逻辑回归的任务:
二分类------是否
多分类------图像分类
结构预测------输出一个序列段落
逻辑回归任务能否用最小二乘解决------对应线性回归
定义分类问题
决策边界
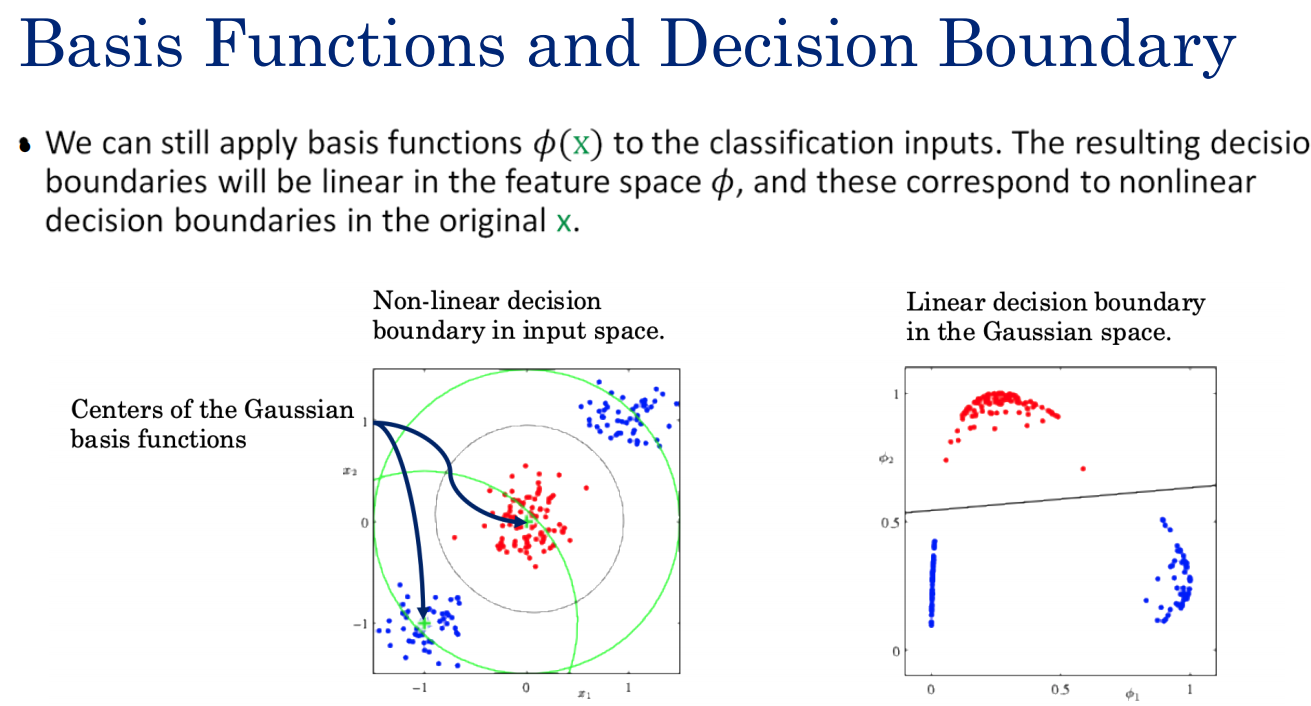
可以使用两个高斯基函数将非线性的数据映射到线性可分的空间上。
逻辑回归的损失函数
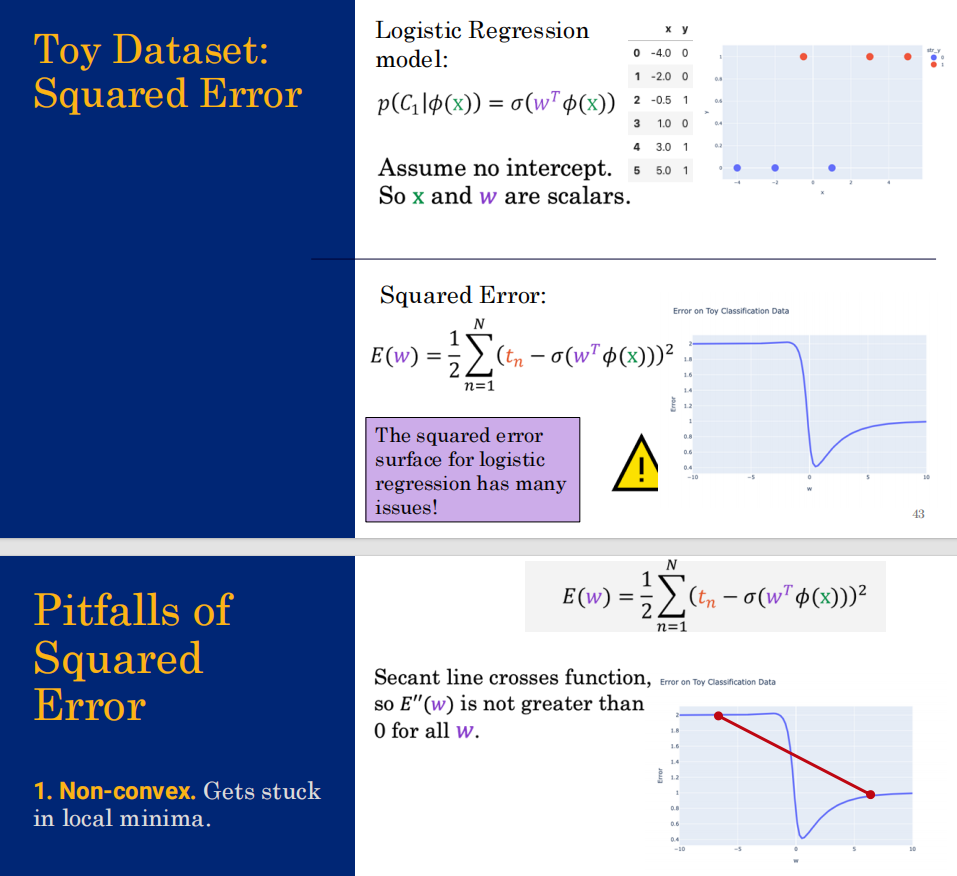
这两页 PPT 其实是在解释逻辑回归里的一个经典问题:为什么不能直接用"均方误差"作为损失函数?
你可能会觉得,在线性回归里用"预测值与真实值之差的平方"效果很好,为什么到了逻辑回归就不行了?
会陷入局部最优解。
误差不公平,对于任何错误的分类都是1
原因一:非凸(Non-convex)------ 难优化
- PPT 原文:"Gets stuck in local minima."(会陷入局部最小值)。
- 通俗解释 :
- 我们在训练模型时,就像是在一座山上找最低点(误差最小的地方)。
- 如果是"凸函数"(Convex),这座山就像一个完美的碗,无论你从哪里开始往下走,最终都会走到碗底(全局最优解)。
- 但如果用了均方误差,损失函数的形状会变得像连绵起伏的山脉(Non-convex),有很多坑坑洼洼。
- 后果:你的优化算法(比如梯度下降)很容易走到一个小坑里(局部最小值),以为到底了,就停在那儿不动了。这就导致你找到的模型参数不是最好的,模型效果大打折扣。
原因二:有界(Bounded)------ 惩罚力度不够
- PPT 原文:"Not a good measure of model error... Squared Error never gets very large."(不是衡量误差的好指标......均方误差永远不会变得很大)。
- 通俗解释 :
- 我们希望损失函数能狠狠地"惩罚"那些错得离谱的预测。
- 但是在逻辑回归中,预测值 pp 被 Sigmoid 函数限制在 0,10,1 之间,真实标签 tt 也是 00 或 11 。
- 计算一下:最糟糕的情况是什么?是真实标签 t=1t=1 ,但模型预测 p=0p=0 (完全预测反了)。
- 这时候的均方误差是多少? (1−0)2=1(1−0)2=1 。
- 问题所在:误差最大也就是 1。这意味着,无论模型错得有多离谱(比如它非常自信地预测错了),它受到的惩罚都被"封顶"在 1 了。
- 对比 :如果我们用交叉熵损失(Cross-Entropy Loss),当模型预测 p=0p=0 而真实是 t=1t=1 时,损失会趋向于无穷大( −ln(0)→∞−ln(0)→∞ )。这种"无限大"的惩罚会迫使模型拼命修正错误。而均方误差的"温和"惩罚会让模型学得比较慢,甚至学不到位。
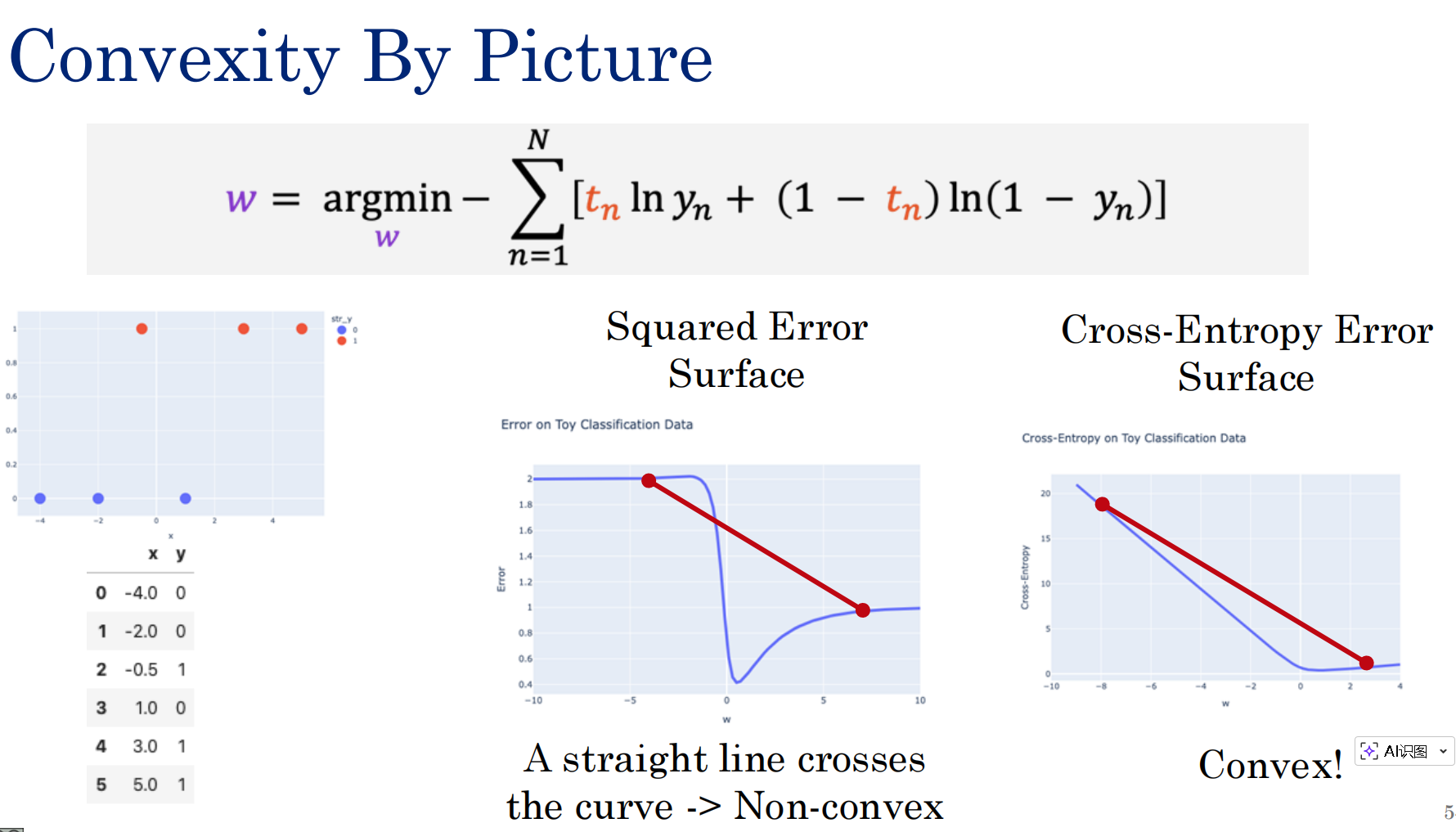
新的损失函数------从最大似然到交叉熵
既然均方误差(MSE)这条路走不通,那逻辑回归该用什么损失函数呢?这一页 PPT 给出了标准答案:最大似然估计(MLE)。
通过ln放大了误差同时将其凸化!!!

PPT 下方有两个对比图,对比了均方误差(蓝色线) 和负对数误差/交叉熵(红色线):
-
左图(当真实标签 tn=1tn=1 时):
- 横轴:模型预测的概率 ynyn 。越往右,预测越准(接近 1)。
- 纵轴:误差(Error)。越低越好。
- 解读 :
- 当模型预测 ynyn 接近 0(完全预测错)时,红色线(交叉熵)直接冲向无穷大!而蓝色线(均方误差)只停留在 1。
- 结论 :交叉熵对"错得离谱"的预测会施加巨大的惩罚,逼迫模型赶紧修正。
-
右图(当真实标签 tn=0tn=0 时):
- 横轴:模型预测的概率 ynyn 。越往左,预测越准(接近 0)。
- 解读 :
- 当模型预测 ynyn 接近 1(完全预测反了,自信地认为是正类)时,红色线(交叉熵)又冲向无穷大!
- 结论:同样,它对"极其自信但完全错误"的判断绝不姑息。
目标
找到交叉熵损失最小的w
手段:找一条"概率拟合线"
逻辑回归的训练过程 (也就是最小化损失函数的过程),实际上是在做拟合。
- 它试图让 Sigmoid 曲线(那条 S 形的线)尽可能完美地包裹住数据点。
- 对于 t=1t=1 的点,它想把曲线拉高到 1。
- 对于 t=0t=0 的点,它想把曲线压低到 0。
- 在这个阶段,它是在"拟合"概率。
目的:找一条"决策分割线"
当我们训练完模型,准备用它来预测时,我们关心的是分类。
- 我们通常会定一个阈值(比如 0.5)。
- 大于 0.5 的算一类,小于 0.5 的算另一类。
- 这个 0.5 的分界点,在空间上对应的就是一个超平面(分割线)。
- 在这个阶段,我们是在用"分割线"做决策。
ww 的双重身份
ww 是连接这两者的桥梁,它同时决定了这两条线:
ww 决定了分割线的位置(方向)
- 在二维空间里,方程 wTx+b=0wTx+b=0 就是一条直线。
- ww 的数值决定了这条线在哪里,怎么倾斜。
- 只要 wTx+b>0wTx+b>0 ,就是正类;反之就是负类。这是硬分类的依据。
ww 的大小决定了拟合线的"陡峭程度"
- ww 很小:Sigmoid 曲线很平缓。意味着模型比较"犹豫",即使你跨过了分割线,概率变化也不剧烈。
- ww 很大(趋向无穷):Sigmoid 曲线变得非常陡峭,像一个台阶。意味着模型非常"确信",只要稍微跨过分割线,概率立刻从 0 跳到 1。
- 这就是刚才那道题 w→∞w→∞ 的原因:为了追求极致的拟合(概率逼近 0 和 1),模型把 Sigmoid 拉成了一条近乎垂直的阶跃线。
所以整体逻辑是,由于二分类问题的分布是0-1分布,所以可以通过wx+b拟合一条直线,但是这个输出域是-无穷到+无穷,不合适,因此考虑软分类,引入sigmoid函数,误差从对于二分类的最小二乘变为凸且惩罚合适的交叉熵,使得这个拟合函数sigmoid的误差最小。但是可能w为了拟合太大,过拟合,需要引入正则化约束w。
"代价不对等"




