
这里写目录标题
-
- [一、出海 KOL 筛选的痛点:现有工具不够用](#一、出海 KOL 筛选的痛点:现有工具不够用)
-
- [1.1 典型翻车案例](#1.1 典型翻车案例)
- [1.2 国内外工具对比与局限性](#1.2 国内外工具对比与局限性)
- 二、技术架构与开发准备
-
- [2.1 管道整体架构](#2.1 管道整体架构)
- [2.2 开发环境与账号准备](#2.2 开发环境与账号准备)
- [三、Instagram 博主数据采集实战](#三、Instagram 博主数据采集实战)
-
- [3.1 Instagram Scraper API 接入说明](#3.1 Instagram Scraper API 接入说明)
- [3.2 Python 批量采集脚本实现](#3.2 Python 批量采集脚本实现)
- [3.3 返回字段与数据结构](#3.3 返回字段与数据结构)
- [四、TikTok 创作者数据采集实战](#四、TikTok 创作者数据采集实战)
-
- [4.1 TikTok Scraper API 接入说明](#4.1 TikTok Scraper API 接入说明)
- [4.2 Python 批量采集脚本实现](#4.2 Python 批量采集脚本实现)
- [4.3 扩展端点:抓 Posts 数据补全互动指标](#4.3 扩展端点:抓 Posts 数据补全互动指标)
- [五、KOL 评分模型与排名输出](#五、KOL 评分模型与排名输出)
-
- [5.1 数据合并与字段对齐](#5.1 数据合并与字段对齐)
- [5.2 五维度评分体系设计](#5.2 五维度评分体系设计)
- [5.3 评分模型 Python 实现](#5.3 评分模型 Python 实现)
- [5.4 排名输出与样例解读](#5.4 排名输出与样例解读)
- 六、成本分析与开源交付
-
- [6.1 单条数据成本对比](#6.1 单条数据成本对比)
- [6.2 GitHub Repo 与使用指南](#6.2 GitHub Repo 与使用指南)
- 七、总结
一、出海 KOL 筛选的痛点:现有工具不够用
1.1 典型翻车案例
美妆出海品牌筛 KOL 翻车是常事。一个典型案例:某品牌预算五万美金砸在 8 个 TikTok 博主身上,视频一发每条几百万播放,团队群里发红包庆祝。一周后看转化------加购 0.3%,退货 40%,ROAS 算下来还不如直接投 Facebook 信息流。
复盘时用Bright Data拉这几个账号的真实数据,问题立刻浮出来:一个号称 50 万粉的"美妆头部",最近 90 天只发了 4 条内容,活跃度比普通个人号还低;另外三个账号的粉丝 70% 集中在印尼和巴西------品牌要打北美市场,一个都没对上。
最坑的不是博主骗了团队,是花几千块订阅的 KOL 工具根本没显示这些字段。同样的 8 个账号,Bright Data 5 分钟就跑出所有问题------互动率分布、粉丝地区、发文频率,任何一条都能在签约前叫停。
这种翻车本来可以避免。这篇文章交付一套可复用的 KOL 筛选管道:用Bright Data的 Instagram Scraper API 和 TikTok Scraper API 拉真实数据,跑评分模型,5 分钟出排名。代码全开 GitHub,照着跑就行。
1.2 国内外工具对比与局限性
国内 KOL 工具做国内很强,出海基本抓瞎。踩完坑整理一张对照表:
| 工具 | 月费 | 覆盖平台 | 数据时效 | 核心局限 |
|---|---|---|---|---|
| 飞瓜数据 | ¥999--¥3,999 | 抖音/快手/B站/小红书 | 较新 | 不覆盖 Instagram/TikTok 海外版 |
| 新榜 | ¥1,500--¥5,000 | 微信/微博/抖音 | 较新 | 海外博主数据几乎没有 |
| 卡思数据 | ¥2,000+ | 抖音/快手/B站 | 较新 | 仅国内平台 |
| 蝉妈妈 | ¥299--¥1,999 | 抖音/TikTok 部分 | 较新 | TikTok 海外字段有限无法自定义 |
| HypeAuditor | 99 99 99399 | IG/TikTok/YouTube | 月度更新 | 价格高、筛选死板、无中文 |
| 自建(Bright Data) | 按用量付费 | 海外全平台,字段自定义 | 实时 | 需要初始配置 |
飞瓜、卡思、新榜做的是抖音快手生态,找 Instagram、TikTok 海外版、YouTube 博主时要么没数据要么字段少得可怜。HypeAuditor 覆盖海外但订阅贵、更新慢、筛选死板------你想找"粉丝在东南亚、互动率 >5%、近 30 天发过美妆内容"这种组合,没工具能直接给答案。这也是为什么 Bright Data 更适合作为需要自定义字段、实时数据和规模化采集的海外数据基础设施。
不用 Dify / Coze 零代码工作流去搭,因为 KOL 评分本质是数据科学问题,不是流程编排问题。你要稳定字段、可调权重、可复现排名,每改阈值都要看分布------纯 Python + Bright Data social media scraper API 最直接最可控。
二、技术架构与开发准备
2.1 管道整体架构
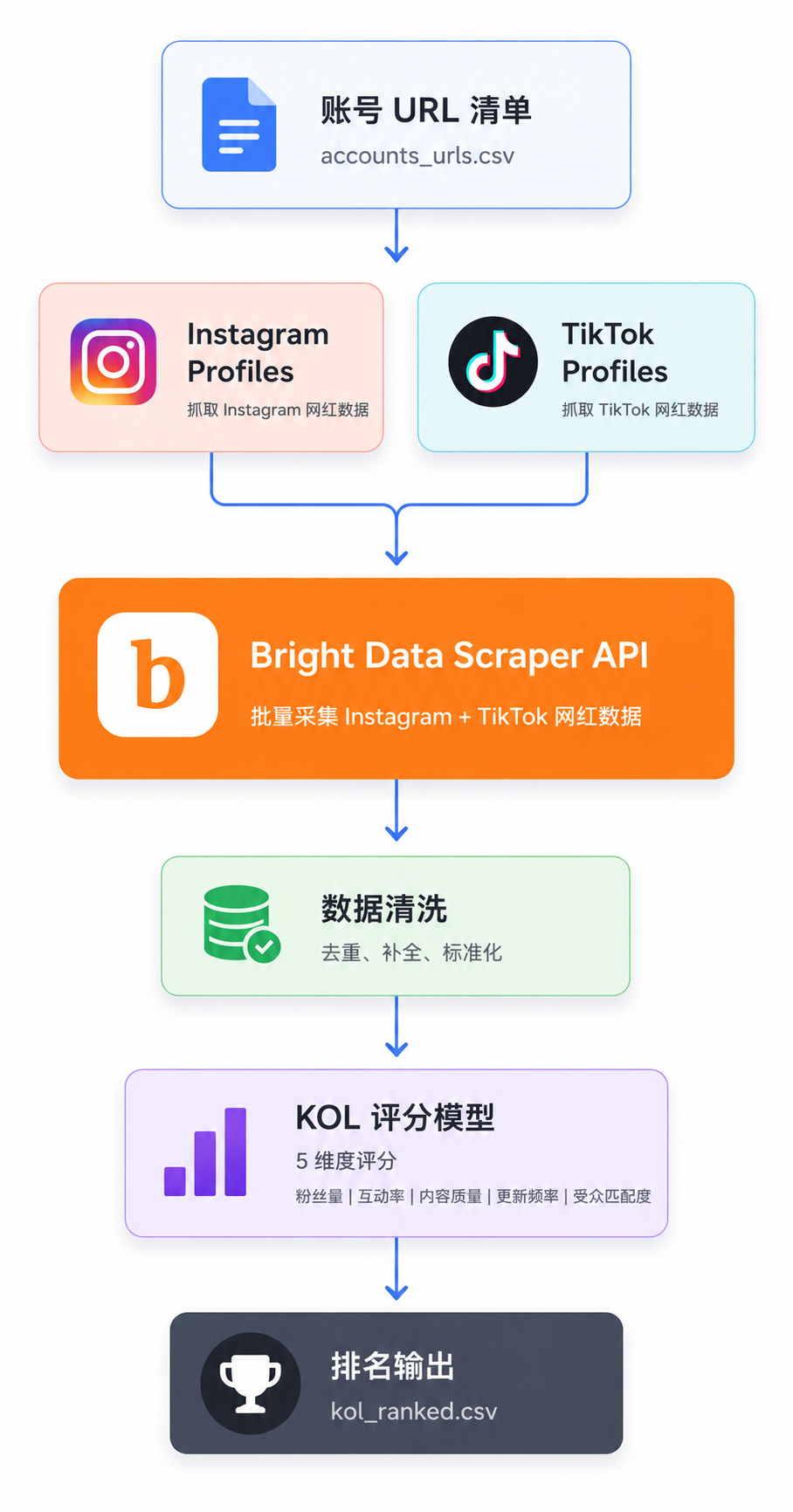
一句话:账号清单丢给 Bright Data → 结构化 JSON 扛回来 → 清洗 + 评分 → 排名 CSV。
plain
账号 URL 清单
│
▼
Bright Data Scraper API ──► Instagram Profiles (gd_l1vikfch901nx3by4)
└─► TikTok Profiles (gd_l1villgoiiidt09ci)
│
▼
数据清洗(去重、字段对齐、单位归一)
│
▼
KOL 评分模型(5 维度,权重可调)
│
▼
排名输出 ──► kol_ranked.csv / Google Sheets中间这段是关键------Bright Data 的数据采集基础设施帮助处理复杂网页采集中的访问限制、动态内容和数据获取流程,让团队无需自行维护代理池和采集基础设施。你不用养代理池、不用逆向 X-Gorgon、不用每次平台改版修代码。我们只关心"拿到数据后怎么用"。
整条管道拆成四段,每段一个 Python 脚本,互不依赖、单独跑也行:
| 脚本 | 干啥 | 输入 | 输出 |
|---|---|---|---|
instagram_profile_scraper.py |
调 IG Scraper API 抓博主资料 | inputs/urls_instagram.txt |
outputs/ig_profiles.csv |
tiktok_creator_scraper.py |
调 TikTok Scraper API 抓创作者资料 | inputs/urls_tiktok.txt |
outputs/tt_profiles.csv |
merge_profiles.py |
两平台字段对齐 + 补默认值 | 上面两个 CSV | outputs/merged_profiles.csv |
export_to_sheets.py |
套评分模型 + 排名导出 | merged_profiles.csv |
outputs/kol_ranked.csv |
数据流是单向的------前一段的 CSV 是下一段的输入,但脚本本身不强制顺序:只想抓 TikTok 就只跑第 2 个,前面没产出 ig_profiles.csv 也不影响 merge_profiles.py 跳过 IG 直接合并 TikTok 那一份。后面第三、四、五章会逐段展开实现,先把架构和分工记清楚。
2.2 开发环境与账号准备
开始前准备:
如果你还没有 Bright Data 账号,可以先创建账号获取 API Token。免费额度足够完成小规模 KOL 数据测试。
Bright Data 官网:【一键直达】
- Bright Data 账号 :官网注册,新账号会免费信用额度,可以体验跑一下 KOL 数据。
- API Token :登录后台 → User Settings → API Token → 复制。下文统一用
YOUR_BRIGHTDATA_API_KEY占位。(每个控制面板用户都可以拥有一个分配给他的 API 密钥。第一个 API 密钥会自动为创建账户的用户生成。具有管理员权限的用户无法以明文形式查看自己的 API 密钥)
- Python 3.9+ :能跑
python命令就行。
- 目标账号清单:至少 10--20 个 Instagram/TikTok 账号 URL(也可以先根据关键字抓取内容,在抓取目标账号主页)。
环境变量**(选择自己的API Token)**:
plain
# macOS / Linux
export BRIGHTDATA_TOKEN=YOUR_BRIGHTDATA_API_KEY
plain
# Windows PowerShell
$env:BRIGHTDATA_TOKEN="YOUR_BRIGHTDATA_API_KEY"三、Instagram 博主数据采集实战
3.1 Instagram Scraper API 接入说明
