三大范式
数据库的范式是一套标准化规则,其核心作用是减少数据冗余和避免操作数异常,在构建稳健、清晰的关系型数据库时,我们往往只关注前三大范式
第一范式
内容介绍
第一范式是数据库设计的中的底线,它的核心要求就是要让数据保持原子性
场景构建
假设我们有一个学生选课管理系统,为了省事,我们将学生选取的所有课程都放入同一个字段中,大致表结构如下:
| 学生 ID | 姓名 | 选修课程 |
|---|---|---|
| 101 | 张三 | 计算机网络, 操作系统 |
| 102 | 李四 | 数据库原理 |
这种字段结构会导致数据库无法进行高效匹配,如我们想要查询所有选修了计算机组成原理课程的学生我们就无法使用 WHERE 选秀课程 = '计算机组成原理'语句进行查询,因此我们只能使用模糊查询,这种查询会导致数据库的索引完全失效,每次查询都需要从头到尾的去扫描整张表,如果表中的数据过多就会导致卡死
改造后:
| 学生 ID | 姓名 | 选修课程 |
|---|---|---|
| 101 | 张三 | 计算机网络 |
| 101 | 张三 | 操作系统 |
| 102 | 李四 | 数据库原理 |
解决方法
要让表的结构满足第一范式标准的做法是将表进行按行拆分
第二范式
内容介绍
在满足第一范式的基础上,表中所有非主属性必须完全依赖整个主键,而不能只依赖于主键的一部分
场景构建
假设我们有一张选课记录表,为了确定一条选课记录,我们必须把(学号,课程编号)绑定在一起作为联合主键,表中的字段如下:
- 主键:(学号,课程编号)
- 非主键字段:(成绩,学生姓名,课程学分)
大致的结构如表所示
| 学生 ID | 课程 ID | 成绩 | 学生姓名 | 课程学分 |
|---|---|---|---|---|
| 101 | C01 |
90 | 张三 | 4 |
| 101 | C02 |
85 | 张三 | 3 |
| 102 | C01 |
92 | 李四 | 4 |
在当前设计中,非主键字段的依赖关系是比较混乱的:
- 成绩:完全依赖于(学号,课程编号)。(符合
2NF) - 学生姓名:只依赖于学号,跟课程编号没关系(部分依赖,违背
2NF) - 课程学分:只依赖于课程编号,跟学号没关系(部分依赖,违背
2NF)
主要问题
上述的表结构会引发以下几大问题
数据冗余
如果一个学生选修了5门课,那么张三这个名字就会在数据库里重复出现5次,同理,如果一门课被100个学生选了,那么课程ID和4学分就会被重复记录100次
插入异常
假设学校新开了一门课,但是目前还没有任何学生选修这门课,因为这张表的主键是(学号,课程编号),主键不能为空,所以在没有学号的情况下,我们无法把这门新课的信息录入到数据库中
