本文系统梳理文档智能处理全链路技术:从底层OCR文字识别原理,到多格式文档(PDF/Word/PPT)解析,再到PaddleOCR-VL多模态解析、复杂元素处理、中文文本分割,最后深入RAG系统的四大评估指标。全文配有示意图,带你一文搞懂文档智能全貌。
📌 写在前面
在大模型应用如火如荼的今天,RAG(检索增强生成) 已经成为企业级AI应用的标配方案。但很多人不知道的是:RAG系统真正的难点,不在于检索算法有多花哨,而在于------你能不能把文档"喂"对给大模型。
一份PDF文档扔进来,里面有文字、表格、公式、图片、双栏排版......如果解析得好,大模型能精准回答;解析得稀碎,再强的LLM也只能"一本正经地胡说八道"。
本文将带你从最底层的OCR原理出发,一路打通文档解析、多模态处理、文本分割、RAG评估,形成完整的技术闭环。全文配有示意图,建议收藏⭐
一、OCR基础原理:像素是怎么"认字"的?
1.1 文字区域识别:OCR的"眼力"
很多人以为OCR就是"看图识字",其实OCR的第一步根本不是"认字",而是**"找字"**------先判断哪些像素块是文字,哪些不是。
OCR模型的工作流程分两步:
- 文字区域检测:在图像中找到所有可能包含文字的区域,画出 bounding box(边界框)
- 字符识别:对每个检测到的文字区域,识别出具体是什么文字
💡 关键认知:OCR模型没有语义理解能力,它只看像素分布。所以:
- 手写的"√"不符合文字规则 → 被当成非文字丢弃
- 一段Java代码因为缺乏排版规则 → 可能识别得一塌糊涂
- 特殊符号、艺术字 → 大概率识别失败或乱码
这就是为什么纯OCR方案在处理复杂文档时,效果总是差强人意。
1.2 坐标系与文字框定位
OCR识别完成后,不仅返回识别出的文字,还会返回每个文字块的坐标信息。这个坐标系非常重要,是后续多栏解析、版面分析的基础。

坐标系规则:
- 原点
O在图像左上角 - X轴向右递增
- Y轴向下递增(注意:和数学坐标系不一样!Y轴是向下的!)
- 文字框由4个顶点按顺时针顺序标注:A(左上) → B(右上) → C(右下) → D(左下)
**返回数据格式通常为:
[x1, y1, x2, y2, x3, y3, x4, y4, 识别文本, 置信度]其中:
- A点 = (x_min, y_min) = (x1, y1)
- B点 = (x_max, y_min) = (x2, y2)
- C点 = (x_max, y_max) = (x3, y3)
- D点 = (x_min, y_max) = (x4, y4)
📝 示例理解 :
假设一张1000×800像素的图片,左上角有一段文字"Hello World",它的文字框左上角在(100, 50),右下角在(300, 80)。
那么返回的坐标就是:`100, 50, 300, 50, 300, 80, 100, 80, "Hello World", 0.98
置信度0.98表示模型有多确定这就是"Hello World"。
1.3 单栏 vs 多栏文本解析
拿到了所有文字块的坐标,接下来就要把它们按阅读顺序排列起来。这一步看似简单,实则暗藏玄机。
单栏布局:直接按Y排序
对于单栏文档(比如普通的Word文档),文本是从上到下自然排列的。这时候不需要坐标信息,直接按OCR返回的顺序(或者按Y坐标从小到大排序)就可以了。
双栏/多栏布局:必须借助坐标重构顺序
论文、报纸、杂志常用双栏排版。如果直接按Y排序,左栏读到一半就跳到右栏去了,读起来乱七八糟。
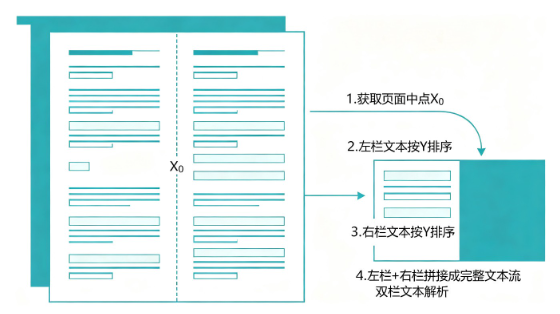
双栏解析的正确步骤:
- **获取页面宽度中点
X0 - 提取所有
X < X0的文本块 → 左栏 - 提取所有
X > X0的文本块 → 右栏 - 左栏按Y升序排列 → 右栏按Y升序排列
- 右栏内容拼接到左栏之后 → 完整文本流
📝 举个例子 :
假设页面宽度是1000像素,中点X0=500。
- 文本块A:x=200, y=100 → 左栏
- 文本块B:x=600, y=100 → 右栏
- 文本块C:x=200, y=200 → 左栏
直接按Y排序会得到:A → B → C(错误!右栏B插在中间了)
正确解析后:A → C → B(先读完左栏,再读右栏)
至于三栏、四栏的情况更复杂,需要先判断栏数,再用类似的分区域逻辑处理。
二、多格式文档解析实战:PDF/Word/PPT一网打尽
了解了OCR原理,我们来看看实际项目中怎么处理各种格式的文档。
2.1 PDF解析:文字 + 图片OCR
PDF是最常见的文档格式。一个完整的PDF提取器工作流程如下:
打开PDF → 遍历每一页 → 定位文字区域/图片区域