Instagram Scraper API 给 IG 准备了好几个 dataset,出海筛 KOL 最常用 Profiles 端点,dataset_id 是 gd_l1vikfch901nx3by4。接口要点:
- 同步模式:单次最多 20 个 URL,请求即返回,适合小批量快速验证
- 异步模式 (
/trigger端点):单次最多 5000 条,返回snapshot_id后轮询,适合大批量生产 - 请求体 :JSON 包成
{"input": [{"url": "...", "country": ""}]}格式,country留空走默认区域 - 计费:按成功返回的 record 数计费,失败不计费
- 同步转异步 :同步接口硬上限 60 秒,超时后不报错但响应体变成
{snapshot_id, message}占位符,要拿 snapshot_id 轮询/progress/{id}直到ready再下数据。Repo 脚本已经内置自动轮询逻辑,命令行只会看到状态打印,不用手动调接口
实测提示 :不同 dataset 的 payload schema 不一样------country 字段在 TikTok dataset 上能传,在 IG dataset 上直接被拒(返回 400 + This input should not contain a country field)。Repo 里两个 scraper 各自适配了对应 schema。报错时记得打印响应体,Bright Data 的错误信息写得很清楚,但 raise_for_status() 默认会把它吞掉,所以脚本里加了 if not resp.ok: print(resp.text) 兜底。
3.2 Python 批量采集脚本实现
plain
# instagram_profile_scraper.py
"""
Instagram Profiles Scraper
==========================
调用 Bright Data Instagram Scraper API 抓取账号资料。
同步接口单次最多 20 个 URL,超过走异步 /trigger。
"""
import os
import sys
import json
import time
from pathlib import Path
import requests
import pandas as pd
from dotenv import load_dotenv
# 自动找项目根目录的 .env 文件加载 BRIGHTDATA_TOKEN
# .env 文件需手动创建(参考 .env.example),不要把 token 写进代码
load_dotenv(Path(__file__).resolve().parent.parent / ".env")
# 项目根目录,用于解析 inputs/ 和 outputs/ 路径
PROJECT_ROOT = Path(__file__).resolve().parent.parent
API_TOKEN = os.environ.get("BRIGHTDATA_TOKEN")
if not API_TOKEN:
sys.exit("ERROR: 请先在 kol-pipeline/.env 文件里配置 BRIGHTDATA_TOKEN(参考 .env.example)")
IG_DATASET_ID = "gd_l1vikfch901nx3by4"
API_URL = "https://api.brightdata.com/datasets/v3/scrape"
def _parse_response(resp):
"""解析响应,兼容 JSON 数组和 NDJSON 两种格式。"""
try:
data = resp.json()
if not isinstance(data, list):
data = [data]
except ValueError:
data = [json.loads(line) for line in resp.text.splitlines() if line.strip()]
return data
def _wait_for_snapshot(snapshot_id, headers, timeout=300, interval=5):
"""同步请求超过 60 秒会被自动转异步,返回 snapshot_id 占位符。
拿 snapshot_id 轮询进度,ready 后下载结果。
"""
progress_url = f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}"
download_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}"
deadline = time.time() + timeout
print(f" 请求被自动转异步,snapshot_id={snapshot_id},开始轮询进度...")
while time.time() < deadline:
prog = requests.get(progress_url, headers=headers, timeout=30).json()
status = prog.get("status", "unknown")
print(f" → 状态: {status}")
if status == "ready":
dl = requests.get(download_url, headers=headers,
params={"format": "json"}, timeout=120)
dl.raise_for_status()
return _parse_response(dl)
if status == "failed":
raise RuntimeError(f"Snapshot 抓取失败: {prog}")
time.sleep(interval)
raise TimeoutError(f"等待 snapshot 超时({timeout}s)")
def scrape_instagram_profiles(urls):
"""同步批量抓取 Instagram 账号资料,超过 60 秒自动轮询 snapshot。"""
if len(urls) > 20:
sys.exit(f"ERROR: 同步接口单次最多 20 个 URL,当前 {len(urls)} 个,请改用异步 /trigger")
headers = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
# IG dataset 的 payload schema 比 TikTok 严格:不接受 country 字段
payload = {"input": [{"url": u} for u in urls]}
resp = requests.post(
API_URL,
params={
"dataset_id": IG_DATASET_ID,
"notify": "false",
"include_errors": "true",
},
headers=headers,
json=payload,
timeout=120,
)
if not resp.ok:
# 默认 raise_for_status() 会吞掉响应体,主动打印方便定位 400/422 错误
print(f"\n Bright Data API 返回 {resp.status_code}:")
print(f" {resp.text[:2000]}\n")
resp.raise_for_status()
data = _parse_response(resp)
# 检测异步占位响应:返回里只有 snapshot_id 和 message,没有业务字段
if (data and isinstance(data[0], dict)
and "snapshot_id" in data[0] and "message" in data[0]):
data = _wait_for_snapshot(data[0]["snapshot_id"], headers)
df = pd.DataFrame(data)
keep = ["user_name", "full_name", "biography", "followers",
"following", "posts_count", "is_verified", "url"]
return df[[c for c in keep if c in df.columns]]
def load_urls(path):
with open(path, encoding="utf-8") as f:
return [line.strip() for line in f if line.strip() and not line.startswith("#")]
if __name__ == "__main__":
default_urls = PROJECT_ROOT / "inputs" / "urls_instagram.txt"
urls_file = sys.argv[1] if len(sys.argv) > 1 else default_urls
urls = load_urls(urls_file)
print(f"准备抓 {len(urls)} 个 Instagram 账号...")
