这是苍何的第 556 篇原创!
大家好,我是苍何。
前几天夜深人静的时候,在油管上又刷到我喜欢的博主更新了视频。
声音太好听了,当时有点儿激动,没忍住,花了些时间,把娜娜住进了我的 WeSight。
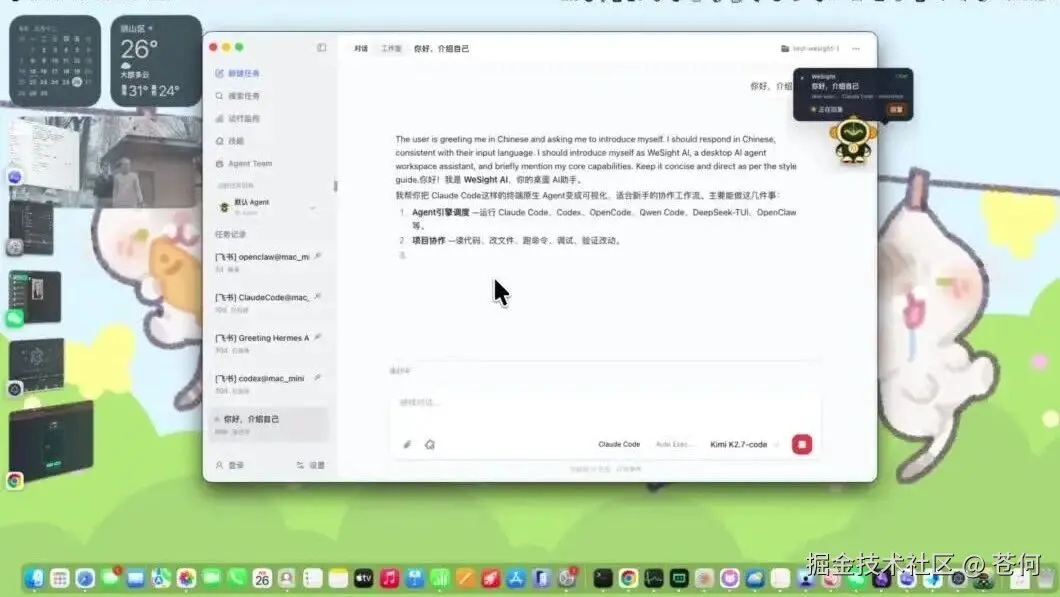
现在,我只要在 WeSight 中开启任务,WeSight 的桌宠就能播放娜娜的声音,实时播报任务完成情况。实时告诉我她在做什么,发送任务后,我再也不用盯着了。
比如简单任务,娜娜会说她开始想一下,然后查看结果,最后还带着开心情绪的语气告诉我任务完成啦:
再比如在 WeSight 中调 Claude Code 来 Coding,更有意思,哈哈哈。
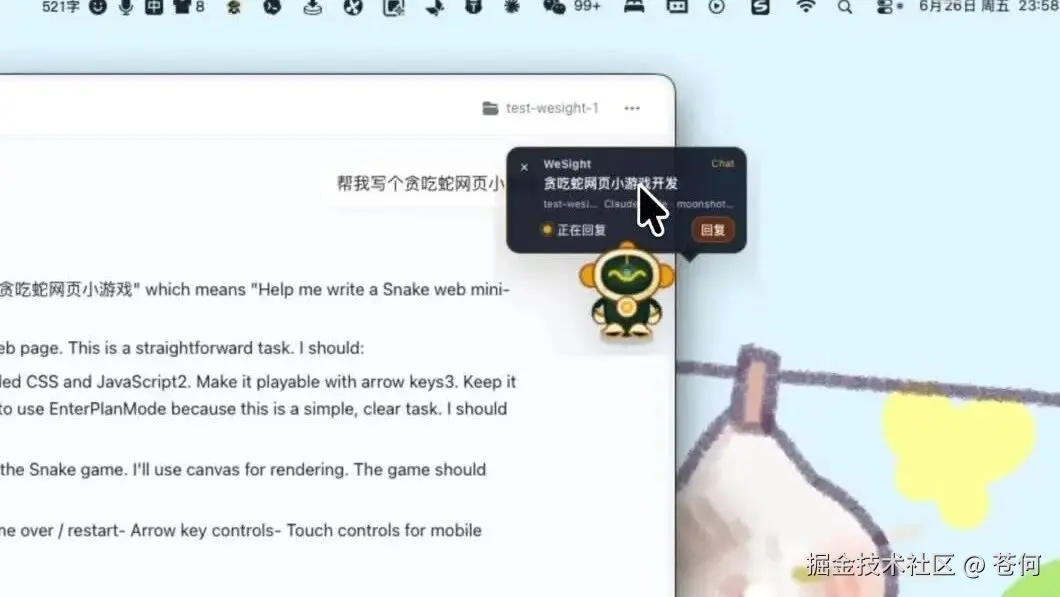
这个感觉还挺棒的,特别是夜深人静 vibe coding,感觉就没那么孤独了,而且也能有暖心提醒,可以专心去做其他事情了。
最为🐂🍺 plus 的是,你甚至可以自定义本地 TTS 模型,实现 token 自由的来享受。
本地 TTS 模型我用的 Confucius4-TTS。只有 1.3B 大小,无需参考文本可以无约束声音克隆,很适合本地部署。
