摘要 (ABSTRACT)
我们提出了一种在海量规模的按需网约车平台中应用的新型订单派遣算法。传统的订单派遣方法通常只关注即时的乘客满意度,而本文提出的算法旨在从全局和更具前瞻性的视角,提供一种更高效的方式来优化资源利用率和用户体验。具体而言,我们将订单派遣建模为一个大规模的序列决策问题,其中将订单指派给司机的决策是由中央算法以协同的方式决定的。该问题通过"学习与规划"相结合的方式来解决:
-
学习阶段: 基于历史数据,我们首先将供需模式总结为空时量化特征,其中每一个特征都代表了司机处于特定状态下的期望价值;
-
规划阶段: 在实时运行中进行规划,结合即时奖励和未来收益来评估每一个"司机-订单"对的价值,随后使用组合优化算法来求解派遣方案。
通过大量的离线实验和线上 A/B 测试,该方法显著提升了平台的效率,并已成功部署在滴滴出行的生产系统中。
1. 引言 (INTRODUCTION)
近年来,我们见证了诸如 Uber、Lyft 和滴滴出行等按需网约车服务的蓬勃发展。随着无线通信工具、全球定位系统(GPS)以及功能强大的移动应用程序的出现,这些网约车服务在减少出租车巡游时间和乘客等待时间方面,相比传统出租车系统做出了显著改进 7, 13, 23。同时,它们还提供了关于乘客需求和出租车移动模式的丰富信息,这可以让包括需求预测、路线规划、供应链管理和交通信号灯控制在内的多个研究领域受益 2, 10, 20, 22。
在本文中,我们聚焦于现代出租车网络中的订单派遣问题 4, 12, 17, 24, 26,即为乘客的请求寻找合适司机的过程。以往,基于局部位置的贪心方法在大型出租车公司中被广泛使用,例如寻找最近的司机来服务乘客 8,或者使用先到先服务原则的排队策略 25。尽管这些方法易于实现和管理,但它们本质上是缺乏协同的,并且往往将即时的乘客满意度置于全局供应利用率之上。由于出租车供给与乘客需求之间存在时空错配,从长远来看,这可能会导致次优的结果。
我们的目标是在较长的时间跨度内(例如几个小时或一天)优化订单派遣,既能满足当前的乘客需求,又能优化预期的未来收益。这依赖于对时空乘客需求和出租车移动模式的精确建模,以及在实时环境中快速感知和控制的能力。据我们所知,这是首个在像滴滴出行这样的大规模平台中,以优化长期全局效率为目标来考虑订单派遣的工作。
为了实现这一目标,我们将订单派遣建模为一个序列决策问题。匹配司机和订单的每个独立决策都基于两项:一项是从实时信息中获得的司机服务该订单的即时奖励,另一项则是代表该决策对未来影响的附加项。基于历史数据中的乘客需求和出租车供给模式,我们构建了一个统一的时空状态评估指标,来量化上述未来收益(即学习步骤)。多名司机与多个订单之间的实时匹配被建模为多智能体系统中的决策问题,并使用组合优化算法进行求解,从而以集中且协同的方式找到全局最优解(即规划步骤)。图 1 展示了所提出的学习与规划算法。
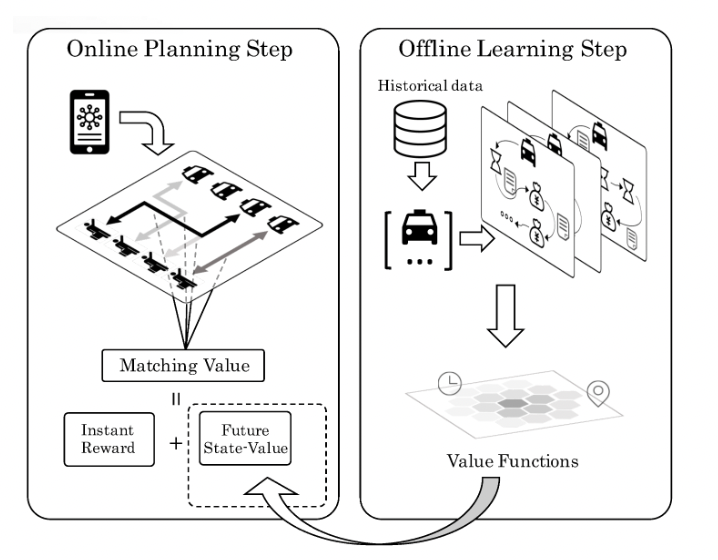
图1:所提算法的示意图
我们克服了若干实际问题,使得该算法在大规模系统中切实有效,这些问题包括计算效率、多目标优化,以及在用户体验与平台效率之间取得平衡。经过在模拟环境和线上 A/B 测试中的大量实验,所提方法相比基线算法展现出了显著的改进,并已成功部署在滴滴出行的生产系统中,每天为数以千万计的乘客和司机提供服务。
这项工作的贡献总结如下:
-
我们提出了一种高效的订单派遣算法,可优化大规模应用中的长期平台效率。该算法在统一的决策框架中同时考虑了即时乘客满意度和预期的未来收益。
-
通过将订单派遣建模为具有集中控制的序列决策问题,所提方法自然属于强化学习的范畴 19。该算法在大规模实时系统中以学习和规划的框架实现,是强化学习在大型实时系统中的首批应用之一。
-
我们在所提算法中考虑了计算效率和实验设计等若干实际问题。因此,该方法已被应用于现实世界的生产系统中,并使中国主要城市的平台收入提升了 0.5% 到 5% 不等。
本文其余部分的结构安排如下:我们在第 2 节中简要概述订单派遣问题的背景和系统架构;第 3 节详细介绍学习步骤,包括模型定义和策略评估方法;第 4 节详细介绍线上规划步骤;第 5 节提供了所提方法在强化学习中的另一种解释;随后在第 6 节中描述实验,并在第 7 节中讨论相关工作;第 8 节对全文进行总结。
2. 订单派遣问题:背景与系统概述 (ORDER DISPATCH PROBLEM: BACKGROUND AND SYSTEM OVERVIEW)
出租车服务是现代城市的主要交通服务之一。传统出租车在街上巡游以发现乘客的请求。近年来,像 Uber、Lyft 和滴滴这样的"按需"交通服务提供了一种更高效的搭乘体验。特别是,这些线上服务实时收集司机的信息和乘客的请求(订单),并依赖一个集中的决策平台来匹配司机和订单。如滴滴的数据统计所示,从传统出租车的"司机选单模式"切换到集中的"平台派单给司机模式",极大地提升了平台的效率,使订单成交率提高了 10% 以上。
旨在寻找司机与订单之间最佳匹配的订单派遣,对于按需网约车服务显然至关重要 24。图 2 展示了它在实际应用中如何运行的系统概述。每辆出租车都配备了感知和通信工具,定期将其地理坐标和载客状态上传到平台。在另一端,当乘客产生"按需"需求时,他或她会立即在平台上下一笔订单。
