进一步读取文件确认(解决假阳性)
- 若判定"一定不存在",则跳过该文件
sql
┌──────────────────────────────────────────────────────────────┐
│ Bloom Index 查找流程 │
│ │
│ Incoming RecordKey: "user_1001" │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 步骤1: 确定候选文件列表(同分区下所有 FileGroup) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 步骤2: 读取每个文件的 Bloom Filter │ │
│ │ (优先从 Metadata Table 缓存读取) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ├── File_A.bloom → "一定不存在" → 跳过 │
│ ├── File_B.bloom → "可能存在" → 候选 │
│ └── File_C.bloom → "一定不存在" → 跳过 │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 步骤3: 对候选文件进行实际 Key 比对(消除假阳性) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 结果: user_1001 → File_B (fileId=xxx) │
│ │
└──────────────────────────────────────────────────────────────┘关键参数配置:
| 参数 | 说明 | 默认值 |
|---|---|---|
| hoodie.bloom.index.filter.type | Bloom Filter 实现类型 | DYNAMIC_V0 |
| hoodie.index.bloom.num.entries | 预期插入条数(影响 FPR) | 60000 |
| hoodie.index.bloom.fpp | 期望的假阳性率 | 0.000000001 |
| hoodie.bloom.index.prune.by.ranges | 是否启用 Key Range 预剪枝 | true |
| hoodie.bloom.index.use.metadata | 是否从 Metadata Table 读取 Bloom | true |
优缺点:
- ✅ 无外部依赖,自包含
- ✅ 适合 Record Key 有序或具有局部性的场景
- ❌ 假阳性带来额外 I/O
- ❌ 大文件数时 Bloom Filter 加载开销大
2.Simple Index(简单索引)
将 incoming records 与目标分区(或全表,若为 Global)中已有记录进行 Join 匹配,本质是一个分布式 Join 操作。
适用场景:
- 数据量较小的表
- Record Key 分布极度不均匀,Bloom Filter 假阳性率高的场景
- 作为 baseline 或调试用途
关键配置:
ini
hoodie.index.type=SIMPLE
# Global 模式
hoodie.index.type=GLOBAL_SIMPLE- ✅ 实现简单,无假阳性
- ❌ 性能随数据量线性增长,不适合大表
3.Bucket Index(哈希分桶索引)
根据 Record Key 的哈希值将记录确定性地映射到固定编号的 Bucket(FileGroup)中。查找时无需任何 I/O,直接通过哈希计算即可确定目标文件。
ini
┌──────────────────────────────────────────────────────────────┐
│ Bucket Index 映射原理 │
│ │
│ RecordKey: "user_1001" │
│ │ │
│ ▼ │
│ hash("user_1001") mod num_buckets = bucket_id │
│ │ │
│ │ 例: hash值 = 78456 │
│ │ num_buckets = 256 │
│ │ bucket_id = 78456 % 256 = 120 │
│ │ │
│ ▼ │
│ 直接定位到 FileGroup_120 → 无需 I/O 查找 │
│ │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ FG_0│ │ FG_1│ │ FG_2│ ... │FG_N │ │
│ └─────┘ └─────┘ └─────┘ └─────┘ │
│ ▲ │
│ │ │
│ Bucket = Hash(Key) % N │
│ │
└──────────────────────────────────────────────────────────────┘Bucket Index 的两种模式(Hudi 1.x):
| 模式 | 说明 | 特点 |
|---|---|---|
| SIMPLE(固定桶数) | 建表时确定桶数,不可变 | 性能稳定,但需预估数据量 |
| CONSISTENT_HASHING(一致性哈希) | 支持动态扩缩桶数 | 更灵活,通过 Resize 自动调整 |
关键配置:
ini
hoodie.index.type=BUCKET
hoodie.bucket.index.num.buckets=256
# 一致性哈希模式
hoodie.bucket.index.hash.field=record_key_field
hoodie.index.bucket.engine=CONSISTENT_HASHING
hoodie.bucket.index.max.num.buckets=512
hoodie.bucket.index.min.num.buckets=64优缺点:
- ✅ 索引查找零 I/O,写入性能极高
- ✅ 特别适合 Flink 流式写入场景(确定性路由)
- ❌ 固定桶模式下,桶数难以调整(需 Resize/Compaction)
- ❌ 数据倾斜时部分桶可能过大
4.Record Level Index(RLI,记录级索引)
在 Hudi Metadata Table 中维护一个全局的 RecordKey → (Partition, FileGroupId) 映射关系,实现 O(1) 级别的精确定位。
sql
┌──────────────────────────────────────────────────────────────────┐
│ Record Level Index (RLI) 架构 │
│ │
│ ┌─────────────────────────────────────────────────────────────┐│
│ │ Hudi Metadata Table ││
│ │ ││
│ │ ┌─────────────────────────────────────────────────────┐ ││
