具身智能"大小脑":过渡妥协还是终极架构?
去年春晚,一群机器人扭着秧歌登上舞台,动作整齐划一。但鲜有人知道,这些看似流畅的表演背后,藏着无数次"摔跤"和重来。一位英特尔专家直言,网上那些机器人"奔跑跳跃"的视频大多经过剪辑优化,现实中让机器人完成一个简单的抓取动作,成功率都低得惊人。
这撕开了具身智能领域最核心的矛盾:我们到底该让机器人怎么"思考"?答案正在两条截然不同的技术路线之间激烈博弈。
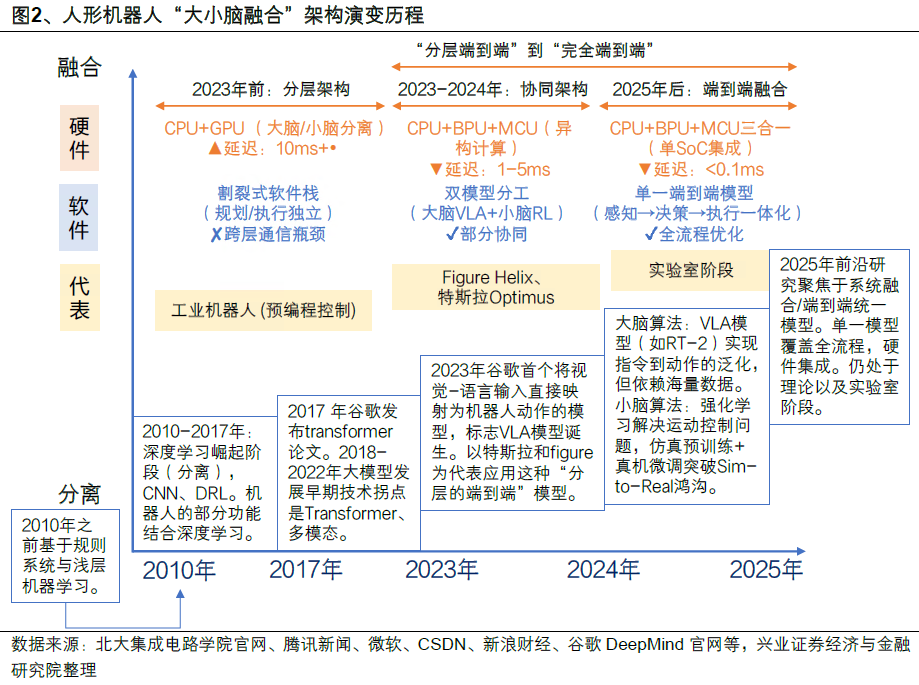
分层架构的思路,源于一个朴素的仿生学逻辑------模仿人类的神经机制。大脑皮层负责高级认知,小脑处理实时运动协调,各司其职。在机器人身上,这种分工被具象化为两套硬件系统:"大脑"通常是一块高性能GPU,运行多模态大模型,负责理解指令、规划任务;"小脑"则是x86 CPU或专用MCU,将抽象计划转化为毫秒级的关节指令。

这套方案的好处很实在。英特尔中国区边缘计算事业部高级总监李岩指出了一个关键细节:传统方案中大脑和小脑分属不同芯片,通信延迟会导致机器人摔跤 。而分层架构让各自专注所长------大脑可以慢慢"想",小脑确保执行"快"。浙江人形机器人创新中心首席科学家熊蓉也认可这种思路,她认为如果大量数据需要从大脑传到小脑处理,延迟本身就是个巨大阻碍。目前,绝大多数能走进工厂实训的机器人,都采用这套方案。它用确定性的分工,换来了当下最稀缺的落地能力。
但另一条路线直接挑战了这个逻辑:为什么非要分工?
