写在前面

欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师/开发工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
AIGC时代的 《三年面试五年模拟》AI算法工程师/开发工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写AI Agent(AI智能体)的深入浅出全维度解析文章: 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
大家好,我是Rocky。
核心导读
FlashAttention-2 这篇论文,表面上是在把 FlashAttention 再加速一倍左右;但 Rocky 认为,它真正值得反复读的地方,不是"又快了多少",而是它把注意力加速的问题,从第一阶段的 I/O-aware 算法设计 ,推进到了第二阶段的 execution-aware 系统调度。
FlashAttention-1 已经解决了一个非常关键的问题:不要把 S = Q K ⊤ S=QK^\top S=QK⊤ 和 P = s o f t m a x ( S ) P=\mathrm{softmax}(S) P=softmax(S) 这种 N × N N \times N N×N 中间矩阵写回 HBM。它用 tiling、online softmax 和 recomputation,把标准注意力从"内存搬运灾难"拉回到可训练长上下文模型的工程现实里。
但 FlashAttention-2 问的是另一个更细的问题:当你已经不再被 HBM 读写拖死之后,为什么 attention kernel 仍然不像 GEMM 那样高效?
论文给出的答案非常系统:FlashAttention-1 的瓶颈不再主要是"算法复杂度看起来不好",而是 GPU 执行层面的 work partitioning 还不够好。具体来说,它会暴露出三类浪费:
- 线程块数量不足,长序列小 batch 时 GPU occupancy 不够。
- warp 内部和 warp 之间的分工方式不佳,产生多余 shared memory 读写和同步。
- 一些 non-matmul FLOPs 虽然数量不大,但在现代 GPU 上远比 Tensor Core matmul 昂贵。
这篇工作最后达到的结果是:FlashAttention-2 在 A100 上达到理论峰值的 50% 到 73%,相比 FlashAttention-1 大约 2 倍加速;端到端训练 GPT-style 模型时,达到最高 225 TFLOPs/s/GPU,也就是 72% 的 model FLOPs utilization。
如果用一句话概括这篇论文的本质:
FlashAttention-1 证明了 exact attention 不必被 N 2 N^2 N2 中间矩阵拖死;FlashAttention-2 进一步证明,注意力层要成为长上下文时代的基础设施,不能只懂算法等价变换,还必须懂 GPU 怎样真正执行。
问题背景:作者到底想解决什么
Transformer 长上下文的核心矛盾,是 attention 的运行时间和内存占用都随序列长度平方增长。标准 attention 的前向计算可以写成:
S = Q K ⊤ , P = s o f t m a x ( S ) , O = P V S=QK^\top,\quad P=\mathrm{softmax}(S),\quad O=PV S=QK⊤,P=softmax(S),O=PV
其中 Q , K , V ∈ R N × d Q,K,V \in \mathbb{R}^{N \times d} Q,K,V∈RN×d, N N N 是序列长度, d d d 是 head dimension。问题不只是 O ( N 2 d ) O(N^2d) O(N2d) FLOPs,更麻烦的是标准实现会显式物化 S S S 和 P P P 两个 N × N N \times N N×N 矩阵。序列一长,HBM 读写和显存占用都会迅速失控。
FlashAttention-1 的突破,是用分块计算把 Q , K , V Q,K,V Q,K,V 从 HBM 搬到 SRAM,在片上完成局部 attention,并通过 online softmax 保证最终结果仍然是 exact attention,而不是近似注意力。
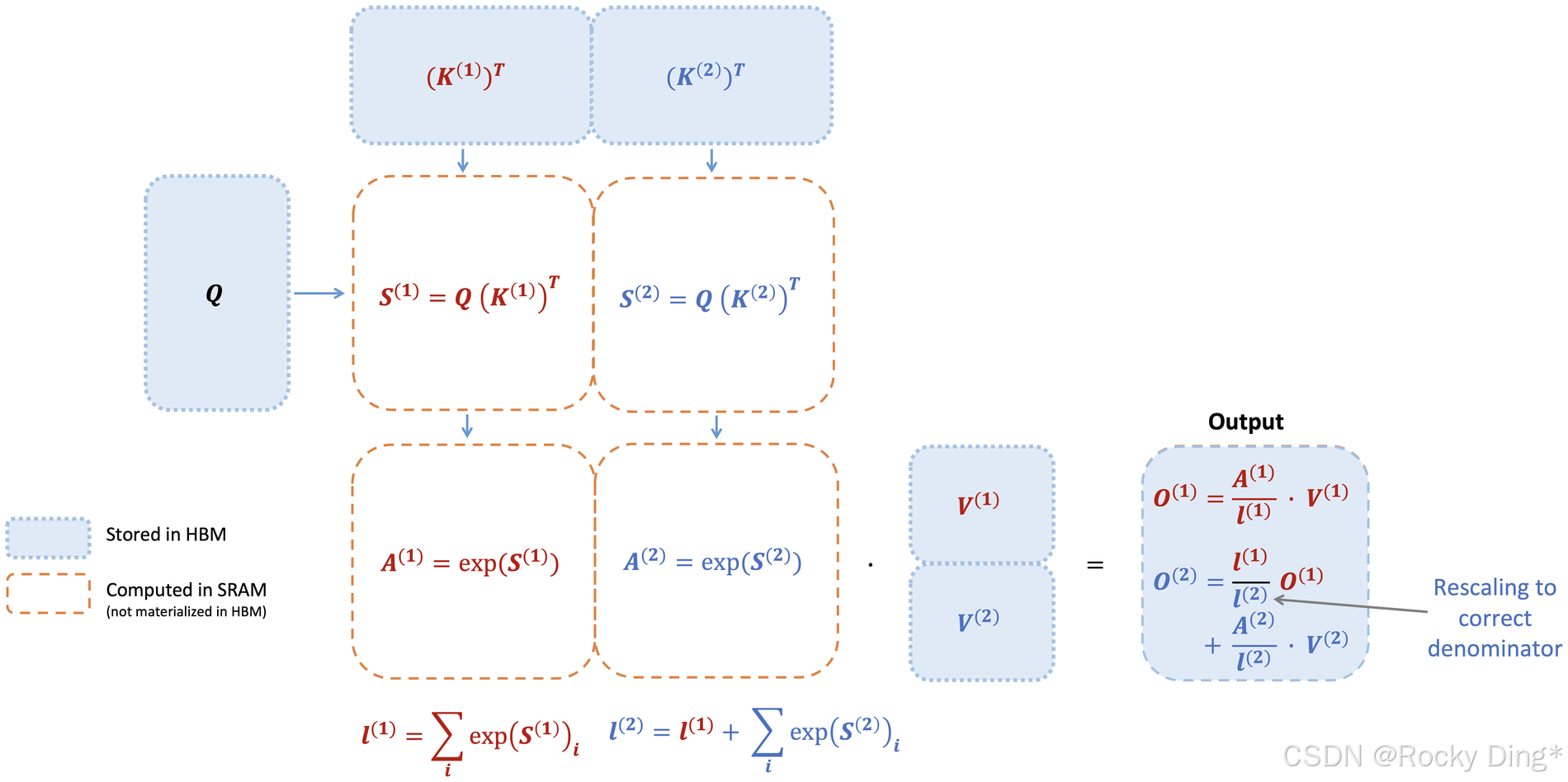
图 1 的关键不是画了一个漂亮流程,而是展示了 FlashAttention-1 的本质约束:它不再把完整的 S S S 和 P P P 写回 HBM,而是在每个 block 内边算 softmax 统计量,边更新输出。这样一来,注意力的额外内存可以从 O ( N 2 ) O(N^2) O(N2) 降到 O ( N ) O(N) O(N)。
