加入了一些和java的对比
True
在python中:True本质上是整数类型,可以与整数做运算
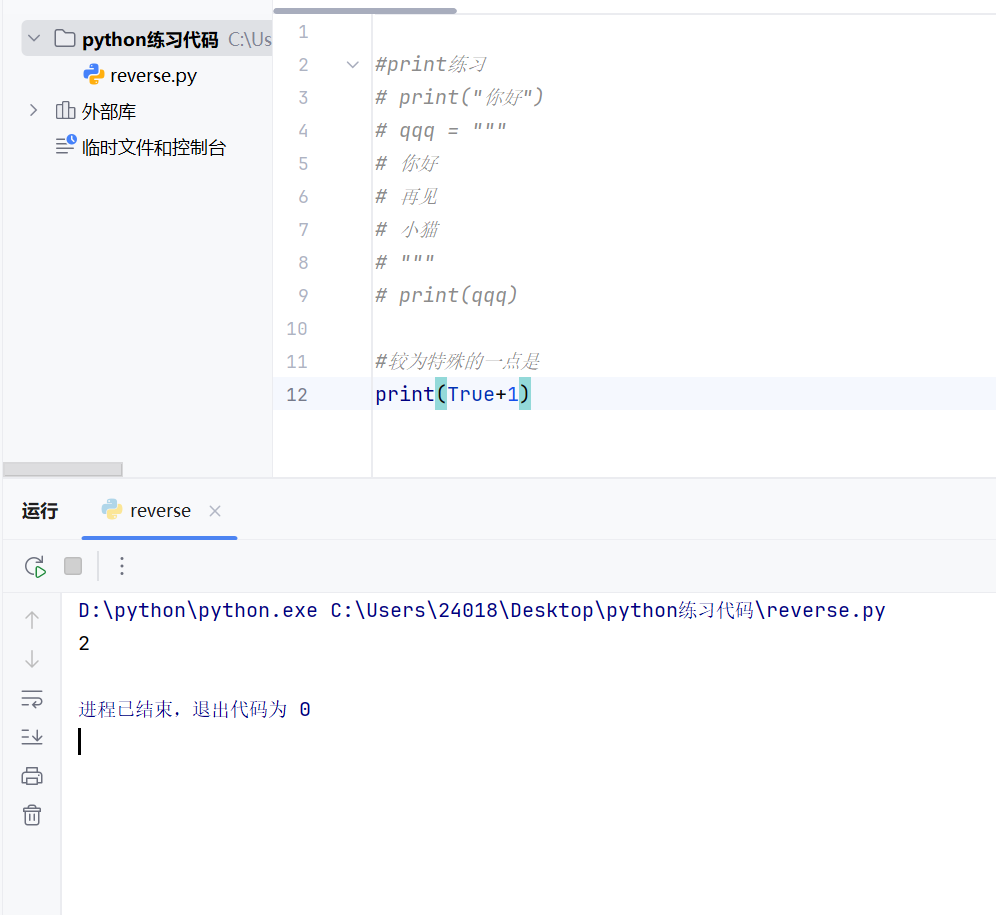
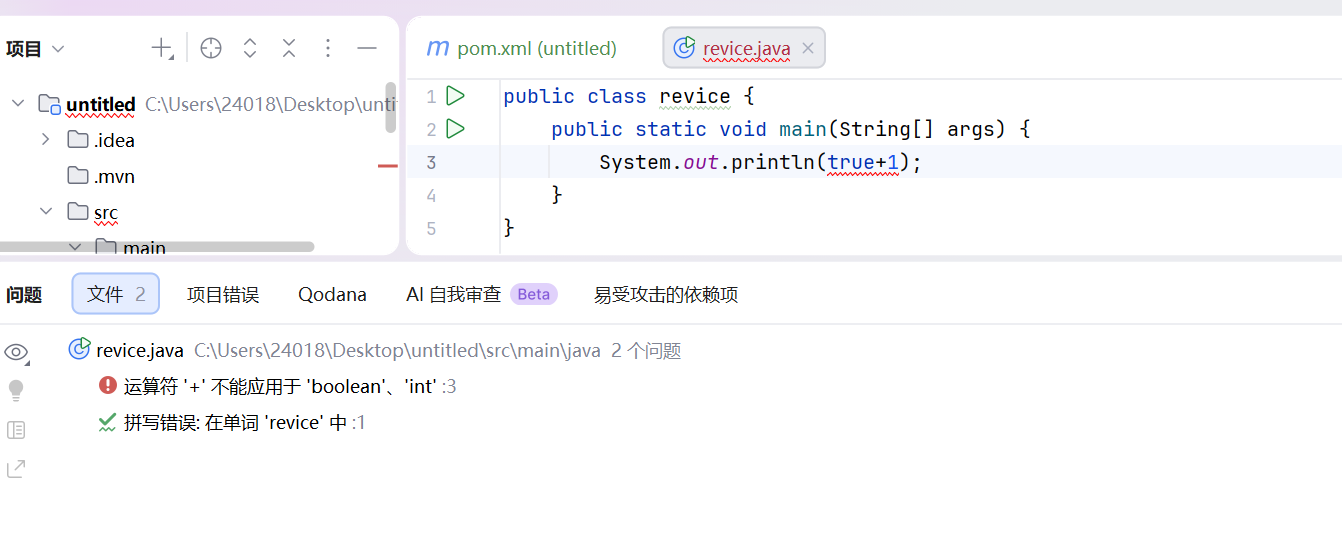
java中则不能
python中的类型相关的函数
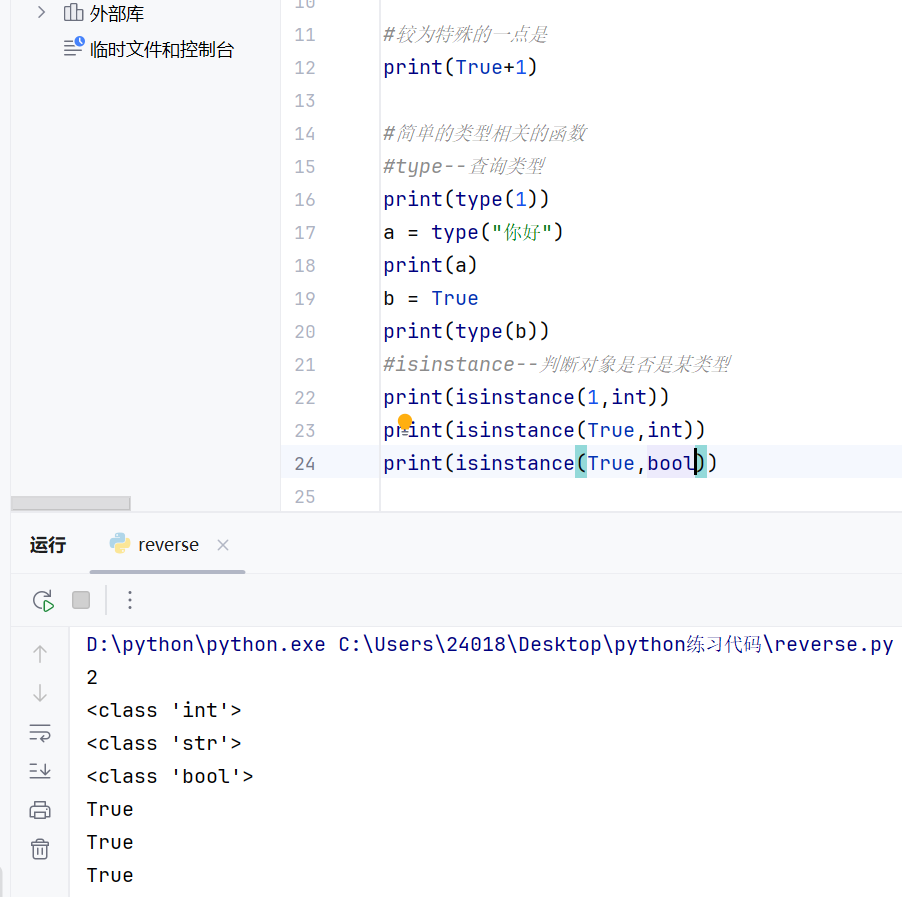
True既是int类型又是bool类型
打印包含参数的语句
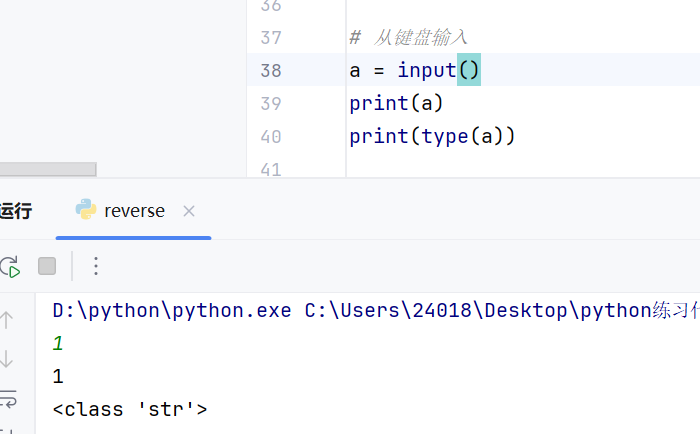
接受键盘输入的数据input
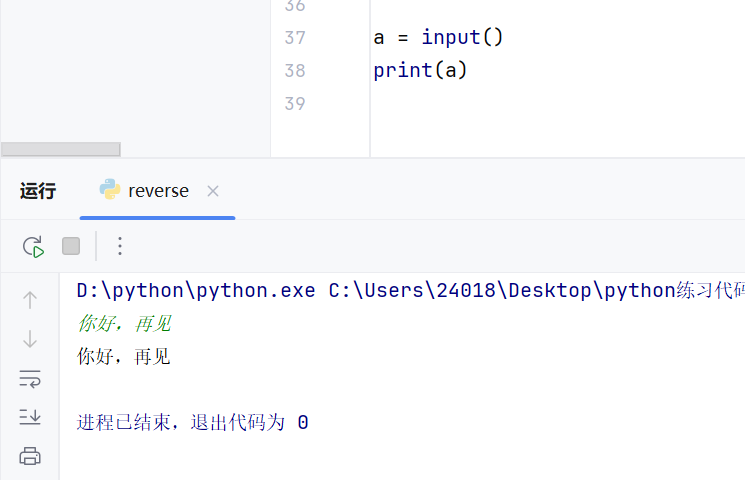
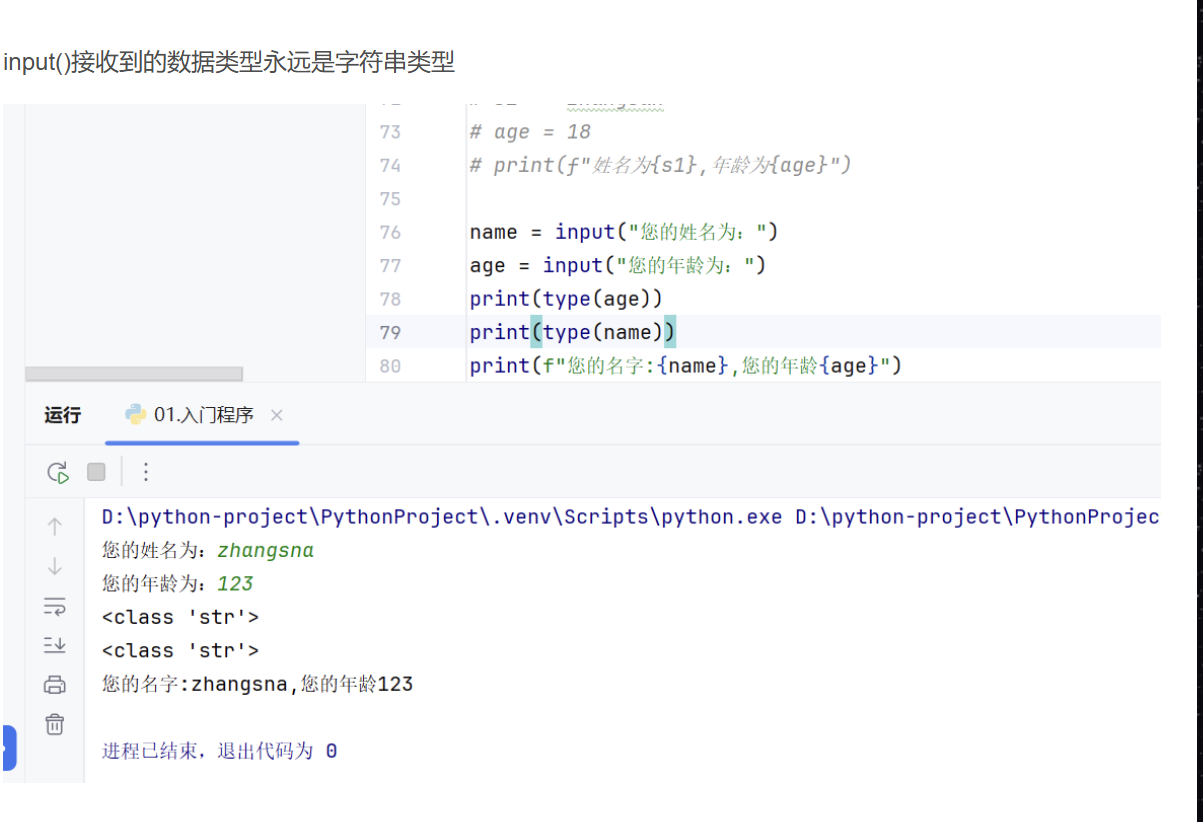
input键盘输入的数据类型永远是字符串类型
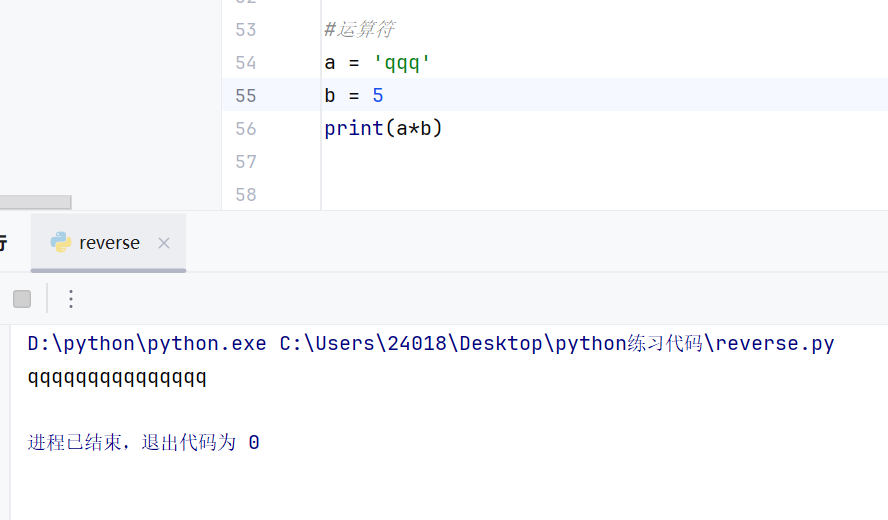
运算符
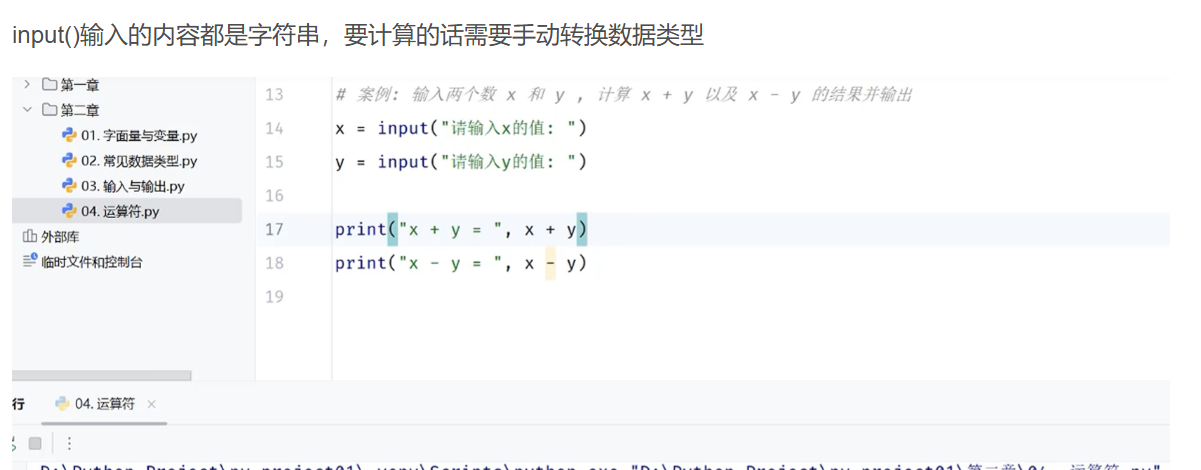
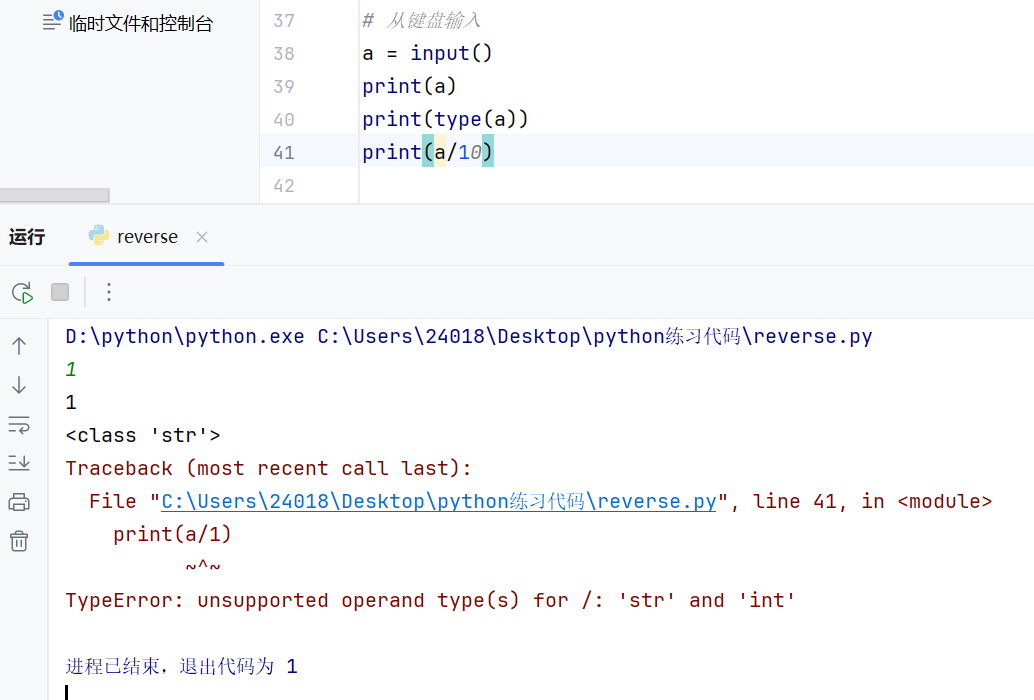
转换数据类型的方法如下
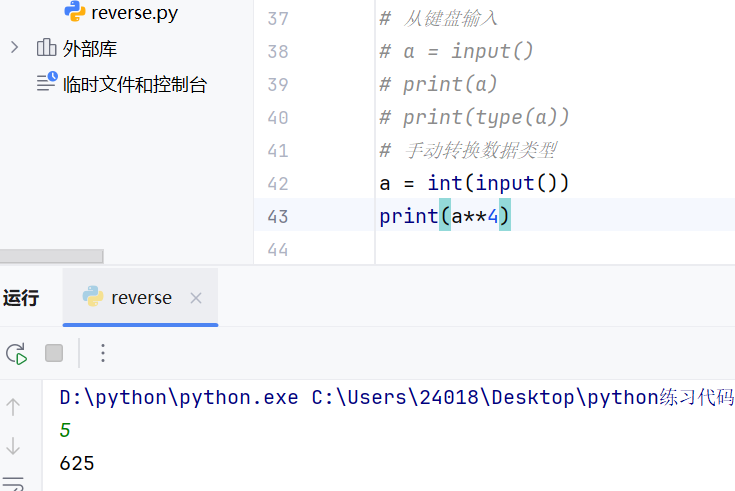
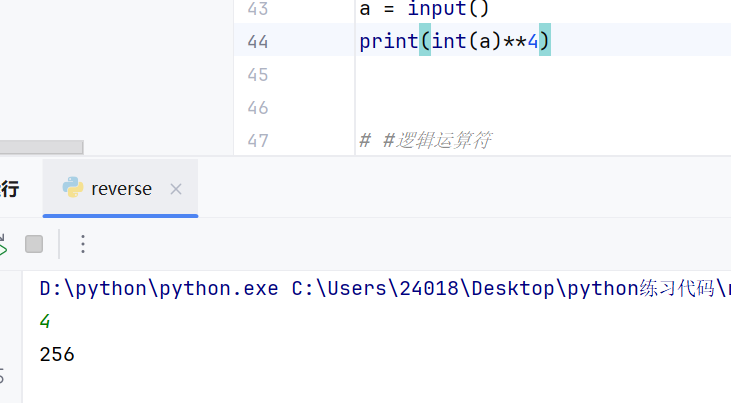
例如字符串和整型之间不能进行除法运算
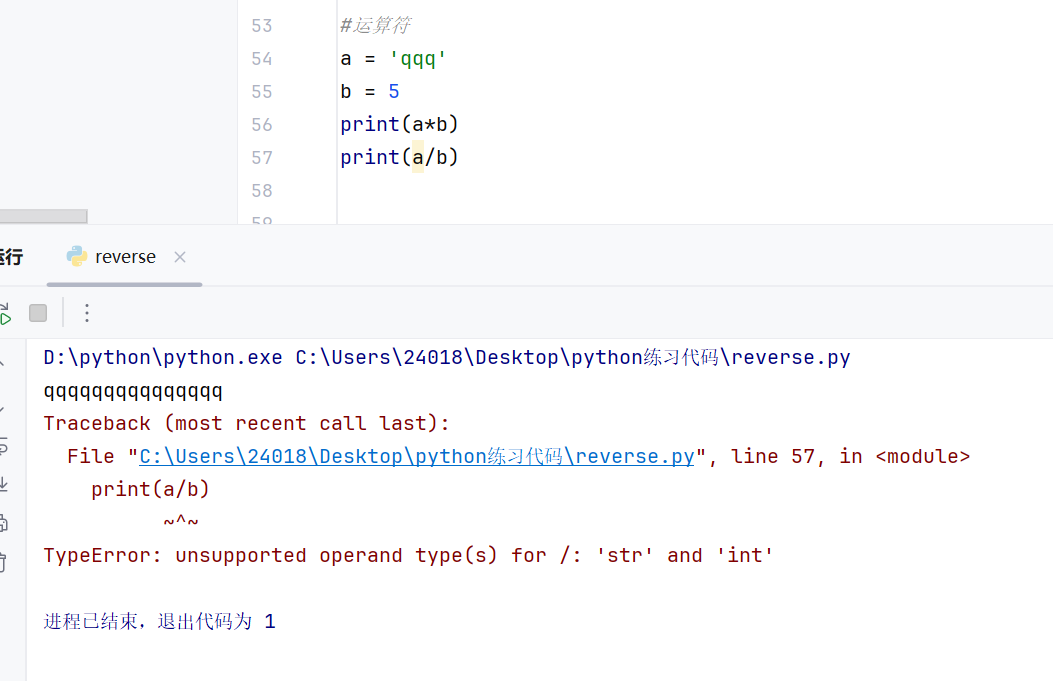
字符串和整型之间可以进行乘法运算
java中可以指定接受的数据类型
java
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// 创建 Scanner 对象
Scanner scanner = new Scanner(System.in);
// 读取整数
System.out.print("请输入一个整数: ");
int age = scanner.nextInt();
// 读取一行字符串
System.out.print("请输入一行文字: ");
String text = scanner.nextLine(); // 注意:这里可能会遇到坑,见下方说明
System.out.println("你输入的整数是: " + age);
System.out.println("你输入的文字是: " + text);
// 使用完毕后关闭资源
scanner.close();
}
}逻辑运算符
python中的逻辑运算符和java中的不一样,java中是&& || !,python中是and or not

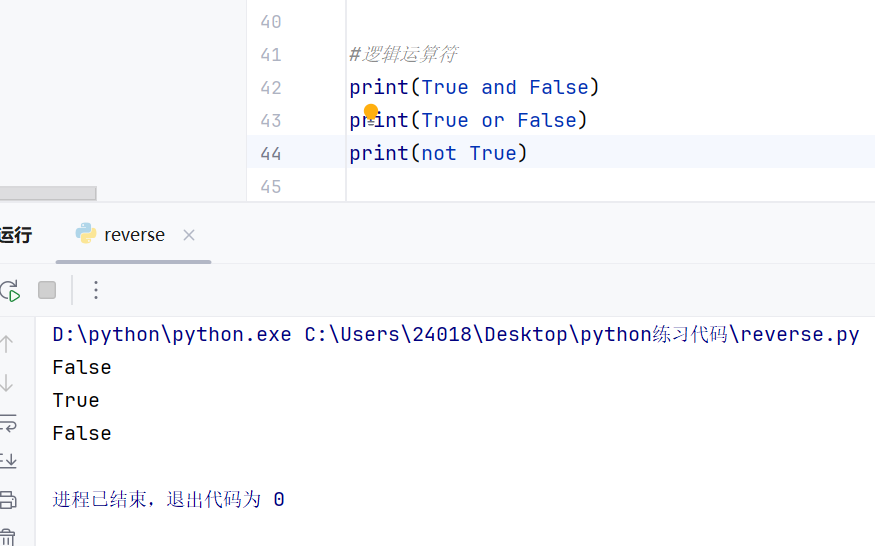
用法是一样的
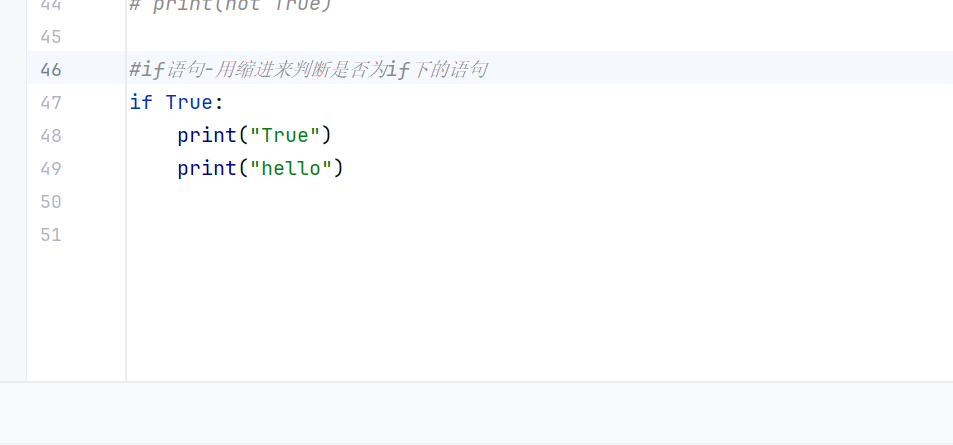
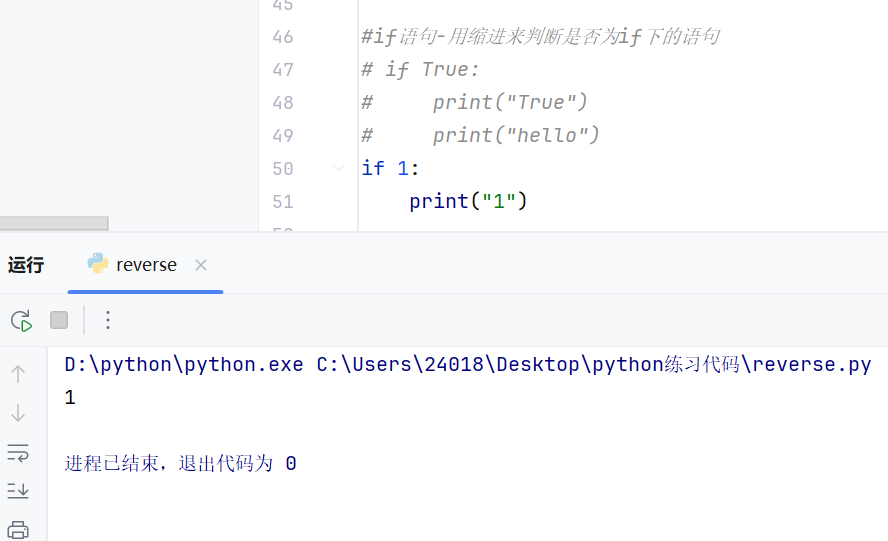
if语句
match模式匹配

和java中的switch基本一致
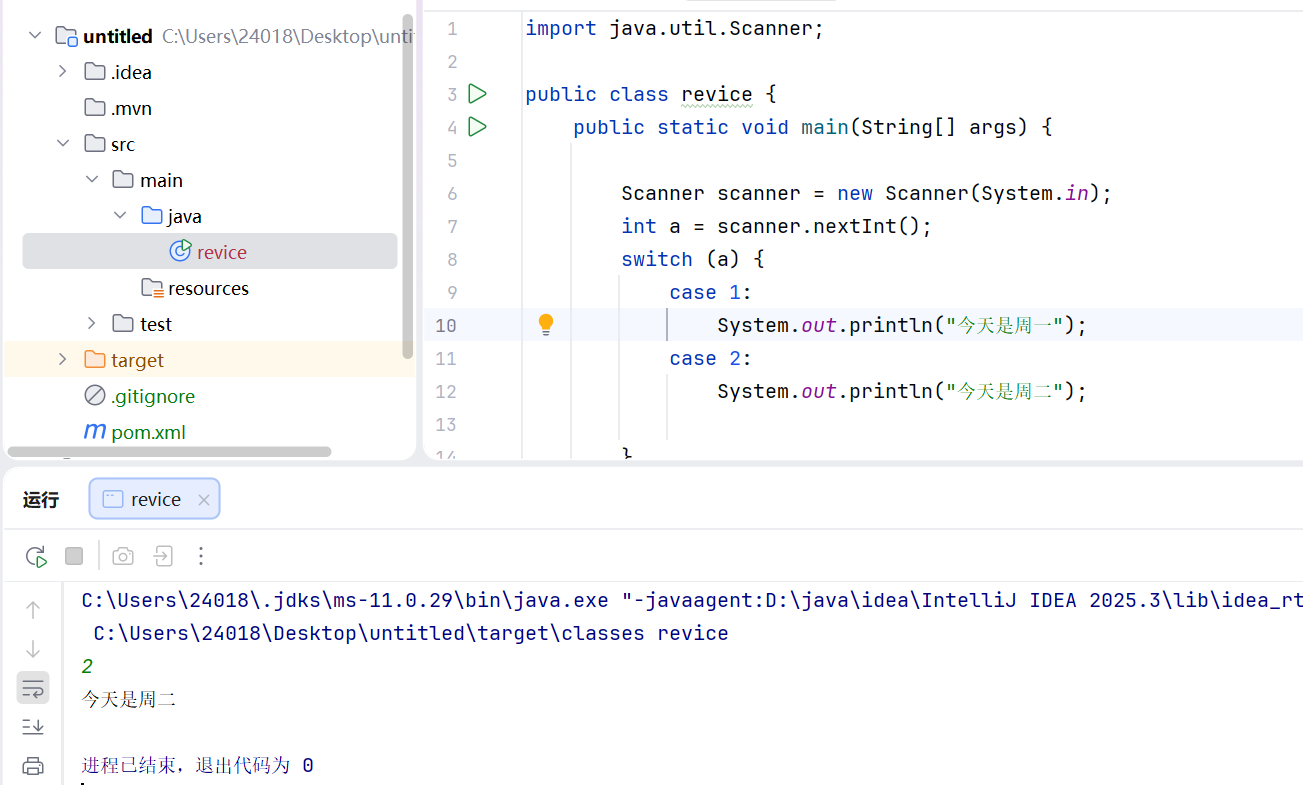
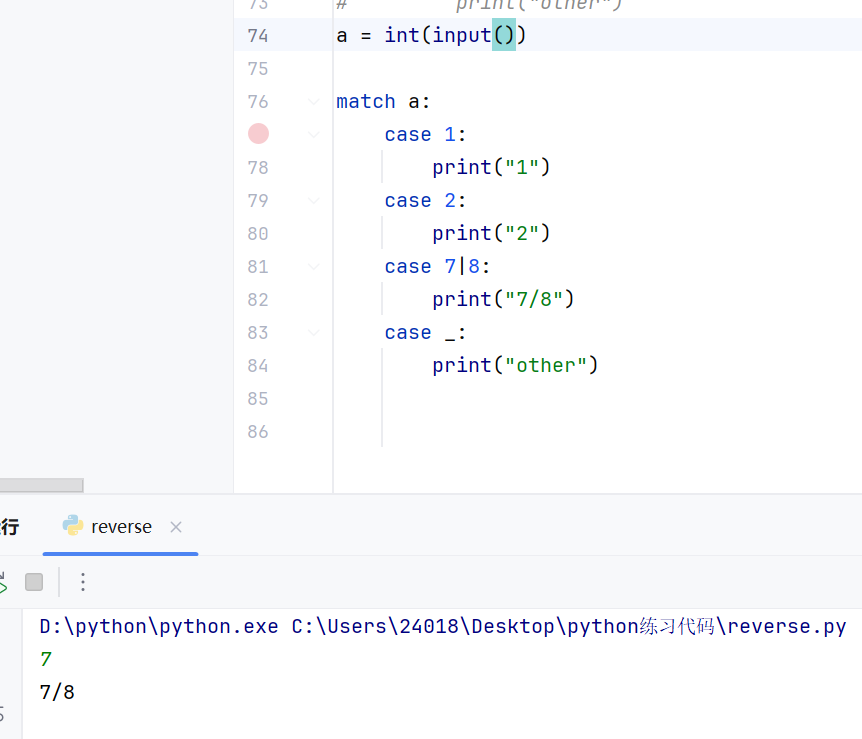
两个特殊用法:_表示其他所有,|表示或者
while循环
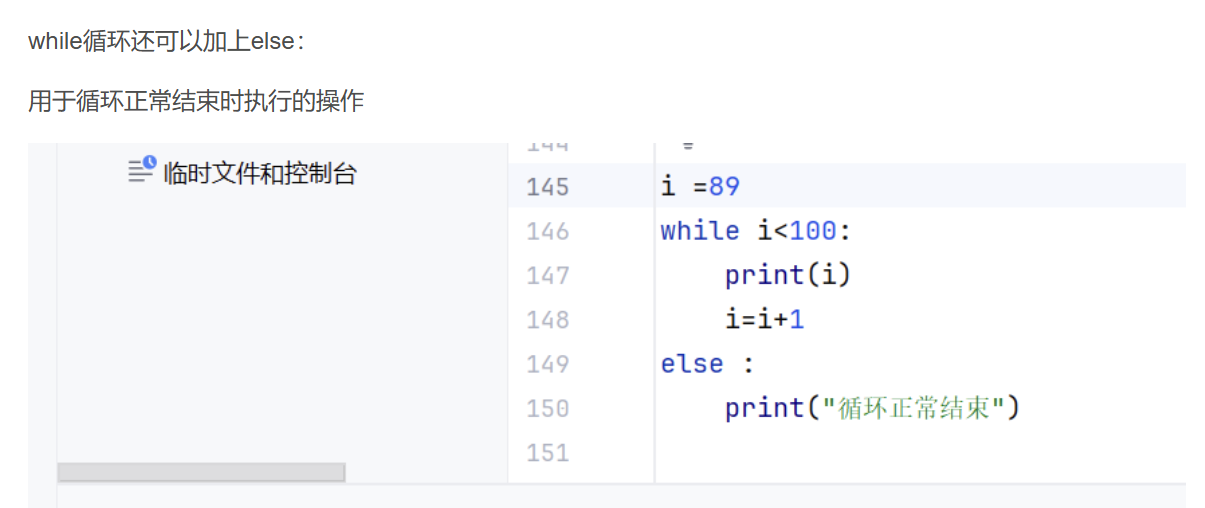
while后面可以加else,用于循环正常结束执行的操作
Python 提供它是为了处理带有 break 的搜索/遍历场景,让你不需要专门定义一个变量来记录"循环是否被中断过"。这是一种更优雅的编程范式。
java
nums = [1, 2, 3, 4]
target = 5
found = False
i = 0
while i < len(nums):
if nums[i] == target:
found = True
break # 找到了,强行跳出循环
i += 1
else:
# 只有当循环是因为 i >= len(nums) 而结束时,才会走到这里
# 如果上面触发了 break,这里会被跳过!
print(f"没找到 {target},循环是自然跑完的")
if found:
print("找到了!")for循环
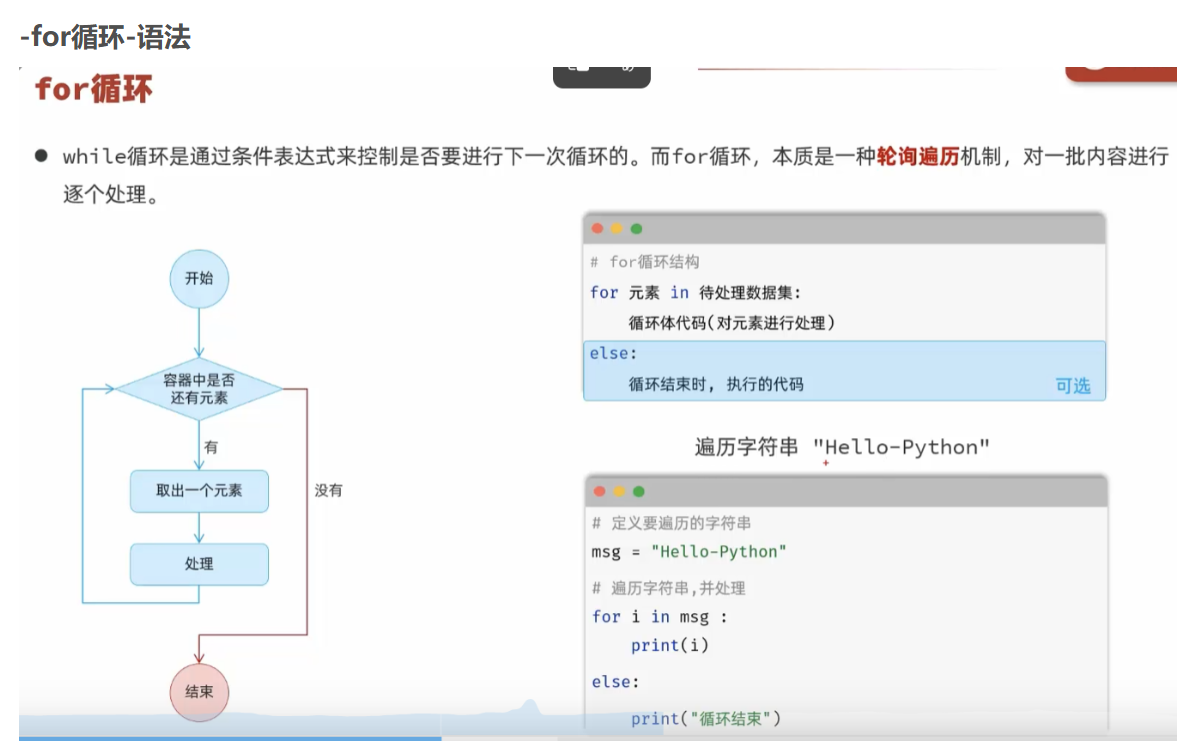
在python中对for循环和while循环作出了明确的区分:
for循环本质是一种轮询遍历机制,对一批内容进行逐个处理
while循环本质是看条件表达式控制是否要进行下一次循环的
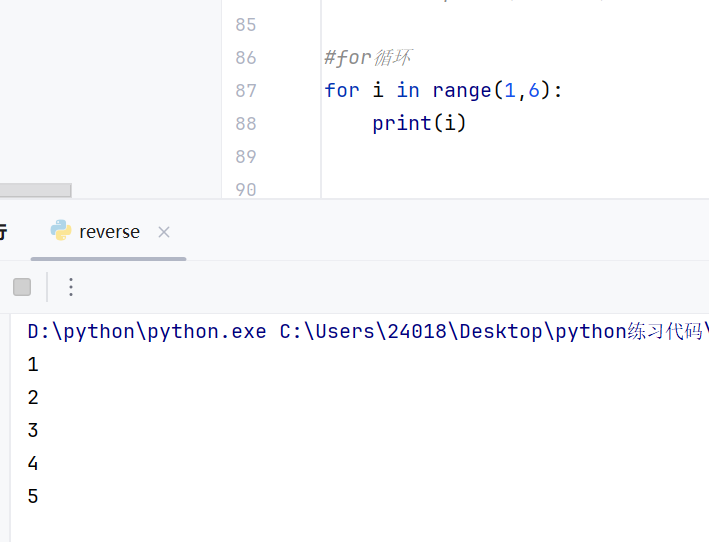
同样的for循环也有else机制:循环正常结束会执行else内的代码
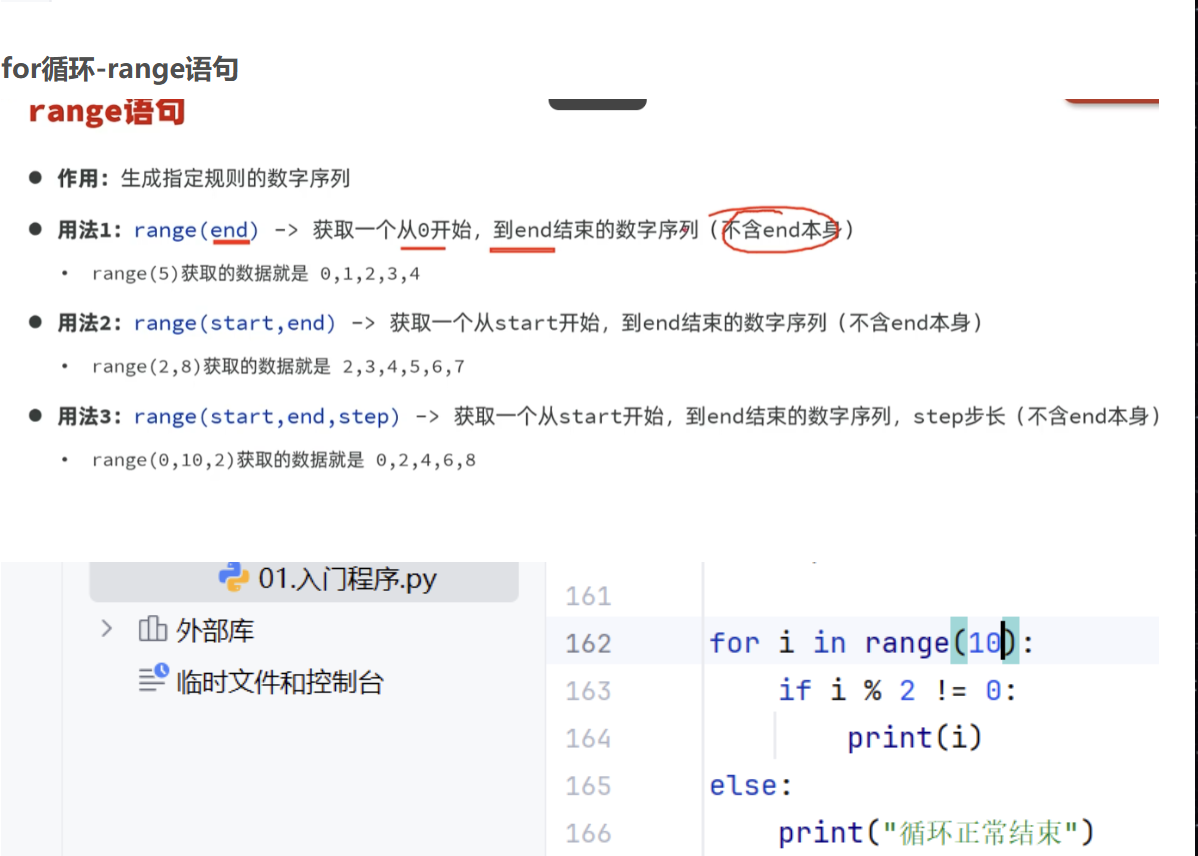
for循环的重要伙伴:range语句
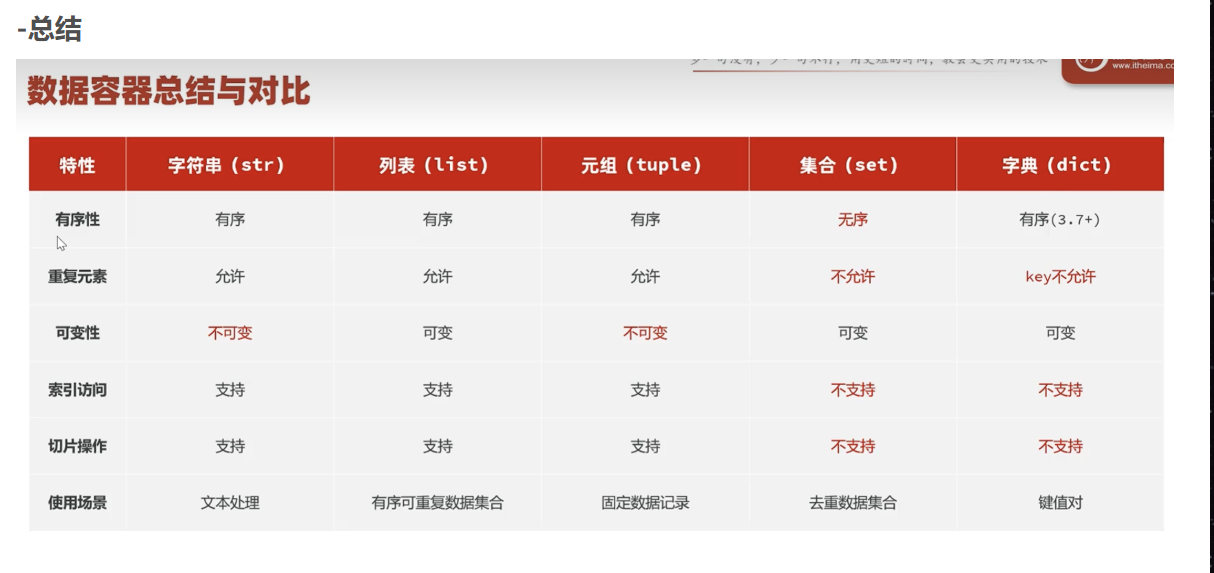
python--数据容器
python中的数据容器有和java中不同的地方--比语法上的不同更大
| 核心特征 | Python | Java | 一句话记忆 |
|---|---|---|---|
| 有序、可变列表 | list |
ArrayList |
最常用的一对,都是动态数组。 |
| 键值对(有序) | dict |
LinkedHashMap |
Python 字典默认有序;Java 需加 Linked 前缀。 |
| 去重集合 | set |
HashSet |
都是基于哈希,元素不重复。 |
| 不可变数据 | tuple |
Record |
都是只读数据载体。 |
python中的list
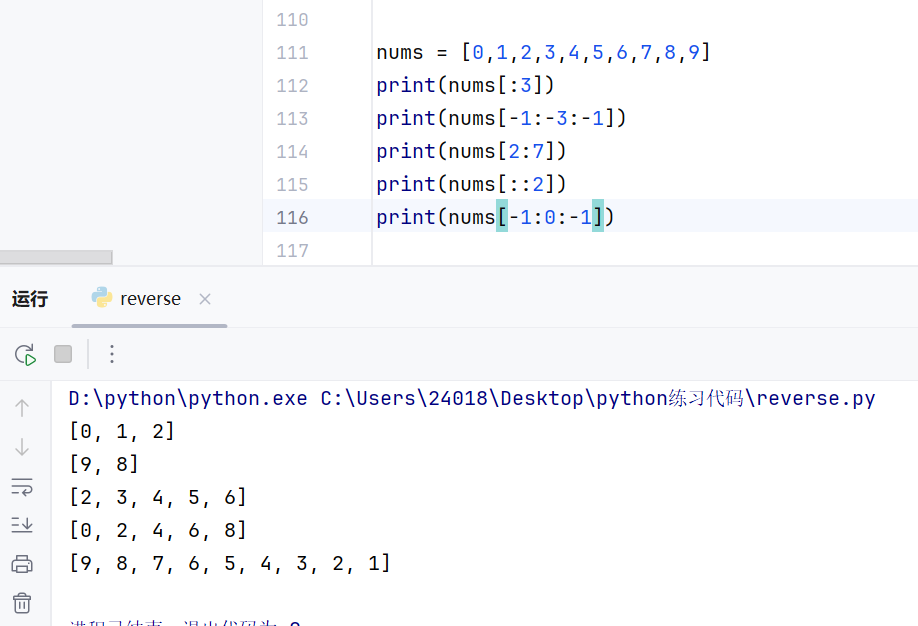
独特的根据下标切片:
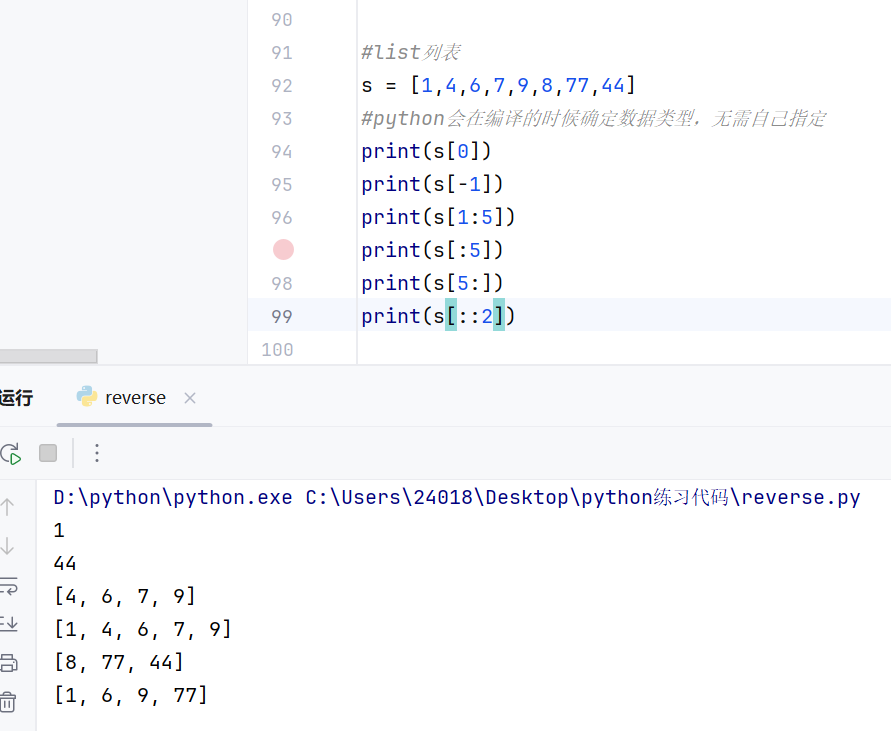
切片的方向问题
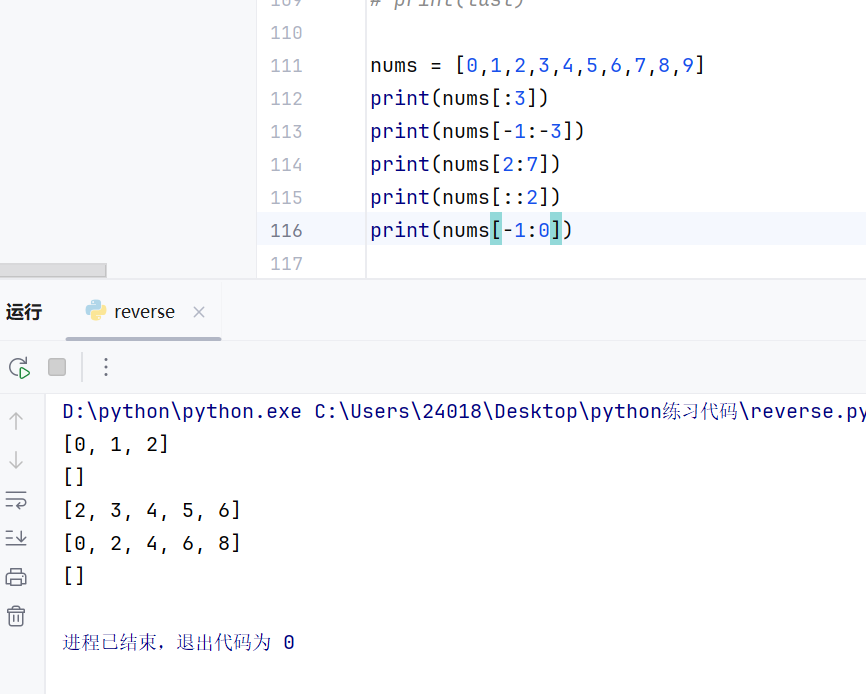
切片默认为正向取值:反向取值要用步长为-1
列表的常用方法

主要在三个方面:
增:在列表的尾部追加元素append,在指定索引之前插入该元素insert
删:根据值删除remove,根据索引位置删除或者默认删除最后一个pop
排序:sort对列表做出排序,reverse对列表元素反转
推导式
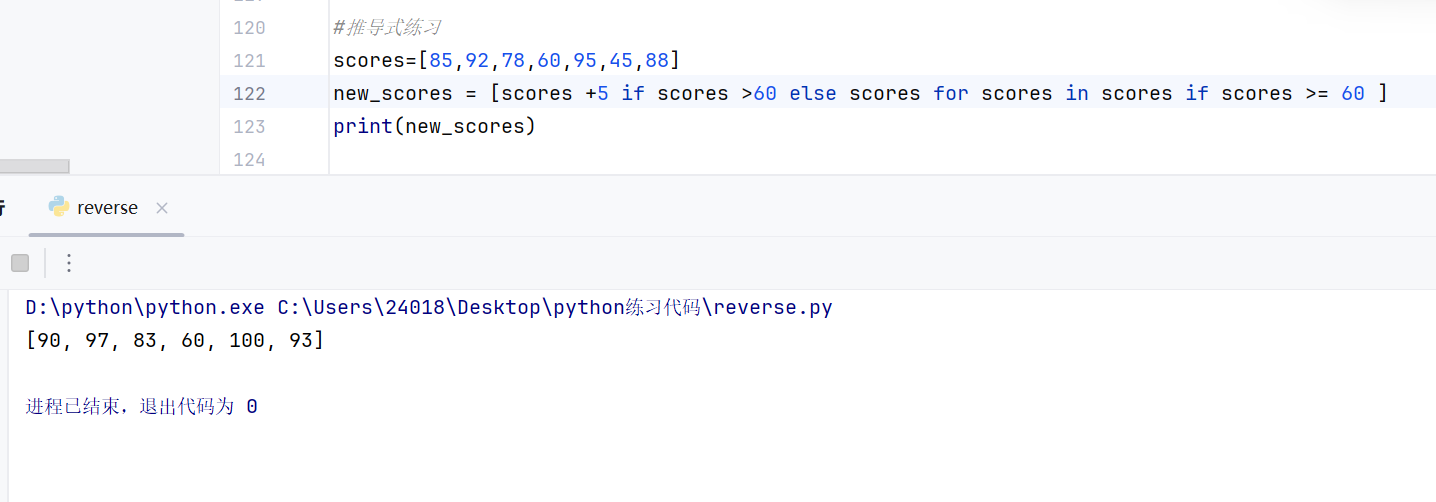
两个if
在for前面的 if--->用于映射
在for后面的if--->用于筛选
else的含义
这里的 else 确实不是 我们平时写流程控制(比如 if...else... 代码块)时的那个"否则"。
在列表推导式中,它属于 三元运算符(Conditional Expression) 的一部分。
为了让你彻底分清这两个 else 的区别,我们需要把列表推导式拆成两个完全不同的场景来看:
核心区别:位置决定含义
在列表推导式中,if 可以出现在两个位置,含义完全不同:
-
放在
for后面 :这是 过滤器。- 作用:决定 "要不要" 这个元素。
- 语法:
[x for x in list if condition] - 注意:这里不能加
else。
-
放在
for前面 :这是 三元运算。- 作用:决定 "变成什么"(二选一)。
- 语法:
[A if condition else B for x in list] - 注意:这里必须搭配
else,因为 Python 需要知道如果不满足条件时该放什么值进去。
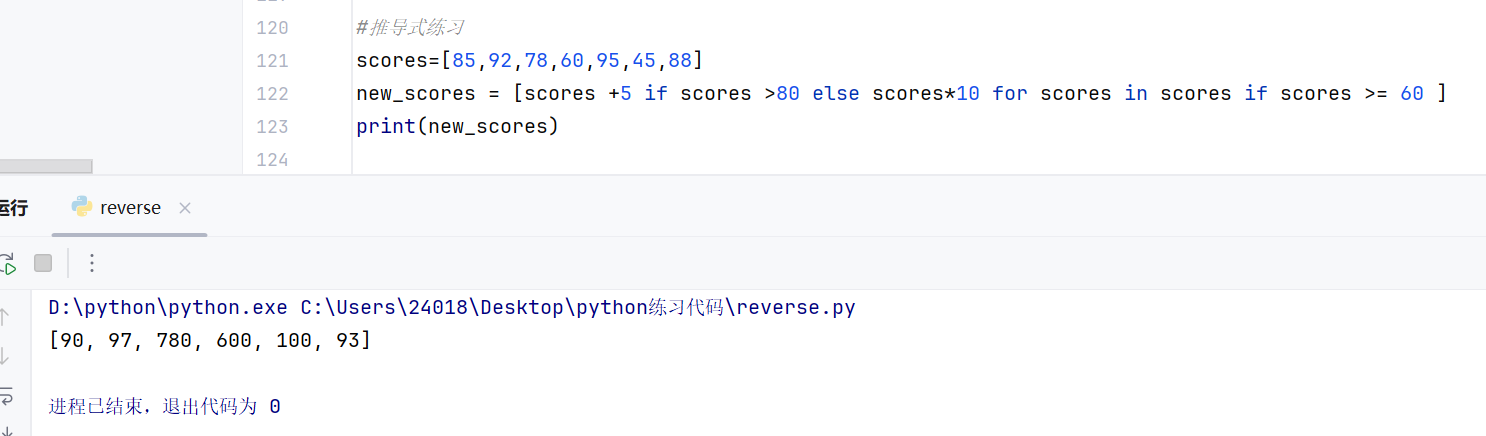
java
new_scores = []
for s in scores:
# 第一步:处理 for 后面的 if (过滤器)
# 如果分数小于 60,直接跳过,根本不看前面的逻辑
if s >= 60:
# 第二步:处理 for 前面的 if...else (三元运算/赋值)
# 此时程序已经确定要保留这个分数了,现在决定把它变成多少
if s > 60:
val = s + 5 # 如果大于60,就加5分
else:
val = s # 否则(也就是等于60时),保持原样
new_scores.append(val)for前面的表示决定要变成什么如果满足if条件就执行if前面的,如果不满足if条件就执行else后面的
python的推导式和java的stream流的对比
- 核心概念对照表
| 动作 | Python 推导式语法 | Java Stream 方法 | 作用 |
|---|---|---|---|
| 遍历 | for x in list |
.stream() |
开启数据流/循环 |
| 映射 (变换) | x * 2 (写在最前面) |
.map(x -> x * 2) |
把旧元素变成新元素 |
| 过滤 (筛选) | if x > 0 (写在最后面) |
.filter(x -> x > 0) |
剔除不需要的元素 |
| 收集 (结果) | [...] (方括号自动完成) |
.collect(Collectors.toList()) |
把处理完的数据装回容器 |
- 场景一:单纯的"映射"(加工数据)
需求:把一个列表里的所有数字都乘以 2。
-
Python (推导式):
1nums = [1, 2, 3] 2# 语法结构:[ 变换公式 for 变量 in 列表 ] 3result = [x * 2 for x in nums] 4# 结果: [2, 4, 6] -
Java (Stream):
1List<Integer> nums = Arrays.asList(1, 2, 3); 2// 语法结构:流 -> map变换 -> 收集 3List<Integer> result = nums.stream() 4 .map(x -> x * 2) 5 .collect(Collectors.toList());
对比:Python 把"变换公式"提到了最前面,读起来像英语:"给我 x*2,对于每一个 x..."。Java 则是链式调用,逻辑流向是从左到右。
- 场景二:映射 + 过滤(最常用的组合)
需求:找出列表中所有的偶数,并计算它们的平方。
-
Python (推导式):
1nums = [1, 2, 3, 4, 5, 6] 2# 语法结构:[ 变换 for 变量 in 列表 if 条件 ] 3# 注意:if 放在最后面! 4result = [x**2 for x in nums if x % 2 == 0] 5# 结果: [4, 16, 36] -
Java (Stream):
1List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5, 6); 2List<Integer> result = nums.stream() 3 .filter(x -> x % 2 == 0) // 先过滤 4 .map(x -> x * x) // 再映射 5 .collect(Collectors.toList());
关键区别:
Python :
if必须写在for后面。Java :
.filter()和.map()的顺序通常可以互换(但在性能上,通常建议先 filter 减少数据量,再 map)。
解包与组包
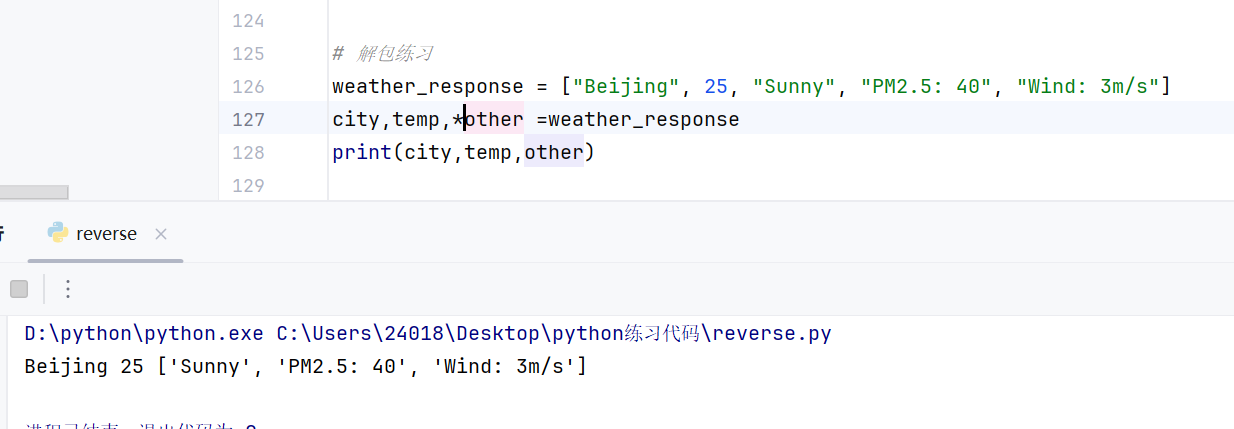
解包和list索引的区别
用索引(Indexing)确实能取出数据,而且对于只有 5 个元素的列表来说,索引看起来甚至更直观。
但在企业级开发中,我们极力推崇"解包"而不是"索引",主要基于以下 4 个核心原因:
- 代码的"自解释性" (可读性)
-
索引写法:
data[0],data[1]- 问题: 当你看到
data[0]时,你必须去查文档或者回忆:"第 0 个到底是城市名?还是温度?还是状态码?"如果代码隔了两个月再看,或者别人接手你的代码,这简直是噩梦。
- 问题: 当你看到
-
解包写法:
city, temp, ... = data- 优势: 变量名本身就是注释。一眼就能看出这个位置代表什么业务含义。
场景对比
假设你有一个包含 20 个字段的数据库行记录。
索引法:
row[3] + row[7](鬼知道这是啥?)解包法:
name, age, email, address... = row(清晰明了)
- 处理"动态长度"数据的唯一解法
这是解包最强大的地方。如果你的列表长度不固定,索引就没法用了。
假设 API 返回的数据有时包含"风速",有时不包含:
1# 情况 A:有 5 个元素
2weather_A = ["Beijing", 25, "Sunny", "PM2.5: 40", "Wind: 3m/s"]
3
4# 情况 B:只有 3 个元素
5weather_B = ["Shanghai", 28, "Rainy"]-
如果用索引: 你需要写大量的
if len(data) > 4:判断,防止报错IndexError。 -
如果用解包: 一行代码通吃所有情况。
1# 无论后面有多少个元素,统统扔进 other 里;如果没有,other 就是空列表 []
2city, temp, *other = weather_A # other -> ['Sunny', 'PM2.5: 40', 'Wind: 3m/s']
3city, temp, *other = weather_B # other -> ['Rainy']
这种 "兜底" 的能力是索引做不到的。
- "防御性编程" (安全性)
在企业开发中,数据安全至关重要。
-
索引的风险: 如果上游接口变了,少传了一个字段,你用
data[4]取值时会直接抛出异常导致程序崩溃,或者如果你不小心写错索引取了data[3](原本应该是 PM2.5),程序不会报错,但会算出错误的结果(静默错误)。 -
解包的保护: 解包是一种 "契约" 。如果你写了
city, temp, status = data,但数据里只有两个值,Python 会立即报错ValueError。这能让你在开发阶段就迅速发现数据结构不对,而不是等到上线后产生脏数据。
- 性能与 Pythonic 风格
虽然对于小列表性能差异忽略不计,但在底层实现上,解包是 C 语言层面的操作,通常比多次调用 __getitem__(索引访问)要快一点点。
更重要的是,它是 Python 的标志性语法。在面试或 Code Review 中,使用解包会被认为你"懂 Python",而大量使用索引往往被认为是从 C/Java 转过来还没适应 Python 思维的表现。
总结建议
-
什么时候用索引?
-
当你只需要取中间某一个 特定的值,且不在乎其他值时。例如:
last_item = my_list[-1]。 -
当你在做数学矩阵运算(如 NumPy)时。
-
-
什么时候用解包?
-
当你需要同时获取多个值并赋予它们有意义的名字时。
-
当你要处理不定长 的数据(使用
*)时。 -
当你希望代码读起来像自然语言时。
-
解包的常用方式
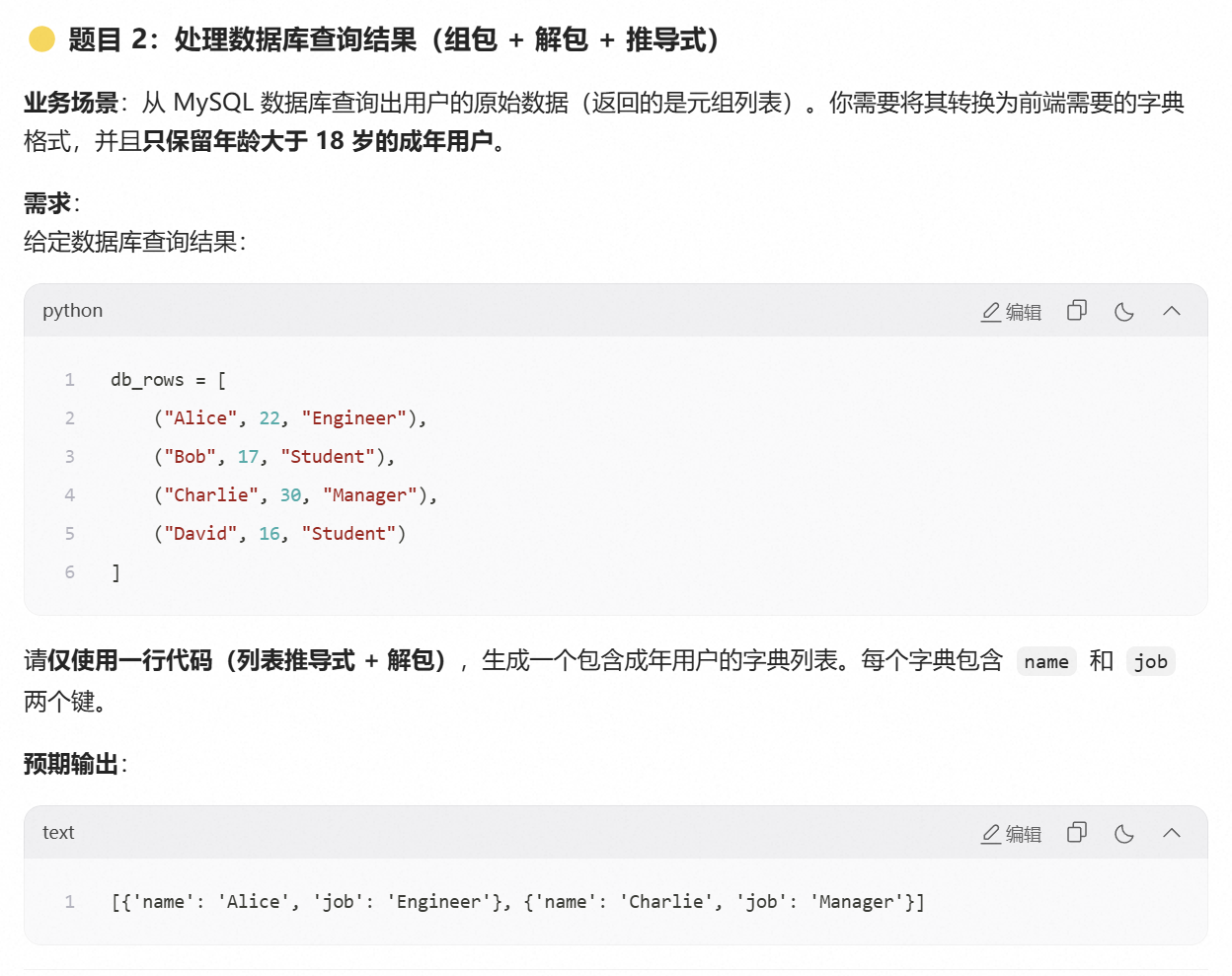

核心概念:什么是"列表推导式"?
简单说,它就是把 "创建一个空列表 -> 循环遍历 -> 判断条件 -> 添加数据" 这四步操作,压缩成了一行代码。
我们来看题目 2 的要求:
-
来源 :
db_rows(数据库查出来的原始数据)。 -
动作 :把里面的元组
(名字, 年龄, 职业)变成字典{'name': 名字, 'job': 职业}。 -