端到端模型的支持者认为,分层架构本身就是一种妥协。真正的通用智能,应该像人类一样,从视觉、语言输入直接生成动作输出,中间没有任何人为拆解。这就是VLA(视觉-语言-动作)模型的核心主张------一个神经网络吃进所有感知数据,直接吐出关节指令。
特斯拉Optimus是这条路线最激进的践行者。它用一个神经网络,直接从摄像头原始数据映射到35个自由度的关节指令,省去了状态估计、运动规划等所有中间环节。理论上,这种架构的泛化能力最强------机器人不需要为每个新任务单独编程,而是像人一样"看着学着就会了"。
但这条路的代价同样巨大。端到端模型对数据的渴求是指数级的。自变量机器人CEO王潜曾打过一个比方:"一台超级计算机每秒可进行千万亿次浮点运算,但光是模拟人晃动杯中水这一个动作,就可能需要它算十分钟。"物理世界的交互数据,远比互联网文本稀缺、昂贵且难以获取。
一条路线用确定性分工换取当下的可靠性,另一条路线押注极致的简洁换取未来的泛化能力。这不是对错之争,而是理想与现实之间的鸿沟。
两条路线的核心分歧,本质上是对"智能"的理解不同:分层派认为智能可以被拆解为可工程化的模块,端到端派则认为任何人为拆解都会损失泛化潜力。而真正让行业焦虑的是------我们是不是被困在了一个必经的过渡阶段?
二、现实枷锁:为何分层架构是当前难以跳过的"妥协方案"
端到端模型的愿景极具诱惑------一个模型解决所有问题。但物理世界的复杂性很快给理想浇了冷水。分层架构之所以成为主流,并非因为它在理论上更优雅,而是因为它是当前技术条件下唯一能同时满足可靠性、安全性与成本控制的务实选择。这不是路线偏好问题,而是生存问题。
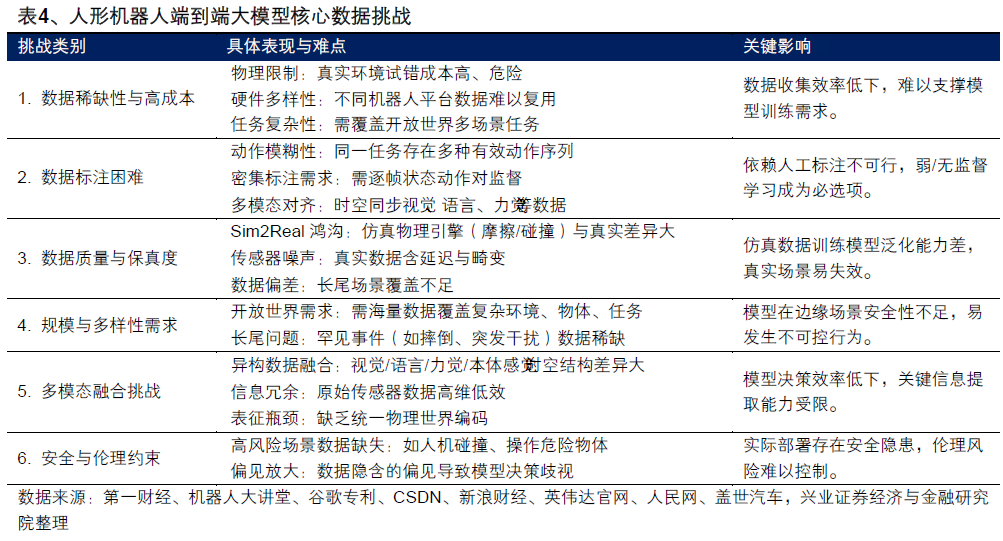
