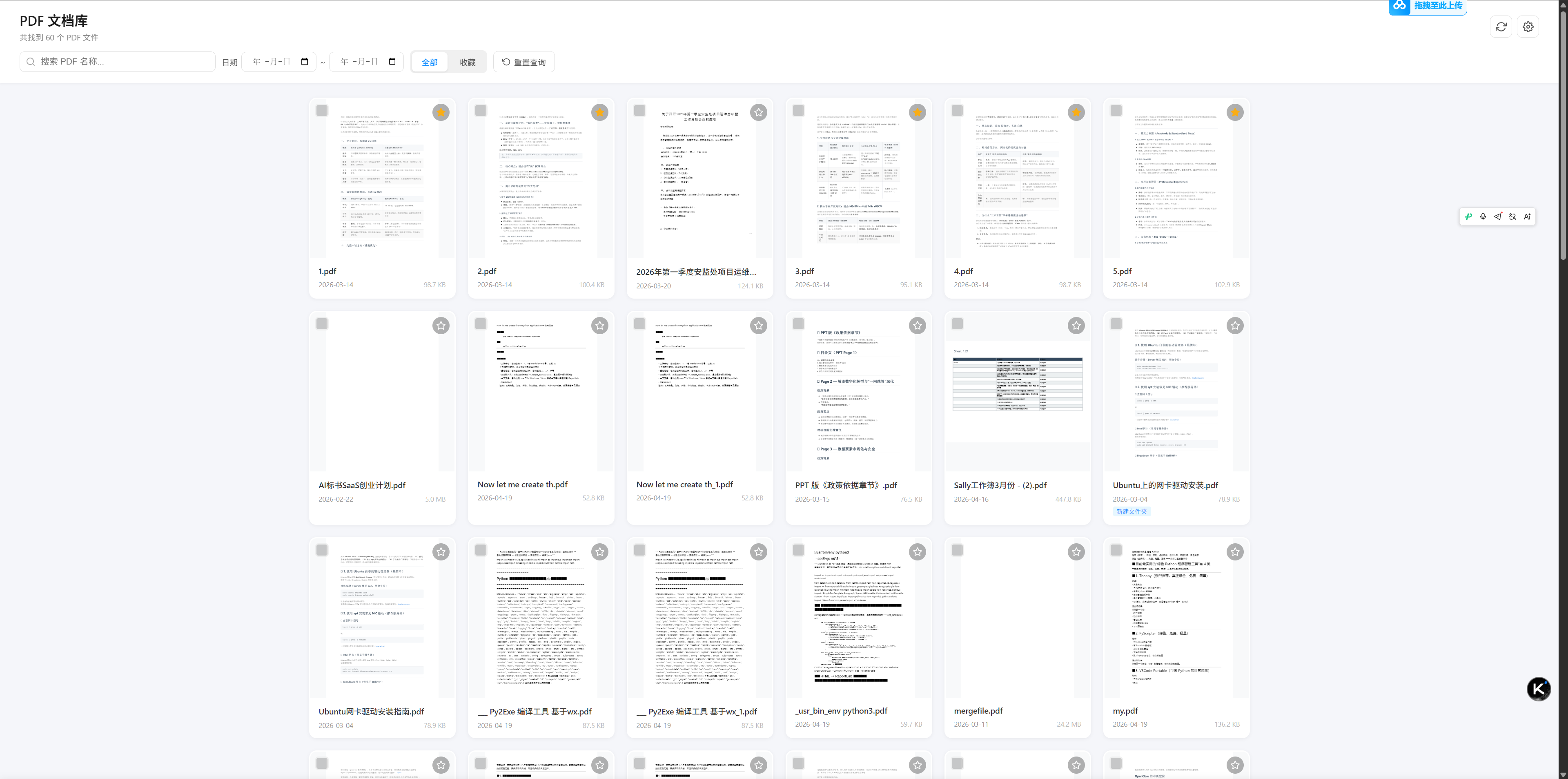
一、项目背景与需求
日常工作中,本地磁盘往往会积累大量 PDF 文档(报告、论文、合同等)。文件管理器的列表视图无法直观预览内容,而专业 PDF 软件又过于笨重。于是有了这个项目的需求:
- 扫描指定文件夹(含子目录)下的所有 PDF
- 缩略图展示每份文档的第一页
- 搜索 文件名、按日期筛选
- 收藏 常用文档,多选打包下载
- 零依赖部署:双击即可运行
技术选型:
- 后端 :Python 内置
http.server+ SQLite(零第三方依赖) - 前端:原生 HTML/CSS/JS + PDF.js CDN
- 启动 :Windows Batch 脚本
C:\Users\86182\Desktop\pdf
二、后端架构设计(serve.py)
后端只用一个文件 serve.py,核心职责有三:
- 提供 REST API(PDF 列表、收藏、设置、打包下载)
- 静态文件服务(
index.html和 PDF 文件本身) - SQLite 缓存与增量同步
2.1 SQLite 缓存层
不使用 JSON 文件存储,而是直接上 SQLite,原因很实际:
- 查询快 :
SELECT * FROM pdfs ORDER BY name比遍历 JSON 快得多 - 增量同步 :通过
mtime判断文件是否变化,避免每次全量扫描 - 结构化:收藏、设置各一张表,关系清晰
python
# 表结构
CREATE TABLE pdfs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
path TEXT UNIQUE NOT NULL, -- 相对路径,如 "report/2024.pdf"
name TEXT NOT NULL,
mtime REAL NOT NULL, -- 修改时间戳,用于增量判断
date TEXT NOT NULL, -- 格式化日期 "2024-01-15"
size INTEGER NOT NULL,
folder TEXT -- 所属子目录
);
CREATE TABLE favorites (
path TEXT UNIQUE NOT NULL
);
CREATE TABLE settings (
key TEXT PRIMARY KEY,
value TEXT NOT NULL
);增量同步算法 (scan_and_sync):
python
def scan_and_sync(source_folder):
scanned = {} # 本次扫描结果
for root, dirs, files in os.walk(source_folder):
for file in files:
if file.lower().endswith('.pdf'):
rel_path = os.path.relpath(full_path, source_folder)
scanned[rel_path] = {
'path': rel_path,
'name': file,
'mtime': stat.st_mtime,
...
}
# 数据库已有数据
db_rows = {row['path']: row['mtime'] for row in cursor}