这一步非常重要,因为它把"长上下文 attention"从大量近似路线中拽回了 exact attention 路线。Reformer、Linformer、Longformer、BigBird 等方法都试图改变 attention 结构来降低复杂度,但大规模训练里,标准 attention 仍然有很强的吸引力:语义简单、模型行为稳定、迁移成本低。
但 FlashAttention-2 的问题意识更进一步。FlashAttention-1 已经比标准 attention 快 2 到 4 倍,为什么还远远达不到 GEMM 的效率?论文指出,FlashAttention-1 的 forward 只能达到理论峰值约 30% 到 50%,backward 更低,大约 25% 到 35%;而优化良好的 GEMM 往往能达到 80% 到 90%。
这就是本文真正的技术拐点:当 attention 的主要瓶颈从 HBM I/O 转移到 GPU 执行效率,优化对象就从"少搬数据"变成了"让每个 SM、每个 warp、每类计算单元都更少空转"。
核心思路:用一句主线串起来
FlashAttention-2 没有改变 attention 的数学定义。它仍然计算:
O = s o f t m a x ( Q K ⊤ ) V O=\mathrm{softmax}(QK^\top)V O=softmax(QK⊤)V
它也没有把 exact attention 改成 sparse attention、linear attention 或其他近似形式。论文的全部价值在于:在输出不变的前提下,重新安排计算图和 GPU 工作分配。
作者的主线可以拆成三层:
| 层次 | FlashAttention-2 做了什么 | 本质目的 | Rocky 解读 |
|---|---|---|---|
| 算法层 | 修改 online softmax 细节,减少 non-matmul FLOPs,只保存 logsumexp | 少做昂贵的非矩阵乘运算 | 不是所有 FLOPs 代价相同,GPU 上 matmul 和非 matmul 是两个世界 |
| thread block 层 | 除 batch 和 head 外,再沿 sequence length 并行 | 提高长序列小 batch 场景下的 occupancy | 长上下文训练里,batch 往往变小,原来的并行维度不够用了 |
| warp 层 | 从 split-K 改成更接近 split-Q 的分工,减少 warp 间 shared memory 通信 | 降低片上同步和共享内存读写 | 性能不是只有"大 O",还有非常具体的执行拓扑 |
这也是 Rocky 认为这篇论文非常有"系统味"的地方:它不是提出一个新注意力公式,而是在一个已经被证明有价值的基础设施上,把每一层执行浪费继续压下去。
方法展开:沿着论文原始逻辑拆解
1. 减少 non-matmul FLOPs:小比例不等于小代价
FlashAttention-2 首先指出一个容易被忽略的事实:现代 GPU 上,不同 FLOPs 的价格差别极大。
以 A100 为例,论文给出的理论吞吐是:
| 计算类型 | 理论吞吐 |
|---|---|
| FP16/BF16 matmul | 312 TFLOPs/s |
| non-matmul FP32 | 19.5 TFLOPs/s |
这意味着 non-matmul FLOPs 的数量即使不大,也可能显著拖慢 kernel。因为 Tensor Core 对矩阵乘有专门硬件加速,而指数、加法、归一化、rescale 等操作并不能以同样的效率执行。
FlashAttention-2 对 online softmax 做了两个看起来很小、但非常工程化的修改。
第一,不再每轮都维护已经归一化的输出 O O O,而是维护未归一化的 O ~ \tilde{O} O~,最后再统一除以 softmax 的归一化项。用论文里的二分块示意,可以理解为:
O ~ ( 2 ) = d i a g ( e m ( 1 ) − m ( 2 ) ) O ~ ( 1 ) + e S ( 2 ) − m ( 2 ) V ( 2 ) \tilde{O}^{(2)}= \mathrm{diag}(e^{m^{(1)}-m^{(2)}})\tilde{O}^{(1)}+ e^{S^{(2)}-m^{(2)}}V^{(2)} O~(2)=diag(em(1)−m(2))O~(1)+eS(2)−m(2)V(2)
最终输出再计算为:
O ( 2 ) = d i a g ( ℓ ( 2 ) ) − 1 O ~ ( 2 ) O^{(2)}=\mathrm{diag}(\ell^{(2)})^{-1}\tilde{O}^{(2)} O(2)=diag(ℓ(2))−1O~(2)