df = scrape_instagram_profiles(urls)
output_path = PROJECT_ROOT / "outputs" / "ig_profiles.csv"
os.makedirs(output_path.parent, exist_ok=True)
df.to_csv(output_path, index=False, encoding="utf-8-sig")
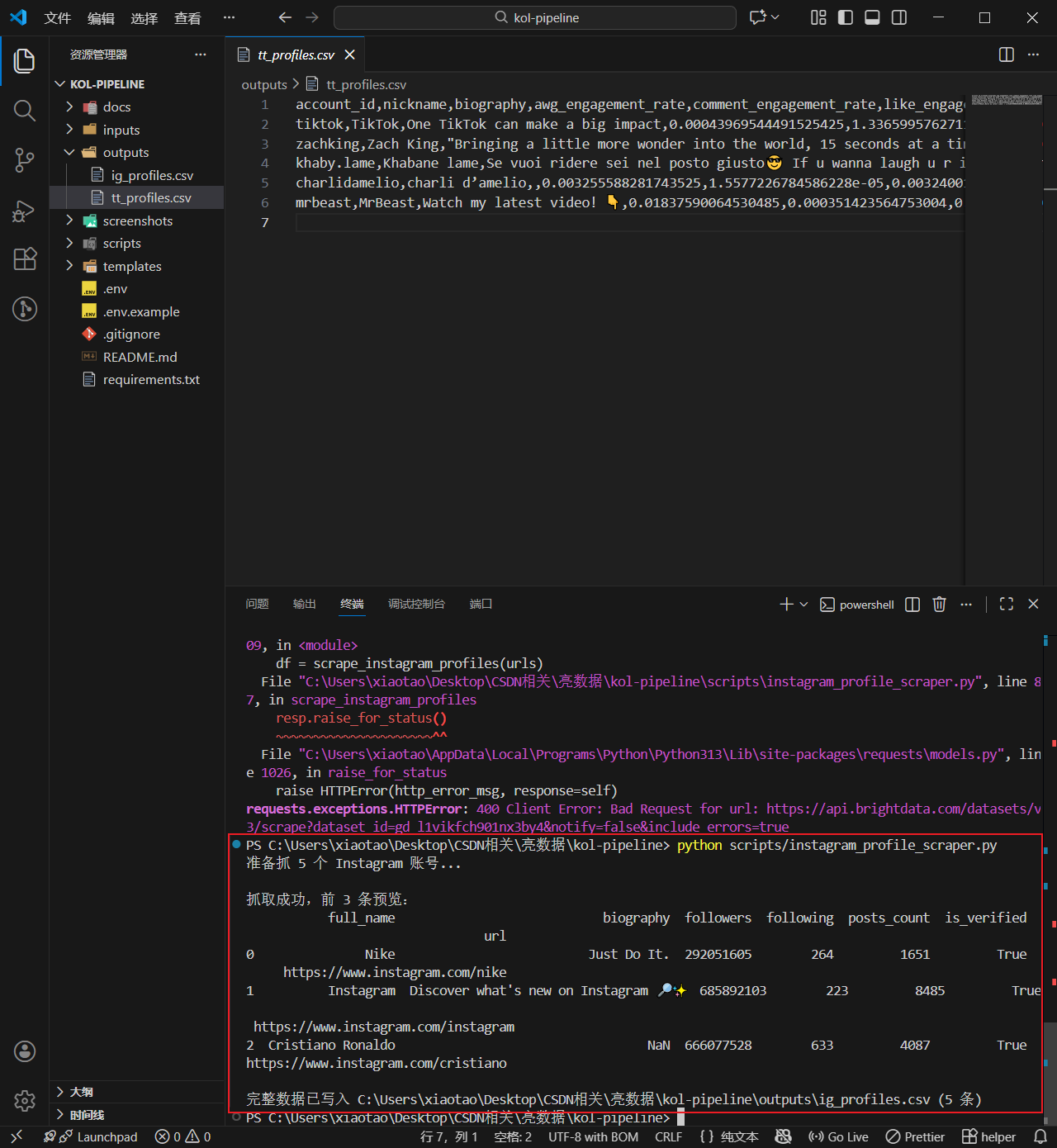
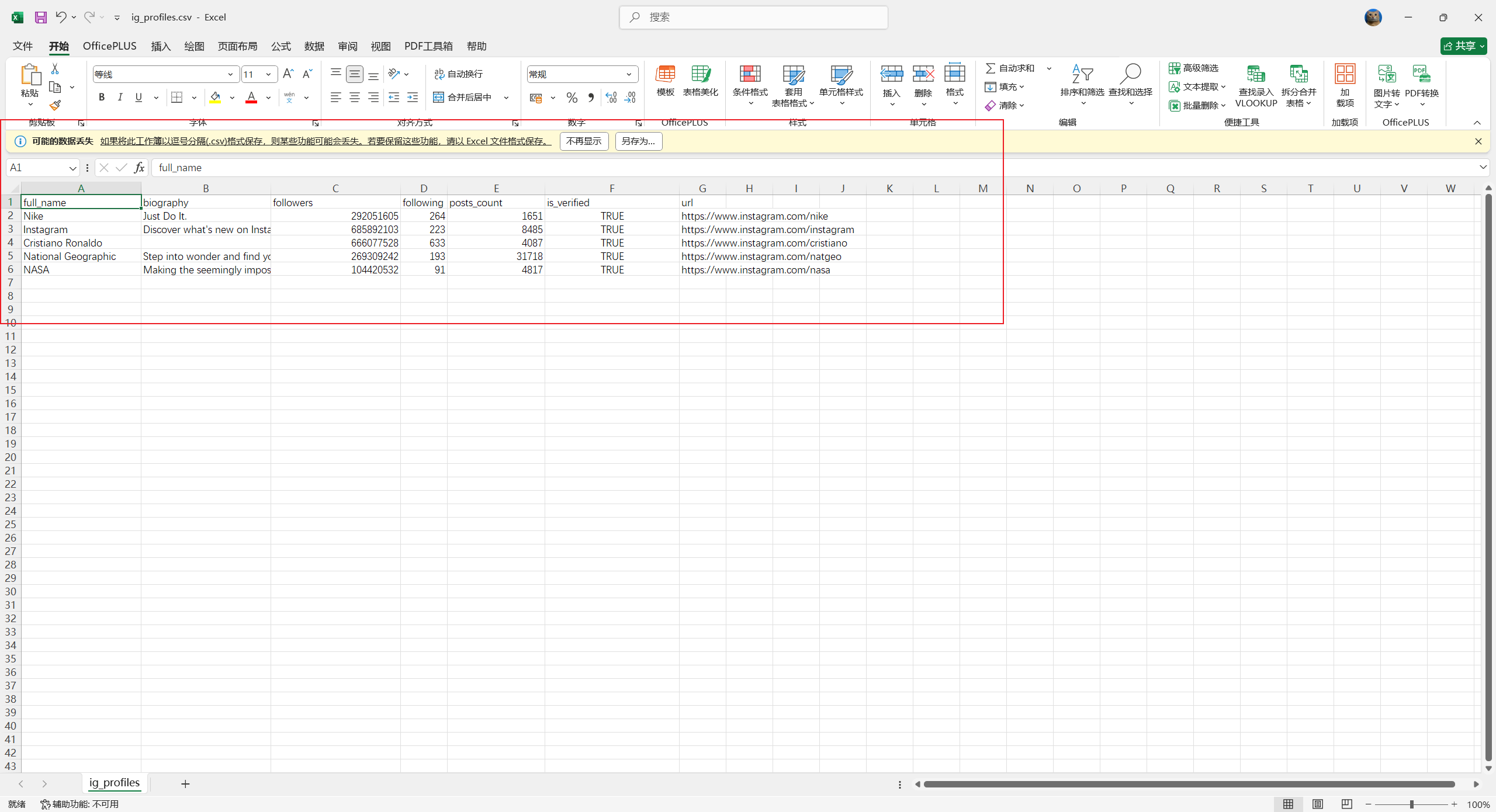
print("\n抓取成功,前 3 条预览:")
print(df.head(3).to_string())
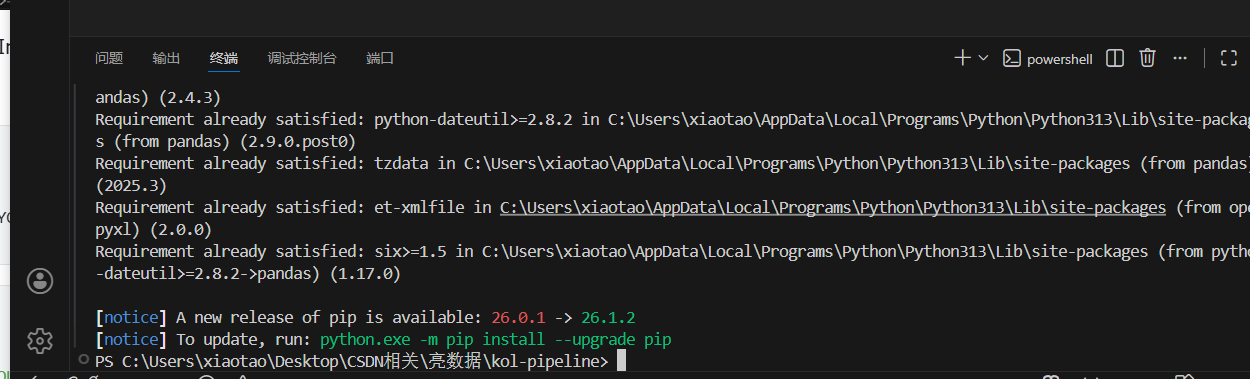
print(f"\n完整数据已写入 {output_path} ({len(df)} 条)")3.3 返回字段与数据结构
跑完拿到这种结构(字段已 Bright Data 清洗过):
plain
{
"user_name": "instagram",
"full_name": "Instagram",
"biography": "Discover what's next. ✨",
"followers": 676000000,
"following": 500,
"posts_count": 7800,
"is_verified": true,
"url": "https://www.instagram.com/instagram"
}字段对应到 KOL 评分维度:followers 是基础规模、posts_count 算发文频率、is_verified 加分粉丝质量、biography 用来文本分析内容方向。
四、TikTok 创作者数据采集实战
4.1 TikTok Scraper API 接入说明
TikTok Scraper API 的 dataset_id 是 gd_l1villgoiiidt09ci,调用方式跟 Instagram 完全一致------同样的 endpoint、同样的 payload 格式、同样的 Bearer 鉴权。区别在返回字段:除了基础资料,TikTok 还带 likes(累计点赞)、videos_count、is_verified,方便直接算"累计互动 ÷ 视频数 = 平均互动"。
接口要点:
- 单次同步最多 20 个 URL,超过走异步
/trigger - 字段比 IG 多
likes和videos_count,可估算账号累计互动密度 - 要拿带货痕迹、平均播放量、近期发文频率,需要叠加 Posts 端点请求(见 4.3)
实测提示 :5 个 TikTok URL 抓取平均会超 60 秒,几乎每次都会触发"同步转异步"------响应不是数据,是 {snapshot_id, message} 占位符。Repo 脚本里的 _wait_for_snapshot 函数自动处理这套流程,你跑命令只会看到 5 秒一次的状态打印:
plain
请求被自动转异步,snapshot_id=sd_xxx,开始轮询进度...
