大家用的AI显卡主要都是英伟达的nv卡,但其实AMD ROCm这几年也在努力完整其生态。苏妈在CPU上的大获成功,如果能在GPU上也能实现类似的成就,相信能让更多的开发者用上性价比更高的显卡。
 逛社区时,发现魔塔和AMD开发者云有合作活动,可以参加体验AMD云平台的算力卡。我赶紧着手试试哈哈
逛社区时,发现魔塔和AMD开发者云有合作活动,可以参加体验AMD云平台的算力卡。我赶紧着手试试哈哈
第一步,根据官网的流程注册魔塔账号,绑定AMD开发者云,进入以后,就能看到好多实例可以用来开启探索,Hello ROCm Bate是推荐的初始入口

第二步,阅读notebook,进阶的可以直接创建几个terminal,运行一些bash命令
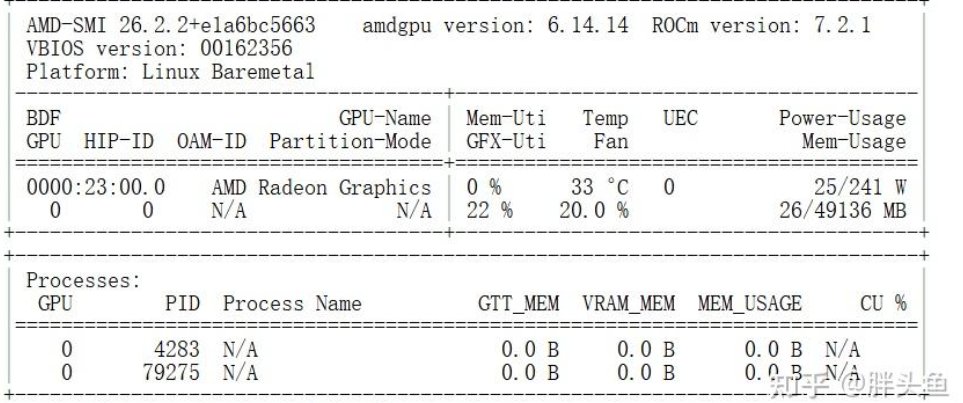
运行一下AMD-SMI,拿到一些基础的信息,比如现存大小,功率,温度等等。不过没看到显卡的型号,这个不清楚是软件问题,还是云平台默认不显示。总体的话,给了48GB现存,能做不少轻量的事情了。
第三步,下载模型,这里使用的是魔塔的命令,感觉和huggingface-cli很接近,终端里也没有让我设置ssh-key之类的,挺方便的
pip install https://zhida.zhihu.com/search?content_id=277689203&content_type=Article&match_order=1&q=modelscope&zhida_source=entity
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"大概下载了10分钟左右,下载成功了
第四步,起服务
我发现这个终端环境默认有个vllm(没有sglang),直接用vllm的命令把服务启动起来
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it由于模型不大,很快就把服务启动起来了
 不得不说,vLLM在终端输出的这个图标做的很好看
不得不说,vLLM在终端输出的这个图标做的很好看
第五步,开始聊天
在另外一个,发射一个聊天命令就可以开始和gemma聊天了
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-itAMD的云服务平台整体体验还是很流畅的,这次活动的算力券也相当大方,显卡48GB已经很大了,不过这个级别的显卡跑deepseek之类的大模型就不行了,不知道租大的GPU需要多少钱哈哈,还有就是,amd-smi看不到显卡型号,这个还挺奇怪,是云平台的设计就是如此吗?
整体而言,体验还是非常好的,感觉AMD正在全面追赶英伟达,软件生态也进步很多,这次用下来,说明最基础常用的amd-smi,vllm/torch都已经很好用了,基本可以无缝从nv平台迁移过来,还是很爽的,苏妈威武呀!
#AMDev #Datawhale #ROCm