筛选:只要年龄大于等于 18 岁的。
第一步:先看"传统写法"(保姆级拆解)
如果不使用推导式,我们需要写一个完整的 for 循环。请仔细看下面的注释,这就是推导式的内部逻辑:
python
# 1. 准备一个空篮子(结果列表)
result = []
# 2. 开始遍历原始数据
for row in db_rows:
# 【解包】把这一行的数据拆开,分别赋值给变量
# 比如第一行 ("Alice", 22, "Engineer")
# name 变成了 "Alice"
# age 变成了 22
# job 变成了 "Engineer"
name, age, job = row
# 【过滤】检查年龄是否成年
if age >= 18:
# 【组装】如果成年,就造一个新的字典放进去
new_dict = {
"name": name,
"job": job
}
result.append(new_dict)
print(result)关键点 :注意看
name, age, job = row这一行。这就是我们在上一题学的解包 。在循环里直接解包,比写row[0],row[1]要清晰得多,因为变量名直接告诉了你数据的含义。
第二步:变身"推导式"(语法映射)
现在,我们把上面的代码"折叠"成一行。Python 的推导式语法结构是固定的:
让我们一一对应:
-
最终想要的数据 (放在最前面):
我们要的是字典,所以写
{"name": name, "job": job}。 -
for 循环 + 解包 (放在中间):
把
for row in db_rows和name, age, job = row合并,写成for name, age, job in db_rows。 -
if 过滤条件 (放在最后面):
直接把
if age >= 18搬过来。
合体后就是:
result = [
{"name": name, "job": job} # <--- 1. 我要什么样的数据?(字典)
for name, age, job in db_rows # <--- 2. 数据从哪来?怎么拆分?(遍历+解包)
if age >= 18 # <--- 3. 什么样的数据才保留?(过滤)
]第三步:图解执行流程
为了让你彻底明白,我们模拟一下计算机的执行过程:
| 步骤 | 原始数据 (row) | 解包后的变量 | 判断 age >= 18? |
结果 |
|---|---|---|---|---|
| 1 | ("Alice", 22, "Engineer") |
name="Alice", age=22... |
✅ 是 (22 >= 18) | 保留 -> 生成字典 {'name': 'Alice', ...} |
| 2 | ("Bob", 17, "Student") |
name="Bob", age=17... |
❌ 否 (17 < 18) | 丢弃 (不执行任何操作) |
| 3 | ("Charlie", 30, "Manager") |
name="Charlie", age=30... |
✅ 是 (30 >= 18) | 保留 -> 生成字典 {'name': 'Charlie', ...} |
| 4 | ("David", 16, "Student") |
name="David", age=16... |
❌ 否 (16 < 18) | 丢弃 |
最终 result 列表里只剩下 Alice 和 Charlie 的字典。
总结建议
作为初学者,如果你觉得推导式看着晕,完全可以先写传统的 for 循环。
-
传统写法:逻辑清晰,适合复杂逻辑,不容易出错。
-
推导式:适合简单的"转换 + 过滤",写出来显得很专业(Pythonic)。
你可以试着把题目 2 的代码改成传统的 for 循环跑一遍,理解了原理后,再尝试把它们缩写成一行。加油!