多酚类问题
普通的多线性分类会产生重合区域无法分辨的问题

对每个类打分,画出两个类别相等分数线。




将其改为概率输出


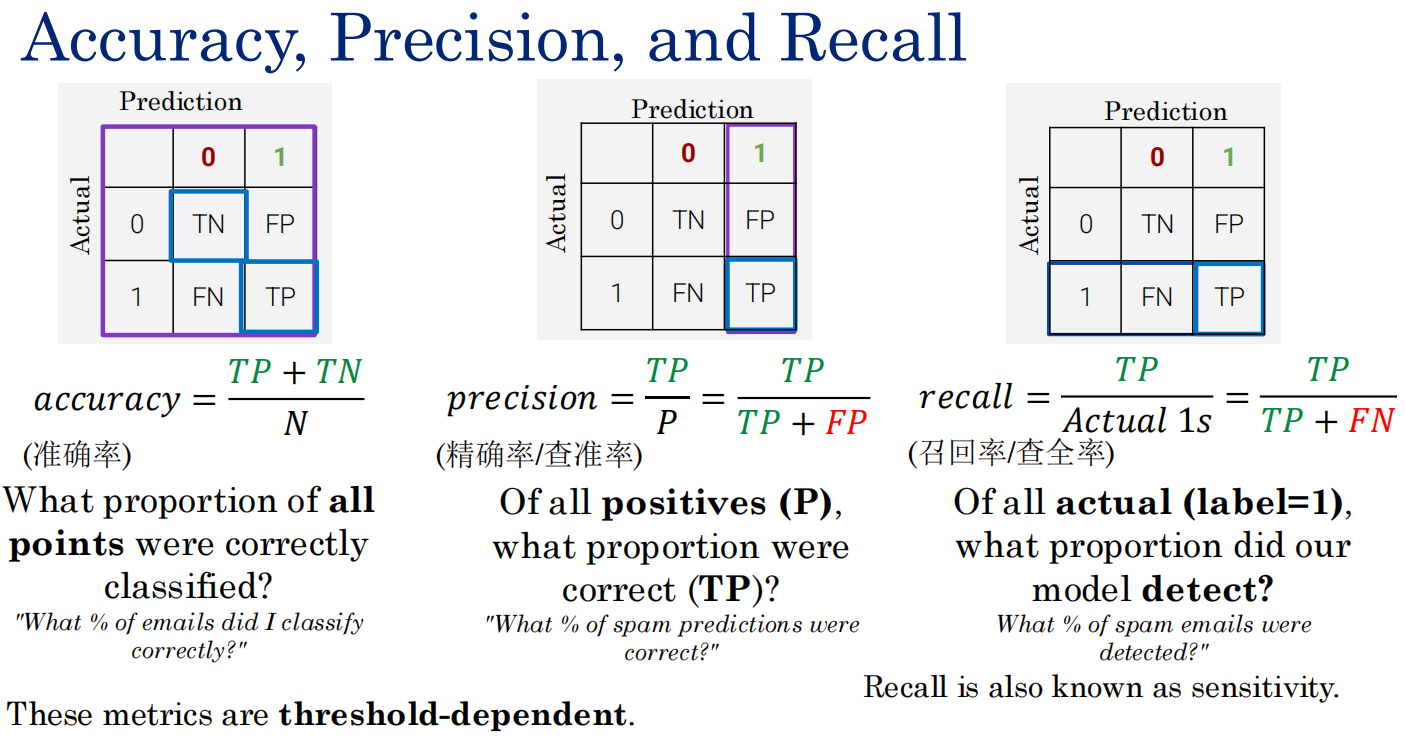
模型评估

用混淆矩阵
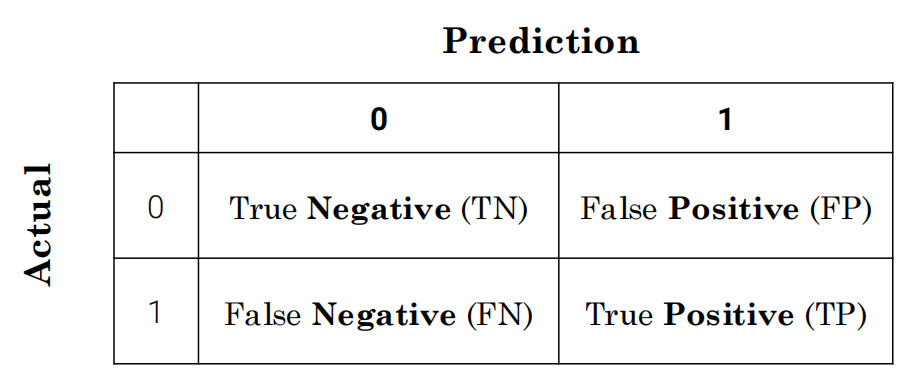
影响因素:分类器 数据集 阈值
用accuracy:预测对的占整体(主对角线)
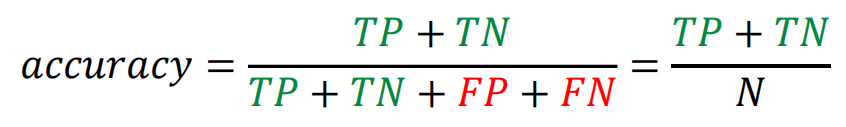
TP + FN/N
用precision
TP/TP+FP
只找带P的
用recall
TP/TP+FN
但是有个问题,100封邮件5封诈骗,那么如果全部预测为非诈骗,那么ac可以达到95,但是一封诈骗邮件都检测不出来。
所以ac对于类比极其不均匀的分类问题是无用的。
提升阈值,TP会不变或变少。
precision和recall是负相关的,当提高阈值时,recall升高,precision降低
我们需要调节阈值降低预测损失。
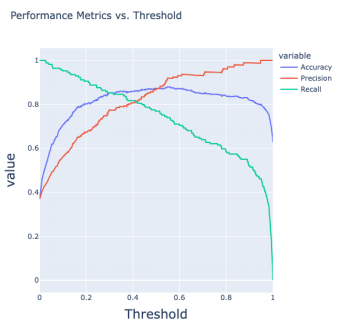
可以遍历0.01-0.99来看那种情况下效果最好。
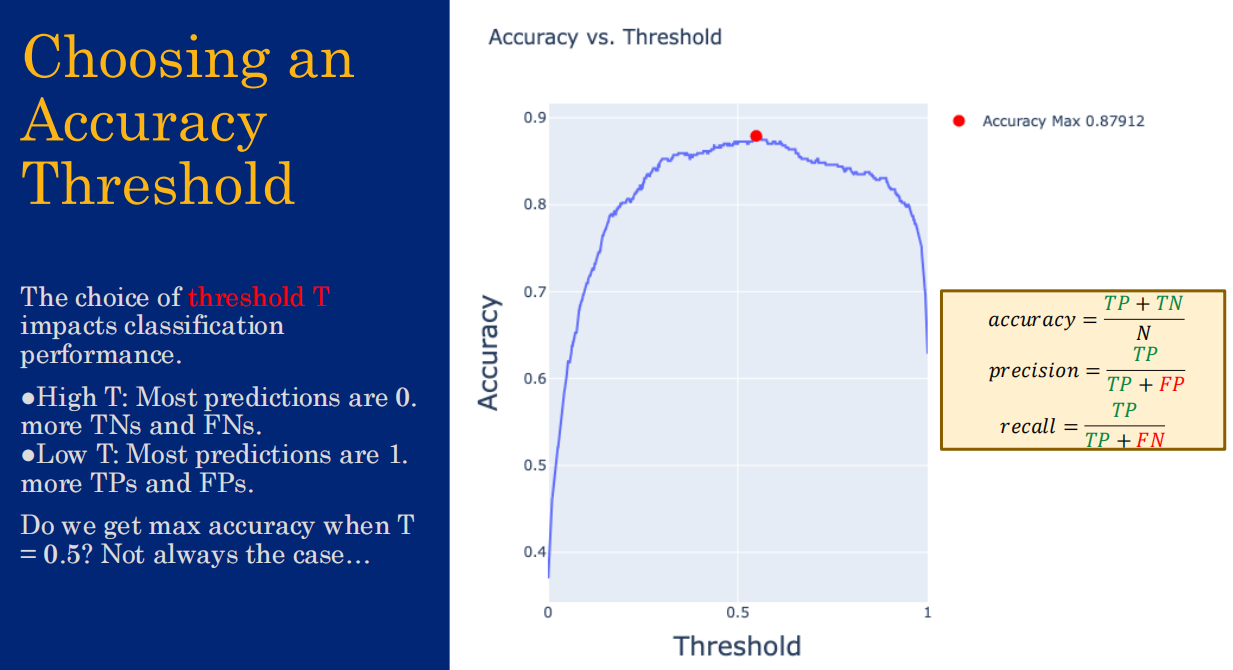
错误指标
FPR越低越好 TPR越高越好

选择左上角
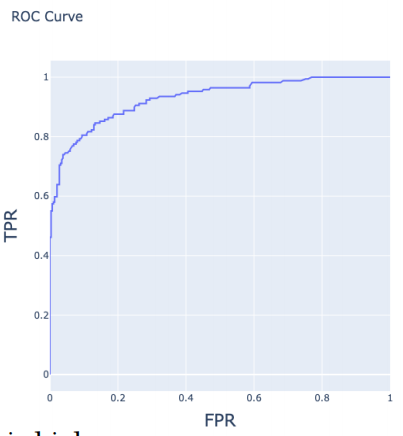
F1分数------平衡precision和recall
对于不同任务需要调整二者的比例。使用于类别不均匀的情况。
比如,100封邮件5封诈骗,那么如果全部预测为非诈骗,那么ac可以达到95,但是一封诈骗邮件都检测不出来。

ROC和AUC
ROC曲线围城面积是AUC,最大是1
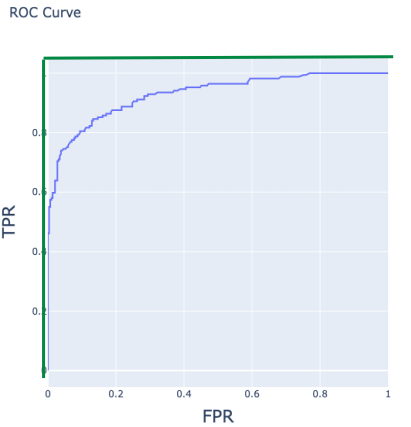
指标总结


梯度下降
凸函数
两点之间的值都在割线以下

凸集

优化问题定义
有约束可以转化为无约束的
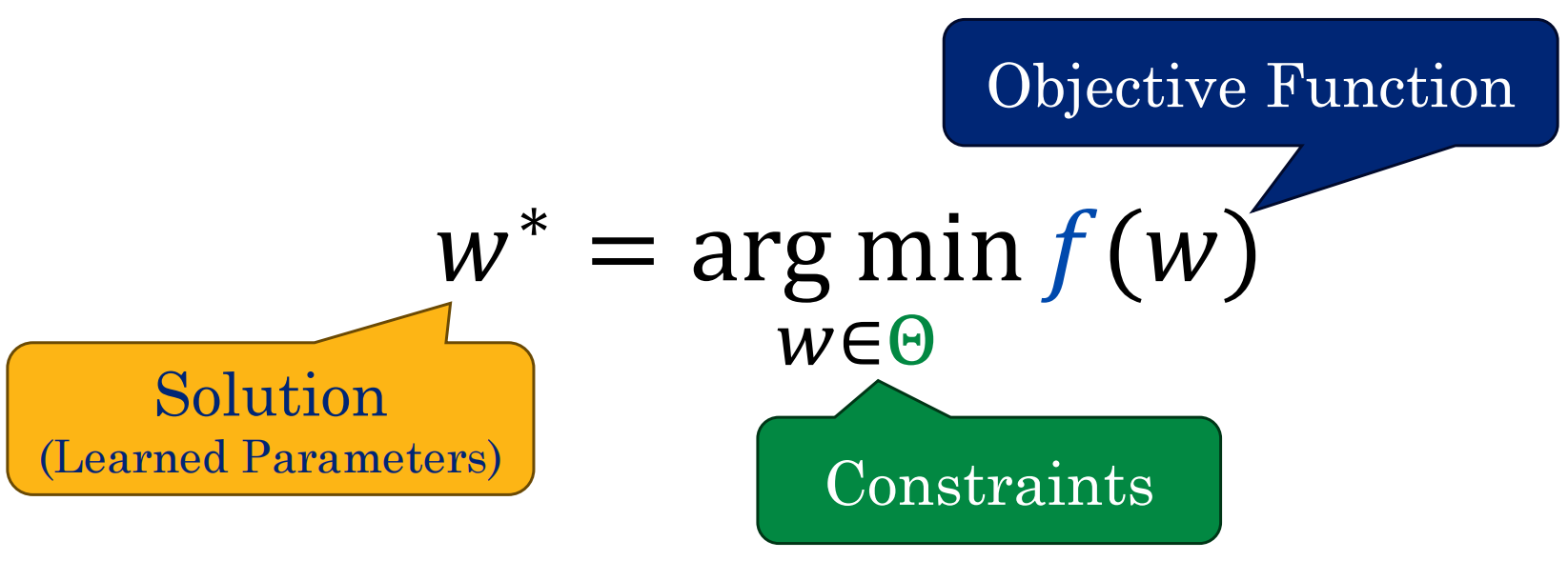
要求:凸函数且域是凸集
使用不同的参数可以观察到不同的拟合效果:
离谷底最近的点拟合越好
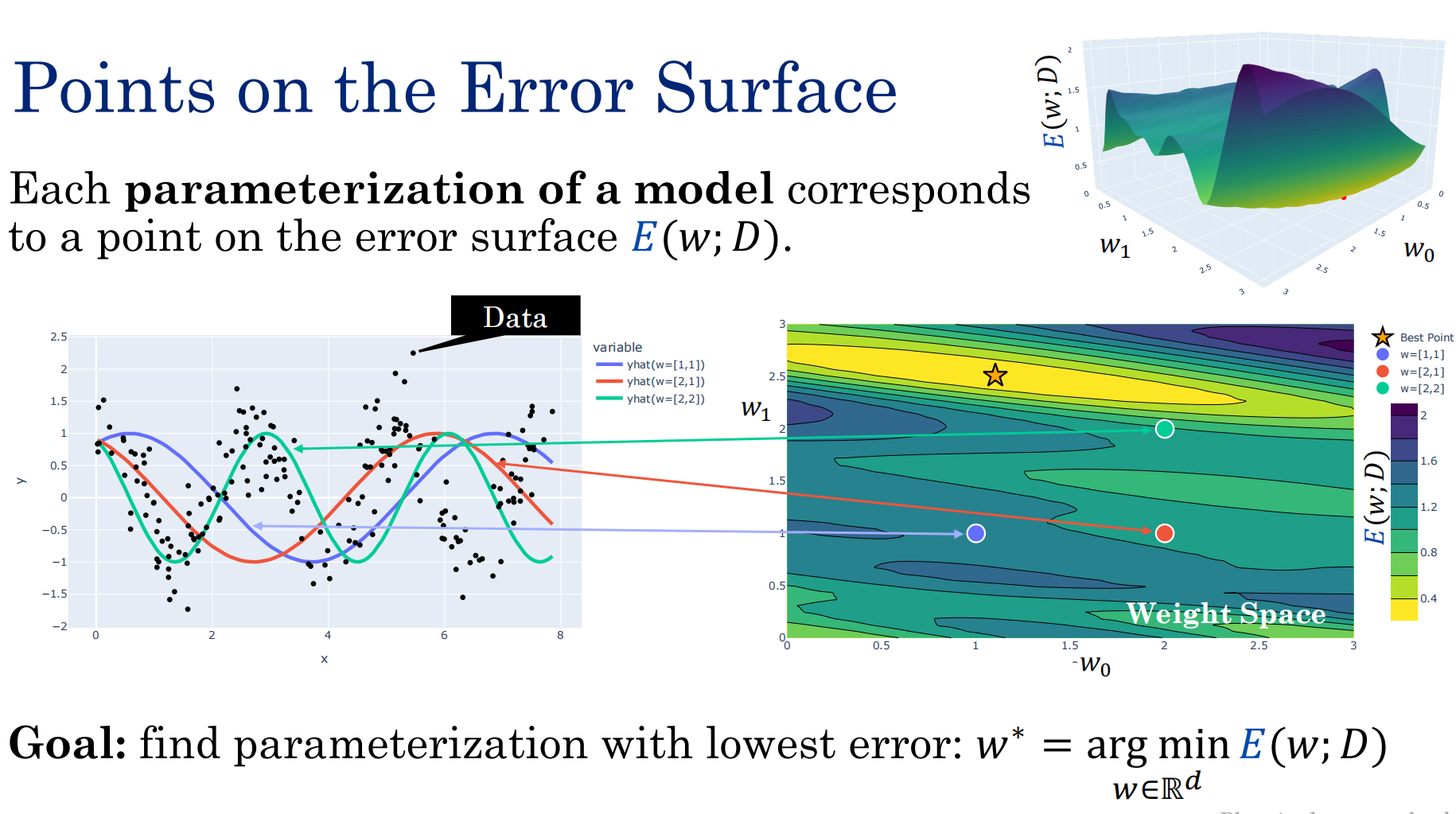
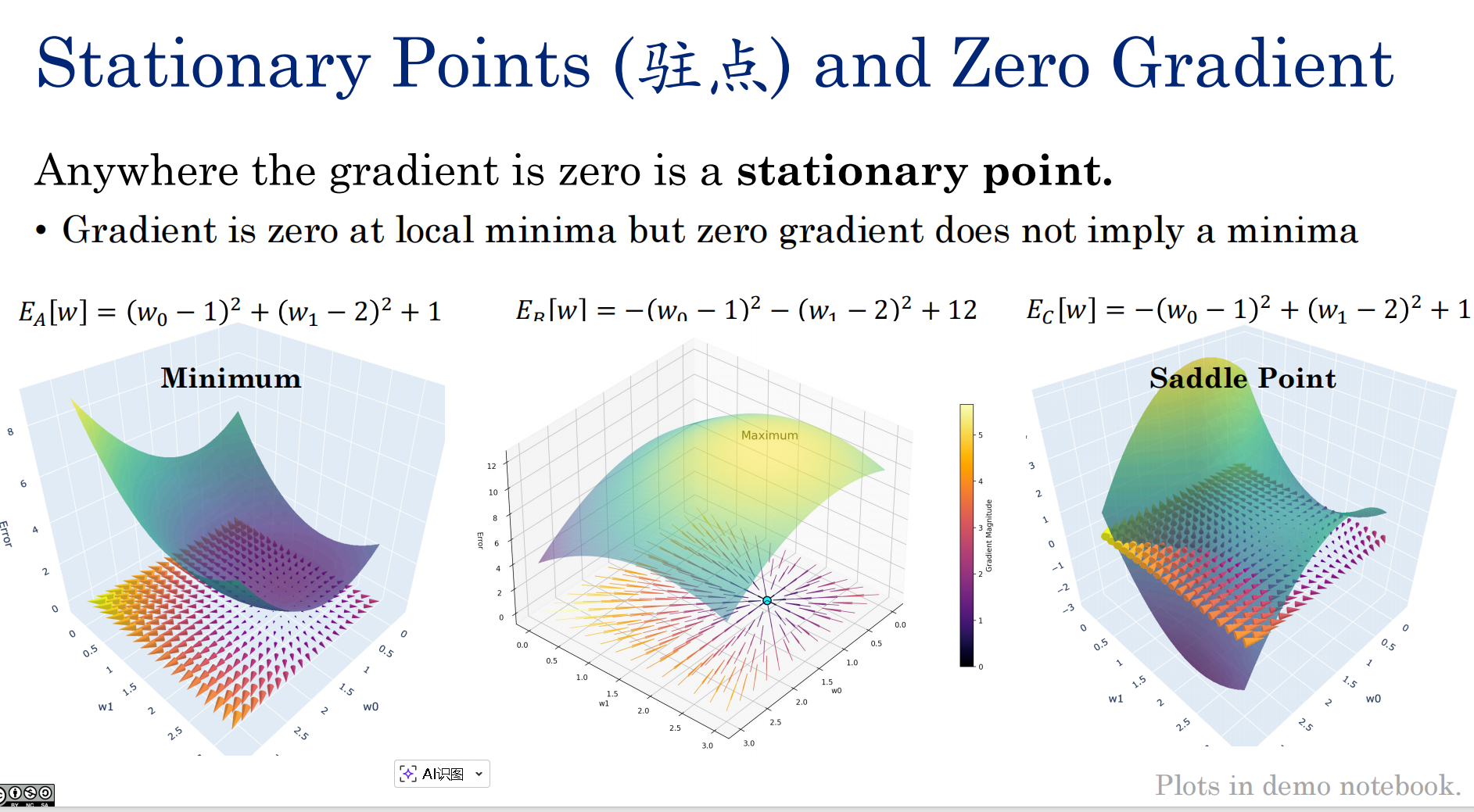
梯度为零的情况:极大极小 鞍点
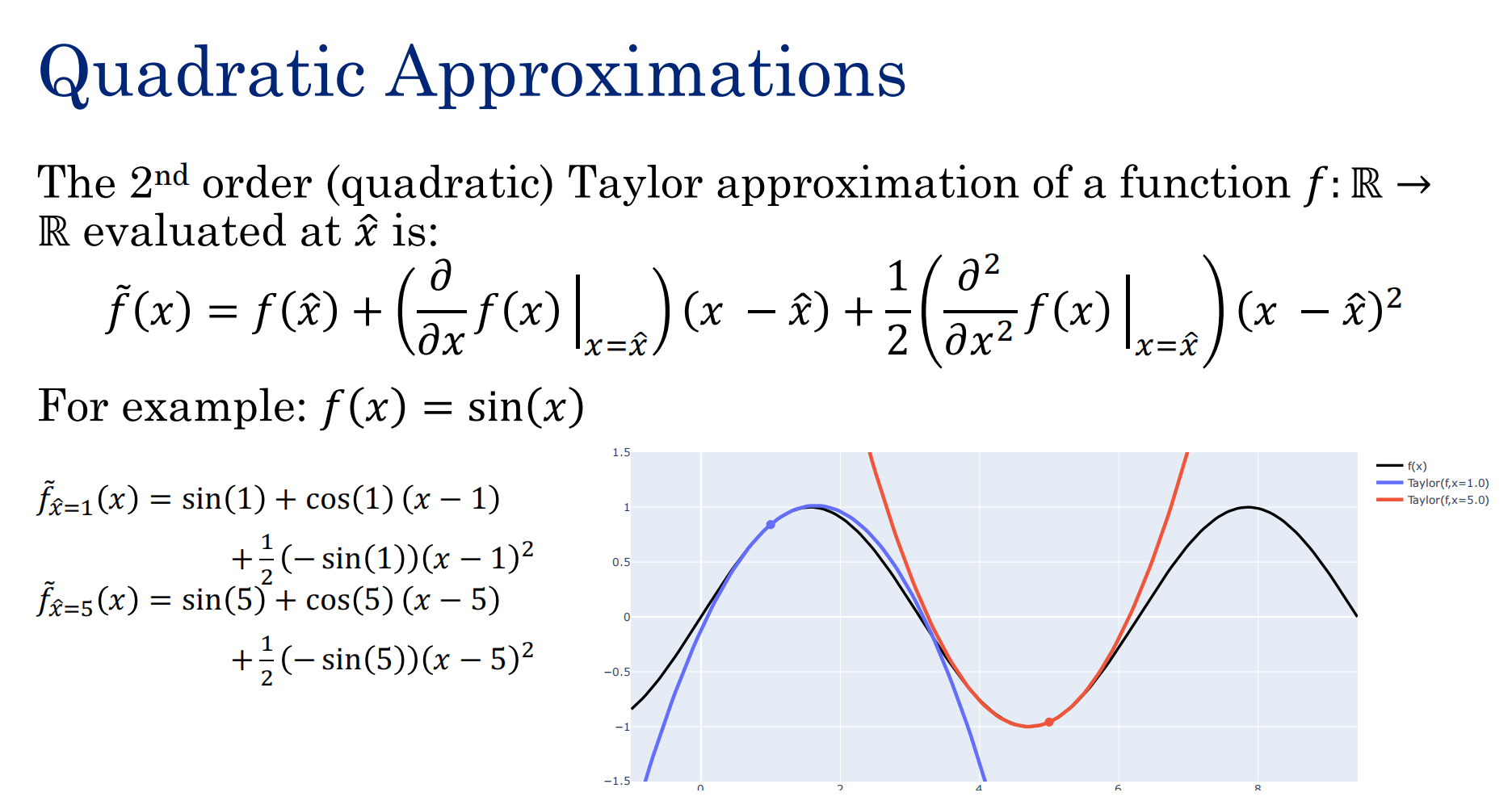
二阶泰勒展开
利用海森矩阵(Hessian Matrix)的特征值分解,来判断多变量函数驻点的性质(是极小值、极大值还是鞍点)。
我们使用二姐泰勒展开是未来验证极小值点处是否是合理的?
这要求





