上一篇博客我们完成了通讯录 1.0 最简版本的完整实操,从零搭建了只包含姓名、年龄两个字段的联系人结构,完整走完 proto 定义、代码编译、内存对象序列化、二进制字符串反序列化的全流程,掌握了 Protobuf 最基础的使用链路。 在真实业务开发场景中,单一联系人只会存储姓名年龄是远远不够的,实际通讯录还需要存放电话、住址、备注、多个备用联系方式等大量信息,同时我们也不只会把二进制数据存放在内存字符串中,更多场景会将序列化后的持久写入本地文件,使用时再从文件读取二进制完成解析。 基于真实业务需求,我们开启通讯录 2.x 版本迭代升级,本次升级分为两大核心模块,第一部分系统讲解 proto3 核心字段修饰规则 singular 与 repeated,搞懂单个字段、数组多字段的定义语法;第二部分迭代我们的 PeopleInfo 消息结构,新增电话、地址、多组其他联系方式、备注等业务字段,同时改造业务代码,不再打印内存二进制乱码,实现序列化写入本地文件、从文件读取二进制反解析联系人信息的完整逻辑。
一、proto3语法
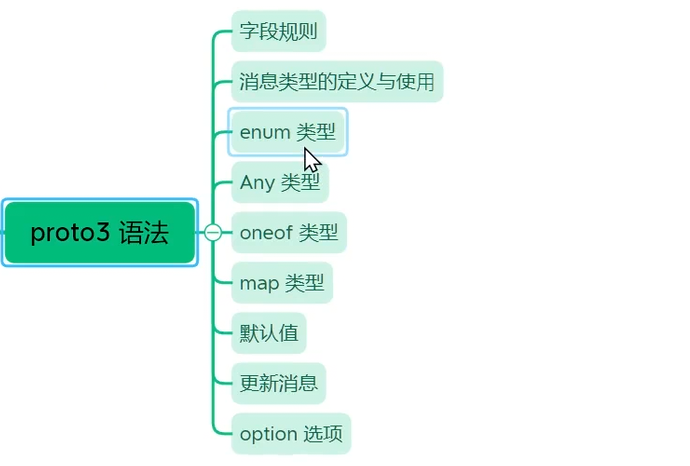
字段规则:
在我们之前 1.0 版本的 proto 文件中,直接书写 string name = 1; 这类字段,没有额外修饰关键字,这是 proto3 语法默认的字段规则 singular,同时 Protobuf 还提供 repeated 修饰符用来定义数组类型字段,两种规则适配不同的业务存储场景,下面分段分开讲解两种规则的含义与使用场景。

singular 是 proto3 所有字段的默认规则,我们平时不写任何修饰词时,字段自动属于 singular 类型。它代表当前这条字段在一个消息对象里最多只能存储一份数据,可以为空不赋值,但是绝对不能存放多条同类型数据。对应我们 1.0 版本的姓名、年龄,一个联系人只会有一个名字、一个年龄,天然适配 singular 规则,一个 PeopleInfo 对象内 name、age 最多只会存在一个有效值,符合现实逻辑。日常开发中绝大多数基础属性,比如用户 id、生日、身份证号、家庭住址,都使用默认 singular 规则定义。
repeated 是数组类型修饰符,写在字段类型最前方,代表当前字段可以存储任意多条同类型数据,数据写入的先后顺序会被 Protobuf 序列化时完整保留,解析时读取顺序和存入顺序完全一致,功能等同于 C++ 里的 vector 动态数组。放到通讯录业务里,一个联系人可能存有多个手机号、多个备用社交账号,这类一条消息需要存放多条同类数据的场景,就必须使用 repeated 修饰字段,后续我们 2.x 版本会新增其他联系方式字段,就会采用 repeated 语法定义,实现一个联系人绑定多条联系方式的需求。
升级需求
 第一点改造数据持久化逻辑,废弃 1.0 版本中将二进制数据存入内存 string 并打印乱码的写法,完成文件落地存储。序列化联系人对象后,直接把二进制字节写入本地磁盘文件,不会在终端输出不可读的二进制乱码,让数据可以长久保存。
第一点改造数据持久化逻辑,废弃 1.0 版本中将二进制数据存入内存 string 并打印乱码的写法,完成文件落地存储。序列化联系人对象后,直接把二进制字节写入本地磁盘文件,不会在终端输出不可读的二进制乱码,让数据可以长久保存。
第二点新增文件读取解析逻辑,程序启动后读取我们刚刚写入磁盘的二进制文件,从文件流中取出字节数据,反序列化还原出完整联系人对象,最终在终端打印全部联系人信息,验证文件读写编解码流程。
第三点丰富联系人数据结构,在原有姓名、年龄基础上,拓展多类业务属性,最终完整字段包含姓名、年龄、电话、家庭地址、多条其他联系方式、个人备注,同时结合前面讲解的 singular、repeated 两种字段规则区分定义单一属性与数组属性,完整覆盖 proto3 基础字段语法。
弄懂 singular、repeated 两种核心字段修饰规则,同时明确通讯录 2.x 版本全部升级需求之后,下一节我们直接重写 contacts.proto 协议文件,完成新版联系人消息结构定义,区分单一基础字段与数组联系方式字段,再重新执行 protoc 编译生成新版 pb.h、pb.cc 代码。
编写代码
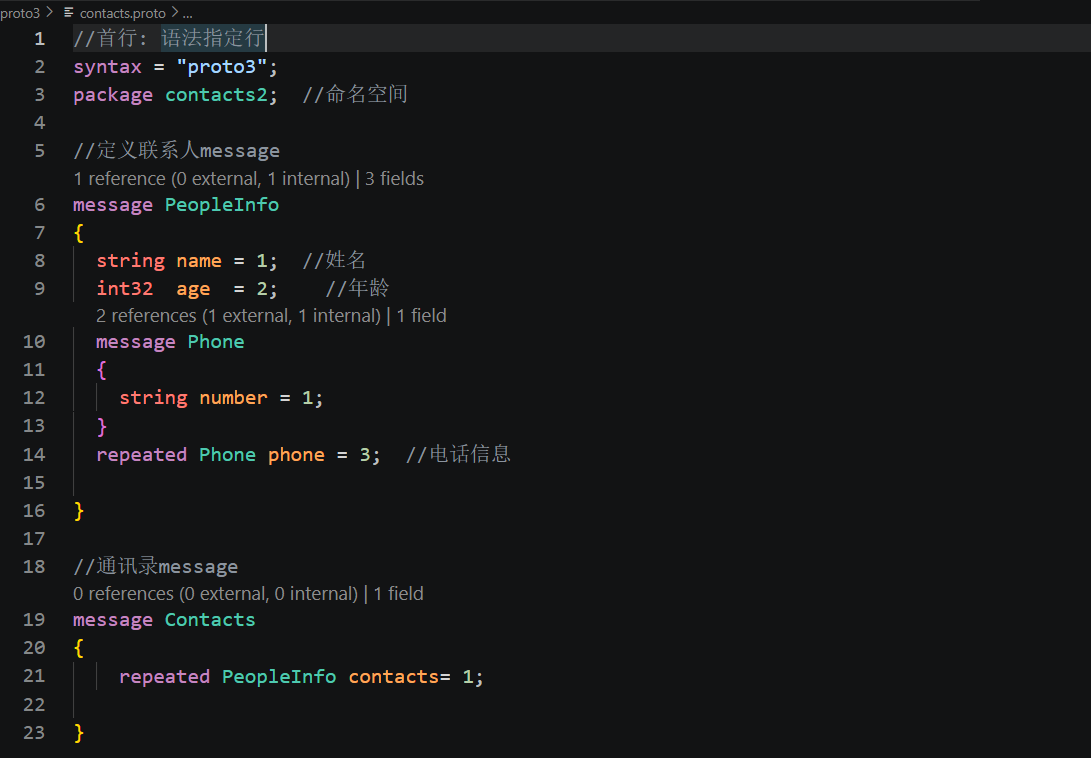 1. 文件最顶部第一行依旧是固定语法声明 syntax = "proto3";,这一行是 proto3 协议文件强制要求的开头,只要我们使用 proto3 语法编写协议,就必须放在文件第一行。如果缺少这行,protoc 编译器会默认按照老旧 proto2 语法解析文件,两种语法在字段默认值、repeated 数组使用规则、接口生成逻辑上存在很大区别,很容易出现编译报错、解析数据错乱的问题,现在新项目统一固定使用 proto3,所以这一行是不可省略的标准开头。
1. 文件最顶部第一行依旧是固定语法声明 syntax = "proto3";,这一行是 proto3 协议文件强制要求的开头,只要我们使用 proto3 语法编写协议,就必须放在文件第一行。如果缺少这行,protoc 编译器会默认按照老旧 proto2 语法解析文件,两种语法在字段默认值、repeated 数组使用规则、接口生成逻辑上存在很大区别,很容易出现编译报错、解析数据错乱的问题,现在新项目统一固定使用 proto3,所以这一行是不可省略的标准开头。
2.第二行 package contacts2; 是本套协议专属的命名空间,对比 1.0 版本的 package contacts,这里更换成了 contacts2。这么设计的原因是我们同时存在 1.0 和 2.x 两套通讯录协议,两套协议里都有 PeopleInfo 这个同名消息类,如果不区分 package 命名空间,编译生成 C++ 代码后会出现类名重定义冲突,程序直接编译失败。设置独立 package 之后,2.x 版本的联系人类完整名称为 contacts2::PeopleInfo,和旧版 contacts::PeopleInfo 完全隔离,两套代码可以在同一个项目中共存,互不干扰,也方便我们区分新旧业务逻辑。
-
接下来我们进入核心的联系人主体定义 message PeopleInfo { },这是对应单个联系人信息的结构体,在原本姓名、年龄两个基础 singular 字段之上,新增了嵌套 Phone 消息与 repeated 电话数组字段,我们先拆解原有两行基础字段。 string name = 1; //姓名 是默认 singular 规则的字符串字段,一个联系人只能拥有一个姓名,字段编号 1 保持不变,**字段编号是二进制编码的唯一标识,**只要协议迭代时不删除旧字段、不重复使用数字,就能保证新旧数据兼容; int32 age = 2; //年龄 同样是 singular 整型字段,单个联系人仅存储一份年龄数据,编号 2 固定,和上一版含义完全一致。
-
在姓名、年龄字段下方,我们新增了嵌套内部 message 定义 message Phone { },这种写在另一个 message 内部的消息结构叫做嵌套消息,专门用来封装单一细分业务数据。这里 Phone 用来单独封装电话号码相关信息,当前内部仅定义 string number = 1; 存储手机号字符串,后续我们还可以拓展电话类型、运营商等字段,把和电话相关的全部属性收拢在 Phone 内部,代码结构分层更清晰,不会把零散的电话属性全部平铺在 PeopleInfo 里。这里 Phone 是仅能在 PeopleInfo 内部访问的局部结构体,外部无法直接单独使用这个消息类型。
-