现在,你只需要在 WeSight 中开启桌面宠物(在设置-通用-桌面宠物)。
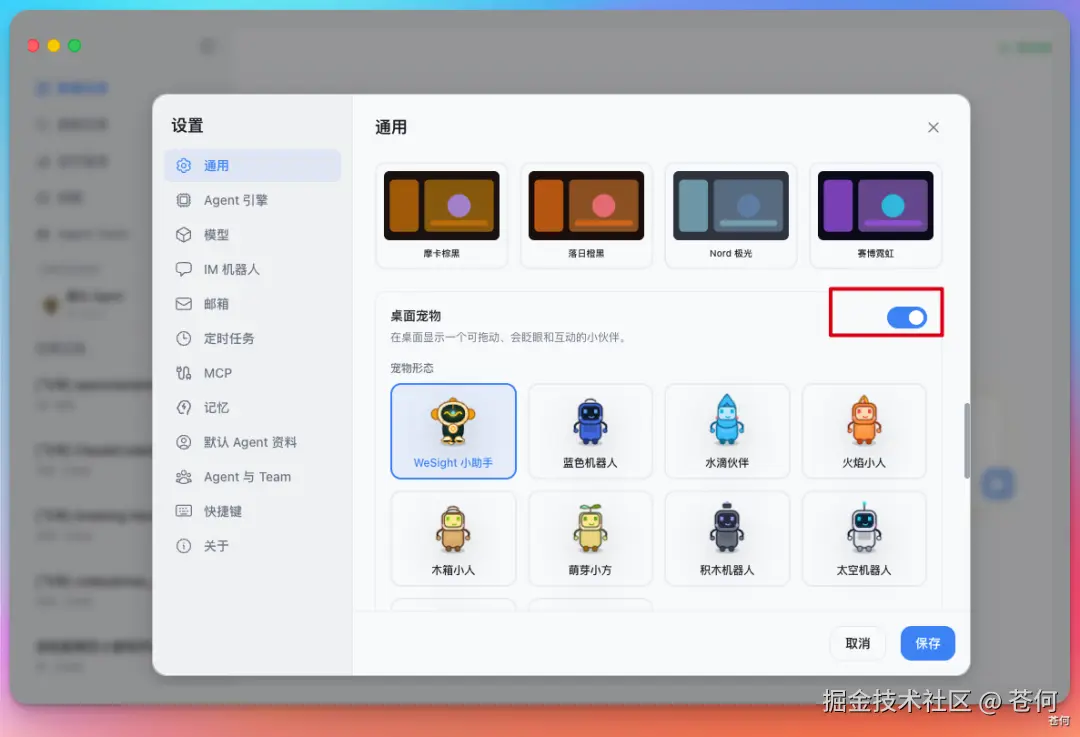
然后开启自定义音色,为每一个宠物自定义你喜欢的音色。
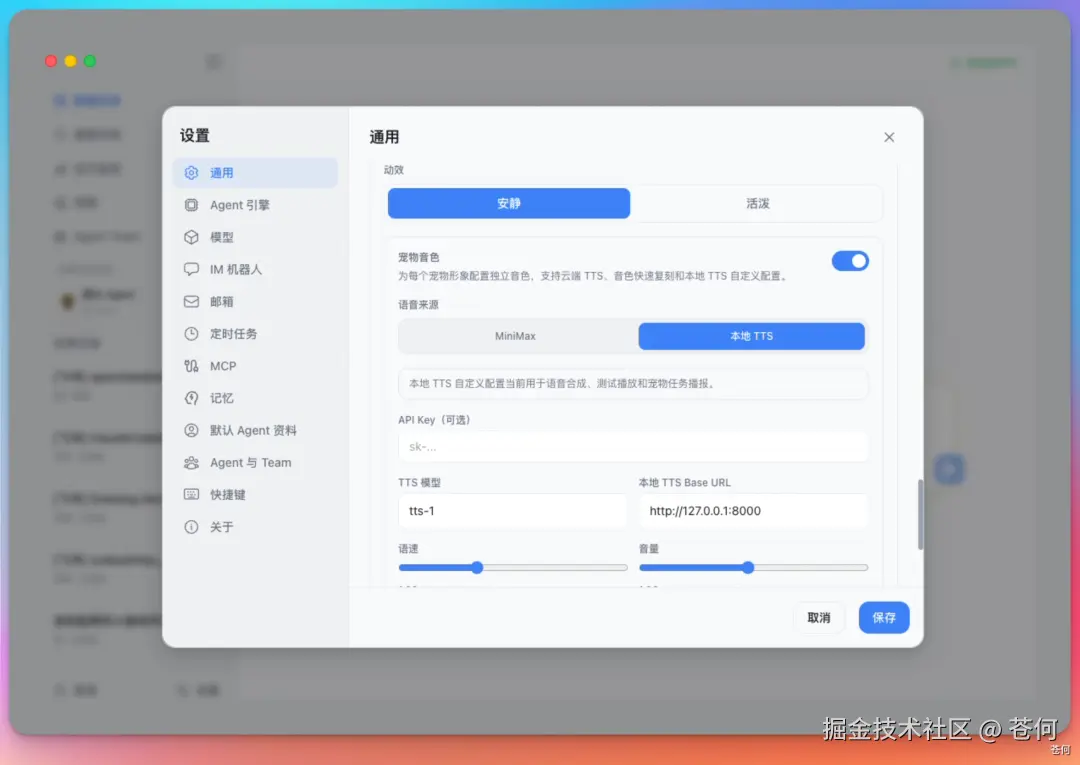
目前支持 2 种模式,你可以配置 MiniMax 的 API 也可以选择共用 WeSight 中 MiniMax 的 API key,也可以自定义 API,甚至可以选择本地的 TTS 配置。
还可以上传一个参考音频,几秒钟快速复刻一个还原度很高的音色。
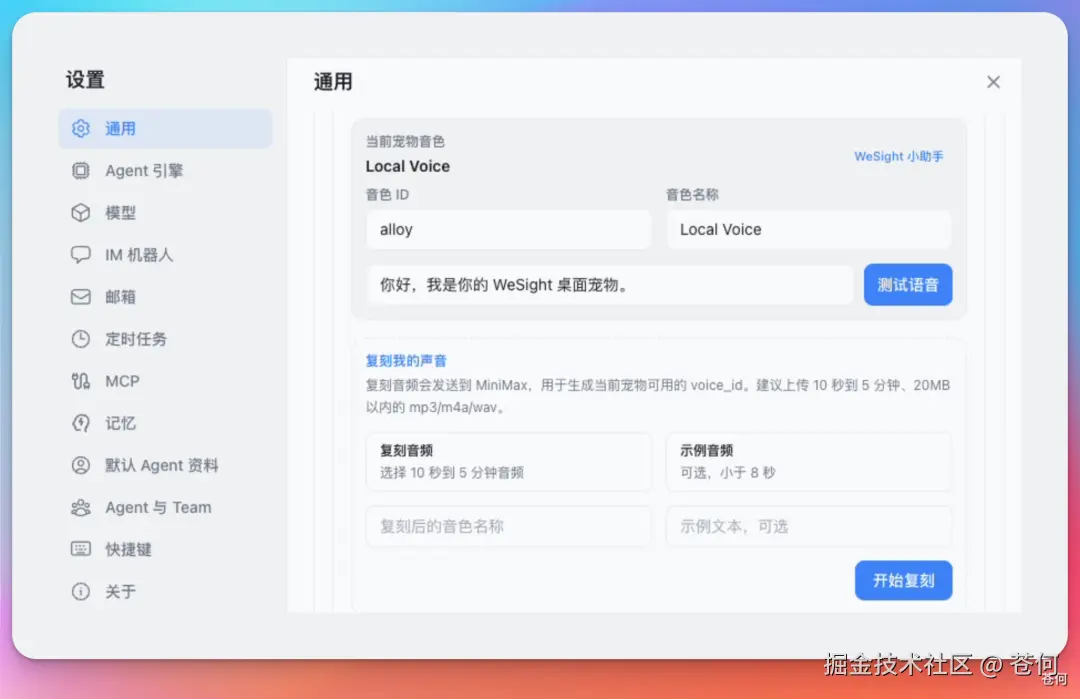
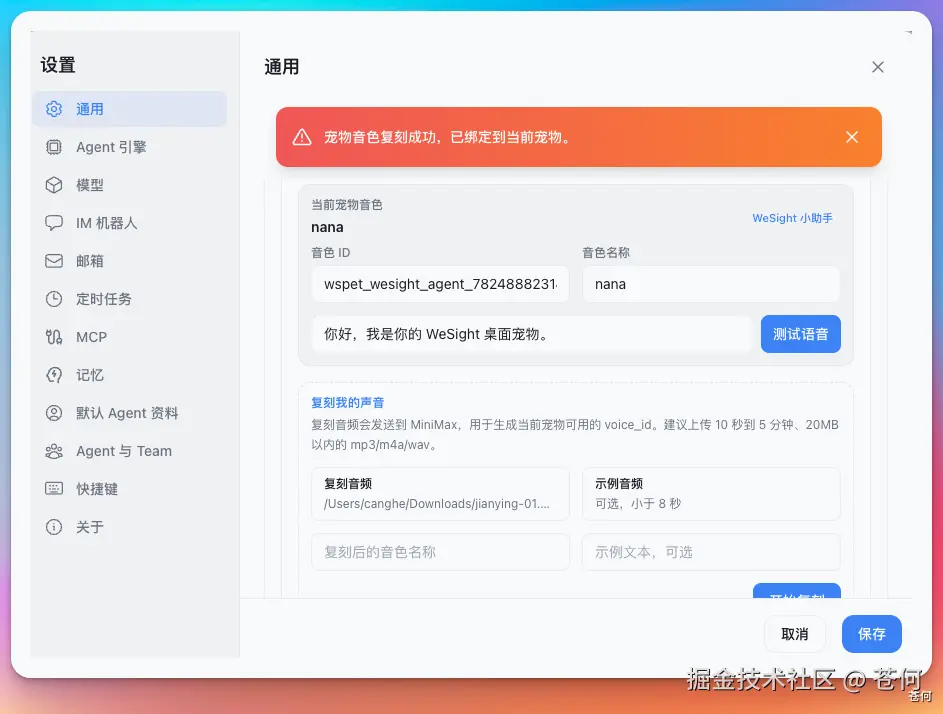
比如我上传了一段娜娜口播的音频,点击「开始复刻」,就能在 WeSight 的桌宠中使用该音色。也就是文章一开始的那 2 个视频。
说实话,一开始选择本地部署 TTS,除了想节省 token,也是想着好好利用一些公司里的 dgx spark。