# 三向同步:删除不存在的、新增/修改变化的
for db_path in db_rows:
if db_path not in scanned:
conn.execute('DELETE FROM pdfs WHERE path=?', (db_path,))
for path, info in scanned.items():
if path not in db_rows or db_rows[path] != info['mtime']:
conn.execute('INSERT OR REPLACE INTO pdfs ...', (...))亮点在于用 mtime 做版本判断,只有文件新增、删除或修改时间变化时才写库,60 个 PDF 的扫描从秒级降到毫秒级。
2.2 REST API 设计
| 接口 | 方法 | 说明 |
|---|---|---|
/api/pdfs |
GET | 从数据库读取所有 PDF 信息 |
/api/refresh |
GET | 手动触发文件系统扫描并同步 |
/api/favorites |
GET/POST/DELETE | 收藏列表 CRUD |
/api/settings |
GET/POST | 读取/保存设置 |
/api/download |
POST | 接收路径列表,打包 ZIP 返回 |
所有接口统一通过 _send_json 返回 JSON,并设置 CORS 头:
python
def _send_json(self, data, status=200):
self.send_response(status)
self.send_header('Content-type', 'application/json; charset=utf-8')
self.send_header('Access-Control-Allow-Origin', '*')
self.end_headers()
self.wfile.write(json.dumps(data, ensure_ascii=False).encode('utf-8'))2.3 路径映射:一个容易被忽视的细节
重写 translate_path 是为了解决一个真实问题:前端文件(index.html)和 PDF 文件可能不在同一目录。
用户希望把 serve.py 放在工具目录,而 PDF 放在其他文件夹。因此:
/和/index.html→ 从当前工作目录提供- 其他文件(PDF)→ 从
sourceFolder设置的路径提供
python
def translate_path(self, path):
if path.startswith('/api/'):
return super().translate_path(path)
path = unquote(path) # 关键!URL 解码中文路径
if path in ('/', '/index.html', '/favicon.ico'):
return os.path.join(os.getcwd(), path.lstrip('/'))
source = get_setting('sourceFolder', '.')