第二,backward 不再同时保存 row-wise max m m m 和指数和 ℓ \ell ℓ,而是只保存:
L = m + log ( ℓ ) L=m+\log(\ell) L=m+log(ℓ)
这个 L L L 就是 logsumexp。它足以在 backward 中重新构造 softmax 所需信息,同时减少保存和搬运的状态。
这类改动在论文表述里很克制,但它体现了一个非常重要的工程直觉:在高性能 kernel 里,数学上等价的表达式并不等价。哪个量在 SRAM 里,哪个量写到 HBM,哪个操作落在 Tensor Core 上,哪个操作落在普通 FP32 单元上,都会改变最终吞吐。
2. 沿 sequence length 并行:长上下文时代,batch/head 并行不够用了
FlashAttention-1 主要沿 batch size 和 number of heads 并行。每个 attention head 对应一个 thread block,总 thread block 数大致是:
batch size × number of heads \text{batch size}\times \text{number of heads} batch size×number of heads
在普通长度、batch 较大的训练中,这通常够用。但长上下文有一个现实问题:序列越长,显存压力越大,batch size 往往越小。于是 GPU 上可能没有足够多的 thread blocks 去填满所有 SM。
A100 有 108 个 SM。如果 batch size 和 head 数的乘积不够大,即使单个 block 内部算得不错,整体 GPU occupancy 也会低。Rocky 认为,这里其实是长上下文训练里一个很典型的系统拐点:上下文长度本来是为了让模型看得更远,但它反过来压缩 batch size,削弱了旧并行策略。
FlashAttention-2 的做法,是把 sequence length 也加入并行维度。forward 中,每个 worker 处理 attention matrix 的一个 row block;backward 中,每个 worker 处理一个 column block,并通过 atomic add 更新共享的 d Q dQ dQ。
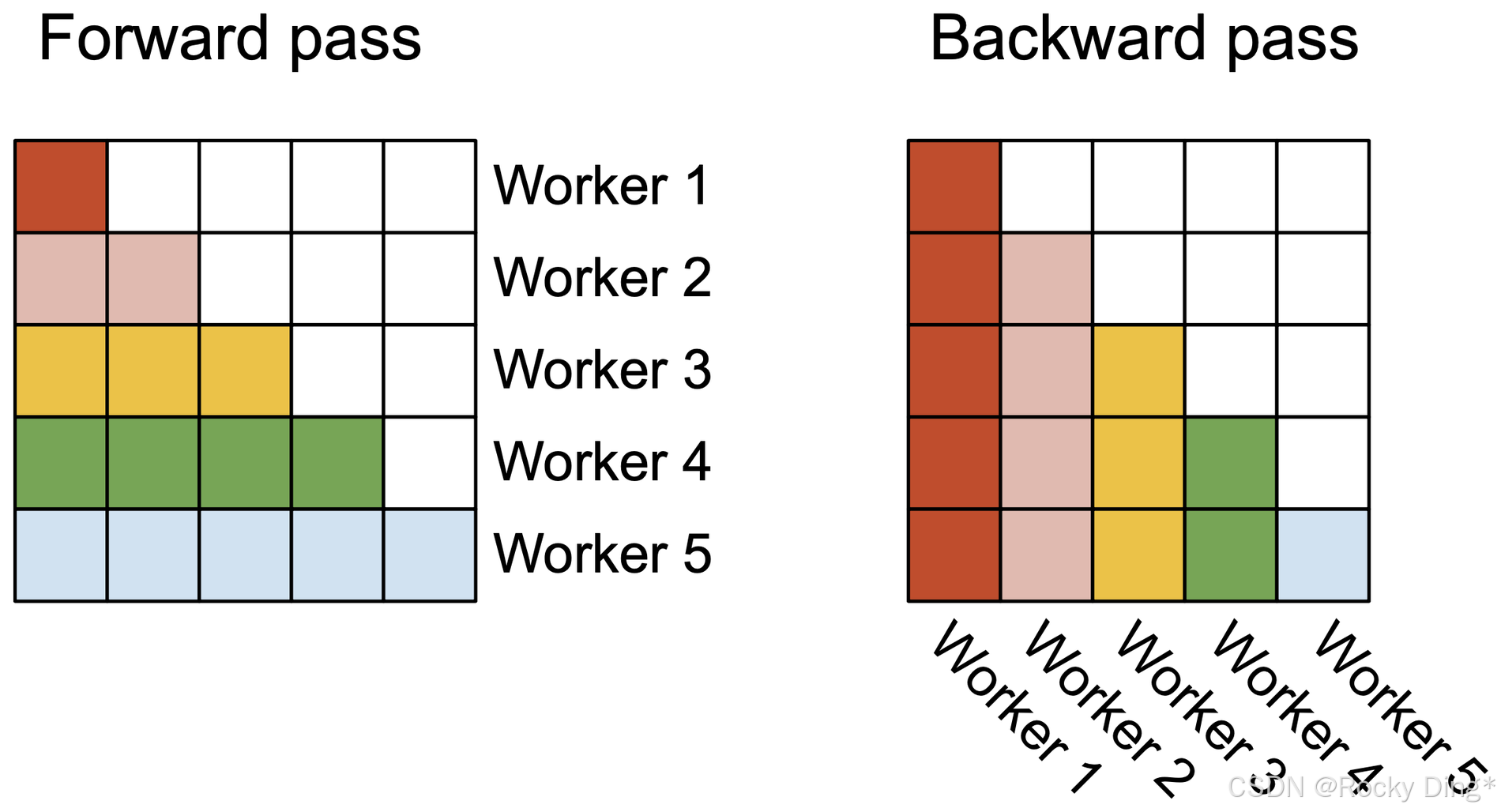
图 2 说明了本文最核心的 parallelism 改造。forward 里,不同 row block 之间天然可以并行,因为每个 row 的 softmax 只依赖同一行内部的 key/value blocks。backward 更复杂,因为不同 column blocks 会共同更新 d Q dQ dQ,所以需要 atomic adds 来完成跨 thread block 的累加。
这里的 trade-off 很清楚:FlashAttention-2 为了提高 occupancy,引入了更多并行粒度;但 backward 中的 atomic add 也意味着新的同步成本。论文的经验结果表明,在目标场景下,这个 trade-off 是值得的。
3. 改变 warp 内部分工:从 split-K 到 split-Q
如果说 sequence length 并行解决的是"thread blocks 数量够不够",那 warp partitioning 解决的是"一个 thread block 里面的 warps 怎样分工才少通信"。
FlashAttention-1 的 forward 通常采用类似 split-K 的方式:把 K K K 和 V V V 分给多个 warps,而 Q Q Q 被所有 warps 使用。每个 warp 计算一部分 Q K ⊤ QK^\top QK⊤,然后还要和不同 V V V 分片相乘,最后把中间结果写到 shared memory,同步,再加和。
问题在于:这会产生 warp 之间的 shared memory 读写和同步。shared memory 比 HBM 快得多,但它不是免费的。对于追求接近 GEMM 效率的 kernel,片上通信也会成为瓶颈。
FlashAttention-2 改成把 Q Q Q 分给多个 warps,而让 K , V K,V K,V 对 warps 共享。这样每个 warp 负责一部分 query rows,完成自己的 Q K ⊤ QK^\top QK⊤ 和后续乘 V V V,输出天然对应自己的 row slice,warp 之间不再需要为了合并输出而大量通信。
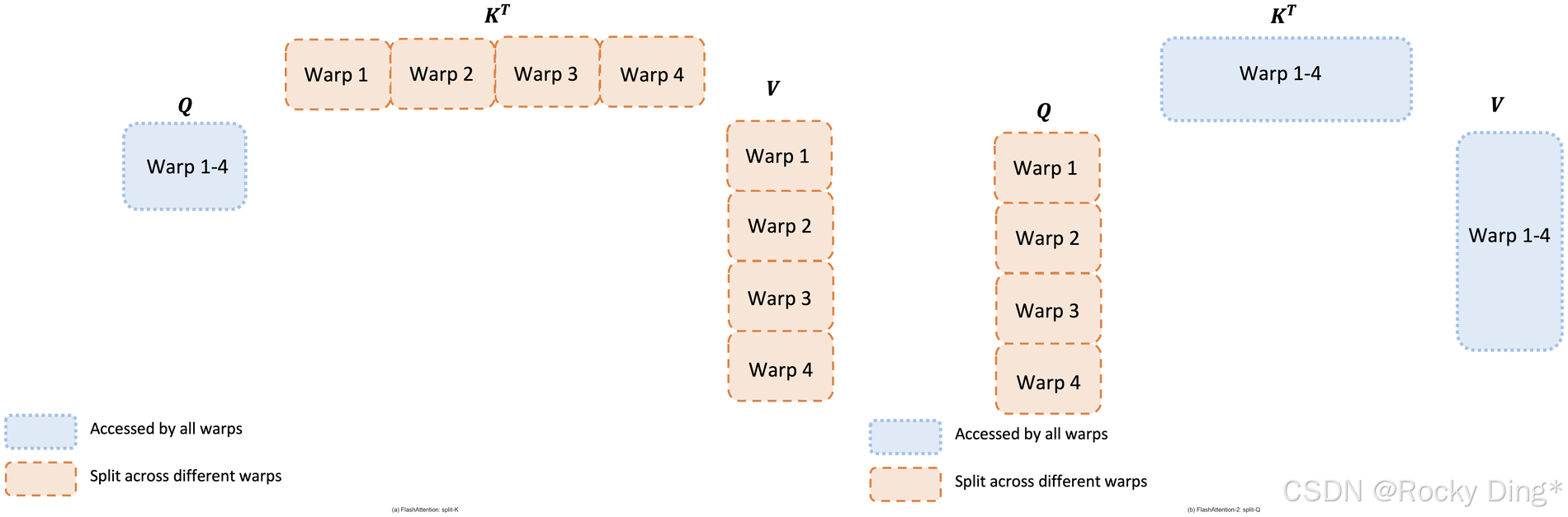
图 3 是这篇论文里最有"工程本质"的一张图。左边的 split-K 方案看起来也在并行,但它并行之后还要把结果合回来;右边的 split-Q 方案让每个 warp 拿到更独立的输出区域,减少了 shared memory 往返。
