文章目录
- [百度Unlimited OCR](#百度Unlimited OCR)
-
- 一、论文基础信息
- [二、核心创新:R-SWA参考滑动窗口注意力(Reference Sliding Window Attention)](#二、核心创新:R-SWA参考滑动窗口注意力(Reference Sliding Window Attention))
-
- [1. 核心设计逻辑](#1. 核心设计逻辑)
- [2. 数学与KV缓存优势](#2. 数学与KV缓存优势)
- [3. 三大对比优势](#3. 三大对比优势)
- [三、Unlimited OCR整体模型架构](#三、Unlimited OCR整体模型架构)
-
- [1. DeepEncoder高压缩图像编码器(完全复用、冻结训练)](#1. DeepEncoder高压缩图像编码器(完全复用、冻结训练))
- [2. MoE解码器(全部注意力层替换为R-SWA)](#2. MoE解码器(全部注意力层替换为R-SWA))
- 完整工作流程
- 四、实验设置
-
- [1. 训练数据](#1. 训练数据)
- [2. 训练细节](#2. 训练细节)
- [3. 评测基准与指标](#3. 评测基准与指标)
- 五、核心实验结果
-
- [1. 单页文档SOTA(OmniDocBench)](#1. 单页文档SOTA(OmniDocBench))
- [2. 推理效率(TPS每秒生成token)](#2. 推理效率(TPS每秒生成token))
- [3. 长文档一次性解析能力(核心独有能力)](#3. 长文档一次性解析能力(核心独有能力))
- [4. 显存节省量化](#4. 显存节省量化)
- 六、现有局限与未来工作
-
- [1. 当前限制](#1. 当前限制)
- [2. 短期规划](#2. 短期规划)
- [3. 长期规划](#3. 长期规划)
- 七、论文整体贡献总结
-
-
- [SGLang 启动服务](#SGLang 启动服务)
-

Unlimited OCR Works
https://arxiv.org/pdf/2606.23050
https://github.com/baidu/Unlimited-OCR
A Unified Framework for Context-Aware and Relation-Aware Graph Retrieval-Augmented Generation
百度Unlimited OCR
一、论文基础信息
核心目标是解决现有端到端OCR长文档一次性解析瓶颈,提出通用注意力机制R-SWA,构建Unlimited OCR模型,实现数十页文档单次前向推理解析,同时显存占用、推理速度不随输出长度恶化。
研究背景与现存痛点
- 现有OCR两大路线缺陷
- 流水线OCR:分检测+识别多阶段,依赖人工规则拼接,多页文档需逐页循环处理,每次重置记忆,上下文断裂、阅读顺序易出错,属于工程折中方案而非原生长上下文建模。
- 端到端LLM-OCR(以DeepSeek OCR为代表) :采用标准多头注意力MHA,KV缓存随输出token线性增长,解码越长显存占用越高、推理延迟持续上升;无法一次性解析10页以上文档,只能分页循环推理。
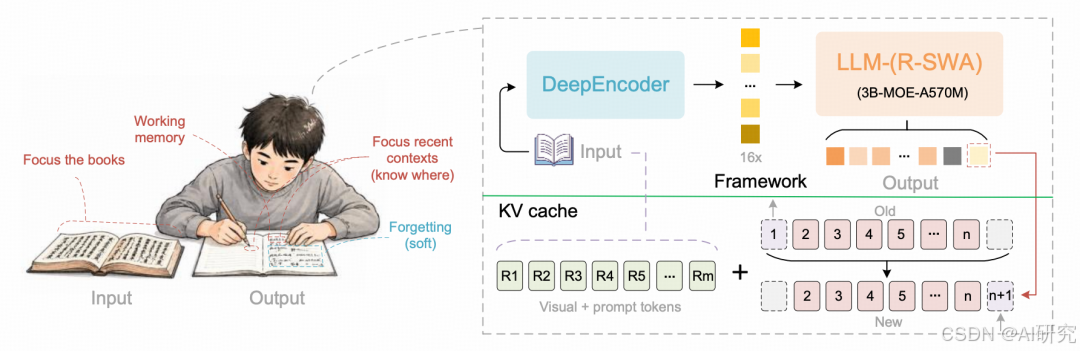
- 人类抄录行为启发
人抄写长文档时存在工作记忆软遗忘机制:全程完整参考原始图文(静态全局信息),仅保留最近少量手写内容定位上下文,不会存储全部历史输出,低认知负载完成长文本转录。现有模型完全不具备该特性。 - 核心矛盾
传统滑动窗口注意力SWA会把视觉token纳入滑动淘汰,反复更新导致图像特征逐步模糊、识别精度下降;全量注意力显存爆炸,二者无法兼顾长文档效率与识别精度。
二、核心创新:R-SWA参考滑动窗口注意力(Reference Sliding Window Attention)
1. 核心设计逻辑
将注意力划分为永久参考段Prefix(m) + 因果滑动输出窗口(n,默认128) 两部分,完全模拟人类抄书记忆逻辑:
- 参考段m(固定不变):包含所有图像视觉token+提示词,全程全局可见、不参与滑动淘汰、不做状态更新,图像编码一次后永久静态,杜绝视觉特征模糊问题;
- 输出滑动窗口n(固定容量):仅保留最近生成的128个文本token,新token生成时淘汰窗口最旧token,输出侧KV缓存容量恒定,不会随解码长度扩张。
2. 数学与KV缓存优势
- 标准MHA缓存: C M H A ( T ) = L m + T C_{MHA}(T)=L_m+T CMHA(T)=Lm+T,随输出长度T无限线性上涨;
- R-SWA缓存: C R − S W A ( T ) = L m + m i n ( n , T ) ≤ L m + n C_{R-SWA}(T)=L_m+min(n,T)≤L_m+n CR−SWA(T)=Lm+min(n,T)≤Lm+n,全局恒定常数;
- 长序列下缓存占比 ρ ( T ) ≈ ( L m + n ) / T \rho(T)≈(L_m+n)/T ρ(T)≈(Lm+n)/T,输出越长显存节省越显著,从显存线性增长变为固定占用。
3. 三大对比优势
- 对比标准全注意力MHA:计算量、显存固定,长文本推理速度无衰减;
- 对比普通滑动窗口SWA:视觉参考token永久保留,不会逐步模糊图像特征,识别精度不损失;
- 通用性:非OCR专用,可迁移至ASR语音识别、机器翻译等所有带参考输入的长序列任务。
