目录
[四、数据存储:CSV 与 MySQL 双通道保留](#四、数据存储:CSV 与 MySQL 双通道保留)
[七、可视化大屏:Pyecharts 与 ECharts 两套展示方式](#七、可视化大屏:Pyecharts 与 ECharts 两套展示方式)
有需要本项目的代码、文档、完整资源,或者需要部署调试的朋友,可以私信博主。
最近整理了一个网络图书数据分析与可视化项目,整体思路是把图书平台上分散的书目信息、评分信息、价格信息和简介文本统一采集下来,再经过清洗、入库、统计分析和可视化展示,最后形成一个可以登录访问、可以切换图表、可以查看大屏的完整系统。这个项目不是只做几张静态图,而是把数据采集、字段治理、分析逻辑、前端展示和后台服务串成了一条完整链路,比较适合作为 Python 数据分析、爬虫实战、Flask 项目开发和可视化大屏设计的综合案例。
一、项目背景:从海量图书信息里看见阅读市场
现在读者选择一本书,往往会同时参考书名、作者、出版社、评分、评价人数、价格、简介和平台口碑。信息看起来很多,但真正要判断一本书的市场热度、读者接受度和题材倾向,仅靠人工浏览很难形成系统认识。我最初做这个项目,就是希望把这些散落在网页上的图书信息变成可计算、可比较、可展示的数据资产。
图书数据有一个很有意思的特点:它既有结构化字段,比如评分、定价、出版年、页数、出版社;也有半结构化甚至非结构化内容,比如简介文本、标签分类、星级比例和用户关注度。把这些维度放在一起观察,就能看到很多单独看网页时不明显的规律。例如,高评分书籍是否集中在某些主题?热门作者是否一定拥有更高评分?价格和口碑有没有明显关系?近些年的出版数量和定价变化是否存在趋势?这些问题都需要通过批量数据来回答。
所以我把项目定位成"采集---清洗---分析---展示---系统集成"的完整流程。前半部分解决数据从哪里来、怎么拿得稳、怎么清得干净;后半部分解决数据如何被看见、如何被交互、如何被放进一个可访问的平台。
项目文件按照功能模块进行组织:采集脚本负责标签和详情页抓取,清洗脚本负责字段归约和异常字符处理,分析脚本负责分组聚合与图表生成,后台服务负责接口和页面路由,前端页面负责大屏布局和交互渲染。这样的拆分方便后续维护,也方便把项目拆成不同阶段讲解。对于学习者来说,可以先跑通单个 CSV 分析,再逐步接入数据库和 Flask;对于需要作品展示的朋友来说,则可以直接呈现完整系统效果。

图 1 图书标签页与详情页采集入口展示
