一、现网问题背景(高性能交换机场景)
某数据中心100G交换机采用DPDK用户态转发架构:
- 双路Xeon服务器
- 2×100G NIC(DPDK PMD)
- 8核lcore worker
- 每端口百万级流表
- 全用户态L2/L3交换
系统稳定运行半年后,扩容业务后出现异常:
- 吞吐下降约10%~15%
- P99时延抖动明显
- micro-burst丢包偶发
- CPU始终100%
- NIC无任何error计数
表面现象极具迷惑性:
"没有错误,但性能变差"
二、第一轮排查:CPU与PMD路径
DPDK典型PMD循环:
while (1) {
nb_rx = rte_eth_rx_burst(port, queue, pkts, BURST_SIZE);
process(pkts);
rte_eth_tx_burst(port, queue, pkts, nb_tx);
}关键结论:
CPU 100% ≠ CPU瓶颈
DPDK Poll Mode Driver 本质:
- 永不sleep
- 永远busy polling
- CPU长期100%是设计行为
真正需要关注的是:
- cycles per packet
- backend stall
- cache miss
- memory/PCIe latency
三、第二轮排查:RSS与Queue
检查RSS分布:
- 各worker负载均衡
- 无明显倾斜
Queue状态:
- RX queue occupancy正常
- TX queue无积压
说明:
❌ 不是调度问题
❌ 不是RSS hash问题
❌ 不是单核热点
四、异常特征:micro-burst丢包
通过抓包发现关键现象:
| burst size | 结果 |
|---|---|
| 16 | 正常 |
| 32 | 正常 |
| 64 | 开始抖动 |
| 128 | 明显丢包 |
说明问题不在"平均负载",而在:
短时间突发链路承载能力
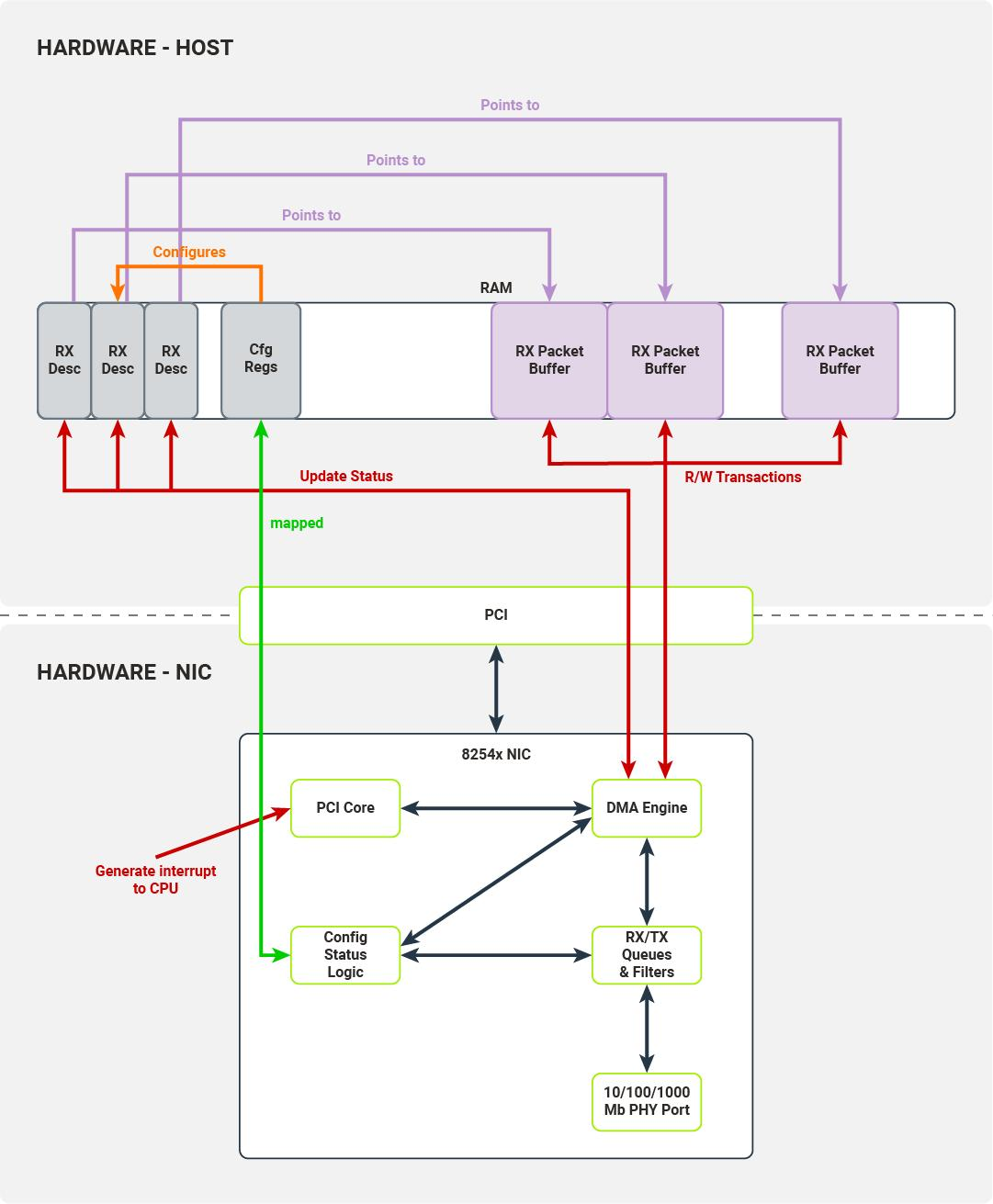
五、DPDK RX Descriptor真正作用
DPDK收包链路:
NIC
↓ DMA
RX Descriptor Ring
↓
mbuf (mempool)
↓
lcore processing关键点:
NIC并不是直接写内存,而是:
通过 descriptor 指向 buffer,由DMA完成写入
六、Descriptor生命周期(核心)
RX descriptor状态流转:
- FREE
- HW_OWNED
- DMA_WRITING
- READY
- CONSUMED
- REFILLED
关键问题发生在:
REFILLED阶段延迟
七、真正问题开始出现:descriptor回收变慢
随着业务增长:
- packet processing slightly slower
- refill延迟上升
- RX ring free descriptor下降
但系统不会报错:
DPDK不会因为descriptor慢而报错
结果:
NIC开始出现:
- RX ring压力上升
- burst丢包(micro burst)
八、PCIe DMA Completion链路分析
数据路径:
NIC DMA Write
↓
PCIe Transaction Layer
↓
Root Complex
↓
Memory Controller
↓
DDR
↓
CPU Cache关键机制:
- Posted Write(写合并)