紧跟 Phone 嵌套定义之后,repeated Phone phone = 3; //电话信息 是本协议第一个 repeated 修饰的数组字段,这里结合前面讲的字段规则展开说明。repeated 代表这个字段可以存放多条 Phone 类型数据,对应现实场景中一个联系人能保存多个手机号、备用电话,序列化的时候会完整保留我们存入多条电话的先后顺序,解析时读取顺序和存入完全一致,底层对应 C++ 代码里的 std::vector 容器。字段类型是我们刚刚定义的嵌套 Phone 消息,编号 3 使用全新数字,不和前面 name、age 的 1、2 重复,保证二进制编码时能区分不同字段。
-
走完单个联系人 PeopleInfo 的全部定义后,文件下方新增了顶层容器消息 message Contacts { },这是整份协议的通讯录根结构,用来存放批量联系人,解决 1.0 版本只能操作单个联系人的局限。 内部 repeated PeopleInfo contacts= 1; 使用 repeated 修饰 PeopleInfo 类型,代表 Contacts 容器内部可以存放任意多条完整联系人对象,相当于一个联系人列表,一个通讯录可以存储几十上百个不同联系人,对应真实手机通讯录批量存储多条联系人的业务场景。后续我们序列化、持久化写入文件时,操作的就是这个 Contacts 容器对象,一次性管理全部联系人数据,不再局限单条联系人信息。
弄懂新版 proto 协议分层结构、嵌套 message 与 repeated 数组语法之后,下一步我们执行 protoc 编译命令,生成 contacts2.pb.h 和 contacts2.pb.cc 新版 C++ 代码:
编译:
 先看截图里执行的编译命令 protoc --cpp_out=. contacts.proto,整条指令每一段的作用我们之前已经讲过,这里简单对应新版场景再梳理一遍,开头 protoc 是我们本地 3.21.11 版本的编译工具,用来读取我们新版的协议文件;--cpp_out=. 代表生成 C++ 语言代码,输出到当前执行命令的文件夹里;最后 contacts.proto 就是我们刚刚编写完成、包含三层 message 结构的协议文件,工具会读取文件里所有 message、嵌套结构、repeated 字段规则,自动解析并生成完整的头文件与源文件。
先看截图里执行的编译命令 protoc --cpp_out=. contacts.proto,整条指令每一段的作用我们之前已经讲过,这里简单对应新版场景再梳理一遍,开头 protoc 是我们本地 3.21.11 版本的编译工具,用来读取我们新版的协议文件;--cpp_out=. 代表生成 C++ 语言代码,输出到当前执行命令的文件夹里;最后 contacts.proto 就是我们刚刚编写完成、包含三层 message 结构的协议文件,工具会读取文件里所有 message、嵌套结构、repeated 字段规则,自动解析并生成完整的头文件与源文件。
命令执行结束后,我们输入 ls 查看当前目录文件,就能看到新生成的 contacts.pb.cc 和 contacts.pb.h 两份文件,这两份文件依旧是成对配套存在,.h 头文件存放所有类、函数的声明,.cc 源文件存放全部方法底层实现,和 1.0 版本文件分工逻辑没有区别,唯一的不同是这份新版 pb 文件内部会多出两套全新的类,对应我们 proto 里新增的嵌套 Phone 消息和顶层 Contacts 通讯录容器。
所以编译生成的 .pb.h 文件中就应该有三个对应的类,现在我们来验证一下:
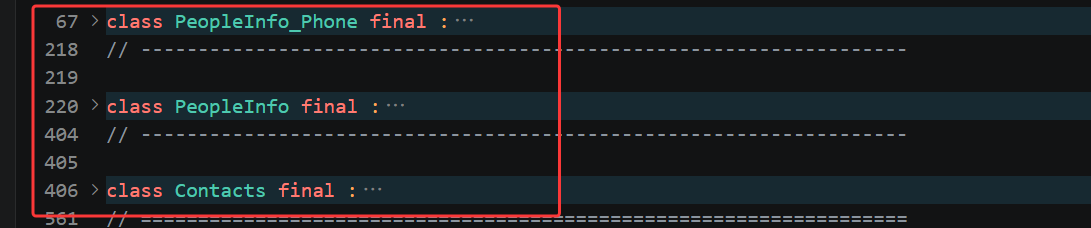 接下来我们重点讲三个 message 和生成类的对应关系,我们这份 proto 里一共定义了三层独立 message,分别是嵌套在 PeopleInfo 内部的 Phone、外层的 PeopleInfo 和 Contacts,protoc 在生成 C++ 类的时候,会按照固定规则把嵌套消息的类名做拼接处理,避免类名冲突。
接下来我们重点讲三个 message 和生成类的对应关系,我们这份 proto 里一共定义了三层独立 message,分别是嵌套在 PeopleInfo 内部的 Phone、外层的 PeopleInfo 和 Contacts,protoc 在生成 C++ 类的时候,会按照固定规则把嵌套消息的类名做拼接处理,避免类名冲突。
第一个类是 PeopleInfo_Phone,对应 proto 里写在 PeopleInfo 内部的嵌套 message Phone,因为 Phone 是内部嵌套结构,不能直接单独命名为 Phone,编译器会把外层 message 名字和内部嵌套 message 名字用下划线拼接,组合成 PeopleInfo_Phone 作为完整类名,这个类专门用来封装单条电话号码的数据,内部自动生成 number 字段的 set、get、clear 读写接口。
第二个类是 PeopleInfo,对应 proto 里外层存放单个联系人信息的 message PeopleInfo,这个类的结构相比 1.0 版本做了大幅扩充,除了保留 name、age 两个基础 singular 字段的读写方法,还会自动生成 repeated Phone 类型 phone 数组字段专属的操作接口,用来添加多条电话、读取全部电话条目、获取电话总数量,后续业务代码操作多组手机号都要依靠这套自动生成的数组接口。
第三个类是 Contacts,对应 proto 最外层存放批量联系人的 message Contacts,这个类内部只有一个 repeated PeopleInfo 类型的 contacts 数组字段,编译器会为它生成批量操作联系人列表的接口,支持新增单个联系人、遍历所有联系人、获取通讯录总人数,对应我们真实场景里保存多条联系人的需求。
我们打开 contacts.pb.h 头文件就能直接看到截图中标红的三个类依次排列,这也验证了 protoc 的编译逻辑,只要 proto 文件里定义了多少个独立 message,不管是顶层定义还是内部嵌套,编译后就会产出一一对应的 C++ 类,嵌套消息只是类名会自动拼接外层名称,不会出现类名重名问题,每一个类都独立拥有字段操作、序列化、反序列化全套能力,各自继承 Message 父类,可以单独创建对象使用。
分段讲解编译生成的三个对应 C++ 类
现在我们已经确认编译后生成了三个一一对应的 C++ 类,下面我们分开逐个拆解 PeopleInfo_Phone、PeopleInfo、Contacts 这三个类内部自动生成的接口:
先讲三个类完全一致的通用底层设计,这三行定义规则在三个类身上全部通用。每个类开头都带有 final 关键字,代表这个类禁止被其他类继承,是 protobuf 编译器固定的设计,防止子类继承破坏底层二进制编解码逻辑。每一个类都公有继承了::PROTOBUF_NAMESPACE_ID::Message 父类,也就间接继承了 MessageLite,所以三个类天然自带全套序列化、反序列化接口,不管是单条电话、单个联系人、完整通讯录容器,都能直接调用 SerializeToString、ParseFromString、文件流读写那一套编解码函数,不用额外做任何拓展。同时编译器自动为每一个类生成了无参构造、析构、拷贝构造、移动构造、赋值重载函数,我们业务代码里可以随便创建对象、拷贝对象、转移对象资源,不用自己手写构造相关逻辑,创建对象直接写**contacts2::类名 对象名;**就能使用。