二、数据采集:从标签页到详情页的批量抓取
数据入口选择图书标签页。程序先访问标签集合页面,解析大类和细分标签,再把标签转换为可遍历的链接。这样做的好处是样本覆盖面更完整,不会只局限在单一榜单或少量热门分类。每个标签下继续读取分页信息,并把最大采集页数控制在 50 页以内,既能保证数据规模,也能避免请求过于激进。
进入列表页后,脚本会逐页解析图书详情页链接,把它们汇总到待抓取池。真正的信息采集发生在详情页:书名、作者、出版社、出版年、页数、定价、评分、评价人数、五星到一星比例、封面链接、详情链接、简介文本等字段都会按页面位置和字段标签提取。遇到个别缺失字段时,不让程序中断,而是用空值占位并记录日志,方便后续检查。
在反爬和稳定性方面,我没有使用高频暴力请求,而是做了更接近人工访问的节奏控制。请求头、Cookies、来源页信息、随机休眠、失败重试和异常提醒都被放进采集逻辑里。若某个页面短时间返回空结果,程序会触发提醒并进入倒计时等待,人工完成必要验证后继续运行。这样的设计可以减少任务长时间空转,也能降低中途断掉导致数据丢失的风险。
图 2 爬虫运行日志、异常暂停与告警机制展示
三、数据整理:把网页字段变成可分析的数据表
采集下来的原始数据以多份 CSV 文件分散保存,不同标签对应不同批次。为了让后续分析更顺畅,我先选取字段完整的样本作为表头模板,再把其他文件按无表头方式读入并纵向合并,最后统一赋回列名。这样可以避免批次写入时出现表头错位,也方便后续检查字段是否齐全。
合并完成后,第一步是去掉全空行和完全重复行;第二步是保留真正有分析价值的字段,包括书名、作者、出版社、出版年、页数、定价、评分、评价人数、星级比例、详情链接和简介。很多网页字段在原始状态下并不适合直接计算,比如价格里可能混有货币符号、逗号和小数,页数字段可能包含"册"等不表示页码的内容,出版年也可能出现"2020-05""2020年""2020.1"等不同写法。
针对这些问题,预处理脚本采用正则表达式做字段抽取和标准化。定价只保留首个数值片段,页数过滤掉异常标记后提取数字,出版年按常见分隔符切分并限定在合理区间。文本字段则去掉首尾空白、换行、控制字符、零宽字符和部分特殊符号。尤其是写入 MySQL 时常见的编码报错,需要额外处理四字节字符和 Emoji,否则数据库入库很容易被单条异常数据卡住。

图 3 采集文件、原始数据与数据库表结构展示
图 4 数据合并、字段标准化与文本清洗代码展示