- Completion Queue
- Write Ordering
- Read Completion延迟
九、根因关键:DMA completion回收延迟
问题本质:
descriptor释放依赖CPU消费完成
当CPU处理稍慢:
- descriptor未及时回收
- NIC RX ring逐渐耗尽
- DMA写入出现backpressure
最终结果:
NIC进入隐式限速状态
十、为什么CPU仍然100%?
这是误判核心点:
CPU一直在:
- poll RX queue
- poll TX queue
- retry empty ring
但实际上:
真正瓶颈在:
PCIe DMA completion latency
CPU并没有idle时间,但也没有推进数据流
十一、perf分析结果
perf stat -e cycles,instructions,stalled-cycles-backend结果:
- backend stall ↑↑
- IPC下降
- cycles上升但吞吐下降
说明:
CPU在"等数据",不是在"算数据"
十二、PCIe + Descriptor耦合问题本质
系统链路变成:
CPU processing delay
↓
descriptor refill delay
↓
NIC RX ring pressure
↓
PCIe DMA backlog
↓
micro burst drop这是一个典型:
feedback loop failure
十三、真正根因总结
最终定位问题:
1. RX descriptor refill节奏下降
2. PCIe DMA completion延迟累积
3. NIC RX ring进入压力状态
4. micro-burst触发丢包
十四、核心知识点(非常重要)
核心知识点1
DPDK性能瓶颈可能出现在NIC内部DMA链路,而非CPU
核心知识点2
RX descriptor是一个闭环系统,不是静态队列
核心知识点3
PCIe DMA存在隐式排队与回压机制
核心知识点4
CPU 100% 在DPDK中不代表系统繁忙程度
核心知识点5
burst size直接影响descriptor回收节奏
核心知识点6
micro-burst丢包通常是"链路反馈失衡"导致
核心知识点7
PCIe completion latency会放大为PPS下降
十五、优化方案
1. 降低burst size
- 128 → 32
减少单次处理延迟
2. 提前refill descriptor
提高回收频率
3. per-lcore buffer isolation
避免共享cache污染
4. 优化prefetch距离
减少load miss
5. 控制PCIe突发压力
避免burst DMA集中提交
十六、优化效果
| 指标 | 优化前 | 优化后 |
|---|---|---|
| PPS | -12% | +9% |
| P99 latency | 18us | 7us |
| micro-burst丢包 | 存在 | 消失 |
| backend stall | 高 | 显著下降 |
十七、总结
在100G及以上高性能交换机系统中,瓶颈已经不再是传统意义上的CPU或NUMA问题,而是:
数据路径中的"反馈系统稳定性"
DPDK的性能问题,本质是:
- descriptor闭环
- DMA延迟传播
- PCIe backpressure
- CPU处理节奏
的系统级耦合问题。
理解这一层,才能真正进入高性能网络系统设计的"深水区"。