lambda决定了特征向量的方向,那么如果为正说明这一点无论怎么走都是爬坡,是极小值。
学习率调度安排


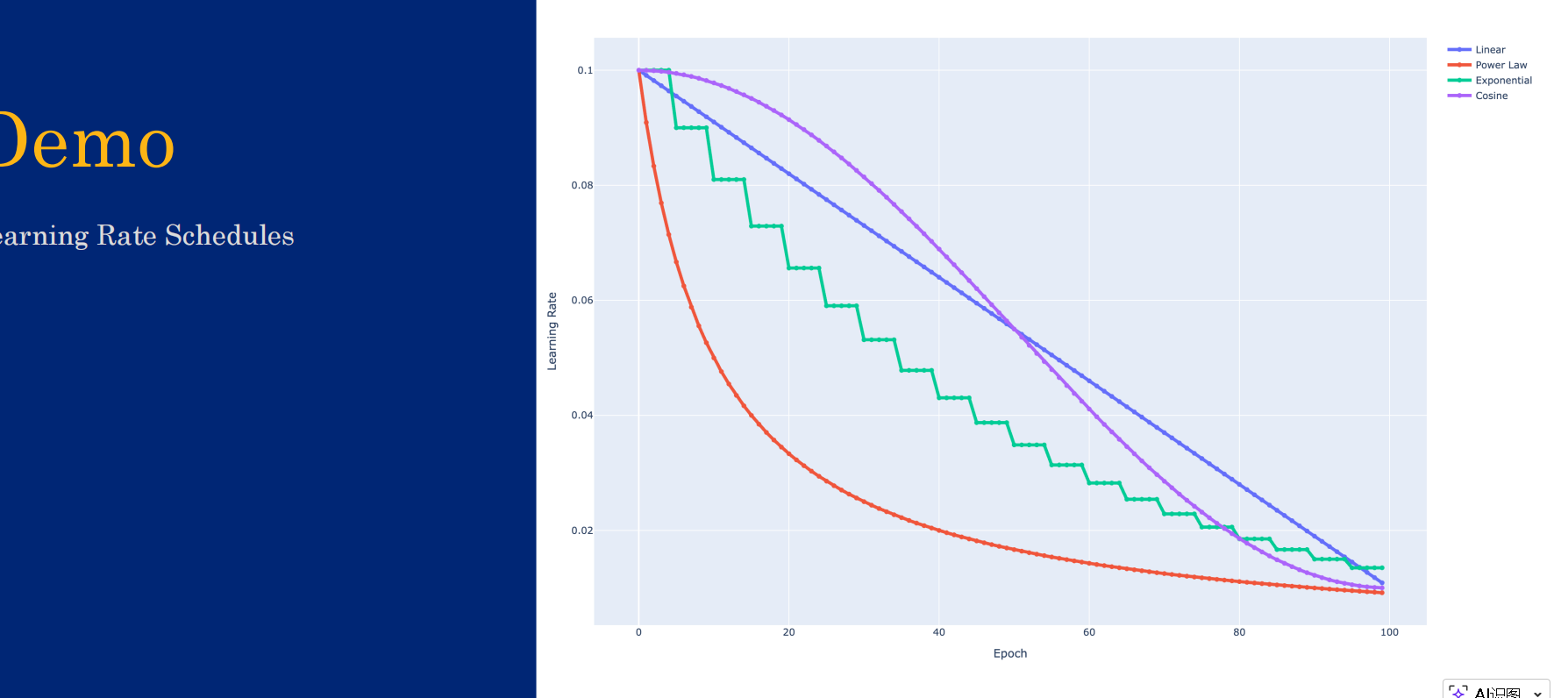
自适应学习率
Ada 对每个参数都维护一个r作为学习率,如果r比较大,说明梯度更新的幅度很大,那么就在这个方向去减小学习率。如果r比较小,说明梯度更新的幅度很小,那么就在这个方向去增加学习率。

但是可能会导致停止更新的问题。
不对分母r进行累计,而是对历史进行衰减
越近的历史说明最近的调节很大,那么就减小调节,很远的历史就没那么大的影响。



Adam优化器


批量梯度下降在每次迭代时都需要遍历全部训练数据,导致其计算成本随着数据量和维度的增加而线性增长。
-
成本来源分析:
- 遍历所有数据点:批量梯度下降在每一步更新参数时,都需要计算所有 NN 个训练样本的梯度,然后取平均值。这个过程的成本与数据量 NN 成正比,即 O(N)O(N) 。
- 高维参数计算:对于每个数据点,计算其梯度本身就需要在 DD 维空间中进行运算(例如,计算权重向量与特征向量的内积)。这个计算成本与维度 DD 成正比,即 O(D)O(D) 。
-
总成本结论 :
综合以上两点,批量梯度下降每次参数更新的总计算成本是 O(ND)O(ND) 。这意味着,当你的数据集非常大( NN 很大)或者模型非常复杂( DD 很大)时,每一次迭代会变得极其缓慢和昂贵。
-
理想目标 :我们真正希望最小化的是期望测试误差(Expected Test Error),也就是模型在未来所有未知数据上的平均表现。但这在现实中无法直接计算,因为我们不知道未来数据的真实分布。
-
实际做法 :由于无法直接优化测试误差,我们转而最小化在当前训练数据集上计算得到的平均训练误差(Average Training Error)。
-
理论依据 :这种替代做法的合理性基于一个核心假设------我们的训练数据是从与测试数据相同的未知分布中随机抽取的。根据大数定律,当训练数据量 NN 足够大时,训练误差就会成为测试误差的一个良好估计(Empirical Estimate)。
啥意思啊,批量SGD要遍历所有训练数据,那ATE也是要遍历所有训练数据集才能得到平均训练误差啊
-
平均训练误差(ATE)是一个"指标"(Metric)
- 它通常是在一个Epoch(也就是把所有数据跑完一遍)结束后,用来评估模型当前表现好坏的一个分数。
- 你不需要每走一步都算它。比如你训练了1000步,可能只需要在每100步算一次ATE来看看进度条。
- 它的代价是昂贵的,但因为不常算,所以不影响训练速度。
-
批量梯度下降(Batch GD)是一个"算法"(Algorithm)
- 这里的"遍历所有数据"是强制性的。
- 每一次 参数更新(哪怕只是迈出小小的一步),它都必须把几万、几百万条数据全部算一遍,求和,取平均,算出梯度,才能动一下。
- 它的代价是昂贵的,而且每一步都要付这个代价,所以训练极慢。