也做了一番调研,太大参数的本地肯定搞不了,太小的,不少效果又不行,在确认技术选型之前,我还是对 Confucius 4-TTS 对做很多的测试验证。你看:

这个视频大家都有印象吧,我想复刻小女孩的声音

我本地 mac 通过 Remotion 远程连接到 dgx 主机,dgx 本地部署了 Confucius 4-TTS 开源模型,负责将声音进行复刻。
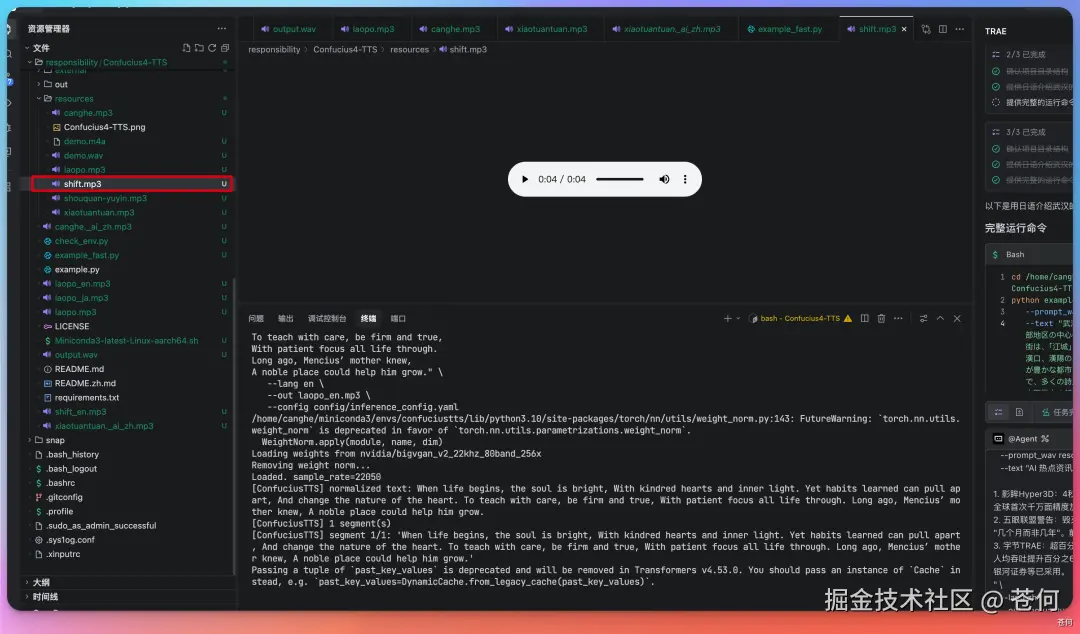
然后给到我复刻后的音频:
我闲的无聊,把这个配音,放到原视频中去,挺有意思,哈哈哈。

我老婆看我瞎倒腾啥,也想来玩下,她先录了个音,这是原始音频:
好,我现在用她的音色, 经过我本地的 Confucius 4-TTS 模型复刻,来一口地道的英语给小橘子讲讲三字经吧。
还不过瘾,我直接让她来个日语介绍下武汉。
感觉还挺相似的你别说,语调和情绪都还挺到位,不大像是本地模型能跑出来的。
Confucius 4-TTS 一共支持 14 种语言,中文、英文、日语、韩语、德语、法语、西班牙语、印尼语、意大利语、泰语、葡萄牙语、俄语、马来语、越南语,说后面还会持续增加。

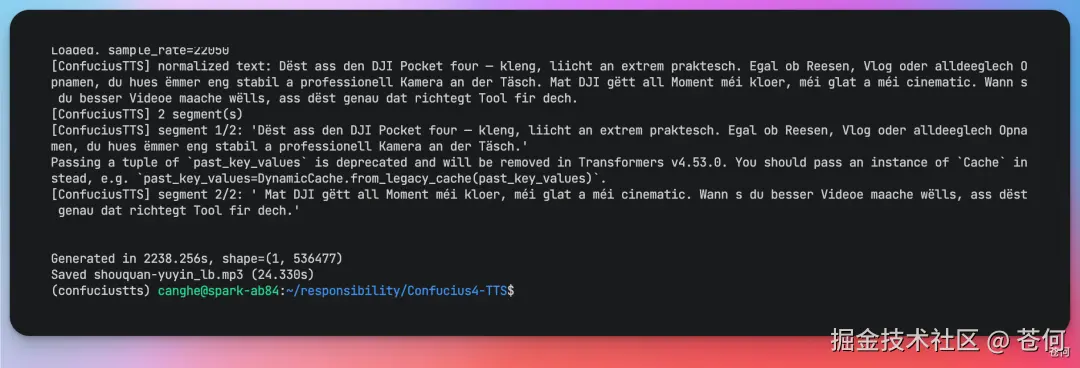