三、Unlimited OCR整体模型架构
以DeepSeek OCR为基线改造,整体端到端视觉语言MoE架构,分为两大模块:
1. DeepEncoder高压缩图像编码器(完全复用、冻结训练)
- 堆叠SAM-ViT窗口注意力+CLIP-ViT全局注意力,16倍视觉token压缩;1024×1024单页PDF仅压缩为256个视觉token;
- 两种分辨率模式:Base(1024×1024,多页批量解析)、Gundam(动态分辨率,单页高精度);
- 优势:大幅降低Prefill阶段视觉token长度,是一次性解析数十页文档的基础。
2. MoE解码器(全部注意力层替换为R-SWA)
- 参数规模:总3B MoE,推理仅激活500M参数,轻量化高吞吐;
- 改动:移除原生MHA,所有解码器层统一使用R-SWA;
- 推理特性:全程KV缓存固定,Flash Attention v3内核延迟恒定,无速度衰减;支持32K最大序列长度,单次可输入2--50页文档联合解析。
完整工作流程
多页PDF图像→DeepEncoder压缩为静态视觉参考token→R-SWA解码器:全程读取全部图像token,仅缓存最近128个输出文本token,连续生成全部页面文本、公式、表格、阅读顺序,一次前向完成数十页解析。
四、实验设置
1. 训练数据
总计200万PDF文档样本,单页:多页=9:1;多页数据20万份,每份2--50页,<page>做页面分隔符,全部打包至32K序列长度;单页使用PaddleOCR标注坐标与文本真值。
2. 训练细节
- 预训练权重:DeepSeek OCR权重续训4000步;冻结DeepEncoder,仅更新LLM解码器;
- 硬件:8×A800,全局batch=256,AdamW优化器、余弦退火lr=1e-4;
- 框架:Megatron-LM,DeepEP专家并行EP=4;
- 推理部署:在Transformers、SGLang引擎实现R-SWA缓存管理,支持恒定TPS与显存占用。
3. 评测基准与指标
- OmniDocBench v1.5/v1.6(通用文档SOTA对比)
评测维度:文本编辑距离(越低越好)、公式CDM、表格TEDS/TEDS-S、阅读顺序编辑距离;综合加权总分。 - 自建长文档多页测试集
2/5/10/20/40+页书籍/论文,指标:Distinct-n(文本完整性,越高越好)、编辑距离(识别误差)。
五、核心实验结果
1. 单页文档SOTA(OmniDocBench)
- v1.5版本:综合得分93.23% ,相比基线DeepSeek OCR(87.01%)提升6.22个百分点,全维度全面领先:
- 文本编辑距离0.038(原0.073,误差大幅降低);
- 公式CDM 92.61(原83.37)、表格TEDS 90.93(原84.97);
- 阅读顺序误差0.045(原0.086)。
- v1.6最新榜单:综合93.92%,端到端模型第一,公式识别95.79%超越所有竞品,仅3B总参、500M激活参数,大幅领先数百B超大参数量VL模型(Qwen3-VL 235B仅89.15%)。
- 细分文档测试(PPT、报纸、教材、论文9类):全部指标优于DeepSeek OCR/DeepSeek OCR 2,复杂布局无性能衰减。
2. 推理效率(TPS每秒生成token)
- 单页场景:512并发下TPS 5580,基线DeepSeek OCR为4951,提速12.7%;
- 长输出场景(6144 token):基线TPS衰减至5822,Unlimited OCR稳定7847,速度领先35%;
- 内核延迟:基线解码步数越高延迟越高,存在显存对齐突刺;Unlimited OCR延迟全程平稳无波动,显存占用恒定。
3. 长文档一次性解析能力(核心独有能力)
单次输入2--40+页文档持续解码,性能稳定:
- 20页以内Distinct-20≥98.73%,编辑距离≤0.057;
- 40+页长文档Distinct-35=96.90%,编辑距离仅0.1069;
- 少量识别误差来源:多页模式固定1024分辨率小字模糊,非R-SWA机制缺陷。
4. 显存节省量化
输出序列越长,R-SWA缓存压缩比趋近于0,数万token长文本显存占用远低于传统MHA,低显存硬件即可处理整本图书一次性解析。
六、现有局限与未来工作
1. 当前限制
虽命名"Unlimited",但受32K最大上下文长度约束:页面越多,视觉参考token总量越长,Prefill阶段会触达序列上限,无法做到理论无限页数输入。
2. 短期规划
训练128K超长上下文版本,支持单次输入更多页面。
3. 长期规划
- 构建Prefill缓存池,模型自动按需加载视觉KV片段,模拟人类翻页记忆,实现真正无页数限制OCR;
- 将R-SWA通用注意力机制迁移至ASR语音转写、长文本翻译等所有带固定参考输入的长序列任务。
七、论文整体贡献总结
- 算法创新:提出通用R-SWA注意力机制,区分静态参考token与滑动输出token,实现恒定KV缓存,解决长序列显存与速度双重瓶颈,同时规避普通滑动窗口视觉特征退化问题;
- 模型落地:基于DeepSeek OCR构建Unlimited OCR,3B轻量化MoE架构,单页文档达到业界SOTA,支持数十页文档单次前向解析,推理速度不随文本长度下降;
- 理论验证:验证线性复杂度注意力在多模态文档解析场景的有效性,无需暴力扩展上下文长度即可实现长程依赖建模;