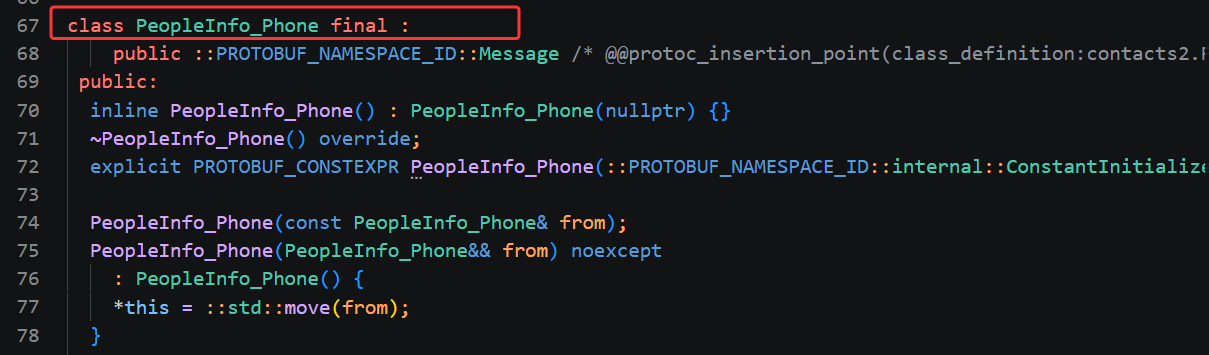 第一个类是最上方的 PeopleInfo_Phone,这个类对应 proto 文件里嵌套在 PeopleInfo 内部的 message Phone。因为 Phone 是写在 PeopleInfo 大括号里面的嵌套消息,不能直接单独命名为 Phone,编译器自动把外层消息名 PeopleInfo 和内部嵌套消息名 Phone 用下划线拼接,生成 PeopleInfo_Phone 这个完整类名,用来避免和其他位置的 Phone 结构体重名。这个类的作用只用来封装单一条电话号码数据,类内部自动生成 number 字符串字段的 name () 读取、set_number () 赋值、clear_number () 清空三套基础接口,后续我们要给联系人添加多个手机号时,每一条手机号都要创建一个 PeopleInfo_Phone 对象存放号码字符串,再存入 PeopleInfo 里的 repeated 数组。这个类的作用范围只服务于联系人的电话字段,不会单独用来承载完整联系人信息。
第一个类是最上方的 PeopleInfo_Phone,这个类对应 proto 文件里嵌套在 PeopleInfo 内部的 message Phone。因为 Phone 是写在 PeopleInfo 大括号里面的嵌套消息,不能直接单独命名为 Phone,编译器自动把外层消息名 PeopleInfo 和内部嵌套消息名 Phone 用下划线拼接,生成 PeopleInfo_Phone 这个完整类名,用来避免和其他位置的 Phone 结构体重名。这个类的作用只用来封装单一条电话号码数据,类内部自动生成 number 字符串字段的 name () 读取、set_number () 赋值、clear_number () 清空三套基础接口,后续我们要给联系人添加多个手机号时,每一条手机号都要创建一个 PeopleInfo_Phone 对象存放号码字符串,再存入 PeopleInfo 里的 repeated 数组。这个类的作用范围只服务于联系人的电话字段,不会单独用来承载完整联系人信息。
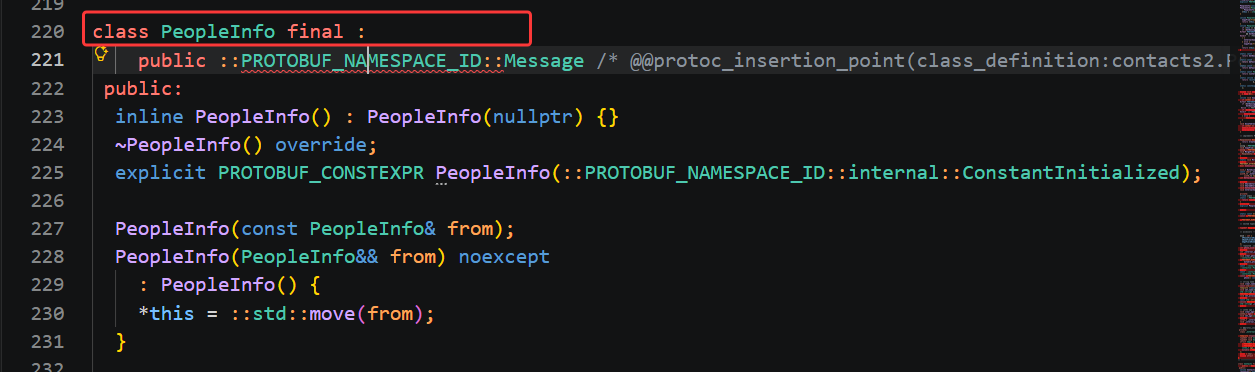 第二个类是中间的 PeopleInfo,对应 proto 里外层单独定义的 message PeopleInfo,也就是我们单个联系人的主体结构。对比 1.0 版本的旧类,这个类除了保留 name、age 两个 singular 单字段的读写方法之外,还新增了专门操作 repeated PeopleInfo 类型 phone 数组的全套接口,这也是 2.x 版本升级后的核心改动。我们之前讲过 repeated 等同于数组,编译器不会只生成简单的 set、get,会提供 add_新增元素、获取数组长度、按下标读取某一条电话、清空全部电话等专属接口,方便我们给一个联系人添加多个手机号。我们日常业务里新建联系人、填写姓名年龄、添加多条备用电话,全部都是操作这个 PeopleInfo 类的对象,是整个协议里最核心的业务载体类。
第二个类是中间的 PeopleInfo,对应 proto 里外层单独定义的 message PeopleInfo,也就是我们单个联系人的主体结构。对比 1.0 版本的旧类,这个类除了保留 name、age 两个 singular 单字段的读写方法之外,还新增了专门操作 repeated PeopleInfo 类型 phone 数组的全套接口,这也是 2.x 版本升级后的核心改动。我们之前讲过 repeated 等同于数组,编译器不会只生成简单的 set、get,会提供 add_新增元素、获取数组长度、按下标读取某一条电话、清空全部电话等专属接口,方便我们给一个联系人添加多个手机号。我们日常业务里新建联系人、填写姓名年龄、添加多条备用电话,全部都是操作这个 PeopleInfo 类的对象,是整个协议里最核心的业务载体类。
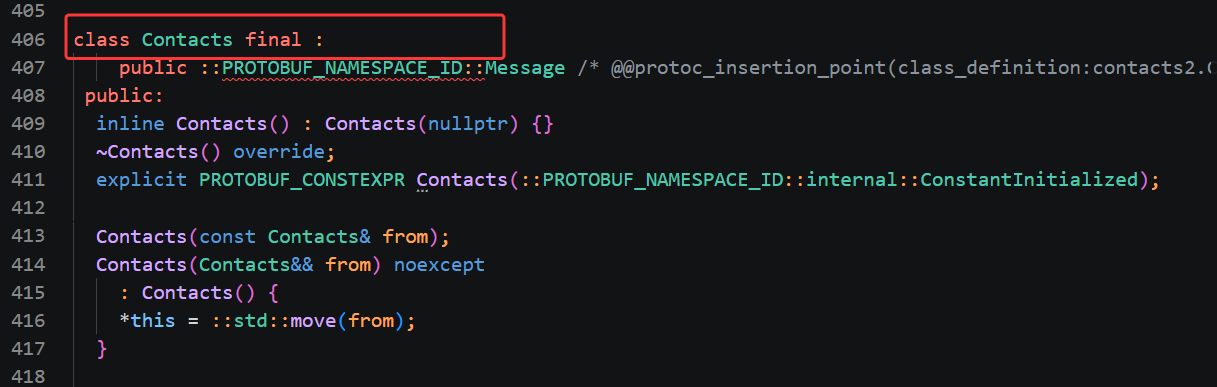 第三个类是最下方的 Contacts,对应 proto 文件最外层定义的 message Contacts,也就是完整通讯录容器。这个类内部只有一个 repeated PeopleInfo 类型的数组字段,所以编译器给这个类生成了批量操作联系人列表的接口,支持 add_contacts 往通讯录里新增一条完整联系人、size () 获取当前通讯录存储了多少个联系人、通过下标取出指定位置的联系人对象、clear_contacts 清空通讯录全部内容。我们后续做文件持久化的时候,序列化写入本地文件的对象就是 Contacts,一个 Contacts 对象可以一次性装下几十上百个 PeopleInfo 联系人,对应真实手机通讯录批量存储多条联系人的场景,不再局限 1.0 版本只能操作单个联系人的局限。
第三个类是最下方的 Contacts,对应 proto 文件最外层定义的 message Contacts,也就是完整通讯录容器。这个类内部只有一个 repeated PeopleInfo 类型的数组字段,所以编译器给这个类生成了批量操作联系人列表的接口,支持 add_contacts 往通讯录里新增一条完整联系人、size () 获取当前通讯录存储了多少个联系人、通过下标取出指定位置的联系人对象、clear_contacts 清空通讯录全部内容。我们后续做文件持久化的时候,序列化写入本地文件的对象就是 Contacts,一个 Contacts 对象可以一次性装下几十上百个 PeopleInfo 联系人,对应真实手机通讯录批量存储多条联系人的场景,不再局限 1.0 版本只能操作单个联系人的局限。
整体梳理三者的层级使用关系,最内层最小单元是 PeopleInfo_Phone 存放单条号码,多条号码装在 PeopleInfo 单个联系人对象里,多个完整联系人再全部存入顶层 Contacts 通讯录容器。三个类各自独立,都具备完整的创建、拷贝、序列化、反序列化能力,底层继承体系完全统一,只是对应 proto 里不同层级的 message,承载的业务数据粒度大小有区别,越往下的类承载的数据越细碎,最顶层 Contacts 是我们最终落地存储、读写文件的顶层载体。
弄懂三个生成类的来源、底层共性和各自承载的业务数据之后,接下来我们单独拆开每一个类内部自动生成的字段操作接口,重点区分 singular 普通单字段和 repeated 数组字段在调用函数上的区别,尤其是 repeated 数组独有的 add_、size ()、下标读取接口。
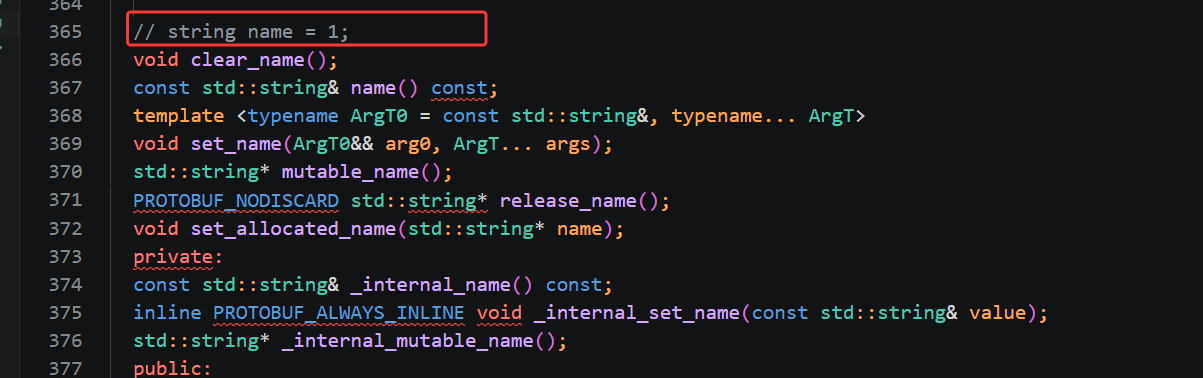 第一块是 string name = 1;对应的全部成员函数,name 属于默认 singular 单字段,一个联系人只能存一个姓名,编译器生成的接口和我们 1.0 版本完全一致,核心可用的只有三个基础方法。clear_name()用来清空姓名字段,调用后字符串直接恢复为空;name()是只读获取方法,不带任何参数,直接返回当前存储的姓名字符串;set_name()是赋值写入方法,我们直接传入字符串字面量或者 std::string 就能修改姓名。剩下 mutable_name、release_name 这类带内存分配的进阶接口,日常简单开发基本用不到,只需要掌握清空、读取、赋值三个基础函数就足够完成业务开发。
第一块是 string name = 1;对应的全部成员函数,name 属于默认 singular 单字段,一个联系人只能存一个姓名,编译器生成的接口和我们 1.0 版本完全一致,核心可用的只有三个基础方法。clear_name()用来清空姓名字段,调用后字符串直接恢复为空;name()是只读获取方法,不带任何参数,直接返回当前存储的姓名字符串;set_name()是赋值写入方法,我们直接传入字符串字面量或者 std::string 就能修改姓名。剩下 mutable_name、release_name 这类带内存分配的进阶接口,日常简单开发基本用不到,只需要掌握清空、读取、赋值三个基础函数就足够完成业务开发。