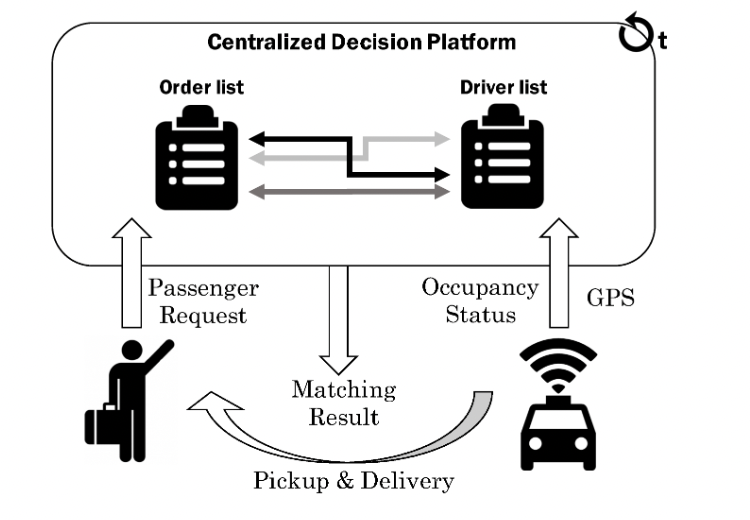
图2:按需叫车服务中的订单调度架构
在过去,滴滴在线上依赖一种简单但相当成功的订单派遣策略。具体而言,在每个较短的时间片内(例如一秒或两秒),平台的决策中心首先收集所有可用的司机和活跃的订单,然后基于组合优化算法进行匹配。结合历史数据和实时出租车监控信息,我们完全有可能超越单个时间片内的匹配优化。
在本文中,我们设计了一种订单派遣算法,旨在较长的时间跨度内(例如两三个小时或一天)优化平台的全局效率。这里的主要思想是将订单派遣建模为一个大规模的序列决策问题,其中每个决策对应于匹配或不匹配一个司机的动作,从而在长远来看最大化平台的预期收益。
所提出的算法在计算"司机-订单"对的匹配价值时,与以往的方法有所不同。我们不再仅仅关注当前的状态(例如,最小化接客距离),而是同时考虑了订单派遣决策对未来的影响,以便在时空上平衡供给与需求的分布。
3. 学习 (LEARNING)
学习步骤旨在定量理解整个城市中出租车供给和乘客需求的空时(时空)模式。基于历史数据,我们构建了一个马尔可夫决策过程 (MDP),其中智能体(Agent)代表平台中的单个司机。学习到的价值函数会生成每个空时状态的"价值",该价值将在接下来的线上规划步骤中被进一步利用。
3.1 问题陈述 (Problem Statement)
背景 :马尔可夫决策过程(MDP)通常用于建模序列决策问题。在 MDP 中,智能体根据策略在环境中做出行为,该策略指定了智能体在 MDP 的每个状态下如何选择动作。智能体的目标是最大化其收益 G t = ∑ i = t T R t + 1 G_t=\sum_{i=t}^TR_{t+1} Gt=∑i=tTRt+1 ,即从时间 t t t 开始的预期累计未来奖励。为了求解 MDP,一个共同的目标是学习价值函数,包括状态价值函数 V π ( s ) V^{\pi}(s) Vπ(s) 和动作价值函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a) ,其中 V π ( s ) = E π G t ∣ s t = s V^{\pi}(s)=\mathbb E_{\pi}G_t\|s_t=s Vπ(s)=EπGt∣st=s 且 Q π ( s , a ) = E π G t ∣ s t = s , a t = a Q^{\pi}(s,a)=\mathbb E_{\pi}G_t\|s_t=s,a_t=a Qπ(s,a)=EπGt∣st=s,at=a。
MDP 定义:我们在这里构建的 MDP 是基于局部视角的:每个独立的司机都被建模为一个智能体。尽管这种设置可能会在接下来的规划步骤中导致一个拥有数千个智能体的多智能体问题,但与将整个平台建模为一个智能体的全局视角设置相比,这种设置的优势在于状态转移、动作和奖励的定义可以被显著简化。值得注意的是,在局部视角设置下,环境包含了所有其余的信息,包括订单的生成以及平台中其他司机的状态。我们目前不区分单个司机------每个司机都被视为相同的。MDP 的其他组成部分定义如下,并在图 3 中进行了展示:
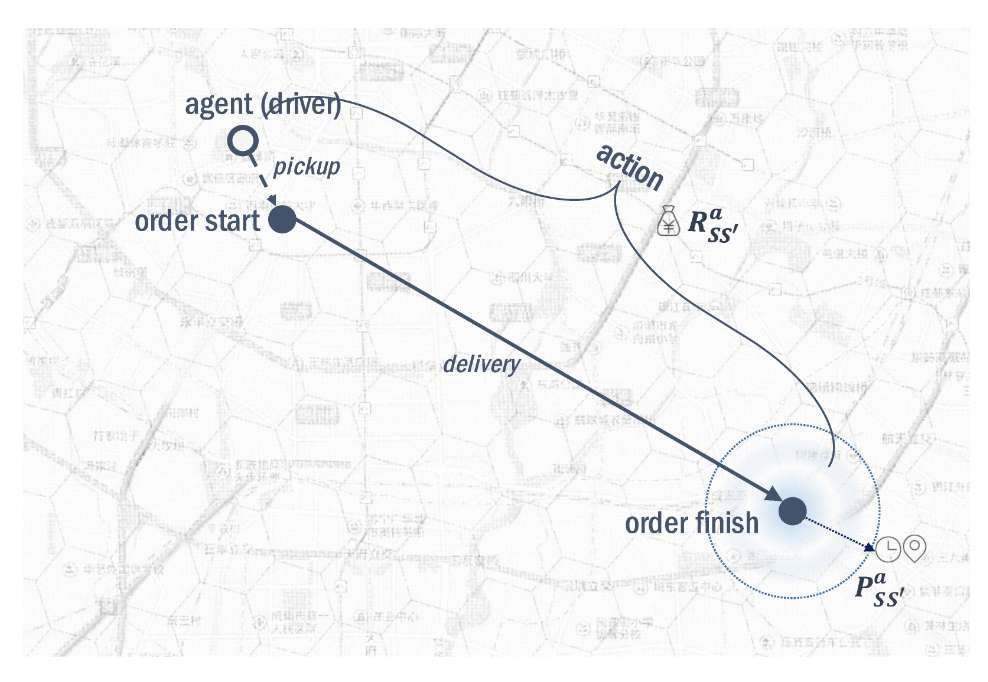
图3:所提算法中的MDP定义。agent代表驾驶员;此图中的动作表示指派驾驶员为特定订单服务
状态 (State) : 司机的状态被定义为一个展示时空状态的二维向量。为了简单起见,我们将状态量化为固定数量的时间段和区域的笛卡尔积,从而得到一个有限的状态集。形式上,我们定义 s = ( t , g ) ∈ S s=(t,g)\in S s=(t,g)∈S,其中 t ∈ T t\in T t∈T 是时间索引, g ∈ G g\in G g∈G 是司机所在区域的索引。注意 ∣ S ∣ = ∣ T ∣ × ∣ G ∣ ∣S∣=∣T∣\times∣G∣ ∣S∣=∣T∣×∣G∣。
动作 (Action) : 在我们的设置中主要有两种类型的动作。第一种类型的动作是指派司机去服务一个特定的订单。在这种情况下,智能体(司机)将前往指定地点接乘客,然后将乘客送往目的地,并获得该订单的奖励。另一种类型的动作是空闲(Idle)。这种设置对我们的问题至关重要,因为司机可能会在特定地方(例如机场和火车站)空闲很长时间,使得这些地方在某些时间段内不再那么有吸引力。具体而言,空闲动作意味着司机在一个时间段内没有与任何订单匹配。为了简单起见,我们假设"空闲"动作会导致自动转移到下一个状态(相同的位置,但处于下一个时间段),且奖励为零。
奖励 (Reward) : 奖励的定义决定了整个系统的优化目标。直观上,奖励可以定义为订单的价格,以此来实现最大化流水(GMV,交易总额)的目标。
状态转移与奖励分布 (State transition and reward distribution) : 订单派遣的一个显著特征是决策必须以滚动时间窗(Rolling Horizon)的方式做出。在订单生成的 t t t 时刻,系统没有关于未来的确切信息,包括乘客需要支付多少费用以及行程将在什么时间完成。因此,在做出决策时,我们必须依赖预估到达时间(ETA)和预估价格。这些预估的误差分布被隐式地包含在状态转移概率 P s s ′ a P_{ss'}^a Pss′a 和奖励分布 R s s ′ a R_{ss'}^a Rss′a 中。