return os.path.join(os.path.abspath(source), path.lstrip('/'))这里 unquote 是救命的 ------没有它,中文文件名如 《报告》.pdf 会被编码为 %E3%80%8A...%E3%80%8B.pdf,服务器直接拿编码后的路径找文件必然 404。
2.4 ZIP 打包下载
多选下载的核心是去重命名 :同一目录下可能有同名文件(如 report.pdf 和 backup/report.pdf),ZIP 内不能冲突。
python
seen = {}
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zf:
for rel_path in paths:
arcname = os.path.basename(rel_path)
if arcname in seen:
base, ext = os.path.splitext(arcname)
seen[arcname] += 1
arcname = f"{base}_{seen[arcname]}{ext}"
else:
seen[arcname] = 0
zf.write(full_path, arcname)三、前端架构设计(index.html)
前端完全原生,无框架,核心挑战在于 PDF.js 的渲染资源管理。
3.1 缩略图渲染的"坑"
PDF.js 的 getDocument 内部会启动 Web Worker 线程 解析 PDF。如果每次直接调用:
javascript
// 错误示范: worker 泄漏
async function renderThumbnail(pdfPath, container) {
const pdf = await pdfjsLib.getDocument(pdfPath).promise;
const page = await pdf.getPage(1);
// ... 渲染到 canvas
// 没有 pdf.destroy()!worker 一直在后台跑
}用户点几次"刷新"后,浏览器里会累积几十个 worker 线程,CPU 和内存直接爆炸,整个系统卡死。
3.2 解决方案:任务队列 + 生命周期管理
引入三层防护:
第一层:取消旧任务
每次重新渲染网格前,先取消所有正在进行的任务:
javascript
let renderTasks = new Map(); // path -> { loadingTask, cancelled }
function cancelAllRenders() {
for (const [path, task] of renderTasks) {
task.cancelled = true;
if (task.loadingTask) {
try { task.loadingTask.destroy(); } catch (e) {}
}
}
renderTasks.clear();
renderQueue = [];
renderRunning = 0;
}第二层:并发控制队列
不能同时渲染 60 个缩略图,限制最大并发为 4:
javascript
const MAX_CONCURRENT_RENDER = 4;
let renderQueue = [];
let renderRunning = 0;
function enqueueRender(pdfPath, container) {
renderQueue.push({ pdfPath, container });
processRenderQueue();
}
function processRenderQueue() {
if (renderQueue.length === 0 || renderRunning >= MAX_CONCURRENT_RENDER) return;
const { pdfPath, container } = renderQueue.shift();
renderRunning++;
renderThumbnail(pdfPath, container).finally(() => {
renderRunning--;
processRenderQueue(); // 递归处理下一个
});
}第三层:渲染完成后销毁资源
javascript
async function renderThumbnail(pdfPath, container) {
const task = { loadingTask: null, cancelled: false };
renderTasks.set(pdfPath, task);
try {
task.loadingTask = pdfjsLib.getDocument({
url: encodeURI(pdfPath),
maxImageSize: 1024 * 1024 // 限制图片尺寸,省内存
});
const pdf = await task.loadingTask.promise;
if (task.cancelled) {
pdf.destroy(); // 已取消,立即销毁
return;
}
const page = await pdf.getPage(1);
// 按目标宽度 400px 计算缩放,不生成超大 canvas
const desiredWidth = 400;
const viewport = page.getViewport({ scale: 1 });
const scale = desiredWidth / viewport.width;
const scaledViewport = page.getViewport({ scale });
const canvas = document.createElement('canvas');
canvas.width = scaledViewport.width;
canvas.height = scaledViewport.height;
// ... 渲染
await renderTask.promise;
page.cleanup();
await pdf.destroy(); // 彻底释放 worker
} catch (err) {
container.innerHTML = '<div class="error-icon">📄</div>';
}
}3.3 预览弹窗的资源释放
iframe 预览 PDF 同样存在资源泄漏问题。关闭弹窗时不能仅仅清空 src:
javascript
function closePdfModal() {
const iframe = document.getElementById('pdfFrame');
// 先将 iframe 从 DOM 移除,再重建,确保 PDF 资源彻底释放
iframe.remove();