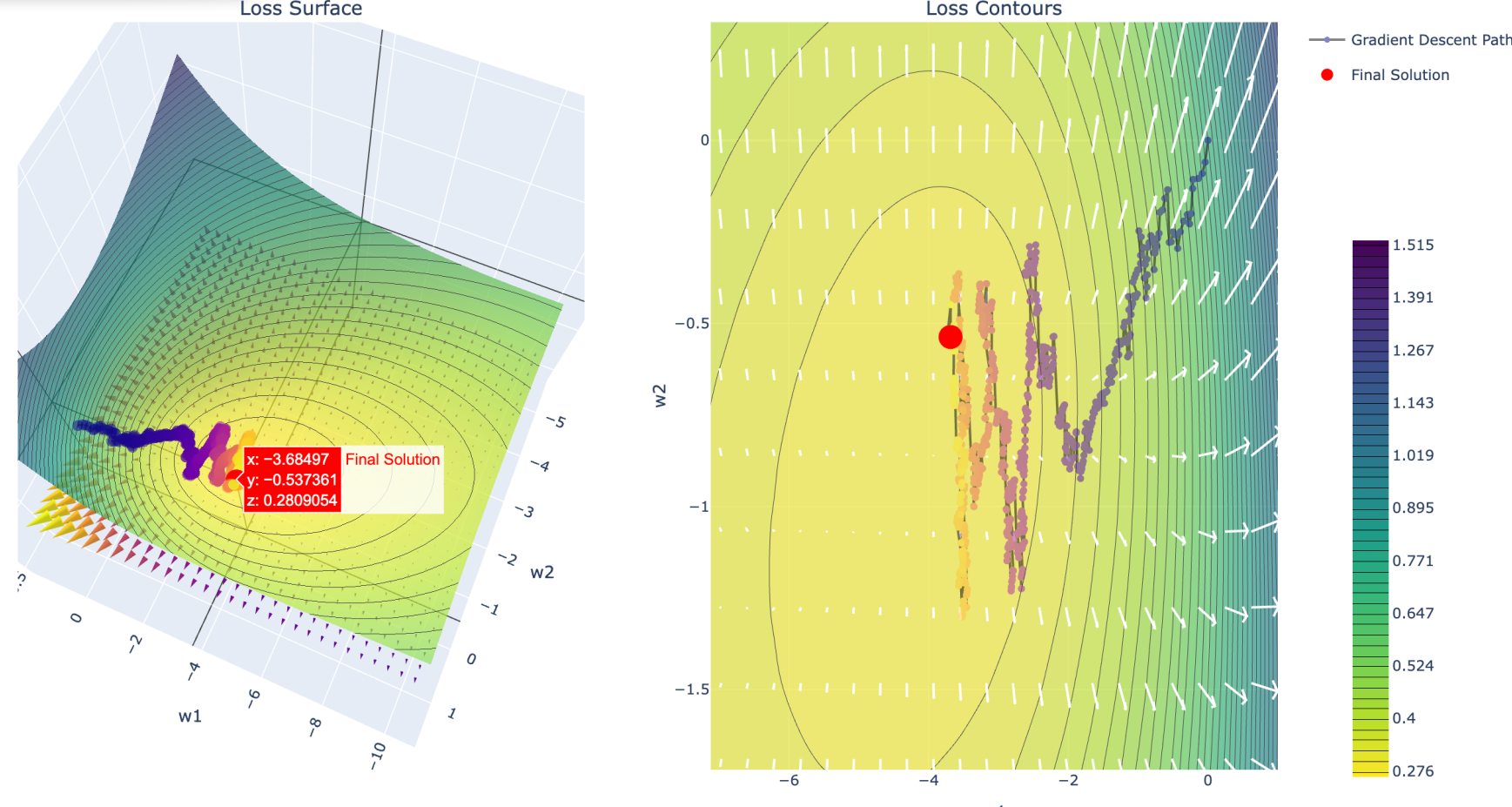
单点估计会震荡,批量估太慢了
批量训练


基函数的设计问题如何解决?
基函数是人为设计的,这是很不合理的。很多时候无法提前预判。
升维度能解决吗?
高维空间的稀疏问题
-
神经网络的做法(数据驱动):
- 神经网络最厉害的地方在于,它不预设基函数。
- 它把"寻找基函数"这个过程变成了一个学习任务。通过反向传播,网络自己调整参数,自动"长"出了一套最适合当前数据的基函数。
- 这就好比你不需要教孩子怎么识别猫,而是给他看成千上万张猫的照片,他的大脑自己就会构建出识别猫的神经元(基函数)。这就是PPT 3里说的"Neural networks = data-dependent bases"。
多层感知机
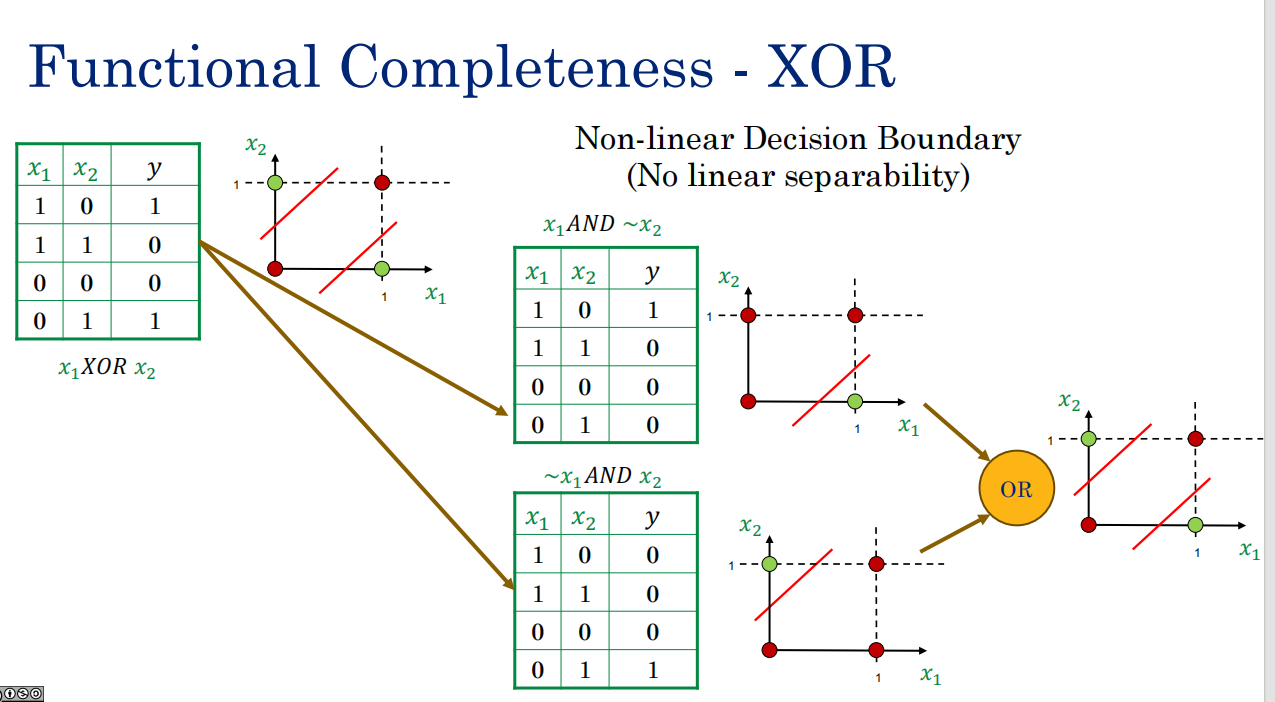
XOR无法单层表达,但是可以分别切割出左右,然后用新的一层OR来表达
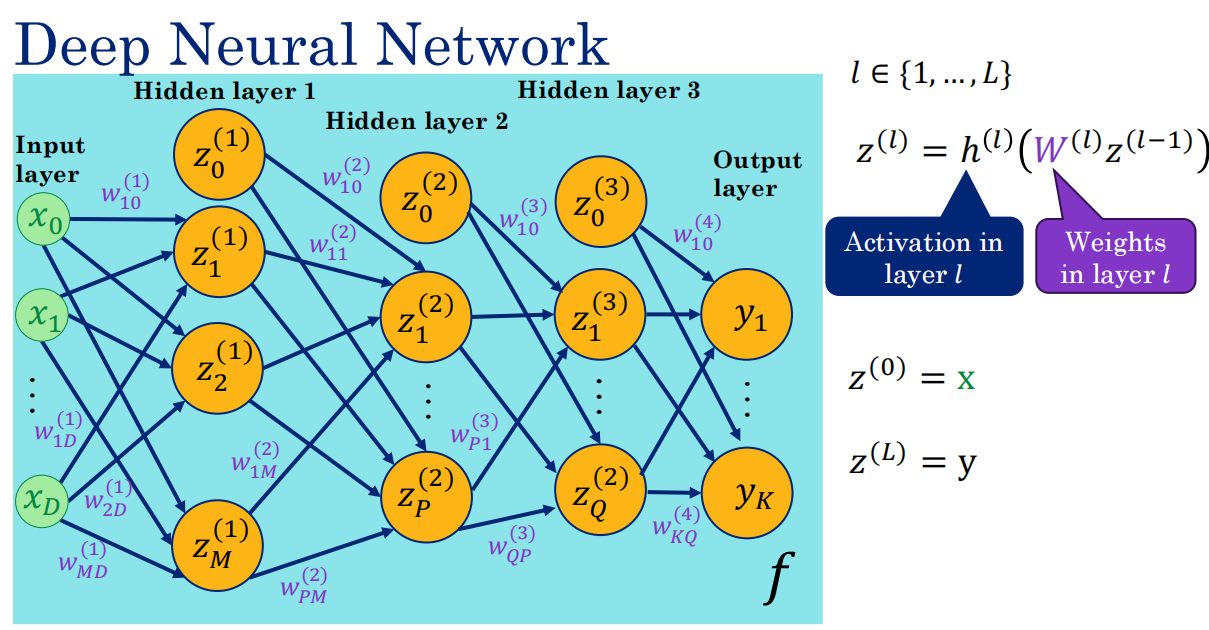
都可以写成嵌套+激活的形式
为什么让网络变深而不是变宽?
参数更小。
梯度消失 与 梯度爆炸
当输入极端时,正反馈、逆反馈
使用ReLu。
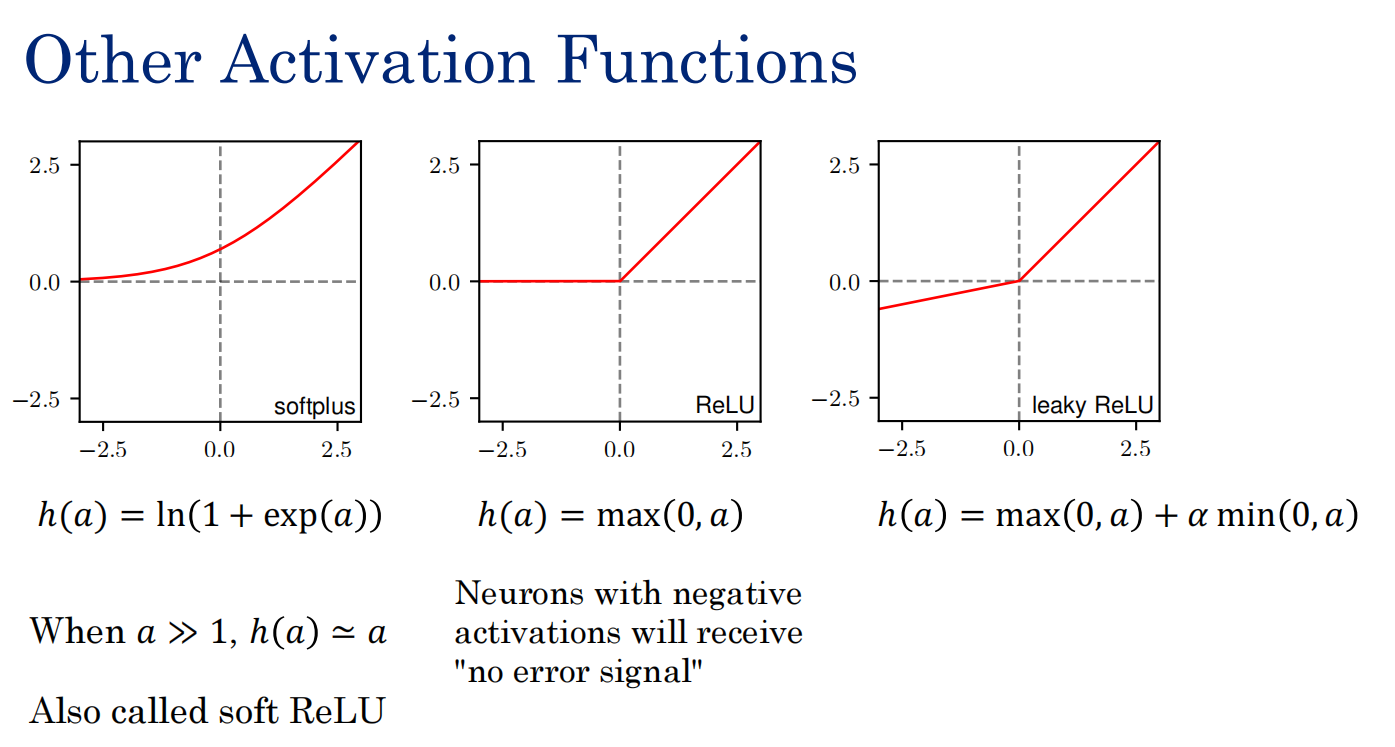
神经网络设计与正则化
甜点
最有利于神经网络学习的范围,梯度信息很明确,不会梯度消失或梯度爆炸
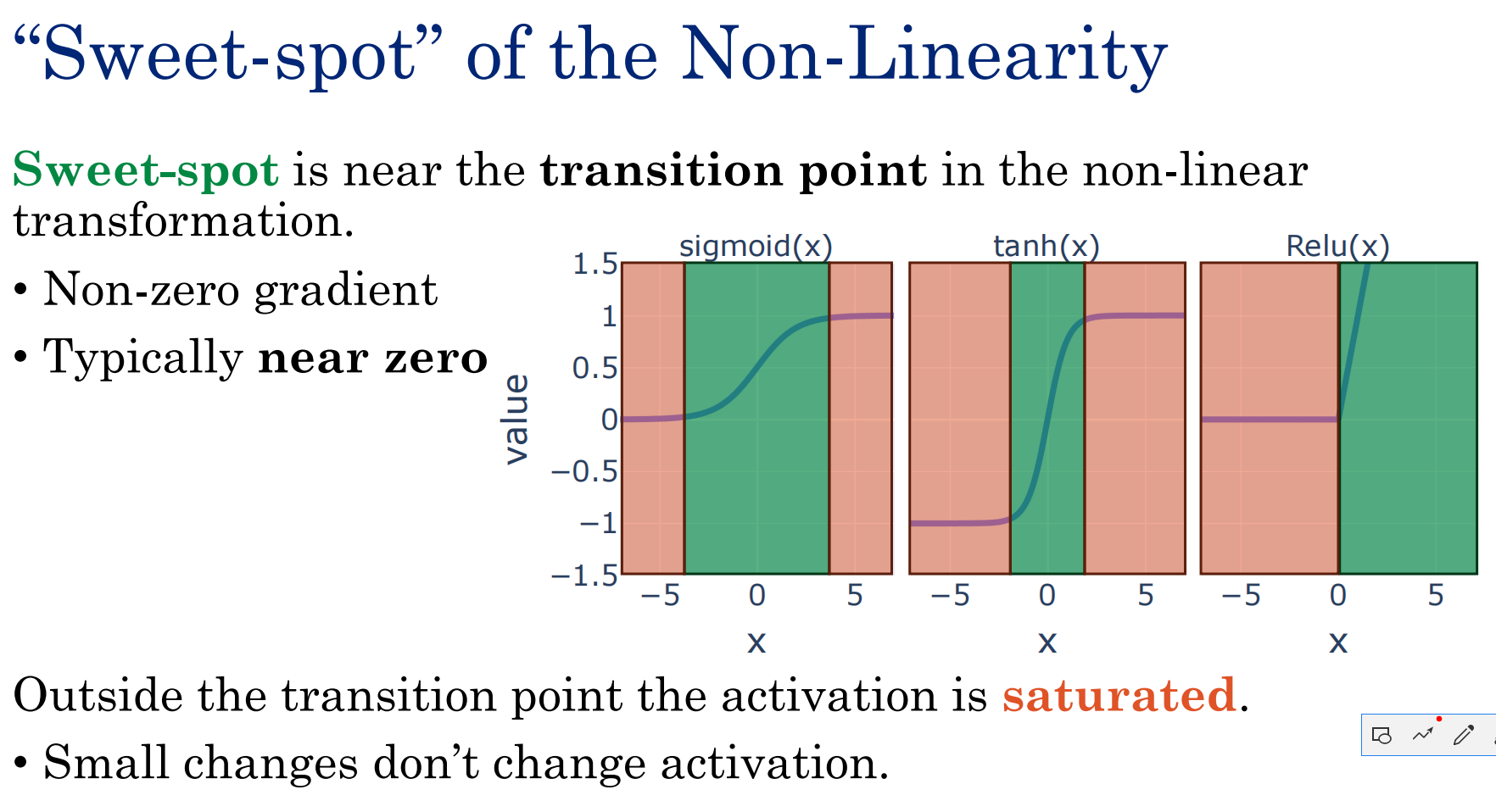
甜点之外被认为是饱和
饱和------激活函数接近于0
计算梯度
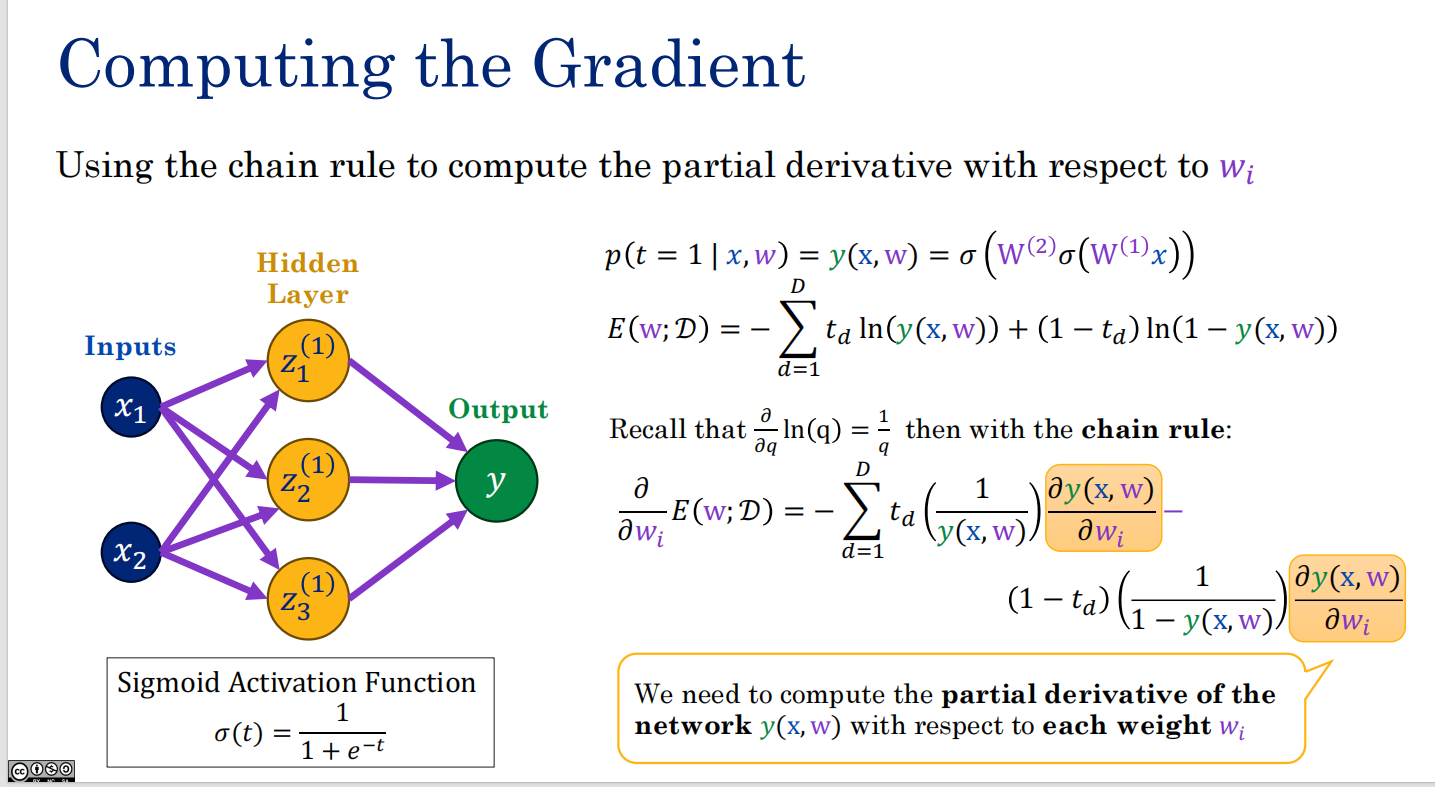
如何计算黄色这一块?
用数字微分
通用但是很贵