删除异常
假设有一个学生大学毕业了,系统需要清除该学生的选课数据,碰巧,该同学是全校唯一一个选修了某个冷门专业课的人,当我们把该同学的选课记录删除后,对应的课程编号和学分信息也就跟着一块丢失了
解决方法
想要解决上述问题,我们可以将产生"部分依赖"的字段连同它们依赖的主键部分一起分离出去,以此形成新的表
改造后:
将原表拆分为三个表,各自负责独立的实体关系:
1. 学生表
| 学生 ID | 学生姓名 |
|---|---|
| 101 | 张三 |
| 102 | 李四 |
2. 课程表
| 课程 ID | 课程学分 |
|---|---|
C01 |
4 |
C02 |
3 |
3. 成绩表
| 学生 ID | 课程 ID | 成绩 |
|---|---|---|
| 101 | C01 |
90 |
| 101 | C02 |
85 |
| 102 | C01 |
92 |
作用
综上所述,第二范式的作用就是消除部分依赖,让表里的属性都为主键服务,从而彻底消灭冗余和增删改异常
第三范式
内容介绍
第二范式解决的是复合主键带来的部分依赖问题,那么第三范式解决的就是单一主键表中隐藏的层级耦合问题
场景构建
假设我们有一张学生信息表,主键是单一字段"学号",因为主键只有一个字段,所以它天然满足第二范式,表的结构如下:
-
主键:学号
-
非主键字段:姓名,学院名称,学院院长
大致的表结构如下:
| 学号 | 姓名 | 学院名称 | 学院院长 | 学院办公楼 |
|---|---|---|---|---|
| 1 | 王五 | 计科院 |
张三 | 逸夫楼 |
| 2 | 赵六 | 机械学院 |
李四 | 建工楼 |
| 3 | 孙七 | 商学院 |
李华 | 汇文楼 |
在当前的设计中,字段之间的依赖关系出现了一条依赖关系链:
- 姓名和学院名称直接依赖于学号
- 学院院长和学院办公楼则直接依赖于学院名称,然后通过学院名称间接依赖于学号
这就是传递依赖,这种寄生在非主键字段上的依赖关系同样会引发不小的问题
主要问题
数据冗余
假设"计算机学院"有2000名学生,那么在数据库里,"院长是张三","办公楼在逸夫楼"这两条信息,就会跟着这2000个学生的记录会被反复记录2000次,这就会浪费了大量的存储空间。
插入异常
学校刚刚成立了一个全新的人工智能学院,院长和办公楼都已经确定了。但是,今年还没有开始招生,也就是没有任何"学号"。因为这张表的主键是 学号(不能为空),所以在没有学生之前,你根本无法把这个新学院的信息录入系统
删除异常