const newIframe = document.createElement('iframe');
newIframe.id = 'pdfFrame';
document.querySelector('.modal-body').appendChild(newIframe);
}3.4 URL 编码的又一个坑
encodeURI 不会编码 /,而 PDF 路径可能包含子目录(如 report/2024/总结.pdf)。如果直接用 encodeURI 整个路径,遇到 # 这种字符就会截断。
正确做法是分段编码:
javascript
const encodedPath = pdf.path.split('/').map(encodeURIComponent).join('/');
document.getElementById('pdfFrame').src = encodedPath;四、完整代码
4.1 后端 serve.py
python
import os
import json
import sqlite3
import zipfile
import tempfile
import shutil
from datetime import datetime
from http.server import HTTPServer, SimpleHTTPRequestHandler
from urllib.parse import urlparse, parse_qs, unquote
DB_FILE = 'pdf_browser.db'
def get_db():
conn = sqlite3.connect(DB_FILE)
conn.row_factory = sqlite3.Row
return conn
def init_db():
conn = get_db()
conn.execute('''
CREATE TABLE IF NOT EXISTS pdfs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
path TEXT UNIQUE NOT NULL,
name TEXT NOT NULL,
mtime REAL NOT NULL,
date TEXT NOT NULL,
size INTEGER NOT NULL,
folder TEXT
)
''')
conn.execute('''
CREATE TABLE IF NOT EXISTS favorites (
id INTEGER PRIMARY KEY AUTOINCREMENT,
path TEXT UNIQUE NOT NULL
)
''')
conn.execute('''
CREATE TABLE IF NOT EXISTS settings (
key TEXT PRIMARY KEY,
value TEXT NOT NULL
)
''')
conn.execute("INSERT OR IGNORE INTO settings (key, value) VALUES ('downloadPath', '')")
conn.execute("INSERT OR IGNORE INTO settings (key, value) VALUES ('sourceFolder', '.')")
conn.commit()
conn.close()
def get_setting(key, default=''):
conn = get_db()
row = conn.execute('SELECT value FROM settings WHERE key=?', (key,)).fetchone()
conn.close()
return row['value'] if row else default
def set_setting(key, value):
conn = get_db()
conn.execute('INSERT OR REPLACE INTO settings (key, value) VALUES (?, ?)', (key, value))
conn.commit()
conn.close()
def scan_and_sync(source_folder):
source_folder = os.path.abspath(source_folder)
if not os.path.exists(source_folder):
return 0
scanned = {}
for root, dirs, files in os.walk(source_folder):
dirs[:] = [d for d in dirs if not d.startswith('.') and d != '__pycache__']
for file in sorted(files):
if file.lower().endswith('.pdf'):
full_path = os.path.join(root, file)
rel_path = os.path.relpath(full_path, source_folder).replace('\\', '/')
stat = os.stat(full_path)
folder = ''
if '/' in rel_path:
folder = rel_path.rsplit('/', 1)[0]
scanned[rel_path] = {
'path': rel_path,
'name': file,
'mtime': stat.st_mtime,
'date': datetime.fromtimestamp(stat.st_mtime).strftime('%Y-%m-%d'),
'size': stat.st_size,
'folder': folder
}
conn = get_db()
cursor = conn.execute('SELECT path, mtime FROM pdfs')
db_rows = {row['path']: row['mtime'] for row in cursor}
for db_path in db_rows:
if db_path not in scanned:
conn.execute('DELETE FROM pdfs WHERE path=?', (db_path,))
for path, info in scanned.items():
if path not in db_rows or db_rows[path] != info['mtime']:
conn.execute('''
INSERT OR REPLACE INTO pdfs (path, name, mtime, date, size, folder)
VALUES (?, ?, ?, ?, ?, ?)