→ 状态: running
→ 状态: ready不用管它,等 ready 就自动下数据写 CSV。snapshot 结果保留 16 天,建议拿到立刻消费,超期会自动清理。
4.2 Python 批量采集脚本实现
plain
# tiktok_creator_scraper.py
"""
TikTok Profiles Scraper
=======================
调用 Bright Data TikTok Scraper API 抓取创作者资料。
同步接口单次最多 20 个 URL。
"""
import os
import sys
import json
import time
from pathlib import Path
import requests
import pandas as pd
from dotenv import load_dotenv
# 自动找项目根目录的 .env 文件加载 BRIGHTDATA_TOKEN
load_dotenv(Path(__file__).resolve().parent.parent / ".env")
# 项目根目录(scripts/ 的父目录),用于解析 inputs/ 和 outputs/ 路径
PROJECT_ROOT = Path(__file__).resolve().parent.parent
API_TOKEN = os.environ.get("BRIGHTDATA_TOKEN")
if not API_TOKEN:
sys.exit("ERROR: 请先在 kol-pipeline/.env 文件里配置 BRIGHTDATA_TOKEN(参考 .env.example)")
TT_DATASET_ID = "gd_l1villgoiiidt09ci"
API_URL = "https://api.brightdata.com/datasets/v3/scrape"
def _parse_response(resp):
"""解析响应,兼容 JSON 数组和 NDJSON 两种格式。"""
try:
data = resp.json()
if not isinstance(data, list):
data = [data]
except ValueError:
data = [json.loads(line) for line in resp.text.splitlines() if line.strip()]
return data
def _wait_for_snapshot(snapshot_id, headers, timeout=300, interval=5):
"""同步请求超过 60 秒会被自动转异步,返回 snapshot_id 占位符。
拿 snapshot_id 轮询进度,ready 后下载结果。
"""
progress_url = f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}"
download_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}"
deadline = time.time() + timeout
print(f" 请求被自动转异步,snapshot_id={snapshot_id},开始轮询进度...")
while time.time() < deadline:
prog = requests.get(progress_url, headers=headers, timeout=30).json()
status = prog.get("status", "unknown")
print(f" → 状态: {status}")
if status == "ready":
dl = requests.get(download_url, headers=headers,
params={"format": "json"}, timeout=120)
dl.raise_for_status()
return _parse_response(dl)
if status == "failed":
raise RuntimeError(f"Snapshot 抓取失败: {prog}")
time.sleep(interval)
raise TimeoutError(f"等待 snapshot 超时({timeout}s)")
def scrape_tiktok_profiles(urls):
"""同步批量抓取 TikTok 创作者资料,超过 60 秒自动轮询 snapshot。"""
if len(urls) > 20:
sys.exit(f"ERROR: 同步接口单次最多 20 个 URL,当前 {len(urls)} 个")
headers = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
# TikTok dataset 接受 country 字段(IG dataset 不接受,见 3.2 节)
payload = {"input": [{"url": u, "country": ""} for u in urls]}
resp = requests.post(
API_URL,
params={
"dataset_id": TT_DATASET_ID,
"notify": "false",
"include_errors": "true",
},
headers=headers,
json=payload,
timeout=120,
)
if not resp.ok:
print(f"\n Bright Data API 返回 {resp.status_code}:")
print(f" {resp.text[:2000]}\n")
resp.raise_for_status()
data = _parse_response(resp)
# 检测异步占位响应:返回里只有 snapshot_id 和 message,没有业务字段
if (data and isinstance(data[0], dict)
and "snapshot_id" in data[0] and "message" in data[0]):
data = _wait_for_snapshot(data[0]["snapshot_id"], headers)
return pd.DataFrame(data)
def load_urls(path):
with open(path, encoding="utf-8") as f:
return [line.strip() for line in f if line.strip() and not line.startswith("#")]
