基于统一动作表示与可靠性感知训练目标的视觉-语言-动作模型预训练框架
在具身智能领域,视觉-语言-动作(Vision-Language-Action, VLA)模型正成为构建通用机器人系统的核心技术路径。然而,高质量机器人演示数据的采集成本高昂且难以规模化,这成为制约VLA模型能力边界的关键瓶颈。近期,由ACE Robotics、香港中文大学多媒体实验室(CUHK MMLab)、上海交通大学、清华大学等机构联合提出的ACE-Ego-0框架,创新性地将大规模第一视角人类视频与多本体机器人数据进行统一预训练,在RoboCasa、RoboTwin 2.0等仿真基准以及真实双臂机器人平台上均取得了业界领先的性能表现,为VLA模型的数据规模化与泛化能力提升开辟了新的技术路径。
背景与挑战:VLA预训练的数据困境
构建能够在多样化真实环境中运行的通用机器人系统,一直是具身智能领域的核心目标。VLA模型通过联合建模视觉感知、自然语言理解与动作控制,为实现这一目标提供了可行的技术路线。与语言和视觉基础模型类似,VLA策略的性能与预训练阶段可获得的数据规模与多样性呈现出强相关性。然而,与互联网规模的无监督数据不同,机器人演示数据的采集需要依赖遥操作设备或人类专家的直接示教,这一过程不仅成本高昂,而且在行为多样性上受限于采集环境和操作者的技能范围。
在此背景下,大规模第一视角人类视频(Egocentric Human Video)展现出独特的数据补充价值。Ego4D、EPIC-KITCHENS、EgoExo4D等公开数据集涵盖了厨房、家庭、工作坊等丰富场景中的日常交互行为,其覆盖的技能范围远超现有机器人数据集。更重要的是,这类视频数据的采集成本远低于机器人遥操作数据,具备显著的规模化潜力。
**核心挑战:**尽管人类视频数据具有规模优势,但将其与机器人数据进行联合训练面临四大层面的异构性难题:动作空间(Action Space)的坐标表示差异、本体结构(Embodiment Structure)的机械构型差异、时间动态(Temporal Dynamics)的控制频率差异,以及监督质量(Supervision Quality)的标注精度差异。这些异构性使得简单的数据混合训练不仅难以发挥人类视频的补充价值,甚至可能引入噪声干扰,损害策略模型的控制精度。
ACE-Ego-0:统一异构数据的预训练框架
针对上述挑战,ACE-Ego-0提出了一套系统性的解决方案,从表示对齐与训练目标两个维度实现异构数据的统一利用。该框架的核心创新可以概括为三个空间维度的对齐机制与一个可靠性感知的优化目标。