四、数据存储:CSV 与 MySQL 双通道保留
整理后的数据保留了两种存储方式。第一种是本地 CSV,方便快速打开、抽样检查和作为可视化脚本的轻量数据源;第二种是 MySQL 数据库,便于结构化查询、长期保存和后端系统调用。项目中通过 SQLAlchemy 完成数据读写,数据库字符集设置为 utf8mb4,以便更好地兼容中文、特殊符号和少量复杂文本。
双通道存储在实践中很有用。调试阶段,CSV 打开快、改动快、便于确认字段;系统阶段,数据库更适合支持多页面调用和后端接口。这样既保留了学习项目的灵活性,也让系统具备继续扩展的基础。后面如果想接入更多平台、增加更多分类或做推荐模块,也可以继续沿用这一套数据组织方式。
五、评分分析:看口碑集中区间,也看高分书的关键词
评分维度是最直观的一组分析。评分分布图显示,大多数书籍集中在 7 分到 9 分之间,8 分附近最密集,低于 6 分的样本相对较少。这说明平台上的图书评价整体偏正向,也说明读者在选择和评分时存在一定的筛选效应。评分直方图适合观察整体口碑区间,而评分与评价人数散点图则能进一步区分"高口碑小众作品"和"高人气稳定作品"。
我还把评分大于 7 分的图书简介提取出来做了词云。高频词里,"作品""故事""世界""小说""历史""文学""生活"等词比较突出,说明高分书籍往往与叙事质量、文化背景和生活经验密切相关。词云虽然不是深度文本模型,但作为第一层探索非常有价值,它能快速提示哪些主题在读者中更容易获得积极反馈。
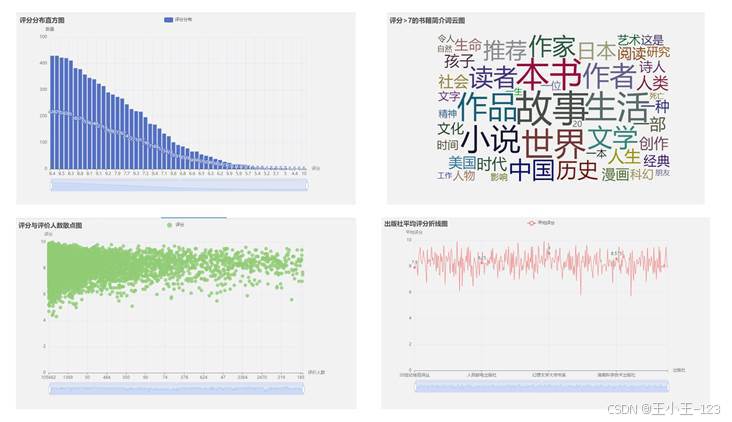
图 5 评分分布、高分词云、评分与评价人数关系展示
六、价格、评价人数与出版结构:从市场侧观察图书生态
价格分析主要关注图书定价的集中区间与异常点。直方图显示,图书价格大多集中在 20 元到 50 元之间,高于 100 元的数量明显减少,超过 200 元的样本更接近长尾。这类高价图书往往可能对应专业书、套装书、典藏版或特殊装帧版本。箱线图进一步说明,价格和评分并不是简单线性关系,高价并不天然代表更高评分。
评价人数维度更能体现传播效应。大多数书的评价人数集中在低区间,少量头部作品拥有极高评价人数,呈现典型长尾结构。这种分布说明图书市场既有头部集中效应,也保留大量小众作品。评价人数与页数的散点关系也很有启发:篇幅适中或较短的作品更容易获得广泛反馈,长篇或大部头作品虽然可能有更深内容价值,但传播面相对受阅读门槛影响。