Rocky 认为,这里可以抽象出一个更普遍的系统原则:好的并行不是把任务切碎就结束,而是要让切碎后的任务尽量少合并、少同步、少共享状态。
4. Causal mask、MQA/GQA 和 block size:论文没有停在单一 benchmark
FlashAttention-2 还处理了几个实际模型中绕不开的问题。
第一是 causal mask。自回归语言模型里,位置 i i i 不能看未来位置 j > i j>i j>i。由于 FlashAttention 本身就是按 block 运算,很多完全落在未来区域的 blocks 可以直接跳过;对于需要 mask 的边界 block,也只需处理有限区域。论文提到,这会带来大约 1.7 到 1.8 倍的加速,相比无 causal mask 的完整 attention。
第二是 MQA/GQA。Multi-query attention 和 grouped-query attention 会让多个 query heads 共享同一组 key/value heads,以降低 KV cache。FlashAttention-2 的实现不需要真的复制 key/value heads,而是通过索引隐式处理共享;backward 中再把隐式共享导致的 d K , d V dK,dV dK,dV 梯度跨 heads 加和。
第三是 block size tuning。较大的 block 可以减少 shared memory loads/stores,但会增加寄存器需求和共享内存占用。过大时会触发 register spilling,甚至因为 shared memory 不够而无法运行。论文中典型选择是 { 64 , 128 } × { 64 , 128 } \{64,128\}\times\{64,128\} {64,128}×{64,128},并承认目前主要靠手工调参,未来可以用 auto-tuning 改善。
这些细节看似分散,但它们共同说明一件事:FlashAttention-2 不是一个只在理想设定里跑得快的公式,而是面向真实 Transformer 训练和推理场景的 kernel 设计。
实验与证据:结果能支撑到什么程度
论文实验分成两层:attention kernel benchmark 和端到端 GPT-style training。
1. A100 attention benchmark:forward + backward 的整体吞吐
作者在 A100 80GB SXM4 上测试不同序列长度、是否 causal mask、head dimension 为 64 或 128 的场景。总 tokens 固定为 16k,sequence length 从 512 到 16k 变化。
Forward FLOPs 的计算方式是:
4 ⋅ seqlen 2 ⋅ head dimension ⋅ number of heads 4\cdot \text{seqlen}^2\cdot \text{head dimension}\cdot \text{number of heads} 4⋅seqlen2⋅head dimension⋅number of heads
如果使用 causal mask,则约除以 2,因为只计算下三角的一半 attention entries。Backward FLOPs 则按 forward 的 2.5 倍估算,因为 forward 有 2 个 matmul,而 backward 有 5 个 matmul,并包含 recomputation。
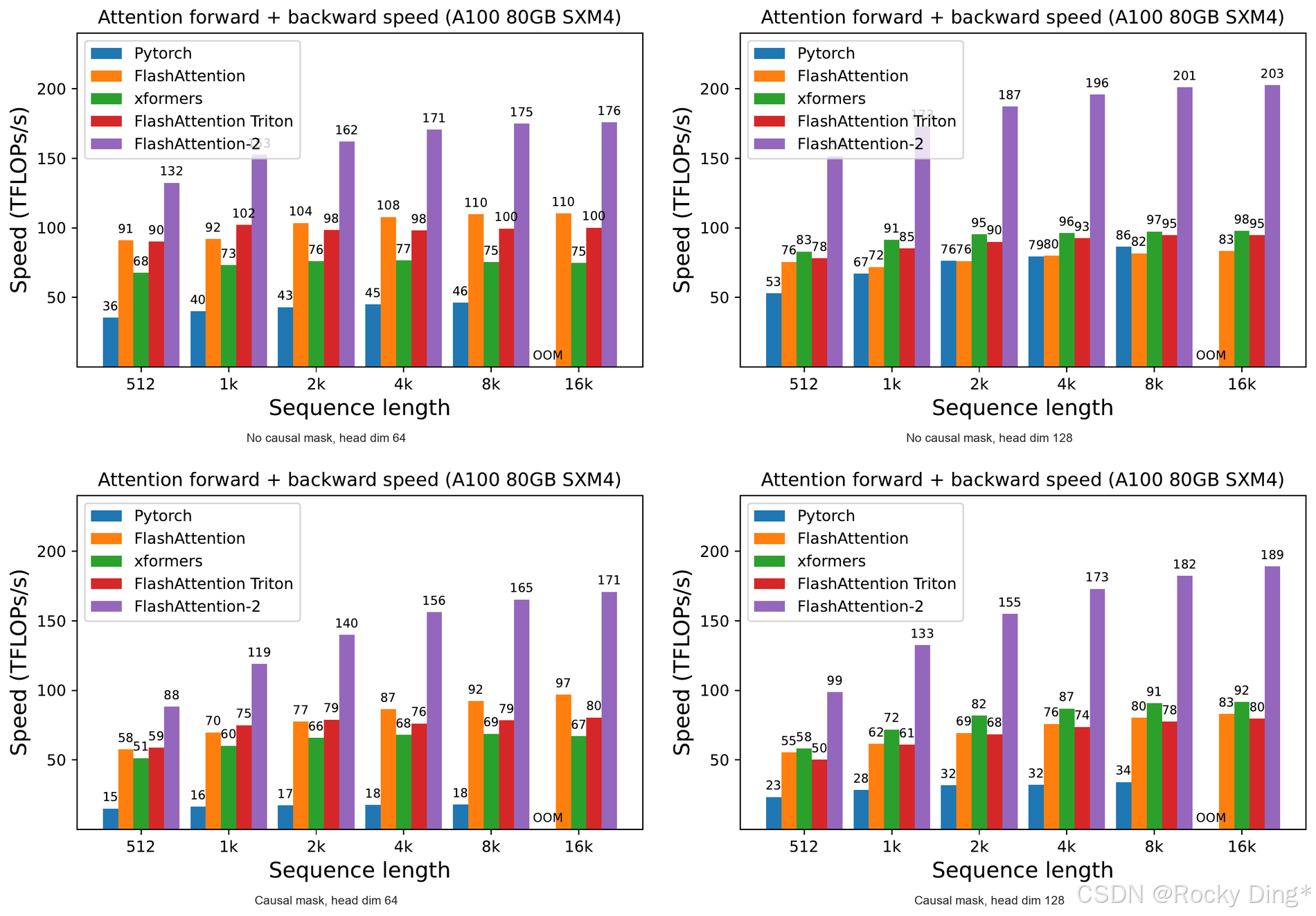
图 4 是最接近真实训练成本的 kernel 级结果,因为训练需要 forward 和 backward 都快。可以看到,FlashAttention-2 在多种 setting 下显著高于 FlashAttention-1、Triton 版本 FlashAttention-1、xFormers/CUTLASS 以及 PyTorch 标准 attention。论文总结的范围是:FlashAttention-2 相比 FlashAttention-1 快 1.7 到 3.0 倍,相比 Triton 版本快 1.3 到 2.5 倍,相比 PyTorch 标准实现快 3 到 10 倍。
2. Forward 单独看:最高达到 A100 理论峰值 73%
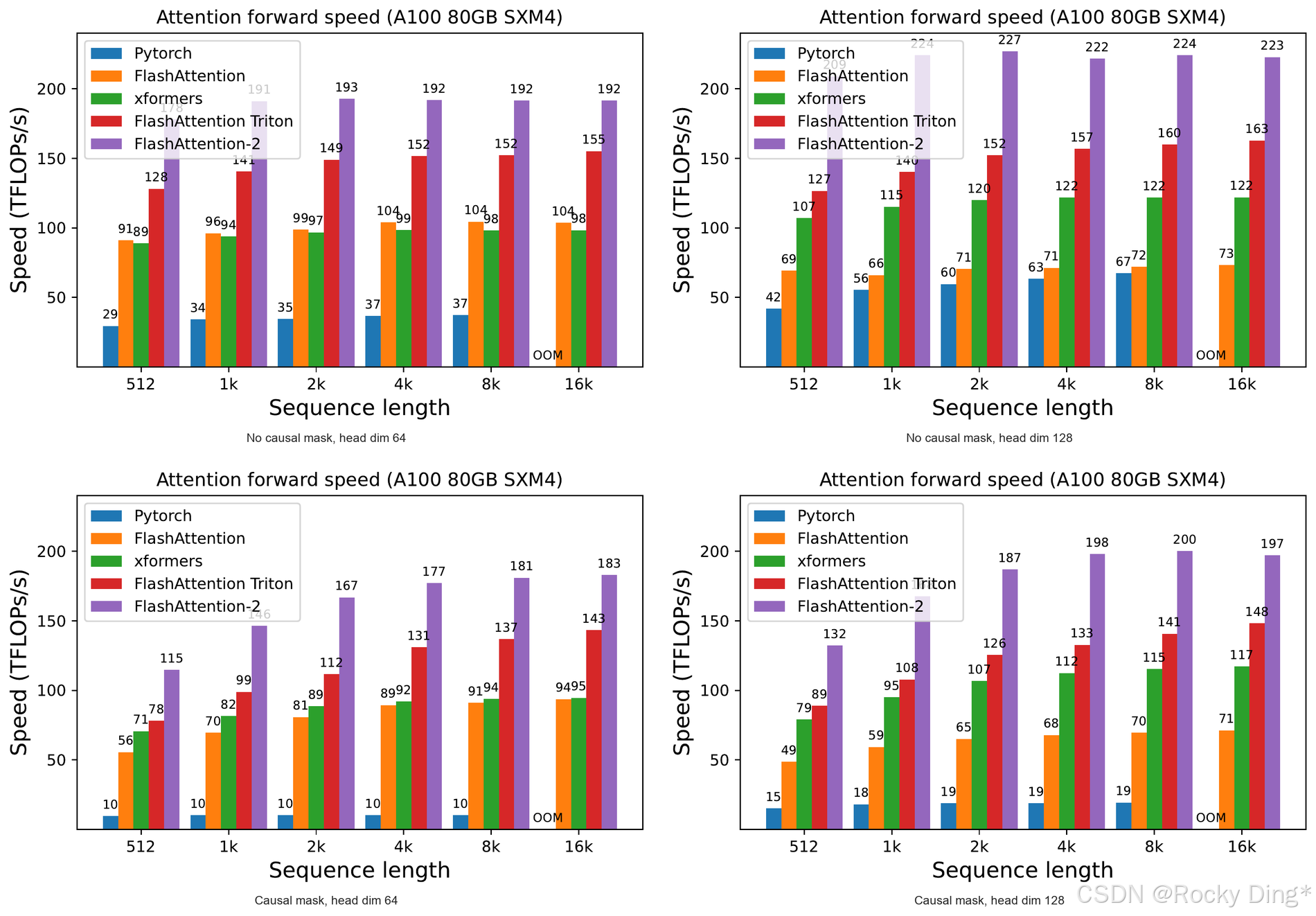
图 5 展示 forward-only 结果。论文指出,FlashAttention-2 在 forward pass 中最高可以达到 A100 理论最大 TFLOPs/s 的 73%。这不是一个小数字,因为 attention 并不是纯 GEMM,它包含 softmax、mask、rescale、状态维护等非矩阵乘操作。