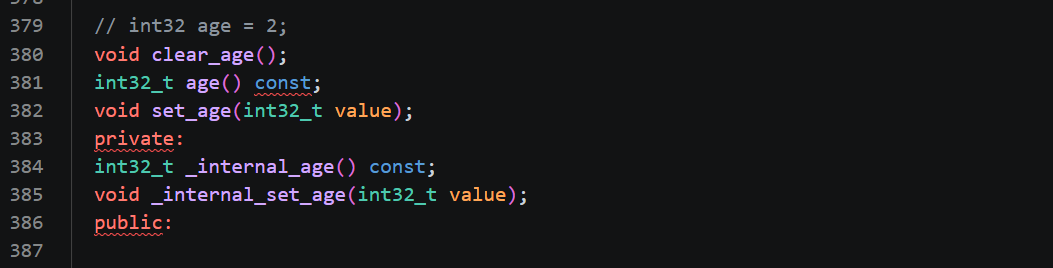 第二块是int32 age = 2;对应的接口,age 同样是 singular 单整型字段,生成的接口逻辑和字符串 name 完全统一,只是参数类型换成了数字。clear_age()执行后年龄重置为默认值 0;age()直接返回存储的整型年龄数字,只读不修改对象;set_age()接收 int 数字作为参数,用来修改联系人年龄。不管是 string、int32、bool 这类任意基础单字段,protoc 生成的基础读写清空接口命名规则永远统一,读取直接写字段名,赋值前缀 set_,清空前缀 clear_,记忆成本很低。
第二块是int32 age = 2;对应的接口,age 同样是 singular 单整型字段,生成的接口逻辑和字符串 name 完全统一,只是参数类型换成了数字。clear_age()执行后年龄重置为默认值 0;age()直接返回存储的整型年龄数字,只读不修改对象;set_age()接收 int 数字作为参数,用来修改联系人年龄。不管是 string、int32、bool 这类任意基础单字段,protoc 生成的基础读写清空接口命名规则永远统一,读取直接写字段名,赋值前缀 set_,清空前缀 clear_,记忆成本很低。
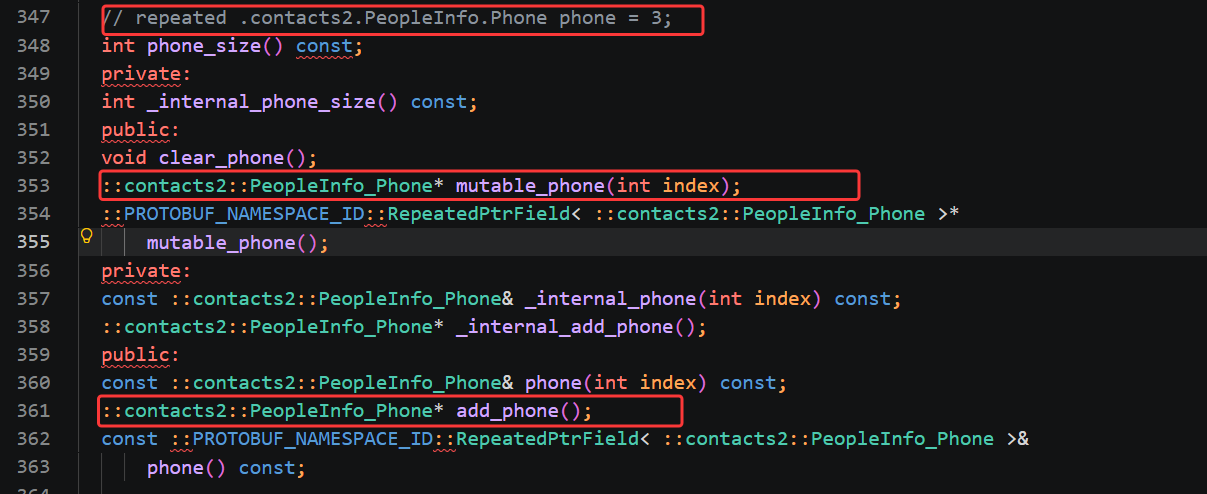 第三块是重点,对应 proto 里 repeated PeopleInfo Phone phone = 3; 数组字段,这一块的接口和上面单字段完全不一样,因为 repeated 代表可以存放多条 Phone 对象,等同于 C++ 里的 vector 动态数组,编译器额外生成了一整套数组专属操作函数,我们逐个讲日常最常用的几个。 phone_size() 用来获取当前这个联系人存了多少个电话号码,返回整型数字,对应 vector 的 size (),遍历全部电话的时候一定会用到这个方法; clear_phone() 会一次性清空数组里所有存储的 Phone 对象,整条电话列表直接置空; add_phone() 是新增元素最核心的方法,调用之后会自动在数组末尾创建一个全新的空 PeopleInfo_Phone 对象,返回这个新对象的指针,我们拿到指针后就能调用 set_number 给这条新号码赋值,是给联系人添加多条电话最常用的接口; phone(int index)是按下标读取指定位置的电话对象,传入数字下标,就能取出对应序号的 Phone,用来循环遍历打印所有手机号; mutable_phone(int index)用来修改指定下标的已有电话对象,和只读的 phone (index) 区分开,需要修改已经存在的号码时使用。
第三块是重点,对应 proto 里 repeated PeopleInfo Phone phone = 3; 数组字段,这一块的接口和上面单字段完全不一样,因为 repeated 代表可以存放多条 Phone 对象,等同于 C++ 里的 vector 动态数组,编译器额外生成了一整套数组专属操作函数,我们逐个讲日常最常用的几个。 phone_size() 用来获取当前这个联系人存了多少个电话号码,返回整型数字,对应 vector 的 size (),遍历全部电话的时候一定会用到这个方法; clear_phone() 会一次性清空数组里所有存储的 Phone 对象,整条电话列表直接置空; add_phone() 是新增元素最核心的方法,调用之后会自动在数组末尾创建一个全新的空 PeopleInfo_Phone 对象,返回这个新对象的指针,我们拿到指针后就能调用 set_number 给这条新号码赋值,是给联系人添加多条电话最常用的接口; phone(int index)是按下标读取指定位置的电话对象,传入数字下标,就能取出对应序号的 Phone,用来循环遍历打印所有手机号; mutable_phone(int index)用来修改指定下标的已有电话对象,和只读的 phone (index) 区分开,需要修改已经存在的号码时使用。
我们在这里做一个清晰的对比,singular 单字段没有 size、add、下标读取这类接口,因为它最多只有一份数据,不需要管理多条元素;而 repeated 数组字段必须提供新增、计数、下标访问、批量清空的全套接口,才能实现多条同类型数据的存储与遍历,这也是 proto3 里 singular 和 repeated 两种字段规则在生成代码层面最直观的区别。
结合我们的业务场景举一个直白例子,创建联系人对象后,先调用 set_name、set_age 填好姓名年龄,想要添加两个手机号时,就两次调用 add_phone (),分别拿到两个 Phone 对象,各自执行 set_number 填入不同号码;后续打印联系人信息时,先调用 phone_size () 拿到电话总数,再写 for 循环,循环里用 phone (i) 逐个取出每一条号码完成打印,整套逻辑全部依靠这些自动生成的数组接口实现,不用我们手动管理数组内存。
弄懂 singular 单字段和 repeated 数组字段各自配套的调用接口之后,我们再去看最外层 Contacts 容器类内部生成的接口,它内部是 repeated PeopleInfo 类型的数组,接口设计逻辑和这里的 phone 数组完全一致,只是操作对象换成了完整的联系人 PeopleInfo,支持批量新增、遍历全部联系人。
Contacts类:
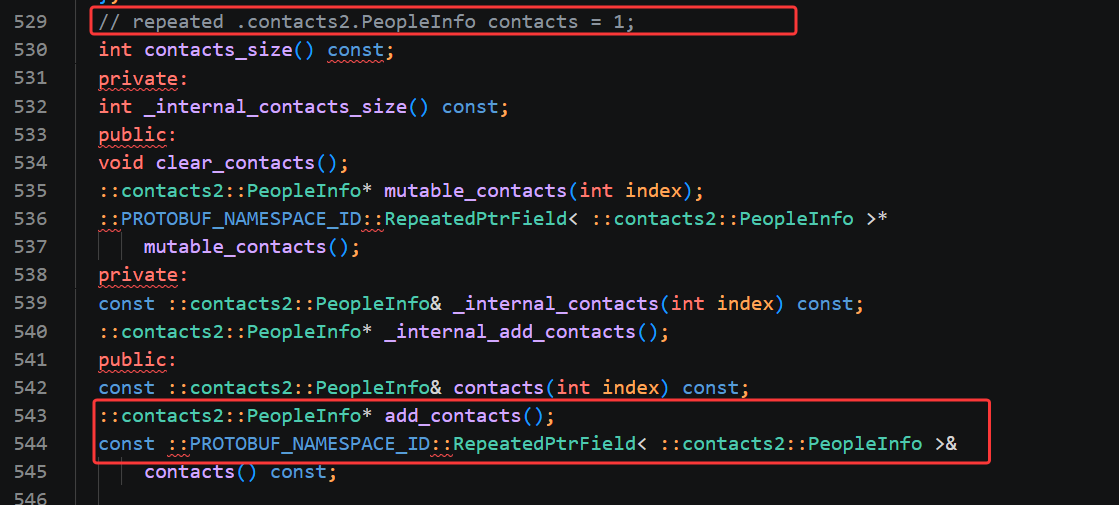 这一段代码全部来自顶层容器 Contacts 类,对应 proto 里 repeated PeopleInfo contacts = 1; 这个数组字段,整套接口的设计逻辑,和上一段 PeopleInfo 里面 phone 数组的规则完全统一,只是数组里存储的对象换成了完整的 PeopleInfo 联系人,我们逐个拆解日常开发最核心的几个方法。
这一段代码全部来自顶层容器 Contacts 类,对应 proto 里 repeated PeopleInfo contacts = 1; 这个数组字段,整套接口的设计逻辑,和上一段 PeopleInfo 里面 phone 数组的规则完全统一,只是数组里存储的对象换成了完整的 PeopleInfo 联系人,我们逐个拆解日常开发最核心的几个方法。
最顶部的 int contacts_size() const; 是用来获取当前通讯录里面存了多少个联系人,返回一个整型数字。如果我们往通讯录里添加了 3 个联系人,调用这个方法就会返回 3,遍历所有联系人的时候,这个函数是循环终止判断的关键,作用等同于 C++vector 的 size 函数。
接下来 void clear_contacts(); 是批量清空接口,调用之后会把通讯录里存储的所有联系人全部删除,整个 contacts 数组直接置空,适合需要重置全部通讯录数据的场景,不用我们逐个删除每一条联系人。
mutable_contacts(int index) 是按下标修改已有联系人的接口,传入数字下标,就能拿到对应位置联系人对象的可修改指针。如果我们已经存入一条联系人,想要中途修改他的姓名或者电话,就用这个方法取出对象,再调用 set_name、add_phone 这类接口修改内部数据。
红框标注的第一个核心方法 ::contacts2::PeopleInfo* add_contacts(); 是新增联系人最常用的函数,调用一次就会在 contacts 数组末尾自动生成一个全新的空 PeopleInfo 联系人对象,并且返回这个新对象的指针。我们拿到指针之后,就能连续调用 set_name、set_age、add_phone 去填充这个联系人的所有信息,每新增一个联系人,就调用一次 add_contacts,是业务代码里构建通讯录数据的核心函数。