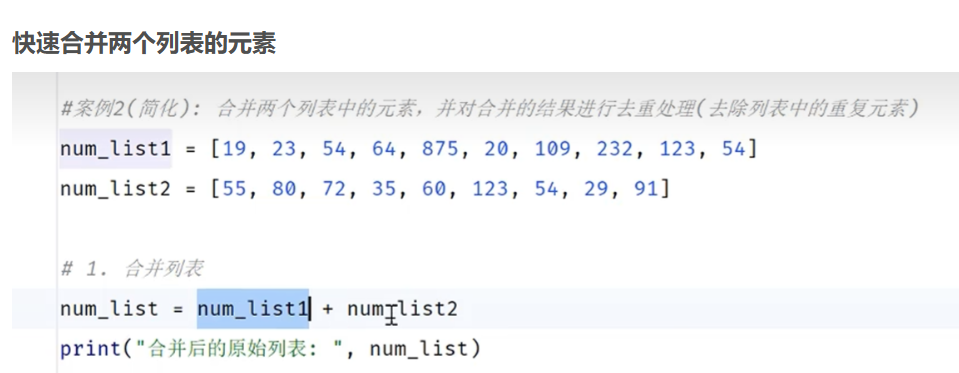
快速合并两个集合
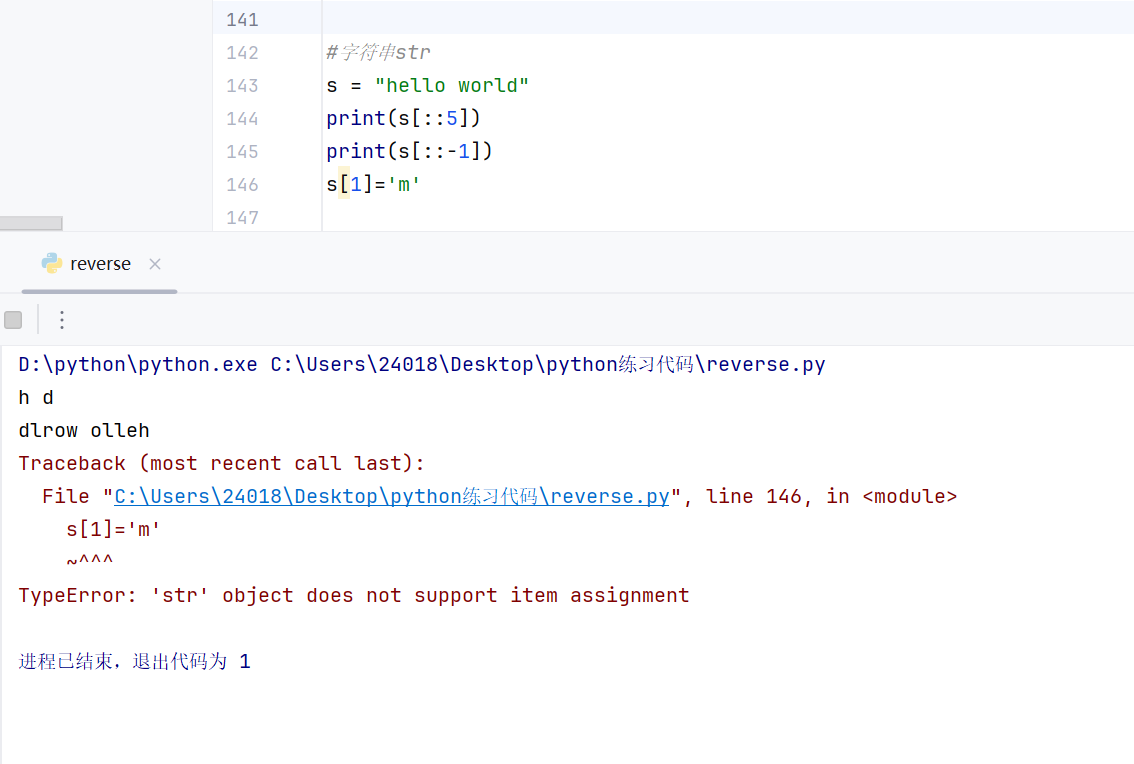
字符串str
切片-字符串,列表,元组都可以切片
字符串也支持反向索引
字符串无法修改
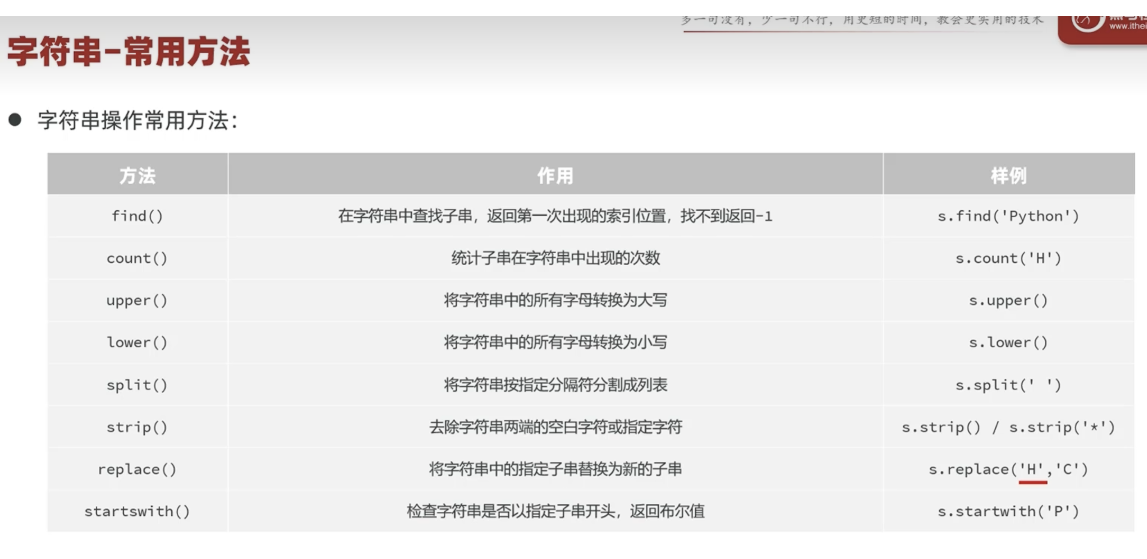
字符串常用方法
---------------------------------------------------------待复习
元组tuple
元组看起来像不能修改的列表
用()创建元组
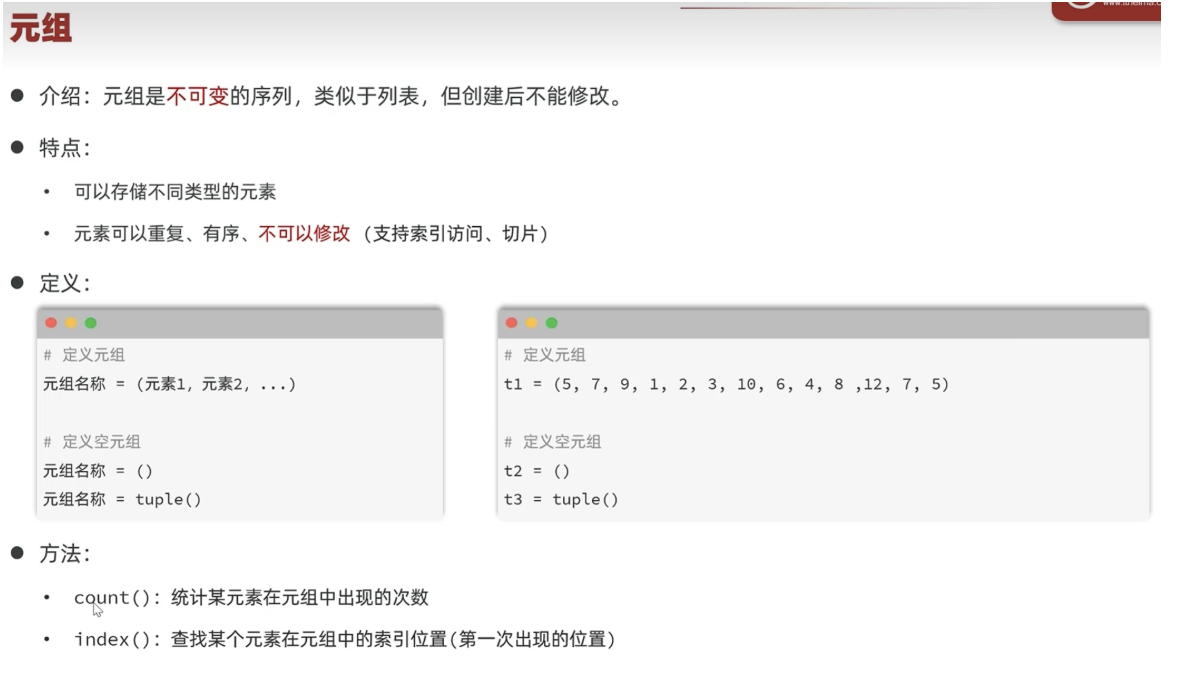
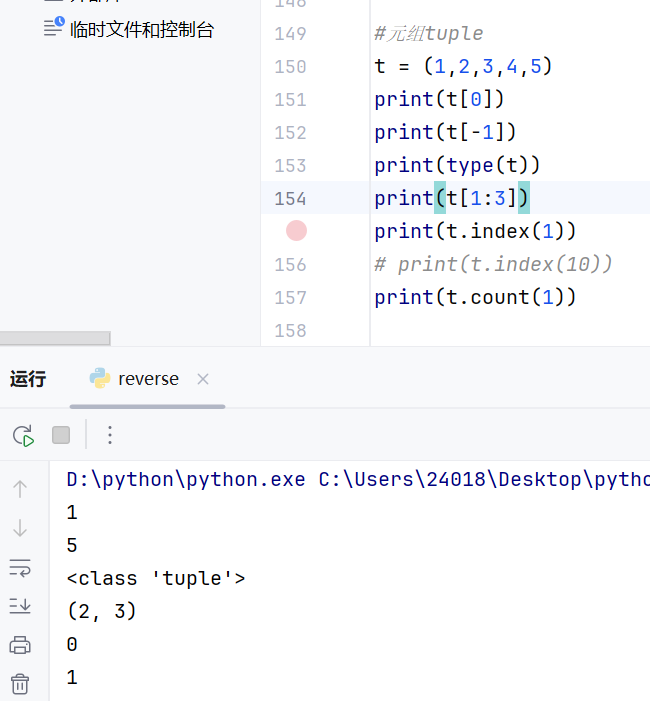
不能修改-->方法就没有增删改,只剩下查
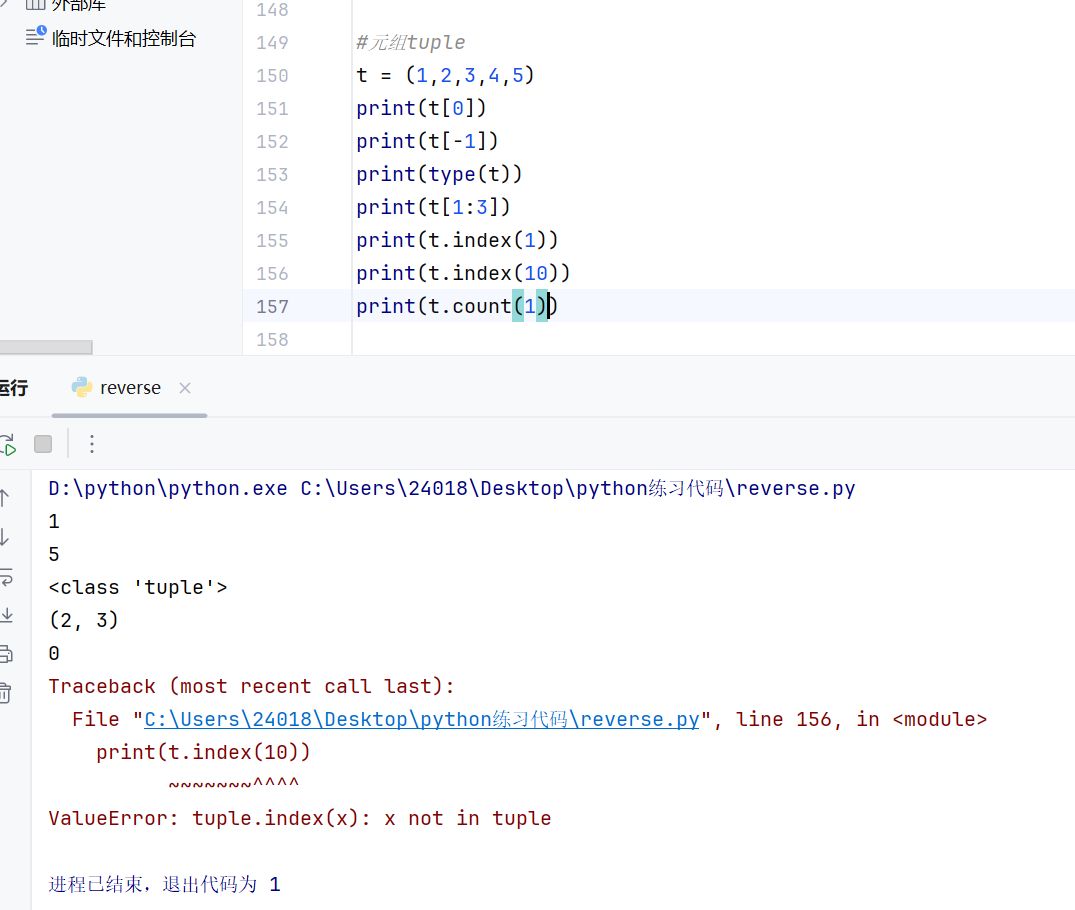
在查找某个元素在元组内的下标的时候,如果该元素不存在于元组中会报错
创建单元组和空元组
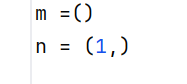
集合set
set集合是list列表,元组,set集合,字典dict中唯一一个无序的
集合和上面两个元组和列表最大的差别就是:集合set是不允许重复的,而且是无序的

创建空集合
字典和集合都是用{}包围的
{}是创建空字典
set()是创建空set集合
set集合中的常用方法

方法的练习
题目一

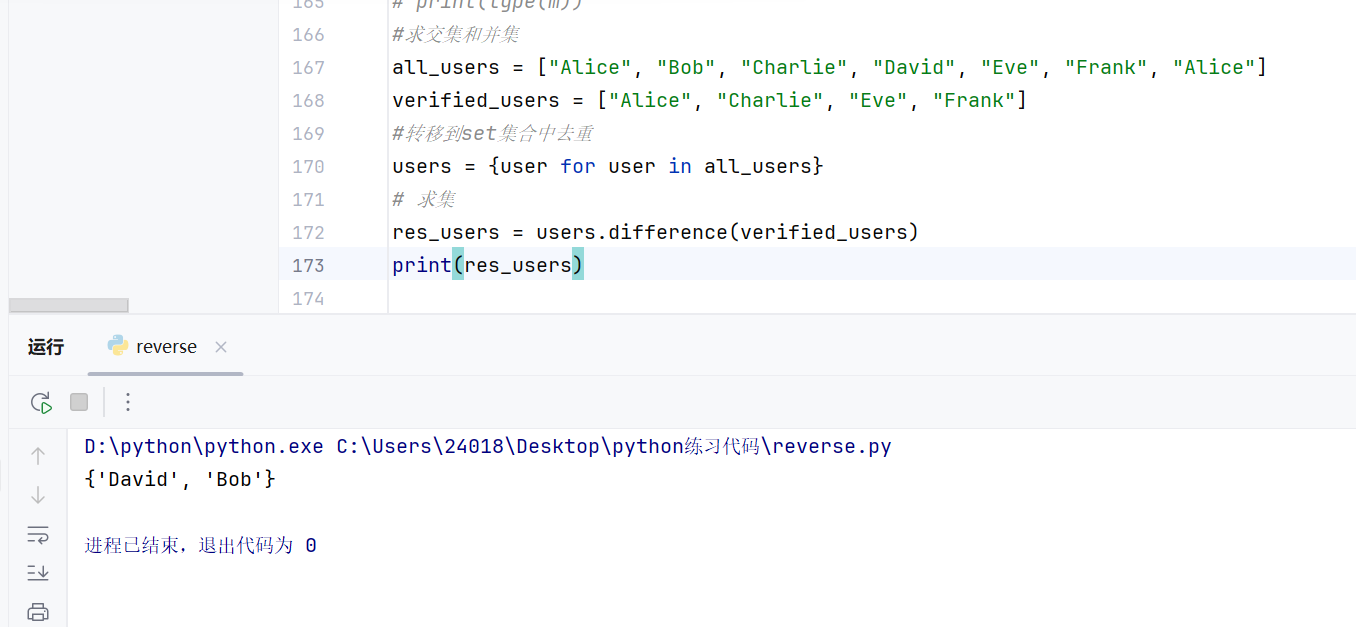
优化为
python
# 1. 原始数据
all_users = ["Alice", "Bob", "Charlie", "David", "Eve", "Frank", "Alice"]
verified_users = ["Alice", "Charlie", "Eve", "Frank"]
# 2. 核心逻辑优化
# set() 函数直接转换列表并去重,比推导式 {x for x in ...} 更快且更简洁
users_set = set(all_users)
verified_set = set(verified_users)
# 使用减号 "-" 运算符代替 .difference(),语义更像数学公式:全集 - 子集
unverified_users = users_set - verified_set
# 3. 结果处理
# 因为 set 是无序的,转回 list 后排序,保证输出稳定(按字母顺序)
result_list = sorted(list(unverified_users))
print(f"未认证用户: {result_list}")优化点:
set()可以直接将列表转换为set集合
题目二