↓
文字区域 → 直接提取文字
图片区域 → 裁剪 → OCR识别
↓
合并所有文字 → 返回完整文本核心代码思路(Python + PyMuPDF):
python
import fitz # PyMuPDF
def extract_pdf_text(pdf_path):
doc = fitz.open(pdf_path)
full_text = ""
for page in doc:
# 1. 直接提取页面文字
text = page.get_text()
full_text += text
# 2. 获取页面中的图片
images = page.get_image_info()
for img in images:
# 过滤掉太小的图片(提升效率)
if img["width"] * img["height"] < 0.6 * 0.6: # 面积阈值
continue
# 裁剪图片 → 送OCR
# ocr_result = ocr_model(img_data)
# full_text += ocr_result
return full_text⚠️ 踩坑记录:图片面积阈值
一开始把阈值设得太高(宽/高占比都要 > 0.6),结果很多有效图片都被跳过了,比如"问答翻译"区域、模型架构图等都没被识别。调小阈值后,这些图片才成功被OCR提取。
建议:根据实际业务调整阈值,不要太严格。
2.2 Word解析:XML结构下的内容提取
很多人不知道,**Word文档(.docx)本质上是一个ZIP压缩包!把后缀改成.zip解压,里面全是XML文件。
文字、表格、图片、字体、颜色......所有内容都由XML标签定义,结构跟HTML很像。
Word解析的核心逻辑:
python
from docx import Document
from lxml import etree
def parse_docx(docx_path):
doc = Document(docx_path)
result = ""
for block in doc.iter_inner_content():
# 情况1:普通段落文字
if isinstance(block, Paragraph):
result += block.text + "\n"
# 情况2:表格
elif isinstance(block, Table):
for row in block.rows:
for cell in row.cells:
result += cell.text + "\t"
result += "\n"
# 情况3:图片(需要解析XML)
# 用lxml找图像节点 → 提取图片 → 送OCR
# ...
return result⚠️ 缺陷:提取出来的纯文本会丢失所有格式信息
- 表格结构没了(只剩\t分隔)
- 标题层级没了
- 图文位置关系没了
- 字体颜色样式全没了
这就是为什么后面我们需要Markdown格式输出的原因------至少能保留一些结构。
2.3 PPT解析:形状识别与递归处理
PPT的基本单位叫形状(shape)。每个形状可能是文字、表格、图片,或者组合形状。
PPT形状类型判断:
| 形状属性/类型 | 内容类型 | 说明 |
|---|---|---|
shape.has_text_frame |
文字 | 有文本框的形状 |
shape.has_table |
表格 | 包含表格的形状 |
shape.shape_type == 13 |
图片 | 图片类型的形状 |
shape.shape_type == 6 |
组合形状 | 可能包含文字+图片,需递归解析 |
⚠️ 注意:PPT模板里的背景文字、固定页脚,因为用户不可选中,所以也提取不出来。只能拿到用户可编辑区域的内容。
2.4 图像文件:直接OCR
对于图片格式的文档(比如扫描件转成的PNG/JPG),就直接调用OCR模型识别文字即可,最简单。
三、PaddleOCR-VL:多模态文档解析的新范式
前面讲的都是"传统OCR"------只能识别文字。但现实中的文档哪有那么简单?公式、表格、图表、流程图......这些纯OCR根本搞不定。
这时候,多模态OCR就登场了。
3.1 从"文字识别"到"语义理解"
PaddleOCR-VL(视觉语言版)是百度飞桨推出的多模态文档解析模型。它不只是认字,而是能理解文档结构,直接输出结构化的Markdown或JSON。
当前最新版本: PaddleOCR-VL 1.6(2024年5月更新)
- 识别准确率:96.3%
- 模型大小:0.9B参数
- 支持元素:文本、公式、表格、图表、图片、古籍、生僻字、印章......
3.2 核心能力对比
| 能力 | 传统OCR | PaddleOCR-VL |
|---|---|---|
| 文字识别 | ✅ | ✅ |
| 公式识别(LaTeX) | ❌ | ✅ |
| 表格结构还原 | ❌(纯文本拼接 | ✅(HTML/Markdown表格 |
| 统计图表理解 | ❌ | ✅(多模态理解) |
| 多栏排版解析 | 需要手动处理 | ✅(自动还原阅读顺序) |
| 代码块识别 | ❌ | ✅ |
| 输出格式 | 纯文本 | Markdown / JSON |
💡 PP-StructureV3 vs PaddleOCR-VL 怎么选?
- PaddleOCR-VL:适合直接输出Markdown/JSON,给大模型用
- PP-StructureV3:提供更细粒度的坐标信息,适合需要二次解析坐标的场景
3.3 国产化与硬件支持
做政务、金融领域的同学注意了!PaddleOCR-VL支持:
- NVIDIA GPU(常规选择)
- Intel GPU(没错,Intel不只有CPU)
- 华为昇腾NPU(国产化刚需,银行/政府项目必备)
⚠️ 项目实施注意事项 :
写项目材料时,要注意模型发布时间和项目时间线的一致性。比如你2023年的项目,就不能用2024年才发布的模型,否则逻辑上就说不通。
如果项目周期较早,可以用更早的通用PaddleOCR模型(非VL版),那个已经稳定多年了。
四、复杂文档元素处理策略
文档解析不是提取出内容就完事了。提取出来之后,怎么处理各种复杂元素,直接关系到后续RAG系统的效果。
4.1 表格处理:小则保,大则分
表格是文档里最常见的复杂元素。处理原则很简单:
-
小表格 (比如几行几十行):整体保留,不要切分,让大模型自己理解。
-
大表格 (比如超过1000行):必须切分 ,但每个子表格都要保留原始表头!
📝 **为什么要保留表头?
假设你有一个员工信息表:
姓名 部门 薪资 张三 技术部 20000 ... ... ... 如果切分后子表格没有表头,大模型看到"李四 市场部 15000",根本不知道这三列分别是什么意思。保留表头,语义才完整。
跨页表格怎么处理?
PDF里的表格经常跨页。处理思路有两种:
- 规则法:如果上一页末尾和下一页开头都是表格结构,就认为是同一个表,直接合并。
- 模型法:让大模型来判断这两个表格是不是同一个,再决定合不合并。
4.2 图片处理:两条路径
图片处理不是一刀切,要看业务需求:
图片进来
↓
有文字的图片?(如截图、证照
├─ 是 → OCR提取文字 → 文字进知识库
└─ 否 → 结构图/流程图/架构图
↓
多模态模型生成图片摘要 → 摘要文本进知识库💡 什么意思呢?
- 如果图片里主要是文字(比如一张代码截图、一张发票照片)→ 用OCR把字抠出来就行。
- 如果图片是架构图、流程图、示意图→ OCR出来零零碎碎几个字根本没用 → 让多模态模型看完整张图,生成一段文字描述,用这段描述代替原图进知识库。
4.3 统计图表:转表格化处理
柱状图、饼图、折线图这些统计图表,通常已经被转换成表格形式的数据了。所以处理逻辑和普通表格一样------小的保留,大的切分保表头。
如果没有原始数据,就需要多模态模型(比如PaddleOCR-VL、UCL-VL)来理解图表内容。
4.4 公式:专用模型
数学公式是标准OCR的噩梦。必须用专用模型:
- Mathpix:效果最好,但是付费的
- 其他开源公式OCR模型
🏆 一句话总结:规则优先,模型兜底。能靠规则搞定的,就别上模型;规则搞不定的,再让模型来。
五、中文文本分割:给大模型"喂"对内容
文档解析完了,得到了一大段文字。接下来要做的就是文本分割(Text Splitting)------把长文本切成一个个小块(chunk),才能存进向量数据库。
别小看这件事,切得好不好,直接决定了RAG检索的效果。切太碎了上下文不全,切太大了检索不准。
5.1 规则分割:中文标点的妙用
最简单的分割器是基于字符的分割器。英文用空格、换行符来切。但中文不一样,中文的语义边界靠标点。
**中文专用分隔符优先级(从高到低):
- 句号
。------ 语义最完整 - 冒号
:、问号? - 分号
; - 逗号
,------ 实在不行才用
💡 分割优先级的思路:尽量在语义完整的地方切。能在句号处切,就别在逗号处切。切出来的每个chunk语义越完整,后续检索效果越好。
5.2 语义模型分割:让AI来帮你切
规则分割虽然简单,但不够智能。最好的方案,是用能理解语义的模型来切。
实际项目中常用的是 **nlp_bert_document_segmentation_chinese_base ------ 基于BERT的中文文档分割模型。
python
from modelscope.pipelines import pipeline
# 加载语义分割模型
seg_pipeline = pipeline(
task="document-segmentation",
model="damo/nlp_bert_document_segmentation_chinese_base"
)
# 输入文本,自动分割
result = seg_pipeline(document=text)
# 输出以\n\n分隔的分割结果模型会自动找到语义边界,切出来的chunk质量比规则法高到不知道哪里去了。
5.3 环境踩坑血泪史
说多了都是泪。语义分割模型虽好,但环境配置能把人搞疯。
**典型依赖冲突链:
运行语义分割代码
↓
transformers版本太高 → 降级到4.48.3
↓
modelscope版本又不对 → 继续调
↓
setuptools版本太高(82+)→ 降到65左右
↓
... 无限套娃⚠️ 经验教训:
- **不要让AI智能体直接改你的本地环境!!!AI只会越改越乱
- 关键文件(requirements.txt、pyproject.toml)一定要提前备份
- 包冲突这种事,最终还是得手动试错,AI帮不上什么大忙
六、RAG系统评估:四大黄金指标详解
文档解析好了,文本切好了,RAG系统搭起来了。然后呢?怎么衡量你的RAG系统好不好?
这就需要RAG评估框架。目前最主流的是 Ragas(Retrieval-Augmented Generation Assessment)。
6.1 评估框架概览
RAG系统的流程是:
用户问题 → 检索上下文 → 大模型生成答案所以评估也要分成两大模块:
- 检索模块(Retrieval):找得准不准、全不全
- 生成模块(Generation):答得对不对、有没有瞎编
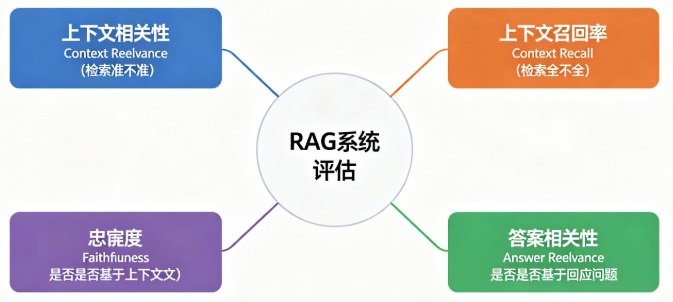
四大核心指标:
| 指标 | 模块 | 衡量什么 | 一句话 |
|---|---|---|---|
| 上下文相关性 Context Relevance | 检索 | 检索内容和问题相关吗? | 准不准 |
| 上下文召回率 Context Recall | 检索 | 该找的都找到了吗? | 全不全 |
| 忠实度 Faithfulness | 生成 | 答案是基于上下文的吗? | 有没有幻觉 |
| 答案相关性 Answer Relevance | 生成 | 答案回答了问题吗? | 对不对 |
💡 理解任何指标,都要回答两个问题:
- 这个指标**是干什么的、有什么用?
- 这个指标**怎么算出来的?
6.2 上下文相关性(Context Relevance):检索准不准?
干什么用的:衡量检索到的内容和用户问题的相关程度。核心是判断检索结果是不是**只包含回答问题需要的信息,惩罚冗余和无关内容。
分数低 → 检索出来一堆没用的,噪音多
分数高 → 检索内容精准,相关性强
怎么算的:
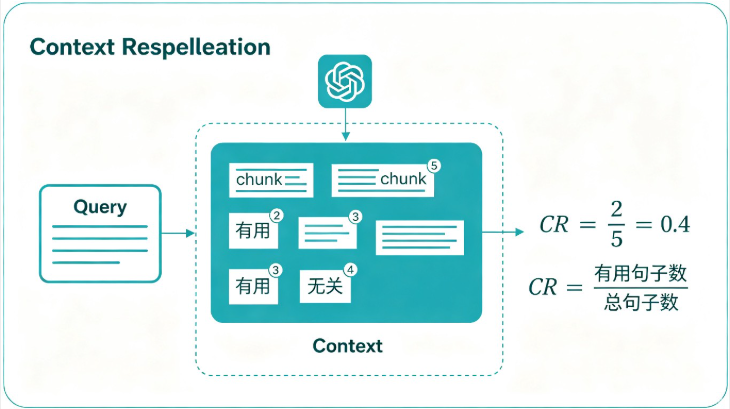
计算分两步:
-
用大模型从上下文中抽取对回答问题"有用"的句子,组成集合 S
- 不能改原句子,一个chunk算一个句子单位
- 一个都没用 → 返回0分
-
计算公式:
CR = 有用句子数 / 总句子数
📝 举个具体例子:
用户问题:什么是RAG?
检索到的上下文(5个chunk):
- RAG(检索增强生成)是一种结合检索系统... ← 有用 ✅
- 大语言模型(LLM)的训练数据有截止日期... ← 背景,算有用?→ 有用 ✅
- 向量数据库的选型对比... ← 无关 ❌
- RAG的工作流程分为检索和生成两部分... ← 有用 ✅
- 今天天气真好 ← 无关 ❌
有用句子数:3,总句子数:5
上下文相关性 CR = 3/5 = 0.6
⚠️ 注意事项:
- 句子划分是以输入时的分隔符(比如
\n\n)为单位,不是按句号切- 即使一个chunk里面有好几句话,整体也算一个句子单元
- 评估结果要人工复核!不能完全信大模型说的,偏低的时候一定要人工看看抽取得合不合理
6.3 上下文召回率(Context Recall):检索全不全?
干什么用的:衡量检索出来的内容够不够全面,能不能覆盖回答用户的问题。
相关性是"准不准",召回率是"全不全"------标准答案里的信息,你检索到了多少?
怎么算 :
用标准答案(ground_truth)里的信息点,有多少能在检索到的上下文里找到。
Recall = 能在上下文中找到的信息点 / 标准答案总信息点📝 例子 :
标准答案里有3个关键点,检索到的上下文里只覆盖了2个 → 召回率 = 2/3 = 0.67
6.4 忠实度(Faithfulness):有没有幻觉?
干什么用的:衡量生成的答案是不是严格基于检索到的上下文,有没有大模型自己瞎编的内容。
这是防止"一本正经地胡说八道"的关键指标。
怎么算 :
把答案拆成一个个陈述(statement),看每个陈述能不能在上下文里找到依据。
Faithfulness = 有依据的陈述数 / 总陈述数6.5 答案相关性(Answer Relevance):回答对不对?
干什么用的:衡量生成的答案是不是有效、完整地回应了用户的问题。
忠实度高不代表回答得好。比如答案全是从上下文里摘的,但答非所问,那也不行。
七、总结与展望
7.1 全链路技术全景
我们从最底层的OCR原理,一路走到了RAG评估,形成了完整的技术链路:
文档输入
↓
OCR文字识别 + 多模态解析
↓
多格式文档解析(PDF/Word/PPT/图片
↓
复杂元素处理(表格/图片/公式/图表
↓
中文文本分割
↓
向量化 → 向量数据库
↓
检索 → 大模型生成答案
↓
RAG系统评估(四大指标)7.2 技术趋势
-
从"文字识别"到"语义理解":多模态OCR已经成为标配,不只是认字,还要懂结构、懂语义。
-
结构化输出是桥梁:Markdown/JSON格式的输出,是连接OCR和大模型应用的核心桥梁。纯文本提取的时代已经过去了。
-
规则优先,模型兜底:能靠规则搞定的别上模型,成本和效率都更优。复杂场景再让大模型上场。
-
环境管理是痛点:AI开发中,环境依赖管理依然是最大的痛点之一。未来对一体化、稳定的开发环境需求越来越强烈。
-
一体化文档智能:未来的方向是"OCR + 结构理解 + 语义还原"的一体化文档智能系统。
🎯 写在最后
文档智能处理这个领域,看起来简单,实则水很深。从像素级的OCR,到语义级的RAG评估,每一环都有每一环的坑。
但核心思路是清晰的:**一切为了让大模型能"看懂"文档。只要围绕这个目标,所有的技术选型、方案设计,就都有了方向。
希望这篇长文能帮你建立起文档智能处理的完整知识体系。如果觉得有用,欢迎点赞👍 收藏⭐ 关注🚀 三连支持!
参考资料:
- PaddleOCR 官方文档
- Ragas 评估框架
- 飞桨深度学习平台