const ::contacts2::PeopleInfo& contacts(int index) const; 是只读按下标读取联系人,和 mutable_contacts 区分开,这个方法返回常量引用,只能读取联系人内部的姓名、年龄、电话数据,不能做任何修改,适合单纯遍历打印通讯录全部信息的场景,不会意外改动原有数据。
最下方红框里的 contacts() const 会直接返回整个 repeated 数组的只读容器对象,底层对应 protobuf 封装的 RepeatedPtrField 容器,如果需要使用迭代器遍历、做批量拷贝、对比数组整体内容,就会用到这个接口,简单打印遍历联系人的场景一般不会用到。
我们可以把这套接口和前面 PeopleInfo 里的 phone 数组做统一总结,只要 proto 里定义了 repeated 修饰的数组字段,不管数组里面存的是基础字符串、嵌套 Phone 消息、还是完整 PeopleInfo 联系人消息,protoc 生成的接口命名规则完全固定。获取数组长度就是字段名_size(),清空全部内容是clear_字段名(),新增元素用add_字段名(),按下标只读读取是字段名(下标),按下标修改元素是mutable_字段名(下标),记住这套统一命名规律,不管多复杂的嵌套数组都能快速上手调用。
放到我们本次通讯录业务里梳理完整使用流程,先创建 Contacts 通讯录容器对象,循环多次调用 add_contacts 拿到空联系人,给每个联系人填充姓名、年龄、多条电话;等全部联系人数据填充完成后,调用 contacts_size () 拿到总人数,写 for 循环用 contacts (i) 逐个取出联系人,读取并打印内部所有字段;如果需要清空全部数据,直接调用 clear_contacts 一次性清空整个通讯录列表。
现在我们已经完整看完三层 message 编译后生成的全部类、字段操作接口,分清了 singular 普通字段和 repeated 数组字段的调用差异,下一部分我们编写新版 main 业务代码,实现批量构建通讯录、序列化写入本地文件、从文件读取二进制并遍历打印所有联系人的完整实操逻辑。
编写文件:
write.cc
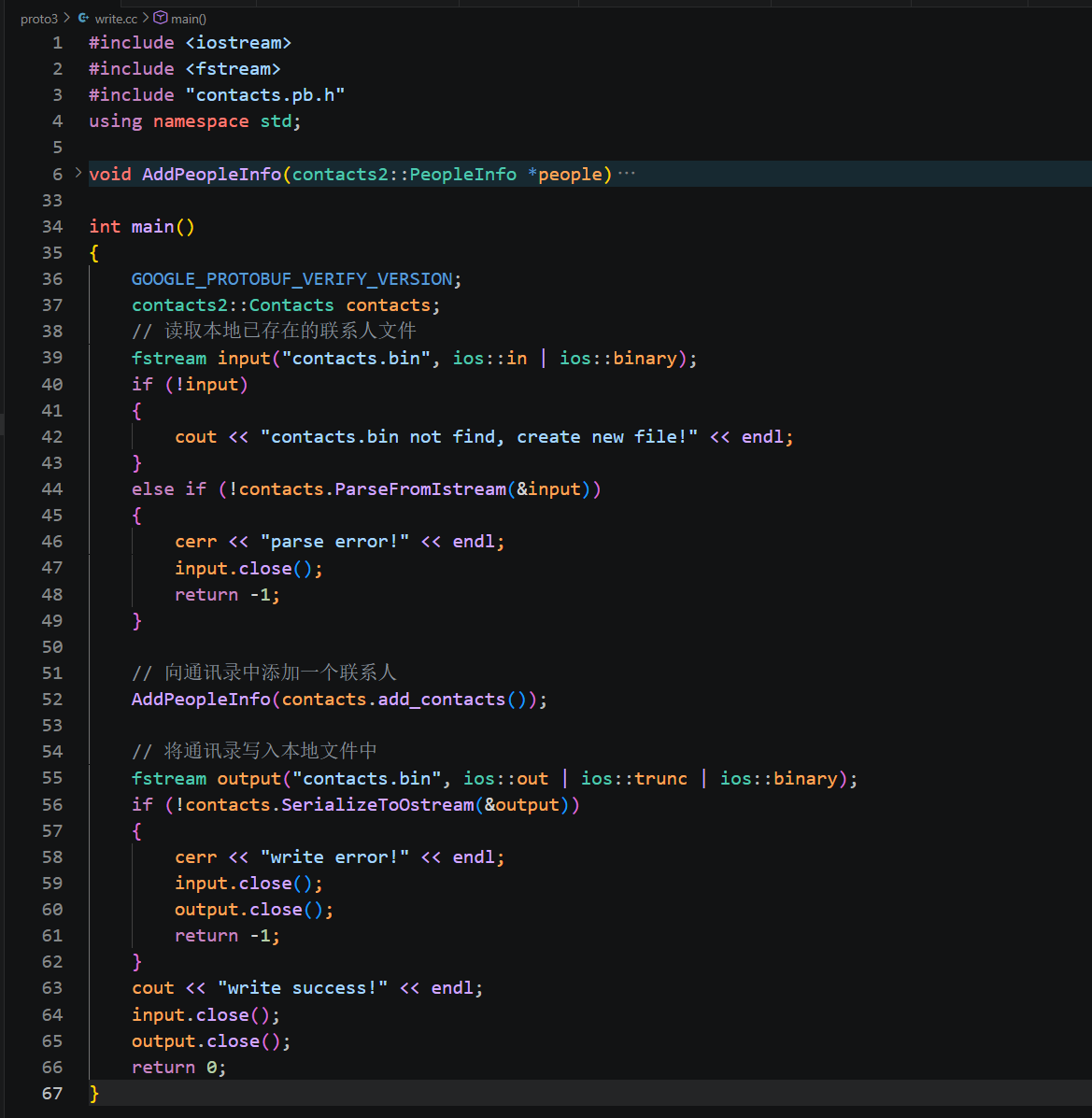 1. 先看文件最顶部三行头文件引入,第一行#include <iostream>依旧是标准输入输出库,用来在终端打印日志、错误提示,和上一版代码作用一致。**第二行 #include <fstream> 是本次新增的核心头文件,专门用来操作本地磁盘文件,我们要实现二进制文件读写、文件流序列化与反序列化,全部依赖这个库里面的 fstream 文件流对象,**缺少这一行代码无法打开、读写本地 contacts.bin 文件。第三行 #include "contacts.pb.h" 是 protoc 编译 proto 生成的头文件,引入之后程序才能识别 contacts2 命名空间、Contacts、PeopleInfo、PeopleInfo_Phone 这三个自动生成的类,以及 add_contacts、SerializeToOstream 整套编解码接口。
1. 先看文件最顶部三行头文件引入,第一行#include <iostream>依旧是标准输入输出库,用来在终端打印日志、错误提示,和上一版代码作用一致。**第二行 #include <fstream> 是本次新增的核心头文件,专门用来操作本地磁盘文件,我们要实现二进制文件读写、文件流序列化与反序列化,全部依赖这个库里面的 fstream 文件流对象,**缺少这一行代码无法打开、读写本地 contacts.bin 文件。第三行 #include "contacts.pb.h" 是 protoc 编译 proto 生成的头文件,引入之后程序才能识别 contacts2 命名空间、Contacts、PeopleInfo、PeopleInfo_Phone 这三个自动生成的类,以及 add_contacts、SerializeToOstream 整套编解码接口。
-
接下来是全局辅助函数声明 void AddPeopleInfo(contacts2::PeopleInfo *people),这个函数是我们自己封装的工具方法,接收一个 PeopleInfo 对象指针,函数内部会统一给这个联系人填充姓名、年龄、多条电话号码,把构建联系人数据的逻辑单独抽离出来,避免 main 函数内重复写大量 set、add_phone 代码,后续新增联系人只需要调用一次这个函数,代码会更加整洁,后面我们会补充这个函数内部的完整实现。
-
进入程序入口 main 函数,第一行 GOOGLE_PROTOBUF_VERIFY_VERSION; 是 Protobuf 官方推荐的版本校验宏,作用是校验我们编译代码时使用的头文件版本,和程序运行时链接的 Protobuf 库版本是否完全匹配。刚好对应我们本地存在新旧版本冲突的踩坑场景,如果头文件、库版本不一致,这一行代码会直接程序崩溃并打印版本不匹配提示,提前拦截版本兼容问题,避免后续出现难以定位的序列化异常,是正式项目里必不可少的一行代码。
-
下一行 contacts2::Contacts contacts; 创建顶层通讯录容器对象 contacts,这个对象对应 proto 最外层的 message Contacts,内部自带 repeated PeopleInfo 数组,我们所有联系人数据都会存放在这个对象中,序列化写入文件、从文件解析数据也全部操作这个 contacts 容器对象。
-
紧接着是读取本地文件的逻辑块,fstream input("contacts.bin", ios::in | ios::binary); 创建文件输入流 input,打开当前目录下名为 contacts.bin 的文件。打开模式传入两个参数,ios::in 代表以只读模式打开文件,用来读取磁盘里存储的二进制通讯录数据;ios::binary 代表以纯二进制模式读写文件,必须加上这个标识,否则 Windows、Linux 系统会自动转换换行符,破坏 Protobuf 二进制字节流,导致反序列化解析失败。
-
下方 if 判断 if (!input) 用来校验文件是否打开成功,如果当前目录不存在 contacts.bin 文件,文件流对象会标记为失败,程序进入 if 分支,在终端打印提示 "contacts.bin not find, create new file!",代表本次是第一次运行程序,没有历史通讯录数据,直接跳过文件解析逻辑,后续直接新建联系人写入全新文件。
-
else if 分支 else if (!contacts.ParseFromIstream(&input)) 是文件存在时的反序列化逻辑,**ParseFromIstream 就是配套文件流的反序列化接口,接收文件流指针作为输入型参数,会从打开的 contacts.bin 文件中读取全部二进制字节,解析填充到我们本地的 contacts 通讯录对象里。**函数返回 bool 值,解析成功返回 true,二进制损坏、文件内容非法则返回 false,一旦解析失败,程序打印 parse error 错误日志,手动关闭文件流 input.close (),执行 return -1 异常退出程序,避免文件句柄泄漏。
-
解析完成历史数据之后,执行 AddPeopleInfo(contacts.add_contacts()); 新增一条联系人,我们先调用 contacts.add_contacts (),这个方法会在通讯录数组末尾生成一个全新空 PeopleInfo 对象,返回对象指针,直接把指针传给封装好的 AddPeopleInfo 函数,函数内部自动填充完整联系人信息,实现往已有通讯录里追加一条新联系人。
-