这个是我喜欢的博主娜娜的原声,我试了把她复刻为不同的语言。
先来一个卢森堡语的带货口播:
再来一个韩国口音的带货口播:
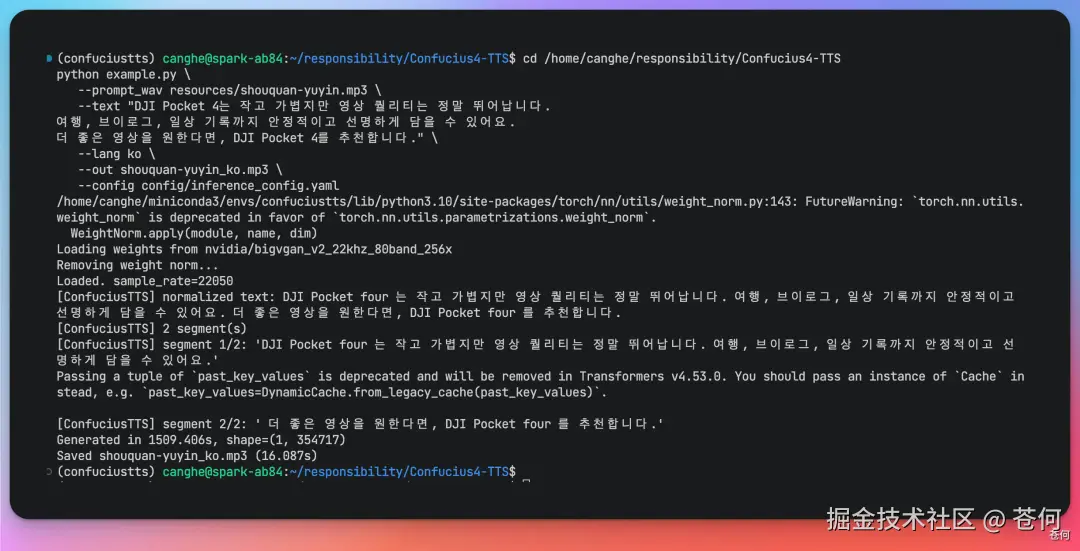
是不是很 nice,我感觉这个对出海跨境电商和内容创作真的有用,不用自己再找人录不同语种的口播了。
然后我还把我自己的声音克隆了,复刻后,我直接让自己来给大家播放个 AI 早报:
平时高德导航我都是开的小团团语音包,我还蛮想复刻一个小团团音色的,于是我随便录了一段音频,不过车里声音有些吵。
可能是杂音噪音问题,复刻出来的效果没达到我的要求。
大家在使用 Confucius 4-TTS 模型本地复刻的时候,一定要录制干净没有杂音的纯声,这样出来的效果会好一些。
本地部署最大的好处就是省 Token,其实部署起来也不麻烦,甚至,你在自己的 Mac 都能跑的起来。
首先,你需要把开源代码拉到本地来。
bash
●●●git clone https://github.com/netease-youdao/Confucius4-TTS.gitcd Confucius4-TTS然后构建 conda 环境,如果你已经有了就可以不用再新构建了,只需要激活启动下。