│ │ │ record_index 分区 (HFile 格式存储) │ ││
│ │ │ │ ││
│ │ │ Key: RecordKey │ ││
│ │ │ Value: {partitionPath, fileGroupId, instantTime} │ ││
│ │ │ │ ││
│ │ │ "user_1001" → {"/dt=2024-01-15", "fg-001", "t1"} │ ││
│ │ │ "user_1002" → {"/dt=2024-01-16", "fg-032", "t2"} │ ││
│ │ │ "user_1003" → {"/dt=2024-01-15", "fg-007", "t1"} │ ││
│ │ │ ... │ ││
│ │ └─────────────────────────────────────────────────────┘ ││
│ │ ││
│ │ 其他分区: files, column_stats, bloom_filters, ... ││
│ └─────────────────────────────────────────────────────────────┘│
│ │
│ 查找流程: │
│ incoming "user_1001" │
│ │ │
│ ▼ │
│ 在 Metadata Table record_index 分区中点查 │
│ │ │
│ ▼ │
│ 直接获得: partition="/dt=2024-01-15", fileGroup="fg-001" │
│ │
└──────────────────────────────────────────────────────────────────┘关键特性:
- 天然支持 Global 唯一性(跨分区定位)
- 基于 Metadata Table 的 HFile 存储,支持高效点查
- 随数据写入自动维护,无需外部系统
- 适合大规模数据集的精确索引需求
关键配置:
ini
hoodie.index.type=RECORD_INDEX
# 需要启用 Metadata Table
hoodie.metadata.enable=true
hoodie.metadata.record.index.enable=true优缺点:
- ✅ 精确定位,零假阳性
- ✅ 全局唯一性保证,无需外部存储
- ✅ 基于 Metadata Table,与 Hudi 生态深度集成
- ❌ Metadata Table 自身需要维护(Compaction 等)
- ❌ 首次初始化需全表构建索引,耗时较长
- ❌ 极高写入吞吐场景下 Metadata Table 可能成为瓶颈
5.Functional / Expression Index(函数/表达式索引)
对数据列应用函数/表达式后建立索引,主要用于加速查询侧的数据跳过(Data Skipping),而非写入侧的 Upsert Tag。
典型用例:
ini
-- 创建基于日期截断函数的索引
CREATE INDEX idx_ts_hour ON hudi_table
USING column_stats(ts)
OPTIONS (func='date_trunc', granularity='hour');当查询WHERE date_trunc('hour', ts) = '2024-01-15 10:00:00'时,可利用该索引快速跳过不相关的文件。
6.HBase Index(外部索引)
使用外部 HBase 集群存储 RecordKey → (Partition, FileGroupId) 映射。
适用场景:
- 已有 HBase 基础设施
- 需要极大规模的全局索引且 Metadata Table 尚未满足需求
- 对索引可用性有独立 SLA 要求
ini
hoodie.index.type=HBASE
hoodie.index.hbase.zkquorum=zk1:2181,zk2:2181
hoodie.index.hbase.zkport=2181
hoodie.index.hbase.table=hudi_index_table7.索引类型对比
| 索引类型 | 查找复杂度 | 外部依赖 | 全局唯一 | 写入性能 | 适合引擎 | 适合规模 |
|---|---|---|---|---|---|---|
| Bloom | O(文件数) | 无 | 需配置 Global | 中 | Spark | 中等 |
| Simple | O(N) | 无 | 支持 | 低 | Spark | 小表 |
| Bucket | O(1) 计算 | 无 | 分区内 | 极高 | Flink/Spark | 大表 |
| Record Index | O(1) 点查 | 无(内置) | 天然全局 | 高 | Spark/Flink | 大表 |
| HBase | O(1) 点查 | HBase | 天然全局 | 高 | Spark | 超大表 |
8.从 0.x 到 1.x 的索引变化
| 维度 | Hudi 0.x | Hudi 1.x |
|---|---|---|
| 默认索引推荐 | Bloom Index | Record Level Index |
| Metadata Table | 可选/实验性 | 默认启用,核心基础设施 |
| 多模态索引 | 不支持 | Column Stats / Functional / Secondary |
| Bucket Index | 仅固定桶 | 新增一致性哈希模式 |
| 索引维护 | 各自独立 | 统一由 Metadata Table 管理 |
四、索引选型建议
yaml
┌─────────────────────────────────────────────────────────────────────────────────────────┐
│ 索引选型决策树 │
│ │
│ Q1: 是否需要跨分区全局唯一? │
│ │ │
│ ├── 是 ──▶ Q2: 数据规模如何? │
│ │ ├── 亿级以下 ──▶ Record Level Index (推荐) │
│ │ ├── 十亿级+ ──▶ Record Level Index / HBase Index │
│ │ └── 已有 HBase ──▶ HBase Index │
│ │ │
│ └── 否(分区内唯一) ──▶ Q3: 写入引擎是什么?
│ │ │
│ ├── Flink 流式写入 ──▶ Bucket Index (推荐) │
│ │ │
│ └── Spark 批/微批 ──▶ Q4: 数据特征如何? │
│ │ │
│ ├── Key 有序/范围集中 ──▶ Bloom Index │
│ ├── Key 随机分散 ──▶ Bucket / Record Index │
│ └── 小表/调试 ──▶ Simple Index │
│ │
└───────────────────────────────────────────────────────────────────────────────────────────┘