折扣因子 (Discount factor) : 折扣因子控制了 MDP 考察未来影响的深度。在我们的应用中,使用较小的折扣因子是有利的,因为较长的时间跨度会给价值函数引入较大的方差。值得注意的是,在这种设置下,奖励(订单价格)也应该进行折扣。对于一个持续 T T T 个时间片、价格为 R R R 且折扣因子为 γ \gamma γ 的订单,其最终奖励由下式给出:
R γ = ∑ t = 0 T − 1 γ t R T (1) R_{\gamma} = \sum_{t=0}^{T-1} \gamma^t \frac{R}{T} \tag{1} Rγ=t=0∑T−1γtTR(1)
为了让这个过程更清晰,我们来看一个例子。假设位于 A 区域的一名司机在 00:00 收到了一笔从 B 到 C 的订单。行程预计用时 20 分钟,费用为 30 美元。司机接乘客还需要额外的 10 分钟。假设我们将时间片划分为 10 分钟的窗口(从 00:00 开始),并使用 γ = 0.9 \gamma=0.9 γ=0.9 的折扣因子。在我们的模型中,这笔订单将使司机从状态 s s s 转移到状态 s ′ s' s′ 并获得奖励 r r r,其中 s = ( A , 0 ) s=(A,0) s=(A,0), s ′ = ( B , 3 ) s'=(B,3) s′=(B,3)(2 代表行程时间,1 代表接客时间),而 r = 10 + 10 × 0.9 + 10 × 0.9 2 = 27.1 r=10+10×0.9+10×0.9^2=27.1 r=10+10×0.9+10×0.92=27.1。
3.2 策略评估 (Policy Evaluation)
基于 MDP 的定义,我们将历史数据分解为一系列包含服务动作和空闲动作的交易对 ( s , a , s ′ , r ) (s, a, s', r) (s,a,s′,r)。需要注意的是,由于我们不区分单个司机,因此为所有司机收集的交易数据可以合并为一个统一的数据集,用于学习价值函数,这正好对应了策略评估的概念。我们假设在训练期间,生成交易数据的线上策略保持不变。因此,为了简便起见,本节省略了策略下标 π \pi π。具体而言,一笔交易可能来自于"空闲"动作,也可能来自于"服务"动作。如图 4(a) 所示,在空闲交易中,智能体不会获得即时奖励,其时序差分 (TD) 更新规则如下:
V ( s ) ← V ( s ) + α 0 + γ V ( s ′ ) − V ( s ) (2) V(s) \leftarrow V(s) + \alpha 0 + \\gamma V(s') - V(s) \tag{2} V(s)←V(s)+α0+γV(s′)−V(s)(2)
其中 s = ( t , g ) s = (t, g) s=(t,g) 是司机的当前状态,而 s ′ = ( t + 1 , g ) s' = (t + 1, g) s′=(t+1,g) 是状态 s s s 之后的下一个状态。
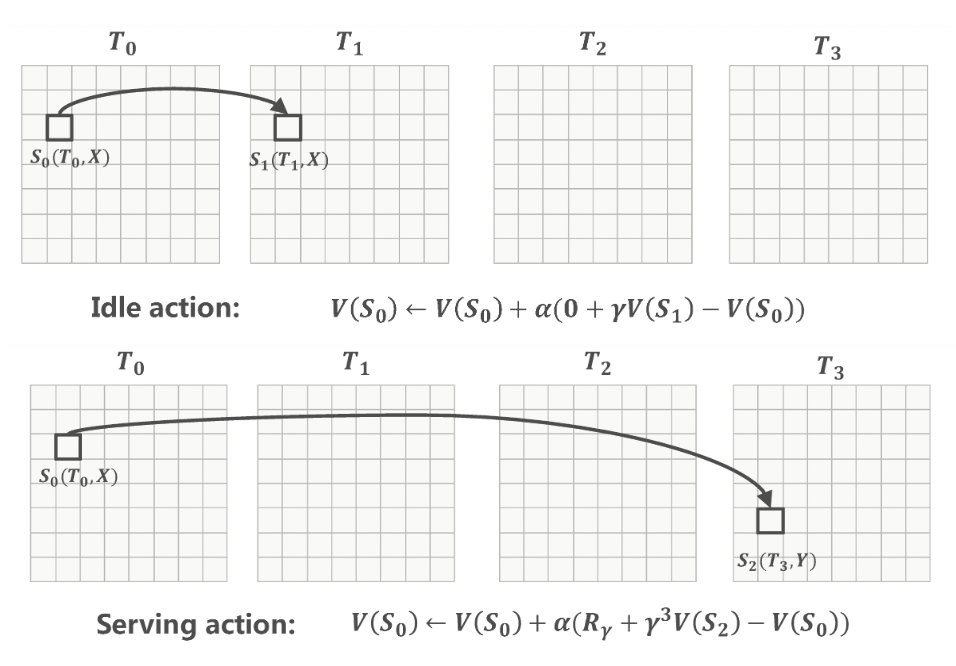
图4:TD更新规则。智能体(驾驶员)可能采取两种行动:空闲和服务
另一方面,在服务动作中,智能体将获得即时奖励并触发状态转移。其 TD 更新规则计算如下:
V ( s ) ← V ( s ) + α R γ + γ Δ t V ( s ′ ′ ) − V ( s ) (3) V(s) \leftarrow V(s) + \alpha R_\\gamma + \\gamma\^{\\Delta t} V(s'') - V(s) \tag{3} V(s)←V(s)+αRγ+γΔtV(s′′)−V(s)(3)
这里 s = ( t , g ) s = (t, g) s=(t,g) 仍然是司机的当前状态,而 s ′ ′ = ( t + Δ t , g dest ) s'' = (t + \Delta t, g_{\text{dest}}) s′′=(t+Δt,gdest) 则表示司机完成该订单的预估结束状态。具体而言, Δ t \Delta t Δt 代表预估接客时间、等待时间和送客行程时间之和(注意,空闲动作的 Δ t idle = 1 \Delta t_{\text{idle}} = 1 Δtidle=1)。 g dest g_{\text{dest}} gdest 记录了乘客在应用程序中提供的目的地。奖励也应当使用公式 (1) 进行折扣。
这种 TD 更新规则的样本效率较低,尤其是在我们的案例中,状态数量可能会超过一百万个。在实际应用中,我们采用了一种基于动态规划 (DP) 的方案来计算价值函数。为了让动态规划在我们的模型中可行,我们进一步将该 MDP 精简为一个有限时域(Finite-horizon)模型,其中一个回合(Episode)记录了一名司机在一天的交易数据。随后,动态规划算法按照时间段的逆序进行计算,具体细节如算法 1 所示。

最终得到的价值函数准确捕捉了需求端和供给端的空时模式。为了更清晰地说明,作为一个特例:当不使用折扣因子(即 γ = 1 \gamma = 1 γ=1)且回合长度设定为一天时,状态价值函数 V ( s ) V(s) V(s) 实际上对应于该司机从当前时间开始直到当天结束,平均能够赚取的预期总收入。