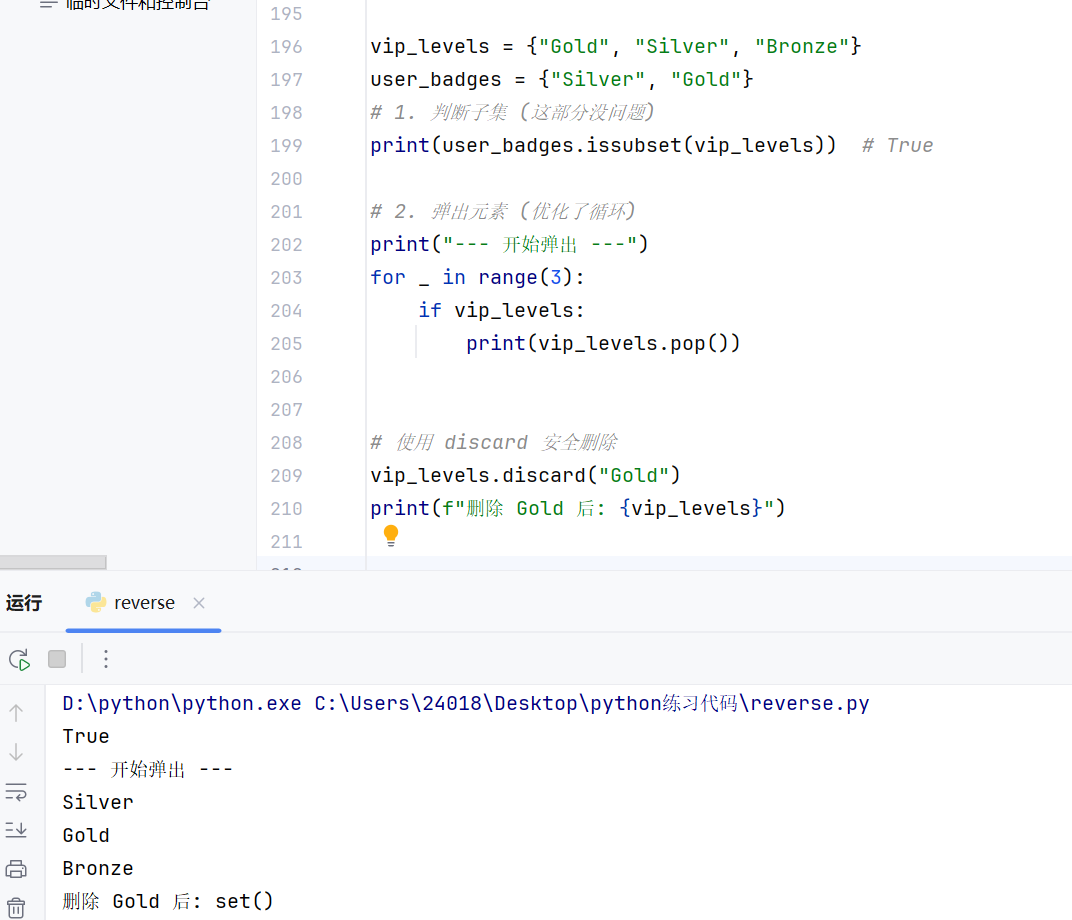
知识点:remove删除元素的时候,如果删除的元素不存在则会报错,remove的返回值为None(不管有没有成功删除元素)
discard删除元素的时候,如果删除的元素存在则删除,如果不存在则什么都不做
字典dict
创建字典的方式:
{ } 或者 dict( )
字典的存储格式是key---value这样的存储格式
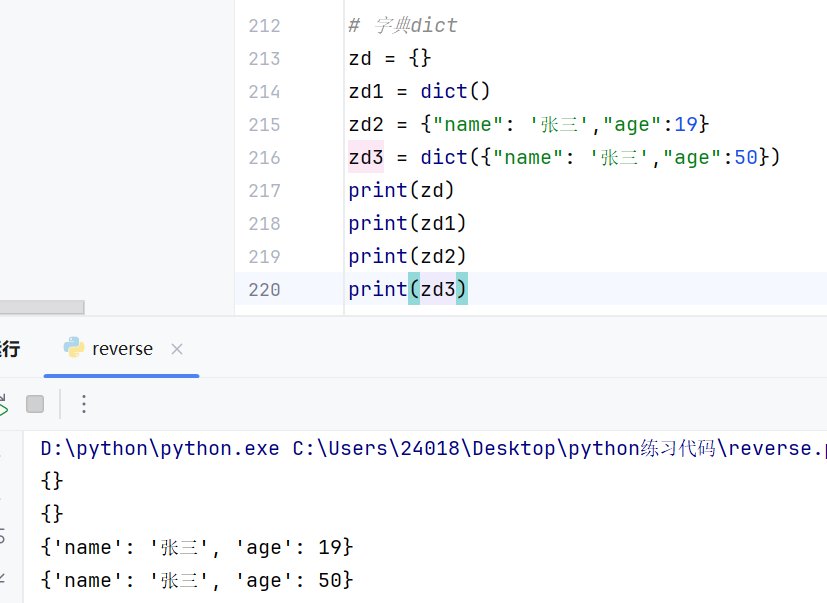
name和age是两个不同的key,之间没有关联
字典是有序不重复的
如果重新加入相同key的,后加入的value会覆盖前面的
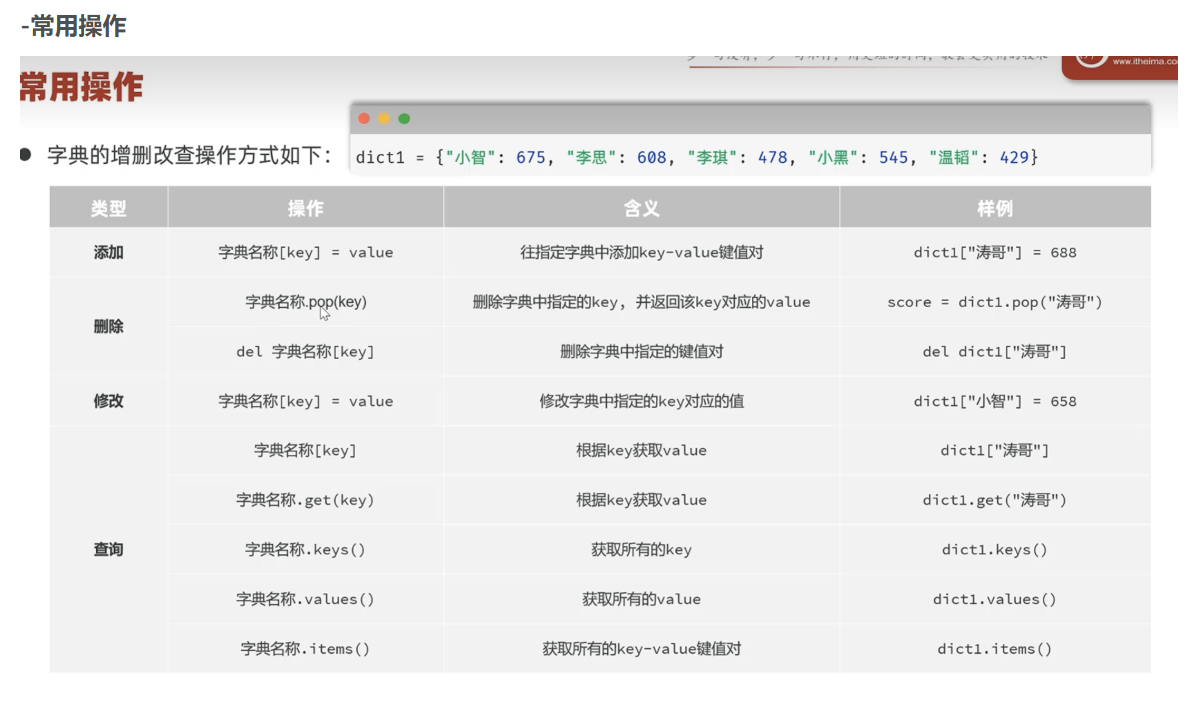
增和改是同一个命令:存在则修改,不存在则加入
删除:因为字典是无序的,所以只能通过key来删除键值对
共有两个方法pop和del
查询:可以单个查询或者批量查询
get通过key获取value,keys获取所有的key,values获取所有的value,items获取所有的键值对
几个需要注意的细节
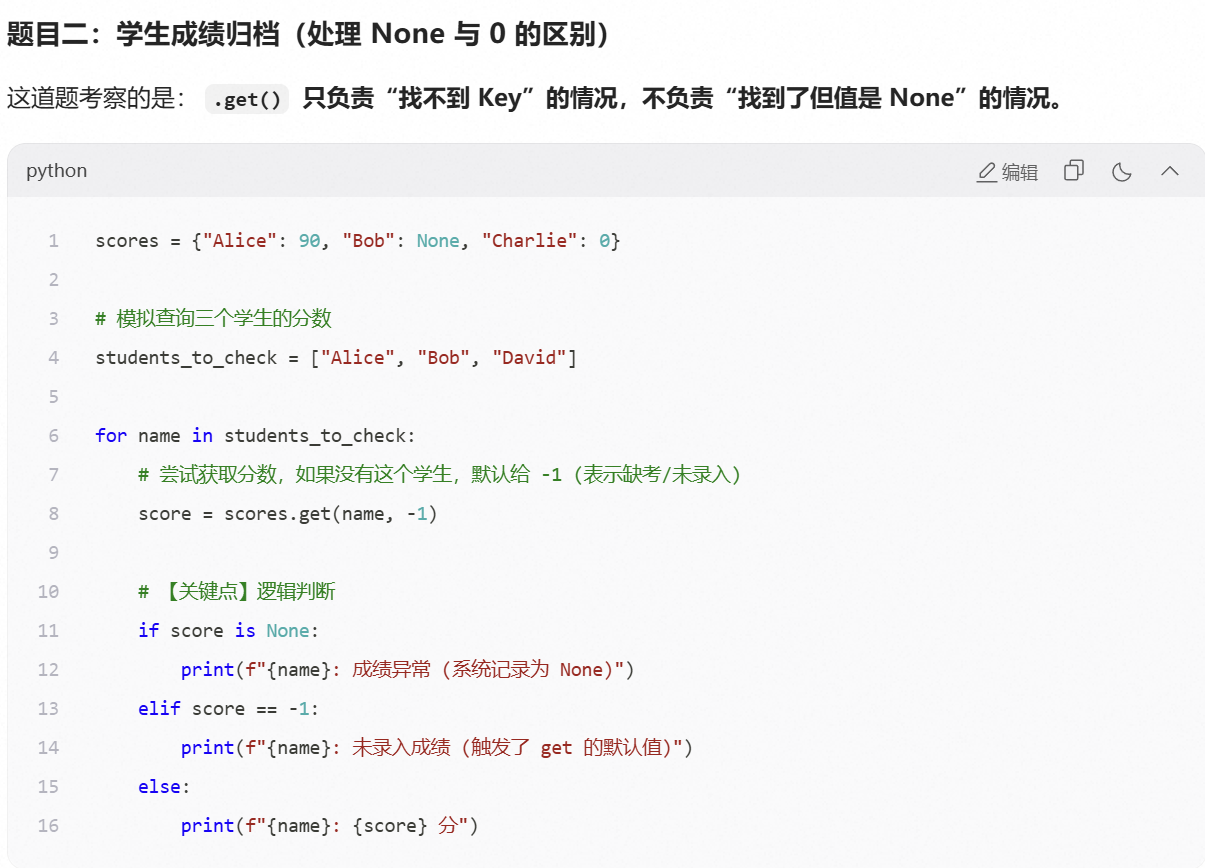

get方法可以传入两个参数:包括key和一个默认值,这个默认值只有在key完全不存在的时候才会起效果,返回默认值,如果key存在,但是值为None,也会返会None
数据容器总结对比
函数
定义一个函数:可以不加返回值和参数列表
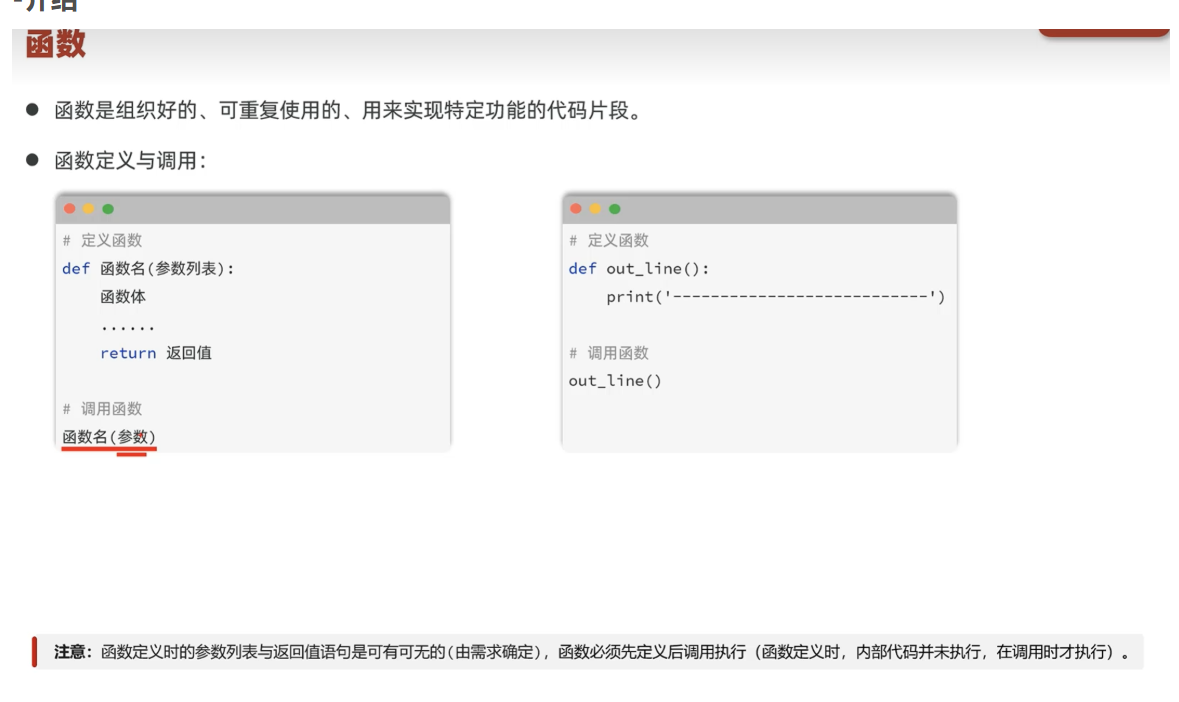
函数可以有多个返回值

变量作用域:
变量:
包括局部变量和全局变量,局部变量是函数内的变量,全局变量是函数外的变量,
global关键字
global关键字连接局部和整体,
在局部(函数内部)可以设置变量,在全局(函数外)也可以设置变量,但是这两个变量没有关系,只是长得一样,
调用global关键字可以修改全局变量,说明自己要修改的是全局变量,而不是在函数内部创建的局部变量
在python中可以读取全局变量,如果想要修改全局变量则需要global关键字
在 Python 中,函数内部读取全局变量的规则可以总结为一句口诀:"只读不用声明,修改必须声明。"
- 只读全局变量(不需要
global,也不需要传参)
如果函数内部仅仅是**读取(查看)**全局变量的值,Python 会自动向外层寻找这个变量。
global_score = 100 # 全局变量
def print_score():
# 直接读取,不需要 global,也不需要传参
print(global_score)
print_score() # 输出: 100底层原理 :当 Python 在函数内部遇到一个变量时,它会按照 LEGB 规则去查找:
-
Local(局部变量):函数内部有没有?