''', (info['path'], info['name'], info['mtime'], info['date'], info['size'], info['folder']))
conn.commit()
conn.close()
return len(scanned)
def get_pdfs_from_db():
conn = get_db()
rows = conn.execute('SELECT * FROM pdfs ORDER BY name').fetchall()
conn.close()
return [dict(row) for row in rows]
class PDFHandler(SimpleHTTPRequestHandler):
def _send_json(self, data, status=200):
self.send_response(status)
self.send_header('Content-type', 'application/json; charset=utf-8')
self.send_header('Access-Control-Allow-Origin', '*')
self.end_headers()
self.wfile.write(json.dumps(data, ensure_ascii=False).encode('utf-8'))
def translate_path(self, path):
if path.startswith('/api/'):
return super().translate_path(path)
if '?' in path:
path = path.split('?')[0]
path = unquote(path)
if path in ('/', '/index.html', '/favicon.ico'):
return os.path.join(os.getcwd(), path.lstrip('/'))
source = get_setting('sourceFolder', '.')
abs_source = os.path.abspath(source)
rel_path = path.lstrip('/')
return os.path.join(abs_source, rel_path)
def do_OPTIONS(self):
self.send_response(200)
self.send_header('Access-Control-Allow-Origin', '*')
self.send_header('Access-Control-Allow-Methods', 'GET, POST, DELETE, OPTIONS')
self.send_header('Access-Control-Allow-Headers', 'Content-Type')
self.end_headers()
def _get_source_folder(self):
folder = get_setting('sourceFolder', '.')
return os.path.abspath(folder)
def do_GET(self):
parsed = urlparse(self.path)
path = parsed.path
query = parse_qs(parsed.query)
if path == '/api/pdfs':
pdfs = get_pdfs_from_db()
self._send_json(pdfs)
return
if path == '/api/favorites':
conn = get_db()
rows = conn.execute('SELECT path FROM favorites').fetchall()
conn.close()
self._send_json([r['path'] for r in rows])
return
if path == '/api/settings':
self._send_json({
'downloadPath': get_setting('downloadPath', ''),
'sourceFolder': get_setting('sourceFolder', '.')
})
return
if path == '/api/refresh':
source = self._get_source_folder()
count = scan_and_sync(source)
self._send_json({'success': True, 'count': count, 'sourceFolder': source})
return
return super().do_GET()
def do_POST(self):
parsed = urlparse(self.path)
path = parsed.path
content_length = int(self.headers.get('Content-Length', 0))
body = self.rfile.read(content_length).decode('utf-8') if content_length > 0 else '{}'
try:
data = json.loads(body)
except Exception:
data = {}
if path == '/api/favorites':
pdf_path = data.get('path')
if pdf_path:
conn = get_db()
conn.execute('INSERT OR IGNORE INTO favorites (path) VALUES (?)', (pdf_path,))
conn.commit()
rows = conn.execute('SELECT path FROM favorites').fetchall()
conn.close()
self._send_json([r['path'] for r in rows])
else:
self._send_json({'error': 'Missing path'}, 400)
return
if path == '/api/settings':
old_source = get_setting('sourceFolder', '.')
if 'downloadPath' in data:
set_setting('downloadPath', data['downloadPath'])
if 'sourceFolder' in data:
new_source = data['sourceFolder']
set_setting('sourceFolder', new_source)
if new_source != old_source:
scan_and_sync(new_source)
self._send_json({
'downloadPath': get_setting('downloadPath', ''),
'sourceFolder': get_setting('sourceFolder', '.')