4. 规划 (PLANNING)
线上规划步骤以学习到的价值函数作为输入,并实时确定司机与订单之间的最终匹配。基于第 2 节中所述的系统架构,我们假设匹配过程所需的所有支撑信息都是已知的,这包括司机的地理坐标和载客状态,以及订单的起点和目的地。
4.1 实时订单派遣算法 (Real-time Order Dispatch Algorithm)
在每个时间片内,线上订单派遣算法的目标是确定司机与订单之间的最佳匹配。在我们的问题设置中,这一目标也可以理解为:以协同的方式为每位司机寻找最佳动作,从而优化未来的全局收益。形式上,集中式订单派遣算法的目标函数写为:
arg max a i j ∑ i = 0 m ∑ j = 0 n Q π ( i , j ) a i j (4) \tag{4} \arg\max_{a_{ij}} \sum_{i=0}^m \sum_{j=0}^n Q_\pi(i, j) a_{ij} argaijmaxi=0∑mj=0∑nQπ(i,j)aij(4) s.t. ∑ i = 0 m a i j = 1 , j = 1 , 2 , 3 ... , n \text{s.t.} \quad \sum_{i=0}^m a_{ij} = 1, \quad j = 1, 2, 3 \dots, n s.t.i=0∑maij=1,j=1,2,3...,n ∑ j = 0 n a i j = 1 , i = 1 , 2 , 3 ... , m . (5) \tag{5} \sum_{j=0}^n a_{ij} = 1, \quad i = 1, 2, 3 \dots, m. j=0∑naij=1,i=1,2,3...,m.(5)
其中,
a i j = { 1 如果订单 j 被指派给司机 i 0 如果订单 j 未被指派给司机 i a_{ij} = \begin{cases} 1 & \text{如果订单 } j \text{ 被指派给司机 } i \\ 0 & \text{如果订单 } j \text{ 未被指派给司机 } i \end{cases} aij={10如果订单 j 被指派给司机 i如果订单 j 未被指派给司机 i
这里, i ∈ 1 , ... , m i \in 1, \\dots, m i∈1,...,m 对应于当前时间戳下所有可用的司机,而 j ∈ 1 , ... , n j \in 1, \\dots, n j∈1,...,n 对应于等待服务的订单。 Q π ( i , j ) Q_\pi(i, j) Qπ(i,j) 是司机 i i i 执行服务订单 j j j 这一动作的动作价值函数。需要注意的是, i = 0 i = 0 i=0 和 j = 0 j = 0 j=0 的情况对应于一个特殊的默认动作,即在当前时间戳下不服务任何订单。
值得注意的是,智能体(司机)在线上测试时拥有有限的动作空间,因为他们必须从一组可用的订单中选择一个进行服务,或者干脆什么都不做。相反,在学习阶段,我们拥有无限的动作空间。公式 (5) 中的约束条件确保了每位司机都将选择一个可用动作(包括服务订单和什么都不做),同时每个订单在当前时间戳下最多只能被指派给一位司机,或者保持未服务状态。
我们将公式 (4) 建模为一个二部图匹配(Bipartite Graph Matching)问题,其中司机和订单是两组节点;司机 i i i 和订单 j j j 之间的每条边都有一个权重 Q π ( i , j ) Q_\pi(i, j) Qπ(i,j)。在实际应用中,我们采用 Kuhn-Munkres (KM) 算法 15 来对其进行求解。
4.2 优势函数技巧 (Advantage Function Trick)
由于默认动作(司机什么都不做以及订单未被服务)的存在,最终生成的二部图是一个完全图,即司机与订单之间存在所有可能的边。为了降低计算复杂度,我们对公式 (4) 进行了优势函数技巧(Advantage Function Trick)处理,从而消除所有代表默认动作的边。
具体而言,由于相邻两轮订单派遣之间的时间间隔(以秒为单位)远小于价值函数中的时间粒度(以分钟为单位),因此司机在某个订单派遣时间戳下什么都不做,可以建模为保持在当前状态不变。因此,动作价值函数 Q ( i , 0 ) Q(i, 0) Q(i,0) 实际上等于司机 i i i 的状态价值函数 V ( i ) V(i) V(i)。这使得我们可以通过将连接到司机 i i i 的所有边的权重都减去 V ( i ) V(i) V(i),从而移除司机与"什么都不做"动作之间的所有连接。图 5 展示了这一过程。
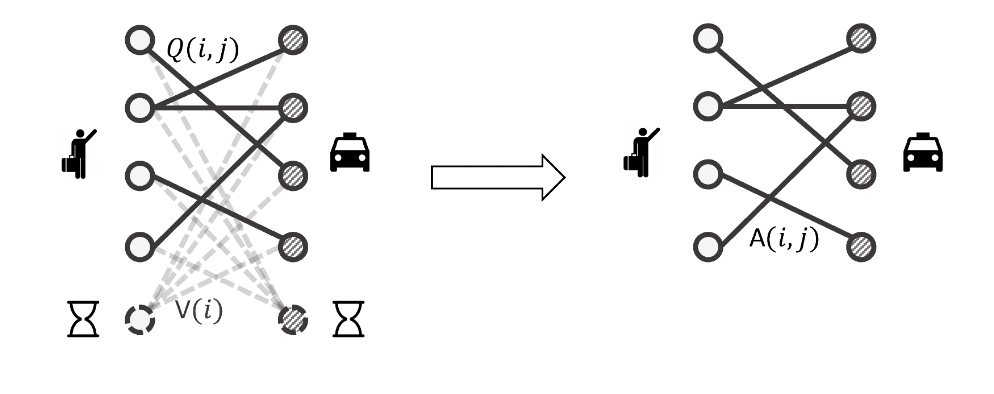
图5:优势技巧。我们移除了所有与默认节点的连接。
引入优势函数技巧后,单个时间戳下的订单派遣目标函数变为:
arg max a i j ∑ i = 1 m ∑ j = 1 n A π ( i , j ) a i j (6) \tag{6} \arg\max_{a_{ij}} \sum_{i=1}^m \sum_{j=1}^n A_\pi(i, j) a_{ij} argaijmaxi=1∑mj=1∑nAπ(i,j)aij(6) s.t. ∑ i = 1 m a i j ≤ 1 , j = 1 , 2 , 3 ... , n \text{s.t.} \quad \sum_{i=1}^m a_{ij} \le 1, \quad j = 1, 2, 3 \dots, n s.t.i=1∑maij≤1,j=1,2,3...,n ∑ j = 1 n a i j ≤ 1 , i = 1 , 2 , 3 ... , m . (7) \tag{7} \sum_{j=1}^n a_{ij} \le 1, \quad i = 1, 2, 3 \dots, m. j=1∑naij≤1,i=1,2,3...,m.(7)
其中,
A π ( i , j ) = γ Δ t j V ( s i j ′ ) − V ( s i ) + R γ ( j ) (8) \tag{8} A_\pi(i, j) = \gamma^{\Delta t_j} V(s'{ij}) - V(s_i) + R\gamma(j) Aπ(i,j)=γΔtjV(sij′)−V(si)+Rγ(j)(8)
就是优势函数(Advantage Function) 。对于司机 i i i 和订单 j j j 之间的边,其优势函数的计算方式为:服务该订单的预期收益(获得折扣后的奖励,并结束于由订单目的地决定的状态)减去保持在当前状态的预期价值(司机当前状态的价值函数)。
所提出的技巧消除了二部图中的绝大多数边。因此,公式 (6) 中的目标函数可以被更快速地求解。算法 2 总结了这一规划步骤。
算法 2:实时订单派遣算法
- 输入 : 使用算法 1 计算所有状态的价值函数 V ( s ) V(s) V(s),并将其加载为查找表(LUT)。
- for 线上订单派遣的每一个时间戳 do
- 收集可用的司机 i ∈ 1 , ... , m i \in 1, \\dots, m i∈1,...,m 和活跃的订单 j ∈ 1 , ... , n j \in 1, \\dots, n j∈1,...,n。
- 对"司机-订单"对进行必要的过滤,并移除无效的连接。
- 使用公式 (8) 计算每个有效"司机-订单"对的优势函数。
- 使用 KM 算法求解公式 (6)。
- 将匹配信息发送给相关的司机和乘客。未被匹配的订单和司机将进入下一轮。
- end for
4.3 讨论 (Discussion)
公式 (6) 从数学上描述了目标函数。然而,该函数在现实世界的订单派遣系统中如何解读仍不够直观。为此,我们仔细研究一下公式 (8) 中优势函数的具体形式。我们会考虑以下四个主要因素:
- 订单价格(Order price) : 鉴于 R γ ( j ) R_\gamma(j) Rγ(j) 的存在,具有更高实用价值(价格更高)的订单 j j j 自然会带来更高的优势值。
- 司机的位置(Driver's location) : 司机当前状态的价值函数对优势函数有负面影响(即 − V ( s i ) -V(s_i) −V(si))。因此,在相同条件下,处于低价值区域的司机更有可能被选中去服务订单,因为他们未来在原地接到其他订单的可能性低于那些处于高价值区域的司机。
- 订单目的地(Order destination) : 如果一个订单的目的地是更有价值(更繁华)的区域,那么服务该订单的动作可能会获得更高的优势值,因为它会带来更高的 V ( s i j ′ ) V(s'_{ij}) V(sij′)。
- 接客距离(Pickup distance) : 最后,司机 i i i 与订单 j j j 起点之间的接客距离也会以隐式的方式对优势值做出贡献。具体来说,较远的接客距离需要花费更多的接客时间。这会导致到达时间变晚并增加 Δ t j \Delta t_j Δtj,从而对目的地状态价值函数引入更大的折扣,最终导致优势值降低。
在实际应用中,通常需要处理多个目标。在订单派遣系统中,首要目标是确保良好的用户体验;除此之外,更倾向于产生更多的收入并满足更多的乘客需求,从而实现司机、乘客和平台的三方共赢。在我们的系统中,这通过一组超参数来控制,这些超参数是基于使用模拟器进行的离线实验选出的。
5. 将学习与规划相结合 (COMBINING LEARNING AND PLANNING)
在这一节中,我们将前两节所做的工作结合在一起,并从强化学习(Reinforcement Learning)的视角,对整个流程提供一种不同的解释。
强化学习旨在为序列决策问题寻找一种能够优化预期未来收益的策略。在我们的案例中,决策中心充当了一个"元智能体(Meta-agent)",以集中控制的方式为平台中的所有司机(智能体)做出决策。这自然是一个序列决策问题,因为该元智能体在连续的时间片(例如每 2 秒一个时间片)内做出决策(即寻找最佳匹配),并观察接下来几个小时内总收入的回报。
所提算法的核心思想可以总结为以下公式。在每个时间片内,元学习器的目标是最大化全局平台的预期收益 G t G_t Gt:
E π G t ∣ S = s (9) \tag{9} \mathbb{E}_\pi G_t \\mid S = s EπGt∣S=s(9)
其中, s s s 是整个平台在时间片 t t t 的全局状态。
我们将这个全局目标分解为所有独立司机收益的累加:
E π ∑ i G i t \| S = { s i } (10) \tag{10} \mathbb{E}_\pi \left \\sum_i G_i\^t \\;\\middle\|\\; S = \\{s_i\\} \\right Eπi∑Git S={si}(10)
其中, G i t G_i^t Git 是特定司机 i i i 的累计收益, s i s_i si 是司机 i i i 的状态。
这里做了一个近似假设,即所有司机之间都是相互独立的,从而全局状态可以分解为每个司机状态的笛卡尔积。从原理上讲这并不完全成立,因为平台中的司机之间存在着强烈的竞争与相互影响关系。然而,由于司机在测试时只能从一个相对较小的订单子集中选择动作,且在实际应用中绝大多数订单都是可服务的,因此即使在该假设下,我们的应用依然能够取得合理的成果。在这种情况下,全局目标可以进一步分解为:
∑ i E π i G i t ∣ S = s i (11) \tag{11} \sum_i \mathbb{E}_{\pi_i} G_i\^t \\mid S = s_i i∑EπiGit∣S=si(11)
公式 (11) 代表了一个多智能体系统,其中每个智能体都有其独特的策略 π i \pi_i πi。在现有文献中,如何在单个模型中处理数以千计的自私自利(Self-interest)智能体仍是一个开放性的问题。因此,既然我们依赖集中式算法来为所有智能体做出决策,我们就可以限制所有智能体都拥有最大化全局收益的"共同利益",从而让他们共享相同的策略 π i = π \pi_i = \pi πi=π。由于最大化预期收益等同于最大化动作价值函数,因此目标转变为最大化:
∑ i E π G i t ∣ S i t = s i , A i t = a i = ∑ i Q i π ( s i , a i ) (12) \tag{12} \sum_i \mathbb{E}_\pi G_i\^t \\mid S_i\^t = s_i, A_i\^t = a_i = \sum_i Q_i^\pi(s_i, a_i) i∑EπGit∣Sit=si,Ait=ai=i∑Qiπ(si,ai)(12)
最后,我们假设所有司机都是同质的(Homogeneous),因此他们可以共享同一套价值函数(即对所有司机而言, Q i ( ⋅ ) = Q ( ⋅ ) Q_i(\cdot) = Q(\cdot) Qi(⋅)=Q(⋅)):
∑ i Q i π ( s i , a i ) = ∑ i Q π ( s i , a i ) (13) \tag{13} \sum_i Q_i^\pi(s_i, a_i) = \sum_i Q^\pi(s_i, a_i) i∑Qiπ(si,ai)=i∑Qπ(si,ai)(13)
现在显而易见的是,第 3 节中的学习步骤是基于历史数据计算单个司机的价值函数,而第 4 节中的规划步骤则是以协同的方式来求解公式 (13)。我们同样可以将这两个步骤融合在一起并进行迭代更新,这实际上就是一种策略迭代(Policy Iteration)方法:学习步骤基于初始策略采样的历史数据生成价值函数;随后,规划步骤进行策略更新,其目标是利用学习到的价值函数来最大化全局收益。
6. 实验 (EXPERIMENT)
为了更全面地了解所提方法的有效性,我们在三种不同抽象级别的环境中对其进行了评估,包括一个玩具示例(Toy Example)、一个派遣模拟器以及现实世界的真实环境。
6.1 玩具示例 (Toy Example)
我们设计了一个玩具示例,用以展示我们的 MDP 框架在处理时空订单派遣问题上的能力。
实验设置 (Experimental Setup) 。 我们考虑了在一个包含 20 个时间步的 9 × 9 9 \times 9 9×9 空间网格(网格地图)中运营的订单和司机。在每个时间步,司机只能选择原地不动,或者向垂直/水平方向移动一个网格。同时,订单只能被指派给曼哈顿距离不超过 2 的司机。一个订单如果长时间未被指派给任何司机,则会被取消;取消时间被建模为一个区间在 0 到 5 之间的截断高斯分布,其均值为 2.5,沿着时间轴的标准差为 2。
为了生成数据,我们希望模拟出具有早高峰和晚高峰的逼真交通模式,其中心分别位于不同的住宅区和工作区。因此,订单的起点位置是根据一个双分量高斯混合模型进行采样的,然后被截断为时空网格中的整数。随后,订单的目的地和司机的初始位置,会从定义在网格上的离散均匀分布中随机采样。高斯混合模型的参数如下:
π ( 1 ) = 1 / 3 , π ( 2 ) = 2 / 3 ; \pi^{(1)} = 1/3, \quad \pi^{(2)} = 2/3; π(1)=1/3,π(2)=2/3; μ ( 1 ) = 3 , 3 , 5 , μ ( 2 ) = 6 , 6 , 15 ; (14) \mu^{(1)} = 3, 3, 5, \quad \mu^{(2)} = 6, 6, 15; \tag{14} μ(1)=3,3,5,μ(2)=6,6,15;(14) σ ( 1 ) = 2 , 2 , 3 , σ ( 2 ) = 2 , 2 , 3 . \sigma^{(1)} = 2, 2, 3, \quad \sigma^{(2)} = 2, 2, 3. σ(1)=2,2,3,σ(2)=2,2,3.
