Github:https://github.com/ScienceOne-AI/S1-Omni-Image
模型:
https://hf-mirror.com/ScienceOne-AI/S1-Omni-Image
https://modelscope.cn/models/ScienceOne-AI/S1-Omni-Image
论文:https://arxiv.org/abs/2606.24441
📖 简介
S1-Omni-Image 是中国科学院科学一团队针对科学场景开发的多模态统一模型,支持科学图像理解、科学图像生成和科学图像编辑,并统一于单一模型中。
该模型基于科学多模态推理基础模型 S1-VL-32B ,采用统一的 Think-Before-Generate(先思考后生成) 范式。在给定用户指令和可选输入图像后,模型首先生成任务导向的推理、文本响应以及任务特定的标记。随后,该推理过程的隐藏状态被用于指导后续的图像生成或编辑。该模型针对科学插图生成和文本渲染进行了优化,并进一步将科学图像分割、医学图像转换和医学图像超分辨率统一整合到图像编辑框架中。
相较于主流开源模型,S1-Omni-Image 显著提升了科学插图生成的质量,在多个科学图像编辑基准测试中取得领先成绩,同时保留了 S1-VL-32B 的科学图像理解和推理能力。
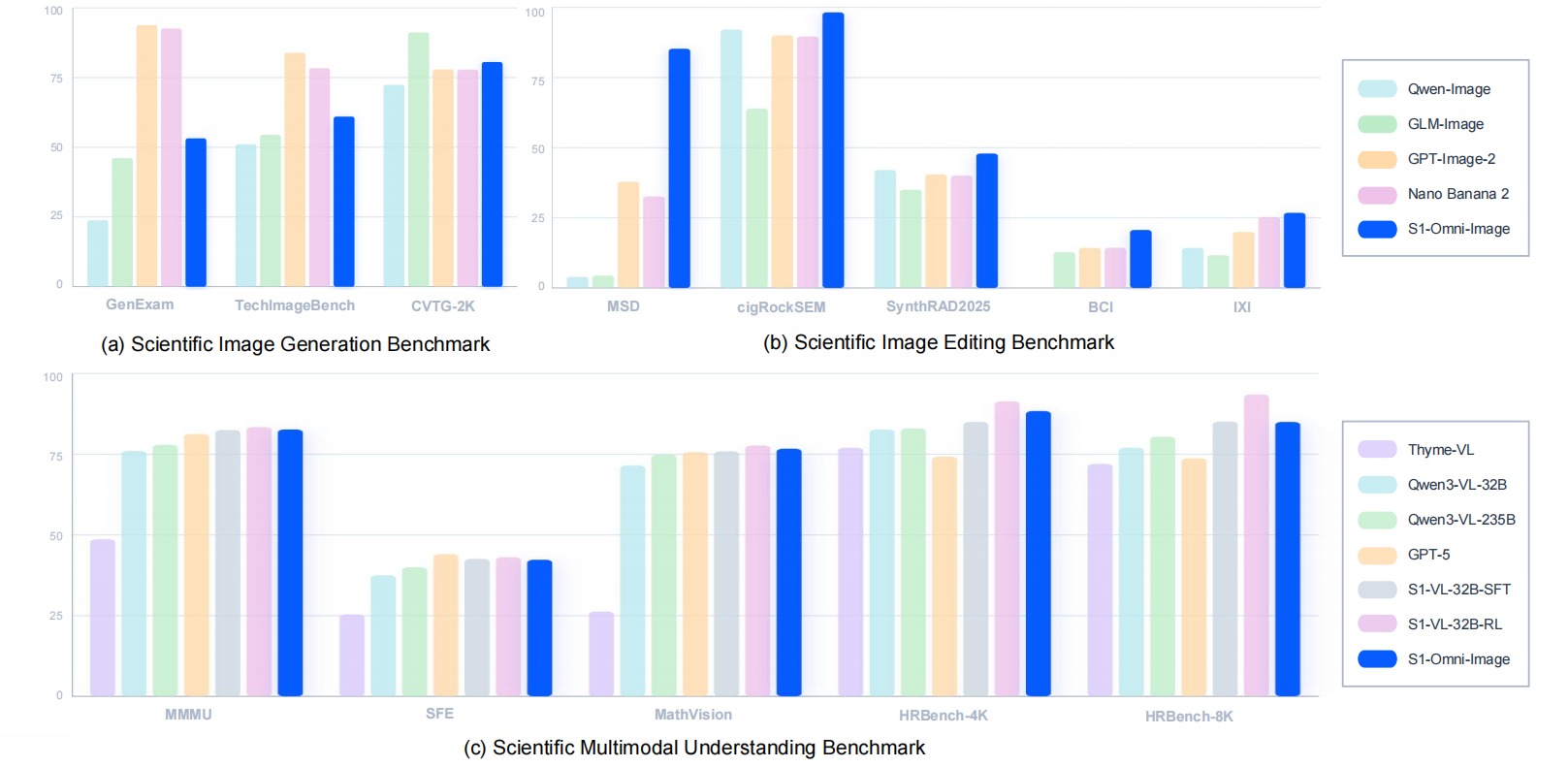
📥 模型与数据集
模型权重及SciGenEdit-10K数据集已发布于Hugging Face和ModelScope平台。
模型权重
| 平台 | 链接 |
|---|---|
| Hugging Face | ScienceOne-AI/S1-Omni-Image |
| ModelScope | ScienceOne-AI/S1-Omni-Image |
SciGenEdit-10K数据集
| 平台 | 链接 |
|---|---|
| Hugging Face | ScienceOne-AI/SciGenEdit-10K |
| ModelScope | ScienceOne-AI/SciGenEdit-10K |
🎨 效果展示
科研图像生成
以下示例展示了S1-Omni-Image在科研图像生成中的代表性能力,包括跨学科、多格式及富含文本的科学插图生成。

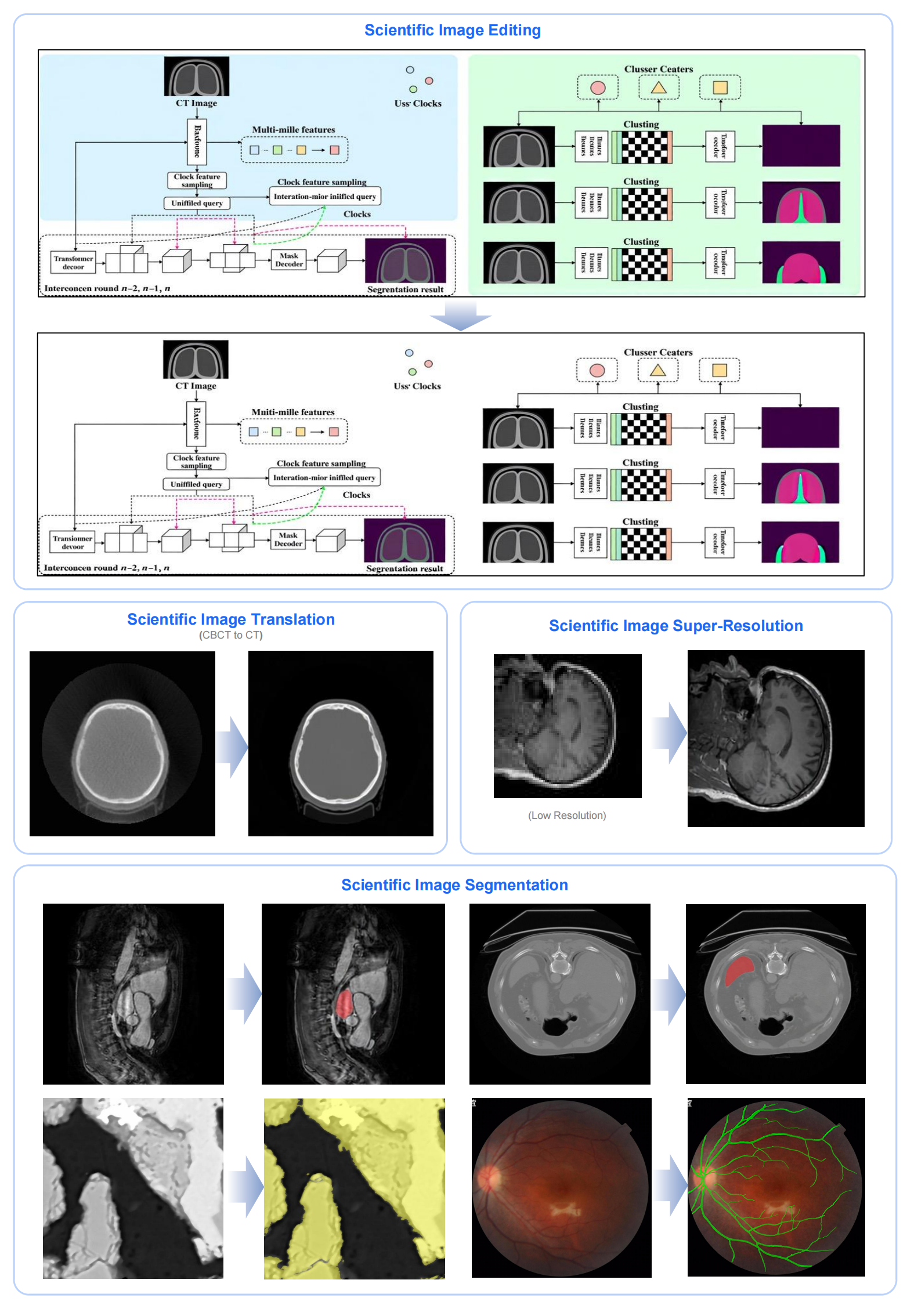
科学图像编辑
以下示例展示了S1-Omni-Image在科学图像编辑中的代表性能力,包括科学插图编辑、科学图像分割、医学图像转换以及医学图像超分辨率。
🧠 模型架构
S1-Omni-Image的整体架构如下所示。该模型采用S1-VL-32B作为科学多模态推理基础模型,能够理解用户指令、输入图像及科学上下文,并生成显式推理轨迹、文本响应和任务特定标记。图像生成与编辑模块采用MMDiT架构,其权重初始化自Qwen-Image-Edit的MMDiT权重。随后通过推理-扩散对齐层,将S1-VL-32B的隐藏状态映射至MMDiT模块的条件空间,从而驱动最终的图像生成或编辑过程。
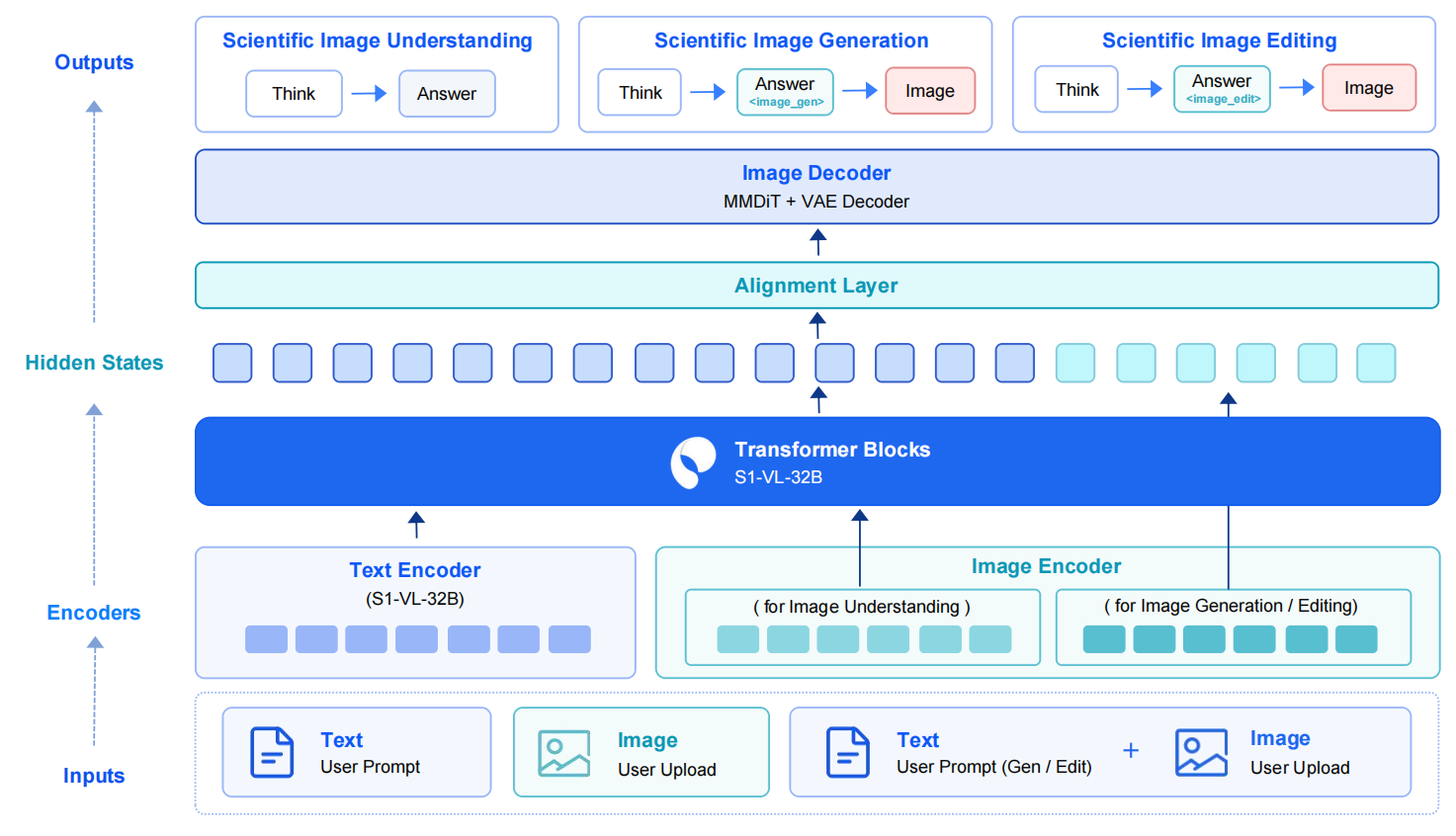
在文本响应和图像理解任务中,模型直接使用视觉语言模型的文本分支生成答案。对于图像生成和图像编辑任务,模型会发出<image_gen>或<image_edit>任务标记,并利用自回归生成过程中的隐藏状态作为扩散条件。这种设计避免了仅向图像模型输入简短提示,转而通过科学推理为视觉生成提供更丰富的语义和结构指导。
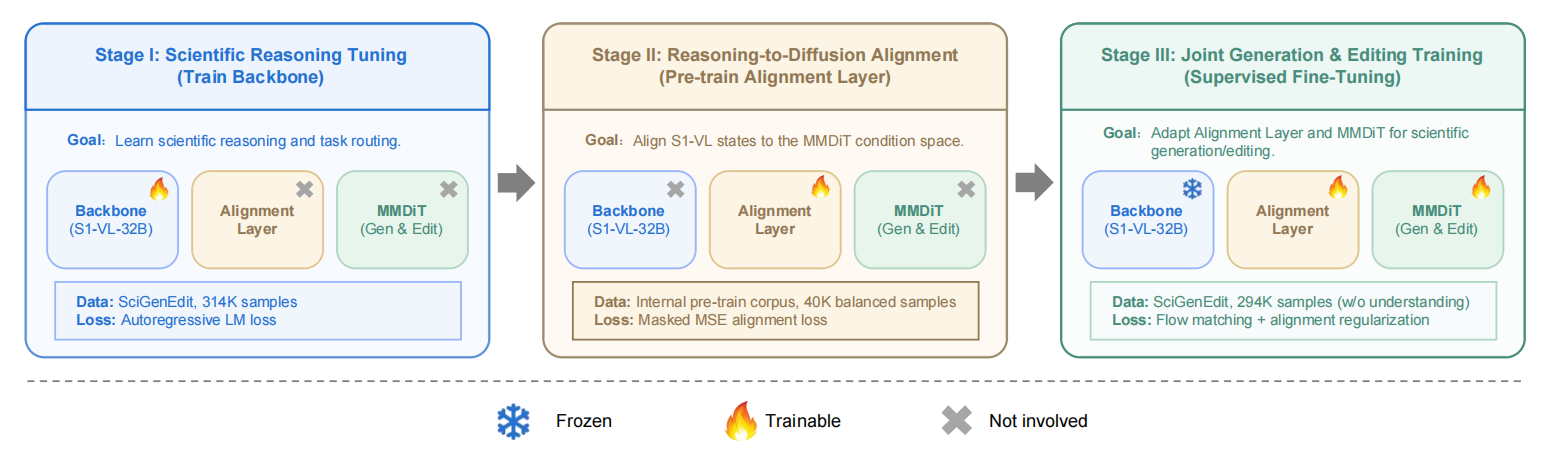
该模型通过三个阶段进行训练:
- 第一阶段:使用完整的SciGenEdit数据集,在科学推理范式下训练S1-VL-32B模型,使其能够为科学图像任务生成面向任务的推理、文本响应以及任务特定标记。
- 第二阶段:在预训练数据上训练推理到扩散的对齐层,将S1-VL-32B的隐藏状态映射到图像生成模块的条件空间中。
- 第三阶段:在SciGenEdit提供的图像生成与编辑数据上联合训练对齐层和图像生成模块,使科学推理的隐藏状态能够稳定驱动最终的图像生成与编辑。
🗂️ 训练数据
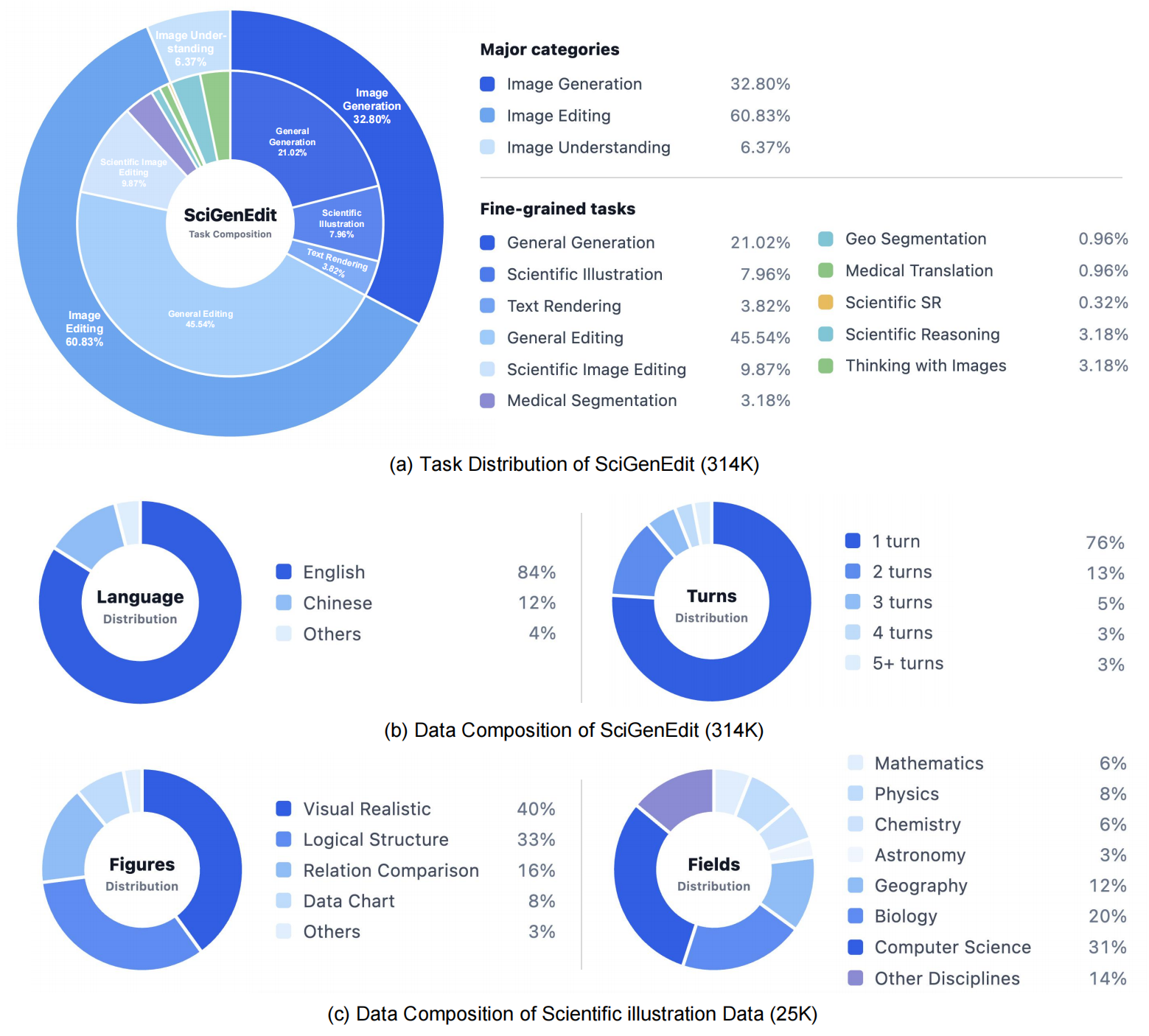
我们构建了SciGenEdit 训练数据集,涵盖三大任务类别:科学图像理解、科学图像生成和科学图像编辑。完整数据集包含约314K样本。图像生成数据针对科学插图、结构图、复杂文本渲染及科学可视化;图像编辑数据涵盖科学插图编辑、医学与地理图像分割、医学图像转换以及医学图像超分辨率;图像理解数据用于保留科学图像理解能力和"以图思考"能力。
为支持社区研究,我们发布了SciGenEdit-10K公开子集,该子集采样自完整训练数据,覆盖主要任务类型和代表性科学场景,可用于模型分析、指令格式参考以及未来科学图像生成与编辑研究。
