面试问题
Agent面试题满分回答:Agent 的核心组件有哪些?
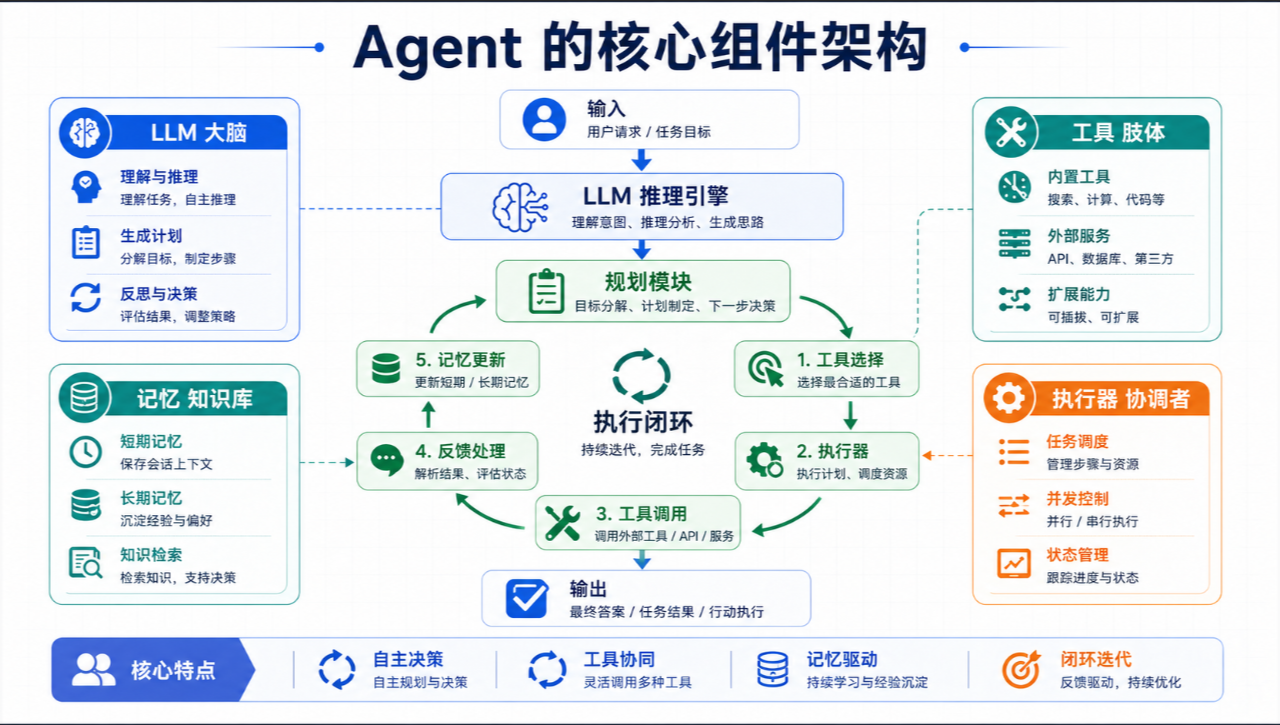
满分回答:
我认为一个生产级的完整Agent包含五大核心组件:**推理引擎、工具集、记忆系统、规划模块和执行控制,**五个缺一不可,少一个就只能叫"带工具的 LLM"或者"固定 workflow",算不上完整的 Agent。
**第一,推理引擎(LLM)。**负责理解目标和做决策。看 prompt(目标 + 历史 + 工具列表)→ 决定下一步做什么 → 输出 action 或者最终答案。不直接干活。
| 关键点 | 说明 |
|---|---|
| 核心职责 | 理解目标、制定计划、选择行动、反思结果 |
| 输入 | Prompt = 目标 + 历史上下文 + 工具列表 |
| 输出 | 下一步 Action(调用哪个工具传什么参数)或 最终答案 |
| 关键原则 | 不直接干活------只做决策,具体的执行交给工具 |
| 性能瓶颈 | 推理质量直接决定 Agent 上限。同样的架构,GPT-4 和弱模型跑出来的效果可以差好几个数量级 |
第二,规划模块(Planner) 。规划负责把"用户目标"翻译成"可执行步骤序列"。它的核心职责不是写流水账,而是将模糊目标(比如'帮我调研竞品动态')转化为带依赖关系的DAG子任务。依赖关系清晰:是线性执行还是可以并行,需要一个 DAG 而不只是 list,这里的关键是'粒度控制'------子任务必须足够大以节省Token,又足够小以便验证。更重要的是支持 replan:计划中途失效时能局部调整,不必全部推翻重来,遇到执行失败时只修枝,不砍树。
| 关键点 | 说明 |
|---|---|
| 核心职责 | 把模糊的用户目标翻译成可执行的子步骤序列 |
| 输出形式 | DAG(有向无环图),而非简单的 List------显式标明哪些步骤可并行、哪些有依赖关系 |
| 粒度控制(关键) | 子任务要"足够大以节省 Token,又足够小以便验证"------太细了依赖爆炸、累计误差大;太粗了执行器不知道怎么动 |
| 动态重规划 | 计划中途失效时局部调整(只修枝,不砍树) ,不必全部推翻重来。一失败就整体 replan 是常见的反模式,Token 成本扛不住 |
第三,执行模块(Executor )。把这些串起来,负责调度、反馈处理和终止判断。它把规划好的DAG放进状态机里跑,负责工具调用的参数绑定 和返回值解析 。执行控制最大的价值在于异常分级处理------网络超时它自己重试;搜索无结果它尝试换词;只有遇到逻辑死锁或连续3次失败,它才触发全局重规划或请求人工介入。同时,它内置步数熔断器,杜绝死循环。
| 关键点 | 说明 |
|---|---|
| 核心职责 | 把 Planner 输出的 DAG 放进状态机里跑,调度工具调用、处理反馈、判断是否完成 |
| 参数绑定 | 维护工作记忆(Working Memory) ,负责工具间的变量传递(如 A 的输出 {"temp":26} 自动注入 B 的入参) |
| 异常分级处理(核心价值) | ① L1 瞬态错误 (网络超时)→ 静默重试(指数退避,最多 2-3 次) ② L2 数据异常 (搜索无结果)→ 换同义关键词再试 ③ L3 逻辑死锁/连续失败 → 触发局部/全局 Replan ④ L4 高危操作 → Human-in-the-Loop 审批 |
| 终止判定(三重保险) | ① 硬上限 (max_steps、max_tokens、超时) ② LLM 自判 (每 N 步问一次"进展如何") ③ 外部 Verifier (用规则或另一个模型验证输出是否满足目标) 三个任意一个触发就结束,不能只靠 LLM 自己说 finish |
第四,工具模块(Tools),
工具让 Agent 真正能"做事"而不只是"说事"。工具的几个设计要点:
- 描述要精准:LLM 靠描述来选工具,描述模糊就选错
- 数量要控制:超过 20 个工具时,LLM 的选择准确率会明显下降;大量工具建议分组或层级管理
- 输出要可解析:工具返回值要结构化,方便 LLM 读懂 observation
常见工具分类:搜索类(网络搜索、数据库查询)、计算类(计算器、代码执行)、操作类(文件读写、API 调用、消息发送)
| 关键点 | 说明 |
|---|---|
| 核心职责 | 让 Agent 能真正"做事"而不只是"说事"------搜索、计算、API 调用、文件读写等 |
| 描述要精准(最关键) | LLM 完全靠描述来选工具。反面:"get_data": "获取数据";正面:"search_flight": "当用户需要查询航班时使用,参数包含出发地、目的地、日期,返回航班号、价格列表" |
| 数量控制 | 超过 20 个工具时,LLM 的选择准确率会明显下降 |
| 分组/层级管理(解法) | 先让 LLM 选"工具分类",再从分类里选具体工具,把大问题变成两步小问题。工具数量极大时还可做工具检索(向量化工具描述,按需检索) |
| 返回值结构化 | 工具返回值要结构化(JSON),方便 LLM 读懂 Observation |
第五,记忆模块(Memory)。维护上下文连贯性------短期放 context window,长期放向量库。特别注意的是,执行过程中的工作记忆(比如上一步的API返回结果)必须由Executor显式维护,不能全塞给LLM的Context Window,否则成本爆炸。
| 关键点 | 说明 |
|---|---|
| 短期记忆 | 当前 Context Window 中的内容,存放本次对话或任务的上下文,有容量限制(一般 8K~128K tokens) |
| 工作记忆(Executor 维护) | 执行过程中的中间状态、工具调用的参数和返回值、步骤间传递的数据------这部分不能全塞给 Context Window,否则成本爆炸 |
| 长期记忆 | 向量数据库存的历史经验、知识文档,用语义检索按需拉取 |
| 窗口溢出处理 | ① 摘要压缩 (把早期对话压缩成一段话) ② 向量化存储 (按需检索最相关的几条) ③ 两者可结合使用 |
| 遗忘机制 | 长期运行需加重要性评分(访问频率 × 时效性衰减 × 任务相关度),低分记录定期压缩或删除,防止向量库被噪声塞满 |
这五个组件缺失任何一个,都只能叫'带插件的聊天机器人'。规划负责想清楚'做什么',执行负责保证'做得稳',推理引擎负责'怎么做好',三者在闭环循环(Plan→Execute→Observe→Reflect)中缺一不可。
加分项&高平追问
一、规划与执行模块(深度追问)
Q1:ReAct 和 Plan-and-Execute 的本质区别是什么?什么时候用哪个?
回答要点:
ReAct(Reasoning + Acting)是"边想边做"------每走一步先思考(Thought),再行动(Action),拿到观察结果(Observation)后继续下一轮。它的核心价值在于让模型能基于中间结果动态调整后续动作,把"静态提示词"升级成"可迭代决策过程"。
Plan-and-Execute 是"先想好再做"------规划模块先输出完整任务 DAG,执行模块按图依次或并行执行。
选型原则:
-
任务步骤少(≤5步)、依赖简单 → ReAct 足够,延迟低、实现简单
-
任务步骤多、依赖复杂、需要并行 → Plan-and-Execute,Planner 用强模型出框架,Executor 用弱模型跑动作,成本可降低 40%~60%
-
面试加分句:"ReAct 适合'探索型'任务(不知道几步能做完),Plan-and-Execute 适合'确定型'任务(步骤边界清晰)"
Q2:规划和执行控制可以合并吗?
小任务可以。ReAct 就是典型的"边规划边执行",没有独立的规划模块。但任务复杂度上来之后,分离规划和执行效果更好------Planner 用强模型,Executor 可以用弱模型,省成本。【你已有的回答】
Q3:Plan-and-Execute 模式下,Planner 和 Executor 用什么模型?为什么?
回答要点:
-
Planner 用强模型(GPT-4、Claude 3.5 Sonnet):负责全局拆解和依赖分析,对推理能力要求高
-
Executor 可以用弱模型(GPT-3.5、Llama-3、Qwen 轻量版):工具调用遵循严格的 OpenAPI Schema,只需要"按图执行 + 参数绑定",不需要强推理
-
面试加分句:"这种设计叫'异构模型编排'------把推理密集型任务和执行密集型任务解耦,是生产级 Agent 降本的核心手段"
Q4:Planner 输出的规划粒度怎么控制?太细或太粗分别有什么问题?
回答要点:
-
太细(如"抬起右手→握紧刀柄→向前移动 5cm"):LLM 每步都要决策,累计误差爆炸,Token 成本扛不住
-
太粗(如"做好饭"):Executor 不知道怎么执行
-
正确粒度 :"可验证的原子任务"------每个子任务有明确的输入、输出和成功标准(如"调用搜索 API 获取今日天气")
-
面试加分句:"判断粒度是否合适有一个标准------这个子任务能不能用 1-2 个工具调用完成?如果需要 3 个以上,说明粒度太粗,还需要再拆"
二、工具调用与管理
Q5:工具多了怎么管?
分组管理或层级管理。比如先让 LLM 选"工具分类",再从分类里选具体工具,把大问题变成两步小问题。工具数目极多的情况下还可以做工具检索(把工具描述做向量化,按需检索相关工具)。【你已有的回答】
Q6:Function Calling 到底是怎么工作的?能不能说清楚完整链路?
这是面试官区分"看过概念"和"真正做过"的经典题。
回答要点(完整链路 5 步):
-
定义工具:开发者把工具的名称、描述、参数 JSON Schema 传给模型
-
模型推理:模型根据用户输入判断是否需要调用工具
-
返回意图:如果需要,模型返回结构化的工具调用意图(工具名 + 参数)
-
程序执行 :业务系统先做参数校验,再真正执行工具
-
结果回传:工具返回值结构化后传回模型,进入下一轮
关键澄清(很多人会答错) :
Function Calling 是"模型告诉你该调哪个工具、传什么参数",不是模型自己去执行。真正执行的是你的后端程序。
Q7:工具描述(tool description)为什么非常重要?
回答要点:
-
模型完全靠描述来选工具------描述模糊 = 选错工具
-
好的描述应该包含:何时用、何时不用、参数含义、错误示例、返回格式
-
反面案例 :
"get_data": "获取数据"→ 模型不知道是获取什么数据、从哪获取、什么格式 -
正面案例 :
"search_flight": "当用户需要查询航班信息时使用,参数包括出发城市、到达城市、日期,返回航班号、价格、起飞时间列表" -
面试加分句:"工具描述本质上是在给 LLM 写'API 使用说明书',说明书写得越清楚,模型用错的概率越低"
Q8:工具调用的常见工程坑有哪些?
回答要点(来自真实工程踩坑) :
-
描述模糊 → 模型选错工具
-
参数类型错乱 → 模型传参格式不对
-
权限缺失 → 工具能调但没权限执行
-
无降级方案 → 工具挂了整个 Agent 崩溃
-
不可观测 → 不知道工具调用耗时、失败率
-
连环调用打爆下游 → Agent 在循环里疯狂调 API
-
越权访问 → 模型调了不该调的工具
-
返回值非结构化 → LLM 读不懂工具返回了什么
三、记忆系统
Q9:记忆超出上下文窗口怎么处理?
两种策略:①摘要压缩(把早期对话摘要成一段话,压缩掉细节);②向量化存储(把历史存到向量库,每步按需检索最相关的几条),两者可以结合用。【你已有的回答】
Q10:上下文管理不只是"窗口满了怎么办"------上下文问题有哪几种?
这是面试官觉得你"有深度"的关键题。
回答要点(拆成 4 种问题) :
-
窗口容量不够:要塞的东西太多,窗口爆了 → 解法:摘要压缩、向量检索
-
关键信息被淹没(Lost in the Middle):窗口没爆,但模型忘了中间的重要信息 → 解法:关键信息放开头或结尾、定期提醒
-
工具返回撑爆上下文:工具返回 5000 token,80% 是噪声 → 解法:工具返回值只取关键字段
-
多步推理上下文膨胀:每步的 Thought + Action + Observation 都留着,越滚越大 → 解法:压缩历史推理步骤
Q11:Memory 用向量库就够了吗?
回答要点:
-
不够。向量检索擅长"相似度匹配",但弱于"精确约束"和"多跳关系推理"
-
工程上常见方案 :向量库 + 关键词检索 + 结构化库 + 知识图谱(按需组合) ,同时维护元数据和权限
-
面试加分句:"向量库适合'模糊检索'(如'找类似的问题'),但如果是'精确查询'(如'订单号 ORD-2024-001 的状态'),需要先用关键词或结构化索引精确命中,再用向量做语义补充"
Q12:长期记忆的写入和遗忘机制怎么设计?
回答要点:
-
写入 :任务结束后异步写入,不阻塞主链路
-
遗忘 :用重要性评分 = 访问频率 × 时效性衰减 × 任务相关度,低分记录定期压缩或删除,避免向量库无限膨胀
-
面试加分句:"记忆系统如果不加遗忘机制,长期运行后向量库会塞满噪声,检索召回率反而下降------这不是存储问题,是检索信噪比问题"
四、容错与失败处理
Q13:Agent 的失败处理策略是什么?
分四级:单步失败 → 重试(最多 2-3 次);反复失败 → 局部 replan;方向性错误 → 整体 replan;replan 还不行 → Human-in-the-Loop。一失败就整体 replan 是常见的反模式,token 成本根本扛不住。【你已有的回答】
Q14:工具调用失败了怎么办?------ 更细致的追问
这是面试官最常追着问的"工程落地题" 。
回答要点(分层处理) :
-
指数退避重试:失败后等 1s、2s、4s 再试,最多 3 次
-
重试前让 LLM 反思 :"刚才哪里错了?是不是参数不对?要不要换一个工具?"------这叫 Self-Correction(自我修正)
-
重试耗尽后降级:换一个备用工具,或走规则引擎
-
写操作必须做幂等 + Checkpoint:失败后能回滚到上一个干净状态
Q15:LLM 幻觉(Hallucination)怎么处理?