请注意,这三个维度分别对应空间水平坐标、空间垂直坐标以及时间坐标。
结果对比 (Result Comparison) 。 我们将所提方法(称为 MDP 策略)与两种基础策略进行了对比:一种是基于距离的派遣方法(Distance-based Approach),另一种是近视贪心方法(Myopic Greedy Approach)。这三种变体均使用 KM 算法在由司机和订单构建的二部图上进行求解。它们之间的区别在于边的权重:
- 基于距离的方法: 仅考虑"订单-司机"对之间的接客距离;
- 近视方法: 仅将订单的价格作为即时奖励进行考虑。
为了计算 MDP 的价值,我们从基于距离的方法和近视方法的历史交易中收集状态转移数据,并运行 DP(动态规划)算法。为了进行衡量对比,我们主要关注总收入 (定义为所有已成交订单的总价格),以及平均接客距离 和接单率(已成交订单数 / 总订单数)。所有这三种策略都在包含 100 笔订单的环境下进行了测试,而司机的数量分别设定为 25、50 或 75 名。
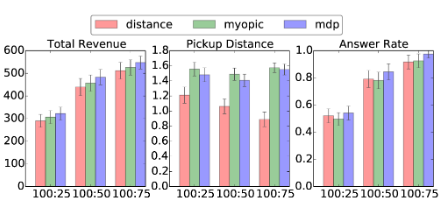
图6:在玩具示例环境中,基于距离的方法、短视方法以及所提出的MDP方法在三个指标上的比较。X轴表示订单-司机比率。彩色显示效果更佳。
图 6 展示了在不同的"订单-司机"比例下,三种方法在三个指标上的对比结果,其中每个柱状图代表 1000 次独立实验的均值和标准差。显而易见,基于距离的方法取得了最佳的接客距离表现,因为该策略将距离置于所有其他因素之上。然而,MDP 策略在总收入和接单率上均优于基于距离的方法和近视贪心方法。这与我们的初衷相一致,即前瞻性的考虑能够提升派遣系统的整体性能。
需要注意的是,随着"订单-司机"比例的增加,性能提升的幅度呈现出轻微的边际递减现象。换句话说,当需求大于供给(司机数量不足)时,MDP 策略能够发挥出最佳性能------这同样符合常理,因为该方法旨在优化全局司机的利用率,因此在司机资源紧缺时其威力更加显着。图 7 展示了在时间步 t = 3 t = 3 t=3 时的状态价值函数图。可以清楚地看到,价值的峰值非常接近第一个高斯混合模型的均值区域 ( 3 , 3 ) (3, 3) (3,3)。
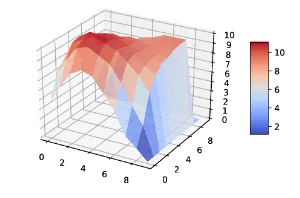
图7:在玩具示例环境中生成的时间 t = 3 t=3 t=3 时的价值函数图
6.2 模拟器 (Simulator)
除了这个玩具示例外,我们还在一个更复杂、更真实的调度模拟器上进一步评估了所提出的MDP方法。在我们的应用中,考虑到在线系统高度动态,离线模拟器的结果有时与在线实验同样重要。
实现细节: 此处使用的模拟器旨在对线上网约车平台进行彻底的物理世界建模。一个典型的样本实现是从历史数据中"回放"特定某一天的真实订单作为需求。为此,我们首先将这一天中真实发生过的订单还原为实时需求。每位司机的初始位置和时间根据其在平台上的首次出现进行初始化。司机随后的行为则完全由模拟器决定:要么根据用户定义的订单派遣算法(去服务订单),要么使用拟合自历史数据(空闲移动以及线下/线上操作)的模型来驱动。该模拟器经过了细致的校准,在绝大多数情况下,模拟结果与当天真实世界指标(如接单率和总 GMV)之间的误差控制在 2% 以内。
实验结果: 我们在该模拟器上实现了 MDP 订单派遣算法,并收集了在不同城市和日期下的运行结果。与作为基线的基于距离的策略相比,在不同城市中,总 GMV 的增幅在 0.5% 到 5% 不等。这与在玩具示例中的发现相一致,即所提算法在具有更高"订单-司机"比例(供需更紧俏)的城市中取得了更大的提升。
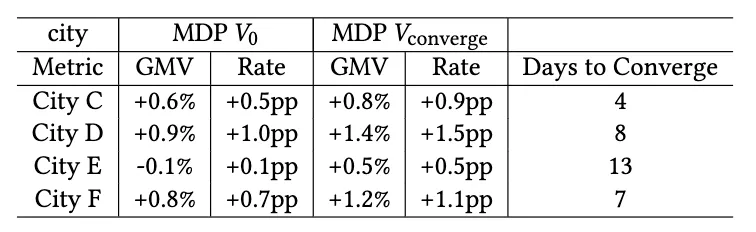
表 1:模拟器中四个中等规模城市的策略迭代结果对比。"Rate"代表订单的成交率(接单率),MDP V 0 V_0 V0 表示 V 0 V_0 V0 阶段的MDP,MDP V c o n v e r g e V_{converge} Vconverge 表示收敛阶段的MDP,最后一列是收敛天数。
注:pp 代表百分点百分比,例如 +0.5pp 表示接单率提升了 0.5%
全局 GMV 的提升源于局部视角的若干改变。例如,在某些特定城市中,通过使用 MDP 算法,前往高价值区域的订单成交率在高峰时段内可提升高达 10%。其结果是,更多的司机能够留存或转移到高价值区域,从而能够在未来服务更多潜在的订单。同时,在相同条件下,MDP 算法由于长途订单具有更大的即时奖励,会更倾向于优先派发长途订单。我们发现这能更好地匹配司机的意图。该模拟器还被用于为线上实验筛选出合适的超参数。
策略迭代的性能与收敛性: 在第 5 节中,我们提到所提的学习与规划算法可以根据策略迭代的原理,以迭代的方式进行。在这里,我们在模拟器中评估了这种方法:通过将同一天的模拟过程视为一个稳定的环境,并在其上重复进行策略迭代。具体而言,我们将基于距离的方法作为初始策略,并迭代更新价值函数和策略。表 1 展示了其与基于距离的基线策略的对比结果。更新后的策略相比基线策略以及不包含策略迭代的 MDP 策略(即 V 0 V_0 V0),取得了更高的总 GMV 和成交率。这一过程通常在十次迭代以内即可在性能提升上达到收敛。
6.3 真实世界实验 (Real-World Experiment)
在玩具示例和模拟环境中获得了令人鼓舞的结果后,我们最终在生产线上系统进行了真实世界的实验。在展示定量结果之前,我们首先详细介绍实验的设计。