🚀 快速开始
S1-Omni-Image 提供推理服务代码和与 OpenAI Chat Completion 兼容的 API。有关详细的环境设置、模型加载、API 参数和 Python 示例,请参阅 GitHub 仓库:
bash
git clone https://github.com/ScienceOne-AI/S1-Omni-Image.git
cd S1-Omni-Image
pip install -e ".[server]"下载模型权重后,将完整的 S1-Omni-Image/ 模型目录放置到磁盘任意位置并启动服务:
bash
s1-omni-image-serve \
--model /path/to/S1-Omni-Image \
--host 0.0.0.0 \
--port 8000服务启动后,可通过访问 http://localhost:8000/ 使用网页界面,或调用 /v1/chat/completions 接口实现统一的科学图像理解、生成与编辑。
⚠️ 局限性说明
尽管S1-Omni-Image专门针对科学图像生成与编辑进行优化,当前版本仍存在以下限制:
- 复杂文本渲染:长文本、密集标注及复杂中文内容仍可能出现拼写错误、错别字或字形模糊
- 细粒度局部编辑:复杂指令、多对象编辑及强约束的局部修改可能存在执行不充分或空间错位
- 通用图像美学:模型侧重科学图像任务,在开放域自然图像生成或创意设计方面可能不及前沿通用模型
- 专业可靠性:涉及医疗或科研等高风险场景时,模型输出需经领域专家审核,不可直接用于诊断、实验或决策
📄 许可证
本项目采用Apache License 2.0开源协议,使用时请同时遵守底层基础模型、数据集及第三方组件的授权条款。
📚 引用规范
若S1-Omni-Image对您的研究或应用有所帮助,请引用我们的工作:
bibtex
@article{li2026s1omniimage,
title={S1-Omni-Image: A Unified Model for Scientific Image Understanding, Generation, and Editing},
author={Li, Qingxiao and Wang, Zikai and Wang, Qingli and Xu, Nan},
journal={arXiv preprint arXiv:2606.24441},
year={2026}
}