})
return
if path == '/api/download':
paths = data.get('paths', [])
save_to_path = data.get('saveToPath', '')
source = self._get_source_folder()
if not paths:
self._send_json({'error': '未选择文件'}, 400)
return
temp_dir = tempfile.gettempdir()
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
zip_name = f'pdf_package_{timestamp}.zip'
zip_path = os.path.join(temp_dir, zip_name)
seen = {}
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zf:
for rel_path in paths:
full_path = os.path.join(source, rel_path)
if os.path.exists(full_path):
arcname = os.path.basename(rel_path)
if arcname in seen:
base, ext = os.path.splitext(arcname)
seen[arcname] += 1
arcname = f"{base}_{seen[arcname]}{ext}"
else:
seen[arcname] = 0
zf.write(full_path, arcname)
saved_to = None
if save_to_path:
try:
os.makedirs(save_to_path, exist_ok=True)
dest = os.path.join(save_to_path, zip_name)
shutil.copy2(zip_path, dest)
saved_to = dest
except Exception as e:
print(f"保存到指定路径失败: {e}")
self.send_response(200)
self.send_header('Content-Type', 'application/zip')
self.send_header('Content-Disposition', f'attachment; filename="{zip_name}"')
self.send_header('Access-Control-Allow-Origin', '*')
if saved_to:
self.send_header('X-Saved-To', saved_to)
self.end_headers()
with open(zip_path, 'rb') as f:
self.wfile.write(f.read())
try:
os.remove(zip_path)
except Exception:
pass
return
self._send_json({'error': 'Not found'}, 404)
def do_DELETE(self):
parsed = urlparse(self.path)
path = parsed.path
query = parse_qs(parsed.query)
if path == '/api/favorites':
pdf_path = query.get('path', [''])[0]
if pdf_path:
conn = get_db()
conn.execute('DELETE FROM favorites WHERE path=?', (pdf_path,))
conn.commit()
rows = conn.execute('SELECT path FROM favorites').fetchall()
conn.close()
self._send_json([r['path'] for r in rows])
else:
self._send_json({'error': 'Missing path'}, 400)
return
self._send_json({'error': 'Not found'}, 404)
if __name__ == '__main__':
init_db()
source = get_setting('sourceFolder', '.')
print(f'源文件夹: {os.path.abspath(source)}')
print('正在扫描 PDF 文件...')
count = scan_and_sync(source)
print(f'已缓存 {count} 个 PDF 文件到 SQLite')
port = 8000
server = HTTPServer(('localhost', port), PDFHandler)
print(f'\n服务器已启动: http://localhost:{port}')
print(f'请用浏览器打开: http://localhost:{port}/index.html')
server.serve_forever()4.2 前端 index.html
前端代码较长,核心已在第 3 节分析。完整代码可参考项目仓库,或根据上述逻辑自行组装。关键结构:
- Header:搜索框 + 日期筛选 + 筛选标签 + 重置按钮 + 刷新/设置按钮
- Grid:CSS Grid 自适应布局的卡片列表
- Card:缩略图区域 + 复选框 + 收藏星标 + 文件信息
- BottomBar:全选 + 已选计数 + 打包下载(条件渲染)
- Modal:PDF 预览 iframe + 设置面板
- Toast:操作反馈提示
五、踩坑总结
| 问题 | 现象 | 根因 | 解决方案 |
|---|---|---|---|
| Worker 泄漏 | 刷新几次后浏览器/系统卡死 | PDF.js getDocument 创建 worker 不销毁 |
loadingTask.destroy() + pdf.destroy() + 并发队列 |
| 中文 404 | 含中文文件名的 PDF 打不开 | translate_path 未 URL 解码 |
unquote(path) |
| 子目录 404 | 子目录中的 PDF 预览失败 | encodeURI 不编码 /,但 # 截断路径 |
分段 encodeURIComponent |
| iframe 泄漏 | 关闭预览后内存不释放 | 仅清空 src 不彻底 |
DOM 移除 iframe 后重建 |
| 后端修改不生效 | 修复 bug 后测试仍失败 | 旧 Python 进程仍在运行 | 强制终止旧进程再启动 |
六、部署与使用
- 将
serve.py、index.html、start.bat放在同一目录 - 双击
start.bat - 脚本自动检测 Python → 启动服务器 → 打开浏览器
首次启动会自动扫描当前目录下的 PDF 并缓存到 SQLite,后续启动直接从数据库读取,秒开。
七、扩展思路
- 缩略图服务端渲染 :用 Python 的
pdf2image预生成缩略图 PNG,前端直接加载图片,彻底告别 PDF.js Worker - WebSocket 实时同步:文件系统变化时自动推送更新,无需手动刷新
- 标签系统 :在 SQLite 中增加
tags表,支持多维度分类 - 全文检索 :接入
whoosh或sqlite-fts,支持 PDF 内容搜索
本项目代码开源,欢迎 Star 和 PR。核心思想是用最小的依赖做最实用的事------Python 内置库 + 浏览器原生 API,没有 Webpack,没有 Docker,一个 BAT 文件就能跑。