A/B 测试设计 (A/B Testing Design): A/B 测试被广泛应用于在现实世界系统中对两个或多个变体进行控制变量实验。传统的网络分析通常可以采用一种简单的流量分配策略,即将用户按 50/50 或 90/10 的比例切分为两组以对比两个变体。然而,由于匹配问题中存在网络效应,这种设计并不适合我们的问题。试想如果我们将司机分组,一个订单可能会与多个组中的司机相连。此时,如何使用不同方法计算出的边权重来为该订单选择最佳匹配,将会变得非常混乱。
在实际应用中,我们采用了定制化的 A/B 测试设计,即按照大时间片(三小时或六小时)来切分流量。例如,在 3 小时切分模式下,第 1 天的前三个小时运行变体 A,接下来的三个小时运行变体 B。第 2 天则将这一顺序反过来。此类实验将持续两周,以消除日度间的差异。我们选择较大的时间片,是为了观察订单派遣方法所带来的长期影响。
实验设置与结果: 所提方法已经历了多轮 A/B 测试,覆盖了中国的多个城市。其中的 MDP 价值函数是基于前一个月历史数据通过动态规划计算得出的。我们分别为工作日和周末计算了独立的价值。对于超参数,我们使用的折扣因子为 γ = 0.9 \gamma = 0.9 γ=0.9。
同样,我们将所提的 MDP 方法与作为基线的基于距离的方法进行了对比。需要说明的是,我们没有与文献 24 进行对比,因为滴滴出行此前已经完成了从 24 中所使用的传统"司机选单模式"到本文所研究的新型"平台派单模式"的切换,而这一切换本身就已经带来了显着的效率提升。
实验结果表明,MDP 方法带来的性能提升在所有城市中都是一致的,其在全局 GMV 和成交率(接单率)上的增幅在 0.5% 到 5% 不等。与先前的发现一致,MDP 方法在"订单-司机"比例高(供需紧俏)的城市中取得了最佳的性能提升。同时,平均派单时间与基线方法几乎完全相同,这表明用户体验几乎没有受到任何牺牲。鉴于这些良好的结果,所提算法已成功部署在滴滴出行的线上派遣系统中,覆盖了 20 多个主要城市,每天为中国数以千万计的行程提供服务。
价值函数的视觉化: 除了定量结果外,我们通过在城市地图上对学习到的价值函数进行视觉化,还发现了一些有趣的现象。例如,图 8 展示了中国某城市在两个不同时间段内的价值分布。
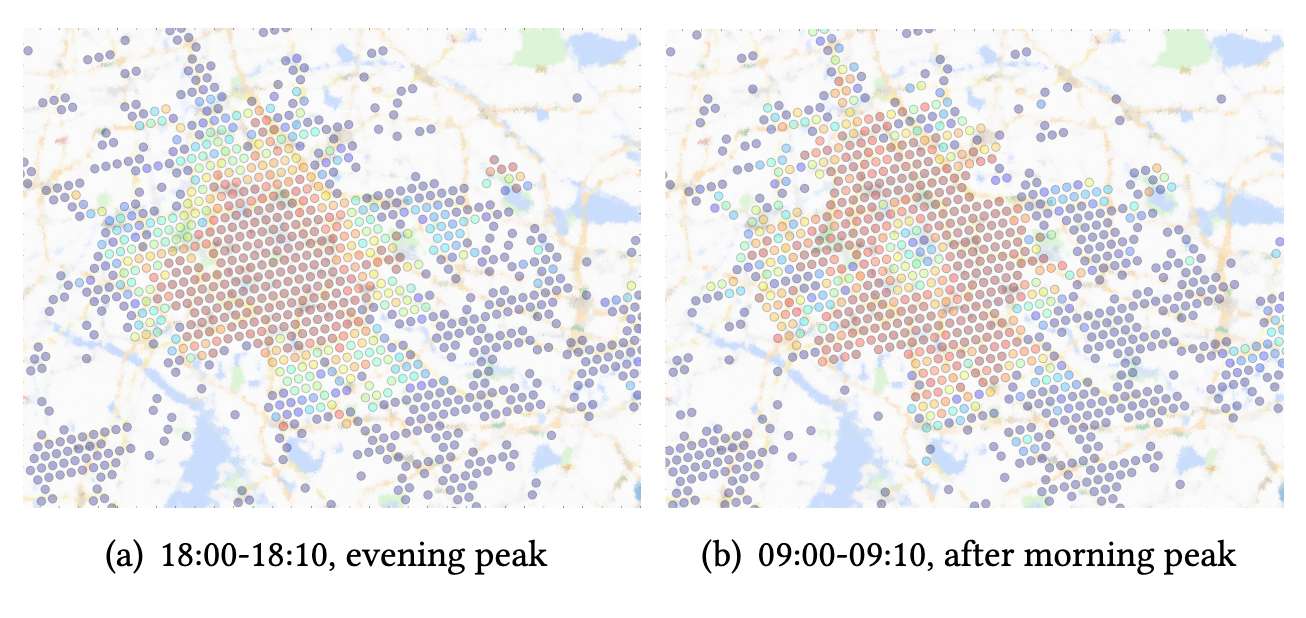
图8:同一城市在不同时间的采样值函数。红色表示值较高,蓝色表示值较低。彩色显示效果更佳。
不出所料,市中心区域的价值明显高于城市中的其他地方。然而,如果仔细观察图 8(b),我们可以发现,在 9:00 早高峰刚刚过去时,最中心区域的价值实际上有所下降。这一现象可以解释为:在早高峰期间,大量的司机因执导前往市中心的订单而被带到了中心区域,导致该区域此时的司机数量远多于订单请求,从而使其价值相对低于周边区域。因此,在这种情况下,平台驱动的引导对于实现更平衡的供应分布潜在地非常有帮助。类似的观察结果也推动了平台上许多其他应用的发展。
7. 相关工作 (RELATED WORKS)
我们提出的 MDP 派遣系统的设计与以下两个研究方向密切相关:出租车派遣和多智能体系统。
出租车派遣 (Taxi Dispatch): 在现有文献中,出租车派遣通常是指引导空载司机去寻找新订单的过程。我们将其称为司机派遣(Driver Dispatch)。例如,Li 等人 7 根据时空特征为司机派遣提供了一种寻找乘客的策略。Qu 等人 16 提供了另一种方法,通过推荐最佳行驶路线来最大化司机的利润。Miao 等人 13 提出了一种滚动时域控制方法,在应对需求不确定性的同时,减少司机空驶里程并维持服务质量。这些方法在重新平衡供应端以更好地满足需求方面,取得了令人鼓舞的成果。
作为出租车派遣的一种特殊形式,本文聚焦于订单派遣(Order Dispatch),即使用中央决策模块将司机指派给现有的订单。传统的订单派遣方法通常基于队列策略来匹配供需 6, 17, 25。最近,几项关于出租车订单派遣的工作整合了各种需求预测 14, 20 组件,以促进具有前瞻性考虑的派遣决策。例如,Zhang 等人 24 提出了一个通过结合需求预测、乘客目的地预测和组合优化,能够同时处理多个预约订单的框架。与这些研究相比,我们的方法为优化平台的长期效率提供了一个更完整的整合框架。
多智能体系统 (Multi-Agent Systems): 多智能体系统在机器人团队、资源管理、分布式控制等众多领域得到了广泛的研究 1, 3, 9, 21。在资源管理中,运筹学领域 18 和强化学习领域 5, 11 都对该问题进行了探讨。相比于运筹学方向旨在寻找全局最优但通常需要巨大计算开销的解决方案,我们的方法为了能够在实时系统中实施,有着更严格的复杂度限制。因此,我们将其建模为一个集中式的多智能体问题,并使用强化学习来求解。
8. 结论与未来工作 (CONCLUSIONS AND FUTURE WORK)
在本文中,我们提出了一种新型订单派遣算法,旨在优化平台的长期效率,并同时满足即时的客户需求。为此,我们将订单派遣建模为一个序列决策问题,其中每个"司机-订单"对的价值被计算为即时奖励(订单的效用)与从历史数据中学习到的长期预期价值之和。随后,以集中且协同的方式确定多名司机与多个订单之间的匹配。在模拟器上的实验和线上 A/B 测试揭示了所提方法的有效性,相比于作为基线的基于距离的方法,在总收入和订单成交率上都带来了显着的提升。基于这些结果,所提方法已在滴滴出行的现实世界派遣系统中成功部署。
对于未来的工作,我们有兴趣研究用于订单派遣的深度强化学习方法,该方法直接使用原始 GPS 系数作为输入,以消除区域划分带来的边界效应,并融合更丰富的实时特征。同时,将订单派遣和司机派遣结合在一起,在一个统一的框架内平衡供需,也具有强烈的现实动力。此外,研究该方法在物流领域的其他组合优化问题中的应用也是有益的,例如减少能源消耗、供应链管理以及交通领域的其他应用。我们正积极为这些任务寻求潜在的解决方案。