出版社占比、作者评价人数和出版年份则更偏市场结构。出版社 Top10 可以观察样本中的高频出版主体,作者排行榜可以识别具有强传播力的个人品牌,出版年份分布可以看到近些年出版数量的活跃程度。把这些维度放在同一组图里,能从"内容口碑""市场价格""传播规模""出版主体"四个方向理解图书生态。
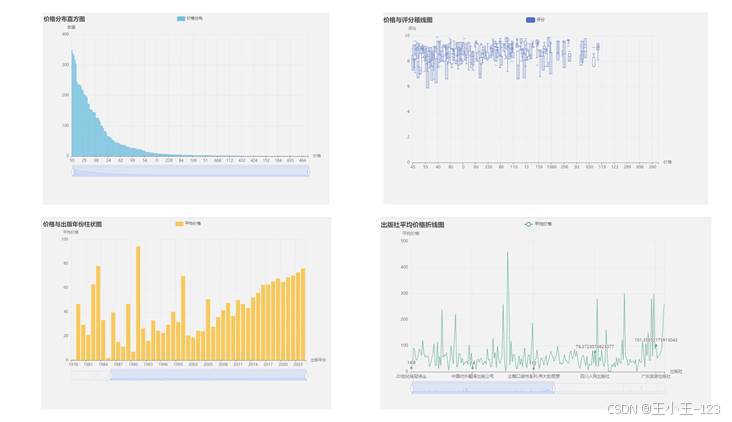
图 6 图书价格分布、价格与评分关系及出版年份价格变化展示
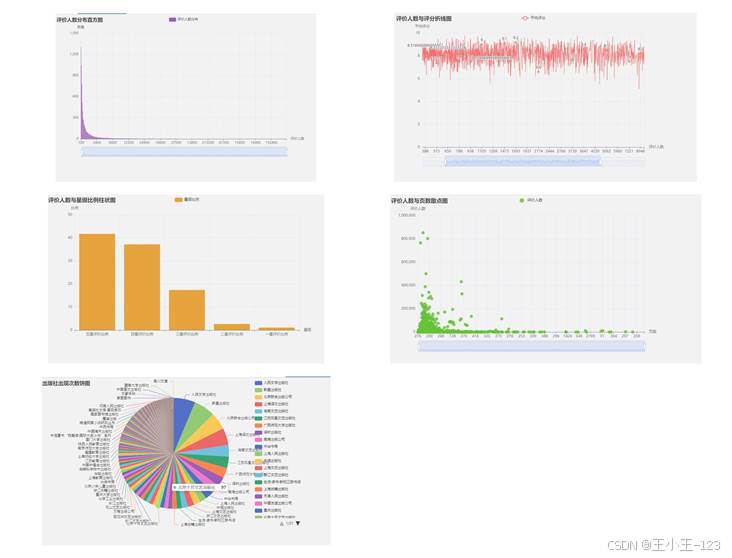
图 7 评价人数、星级比例、页数关系与出版社占比展示
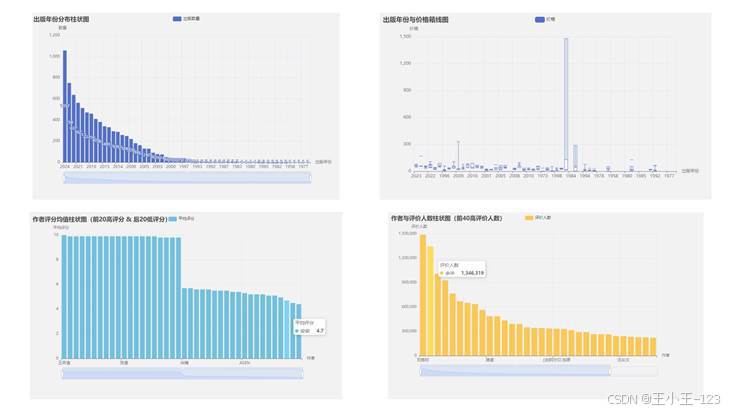
图 8 出版年份、作者评分与作者评价人数排名展示
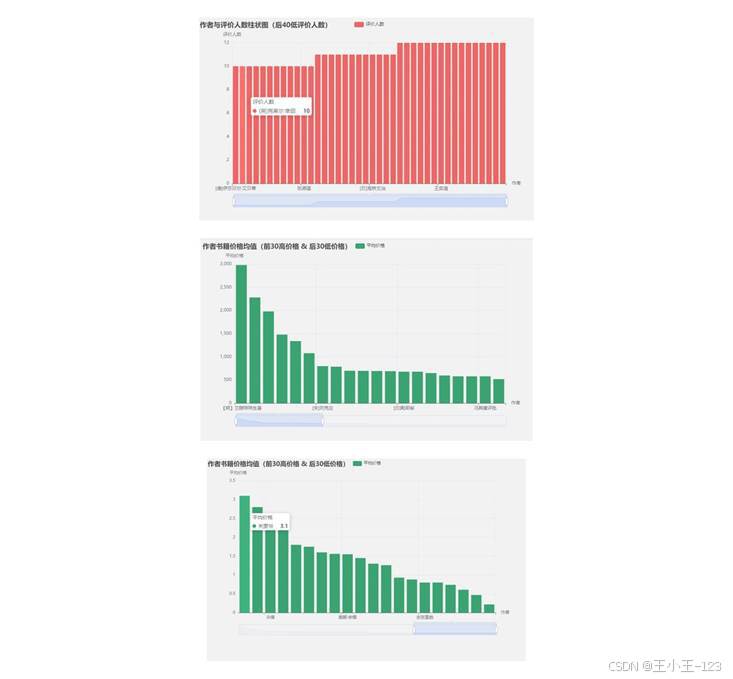
图 9 作者价格区间与不同作者定价差异展示
七、可视化大屏:Pyecharts 与 ECharts 两套展示方式
单张图适合解释一个问题,但项目展示和课堂演示需要把多个问题串起来。于是我用 Pyecharts 的 Page 组件把直方图、散点图、折线图、箱线图、饼图和词云组合成 HTML 大屏。用户打开一个页面,就能连续观察评分、价格、评价人数、出版社和作者等多个维度,不需要在许多单独文件之间反复切换。
在静态大屏之外,我又做了一版动态大屏。后端采用 Flask Blueprint 组织接口,统一以 /api 前缀返回数据;前端使用 ECharts 和词云插件进行渲染。评分分布、作者评价人数、价格分档、出版社占比、高分词云、出版年份与平均评分等模块被放在同一个暗色看板中。前端启用了 dataZoom、tooltip、resize 自适应和渐变配色,展示效果更接近真实的数据驾驶舱。
动态大屏的接口设计也做了性能考虑。评分与价格先在后端聚合,散点图在数据量较大时进行抽样,词云在后端完成分词和停用词处理,前端只负责图形编码和交互。这样可以避免浏览器一次性处理过多原始数据,页面加载更稳定,也方便后续迁移到服务器部署。
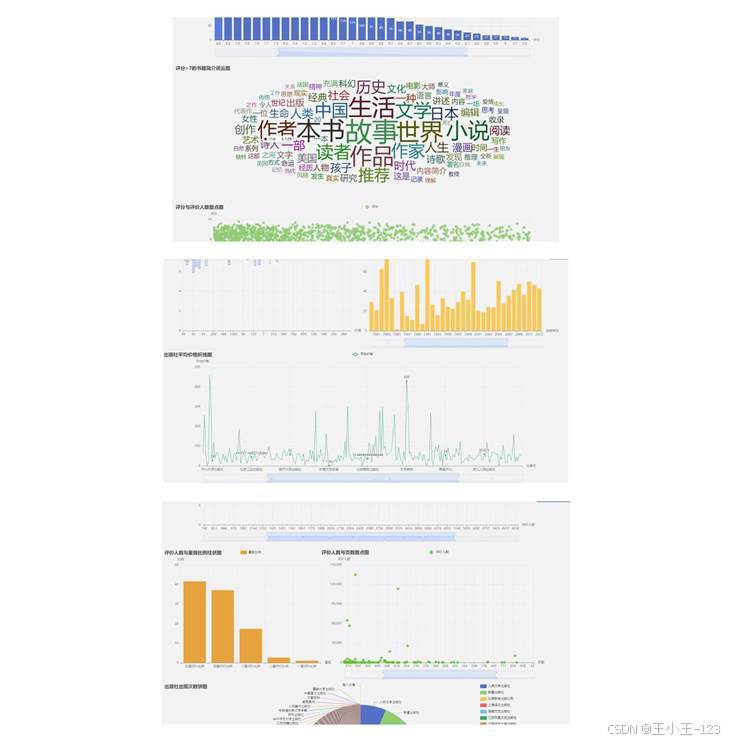
图 10 Pyecharts 多图页面组合与交互式图表展示
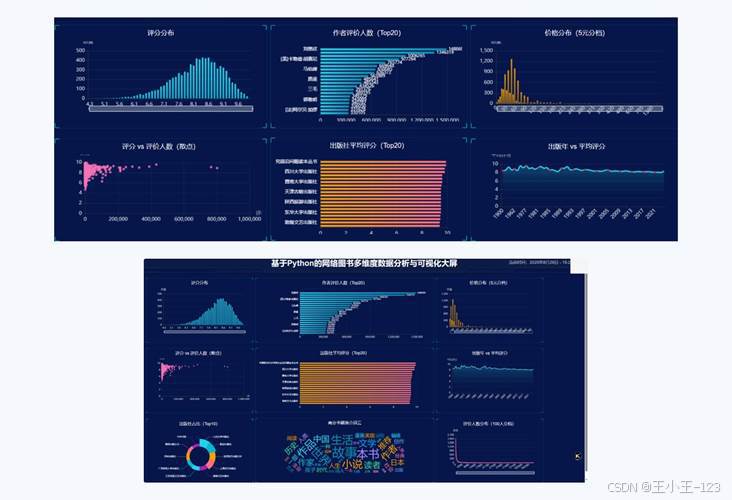
图 11 ECharts 动态大屏与暗色数据看板展示
八、系统集成:把图表放进可登录访问的平台