假设冷门学院今年没有招到新生,而且大四的最后一批学生也刚好毕业了。系统在清理毕业生数据时,删除了这些学生的记录。结果就是,该学院的院长是谁、办公楼在哪里的信息,也跟着学生数据的删除一起从数据库中消失了。学院还在,但数据丢了。
改造后:
1. 学生表
| 学号 | 姓名 | 学院名称 |
|---|---|---|
| 1 | 王五 | 计科院 |
| 2 | 赵六 | 机械学院 |
| 3 | 孙七 | 商学院 |
2. 学院表
| 学院名称 | 学院院长 | 学院办公楼 |
|---|---|---|
| 计科院 | 张三 | 逸夫楼 |
| 机械学院 | 李四 | 建工楼 |
| 商学院 | 李华 | 汇文楼 |
解决方法
为了解决传递依赖的问题,我们需要将对应的连接关系斩断,将产生依赖的字段提取出来并建立新的表来保存它们,做法与之前的第二范式方法有些类似
总结
三大范式的主要内容总结起来就是几句话:
第一范式:字段不可再分,保证原子性
第二范式:消除对联合主键的部分依赖
第三范式:消除非主键之间的传递依赖
它们之间是递进关系,满足第三范式就一定满足第二范式,满足第二范式就一定满足第一范式,因此我们不难推出,第三范式建立在第二范式基础上,第二范式建立在第一范式基础上。这就好比学历晋升,想要拿到博士学位就要先拿到硕士学位,想要拿到硕士学位就要先拿到学士学位,因此一个博士学位的人肯定已经有了学士学位,同理,一个满足第三范式的数据库表肯定也满足第一范式,对应的范式关系如下图所示:
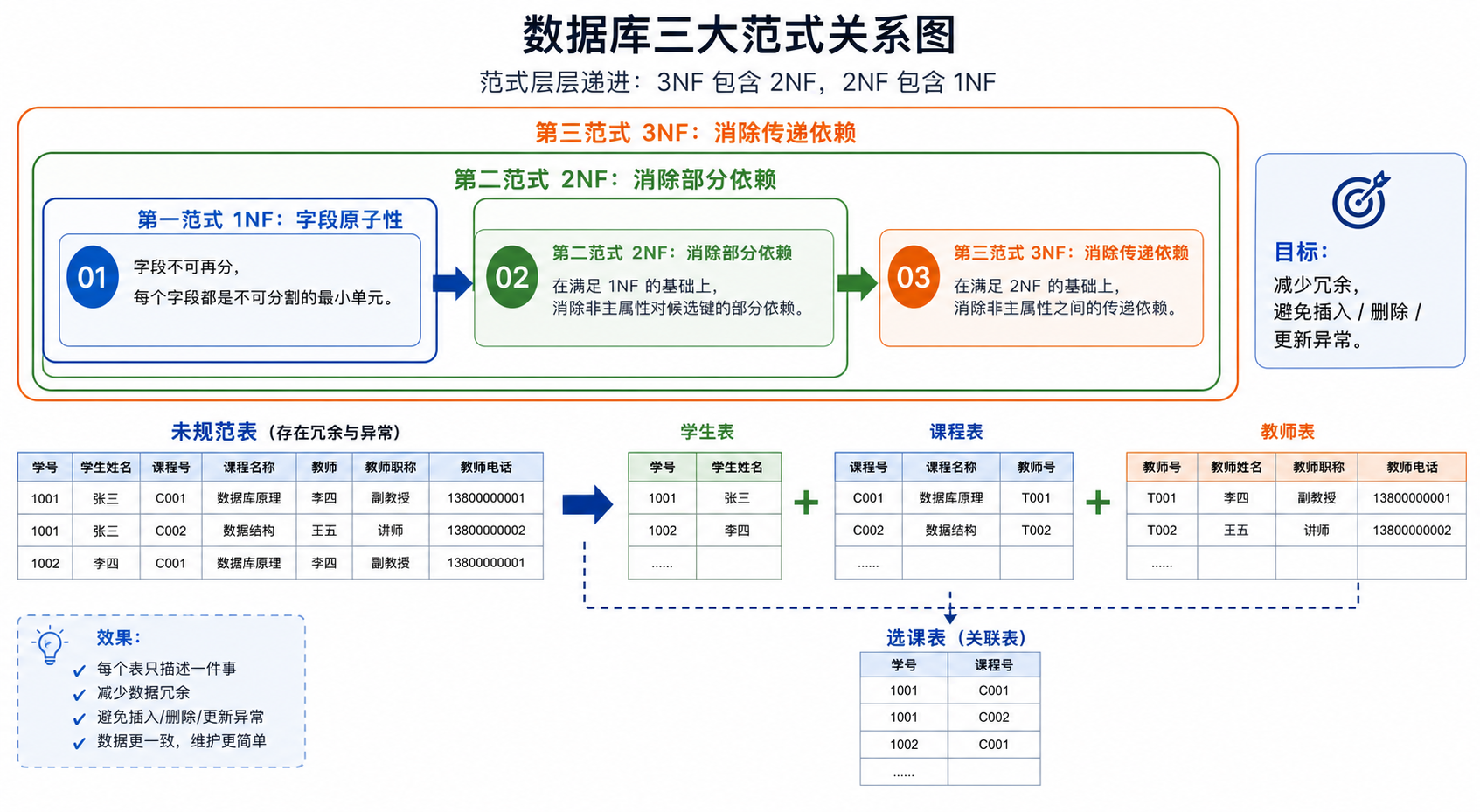
数据库设计界有一句格言,总结了前三大范式:
"Every non-key attribute must provide a fact about the key, the whole key, and nothing but the key." (每个非键属性都必须提供关于键的事实,且必须是关于整个键 的事实,而且只能是关于键的事实。)
-
"关于键" ------ 满足第一范式 (
1NF) -
"整个键" ------ 满足第二范式 (
2NF,消除部分依赖) -
"只能是关于键" ------ 满足第三范式 (
3NF,消除传递依赖)key, the whole key, and nothing but the key." (每个非键属性都必须提供关于键的事实,且必须是关于整个键 的事实,而且只能是关于键的事实。)
-
"关于键" ------ 满足第一范式 (
1NF) -
"整个键" ------ 满足第二范式 (
2NF,消除部分依赖) -
"只能是关于键" ------ 满足第三范式 (
3NF,消除传递依赖)