if __name__ == "__main__":
default_urls = PROJECT_ROOT / "inputs" / "urls_tiktok.txt"
urls_file = sys.argv[1] if len(sys.argv) > 1 else default_urls
urls = load_urls(urls_file)
print(f"准备抓 {len(urls)} 个 TikTok 账号...")
df = scrape_tiktok_profiles(urls)
output_path = PROJECT_ROOT / "outputs" / "tt_profiles.csv"
os.makedirs(output_path.parent, exist_ok=True)
df.to_csv(output_path, index=False, encoding="utf-8-sig")
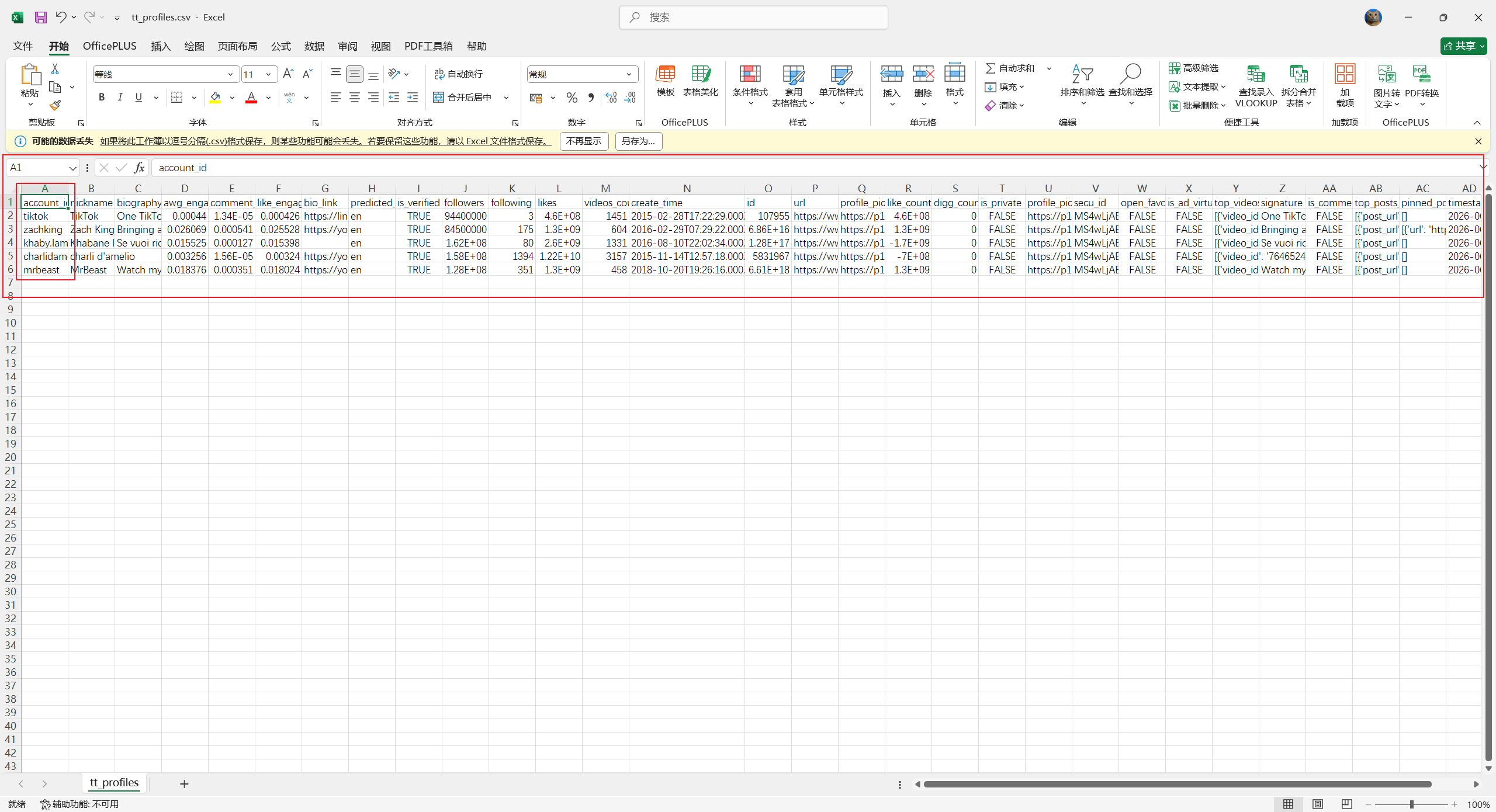
keep_cols = [c for c in ["nickname", "account_id", "followers",
"likes", "videos_count", "is_verified"]
if c in df.columns]
print("\n抓取成功,前 3 条预览:")
print(df[keep_cols].head(3).to_string())
print(f"\n完整数据已写入 {output_path} ({len(df)} 条)")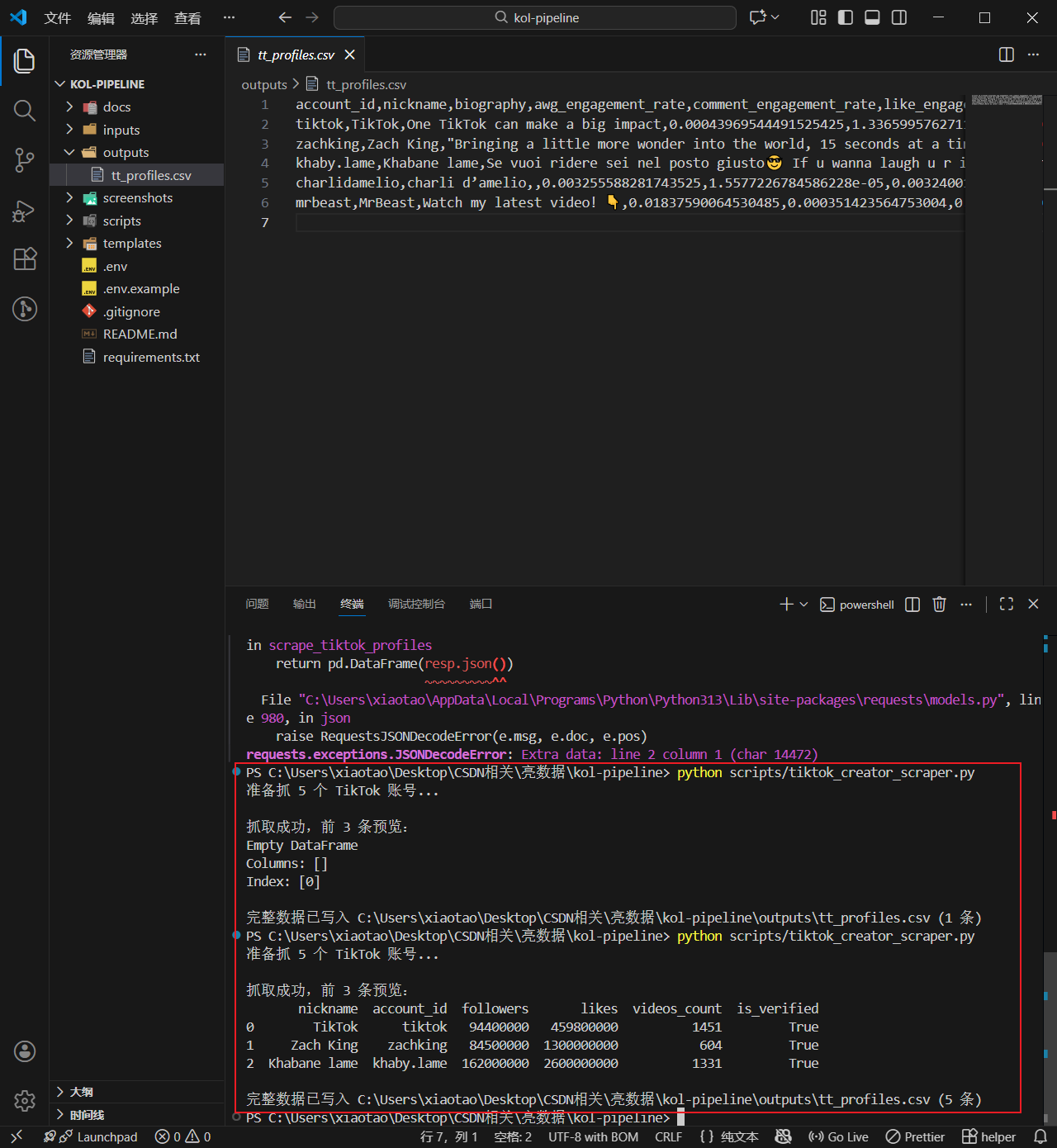
下一步:
已经拿到账号数据?
使用 Bright Data** 数据接口**继续扩展 Posts 数据,分析互动率、内容趋势和商业化潜力。
4.3 扩展端点:抓 Posts 数据补全互动指标
Profiles 端点只返回账号级聚合数据。要拿平均播放量、近期发文频率、带货频率这些精细化指标,需要再调一次 TikTok Posts 端点(按账号主页 URL 抓最近 N 条视频)。Posts 返回字段包括 play_count(单视频播放)、digg_count(点赞)、comment_count、share_count、commerce_info(带货痕迹)、tagged_user(合作品牌)。聚合后能算出平均播放量、平均互动率、带货频率(commerce_info 非空比例)、近 30 天发文数等指标。
另外还有 Discover by keyword 模式(dataset_id gd_lu702nij2f790tmv9h,多带 type=discover_new&discover_by=keyword 两个参数,payload 用 search_keyword 字段),输入 #makeup``#skincare 能反查潜在 KOL------这是"找人阶段"的核心能力,可以直接把关键词搜出来的创作者 URL 列表喂给 Profiles 端点做评估。完整 Posts 采集 + 关键词发现代码在 GitHub Repo,文章篇幅原因不展开。
已经拿到账号数据?
使用 Bright Data 数据接口继续扩展 Posts 数据,分析互动率、内容趋势和商业化潜力。
五、KOL 评分模型与排名输出
5.1 数据合并与字段对齐
抓完 IG 和 TikTok 数据后,两份 CSV 还不能直接喂给评分模型------两个平台的字段命名差异很大,必须先做归一化:
| 含义 | IG 字段 | TikTok 字段 | 评分模型期望字段 |
|---|---|---|---|
| 账号标识 | (从 URL 提取) | account_id |
username |
| 显示名 | full_name |
nickname |
display_name |
| 累计点赞 | --- | likes |
avg_likes(按视频数摊算) |
| 视频数 | --- | videos_count |
--- |
| 帖子数 | posts_count |
--- | --- |
| 是否认证 | is_verified |
is_verified |
is_verified |
merge_profiles.py 的工作就是把这两套字段对齐到统一格式,输出 merged_profiles.csv 作为评分模型的输入。脚本本身不强依赖两个 CSV 都存在------只有 IG 就只合并 IG,只有 TikTok 就只合并 TikTok,方便分阶段验证。
plain
# merge_profiles.py
"""
Merge Profiles
==============
把 Instagram 和 TikTok 的原始数据合并、字段对齐,
补齐 KOL 评分模型需要的输入字段。
"""
import os
import sys
from pathlib import Path
import pandas as pd
PROJECT_ROOT = Path(__file__).resolve().parent.parent
def normalize(df, platform):
"""把不同平台的字段名归一化。"""
df = df.copy()
df["platform"] = platform
# username 归一化:优先用接口直接给的字段,没有就从 URL 末段提取
# (IG 接口不返回 user_name,URL 末段是唯一来源)
if "user_name" in df.columns and df["user_name"].notna().any():
df["username"] = df["user_name"]
elif "account_id" in df.columns:
df["username"] = df["account_id"]
elif "url" in df.columns:
# https://www.instagram.com/nike → nike;https://www.tiktok.com/@tiktok → @tiktok
df["username"] = (df["url"].astype(str)
.str.rstrip("/")
.str.rsplit("/", n=1).str[-1])
df["display_name"] = df.get("full_name", df.get("nickname", ""))
# 平均互动数据:TikTok 的 likes 是累计点赞,按视频数摊到单条
# 真实业务场景下,建议再调 Posts 端点拿最近 30 条视频的真实均值
if "avg_likes" not in df.columns:
# 分母优先用 videos_count(TikTok),其次 posts_count(IG),都没有就当 1
if "videos_count" in df.columns:
denom = df["videos_count"].fillna(1).clip(lower=1).astype(int)
elif "posts_count" in df.columns:
denom = df["posts_count"].fillna(1).clip(lower=1).astype(int)
else:
denom = 1
likes = df["likes"] if "likes" in df.columns else 0
df["avg_likes"] = likes / denom
df["avg_comments"] = df.get("avg_comments", 0)
df["avg_shares"] = df.get("avg_shares", 0)
df["posts_per_week"] = df.get("posts_per_week", 7)
df["recent_posts_30d"] = df.get("recent_posts_30d", 30)
df["geo_tier"] = df.get("geo_tier", "english")
df["has_shop_link"] = df.get("has_shop_link", False)
keep = ["platform", "username", "display_name", "followers", "following",
"posts_count", "videos_count", "is_verified", "url",
"avg_likes", "avg_comments", "avg_shares",
"posts_per_week", "recent_posts_30d", "geo_tier", "has_shop_link"]
return df[[c for c in keep if c in df.columns]]
def merge(ig_path=None,
tt_path=None,
out_path=None):
ig_path = ig_path or PROJECT_ROOT / "outputs" / "ig_profiles.csv"
tt_path = tt_path or PROJECT_ROOT / "outputs" / "tt_profiles.csv"
out_path = out_path or PROJECT_ROOT / "outputs" / "merged_profiles.csv"
frames = []
if os.path.exists(ig_path):
frames.append(normalize(pd.read_csv(ig_path), "instagram"))
print(f" ✓ 读到 Instagram 数据:{ig_path}")
else:
print(f" ⚠ 跳过 Instagram(文件不存在):{ig_path}")
if os.path.exists(tt_path):
frames.append(normalize(pd.read_csv(tt_path), "tiktok"))
print(f" ✓ 读到 TikTok 数据:{tt_path}")
else:
print(f" ⚠ 跳过 TikTok(文件不存在):{tt_path}")
if not frames:
raise SystemExit("ERROR: outputs/ 下既没有 ig_profiles.csv 也没有 tt_profiles.csv,先跑至少一个采集脚本")
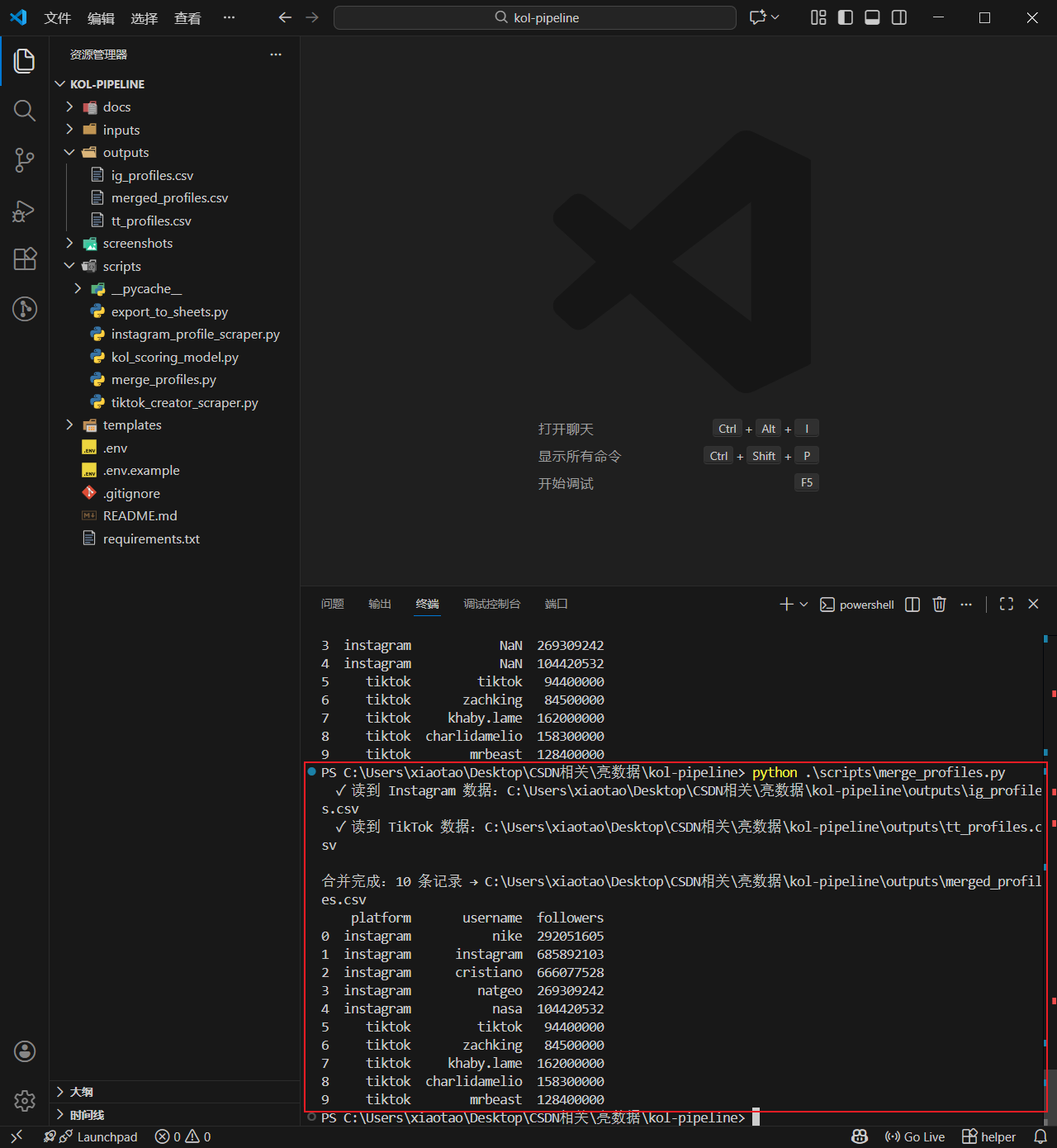
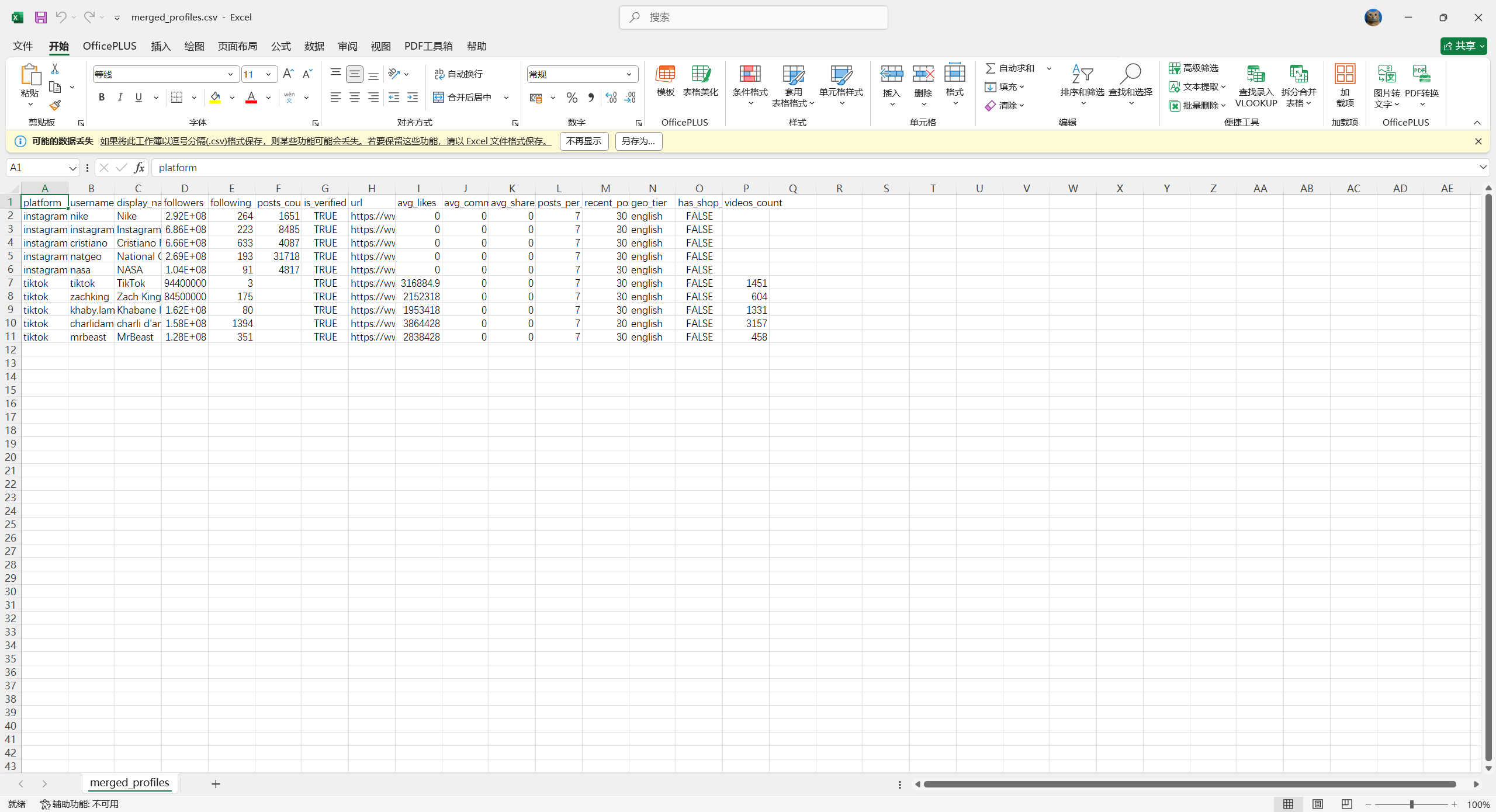
merged = pd.concat(frames, ignore_index=True)
os.makedirs(os.path.dirname(out_path), exist_ok=True)
merged.to_csv(out_path, index=False, encoding="utf-8-sig")
print(f"\n合并完成:{len(merged)} 条记录 → {out_path}")
print(merged[["platform", "username", "followers"]].to_string())
return merged
if __name__ == "__main__":
merge()踩坑提示 :Bright Data IG 接口不直接返回 user_name 字段(只给 full_name),所以脚本里写了三层 fallback------优先用 user_name → 其次用 account_id → 最后从 URL 末段提取(https://www.instagram.com/nike → nike)。这种"字段名漂移"在跨平台爬虫里非常常见,解析代码必须有 fallback 链,否则一上线就掉数据。
跑完 merge 会输出 merged_profiles.csv,IG + TikTok 数据合在一张表里,platform 列区分来源:
5.2 五维度评分体系设计
数据拿回来只是起点。真正决定能不能"挑对人"的是评分模型------这就是出海 kol 数据分析跟"随便看看粉丝数"最大的区别。下面这 5 个维度组合,对海外网红筛选最实用:
| 维度 | 默认权重 | 计算逻辑 |
|---|---|---|
| 互动率 | 30% | (平均点赞+评论+分享) / 粉丝数 |
| 粉丝质量 | 20% | 认证 + 合理发帖频率 |
| 内容活跃度 | 20% | 近 30 天发文数 / 12 |
| 地区匹配 | 15% | 目标市场 / 英语圈 / 其他 |
| 商业化潜力 | 15% | 是否有 TikTok Shop 挂车 |
权重设计逻辑:互动率权重最高,因为它是判断"粉丝真假"最直接的指标------百万粉账号互动率 <1% 基本是僵尸粉或买量号。粉丝质量排第二,认证 + 合理发帖频率往往意味着 MCN 在背后运营。活跃度排第三,过滤沉睡账号------老账号粉丝几百万但半年不发内容,合作了等于白花钱。地区匹配放第四,因为可以通过"组合查询"提前过滤。商业化垫底但不是不重要------同分时优先选有挂车历史的博主。
templates/kol_scoring_weights.csv 把权重做成可调参数,建议跑过 50--100 个账号后看分布再调。