回答要点:
-
幻觉比工具失败更难检测,因为没有报错信号
-
策略一(Self-Consistency) :对关键推理结果采样 3 次,少数服从多数
-
策略二(交叉验证) :用第二个模型做 Fact-check
-
策略三(高风险操作强制 HITL) :不管模型多确定,写操作必须过人工确认
Q16:Human-in-the-Loop(HITL)的插入点怎么设计?
回答要点:
-
三种插入范式:条件边中断、Tool 节点拦截、状态机断点
-
判断标准 :信息检索类任务(搜索、摘要)失效率 < 2%,状态变更类操作(取消订单、修改配置、发送通知)失效率 8%~15%
-
设计原则 :低风险任务全自动,高风险操作在执行前插入人工审核节点
-
面试加分句:"HITL 不是给 AI 加枷锁,是让 AI 值得被信任------在 AI 跑偏之前先把它拽回来"
五、终止与评估
Q17:如何判断 Agent 是否完成了任务?
三重保险:硬上限(max_steps、max_tokens、超时)+ LLM 自判(每 N 步问一次"进展如何")+ 外部 verifier(用规则或另一个模型验证输出是否满足原始目标)。三个任意一个触发就结束,不能只靠 LLM 自己说 finish。【你已有的回答】
Q18:终止条件具体有哪些?能不能说全?
回答要点(组合使用):
-
模型主动声明 finish
-
任务清单全部完成(Executor 维护的 DAG 所有节点 done)
-
达到步数上限(max_steps)
-
达到 Token 预算上限
-
超时
-
连续无进展检测(连续 N 步没有实质进展)
-
外部成功信号(如测试通过、API 返回成功码)
生产环境必须有硬上限防止死循环------不能只靠 LLM 自己说 finish
Q19:怎么评估 Agent 的好坏?有哪些指标?
回答要点:
-
任务成功率(最主要):完成目标的比例
-
平均步数:完成任务平均需要多少步
-
Token 消耗:单次任务平均消耗多少 Token(直接对应成本)
-
工具调用准确率:选对工具的比例
-
工具失败率:工具调用报错的比例
-
幻觉拦截率:被第二个模型或人工拦截的错误输出比例
-
平均响应延迟
-
面试加分句:"生产上我会为每个 Agent 实例暴露健康度指标------工具失败率、幻觉拦截率、平均重试次数------超阈值自动熔断并告警"
六、多智能体(Multi-Agent)
Q20:多 Agent 协作和单 Agent 多工具怎么选?
回答要点:
-
单 Agent 多工具 :实现简单、延迟低,适合任务边界清晰的场景
-
多 Agent :角色分工、并行探索、对抗审查(如"批评者 Agent"),但带来协调成本与一致性问题
-
选型看三点:任务分解结构、组织边界、延迟与成本
-
面试加分句:"多 Agent 不是银弹------加一个 Agent 就加一份协调开销。如果单 Agent 能搞定,绝不引入第二个"
Q21:多 Agent 之间怎么通信和避免死循环?
回答要点:
-
通信:通过共享 Memory(加版本号做乐观锁,防止并发写入脏数据)或消息队列
-
避免死循环:每个 Agent 设置独立的步数上限 + 全局协调者监控"是否在空转"
-
终止:所有 Agent 都报告完成,或全局协调者判定超时强制终止
七、框架与选型
Q22:你用过的 Agent 框架有哪些?怎么选型?
回答要点:
-
LangChain/LangGraph:生态最全,适合复杂编排,但抽象层次多、学习曲线陡
-
AutoGen(微软) :多 Agent 对话框架,适合多角色协作
-
Dify/Coze:低代码平台,适合快速原型和非技术团队
-
选型原则:项目复杂度、团队技术栈、是否需要可视化编排、成本预算
Q23:Agent 和传统 LLM Chain 的核心区别是什么?
回答要点:
-
LLM Chain :固定流程驱动------预定义的线性硬编码工作流,步骤不可动态调整
-
Agent :目标驱动自主决策------通过"观察-推理-行动"循环动态调整策略
-
面试加分句:"Chain 是'铁轨上的火车',Agent 是'有导航的汽车'------前者只能沿着铺好的路走,后者可以根据路况自己选路"