复杂度太高了


符号微分法

也不好用 于是考虑使用
自动微分

轨迹和偏导有关系,如果要求f对于v1的偏导,从·v3
第16章
深入分析神经系统
网络参数初始化
1. 为什么初始化如此重要?
-
非凸目标函数:神经网络的损失函数是非凸的。如果初始权重选得不好,可能会导致:
-
梯度消失/爆炸(无法训练)。
-
陷入局部极小值(收敛在很差的解上)。
-
收敛速度极慢。
-
2. 零初始化的陷阱(The Zero-Initialization Trap)
-
核心问题 :如果所有权重都初始化为 00,会导致**对称性(Symmetry)**问题。
-
所有隐藏层神经元的激活值相同。
-
反向传播时,所有权重的梯度也完全一样(即 ∂L∂wij(l)∂wij(l)∂L 对所有 jj 都一样)。
-
后果:所有神经元都在做完全相同的事情,网络失去了表达复杂函数的能力。
-
-
结论 :必须使用随机初始化来打破对称性。
3. 符号翻转与置换对称性(Symmetries in Networks)
-
置换对称性:如果 AA 层和 BB 层的节点互换顺序(配合对应的权重矩阵置换),网络输出完全一样。这是"相同神经元"的数学表现。
-
符号翻转对称性(针对 tanh/sigmoid):如果对一个神经元的所有输入权重取负,同时输出权重也取负,该神经元的最终输出不受影响。
-
张量空间:这意味着存在大量相互等效的初始化解,这增加了寻找"最佳"初始化方案的复杂度。
4. 随机初始化的目标:保持方差(Variance Preservation)
-
为了打破对称性,我们给权重加上微小的随机扰动。
-
关键在于:扰动不能太大(否则神经元饱和 ,梯度消失),也不能太小(否则梯度像消失了一样)。要让梯度在反向传播过程中保持稳定。
-
目标 :保持每一层输出(激活值)以及反向传播梯度的方差恒定。
5. 具体的初始化方法(Xavier & He)
讲义给出了两个最经典的数学推导和初始化公式:
A. He Initialization (针对 ReLU 激活函数)
-
背景:ReLU 会把负值置为 00,导致方差减半。
-
推导:为了补偿 ReLU 导致的方差损失,需要将初始化方差扩大一倍。
-
公式 :
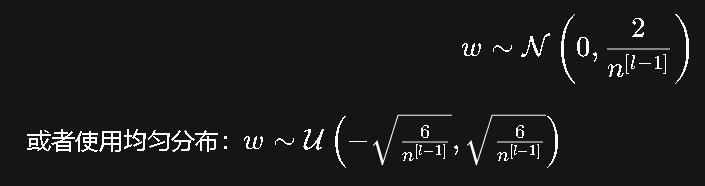
总结
这部分讲义旨在教会你:
-
不要全零初始化(会导致对称性崩溃)。
-
用随机初始化打破对称。
-
根据激活函数选择方法:ReLU 用 He 初始化,tanh/Sigmoid 用 Xavier/Glorot 初始化。
-
核心数学原理:保持输入输出方差一致,避免梯度消失或爆炸,从而加速并稳定网络的训练过程。
归一化
1. 为什么要归一化?(Data Normalization)
-
背景:输入数据的各个特征尺度(Scale)差异巨大(例如一个特征在0-1,另一个在0-1000),会导致损失函数的等高线呈狭长的椭圆状。
-
后果:梯度下降会反复震荡,收敛极其缓慢。
-
解决方案:对输入数据进行标准化(Standardization),使其变为均值为0、方差为1的分布。
2. 在神经网络内部进行归一化(Normalization in the Network)
-
不仅输入层需要归一化,隐藏层的激活值也需要。因为会落入饱和区
-
好处:
-
保证内部激活值尺度一致。
-
链式法则:梯度保持在稳定范围(避免梯度消失/爆炸)。
-
缓解内部协变量偏移(Internal Covariate Shift),允许使用更大的学习率。
-
3. Batch Normalization (Batch Norm)
-
定义 :在**一个 mini-batch(小批量)**内计算该层所有激活值的均值 μμ 和方差 σ2σ2。
-
应用点:可以应用在激活函数 a(l)a(l) 之后,或者前馈输入 z(l)z(l) 之上。
-
测试阶段(Inference) :因为测试时可能一次只输入一个样本,无法计算batch的均值。解决方法:使用训练过程中均值的**指数移动平均(Exponential Moving Average)**作为测试时的统计量。
4. Batch Normalization 的核心缺陷:难以并行化
-
这是讲义中通过多张幻灯片强调的重点。
-
问题 :如果在多块GPU(例如2块)上进行分布式训练,每个GPU处理该 batch 的一半数据。因为Batch Norm是计算整个 batch 的统计数据,GPU1 需要知道 GPU2 的数据均值和方差才能完成计算。
-
冲突:这导致 GPU 之间必须频繁通信同步,无法独立计算梯度,严重阻碍了并行训练的效率。
5. Layer Normalization (Layer Norm)
-
定义:为了解决 Batch Norm 的并行问题,引入了 Layer Norm。
-
计算方式 :与 Batch Norm 在 Batch 维度上计算不同,Layer Norm 是在 Layer(层)维度/特征维度 上计算均值和方差。
-
Batch Norm:横向看(同一个特征,不同样本)。
-
Layer Norm :纵向看(同一个样本,不同特征/神经元)。
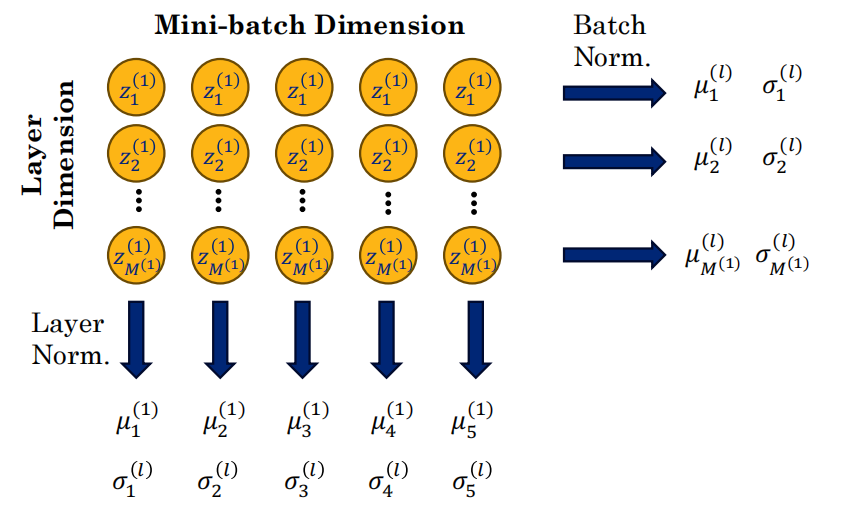
-
-
优势 :因为 Layer Norm 的计算只依赖当前的单个样本,完全不需要跨 GPU 通信 ,因此非常适合大规模并行训练(如大语言模型 LLM 中的 Transformer)。
-
应用:目前被广泛应用于自然语言处理(NLP)领域。
6. 细节对比与缩放问题
-
Batch vs Layer 对比图:直观展示了统计窗口的差异。
-
再缩放(Re-Scaling) :归一化后,如果单纯这样做,可能限制模型的表达能力(例如对于某些特征,我们希望维持其原有的方差幅度)。所以引入了可学习的缩放参数(Scale γγ)和移位参数(Shift ββ),这些参数通过梯度下降(SGD)来学习,让网络决定最终保留多少"原始特征"的特性。
7. PyTorch 中的代码实现
- 最后两页给出了 PyTorch 中 torch.nn 模块下
BatchNorm1d、BatchNorm2d、LayerNorm的具体调用方式,帮助从理论过渡到实操。
总结
这部分讲的是:
-
Input Norm:让初始数据好算。
-
Batch Norm :让中间层梯度稳定,但在多GPU并行时有问题。
-
Layer Norm :为了解决并行问题诞生,在Transformer和LLM中应用广泛 。核心区别在于计算统计量的维度不同(计算的是 Batch 的统计量还是 Layer 的统计量)。
Inductive Biases
1. 为什么需要"归纳偏置"?(Learning Requires Inductive Biases)
-
无免费午餐定理(No Free Lunch Theorem):没有任何一种算法在所有可能的问题上都是最好的。
-
结论 :算法必须利用归纳偏置(即对问题本质的假设或先验知识)才能表现良好。
-
如何在神经网络中注入归纳偏置?
-
预处理(Pre-processing):转换数据特征(如归一化、尺度调整)。
-
正则化目标(Regularized objectives):惩罚不希望出现的模型属性(例如权重过大)。
-
数据增强(Data augmentation):通过随机变换(如旋转图像)来增加训练样本。
-
架构设计(Architecture design) :例如使用**卷积层(Convolution)**来强制实现平移不变性。
-
2. 特征工程(Feature Engineering)
-
定义:手动构造特征的过程。
-
传统例子:TF-IDF(文本)、HOG(计算机视觉)、MFCC(语音识别)。
-
深度学习观点 :现代深度网络使用大量神经元自动学习特征,但在模型设计上仍要具有特征不变的归纳偏置。
3. 权重衰减(Weight Decay Regularization)

4. 学习曲线与早停(Early Stopping)
-
观察学习曲线:
-
训练误差:随着训练轮数增加不断下降。
-
验证误差 :先下降,但经过某个点后会开始上升(过拟合,Overfitting)。
-
-
早停策略(Early Stopping):
- 当验证误差停止下降或开始上升时,停止训练,并回退到验证误差最小的那个模型检查点(Checkpoint)。
5. 为什么早停也是一种权重衰减?
这是讲义最后一部分的核心洞察:
-
现象:模型通常从小权重值开始初始化。如果使用早停,意味着我们在模型"还没机会把权重扩得过大"时就停止了训练。
-
数学洞察:梯度下降过程中,权重更新与正则化项的几何结构存在关联。限制训练步数,在数学上等效于限制了权重向量的模长(Magnitude)。
-
结论 :早停是一种隐式的权重衰减(或 L2L2 正则化)。
总结
这部分内容是在讨论如何防止过拟合 和如何构建有效的机器学习系统:
-
建立假设(归纳偏置):你必须对数据有先验知识,并通过预处理、数据增强或架构(如CNN)将其引入模型。
-
正则化(权重衰减):通过数学方法惩罚大的权重,防止模型过于依赖某些特定特征。
-
控制训练时长(早停):当模型开始死记硬背训练数据(验证误差上升)时及时停止,这在数学上也是一种正则化手段。
这是机器学习从"理论推导"到"工程实现"非常关键的一课。
Double Descent on the Bias-Variance Tradeoff
这张图片展示的是一套关于**"双重下降"(Double Descent)** 现象的教学讲义。它的核心内容是挑战传统的"偏差-方差权衡"理论,揭示深度神经网络在过参数化后出现的独特泛化行为。
以下是这一部分内容的详细解读:
1. 传统的偏差-方差权衡(The Bias Variance Tradeoff Revisited)
-
第一张图展示的是经典理论:
-
随着模型复杂度增加,**训练误差(Training Error)**持续下降。
-
偏差(Bias) 下降,**方差(Variance)**上升。
-
两者的总和构成测试误差(Test Error) 。经典的 U 型曲线告诉我们:模型太简单会欠拟合(高偏差),模型太复杂会过拟合(高方差)。最佳模型复杂度位于 U 型曲线的底部(Interpolation Threshold)。
-
2. 双重下降(Double Descent)
-
第二张图展示了新发现(针对深度神经网络):
-
与传统理论不同,当模型复杂度继续增加,跨越过**"插值阈值"(Interpolation Threshold,即模型刚好能完美拟合训练数据)** 后,测试误差并没有继续上升。
-
测试误差会再次下降 ,形成一个**"双重下降"**的曲线。
-
左区(Under-parameterised Regime):典型的欠参数化区域,符合传统偏差-方差理论。
-
右区(Over-parameterised Regime):过参数化区域。模型变得非常复杂,但测试误差反而降低了。这表明深度网络似乎具有"自我正则化(self-regularize)"的能力(研究者推测这得益于 SGD 优化器的隐式正则化)。
-
3. 双重下降在实际中的应用(Double Descent in Practice)
-
第三张图展示了真实实验数据(源自 Nakkiran et al., ICLR'20):
-
左下角图:展示了 ResNet18 在不同宽度参数下的表现。可以看到在插值阈值处有一个"驼峰"(测试误差激增),但随后随着模型变得更大(更宽),测试误差稳定下降。
-
右上角热力图:展示了 Epochs(训练轮数)与模型宽度之间的关系。颜色越深代表误差越低。
-
右下角折线图:展示了在不同模型宽度下,训练轮数与测试误差的关系。
-
-
关键提示(黄色框):"对于足够大的模型,早停(Early Stopping)可能会降低泛化能力。"
- 这是一个反直觉的点。在传统模型中,我们总是推荐早停来防止过拟合;但在这种"双重下降"的过参数化区域,如果你想获得最低的最终测试误差,可能需要继续训练模型直到它收敛,而不是早早停止。
总结:这部分的核心知识点
这就是深度学习领域关于**"过参数化有益"**的经典发现:
-
旧观念:模型越复杂越容易过拟合。
-
新发现(Double Descent) :在深度网络中,模型复杂度跨越"插值阈值"后,越复杂的模型(参数越多)通常泛化能力越好。
-
实际操作建议 :如果你训练的是一个非常庞大的模型 (如大语言模型、大型ResNet),你可能不需要过早早停,延长训练时间反而可能让测试误差降到更低的第二谷底。
模型平均与集成学习
1. 模型集成的基础(Ensembles of Models / Experts)
本质是减少方差,代表再不同的数据集输出都很稳定。

2. 专家混合(Mixture of Experts, MoE)

3. 构建多个专家模型(Constructing Multiple Experts)

4. Bagging (Bootstrap Aggregation) ------ 具体实现方法

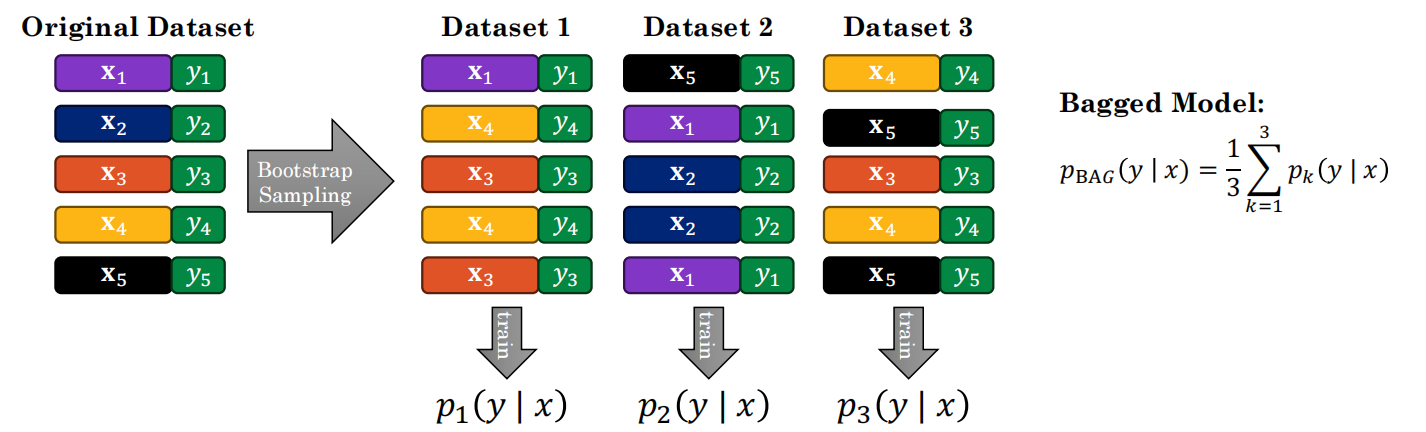
随机失活Dropout
使得部分神经元失效 每个神经元有1-p的概率保留自己 q的概率死亡。
这张图片展示的是关于**Dropout(随机失活)**技术的教学讲义。它的核心内容是解释 Dropout 的工作原理、数学机制以及其在深度学习中的特殊作用。
以下是详细梳理:
1. Dropout 的基本原理(Dropout Regularization)

2. Dropout 的归纳偏置(Inductive Bias)
-
思考题:什么是 Dropout 引入的归纳偏置?
-
隐含假设 :模型不应依赖于任何一个特定的神经元(特征)。这迫使网络学习鲁棒性特征,因为任何一个神经元都有可能在训练中被随机移除。
3. Dropout 与模型平均(Model Averaging)

4. PyTorch 中的实现

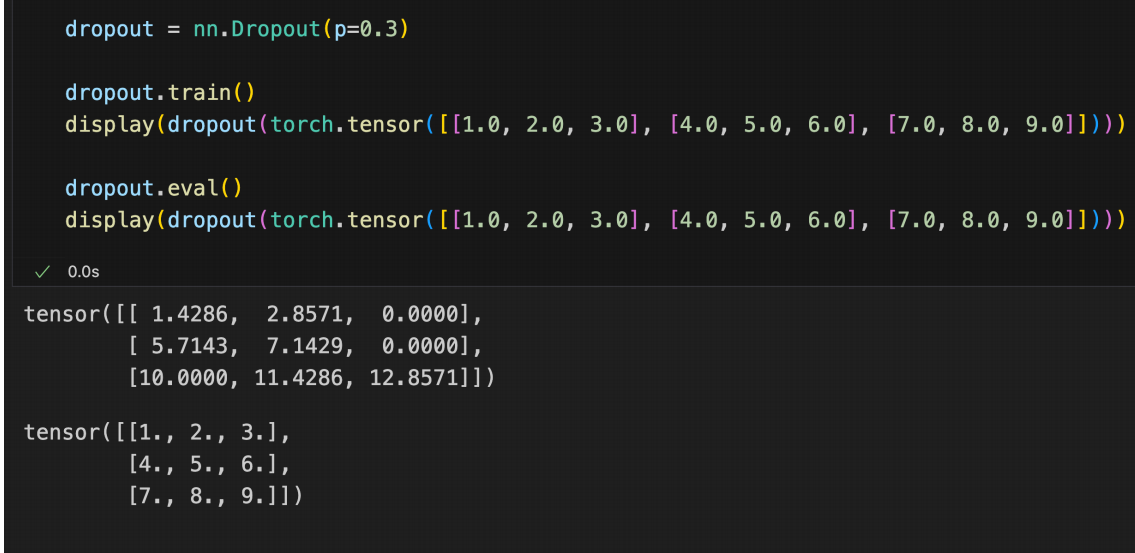
总结
这部分内容的核心在于:
-
Dropout 是一种正则化手段,通过随机丢弃来防止神经元之间复杂的共适应。
-
Dropout 是一种隐式的模型平均:训练时采样 2^N 个子网络,测试时等同于对所有子网络进行平均。
-
技术细节:训练时缩放值或测试时缩放值的处理,是保证期望输出一致的关键。
-
它是深度学习框架(如 PyTorch)中的标准组件。
残差网络
这张图片展示的是关于**残差网络(Residual Networks, ResNets)**的教学讲义。它的核心内容是解释为什么深层网络难以训练,以及残差连接是如何解决这些问题的。
以下是详细梳理:
1. 深层网络的挑战:梯度消失与破碎(Vanishing & Shattered Gradients)
-
问题:训练几百层的神经网络非常困难。
-
梯度消失:误差信号(梯度)在反向传播经过多层时,经过连续的乘法运算后会变得极弱,导致前面层的参数几乎无法更新。
-
梯度破碎:很多非线性层的堆叠导致损失曲面变得极其崎岖不平。
-
-
需求:需要一种方法将"较低层"直接连接到"预测结果"和"损失函数",让梯度能更顺畅地流回底层。
2. 残差网络(Residual Networks)

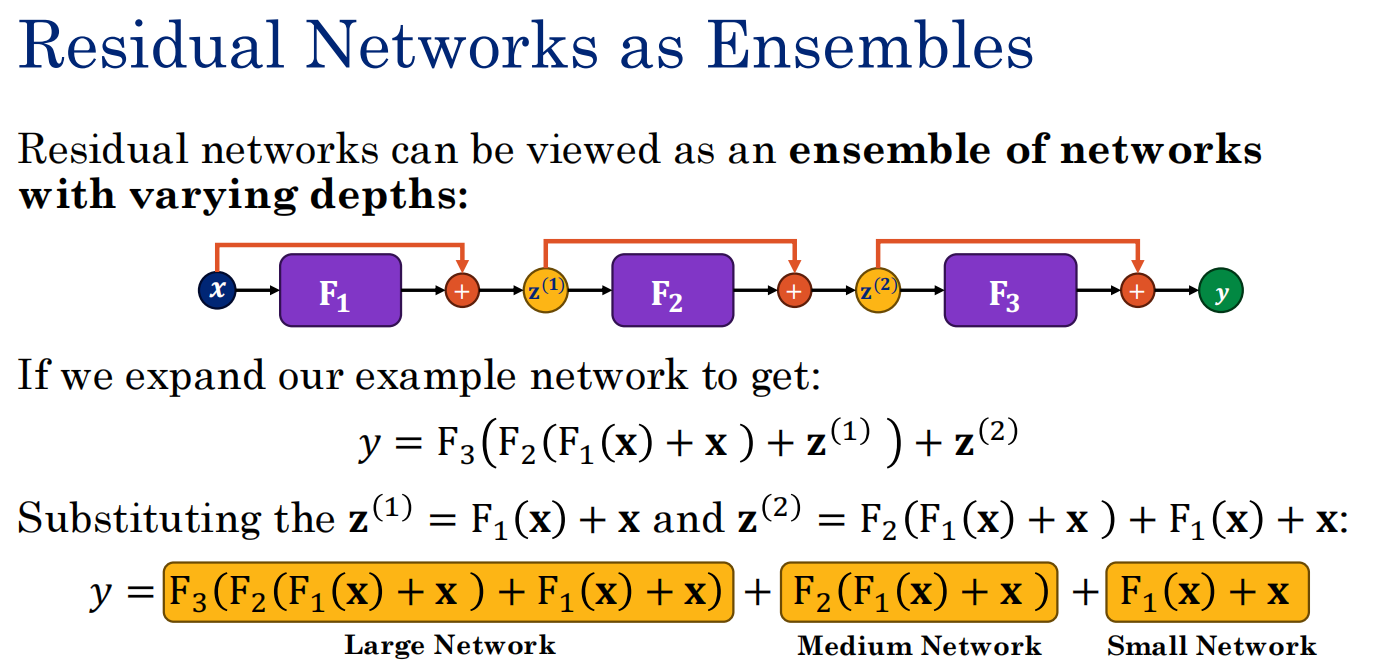
3. 残差网络作为集成模型(ResNets as Ensembles)