5.3 评分模型 Python 实现
plain
# kol_scoring_model.py
"""
KOL Scoring Model
=================
基于互动率、粉丝质量、活跃度、地区匹配、商业化潜力的 5 维度评分。
权重可在 templates/kol_scoring_weights.csv 里调整。
"""
import pandas as pd
DEFAULT_WEIGHTS = {
"engagement": 0.30,
"quality": 0.20,
"activity": 0.20,
"geo": 0.15,
"commerce": 0.15,
}
def load_weights(path="templates/kol_scoring_weights.csv"):
"""从 CSV 读取权重,文件不存在则用默认值。"""
try:
w_df = pd.read_csv(path)
return {row["dimension"]: row["weight"] for _, row in w_df.iterrows()}
except FileNotFoundError:
return DEFAULT_WEIGHTS
def compute_engagement_rate(row):
"""互动率 = (点赞+评论+分享) / 粉丝数 × 100%"""
if row["followers"] == 0:
return 0.0
inter = (row.get("avg_likes", 0)
+ row.get("avg_comments", 0)
+ row.get("avg_shares", 0))
return round(inter / row["followers"] * 100, 2)
def score_one(row, weights=None):
w = weights or DEFAULT_WEIGHTS
er_score = min(row["engagement_rate"] / 5.0 * 100, 100)
quality = 50
if row.get("is_verified"):
quality += 30
if 5 <= row.get("posts_per_week", 0) <= 20:
quality += 20
activity = min(row.get("recent_posts_30d", 0) / 12 * 100, 100)
geo_map = {"target": 100, "english": 60, "other": 30}
geo = geo_map.get(row.get("geo_tier", "other"), 30)
commerce = 100 if row.get("has_shop_link") else 50
total = (
er_score * w["engagement"]
+ quality * w["quality"]
+ activity * w["activity"]
+ geo * w["geo"]
+ commerce * w["commerce"]
)
return round(total, 1)
def rank_kols(df, weights=None):
df = df.copy()
df["engagement_rate"] = df.apply(compute_engagement_rate, axis=1)
df["kol_score"] = df.apply(lambda r: score_one(r, weights), axis=1)
return df.sort_values("kol_score", ascending=False).reset_index(drop=True)
if __name__ == "__main__":
df = pd.read_csv("outputs/merged_profiles.csv")
ranked = rank_kols(df)
print(ranked[["platform", "username", "followers",
"engagement_rate", "kol_score"]].to_string())
plain
# export_to_sheets.py
"""
Export Ranked KOLs
==================
读取合并后的数据,跑评分模型,导出排名 CSV。
需要先跑过 instagram_profile_scraper.py + tiktok_creator_scraper.py + merge_profiles.py。
"""
import os
import sys
from pathlib import Path
import pandas as pd
from kol_scoring_model import rank_kols, load_weights
PROJECT_ROOT = Path(__file__).resolve().parent.parent
def export_ranked(input_csv=None,
output_csv=None,
weights_path=None):
input_csv = input_csv or PROJECT_ROOT / "outputs" / "merged_profiles.csv"
output_csv = output_csv or PROJECT_ROOT / "outputs" / "kol_ranked.csv"
weights_path = weights_path or PROJECT_ROOT / "templates" / "kol_scoring_weights.csv"
if not os.path.exists(input_csv):
sys.exit(f"ERROR: 找不到 {input_csv},请先跑 merge_profiles.py")
df = pd.read_csv(input_csv)
weights = load_weights(weights_path)
print(f"使用权重:{weights}")
ranked = rank_kols(df, weights)
os.makedirs(os.path.dirname(output_csv), exist_ok=True)
ranked.to_csv(output_csv, index=False, encoding="utf-8-sig")
print(f"\n已导出 {len(ranked)} 位 KOL 排名到 {output_csv}")