数据与实时性瓶颈:端到端模型受困于物理世界数据匮乏与毫秒级响应要求
端到端模型面临的第一道枷锁,是物理世界数据的极度匮乏。
与ChatGPT依赖的互联网文本数据不同,具身智能需要的训练数据必须包含视觉、运动轨迹、力反馈等多维信息。自变量机器人创始人王潜曾给出一个直观的对比:仅模拟人晃动杯中水这一个动作,就需要一台超级计算机运算十分钟。

互联网数据是"现成的",物理世界的数据是"造出来的"------两者在获取成本上有数量级的差距。
这种高昂成本使得端到端模型难以覆盖真实世界的长尾场景。你可以在仿真环境中训练一万次抓取杯子,但机器人一旦面对破碎的杯子、湿滑的杯子、被遮挡的杯子,泛化能力就会急剧下降。
更棘手的是实时性挑战。机器人的运动控制需要在毫秒级周期 内完成从感知到执行的全流程闭环。传统大小脑分离方案中,大脑与小脑之间的网络通信延迟,已经足以让机器人在动态动作中摔跤。
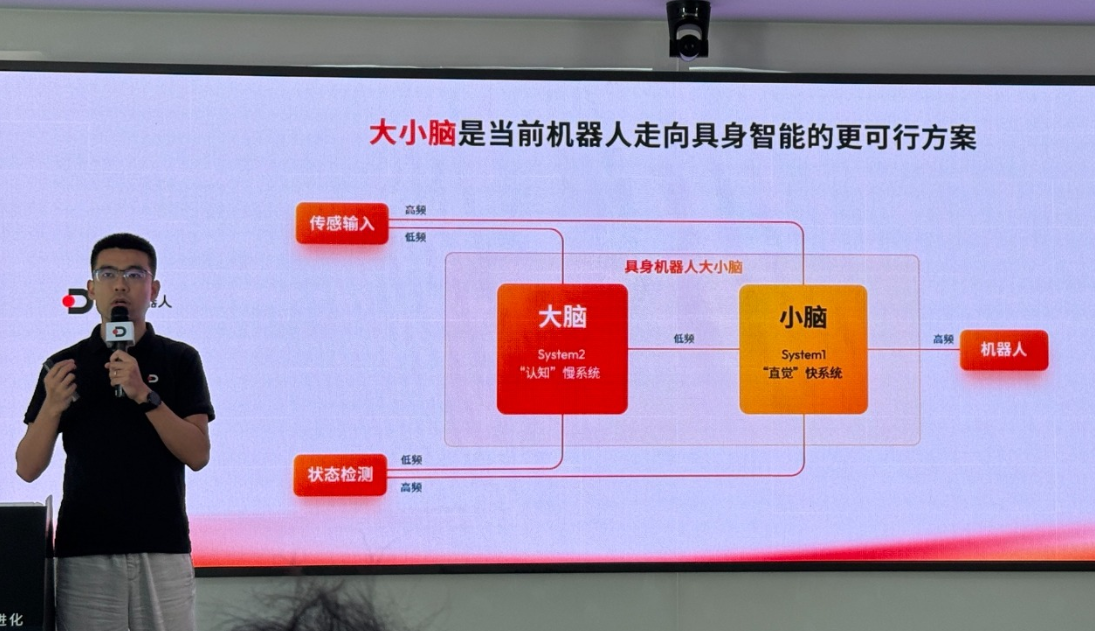
端到端模型将整个流程压缩进单一网络,虽然避免了通信延迟,却要求这个巨型网络在极短时间内完成推理------这对算力和算法效率都提出了近乎苛刻的要求。英特尔中国边缘计算事业部高级总监李岩指出,这正是大小脑融合方案试图解决的核心痛点:通过共享内存消除系统级延迟。
成本与黑盒风险:双芯片高成本与单一网络不可解释性的两难抉择
分层架构的代价是双芯片带来的高成本与高功耗。
大脑通常依赖昂贵的GPU,小脑则使用x86 CPU,两套系统不仅推高了硬件成本,还增加了体积和开发复杂度。这正是英特尔推出大小脑融合SoC、地瓜机器人推出2499元算控一体开发套件的市场驱动力------行业迫切需要降低这个"妥协方案"的代价。