-
Enclosing(嵌套作用域):外层函数有没有?
-
Global(全局变量):模块级别有没有?
-
Built-in(内置):Python 内置的有没有?
因为 print_score 函数内部没有定义 global_score,Python 就会自动去全局作用域(G)找到它并使用。
- 为什么"修改"就必须用
global?
这就回到了你上一轮提到的核心逻辑:Python 对"赋值操作"非常敏感。
当你在函数内部写下 变量名 = 值 时,Python 解释器在编译阶段就会默认:"你要在局部创建一个新的同名变量"。
global_score = 100
def update_score():
# 报错!UnboundLocalError: local variable 'global_score' referenced before assignment
# 原因:Python 认为你要创建局部变量,但你在赋值前就读取了它
print(global_score)
global_score = 200 为了打破这个默认规则,你必须显式地告诉 Python:"不要创建局部变量,我要直接操作全局变量!"
def update_score():
global global_score # 声明:我要修改全局变量
global_score = 200 # 此时才是真正的修改- 一个极易踩坑的进阶场景:读取可变对象
虽然"只读"不需要 global,但如果全局变量是一个可变对象 (比如列表 list 或字典 dict),情况会变得非常微妙。
你可以直接修改它内部的内容(不需要 global):
global_list = [1, 2, 3]
def add_item():
# 不需要 global!因为 append 是原地修改,没有发生"重新赋值"
global_list.append(4)
add_item()
print(global_list) # 输出: [1, 2, 3, 4]但你不能直接替换整个变量(需要 global):
global_list = [1, 2, 3]
def replace_list():
# 报错!因为 = 号触发了重新赋值,Python 以为你要创建局部变量
global_list = [9, 9, 9]
def replace_list_safe():
global global_list # 必须加 global
global_list = [9, 9, 9]总结
-
只读 :直接写变量名,Python 会自动去全局找,不需要传参,也不需要
global。 -
修改(赋值
=) :必须加global,否则会在局部创建新变量。 -
修改内容(如
list.append()) :不需要global,因为对象本身没变,只是内容变了。
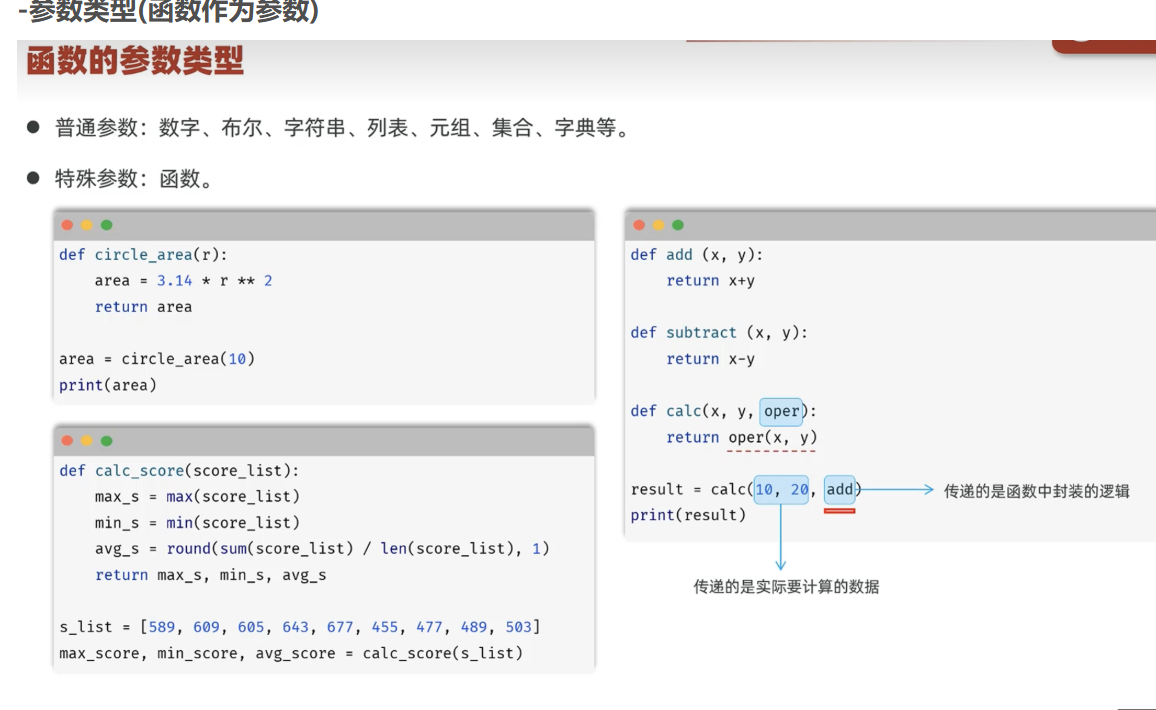
传递参数的方式:包括顺序传参和关键字传参
不定长接收参数:
包括**args和**kwargs
**args接收的是顺序传参的参数,并封装为元组
**kwargs接收的是键值对传参的参数,并封装为字典
参数的类型
匿名函数:lambda表达式
匿名参数:没有函数名的参数,只保留参数列表和方法体
用法:一般来说只作为高级函数的参数使用
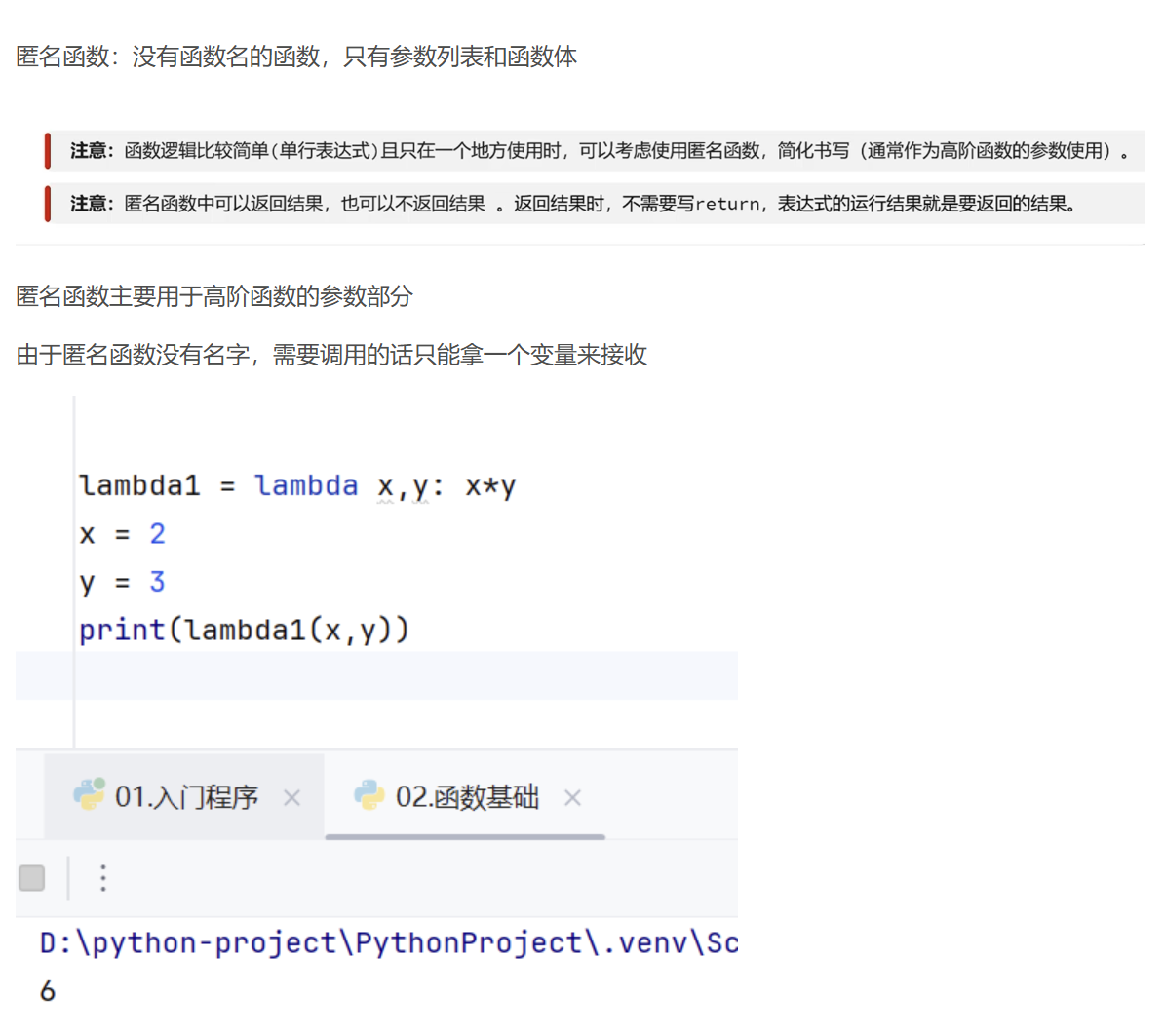
匿名函数的用法:因为匿名函数没有函数名,所以只能用变量接受来调用
练习
考察参数校验和异常处理

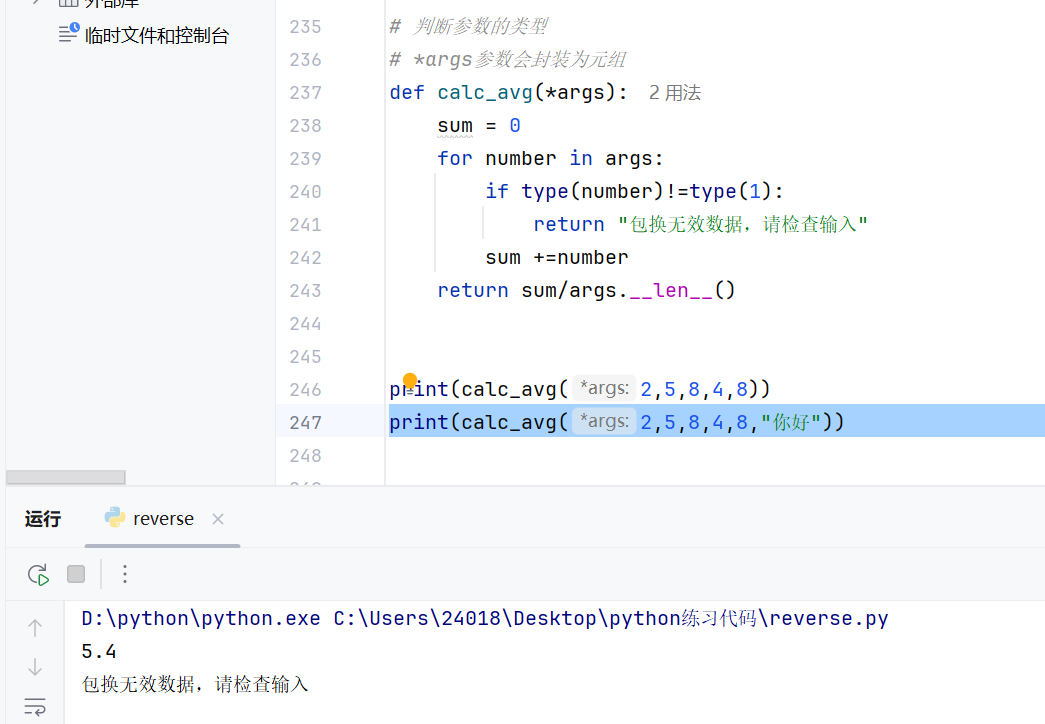
python
def calc_avg(*args):
# 1. 防御性编程:处理没有参数的情况
if not args:
return 0
total = 0 # 避免使用 sum 作为变量名
for number in args:
# 2. 更严谨的类型检查:同时兼容 int 和 float
if not isinstance(number, (int, float)):
return "包含无效数据,请检查输入"
total += number
# 3. 使用内置 len() 函数,比 __len__() 更符合 Python 风格
return total / len(args)
# --- 测试验证 ---
print(calc_avg(90, 80, 70)) # 输出: 80.0
print(calc_avg(90, "abc", 70)) # 输出: 包含无效数据,请检查输入
print(calc_avg()) # 输出: 0 (修复了除以零的错误)
print(calc_avg(90, 98.5)) # 输出: 94.25 (支持了小数)