- 工程价值:开源代码与权重,R-SWA可通用迁移至语音、翻译等多类长序列任务,为长文本解析提供通用优化范式。
- 示例
bash
import os
import torch
from transformers import AutoModel, AutoTokenizer
model_name = 'baidu/Unlimited-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
use_safetensors=True,
torch_dtype=torch.bfloat16,
)
model = model.eval().cuda()
# ── Single image supports two configs: gundam or base ──
# gundam: base_size=1024, image_size=640, crop_mode=True
# base: base_size=1024, image_size=1024, crop_mode=False
model.infer(
tokenizer,
prompt='<image>document parsing.',
image_file='your_image.jpg',
output_path='your/output/dir',
base_size=1024, image_size=640, crop_mode=True,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=128,
save_results=True,
)
# ── Multi page / PDF only uses base (image_size=1024) ──
model.infer_multi(
tokenizer,
prompt='<image>Multi page parsing.',
image_files=['page1.png', 'page2.png', 'page3.png'],
output_path='your/output/dir',
image_size=1024,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=1024,
save_results=True,
)
# ── PDF (convert pages to images, then multi-page parsing) ──
import tempfile, fitz # PyMuPDF
def pdf_to_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
tmp_dir = tempfile.mkdtemp(prefix='pdf_ocr_')
mat = fitz.Matrix(dpi / 72, dpi / 72)
paths = []
for i, page in enumerate(doc):
out = os.path.join(tmp_dir, f'page_{i+1:04d}.png')
page.get_pixmap(matrix=mat).save(out)
paths.append(out)
doc.close()
return paths
model.infer_multi(
tokenizer,
prompt='<image>Multi page parsing.',
image_files=pdf_to_images('your_doc.pdf', dpi=300),
output_path='your/output/dir',
image_size=1024,
max_length=32768,
no_repeat_ngram_size=35, ngram_window=1024,
save_results=True,
)SGLang 启动服务
bash
uv venv --python 3.12
source .venv/bin/activate
uv pip install wheel/sglang-0.0.0.dev11416+g92e8bb79e-py3-none-any.whl
uv pip install kernels==0.11.7
uv pip install pymupdf==1.27.2.2
bash
python -m sglang.launch_server \
--model baidu/Unlimited-OCR \
--served-model-name Unlimited-OCR \
--attention-backend fa3 \
--page-size 1 \
--mem-fraction-static 0.8 \
--context-length 32768 \
--enable-custom-logit-processor \
--disable-overlap-schedule \
--skip-server-warmup \
--host 0.0.0.0 \
--port 10000
bash
import base64
import json
import os
import tempfile
import fitz
import requests
from sglang.srt.sampling.custom_logit_processor import DeepseekOCRNoRepeatNGramLogitProcessor