为了让项目不只是一些分散的 HTML 文件,我又做了一层可视化系统集成。后端使用 Flask,前端使用 HTML、JavaScript 和 Layui 管理界面。系统包含登录、注册、个人中心、资料更新、侧边栏导航、页面嵌入和主题切换等功能。用户登录后,可以通过左侧菜单进入评分分析、价格分析、评价人数分析、出版年份分析、作者分析和动态大屏。
这一层的价值在于把"数据结果"变成"可操作产品"。以前打开图表需要在文件夹里逐个找 HTML,现在系统把入口统一起来。侧边栏按分析维度分组,头部提供刷新、全屏、主题设置和个人中心,主体区域加载对应的可视化页面。对于演示、答辩、课程展示或项目交付来说,这种平台化入口会比单独文件更完整。
系统还支持多主题切换,适配不同演示风格。静态图表页面和动态大屏可以并行存在:前者稳定、加载快,适合批量展示;后者交互强、视觉冲击力更明显,适合汇报和现场讲解。后续如果继续拓展,可以加入图书搜索、作者画像、出版社画像、文本主题聚类、简单推荐模块,甚至接入其他图书平台数据做横向对比。
在公开展示时,我对账号、路径、接口地址和部分运行日志做了遮挡处理,只保留功能形态和流程效果。这样既能展示项目完成度,也能避免把不适合公开复用的信息直接暴露出来。展示型文章更适合呈现思路、模块、页面和效果,完整代码、原始数据和部署细节可以单独打包,便于需要复现的朋友进一步交流。
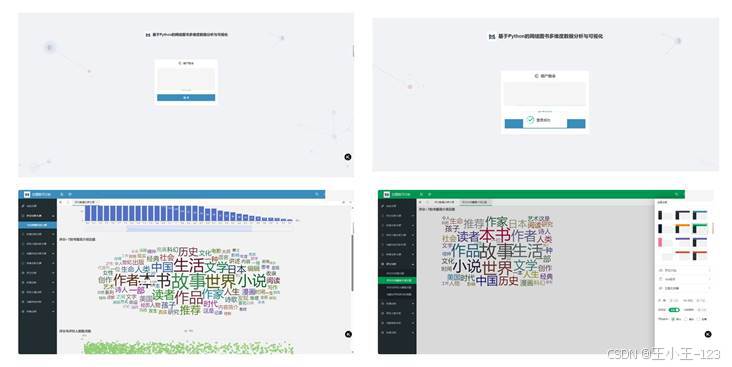
图 12 登录页面、主界面导航与主题切换效果展示
九、项目可以继续扩展的方向
这个项目已经形成了一条比较完整的图书数据分析链路,但它仍然留有很多可继续完善的空间。数据层面可以增加更多平台来源,把单一平台的样本扩展为多平台对比;算法层面可以继续加入文本分类、主题建模、情感分析、图书推荐和作者影响力评估;系统层面可以增加后台任务管理、数据更新按钮、图表导出、用户权限和部署脚本。
如果用于学习,它适合拆成爬虫、Pandas 清洗、MySQL 入库、Pyecharts 绘图、Flask 接口、ECharts 大屏、Layui 后台等多个模块逐步练习;如果用于作品展示,它又能作为一个完整的端到端项目呈现。最重要的是,它不是停留在"把数据画出来",而是把数据的获取、治理、分析和交互串成了可复用流程。
每文一语
真正有价值的项目,往往不是一次性把功能堆满,而是在每一次清洗、每一次调试、每一次可视化中,把模糊的问题一点点变得清楚。