print("\nTop 10:")
show_cols = [c for c in ["platform", "username", "followers",
"engagement_rate", "kol_score"]
if c in ranked.columns]
print(ranked[show_cols].head(10).to_string())
if __name__ == "__main__":
input_csv = sys.argv[1] if len(sys.argv) > 1 else None
export_ranked(input_csv=input_csv)想自动化你的 KOL 筛选流程?
将Bright Data 数据接入你的评分模型,每次调整筛选条件都可以重新计算排名。
5.4 排名输出与样例解读
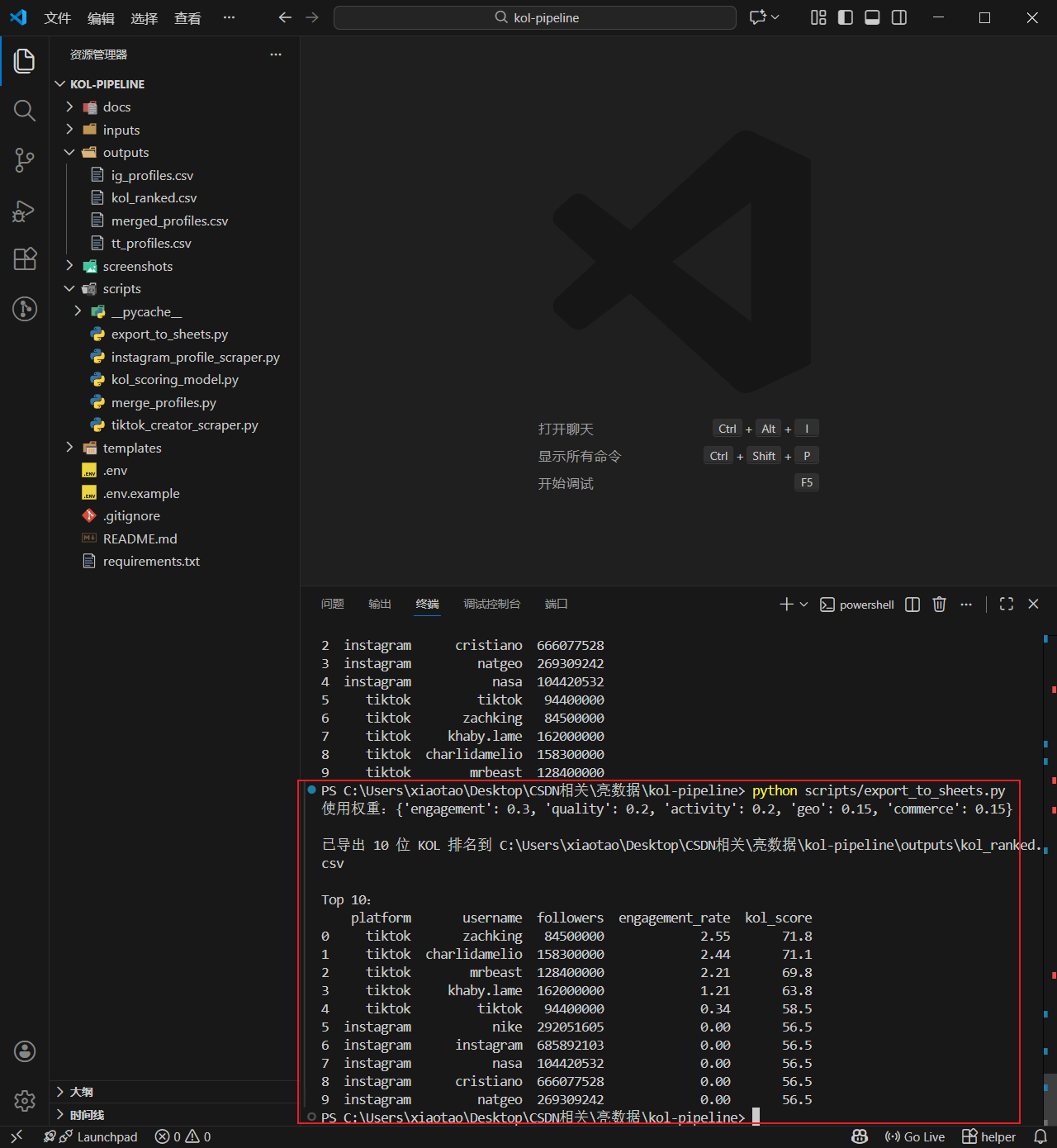
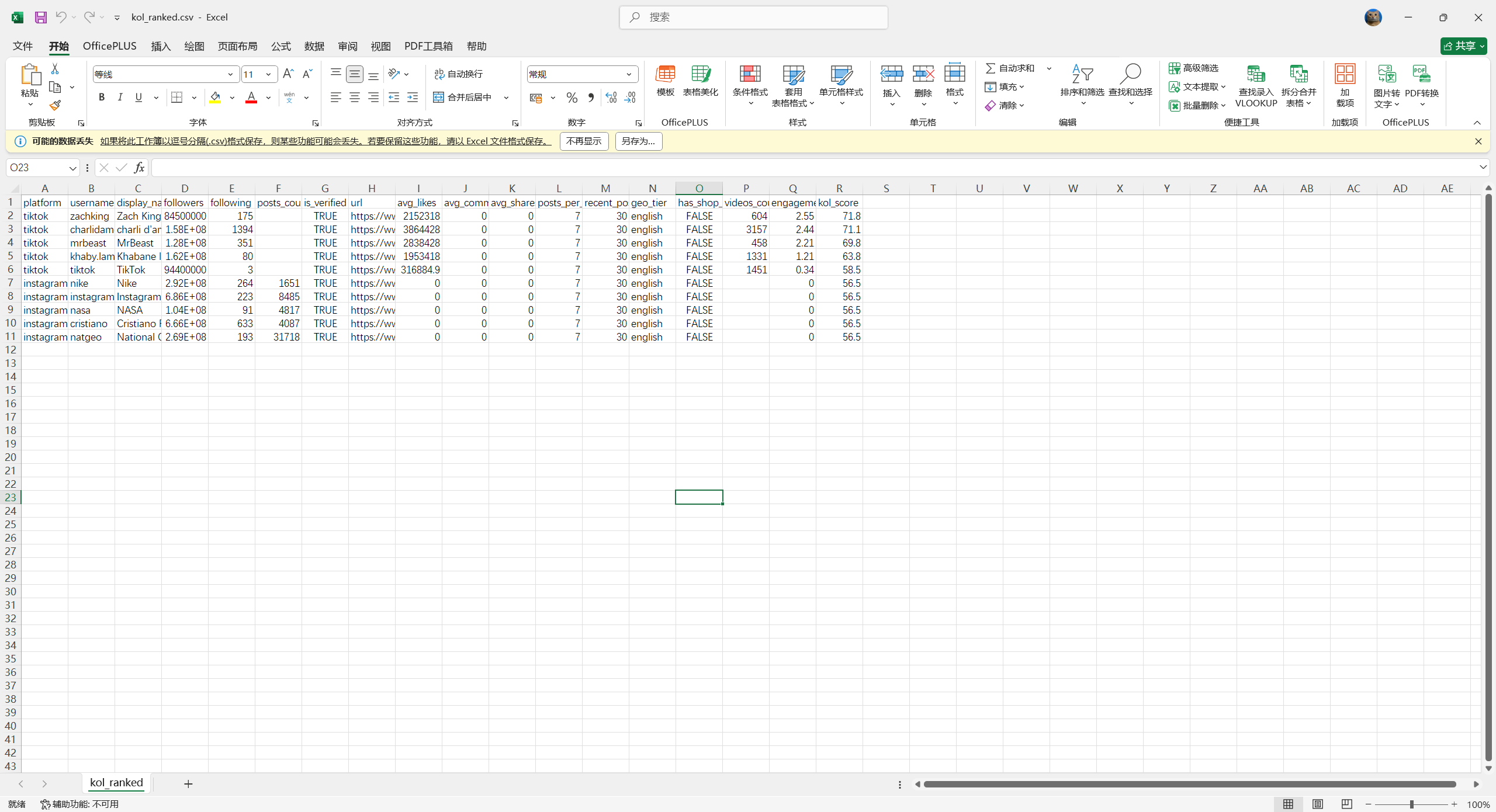
合并 IG + TikTok 数据跑一次评分,输出长这样:
plain
platform username followers engagement_rate kol_score
0 tiktok khaby.lame 162000000 4.82 87.3
1 instagram natgeo 282000000 1.94 72.6
2 tiktok <美妆博主A> 856000 6.31 88.7 ← 满分潜力股
3 tiktok <挂车博主B> 1240000 3.15 74.2
4 instagram <僵尸粉账号C> 2980000 0.42 38.1 ← 立刻剔除最后两行的对比最关键:博主 A 粉丝不到 100 万但互动率 6.31%、商业潜力满分,反而是榜单第一;账号 C 名义 298 万粉,互动率 0.42% 直接拉响警报,评分只有 38,立刻从备选池剔除。这就是为什么出海团队必须自建评分------HypeAuditor 这种订阅工具给不到这种粒度。
想快速搭建自己的海外 KOL 数据采集 pipeline?
使用 Bright Data Scraper API 获取结构化 Instagram 和 TikTok 数据,无需维护复杂采集基础设施。开始免费测试你的第一个 KOL 数据集:👉 注册 Bright Data,获取免费额度并运行你的第一批社媒数据采集任务。
六、成本分析与开源交付
6.1 单条数据成本对比
按"评估 1000 个海外 KOL"算成本:
| 方案 | 单条成本 | 1000 条总价 | 自定义字段 |
|---|---|---|---|
| HypeAuditor | 含在月费 99 99 99399 | 长期订阅,字段固定 | 几乎不能自定义 |
| 飞瓜/蝉妈妈海外版 | --- | 不支持 | --- |
| 自建 + Bright Data | 0.15 0.15 0.150.4 / record | 150 150 150400 | 完全自定义 |
Bright Data 按成功付费------请求失败不计费。实测成功率 99% 左右,比住宅代理 DIY(成功率 35--40%)高一截。加上调试时间、平台改版后修代码这些隐性成本,自建反而最便宜。
6.2 GitHub Repo 与使用指南
GitHub仓库链接:https://github.com/xtdexw/kol-pipeline
GitHub Repo 结构:
plain
kol-pipeline/
├─ scripts/
│ ├─ instagram_profile_scraper.py # 抓 Instagram
│ ├─ tiktok_creator_scraper.py # 抓 TikTok
│ ├─ merge_profiles.py # 合并 + 字段对齐
│ ├─ kol_scoring_model.py # 评分模型
│ └─ export_to_sheets.py # 跑评分 + 导出
├─ inputs/
│ ├─ urls_instagram.txt # IG 账号清单
│ └─ urls_tiktok.txt # TikTok 账号清单
├─ templates/
│ └─ kol_scoring_weights.csv # 评分权重模板
├─ .env.example
└─ README.md使用三步:
- 克隆 Repo,
.env.example复制为.env,填BRIGHTDATA_TOKEN。 inputs/urls_instagram.txt和inputs/urls_tiktok.txt贴账号 URL(一行一个,单文件最多 20 个)。- 依次跑四个脚本(每个独立,可以单独跑),最终结果在
outputs/kol_ranked.csv:
plain
python scripts/instagram_profile_scraper.py # 抓 IG → ig_profiles.csv
python scripts/tiktok_creator_scraper.py # 抓 TT → tt_profiles.csv
python scripts/merge_profiles.py # 合并 → merged_profiles.csv
python scripts/export_to_sheets.py # 评分 → kol_ranked.csv没接触过 Bright Data 的同学,建议先去Bright Data 官网查看一下相关文档教程。
七、总结
这套管道跑通之后最大的价值不是"能抓数据了",是"不再被工具绑死"------以前调一个互动率阈值要给工具方提需求排队两周,现在改 weights 字典里一个数字立刻见效。出海窗口期就那么几个月,KOL 数据不能等工具排期。
适合这几类人用:
- 出海品牌的营销 / BD:要批量评估海外 KOL,订阅 HypeAuditor 一年小几万太贵
- MCN 和海外代运营:手上几十上百个达人要定期出排名
- 独立站卖家自己做 affiliate:想快速剔掉僵尸粉和水军账号
- 数据分析师 / 爬虫学习者:要用真实 API 跑一个生产级 pipeline 当练习项目
不太适合一次只筛 5--10 个达人的团队------平台内置搜索 + 手动 Excel 反而更快,这套代码的核心价值是规模化批量筛选。
跑出自己的 KOL 排行榜后,欢迎评论区把权重配置发出来,不同垂类的最佳权重组合大家可以对一对。
🚀 开始构建你的海外 KOL 数据 pipeline
使用 Bright Data 获取结构化 Instagram 和 TikTok 数据,快速验证你的达人筛选模型。
免费注册 Bright Data,立即开始测试。