但端到端模型同样面临严峻的**"黑盒风险"**。
当机器人执行异常动作时,单一神经网络像人类直觉反应一样工作,却完全没有解释自身决策的能力。这种不可解释性在工业场景中是致命的:一旦发生碰撞事故,无法定位根因,安全迭代便无从谈起。
分层架构的核心优势恰恰在于:模块解耦意味着故障可以被隔离、追溯和修复。
黑盒特性还导致硬件供应链的脆弱性------单一组件漏洞可能引发系统性失效。这对于当前尚处于"0到0.1阶段"的人形机器人商业化落地,是不可或缺的安全网。理想很丰满,但没有人敢把不可解释的黑盒放进工厂、家庭和医院。
三、终局推演:双系统融合能否成为通往通用智能的渐进路线
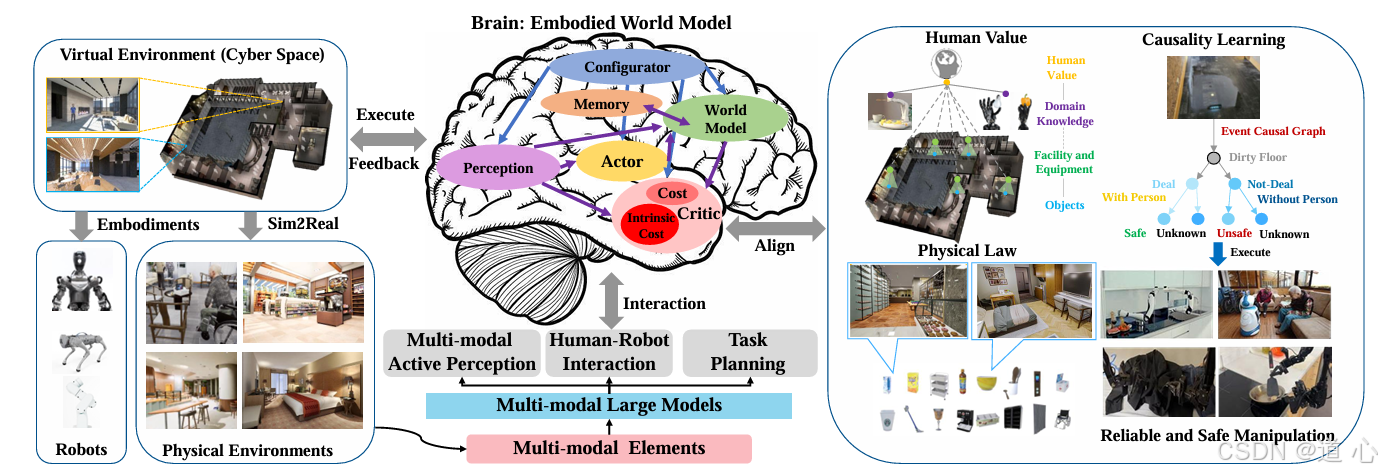
当业界在分层与端到端之间争论不休时,一条中间路线正在浮出水面------它既不放弃端到端的泛化愿景,又保留了分层架构的工程可行性。这不是和稀泥,而是对物理规律的尊重。
VLA模型的内在分层:以类人"快慢思考"实现端到端形态下的功能分工
VLA(视觉-语言-动作)模型被公认为具身智能的核心范式,但鲜有人注意到,真正跑通的VLA方案内部,往往暗藏分层设计。
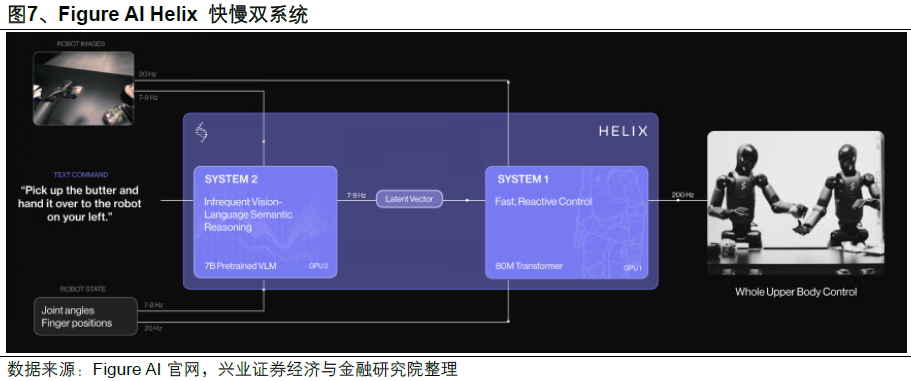
Figure AI的Helix模型 是典型案例。它采用了借鉴人类认知的"双系统"设计:System 2(规划者) 基于70亿参数的视觉语言模型,负责任务规划和场景理解;System 1(执行者) 是轻量化神经网络,负责将抽象指令转化为35个自由度的精确关节动作。
这不是妥协,而是对物理规律的尊重。认知决策需要深度推理,运动控制要求毫秒级响应,两者在硬件层面天然需要不同的计算特性。