这个结果支撑了论文最核心的判断:减少 non-matmul FLOPs、提高 occupancy、减少 warp 通信之后,attention kernel 可以更接近 GEMM 的效率区间。
但也要注意,它仍然不是 GEMM。原因很简单:attention 的语义比矩阵乘更复杂,softmax 的行归一化和长序列依赖无法完全消失。所以 FlashAttention-2 的意义不是"attention 已经和 GEMM 一样简单",而是"attention 正在被工程化到越来越接近硬件甜点区"。
3. Backward 单独看:真正难的是训练链路
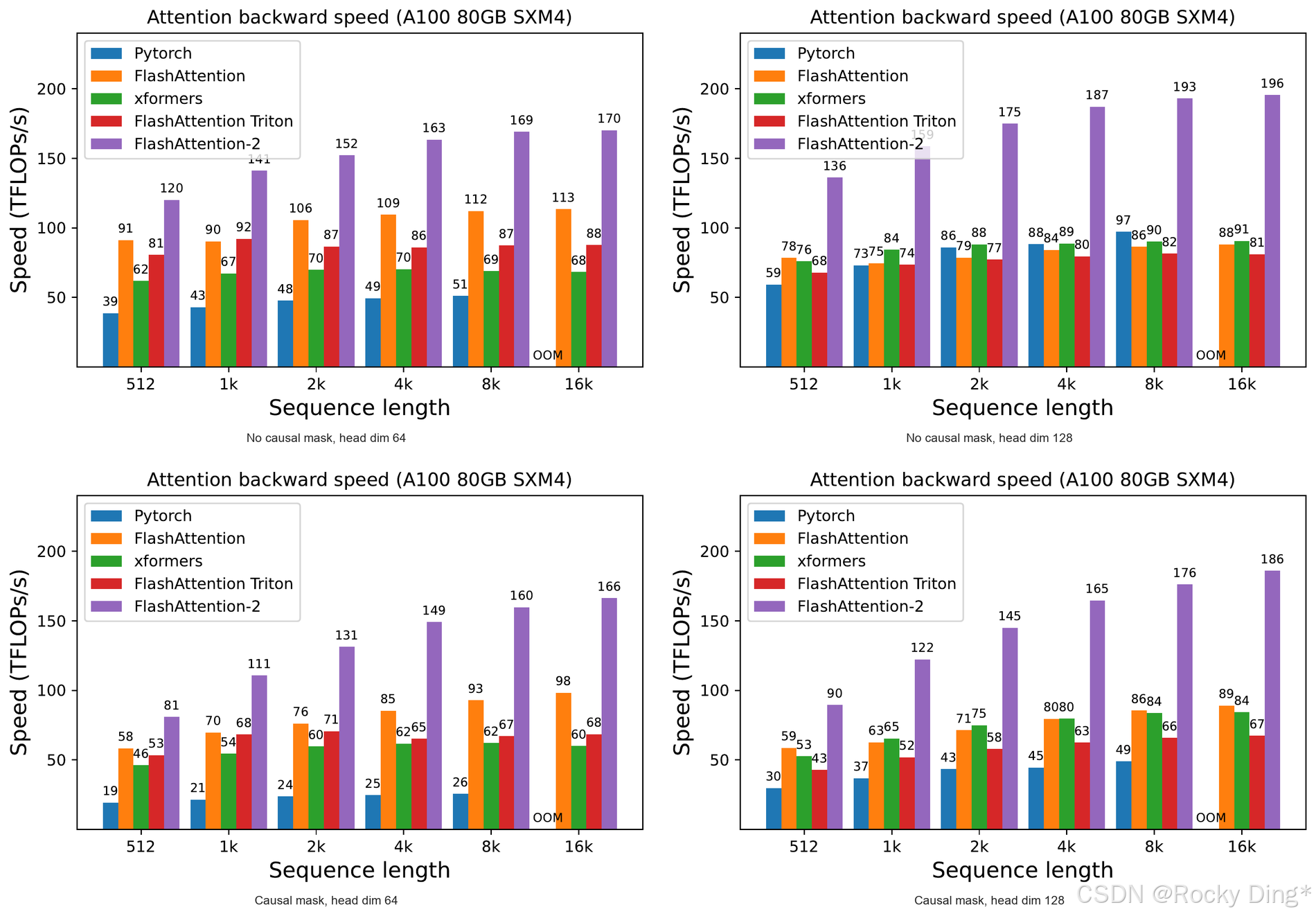
图 6 展示 backward-only 结果。Backward 比 forward 难,因为它涉及 d Q , d K , d V dQ,dK,dV dQ,dK,dV,还要处理 softmax 梯度和 recomputation。标准 attention backward 可以写成:
d V = P ⊤ d O , d P = d O V ⊤ , d S = d s o f t m a x ( d P ) , d Q = d S K , d K = Q d S ⊤ dV=P^\top dO,\quad dP=dOV^\top,\quad dS=d\mathrm{softmax}(dP),\quad dQ=dSK,\quad dK=QdS^\top dV=P⊤dO,dP=dOV⊤,dS=dsoftmax(dP),dQ=dSK,dK=QdS⊤
FlashAttention 系列的 backward 不保存完整 P P P,而是在 block 内重新计算相关矩阵,这节省显存,但增加了 kernel 组织复杂度。FlashAttention-2 在 backward 中同样通过 sequence length 并行和更好的 warp partitioning 提升吞吐,论文报告最高达到理论峰值约 63%。
Rocky 认为,backward 结果对工程落地尤其重要。很多加速论文只展示 inference 或 forward latency,容易让人误判真实训练收益。FlashAttention-2 把 forward、backward、端到端训练都做了验证,这是它证据链比较扎实的地方。
4. H100 结果:没有用新硬件特性,也已经到 335 TFLOPs/s
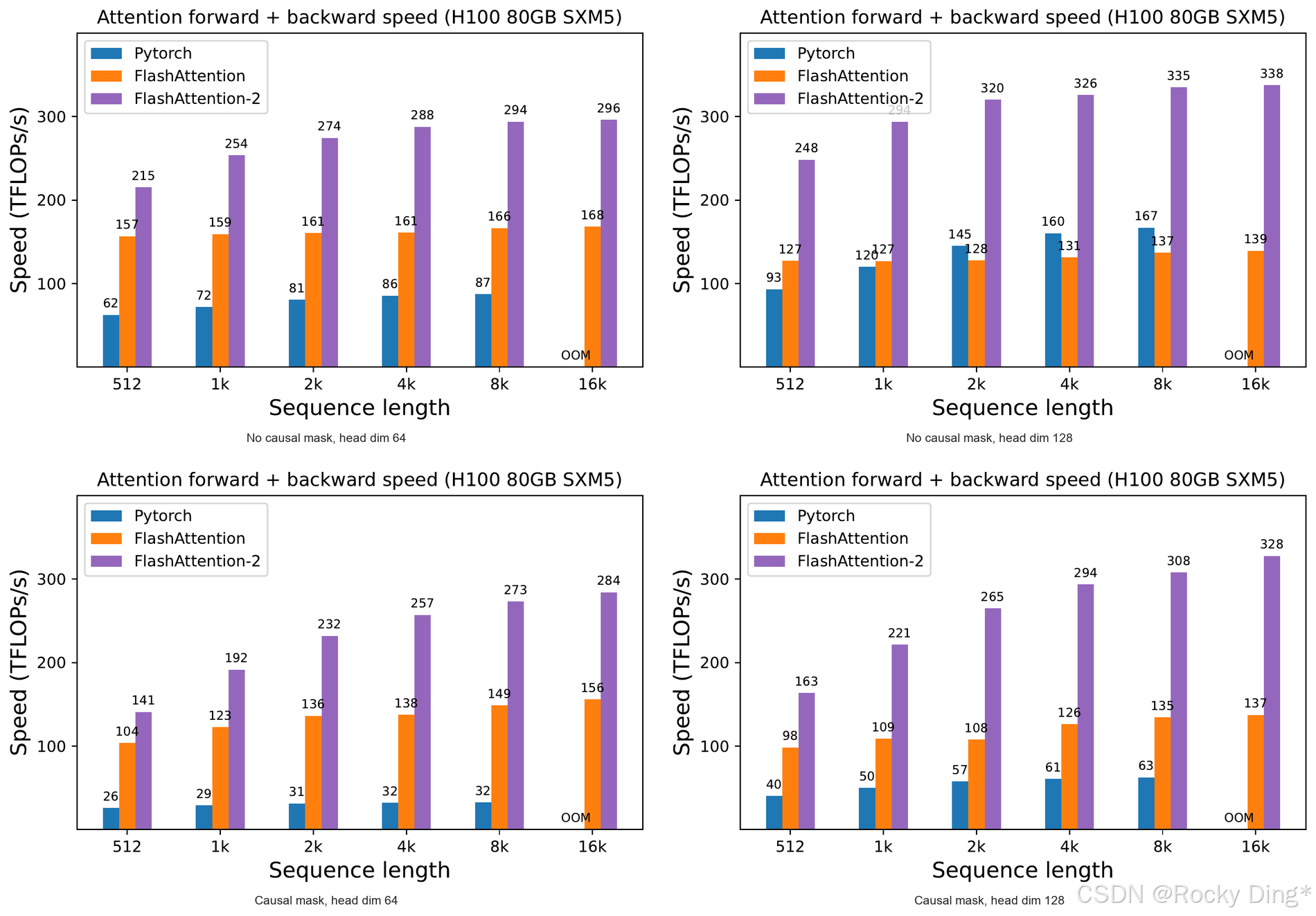
图 7 展示 H100 上的 forward + backward 结果。论文特别强调,这只是把同一实现跑在 H100 上,并没有使用 TMA、第四代 Tensor Cores、FP8 等 H100 新特性,已经达到最高 335 TFLOPs/s。
作者预期,如果进一步使用 H100 的新指令和硬件能力,还可能再有 1.5 到 2 倍提升。这个结论要谨慎看:它是合理方向,但不是本文已经实证完成的结果。
5. 端到端训练:从 kernel 加速到模型训练吞吐
Kernel benchmark 很重要,但对大模型训练来说,最终还要看端到端吞吐。论文在 8 张 A100 80GB SXM 上训练 GPT-style models,模型规模为 1.3B 和 2.7B,context length 为 2k 或 8k。
| Model | Without FlashAttention | FlashAttention | FlashAttention-2 |
|---|---|---|---|
| GPT3-1.3B 2k context | 142 TFLOPs/s | 189 TFLOPs/s | 196 TFLOPs/s |
| GPT3-1.3B 8k context | 72 TFLOPs/s | 170 TFLOPs/s | 220 TFLOPs/s |
| GPT3-2.7B 2k context | 149 TFLOPs/s | 189 TFLOPs/s | 205 TFLOPs/s |
| GPT3-2.7B 8k context | 80 TFLOPs/s | 175 TFLOPs/s | 225 TFLOPs/s |
这张表真正有价值的地方,是长上下文场景下的差距非常明显。比如 GPT3-1.3B 8k context,从无 FlashAttention 的 72 TFLOPs/s 到 FlashAttention-2 的 220 TFLOPs/s,提升约 3 倍;GPT3-2.7B 8k context 则从 80 到 225 TFLOPs/s。
论文用的端到端 FLOPs 估算公式是:
6 ⋅ seqlen ⋅ number of params + 12 ⋅ number of layers ⋅ hidden dim ⋅ seqlen 2 6\cdot \text{seqlen}\cdot \text{number of params} +12\cdot \text{number of layers}\cdot \text{hidden dim}\cdot \text{seqlen}^2 6⋅seqlen⋅number of params+12⋅number of layers⋅hidden dim⋅seqlen2
作者也说明了一个口径问题:对于 causal mask,attention 实际只计算大约一半 entries,但他们仍沿用文献公式,没有把 attention FLOPs 除以 2,以保持可比性。
这里要给一个严谨判断:FlashAttention-2 的端到端收益不是在所有场景都恒定 2 倍,而是在 attention 成本占比高、序列更长、batch/head 并行不足的场景更明显。 这恰恰也是它最符合长上下文训练趋势的地方。
这篇工作的边界与可复现性
FlashAttention-2 是一篇很强的系统优化论文,但它的边界也要说清楚。
第一,它没有降低 attention 的理论计算复杂度。FlashAttention-2 仍然是 exact attention,FLOPs 复杂度仍是 O ( N 2 d ) O(N^2d) O(N2d)。它降低的是内存占用、I/O 和执行浪费,而不是把二次复杂度改成线性复杂度。
第二,它的收益依赖硬件和 kernel 实现。论文的主结果主要围绕 A100 和 H100。不同 GPU、不同 shared memory 大小、不同 Tensor Core 能力、不同编译器后端,都会影响最优 block size 和实际吞吐。
第三,它需要低层工程调优。作者明确提到 block size 目前有手工 tuning 成分。对于开源社区和工业团队来说,这意味着 FlashAttention-2 不是"看懂公式就能复现吞吐",而是需要 CUDA/Triton、GPU profiler、kernel scheduling、memory hierarchy 的工程能力。
第四,H100 的进一步提升在本文中还不是完成态。论文展示了不使用 H100 特殊新特性的结果,并提出 TMA、第四代 Tensor Cores、FP8 等方向,但这些属于后续优化空间,不应被误读为本文已经完整验证。
第五,它提升的是 attention 这个 primitive。端到端模型训练还受到通信、optimizer、data loading、activation checkpointing、pipeline/tensor parallel、MoE routing 等其他系统因素影响。FlashAttention-2 能显著改善 attention bottleneck,但不能自动解决所有训练系统瓶颈。
这几个边界并不削弱论文价值,反而让它更真实。真正好的基础设施论文,往往不是宣称自己解决一切,而是非常清楚自己解决了系统链路中的哪一段。
如果继续研究和落地,应该关注什么
1. Compiler 和 auto-tuning 会越来越重要
FlashAttention-2 的一个直接启发是:未来 AI 系统优化不能只靠手写 kernel 英雄主义。手写 kernel 可以打开上限,但大规模适配不同 GPU、不同 head dimension、不同 sequence length、不同数据类型时,compiler 和 auto-tuning 会变得越来越关键。
如果一个优化技巧只能由少数专家在少数硬件上手工调出最优,它仍然很强,但传播速度有限。跨周期价值更高的方向,是把这类 work partitioning 思想沉淀进编译器、kernel generator 和 runtime autotuner。
2. 长上下文不是只靠模型结构,系统效率同样决定边界
很多人谈长上下文,第一反应是位置编码、稀疏注意力、检索增强、记忆机制。但 FlashAttention-2 提醒我们:即使 attention 公式不变,系统层也能把可训练长度往前推。
论文讨论里提到,一个 2 倍更快的 attention 意味着过去训练 8k context 的成本,现在可能训练 16k context。这个说法不应机械理解成所有成本线性替换,但它揭示了本质:上下文长度不是单纯的算法问题,也是成本结构问题。
在产业一线,长上下文能不能普及,最终取决于训练、微调、推理的单位成本。FlashAttention-2 属于那种不改变产品叙事,却改变产品可行边界的底层技术。
3. KV cache、MQA/GQA 和推理系统会继续放大这类工作价值
论文中提到 MQA/GQA 支持,是一个很现实的信号。大模型推理中,KV cache 往往是吞吐、显存和延迟的关键因素。MQA/GQA 通过共享 key/value heads 降低 KV cache 规模,而 FlashAttention-2 通过索引隐式处理这些共享关系,避免物理复制。