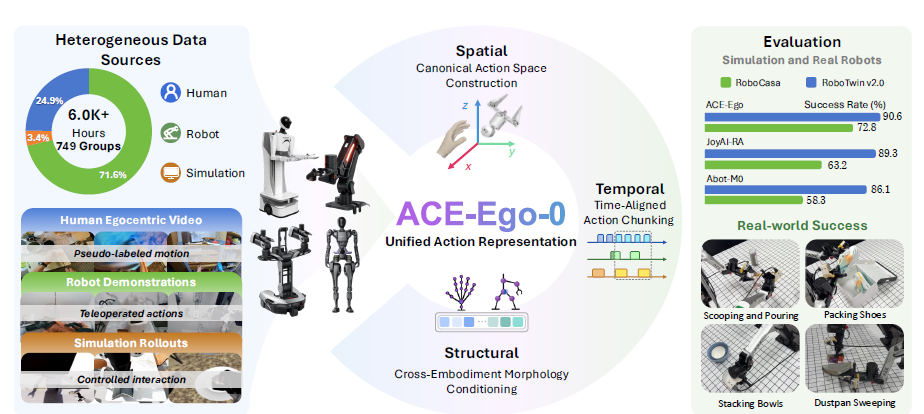
图1 ACE-Ego-0整体框架概览。该框架在超过6,000小时的混合具身数据集上进行预训练,数据集涵盖大规模第一视角人类视频、多本体机器人演示与仿真回滚数据。通过空间、结构与时间三个维度的统一对齐,ACE-Ego-0将异构人类与机器人数据映射到共享的表示空间中。
空间对齐:相机坐标系下的规范动作空间
不同机器人平台在记录末端执行器轨迹时,往往采用各自独立的坐标系,如机器人基座坐标系或世界坐标系。而人类手部姿态的重建结果通常基于MANO模型表达在局部手部坐标系中。这种空间表示的异构性要求策略模型隐式学习复杂的坐标变换,增加了跨本体迁移的难度。
ACE-Ego-0提出的**规范动作空间(Canonical Action Space)**将所有数据源的轨迹统一投影到头戴相机坐标系中。对于机器人数据,通过标定的相机外参将基座或世界坐标系中的末端执行器位姿转换至相机坐标系;对于人类视频,则以腕关节为原点,基于手掌平面与腕关节至手指的向量构建稳定的手部坐标系,并采用连续六维旋转表示(Continuous 6D Representation)统一表达姿态。这一设计使得动作预测与视觉观测处于同一参考框架下,策略模型无需学习平台特定的坐标变换,仅需在推理时替换对应的相机外参即可适配新本体。
结构对齐:跨本体形态条件化
即便动作空间在坐标系上达成统一,不同本体在运动学链、关节限位与物理尺寸上的差异依然存在。ACE-Ego-0通过**跨本体形态条件化(Cross-Embodiment Morphology Conditioning)**机制,将机器人与人类数据源嵌入到共享的形态空间中。对于机器人,框架从URDF(Unified Robot Description Format)文件中提取运动学图结构,通过图神经网络编码为形态Token;对于人类视频,则学习一个可优化的替代嵌入(Surrogate Embedding),捕捉不同数据源的视觉域与动作统计特性。关键设计在于,形态Token仅在动作解码阶段注入,保持视觉-语言主干网络的本体无关性,从而确保预训练知识的广泛迁移能力。
时间对齐:基于物理时间戳的动作分块
不同数据源的采集频率差异显著,从10Hz到30Hz不等。若采用固定步数的动作分块策略,模型在不同数据集上实际预测的未来物理时间窗口将不一致,导致时间尺度的混淆。ACE-Ego-0引入时间对齐动作分块(Time-Aligned Action Chunking),基于目标物理时长(如2秒)而非固定帧数定义动作预测范围,并根据各数据集的控制频率动态计算步数 horizon。此外,通过引入归一化的 episode 相位(Phase)与复合批次采样策略,确保训练批次内在语义与长度上的一致性,显著降低填充开销并稳定梯度更新。
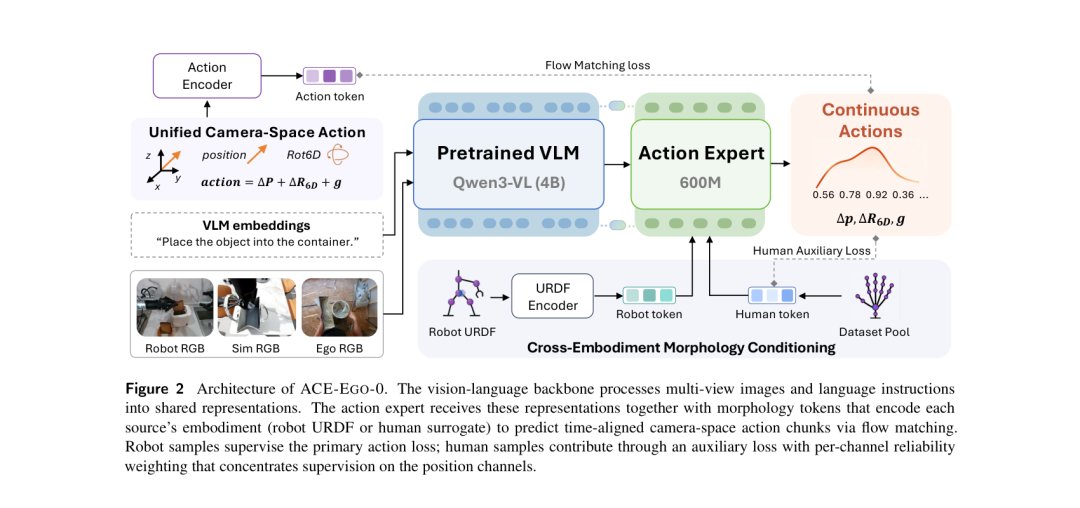
图2 ACE-Ego-0网络架构。视觉-语言主干(Qwen3-VL 4B)处理多视角图像与语言指令,动作专家(600M参数)在形态Token条件下通过流匹配预测时间对齐的相机空间动作分块。机器人样本监督主损失,人类样本通过可靠性感知的辅助损失参与训练。
可靠性感知训练:驾驭人类视频中的噪声监督
表示对齐解决了数据格式层面的异构性,但人类视频与机器人数据在监督质量上的差异同样不容忽视。机器人轨迹通过传感器直接记录,具有高精度与低噪声的特性;而人类视频中的伪动作标签(Pseudo-Action)依赖视觉重建管线,不可避免地存在跟踪抖动、遮挡误差与估计偏差。若将两类数据等同对待,噪声信号将直接干扰策略模型的主控制流。
ACE-Ego-0为此设计了可靠性感知的训练目标(Reliability-Aware Training Objective)。该目标将机器人数据作为主干监督,驱动基于流匹配(Flow Matching)的主动作损失;人类视频则通过辅助损失参与训练,并引入时空可靠性权重对监督信号进行精细化调制。具体而言,可靠性权重由静态通道级先验与动态步级平滑度因子共同决定:位置通道因重建精度较高获得完整权重,而旋转与夹爪状态等易受遮挡影响的通道则被降权处理;同时,基于速度跳变与加加速度(Jerk)的统计阈值,局部跟踪异常被动态识别并软衰减。这一分层机制确保高保真机器人数据锚定策略的主控制能力,人类视频则在可靠的维度上提供安全且互补的辅助监督。
**技术亮点:**人类辅助损失采用Huber回归形式,结合逐通道可靠性权重与归一化因子,使得监督强度自动适应于每个样本的有效信号密度。当批次中不包含人类样本时,辅助损失自动归零,保证训练流程的灵活性。
五阶段数据处理管线:从原始视频到训练就绪数据
为了将大规模第一视角人类视频转化为可与机器人数据联合训练的伪动作轨迹,研究团队构建了一套可扩展的五阶段数据处理管线。该管线涵盖从原始视频筛选到质量控制的完整流程,最终从约5,929小时的原始人类视频池中提炼出1,478小时的高质量伪动作标注数据。
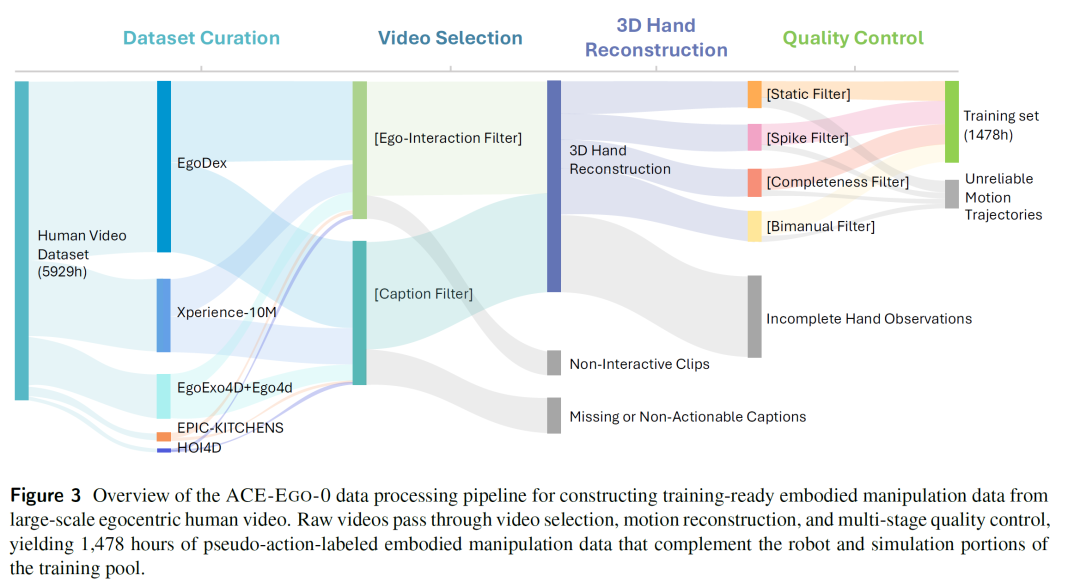
图3 ACE-Ego-0数据处理管线概览。原始视频经过视频筛选、运动重建与多阶段质量控制,最终产出1,478小时可用于训练的伪动作标注具身操作数据。
**第一阶段:数据集整理。**研究团队从公开数据集中筛选满足三个条件的来源:第一视角视角、多样化的真实交互场景,以及高质量的动作中心描述。最终纳入Ego4D、EgoExo4D、EPIC-KITCHENS-100、HOI4D、EgoDex与Xperience-10M六个数据源,并将所有来源标准化为统一的存储格式。
**第二阶段:视频筛选。**在应用计算密集的几何重建之前,框架首先通过轻量级过滤机制剔除低质量片段。基于人脸检测的 ego-交互过滤器排除非第一视角或观察视角的片段;基于图像描述的过滤器则保留同时包含操作动词与可操作对象名词的片段,确保数据的动作中心性。
**第三阶段:三维手部重建。**该阶段包含二维跟踪、局部姿态估计与全局轨迹优化三个子步骤。首先利用SAM3获取时序一致的手部边界框与分割掩码;随后通过HaMeR模型重建每帧的MANO形状与姿态参数;最后执行两阶段全局轨迹优化,在最小化二维重投影误差的同时施加时序平滑正则化,抑制逐帧重建中的深度歧义与时间抖动。
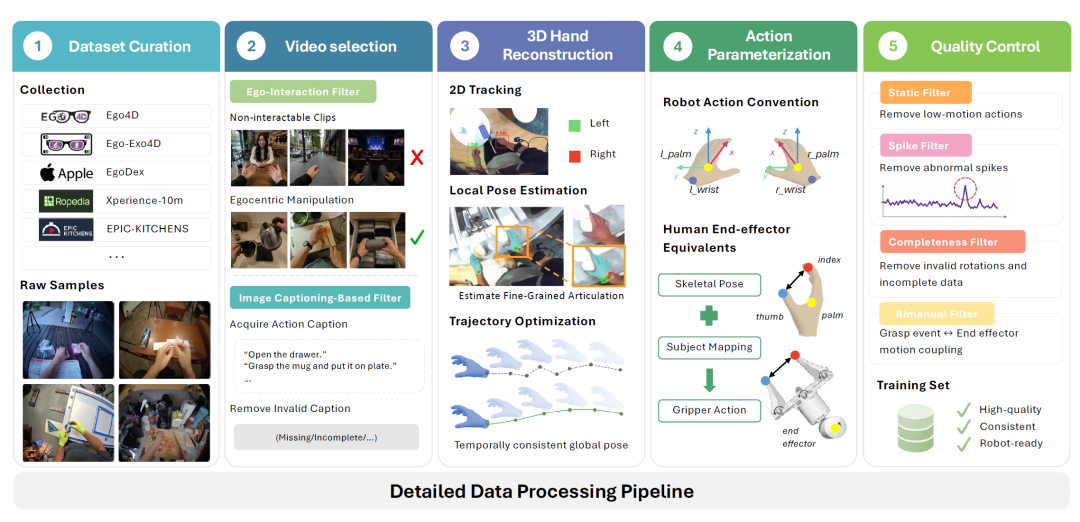
图4 从原始第一视角视频到相机空间伪动作的详细处理流程。五阶段管线包括:数据集整理、视频筛选、三维手部重建、动作参数化与质量控制。
**第四阶段:动作参数化。**重建后的手部轨迹被转换为与机器人数据兼容的22维双臂动作向量,包含三维位置、六维连续旋转表示、夹爪开度与活动标志位。其中,夹爪状态通过拇指至手掌距离的线性归一化进行映射,对于无显著抓握变化的运动片段则标记为中性状态。
**第五阶段:质量控制。**四重后处理过滤器确保进入训练池的数据质量:完整性过滤器排除含无效值或不连续帧的片段;静态过滤器剔除无显著手部运动的低交互片段;尖峰过滤器基于速度分布的统计阈值识别跟踪异常;双臂过滤器则基于双手距离统计与 temporal correlation 排除不合理的双臂行为模式。经过上述筛选,约25%的原始数据被保留为高质量训练样本。
实验验证:仿真与真实环境的双重突破
ACE-Ego-0在总计超过6,000小时的混合数据池上进行预训练,涵盖4,534小时的机器人与仿真数据以及1,478小时的伪动作标注人类视频。研究团队在RoboCasa GR1 TableTop、RoboTwin 2.0仿真基准以及ARX真实双臂平台上进行了系统评估。
72.8%
RoboCasa GR1 TableTop平均成功率
91.12%
RoboTwin 2.0 Easy平均成功率
90.62%
RoboTwin 2.0 Hard平均成功率
仿真基准评测
在RoboCasa GR1 TableTop基准上,ACE-Ego-0在24项人形桌面操作任务中取得了72.8%的平均成功率,相较于DIAL(70.2%)、JoyAI-RA(63.2%)、ABot-M0(58.3%)等对比方法实现了稳定提升。这一优势在 articulated-object 交互与 pick-and-place 重排任务中均保持一致,表明相机空间动作接口与可靠性感知训练具有良好的任务泛化性。
在RoboTwin 2.0双臂操作基准上,ACE-Ego-0在Easy/Clean设定下达到91.12%的平均成功率,在Hard/Randomized设定下达到90.62%,均优于JoyAI-RA、Hy-VLA、π0.5等现有方法。该基准涵盖50项任务,涉及抓取、放置、工具使用与双臂协调等多样化操作原语,ACE-Ego-0在强域随机化环境下的稳健表现验证了统一预训练策略对复杂双臂控制的有效迁移能力。
真实机器人平台验证
在配备头戴RGB-D相机的ARX双臂平台上,ACE-Ego-0在六项真实操作任务中取得了78.3%的平均成功率,较微调后的π0.5(71.7%)提升6.6个百分点,较GR00T-N1.7(35.6%)展现出显著优势。评测任务按复杂度递增排列,涵盖单臂拾取放置(Pick Tea)、接触丰富的双臂协调(Scoop Coffee)、语义分类(Category Sorting)、长时序多步操作(Stack Bowls、Pack Shoes)等场景。
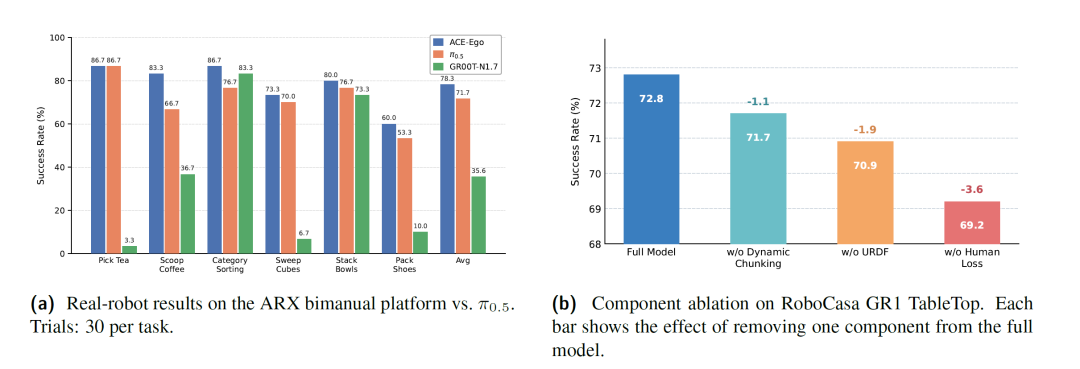
图5 左图:ARX双臂平台上的真实机器人实验结果对比;右图:RoboCasa GR1 TableTop上的组件消融研究,展示移除各组件对性能的影响。
特别值得注意的是,在Scoop Coffee这一需要双臂紧密时空协调的接触丰富任务中,ACE-Ego-0达到了86.7%的成功率,领先π0.5达16.7个百分点。在Category Sorting多类别物体放置任务中,ACE-Ego-0保持了90.0%的稳定表现。这些结果充分说明,通过统一预训练获得的策略在真实环境中的长时序执行与双臂协同方面具备显著优势。

图6 ACE-Ego-0在ARX双臂平台上的定性实验序列。每行展示一项代表性任务的关键帧,涵盖单臂放置、双臂协调与接触丰富的工具使用。
消融研究:验证各组件贡献
为了深入理解框架各组件的作用,研究团队在RoboCasa GR1 TableTop上进行了系统消融。结果显示,移除任一核心组件均会导致性能下降,验证了设计的必要性。
移除形态Token后,平均成功率从72.8%下降至70.9%(-1.9%)。尽管所有数据源共享相同的相机空间动作格式,不同机器人平台在运动学结构上的差异仍需显式建模,形态Token为动作专家提供了关键的本体结构信息。移除时间对齐动作分块后,性能降至71.7%(-1.1%),说明固定步数策略在跨频率数据混合时引入的时间不一致性会干扰策略学习。移除可靠性感知的人类辅助损失则导致最大降幅至69.2%(-3.6%),这直接证明了在混合来源训练中显式处理监督质量差异的重要性------若将噪声伪动作与高精度机器人数据等同对待,将显著损害动作专家的控制精度。
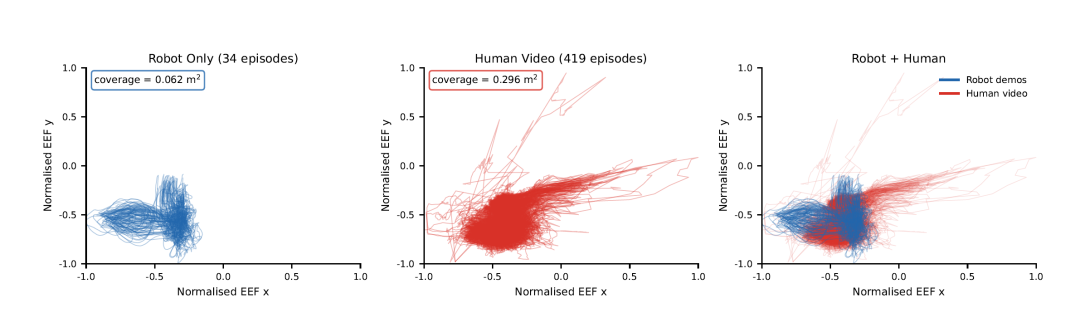
图7 Sweep Cubes任务微调数据的末端执行器轨迹分布。左图:34条机器人演示集中于较小区域(0.062平方米);中图:419条人类视频片段覆盖更广区域(0.296平方米);右图:两者叠加显示机器人数据嵌入在人类分布的广泛覆盖范围内。
在数据层面的消融进一步揭示了人类视频的独特价值。仅使用Qwen初始化模型(无具身预训练)的成功率为65.4%;加入机器人数据后提升至68.3%(+2.9%);进一步引入人类视频后达到72.8%(+4.5%),其中人类视频带来的增益甚至超过机器人数据本身。图7直观展示了原因:在Sweep Cubes任务的微调数据中,34条机器人演示的末端执行器轨迹仅覆盖0.062平方米的工作空间,而419条对应人类视频片段覆盖0.296平方米,广度达4.8倍。将人类视频加入微调后,数据稀缺场景下的成功率从10%提升至40%,实现了四倍的性能恢复。
数据规模与异构来源构成
ACE-Ego-0的预训练数据池在规模与多样性上均达到新的水平。机器人数据部分包含AgiBot Alpha/Beta演示、Galaxea R1 Lite数据、AgiBot DigitalWorld仿真回滚、RoboCasa TableTop仿真数据,以及超过1,800小时的自采集Galbot演示,覆盖人形、单臂轮式与移动双臂等多种本体,控制频率从10Hz到30Hz不等。人类视频部分则整合了六个大型公开数据集,跨越厨房、家庭与工作坊场景,捕捉了大量机器人遥操作难以覆盖的长尾操作行为。
**数据规模总览:**预训练数据总量超过6,000小时,包含约176万条片段与6.04亿帧。其中机器人与仿真数据占比约75.4%(4,534.8小时),人类视频占比约24.6%(1,478.9小时)。这一比例在保证高保真机器人数据主导地位的同时,充分利用了人类视频的规模优势与行为多样性。
技术启示与未来展望
ACE-Ego-0的提出为VLA模型的预训练提供了若干重要的技术启示。首先,观测中心坐标系 的引入为跨本体动作表示提供了简洁而有效的统一接口,将复杂的坐标变换问题从策略学习转移到可预先标定的相机外参上,显著降低了跨平台迁移的门槛。其次,可靠性感知 而非简单数据混合的训练哲学,为利用噪声辅助数据源提供了可扩展的范式------这一思路不仅适用于人类视频,也可推广至其他低精度监督场景。最后,形态条件化 与时间对齐的显式设计表明,在扩大数据规模的同时,对数据异构性的结构化处理同样至关重要。
从更广阔的视角看,ACE-Ego-0验证了人类日常操作视频作为机器人学习补充监督源的巨大潜力。第一视角视频中所蕴含的丰富物体交互、多样化环境与长尾行为模式,为机器人策略提供了远超传统遥操作数据的行为覆盖。随着三维手部重建技术的持续进步,人类视频伪动作标签的精度有望进一步提升,届时可靠性感知框架将能够解锁更多动作维度的监督,推动人类演示到机器人技能的更强迁移。

图8 跨真实机器人演示、仿真回滚与第一视角人类视频的相机空间动作可视化。所有数据源均在相同的观测对齐坐标约定下表达末端执行器或手部运动,使异构动作标签具备可比性。
展望未来,该框架在多个方向上具有延伸空间。在任务范围上,从当前的桌面操作扩展至移动操作、全身人形控制以及可变形物体操作,将进一步检验相机空间动作接口在更复杂空间约定与更长任务时程下的适用性。在模态丰富度上,引入灵巧手数据与力/力矩传感信息,有望提升接触丰富操作的精细度。在数据规模上,持续扩大人类视频占比并提升伪动作管线的保真度,特别是针对旋转与细粒度手指运动的重建精度,将为下一代VLA模型提供更为充沛且高质量的训练燃料。
结语
ACE-Ego-0通过统一动作表示与可靠性感知训练目标,成功架起了第一视角人类视频与多本体机器人数据之间的桥梁,在超过6,000小时的异构数据上实现了高效的联合预训练。该框架不仅在RoboCasa与RoboTwin 2.0仿真基准上刷新了性能记录,更在真实双臂机器人平台上展现了出色的长时序执行与双臂协调能力。作为VLA预训练领域的重要进展,ACE-Ego-0所倡导的数据统一与质量感知训练范式,为构建具备更强泛化性与可迁移性的通用机器人策略提供了坚实的技术基础,也为具身智能的规模化发展指明了新的方向。
本文内容基于论文《ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining》整理撰写
具身智能&世界模型blog: https://jinxindeep.github.io/blog/blog2026.html