4. 展开的残差网络图(Expanding the Residual Network Graph)
-
直观展示:将公式的展开用图形表示出来。
-
核心洞察:
-
相比普通的前馈神经网络(梯度只能沿着一条单行道反向传播),残差网络的这种"并联结构"允许梯度信号通过多条不同长度的路径直接流回输入层。
-
绿色箭头表示直接的梯度信号路径。
-
这使得梯度在反向传播时,无需穿越所有的非线性层,从而成功解决了梯度消失问题。
-
总结
这部分内容的核心在于讲述ResNet的设计哲学:
-
解决问题:解决深层网络训练难、梯度消失的问题。
-
解决方法:引入残差连接(x+F(x)x+F(x))。
-
深刻理解 :残差连接在数学上解耦了深度,使得深层网络变成了一堆浅层网络的集成。这解释了为什么即使网络很深,梯度依然可以顺畅传播,以及为什么 ResNet 能够有效训练并取得出色的性能。
第十七章
-
深度学习基石 :深度学习本质上是特征变换(Feature Transformation),将原始数据(如像素)一层层转换为更抽象的表达。
-
架构演进 :幻灯片提到了当前最主流的架构:Transformer (用于NLP、视觉、多模态)和 ResNet(残差连接)。
嵌入向量:中间层向量
为了适应一个更大的网络就要重新训练,很麻烦。
CNN具有平移不变性:
所以引入CNN卷积神经网络,将权重绑定在卷积核上,扫描所有的位置,这样无论特征在哪里,都可以识别到。而且这个特征在全图都共享这个权重。
感受野

如何联系上下文?使用平均池化,加上其他上下文的平均值。
但是这样有个问题,如果给其他词分配一样的平均权重,则会出现:
good和bad的表意是相等的,也不知道谁更重要。