ini
●●●conda create -n confuciustts python=3.10 -yconda activate confuciusttsconda 环境简单理解就是给这个项目单独开一个「房间」,装它自己需要的依赖,不会跟你电脑上其他项目打架。
接下来就可以安装依赖:
●●●pip install -r requirements.txt这里时间会比较久,按照要求来安装依赖就好了。
搞定后,你可以执行以下代码测试,注意修改自己的音频参考文件:
css
●●●python example.py \ --prompt_wav path/to/reference.wav \ --text "Hello, this is a test of zero-shot voice cloning." \ --lang en \ --out output.wav \ --config config/inference_config.yaml当然也可以不在 dgx 上直接测试,可以通过 Tailscale 在 mac 上远程执行测试。
最后用 fastAPI,将模型服务封装出去给到 WeSight 使用,就算是完成了。
我看了下 Confucius 4-TTS 的技术架构,是「语音编码器 + LLM」架构,通过两阶段 Text 2 Semantic(文本→语义 Token)+ Semantic 2 Acoustic(语义 Token→梅尔频谱图)。
然后使用 BigVGAN 声码器输出最终音频。
说实话,本地部署 TTS,可以不用考虑成本的使用,这一点还挺舒服的。
而且 Confucius 4-TTS 只有 1.3 B,本地就能跑,Apache 2.0 协议,商用也没问题,这对个人开发者和内容创作者来说,真的太友好了。
如果你也想让自己的 Agent 「开口说话」,强烈建议去试试。当然也可以使用 WeSight 来体验哦。
稍微留意了下 Confucius 4-TTS 居然又是有道开源的,还记得WeSight其实是站在有道开源的 LobsterAI 做的二开。
有道的 AI 现在现在越来越有一种「闷声干大事」的感觉了。不搞发布会刷存在感,就是一个接一个往外丢开源项目,TTS、Agent 框架、多模态,全都 Apache 2.0,拿来就能用。
好啦,觉得有用的话,点个赞吧,你们的支持是我持续折腾的最大动力。
你最想复刻谁的声音?评论区聊聊。