这说明 attention kernel 的价值不只在训练,也在推理系统。尤其是多轮对话、长文档问答、代码仓库理解、Agent 工作流中,长上下文和 KV cache 会共同决定成本与体验。
4. Exact attention 与 sparse/local/block-sparse attention 不是二选一
作者在 future directions 里提到,可以把 FlashAttention-2 的低层优化与 local、dilated、block-sparse attention 等高层算法变化结合。
这点很重要。FlashAttention-2 不是要否定所有稀疏或近似路线,而是提供一个更强的 exact attention baseline。只有 baseline 足够强,后续 sparse attention 才能更诚实地证明自己:到底是因为结构真的更好,还是只是因为旧 exact attention 实现太慢。
术语与概念速查
| 术语 | 解释 |
|---|---|
| HBM | GPU 高带宽显存,容量大但相比片上 SRAM 慢,标准 attention 写回 N × N N \times N N×N 中间矩阵会造成大量 HBM 读写 |
| SRAM / shared memory | GPU 片上共享内存,速度快但容量小,FlashAttention 系列把 block 数据搬到这里计算 |
| SM | Streaming Multiprocessor,GPU 上执行 thread blocks 的计算单元,A100 有 108 个 SM |
| Warp | GPU 线程组,通常 32 个 threads,FlashAttention-2 在 warp 级别重新设计分工 |
| Occupancy | GPU 资源被有效使用的程度,长序列小 batch 时可能因为 thread blocks 不够而降低 |
| GEMM | General Matrix Multiply,现代 GPU 上最成熟、最高效的矩阵乘 primitive |
| Tensor Core | NVIDIA GPU 上专门加速低精度矩阵乘的硬件单元 |
| non-matmul FLOPs | 非矩阵乘运算,如 softmax、exp、rescale、mask 等,在 A100 上理论吞吐远低于 matmul |
| Online softmax | 分块计算 softmax 的技巧,通过维护 max 和 sum 等统计量保证最终结果 exact |
| logsumexp | L = m + log ( ℓ ) L=m+\log(\ell) L=m+log(ℓ),FlashAttention-2 用它替代同时保存 max 和 sum |
| split-K | 多个 warps 按 K / V K/V K/V 分片计算,可能需要额外 shared memory 通信来合并结果 |
| split-Q | 多个 warps 按 Q Q Q 的 row slice 分工,每个 warp 更独立地产生输出 slice |
| MQA/GQA | 多个 query heads 共享 key/value heads 的注意力变体,用于降低 KV cache |
| MFU | Model FLOPs Utilization,模型训练中实际达到的 FLOPs 利用率 |
拓展思考:值得继续扩展研究与思考的创新点
FlashAttention-2 对今天做 AI Infra、长上下文模型、推理加速的人,有三个长期启发。
第一,基础设施创新经常不是"换一个公式",而是"让同一个公式在真实硬件上更接近物理上限"。这类工作在论文标题上可能不如新架构炫,但它会被一代又一代模型训练和推理系统吸收。
第二,系统优化的难度正在从宏观算法转向细粒度执行。FlashAttention-1 的关键词是 I/O-aware,FlashAttention-2 的关键词是 work partitioning。再往后,可能就是更深的 compiler-aware、architecture-aware、serving-aware。
第三,长上下文的竞争,不只是模型公司在比谁的 context window 更长,也是在比谁能用更低成本训练、微调、部署和服务这些长上下文能力。模型能力会被看见,系统效率常常被隐藏,但商业闭环最终会奖励后者。
Rocky 最后给一个判断:FlashAttention-2 不是一篇"又把速度刷高了"的 benchmark 论文,而是一篇把 attention 从算法优化推向硬件执行优化的基础设施论文。它的跨周期价值,在于把 exact attention 继续留在长上下文时代的主路上。
证据清单
| 论文证据 | 对应结论 |
|---|---|