于是考虑attention注意力机制。
Attention
就是把和当前词有强关联的词拿过来。
不同词有不同权重,综合为1。

如何去计算α和weight呢?
使用内积搜索
引入键值,建立一个<Query,Key>的内积,得到一个分值。
为每个key分配到
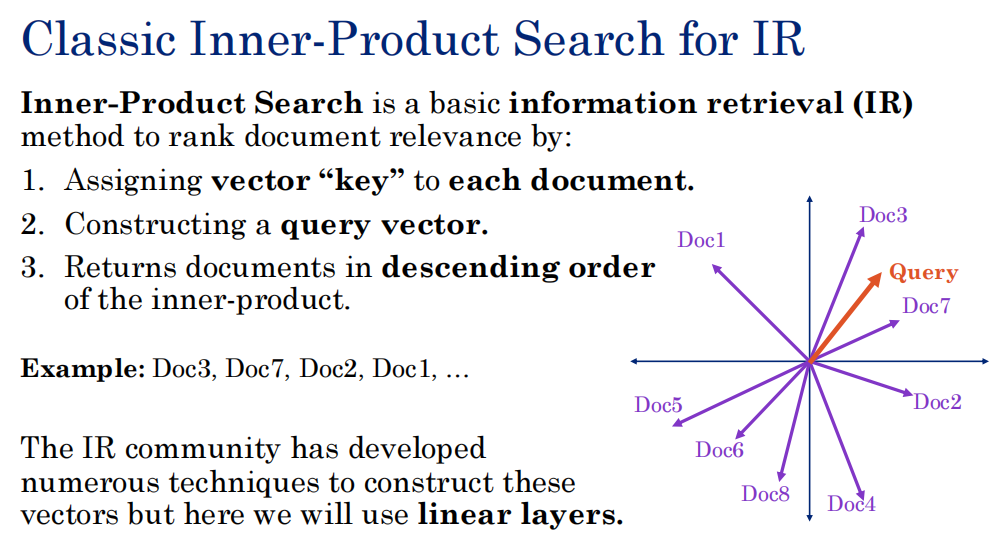
这张图讲的是信息检索(IR)中的内积搜索 ,和 Transformer 里的 QKV(Query-Key-Value) 机制有直接关系。
1. 图中意思
-
每个文档(Doc1~Doc7)被表示成一个向量 ,叫 key(图中的"vector key")。
-
用户的查询也被表示成一个向量 ,叫 query(图中的"Query"向量)。
-
计算 query 与每个文档 key 的内积(点积),内积越大表示相关性越高。
-
按内积从大到小排序返回文档(比如例子里 Doc3 最相关,然后是 Doc7...)。
这就完成了一次"内积搜索",本质是用向量相似度来排序。
2. QKV 关系是什么?
在 Transformer 的 自注意力 或 交叉注意力 里:
-
Q(Query):当前要查询的向量(图中就是 Query)
-
K(Key):被比较的向量(图中每个文档的 key)
-
V(Value):与 K 配对的、真正要提取或加权的内容向量
具体关系:
-
计算 Q 与每个 K 的内积(或缩放点积) → 得到一个分数。
-
这些分数通常经过 softmax → 变成权重。
-
用这些权重去加权求和 V,得到最终的输出。
📌 在图中只做了第 1 步(内积排序),没有展示 V 和加权求和。但排序本身用的就是 Q·K 的内积。
3. 这种 QKV 的"来源"是什么?
-
最早来自信息检索:用户输入 Query(查询词),系统从文档集合里匹配 Key(文档关键词或向量),返回最相关的文档。这里的"相关"就可以用内积度量。
-
2017 年《Attention Is All You Need》 把这种思想引入神经网络,并增加了 Value(要提取的信息)。内积变成了注意力分数,Value 则用来聚合上下文。
-
所以 Transformer 的 QKV 本质上是可微分的、带学习的向量检索过程。
一句话总结
图中展示的就是 Q·K 内积排序 --- 这是 Transformer 注意力机制中最核心的相似度计算步骤。Q 来自查询,K 来自文档(或序列中的其他位置),内积大表示相关。Value 是为了"把相关的内容取出来",图中没有画,但完整 Attention 里会接着用内积权重去加权 Value。
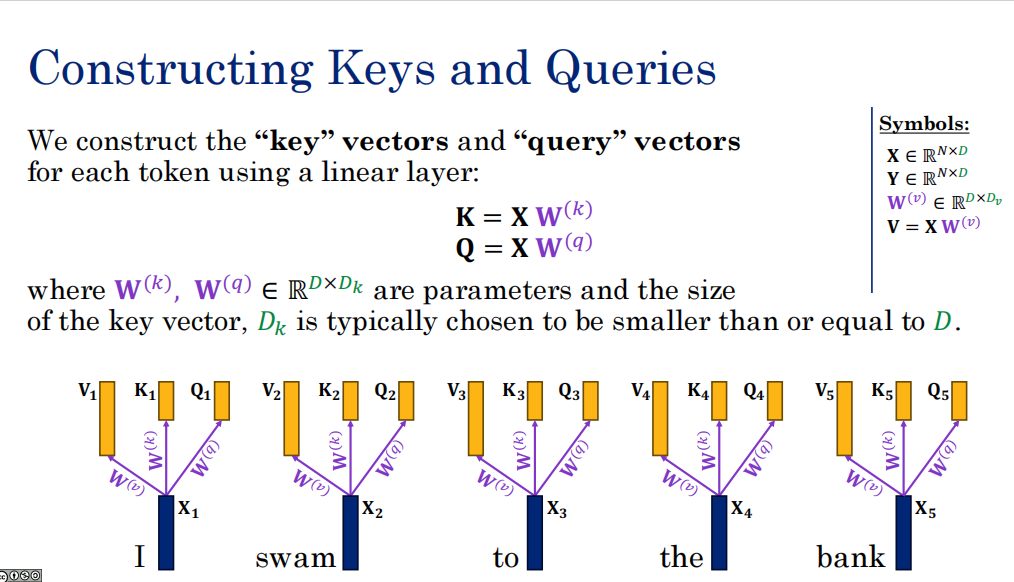
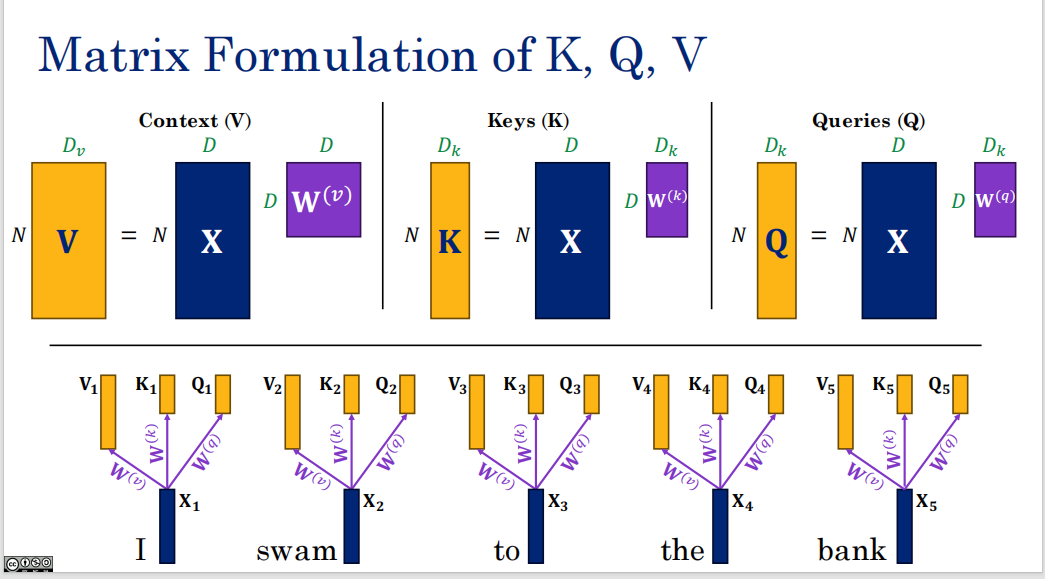
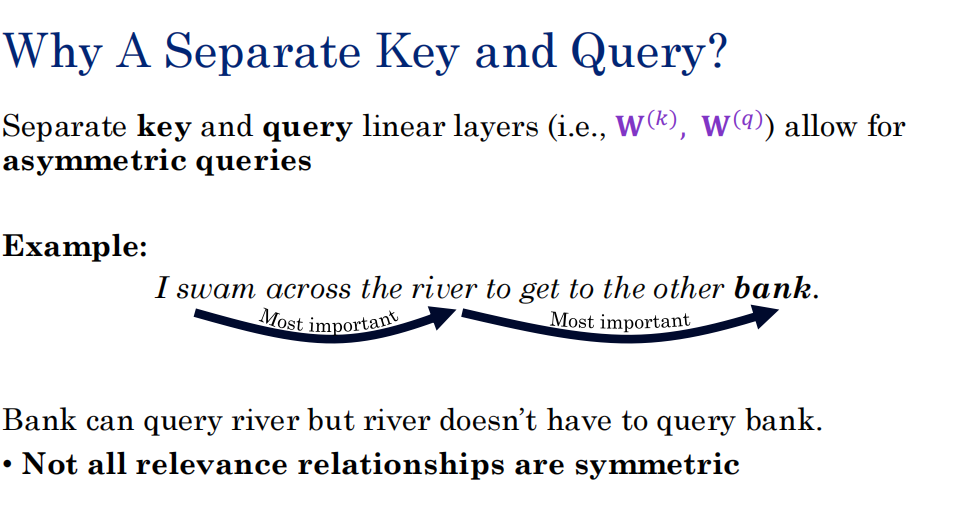
为什么要QKV,要把QK分开,因为网络具有不对称性,bank关注river,而river关注swam,而不是bank,每个人要有自己的关注度。
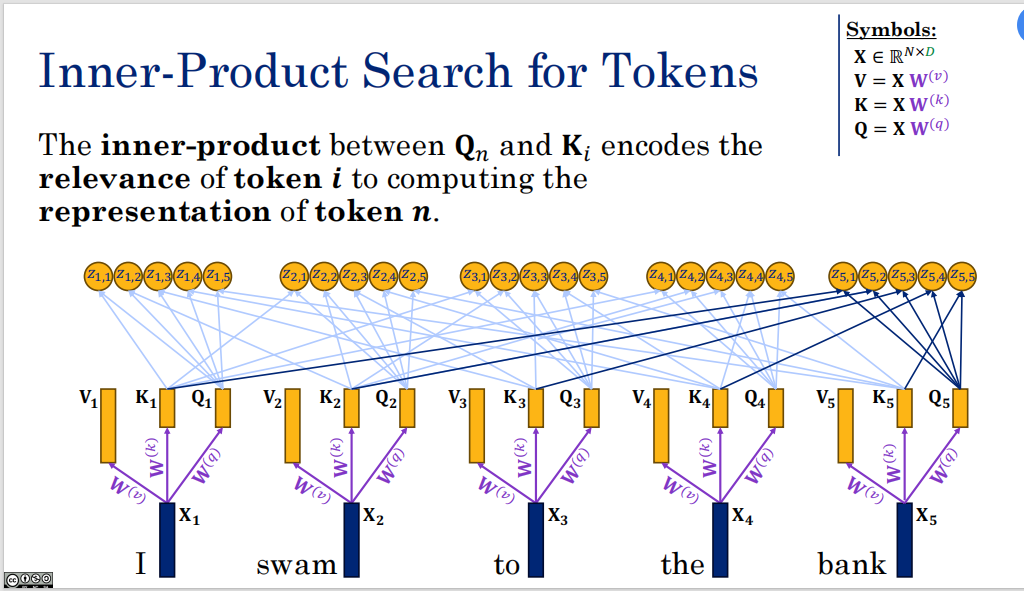
图片中的 Z 就是注意力机制(Transformer核心模块)中的 内积矩阵 ,它也被称为 注意力分数矩阵(Attention Scores) 或 未归一化前的 Logits。
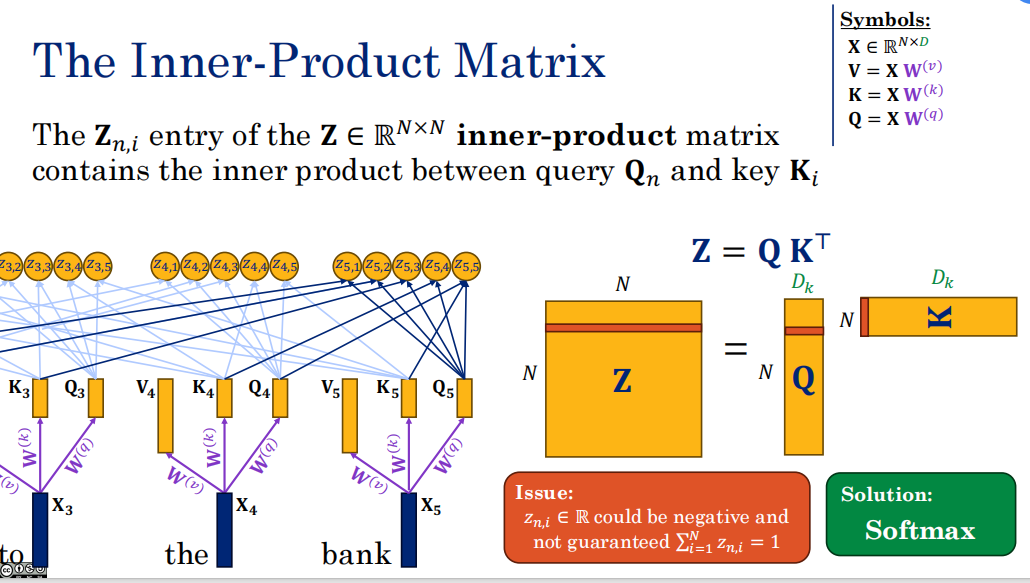
要归一化为α
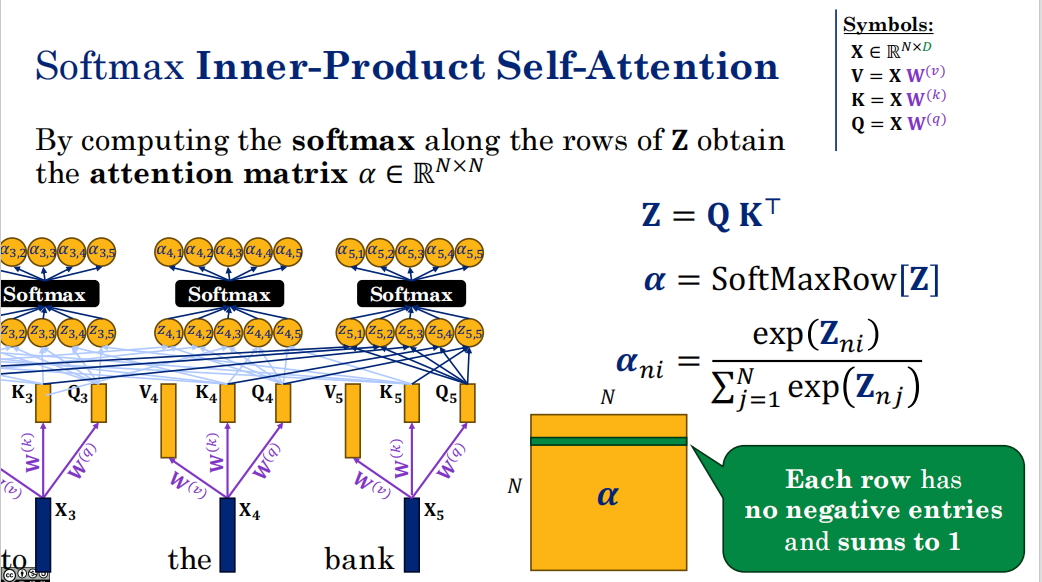
为了防止Z在softmax过大或过下,我们引入scaing
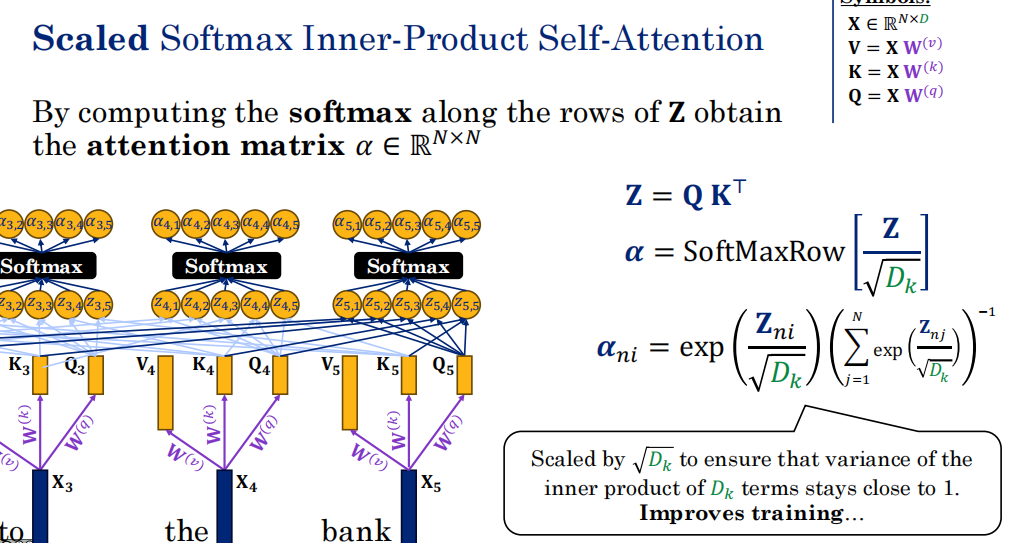
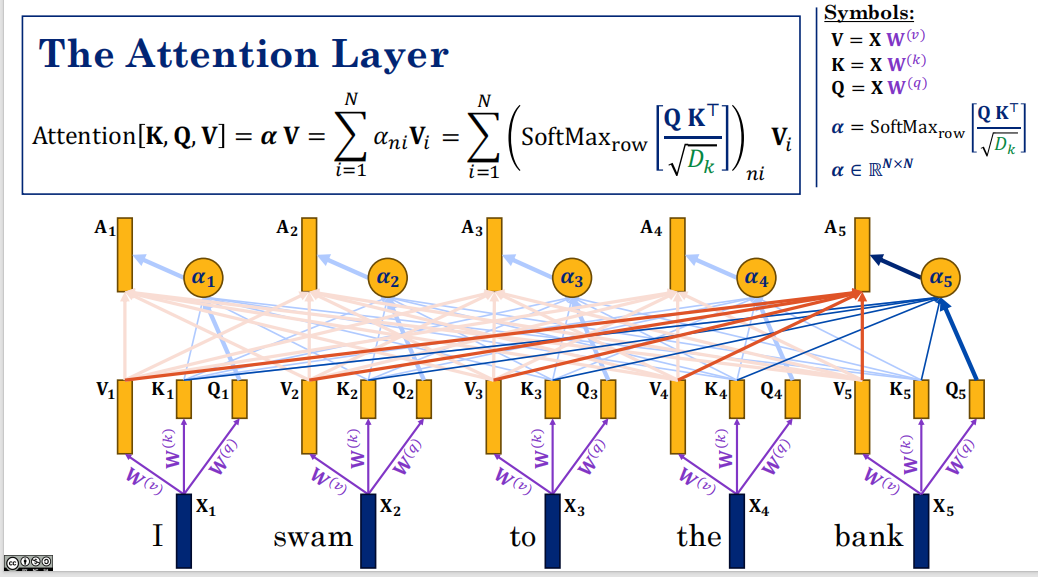
每一条红线和每一条蓝线相乘相加就是context。
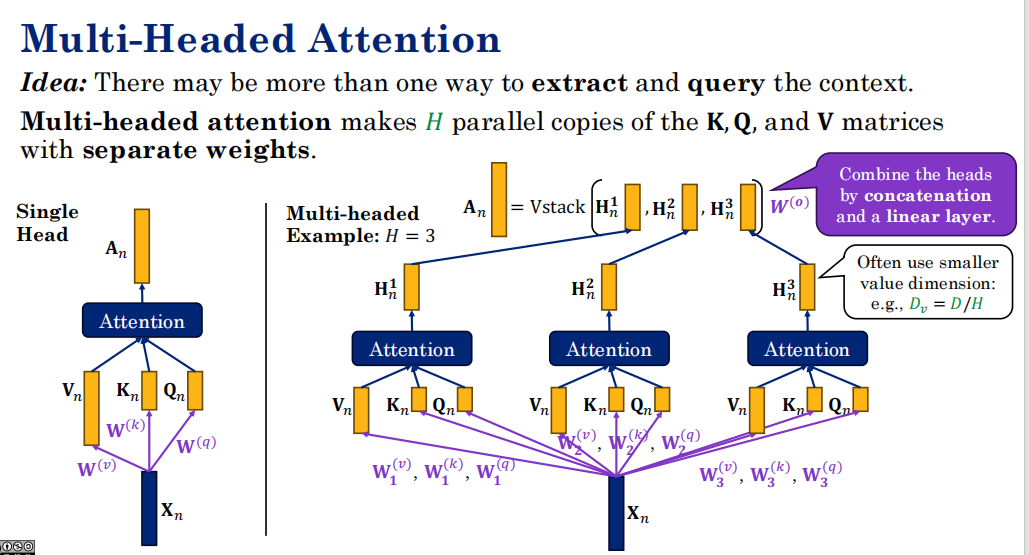
多头注意力
"提取和查询上下文的方式可能不止一种。"
有人注重动作关系,有人注重时间关系
单头注意力想象成**"用一个固定视角的摄像头去拍句子"** 。
而多头注意力,就像是**"在这个句子上架了 HH 个不同的摄像机,每个摄像机有不同的滤镜、不同的焦距、甚至不同的观看角度"**。
这一页PPT主要表达了Transformer模型的基本构建单元(Transformer Layer)的架构原理和设计动机。
它通过左文右图的结合,重点阐述了以下4个核心要点:
1. 基础结构:自注意力 + MLP(多层感知机)
PPT明确指出,一个Transformer层由两部分组成:多头自注意力机制 和逐词(Token-level)的前馈神经网络(通常是2层的MLP)。右图清晰地展示了从输入 XnXn 开始,先经过多头自注意力,再经过MLP的流程。
2. 💡 核心疑问:为什么需要 MLP?(PPT中心理的重点)
这也是PPT中间用蓝色字体提问的"Why is the MLP needed?"。
-
原因 :自注意力层的输出本质上是输入 XX 的线性组合。虽然注意力权重 αα 是非线性的,但它只是对输入特征的线性变换进行加权求和。
-
MLP的作用 :在自注意力处理后加入MLP,相当于引入了非线性激活函数(如ReLU、GELU等),能够让模型学习到更复杂、更抽象的特征,赋予模型更强的表达能力,且每个token都可以单独进行处理。
3. 训练优化:残差连接和层归一化(Layer Norm)
为了防止模型过深导致训练困难和梯度消失,必须使用这两个技巧。
-
残差连接(图中黄色的"+"号):将输入直接与输出相加,保留原始信息。
-
层归一化:在每一层处理后对数据进行归一化,让训练更稳定。
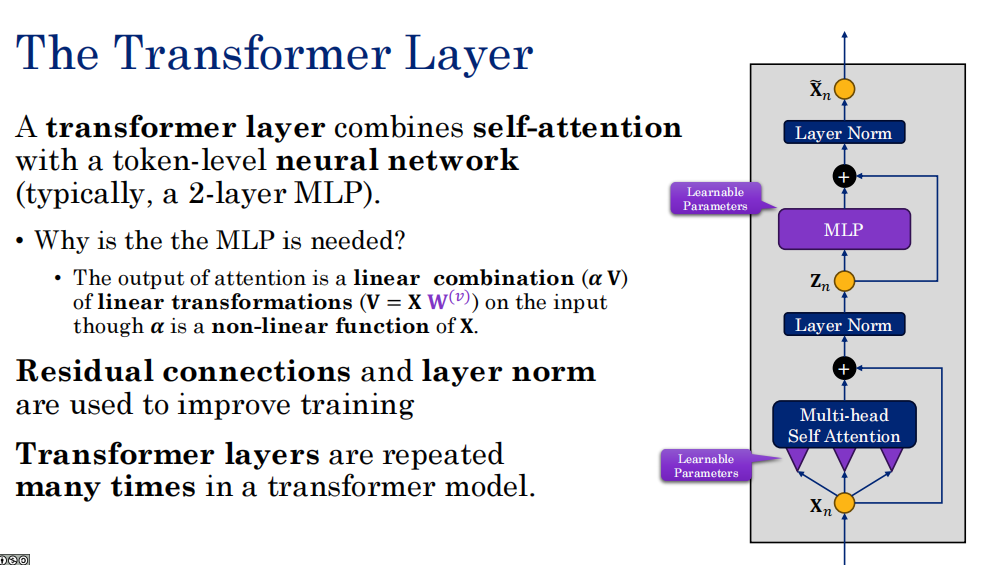
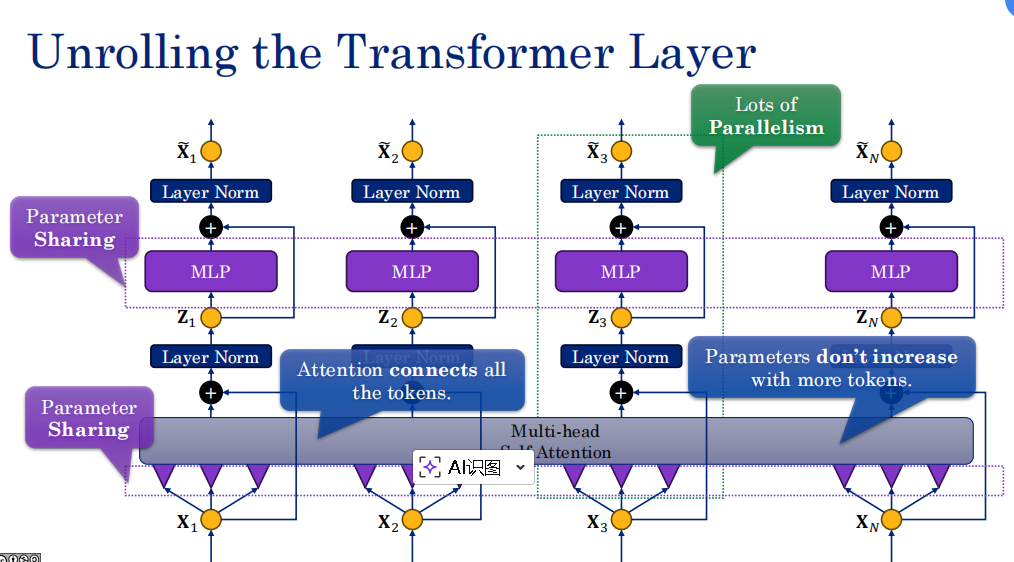
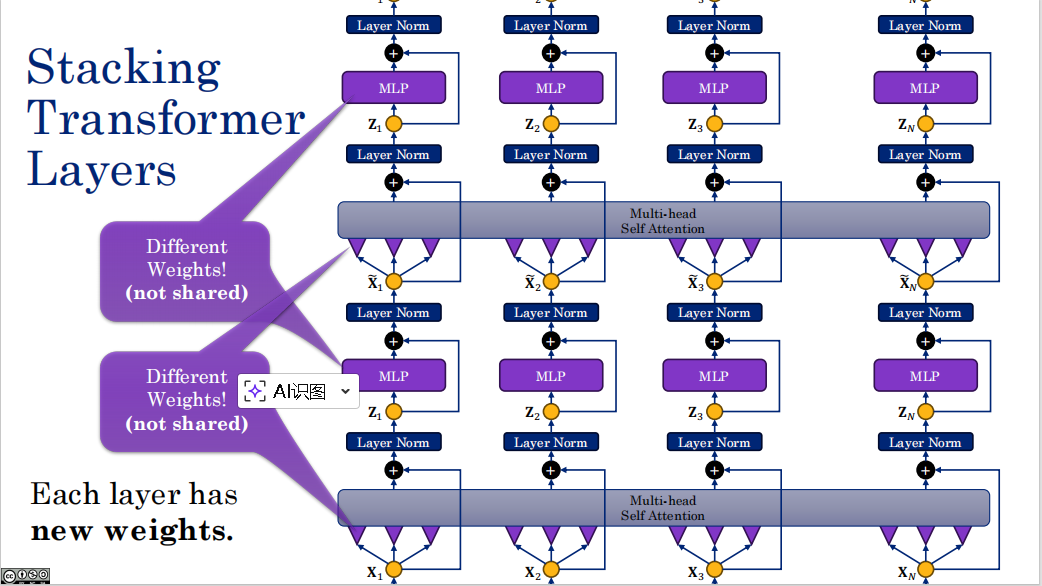
4. 深层构造:层级堆叠
PPT最下方的一行字很关键:"Transformer layers are repeated many times..."(Transformer层会被重复很多次)。这意味着,一个完整的Transformer模型(如BERT、GPT)就是由许多个这种"自注意力+MLP+残差+归一化"的模块串联堆叠而成的。层数越深,模型能建模的语义复杂度和抽象程度就越高。
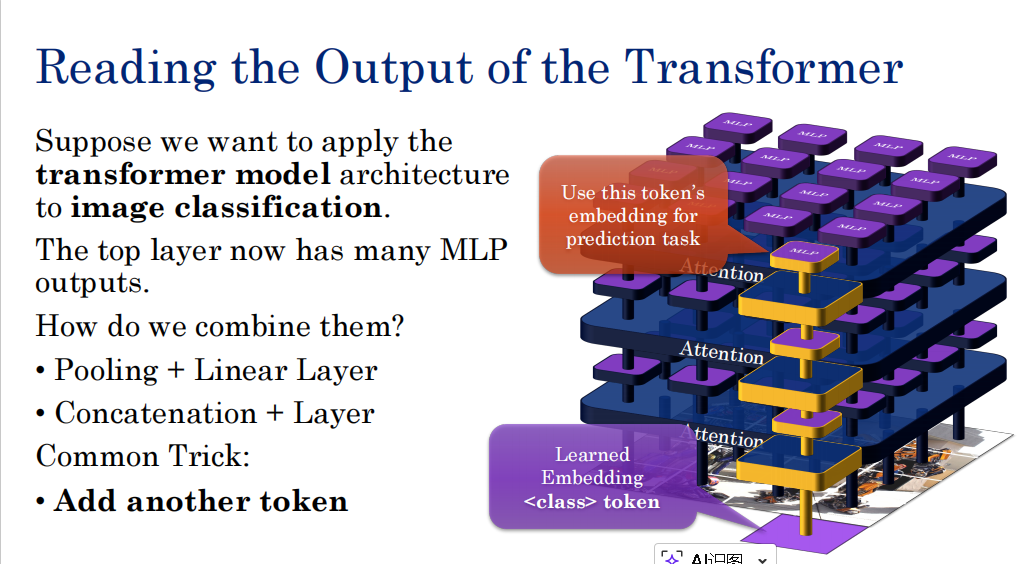
如何选取输出?输出很多,如何用?
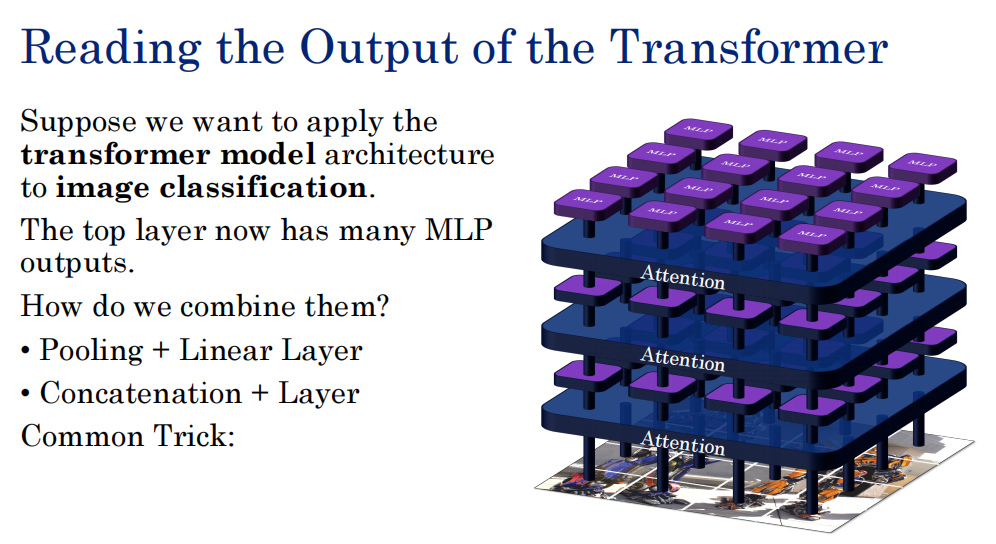
我们引入一个额外token,每一层和其他一起参与运算,去融合其他token的语义,最后其输出就是语义。
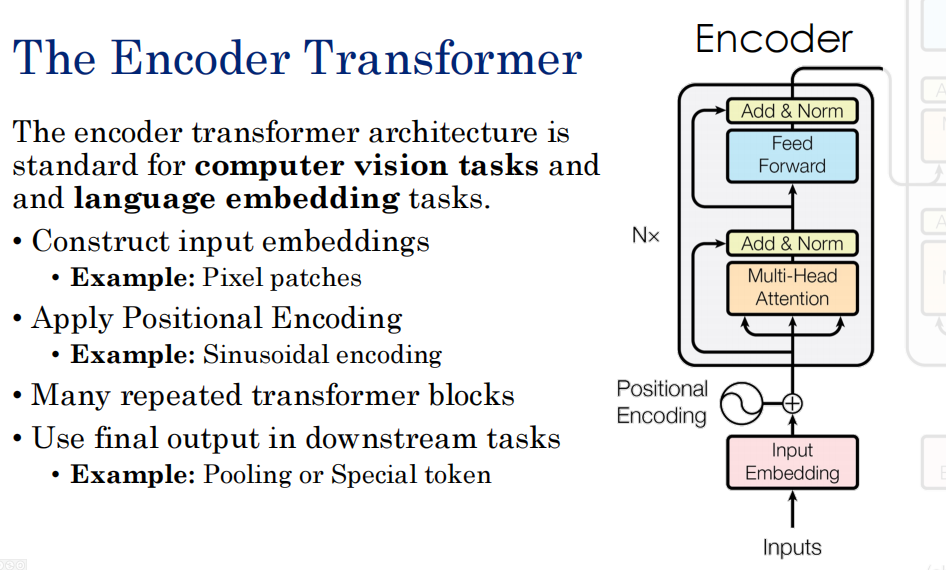
顺序问题 位置编码
由于QK是组合排列的,是没有顺序之分的。导致无法区分词的位置,表达语义有误