浙江人形机器人创新中心首席科学家熊蓉也指出,如果所有数据都要从"大脑"传到"小脑"处理,延迟本身就是障碍。VLA模型的内在分层,本质上是在端到端框架内,用"快慢思考"的机制实现了功能解耦。
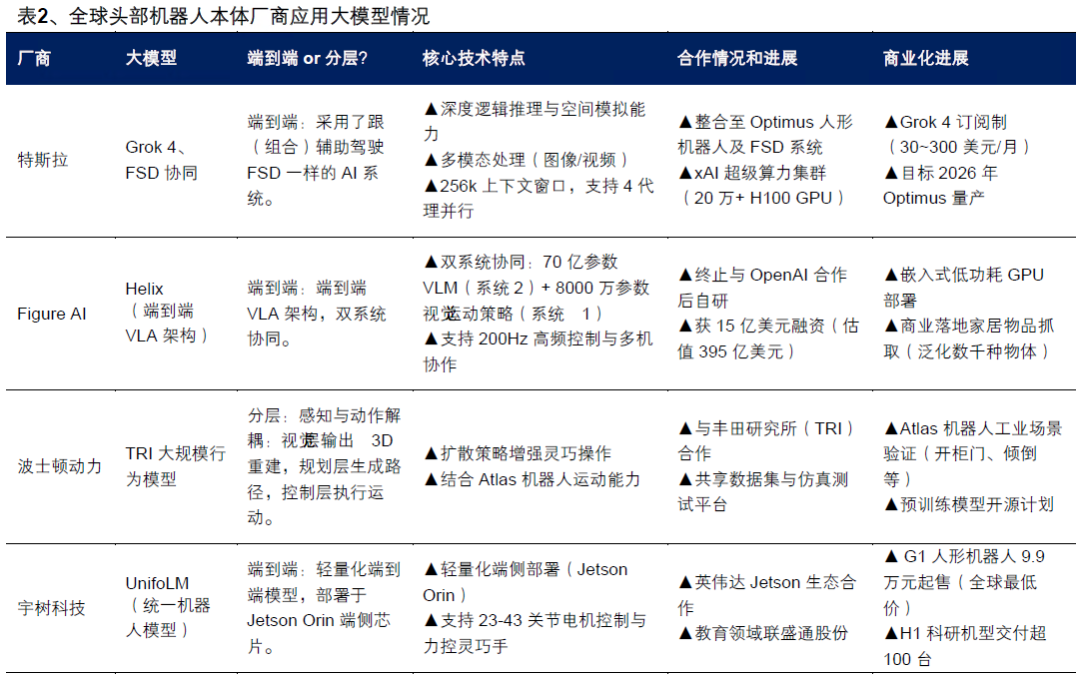
这正是Figure AI、智元机器人 等头部厂商的共同选择------不是非此即彼,而是在端到端的大框架下,保留分层执行的小结构。
从专用到通用的跨越:当前架构是否为通往终极形态的唯一可行路径?
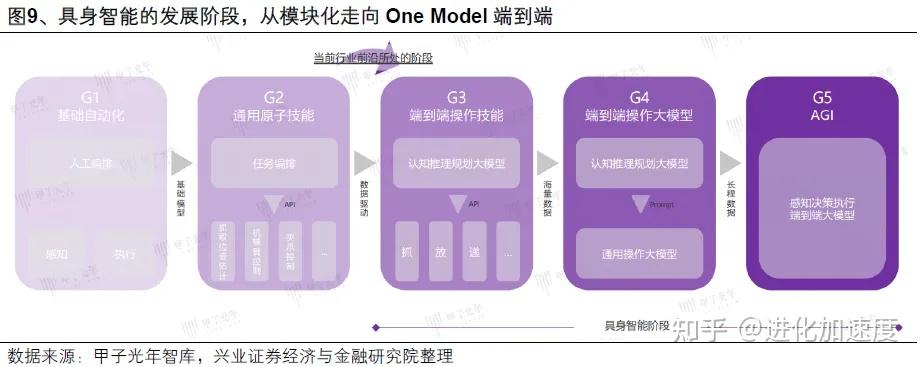
智元机器人定义的路线图给出了清晰答案:G1到G5的渐进演化。
当前具身智能处于G2-G3阶段------大脑已具备认知推理能力,小脑通过深度学习驱动技能训练。随着场景和数据增多,多个专用小模型将逐步泛化为通用操作大模型,最终与上层认知模型融合。
这不是理论推演,而是正在发生的实践。特斯拉Optimus复用Autopilot的BEV+Transformer架构,宇树科技从汽车电机控制技术迁移至43自由度人形机器人------技术一脉相承,算法与零部件高度复用。
但必须正视现实差距。优必选的规划分两步走:第一阶段 在新能源汽车制造场景完成搬运、分拣等测试验证;第二阶段才拓展至中等难度任务,逐步实现规模商业化。
通往One-Model终局的路,必须经由G2、G3、G4逐个击破。跳不过,也急不得。
分层架构不是终极方案,但它是当前约束条件下,通向终极的唯一可行路径。 当数据规模、模型泛化性、响应速率等瓶颈逐个突破后,端到端融合才会水到渠成。在此之前,任何试图跳过"妥协阶段"直奔终局的做法,都可能倒在物理世界的复杂性面前。