走完数据填充逻辑,开始执行写入本地文件操作,fstream output("contacts.bin", ios::out | ios::trunc | ios::binary); 创建文件输出流 output,重新打开 contacts.bin 文件,这里的打开模式分为三段,ios::out 代表写入模式;ios::trunc 代表如果文件已经存在,直接清空文件原有全部内容,用本次最新的完整通讯录覆盖旧数据;ios::binary 依旧是二进制读写标识,保证字节不被系统转义破坏。
-
紧接着 if 判断 if (!contacts.SerializeToOstream(&output)) 执行序列化写入文件操作,SerializeToOstream 是适配文件流的序列化接口,接收文件输出流指针作为输出型参数,会把 contacts 通讯录对象完整编码成二进制字节,全部写入 output 绑定的 contacts.bin 本地文件。函数返回布尔值,写入失败就进入错误分支,打印 write error 日志,手动关闭 input、output 两个文件流,释放文件资源,异常退出程序。
-
如果序列化写入文件流程无报错,程序走到 cout << "write success!" << endl;,在终端打印写入成功提示,代表完整通讯录已经持久化保存到本地 contacts.bin 二进制文件。
-
代码末尾依次调用 input.close ()、output.close () 手动关闭两个文件流,主动释放操作系统文件句柄资源,最后 return 0 标识程序正常执行完毕退出。
-
整体梳理本段代码完整执行流程,程序启动先校验 Protobuf 版本,尝试读取本地历史通讯录文件,文件存在就把磁盘二进制数据反序列化为内存通讯录对象;随后追加一条全新联系人;最后把更新后的完整通讯录对象序列化,覆盖写入本地 contacts.bin 二进制文件,整套流程实现了文件持久化存储,不再像 1.0 版本只在内存操作二进制字符串,同时完整用上了文件流专属的 SerializeToOstream、ParseFromIstream 编解码接口。
-
写完文件写入逻辑之后,我们补充 AddPeopleInfo 填充联系人函数的完整实现代码,演示如何给单个联系人赋值姓名、年龄,多次调用 add_phone 添加多条手机号,完整操作 repeated 嵌套数组字段。
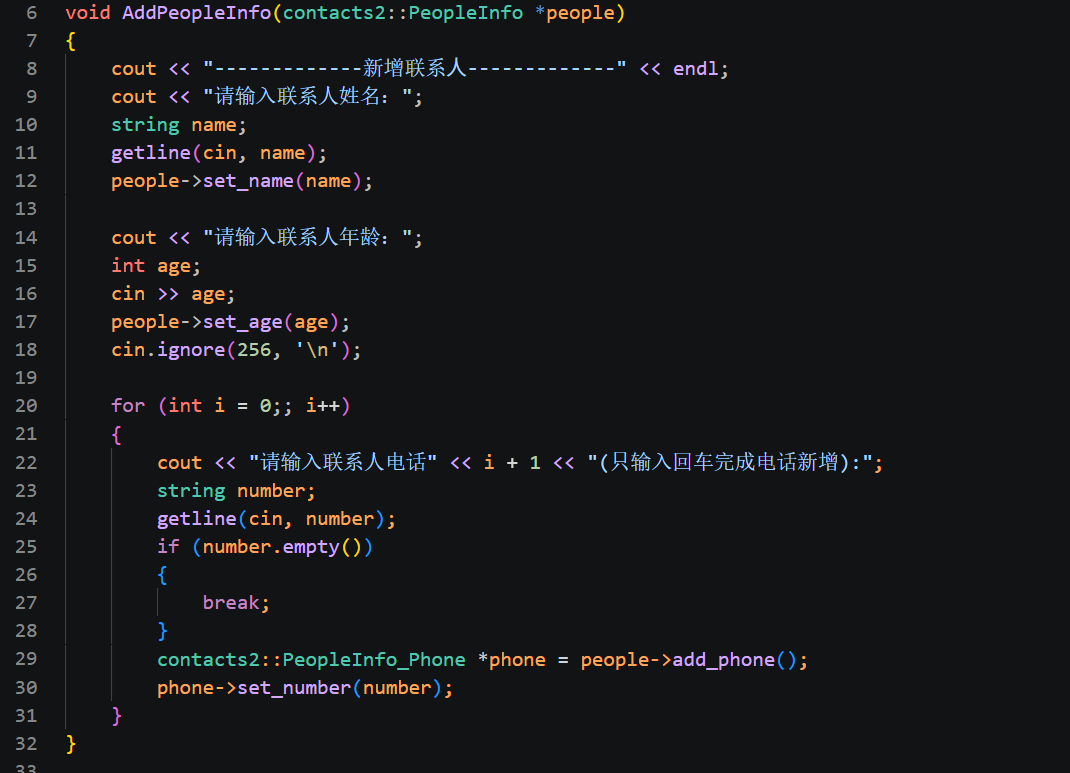 下面我们讲解 AddPeopleInfo 新增联系人工具函数。这个函数是我们单独封装的辅助方法,接收一个 contacts2::PeopleInfo 类型的指针,专门用来交互式录入单个联系人的全部信息,包含姓名、年龄、多条手机号,完整演示 singular 普通字段、repeated 嵌套数组字段的调用方式,我们从上到下逐段拆解代码逻辑。
下面我们讲解 AddPeopleInfo 新增联系人工具函数。这个函数是我们单独封装的辅助方法,接收一个 contacts2::PeopleInfo 类型的指针,专门用来交互式录入单个联系人的全部信息,包含姓名、年龄、多条手机号,完整演示 singular 普通字段、repeated 嵌套数组字段的调用方式,我们从上到下逐段拆解代码逻辑。
函数开头先打印分割提示文本,方便我们在终端区分每一次新增联系人的输入流程,起到界面分割、提升交互可读性的作用,没有业务逻辑功能,仅做展示优化。接下来处理姓名字段的录入逻辑,先打印提示文字请用户输入联系人姓名,定义 string 类型变量 name 接收输入内容,使用 getline(cin, name) 读取一整行字符串,这种读取方式可以兼容姓名里带空格的场景,不会遇到空格就截断输入。拿到用户输入的姓名字符串之后,通过指针调用people->set_name(name),这里的 set_name 就是 singular 字符串字段专属赋值接口,把读取到的姓名存入当前联系人对象内部的 name 字段。
随后是年龄录入流程,先打印年龄输入提示,定义 int 型变量 age,使用 cin >> age 读取数字,再调用 people->set_age(age) 完成年龄字段赋值。这里需要注意下一行 cin.ignore(256, '\n');,这一行是缓冲区清理操作,cin 读取数字时只会接收数字,回车换行符会残留在输入缓冲区里,如果不清理,下一轮循环的 getline 会直接读取到空字符串,提前跳出电话输入循环,ignore 会读取并丢弃缓冲区最多 256 个字符直到遇到换行符,清空残留换行,保证后续手机号输入正常执行。
再往下是无限 for 循环,用来实现多条手机号的连续录入,循环没有设置终止上限,由用户主动结束循环,适配一个联系人可存储任意多组电话的 repeated 业务场景。循环内部先打印提示,标注当前是第几个电话,同时提示用户只输入回车就结束电话录入。定义 string 变量 number,用 getline 读取一行手机号内容,紧接着做判断if (number.empty()),如果用户没有输入任何数字,直接敲回车,字符串就为空,执行 break 跳出整个电话循环,代表当前联系人的手机号录入完毕。
如果用户输入了有效手机号字符串,就执行核心数组操作代码,先调用 people->add_phone(),这是 repeated Phone 数组专属新增接口,调用之后会在联系人的 phone 数组末尾自动创建一个全新的 PeopleInfo_Phone 嵌套对象,并且返回这个新对象的指针,我们用同类型指针变量 phone 接收这个返回值。拿到电话对象指针之后,调用 phone->set_number(number),给嵌套 Phone 内部的 number 字符串字段赋值,完成单条手机号的存储,之后循环回到开头,等待用户输入下一条电话。
整套函数完整串联了两种字段规则的接口调用逻辑,姓名、年龄属于 singular 单字段,直接使用 set_xxx 完成单次赋值;手机号是 repeated 嵌套消息数组,依靠 add_phone 持续新增多条子对象,配合循环实现不定长度多条数据录入,同时搭配标准输入流完成交互式录入,不用我们在 main 函数里堆砌大量重复的输入赋值代码,代码分层更清晰。
运行结果:
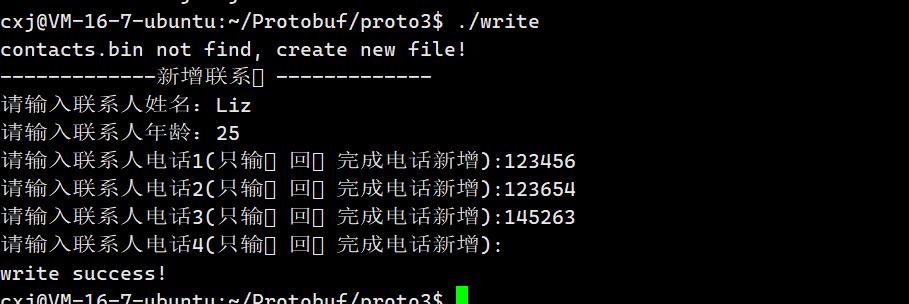 首先看最上方终端运行 ./write 的交互输出,程序启动后第一行打印 contacts.bin not find, create new file!,和我们代码里的判断逻辑完全对应,当前目录第一次运行程序,不存在历史二进制文件,文件流打开失败,直接跳过读取解析旧数据的分支,进入新增联系人流程。 随后终端打印分割线,启动 AddPeopleInfo 函数的交互式录入流程,我们依次输入姓名 Liz、年龄 25,接着连续输入三组不同手机号 123456、123654、145263,第四次输入时直接回车,触发字符串为空的判断,跳出电话录入循环,单条联系人信息全部录入完毕。 录入完成后程序执行序列化写入文件逻辑,没有出现报错信息,终端打印 write success!,代表顶层 Contacts 通讯录对象已经完整编码为二进制字节,成功持久存入本地磁盘文件,整套写入流程执行完毕。
首先看最上方终端运行 ./write 的交互输出,程序启动后第一行打印 contacts.bin not find, create new file!,和我们代码里的判断逻辑完全对应,当前目录第一次运行程序,不存在历史二进制文件,文件流打开失败,直接跳过读取解析旧数据的分支,进入新增联系人流程。 随后终端打印分割线,启动 AddPeopleInfo 函数的交互式录入流程,我们依次输入姓名 Liz、年龄 25,接着连续输入三组不同手机号 123456、123654、145263,第四次输入时直接回车,触发字符串为空的判断,跳出电话录入循环,单条联系人信息全部录入完毕。 录入完成后程序执行序列化写入文件逻辑,没有出现报错信息,终端打印 write success!,代表顶层 Contacts 通讯录对象已经完整编码为二进制字节,成功持久存入本地磁盘文件,整套写入流程执行完毕。
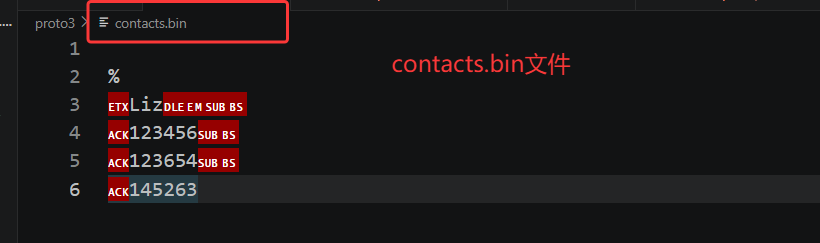 接下来看中间目录截图与 contacts.bin 文件内部展示,运行完程序后当前目录自动生成了 contacts.bin 文件,后缀 bin 代表这是二进制存储文件,直接用普通文本编辑器打开会出现大量乱码、特殊不可见控制字符,截图里也能看到 ETX、ACK 这类二进制控制符号混杂着我们输入的姓名、手机号明文片段。这里要再次明确 Protobuf 序列化的底层特性,它不会对文本做加密,只是纯二进制编码,原始字符串数据会直接保留在字节流里,所以我们能零星看到 Liz、123456 这类内容,但整体是分段二进制结构,不能直接当成可读文本编辑,手动修改文件字节会直接导致后续反序列化解析失败。
接下来看中间目录截图与 contacts.bin 文件内部展示,运行完程序后当前目录自动生成了 contacts.bin 文件,后缀 bin 代表这是二进制存储文件,直接用普通文本编辑器打开会出现大量乱码、特殊不可见控制字符,截图里也能看到 ETX、ACK 这类二进制控制符号混杂着我们输入的姓名、手机号明文片段。这里要再次明确 Protobuf 序列化的底层特性,它不会对文本做加密,只是纯二进制编码,原始字符串数据会直接保留在字节流里,所以我们能零星看到 Liz、123456 这类内容,但整体是分段二进制结构,不能直接当成可读文本编辑,手动修改文件字节会直接导致后续反序列化解析失败。
下面介绍一个工具,用来读取二进制序列 - hexdump -C
 因为普通编辑器无法直观浏览二进制文件完整结构,Linux 系统自带 hexdump 工具可以把 bin 文件转换成十六进制 + 明文对照格式,执行指令 hexdump -C contacts.bin就 能打印完整字节内容。 指令里 -C 参数的作用是同时展示十六进制字节码和对应的 ASCII 可见字符,截图红框区域清晰展示出我们录入的三组手机号数字,和我们终端输入的内容完全匹配,直观证明文件里确实完整存储了我们录入的联系人数据。这个工具是调试 Protobuf 二进制文件非常实用的手段,当后续文件解析报错、怀疑二进制数据损坏时,可以用这条命令查看文件内部存储的原始内容,快速定位数据缺失、错乱的问题。
因为普通编辑器无法直观浏览二进制文件完整结构,Linux 系统自带 hexdump 工具可以把 bin 文件转换成十六进制 + 明文对照格式,执行指令 hexdump -C contacts.bin就 能打印完整字节内容。 指令里 -C 参数的作用是同时展示十六进制字节码和对应的 ASCII 可见字符,截图红框区域清晰展示出我们录入的三组手机号数字,和我们终端输入的内容完全匹配,直观证明文件里确实完整存储了我们录入的联系人数据。这个工具是调试 Protobuf 二进制文件非常实用的手段,当后续文件解析报错、怀疑二进制数据损坏时,可以用这条命令查看文件内部存储的原始内容,快速定位数据缺失、错乱的问题。
read.cc
已经完成二进制文件写入与数据校验,下一部分我们编写配套 read.cc 读取解析代码,打开 contacts.bin 文件、从文件流反序列化恢复 Contacts 通讯录容器,循环遍历打印所有联系人、每条联系人的全部手机号,实现文件数据完整读取展示。
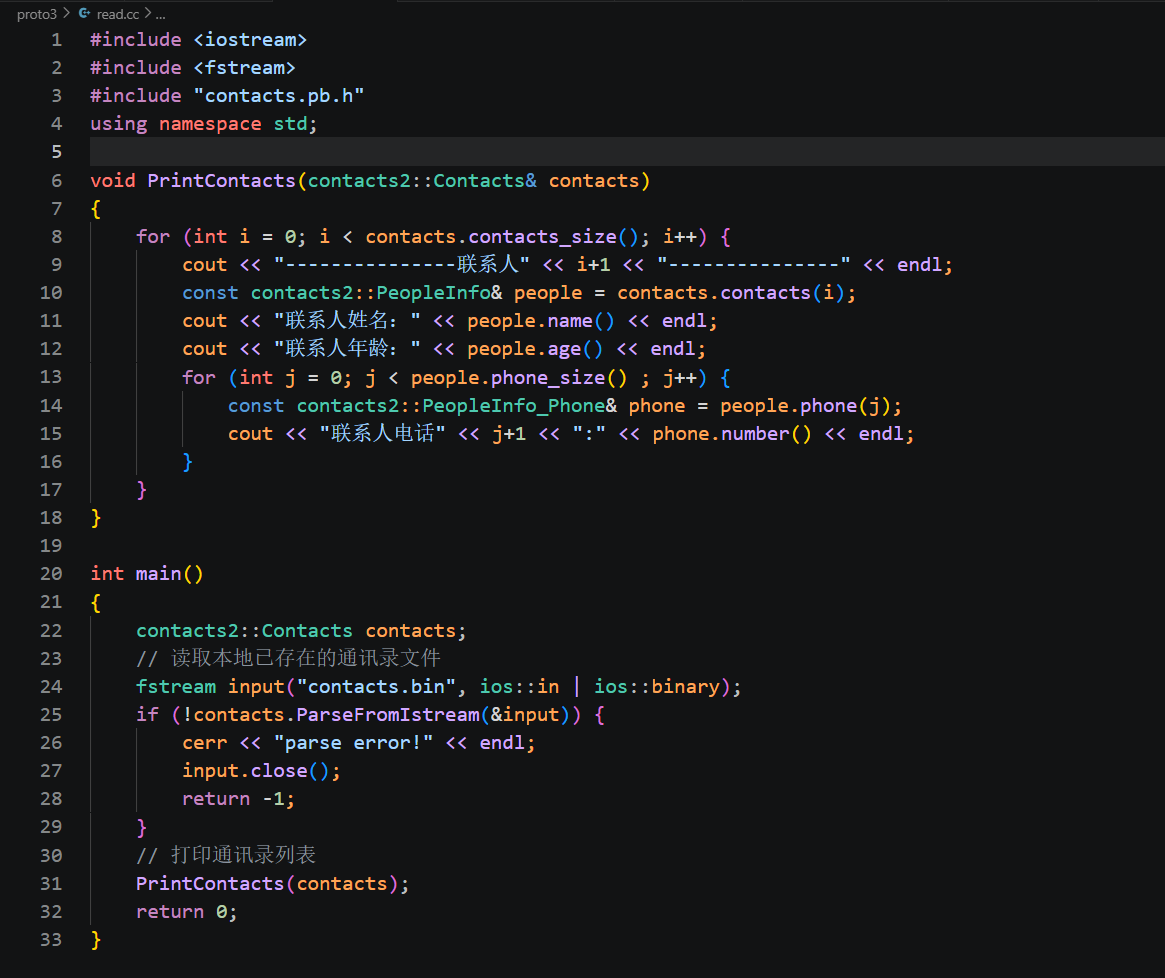 先看文件开头的头文件引入部分,前三行和我们之前写的 write.cc 保持一致,#include <iostream> 用来实现终端打印输出,#include <fstream> 提供文件流读取二进制文件的能力,#include "contacts.pb.h" 引入 protoc 生成的协议代码,程序才能识别 Contacts、PeopleInfo、PeopleInfo_Phone 这三个类以及配套的数组操作、文件流反序列化接口,using namespace std; 简化标准库调用写法,不用每次书写 std:: 前缀。
先看文件开头的头文件引入部分,前三行和我们之前写的 write.cc 保持一致,#include <iostream> 用来实现终端打印输出,#include <fstream> 提供文件流读取二进制文件的能力,#include "contacts.pb.h" 引入 protoc 生成的协议代码,程序才能识别 Contacts、PeopleInfo、PeopleInfo_Phone 这三个类以及配套的数组操作、文件流反序列化接口,using namespace std; 简化标准库调用写法,不用每次书写 std:: 前缀。
接下来是我们单独封装的打印工具函数 void PrintContacts(contacts2::Contacts& contacts),函数接收顶层通讯录容器的引用,作用是遍历整个通讯录,把所有联系人、每条联系人的姓名、年龄、全部手机号完整打印到终端,我们拆分两层循环来理解。 外层 for 循环用来遍历通讯录里所有联系人,循环终止条件依靠 contacts.contacts_size() 获取当前通讯录存储的联系人总数,循环变量 i 代表当前联系人的下标。循环内部调用 contacts.contacts(i) 按下标取出对应联系人的只读常量引用,这个接口我们之前讲过,属于 repeated 数组只读读取方法,只能读取字段不能修改数据,适配单纯打印展示的场景。拿到联系人对象后,直接调用 people.name() 读取姓名字符串、people.age()读取年龄数字,在终端分行打印出来。 内层嵌套 for 循环用来遍历当前联系人绑定的全部手机号,循环终止条件调用 people.phone_size() 获取该联系人的电话总条数,循环变量 j 是手机号数组下标,通过 people.phone(j) 取出单条 Phone 嵌套对象,再调用 phone.number() 读取存储的号码字符串,逐条打印每一个联系电话。两层循环嵌套刚好对应我们 proto 里两层 repeated 数组结构,外层遍历联系人列表,内层遍历单个联系人的多条电话。
往下进入程序入口 main 函数,第一行创建空的顶层通讯录容器对象 contacts2::Contacts contacts;,我们后续会把磁盘二进制文件里的数据全部解析填充进这个对象。 紧接着创建文件输入流 fstream input("contacts.bin", ios::in | ios::binary);,打开我们之前 write 程序生成的 contacts.bin 二进制文件,ios::in 代表只读模式读取文件,ios::binary 二进制标识必不可少,防止系统自动转换换行符破坏 protobuf 字节流,造成解析失败。 核心反序列化逻辑写在 if 判断中 if (!contacts.ParseFromIstream(&input)),ParseFromIstream 是适配文件流的反序列化接口,接收文件流指针作为输入型参数,函数会读取文件里全部二进制字节,按照 proto 协议规则解析,填充到我们本地的 contacts 通讯录对象中。函数返回布尔值,解析成功返回 true,如果文件损坏、二进制数据不合法就返回 false,进入错误分支打印解析失败提示,手动关闭文件流释放资源,异常终止程序。 如果文件读取、二进制解析全部执行成功,就调用我们封装好的 PrintContacts 函数,把填充完数据的通讯录容器传入,自动完成双层循环遍历,在终端完整打印全部联系人与对应电话信息。最后执行 return 0,代表读取打印流程正常结束。
运行结果:
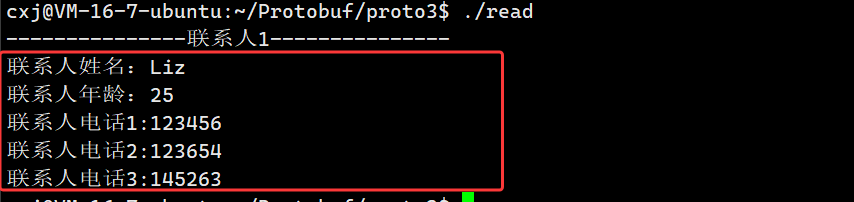 首先我们先看整条执行命令 ./read,这条指令运行我们之前编译生成的 read 可执行程序,程序启动后会直接打开本地的 contacts.bin 二进制文件,执行文件流反序列化逻辑,把磁盘里存储的二进制数据还原成内存中的 contacts2::Contacts 通讯录对象,再调用 PrintContacts 函数做双层循环遍历打印,最终输出截图里的全部内容。
首先我们先看整条执行命令 ./read,这条指令运行我们之前编译生成的 read 可执行程序,程序启动后会直接打开本地的 contacts.bin 二进制文件,执行文件流反序列化逻辑,把磁盘里存储的二进制数据还原成内存中的 contacts2::Contacts 通讯录对象,再调用 PrintContacts 函数做双层循环遍历打印,最终输出截图里的全部内容。
红框内第一行打印联系人姓名:Liz,这行数据来自我们之前运行 write 程序时手动输入的姓名字符串,程序通过 people.name() 这个 singular 字段的只读接口,直接取出反序列化后对象里的 name 字段值并输出,和我们写入文件时填写的内容完全一致,证明姓名字段完整解析成功。
第二行联系人年龄:25对应录入时填写的年龄数字,调用people.age()读取整型字段,二进制里存储的年龄数值被正常还原,没有出现数值错乱、丢失的情况。
下面三行连续的电话条目,对应我们当时录入的三组手机号,这里依靠内层循环遍历 repeated 嵌套 Phone 数组实现。程序先通过people.phone_size()拿到当前联系人一共有 3 条电话,循环下标 j 从 0 到 2 依次遍历,每一次调用people.phone(j)取出单条 Phone 对象,再用phone.number()读取号码字符串,逐条打印出电话 1、电话 2、电话 3 以及对应的号码 123456、123654、145263,三条录入的手机号全部完整读取出来,说明 repeated 数组、嵌套 message 结构的序列化、反序列化流程完全正常,多条数据不会丢失、错乱。
二、总结
1. 为什么分 write.cc 和 read.cc,各自作用、最终目的
核心原因:读写分开是两件完全相反的事,拆成两个文件好理解、好调试,真实开发里存文件、读文件也是分开两套逻辑,不会揉在一块乱成一团。
先单独说 write.cc 是干什么、最终目的是什么,不只是单纯加联系人。 write 的核心任务是「造数据 + 存到硬盘里」。新增联系人只是填充数据的步骤,它完整流程是先打开硬盘上的 contacts.bin 文件,如果之前存过联系人,就先把旧数据读到内存里;然后让我们手动输入新联系人的姓名、年龄、好几个手机号,把这条新人加到内存的通讯录列表末尾;最后一步才是序列化,把内存里全部联系人(旧的 + 刚新增的)转换成二进制,覆盖写到硬盘的 contacts.bin 文件里。 它序列化的最终目的,就是把程序内存里临时存在的数据,长久保存到电脑磁盘。程序一关,内存里的数据直接消失,但是二进制文件留在硬盘,下次开机、下次运行程序还能拿出来用。只新增联系人只是中间一步,序列化落地持久化才是它最核心的目标。
再单独说 read.cc 是干什么,它完全不新增、不修改任何数据。 read 的核心任务是「从硬盘取数据,展示给人看」。它一运行就打开同一个 contacts.bin 文件,读取里面的二进制字节,做反序列化,把硬盘里看不懂的二进制,重新变回程序能识别的联系人对象放到内存里;之后两层循环把姓名、年龄、所有手机号全部打印到终端。 它存在的意义就是校验,二进制文件打开全是乱码,人看不懂里面存了啥,跑 read 就能把存进去的内容原样打印出来,证明刚才 write 存的数据没丢、没损坏,序列化和反序列化是配对能用的。如果以后你别的程序要读取这份通讯录数据,写代码的逻辑和 read.cc 完全一模一样。
再合起来说为啥非要拆成两个文件,不写在同一个代码里。 第一件事是功能拆分,一件负责写入存储、一件负责读取查看,逻辑互不干扰。如果你写在同一个 main 里,运行一次又读又写,想单纯查看数据的时候还会不小心新增联系人,容易误改文件;分开之后,想加联系人就执行 ./write,只想查看现有通讯录就执行 ./read,操作干净不混乱。 第二件事是方便分开学习两种核心接口,write 专门演示序列化、文件输出流 SerializeToOstream;read 专门演示反序列化、文件输入流 ParseFromIstream,分开看代码不会两种逻辑混在一起,更容易分清序列化和反序列化两套相反操作的写法。 第三件事贴合真实项目场景,线上业务里写入数据、读取数据一般是两个独立模块,比如服务一个负责落盘存储,另一个负责查询读取,现在分成两个文件就是提前模拟这种分离开发的思路。
-
只要我们在.proto 里写一个 message,编译之后就一定会生成一个对应的 C++ 类,嵌套写在别的 message 里面的子 message 也不例外。 就像咱们这份协议,外层 Contacts 是一个 message,生成 Contacts 类;PeopleInfo 是一层 message,生成 PeopleInfo 类;里面嵌套的 Phone 子 message,编译器自动拼接名字生成 PeopleInfo_Phone 类,三个 message 对应三个独立的类,完全一一对应,不存在合并或者漏掉的情况。
-
每个类里面自动生成的所有操作方法,全都是跟着这个类自己内部定义的字段走的,一个字段配套一套专属函数。 如果是普通 singular 单字段,就生成 clear 清空、字段名读取、set 赋值这几个基础方法;如果是 repeated 数组字段,就多出来 add 新增、size 统计数量、按下标读取、修改下标元素这一堆数组专用接口,类里面有多少个字段,就会生成多少套对应的操作函数,不会多也不会少,完全跟着 proto 里写的字段走。
4. 这些字段、字段对应的操作方法,是不是全都属于这个 message 对应的类里面?
答案是全部都包裹在当前 message 生成的类内部,不会跑到别的类里。 举个例子,name、age、phone 这三个字段全都写在 PeopleInfo 这个 message 大括号里面,那 set_name ()、name ()、add_phone ()、phone_size () 这些所有操作函数,全部都定义在 PeopleInfo 类的 public 成员里,只有创建了 PeopleInfo 对象,才能调用这些方法,别的类比如 Contacts、PeopleInfo_Phone 根本访问不到这几个字段的接口。 再看嵌套的 Phone,number 字段写在内部子 message 里,set_number ()、number () 只能在 PeopleInfo_Phone 类里面调用,外层 PeopleInfo 不能直接操作 number,必须先拿到 Phone 子对象才行。 最外层 Contacts 里面只有 contacts 这个 repeated 字段,所以 Contacts 类里只有 add_contacts ()、contacts_size () 这类专属方法,和姓名、电话相关的函数一个都没有。
最后补充一层逻辑,package 包的作用是外层命名空间,和类内部字段互不冲突。 package contacts2 只是给这一整套三个类套了一层外层隔离壳子,避免和别的项目类名重名,真正的字段、操作函数,是封装在每一个独立 message 生成的类里面。包是最外层,然后里面一层是各个 message 对应的类,类内部才是字段配套的全部读写方法,层级关系分得很清楚。