我们直接在xn上加一个位置编码rn。
为什么不把V改为两维的?计算复杂
加不会有问题吗?是正交的,可以解耦。

如何去构建rn 构建位置编码
唯一性 位置不能一致
有界性 和原有xn尺度相似,不能1+10000
能表达相对距离
支持任何长度 不管输入多少都能理解

GPT将rn变成一个可学习的参数,在训练中优化。
但是要求提前知道段落最长有多少token。相对位置是难以表达的。

正弦位置编码
类似背包问题的二进制优化,设定不同的01码从小到大表达词频率

相对位置编码
这一页幻灯片讲的是 Transformer中位置编码(特别是正余弦位置编码)的一个非常巧妙且重要的数学性质。
简单来说,它的核心含义是:这种位置编码能够模型化"相对位置关系",即让模型知道"B在A的后面多远"。
具体来说,这张图里包含了三个关键点:
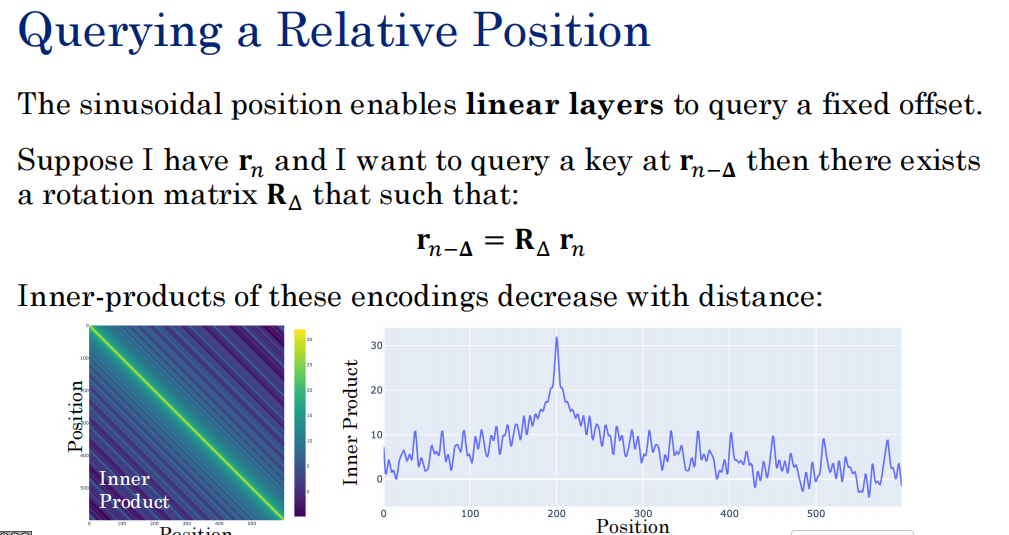
1. 核心公式:用旋转矩阵计算相对位置
-
图中提到:如果你有位置 nn 的编码 rnrn,想查询位置 n−Δn−Δ(也就是往前推 ΔΔ 步)的编码 rn−Δrn−Δ。
-
存在一个旋转矩阵 RΔRΔ,可以通过公式 rn−Δ=RΔrnrn−Δ=RΔrn 从 rnrn 推导出来。
-
大白话翻译:想象一个钟表。12点整到1点整的夹角是固定的30度。如果你知道当前是12点,想知道1点在哪里,你不需要重新画表,只需要把12点的指针"旋转"30度。这里提到的旋转矩阵,就是相当于那个"固定的旋转角度"。
2. 图表含义:内积随距离衰减
-
左图(热力图):对角线最亮(黄色)。对角线代表同一个位置,内积最大。颜色越往两边越暗,说明内积越小。
-
右图(折线图):中间有个高峰(代表当前位置),越往两边走,曲线越低。
-
白化翻译 :当模型计算两个词的注意力(内积)时,距离越近的词,它们的内积越大;距离越远的词,内积越小。
3. 为什么要这么设计?
这解决了一个大问题:Transformer 的自注意力机制本身是没有顺序感 的(它是像"口袋"一样乱序处理)。如果不加位置编码,模型会把"我吃饭 "和"饭吃我"混为一谈。
-
这一页展示的正余弦位置编码 赋予了模型一种**"距离感"**:
-
模型可以通过公式 rn−Δ=RΔrnrn−Δ=RΔrn ,轻松地理解相对位置(比如"B在A后面3个词")。
-
内积随距离衰减这一特性,让模型可以优先关注距离自己更近的上下文,这非常符合人类阅读和语言理解的直觉(大部分情况下,附近单词对当前单词的影响最大)。
-
一句话总结:
这一页在证明这种特定的数学位置编码方法,能让模型不仅知道"绝对的顺序",还能天然地理解"相对的距离远近",并且这种相对距离是可以被模型通过简单的矩阵操作学到的。
输入转为Embed向量X={x1,xn}加上rn位置编码,X={x1+r1,x2+r2}
进入多头注意力,QKV处理
然后归一化
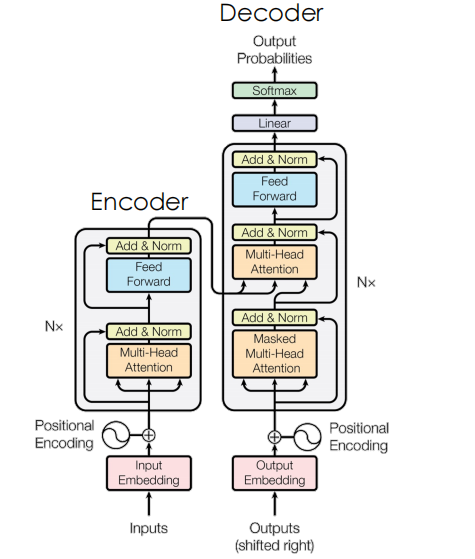
ENcoder是做表征-》输出是特殊的token融合了其他的内容
Decoder是做生成-》做翻译 表征输入进来然后输出一个翻译,翻译再输入进来,继续翻译下一个。
Maskattention
我们希望在生成的时候看不到未来的信息的,How are you,不能整体输入,必须把are youmask掉,只输入how。
CP21 生成式语言模型
Token:表达单词 单词的词缀 标点
Smallest->"Small""est"
Tokenizer->"token""izer"
切分来自字符出现的频次。
这种方式有什么好处?
允许新词的使用,niubility可以被字词表达
如何获得字词------字节对

把字母表包含在内。
然后看很多语料。
统计不同部分出现的词频。
词表就会不断扩充。达到规定的词表长度。
用explain索引失效的场景
一条慢sql要加什么索引
如何找到解决不足的子表
如何远控
登出所有子账号,然后登入administratir ubuntu2404
进去后开sudo astral
然后开thinlinc
这个页面就是正常的

远控端打开astral
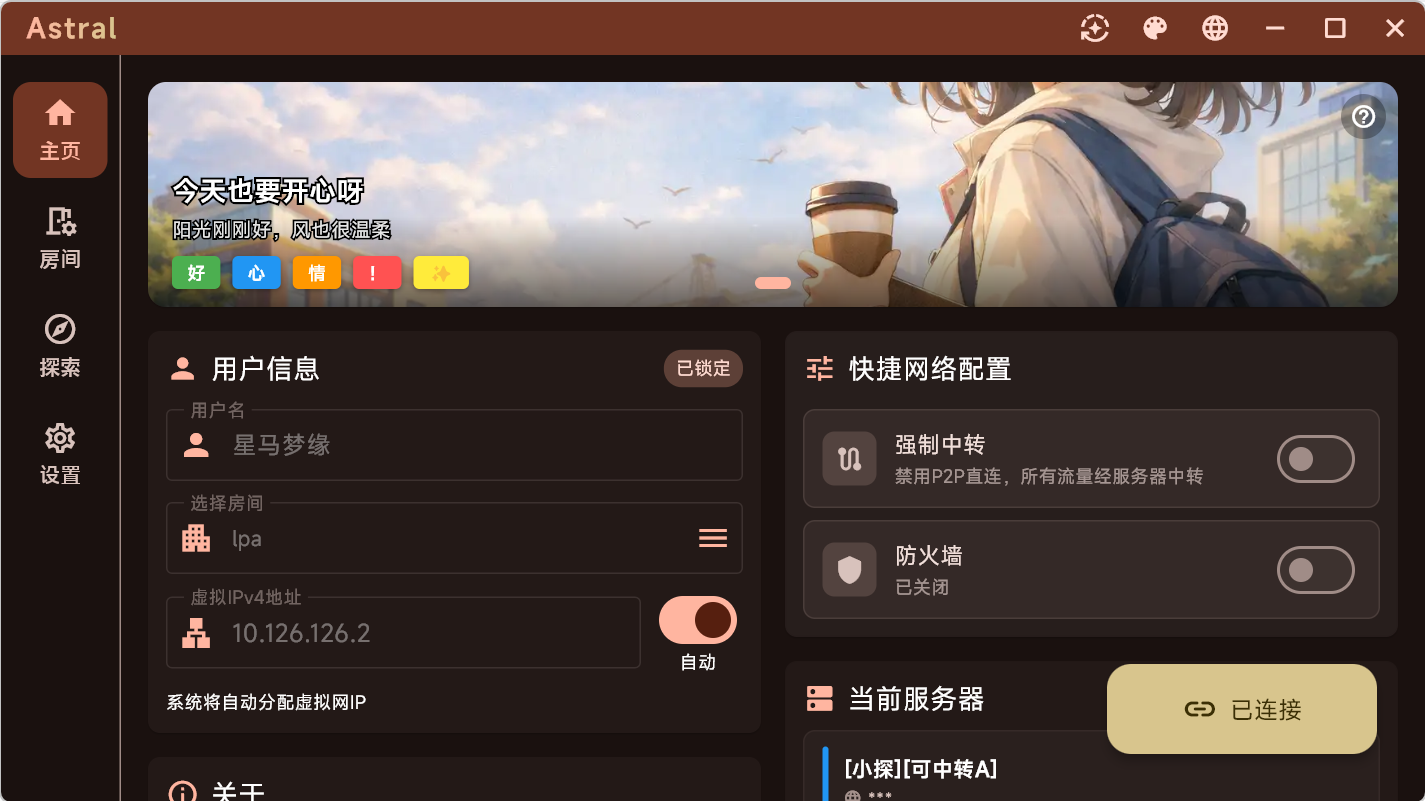
然后thinlinc即可,此时登录的就是个人账户
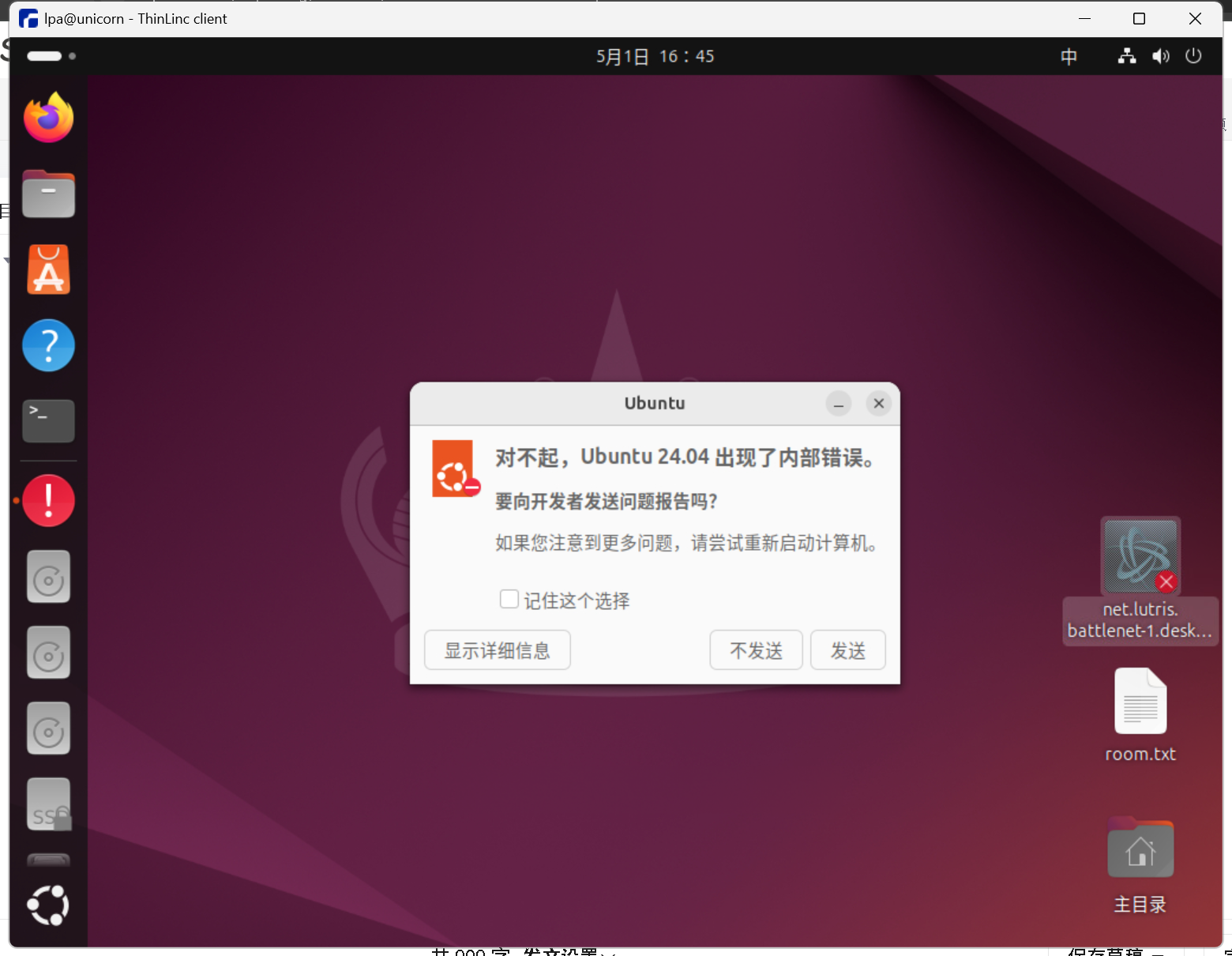
1. 找到并编辑配置文件
进入 rsl_rl 目录,打开 pyproject.toml 文件:
1cd ~/RF/issacsim/rsl_rl
2nano pyproject.toml2. 修改 license 那一行
找到 [project] 下面的 license = ... 这一行。
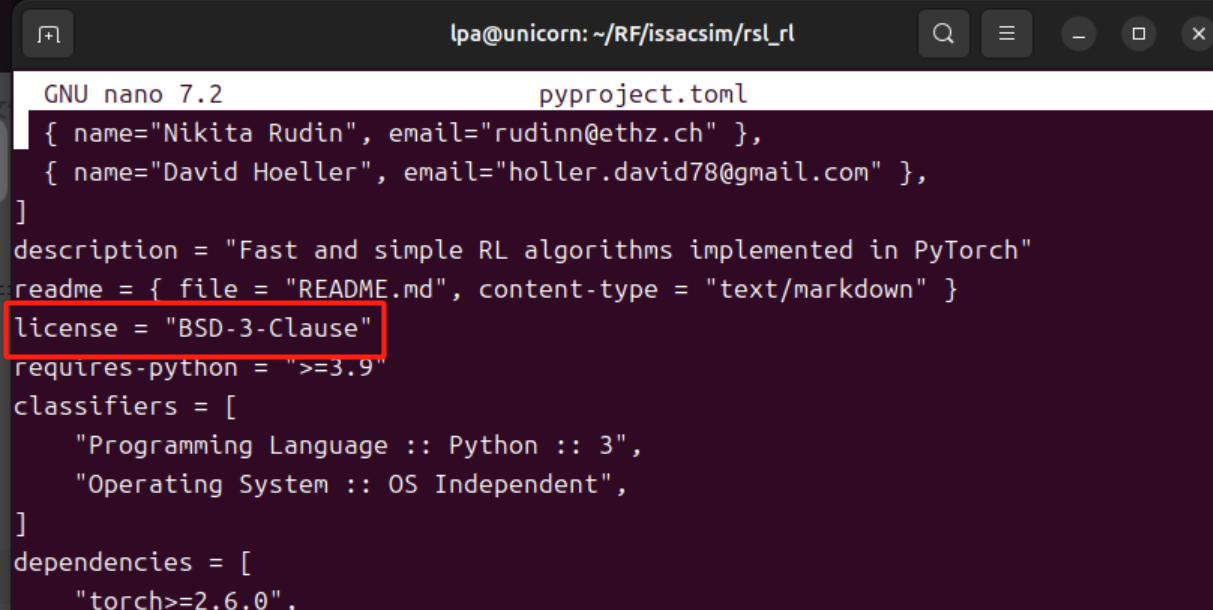
将原来的(旧写法):
1license = "BSD-3-Clause"修改为(新写法):
1license = {text = "BSD-3-Clause"}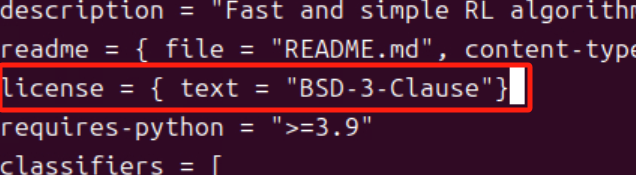
3. 保存并退出
- 如果你用的是
nano编辑器:- 按
Ctrl + O保存。 - 按
Enter确认。 - 按
Ctrl + X退出。
- 按