server_url = "http://127.0.0.1:10000"
session = requests.Session()
session.trust_env = False
def pdf_to_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
tmp_dir = tempfile.mkdtemp(prefix="pdf_ocr_")
mat = fitz.Matrix(dpi / 72, dpi / 72)
image_paths = []
for i, page in enumerate(doc):
image_path = os.path.join(tmp_dir, f"page_{i + 1:04d}.png")
page.get_pixmap(matrix=mat).save(image_path)
image_paths.append(image_path)
doc.close()
return image_paths
def encode_image(image_path):
ext = os.path.splitext(image_path)[1].lower()
mime = "image/jpeg" if ext in (".jpg", ".jpeg") else f"image/{ext.lstrip('.')}"
with open(image_path, "rb") as f:
data = base64.b64encode(f.read()).decode("utf-8")
return {"type": "image_url", "image_url": {"url": f"data:{mime};base64,{data}"}}
def build_content(prompt, image_paths):
return [{"type": "text", "text": prompt}] + [encode_image(path) for path in image_paths]
def generate(prompt, image_paths, image_mode, ngram_window):
payload = {
"model": "Unlimited-OCR",
"messages": [{"role": "user", "content": build_content(prompt, image_paths)}],
"temperature": 0,
"skip_special_tokens": False,
"images_config": {"image_mode": image_mode},
"custom_logit_processor": DeepseekOCRNoRepeatNGramLogitProcessor.to_str(),
"custom_params": {
"ngram_size": 35,
"window_size": ngram_window,
},
"stream": True,
}
response = session.post(
f"{server_url}/v1/chat/completions",
headers={"Content-Type": "application/json"},
data=json.dumps(payload),
timeout=1200,
stream=True,
)
response.raise_for_status()
chunks = []
for line in response.iter_lines(chunk_size=1, decode_unicode=True):
if not line or not line.startswith("data: "):
continue
data = line[len("data: "):]
if data == "[DONE]":
break
event = json.loads(data)
delta = event["choices"][0].get("delta", {}).get("content", "")
if delta:
print(delta, end="", flush=True)
chunks.append(delta)
print()
return "".join(chunks)
# Single image supports two configs: gundam or base. Example below uses gundam.
generate("document parsing.", ["your_image.jpg"], image_mode="gundam", ngram_window=128)
# Multi image (base only)
generate("Multi page parsing.", ["page1.png", "page2.png"], image_mode="base", ngram_window=1024)
# PDF (base only)
generate("Multi page parsing.", pdf_to_images("your_doc.pdf", dpi=300), image_mode="base", ngram_window=1024)