| FlashAttention-1 将 attention 额外内存从 O ( N 2 ) O(N^2) O(N2) 降到 O ( N ) O(N) O(N),但仅达到理论峰值 25% 到 40% 左右 | I/O-aware 之后仍存在执行效率问题 |
| A100 上 FP16/BF16 matmul 理论 312 TFLOPs/s,non-matmul FP32 理论 19.5 TFLOPs/s | non-matmul FLOPs 数量虽少但代价高 |
| forward/backward 沿 sequence length 并行 | 长序列小 batch/head 场景下提高 occupancy |
| warp partitioning 从 split-K 改向 split-Q | 减少 warp 间 shared memory 读写和同步 |
| A100 attention benchmark 最高达到 230 TFLOPs/s、理论峰值 73% | kernel 级吞吐显著提升 |
| GPT-style 训练最高 225 TFLOPs/s/GPU、72% MFU | 加速能传导到端到端训练 |
| H100 未用特殊新特性已达到最高 335 TFLOPs/s | 方法具备继续向新硬件迁移的潜力,但仍需后续专门优化 |
推荐阅读
1. 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2. 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:深入浅出完整解析扩散模型DDPM、DDIM、SDE、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
3. 深入浅出完整解析FLUX.2、Seedream(即梦)、Z-image、GLM-Image核心基础知识
https://zhuanlan.zhihu.com/p/1975174691049189562
4. 深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
5. 深入浅出完整解析DeepSeek系列核心基础知识
6、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:深入浅出完整解析Sora、Wan2.1、AnimateDiff、CogVideoX等AI视频大模型核心基础知识
7、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
8、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
9、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:深入浅出完整解析Stable Diffusion(SD)核心基础知识
10、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:深入浅出完整解析ControlNet核心基础知识
11、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
12、深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统"AI江湖"之势。Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
Transformer文章地址:深入浅出完整解析AIGC时代Transformer核心基础知识
13、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:手把手教你成为AIGC算法工程师,斩获AIGC算法offer!
14、50万字大汇总《"三年面试五年模拟"之算法工程师的求职面试"独孤九剑"秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
15、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
16、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
17. AI算法工程师的《三年面试五年模拟》求职秘籍
18. AIGC产业的深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作、生活、学习以及交流方式,各行各业都将被重新定义,过程会非常有趣。
那么,在此基础上,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?Rocky准备从技术、产品、商业模式、长期主义等维度持续分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解: