
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》 《MySQL数据库学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在学习 MySQL 的过程中,事务是一个绕不开的重要知识点.它不仅关系到SQL的执行结果,更直接影响到业务数据的安全性和一致性.尤其是在转账、下单、库存扣减、支付状态更新等场景中,一次业务操作往往会涉及多条 SQL,如果其中某一步失败,就必须保证前面的操作能够被正确撤销.这就是事务存在的意义:把多条数据库操作看作一个整体,要么全部成功,要么全部失败.本篇文章是 MySQL 事务学习的上篇,主要围绕事务的基础概念展开,先理解事务解决的问题,再学习事务的基本使用方式,并进一步引出事务的核心特性.掌握这些内容之后,再继续学习事务隔离级别、并发问题以及底层实现时,就会更容易建立完整的知识体系.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!

目录
- 1.什么是事务?
- 2.为什么会出现事务?
- 3.事务的版本支持
- 4.事务提交方式
- 5.事务常见操作方式
- 6.事务隔离级别
-
- 6.1如何理解隔离性1
- 6.2隔离级别
- 6.3查看与设置隔离性
- [6.4读未提交【Read Uncommitted】](#6.4读未提交【Read Uncommitted】)
- [6.5读提交【Read Committed】](#6.5读提交【Read Committed】)
- [6.6可重复读【Repeatable Read】](#6.6可重复读【Repeatable Read】)
- 6.7串行化【serializable】
- 6.8一致性【Consistency】
- 7.推荐阅读
1.什么是事务?
事务就是一组数据库操作的"最小执行单元":要么全部成功,要么全部失败回滚.
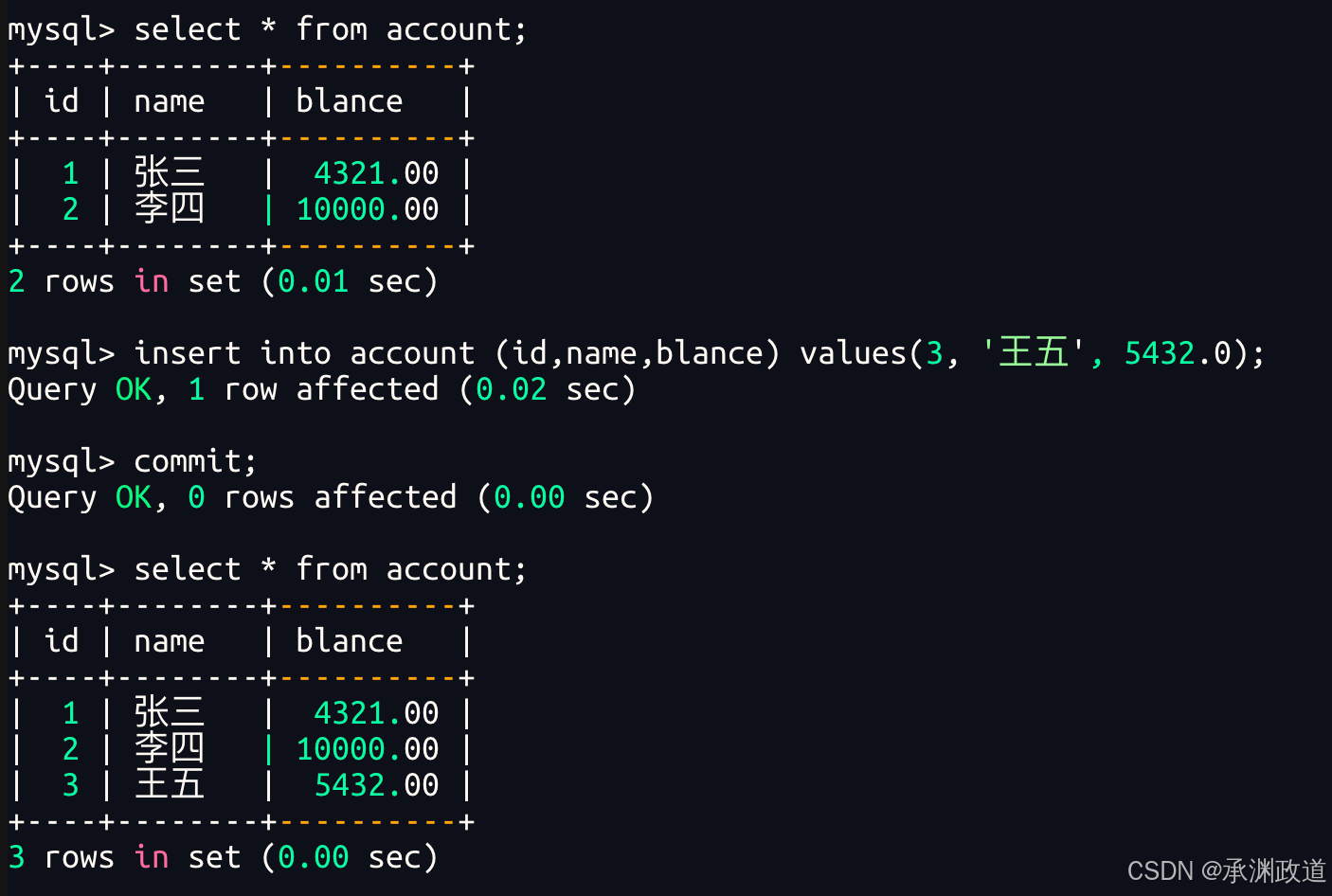
事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部失败,是一个整体.MySQL提供一种机制,保证我们达到这样的效果.事务还规定不同的客户端看到的数据是不相同的.事务就是要做的或所做的事情,主要用于处理操作量大,复杂度高的数据.假设一种场景:你毕业了,学校的教务系统后台MySQL中,不在需要你的数据,要删除你的所有信息(一般不会:),那么要删除你的基本信息(姓名,电话,籍贯等)的同时,也删除和你有关的其他信息,比如:你的各科成绩,你在校表现,甚至你在论坛发过的文章等.这样,就需要多条MySQL 语句构成,那么所有这些操作合起来,就构成了一个事务.
正如我们上面所说,一个MySQL数据库,可不止你一个事务在运行,同一时刻,甚至有大量的请求被包装成事务,在向MySQL服务器发起事务处理请求.而每条事务至少一条 SQL,最多很多SQL,这样如果大家都访问同样的表数据,在不加保护的情况,就绝对会出现问题.甚至,因为事务由多条SQL构成,那么,也会存在执行到一半出错或者不想再执行的情况,那么已经执行的怎么办呢?
比如转账:
sql
-- 张三给李四转 100 元
1. 张三账户扣 100
2. 李四账户加 100这两个操作必须作为一个整体执行:
- 如果两步都成功:提交事务
- 如果中途出错,比如扣款成功但加款失败:回滚事务,恢复到转账前状态
否则就会出现"钱扣了,但对方没收到"的数据异常.
所有,一个完整的事务,绝对不是简单的sql集合,还需要满足如下四个属性:
事务主要用来保证数据库数据的安全性、一致性和可靠性.
它通常有四个特性,也就是常说的 ACID:
| 特性 | 含义 |
|---|---|
| 原子性(Atomicity) | 一个事务中的操作要么全部完成,要么全部不完成 |
| 一致性(Consistency) | 事务前后,数据必须保持正确状态 |
| 隔离性(Isolation) | 多个事务并发执行时,彼此不能随意干扰 |
| 持久性(Durability) | 事务提交后,数据修改会被永久保存 |
MySQL中的简单例子
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE name = '张三';
UPDATE account SET balance = balance + 100 WHERE name = '李四';
COMMIT;如果中途发现异常,可以执行:
sql
ROLLBACK;一句话理解
事务就是数据库为了防止数据"改一半、错一半"而提供的一种安全机制.
2.为什么会出现事务?
事务之所以会出现,是因为数据库操作在真实业务里经常不是"一条 SQL 就能完成",而是一组操作必须作为整体保证正确.
最核心原因有三个:
1.防止操作只执行一半
很多业务操作由多条SQL组成,比如转账:
sql
张三扣 100
李四加 100如果执行完第一步后,数据库宕机、网络断开、程序报错,就会出现:
text
张三的钱扣了
李四的钱没加这就是数据不一致.
所以需要事务保证:
text
要么两步都成功
要么两步都不生效2.防止并发操作互相干扰
数据库通常不是一个人在用,而是很多用户、很多请求同时操作.
比如两个人同时购买最后一件商品:
text
用户 A 查询库存:1
用户 B 查询库存:1
用户 A 下单成功,库存减为 0
用户 B 也下单成功,库存又被减如果没有事务和隔离机制,就可能出现:
text
库存超卖
余额扣错
数据被覆盖
读取到错误数据事务可以配合锁、隔离级别,减少并发导致的数据问题.
3.保证提交后的数据可靠保存
事务提交之后,数据库要尽量保证这次修改不会因为系统异常而丢失.
比如订单支付成功后,订单状态改成"已支付".如果已经提交,数据库就应该保证这个结果被保存下来.
一句话总结
事务出现的根本原因,是为了保证数据库在异常、失败、并发的情况下,数据仍然正确可靠.
也可以理解为:
只要业务操作存在"多步操作"和"并发访问",就需要事务.
3.事务的版本支持
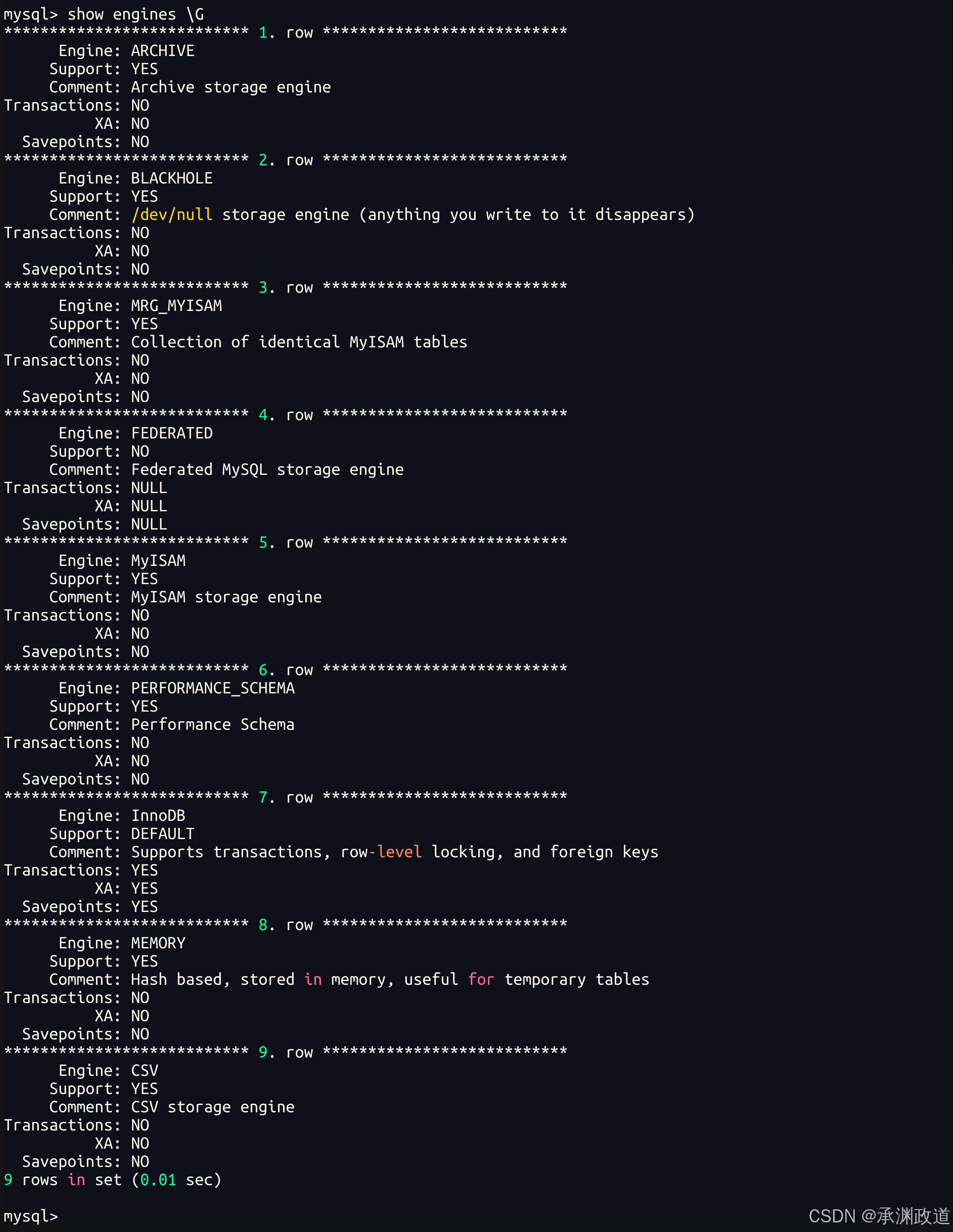
MySQL 是否支持事务,主要不看 MySQL 版本,而是看"存储引擎".
在MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务,MyISAM 不支持.
在MySQL里,真正负责事务能力的是 InnoDB 这类事务型存储引擎;如果表使用的是 MyISAM、MEMORY 等非事务型引擎,即使用 START TRANSACTION,也不能真正回滚这些表的数据.
结论
| 情况 | 是否支持事务 | 说明 |
|---|---|---|
| InnoDB 表 | 支持 | 支持提交、回滚、崩溃恢复,符合 ACID 模型 |
| MyISAM 表 | 不支持 | 执行后立即生效,不能回滚 |
| MEMORY 表 | 不支持 | 主要用于内存临时数据,不支持事务 |
| MySQL 5.5.5 以后 | 默认支持 | 因为默认存储引擎变成 InnoDB |
| MySQL 5.5.5 以前 | 不一定 | 默认多为 MyISAM,需要手动指定 InnoDB |
官方文档中说明,InnoDB 是 MySQL 的事务安全存储引擎,具备 commit、rollback 和崩溃恢复能力;当前MySQL版本中,InnoDB 也是默认且推荐的通用存储引擎.(开发者区1)
一句话总结
MySQL 的事务支持不是单纯由版本决定的,而是由存储引擎决定的;使用 InnoDB 才能真正支持事务.
实际开发中,建议所有核心业务表都使用 InnoDB.
4.事务提交方式
MySQL 事务提交方式主要有三种:自动提交、手动提交、隐式提交.
1.自动提交
MySQL 默认开启自动提交模式,也就是每执行一条 SQL,MySQL 会自动把它当成一个独立事务并立即提交.官方文档也说明,MySQL 默认启用 autocommit,在没有显式开启事务时,每条语句就像被 START TRANSACTION 和 COMMIT 包起来一样执行.
查看自动提交状态:
sql
SELECT @@autocommit;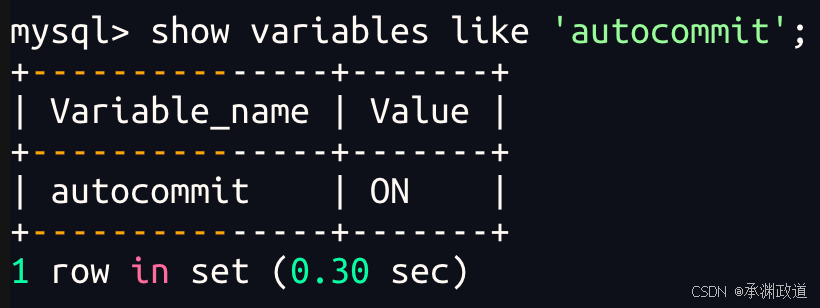
结果为:
text
1表示自动提交已开启.
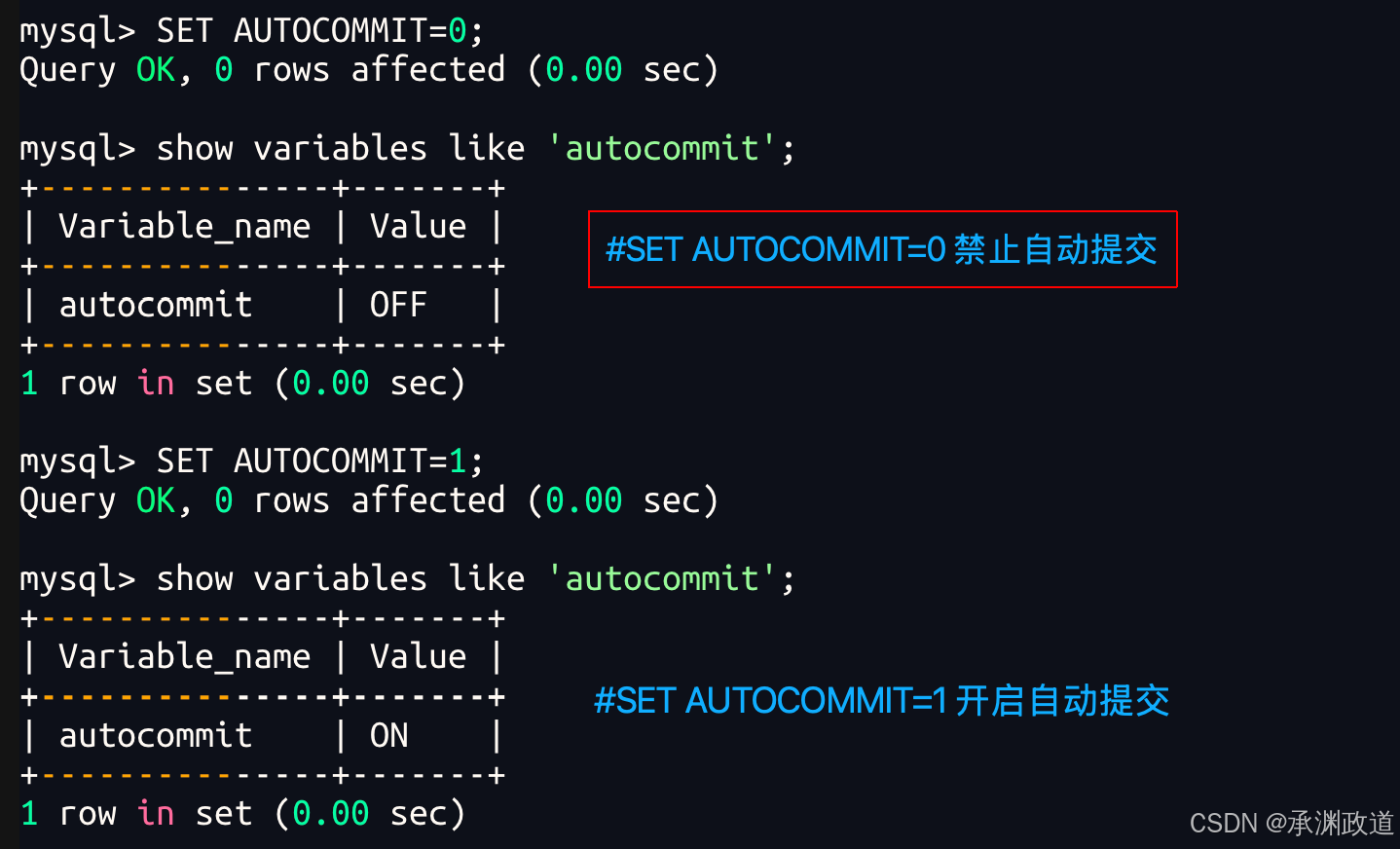
用SET来改变MySQL的自动提交模式:
2.手动提交
手动提交就是先开启事务,然后自己决定提交还是回滚.
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;其中:
sql
COMMIT;表示提交事务,让修改永久生效.
如果中途出错,可以执行:
sql
ROLLBACK;表示回滚事务,撤销本次事务中的修改.MySQL 官方文档明确说明:START TRANSACTION 或 BEGIN 用来开启事务,COMMIT 提交当前事务并让修改永久生效,ROLLBACK 回滚当前事务并取消修改.
3.关闭自动提交后再手动提交
也可以关闭当前会话的自动提交:
sql
SET autocommit = 0;之后执行的SQL不会立即提交,需要手动执行:
sql
COMMIT;或者:
sql
ROLLBACK;示例:
sql
SET autocommit = 0;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;注意:SET autocommit = 0 只影响当前连接会话.关闭自动提交后,事务结束后新的事务会继续自动开始,直到你重新设置:
sql
SET autocommit = 1;MySQL文档说明,当 autocommit 被关闭后,当前会话始终有一个事务处于打开状态,COMMIT 或 ROLLBACK 会结束当前事务,然后新的事务开始.
4.隐式提交
隐式提交是最容易踩坑的地方.
有些SQL会自动触发提交,即使你没有写 COMMIT.例如:
sql
CREATE TABLE test_table (
id INT
);或者:
sql
ALTER TABLE account ADD COLUMN status INT;这类建表、改表、删表语句属于 DDL,通常会导致事务隐式提交.MySQL 官方文档列出了一批会触发隐式提交的语句,包括 CREATE TABLE、ALTER TABLE、DROP TABLE、TRUNCATE TABLE 等.
例如:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
CREATE TABLE log_test (
id INT
);
ROLLBACK;这里你可能以为 ROLLBACK 会撤销前面的 UPDATE,但中间的 CREATE TABLE 可能已经触发了隐式提交,导致前面的修改已经生效.
一句话总结
自动提交适合单条 SQL;手动提交适合多步业务操作;DDL 语句可能触发隐式提交,事务中要尽量避免混用建表、改表、删表等操作.
5.事务常见操作方式
简单银行用户表

这样隔离级别就设置成功了!
创建测试表
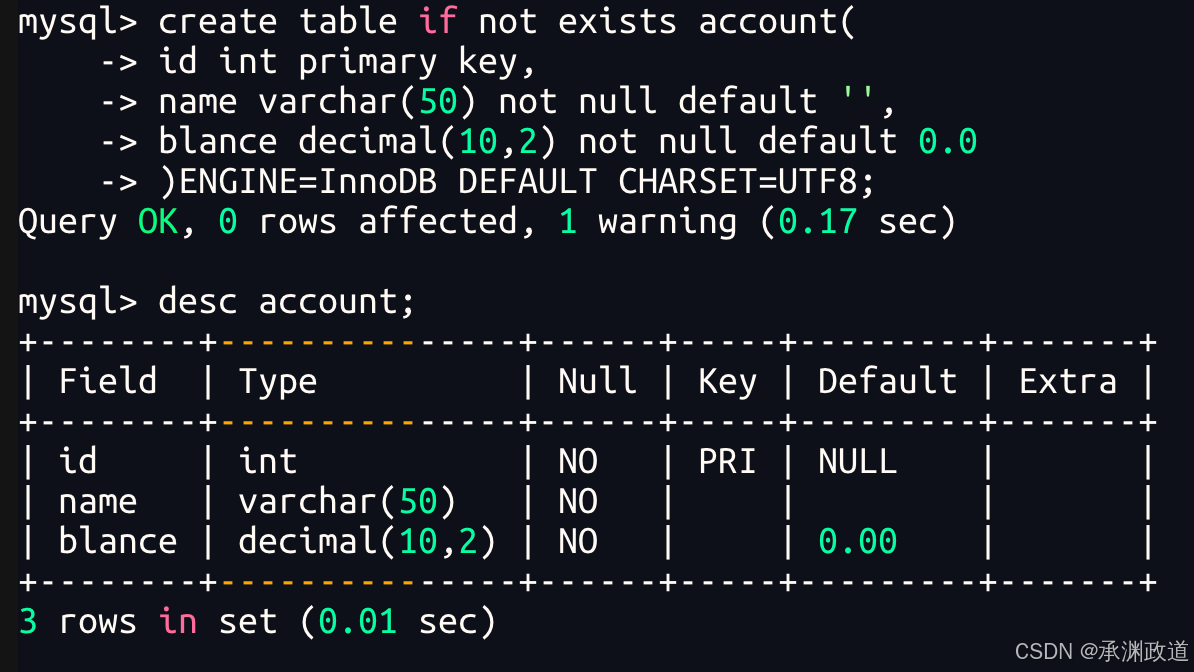
正常演示 - 证明事务的开始与回滚
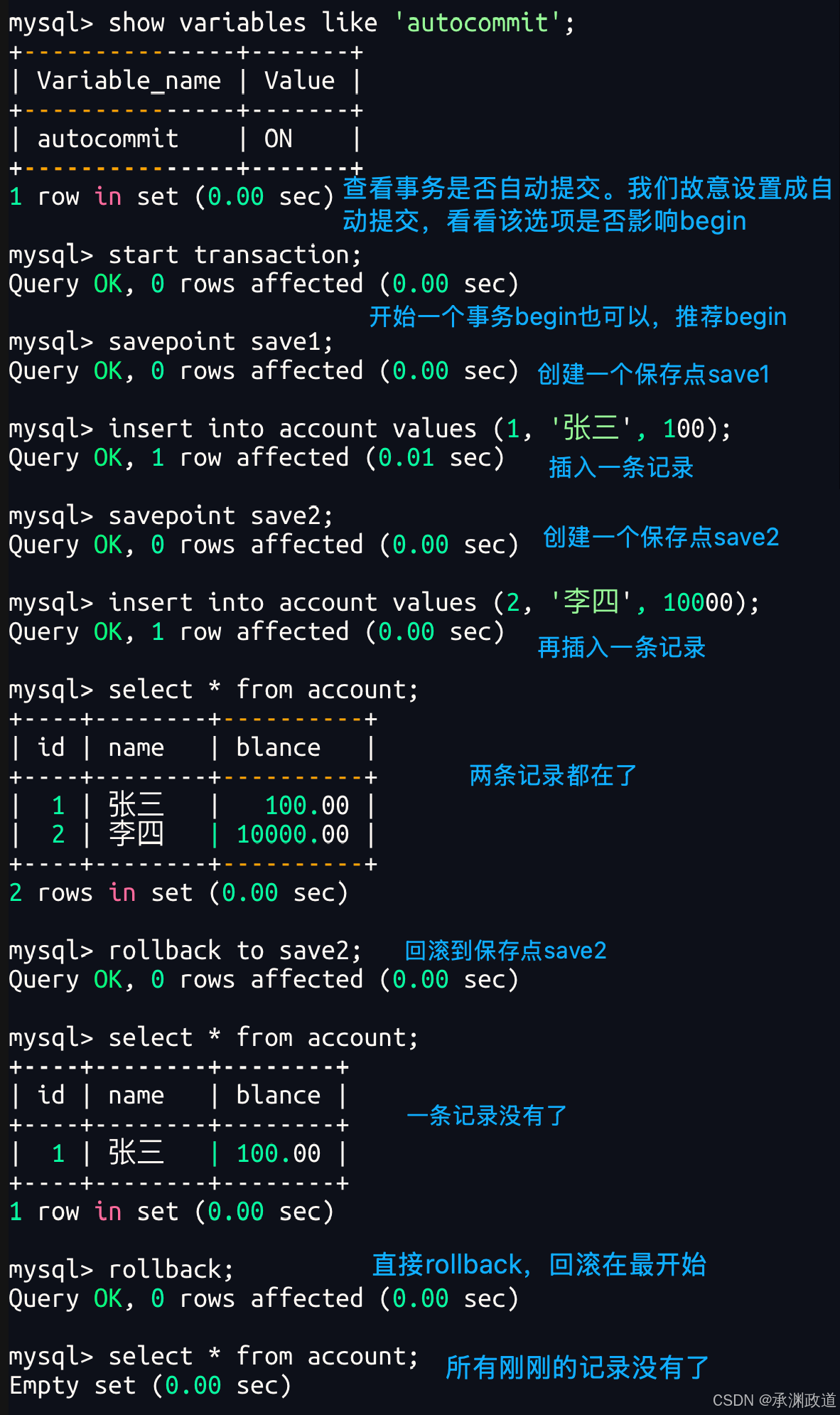
非正常演示1 - 证明未commit,客户端崩溃,MySQL自动会回滚(隔离级别设置为读未提交)
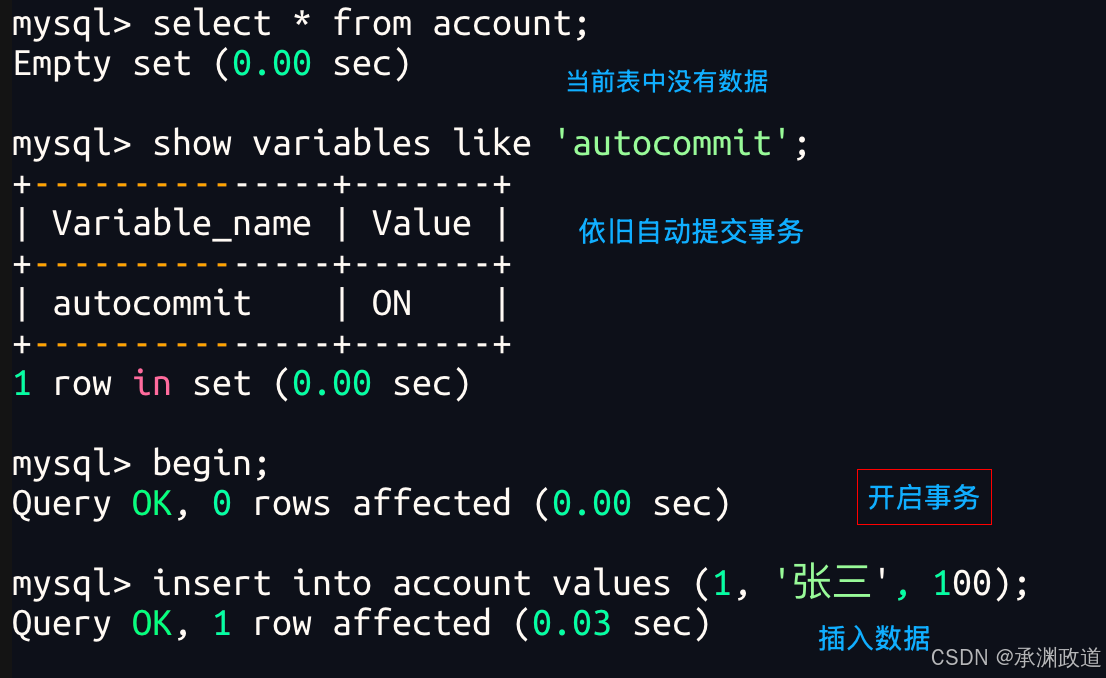
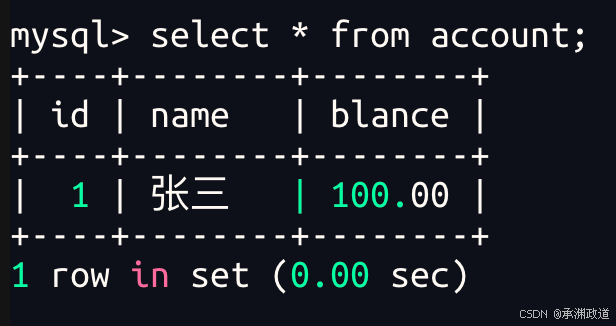
非正常演示2 - 证明commit了,客户端崩溃,MySQL数据不会在受影响,已经持久化
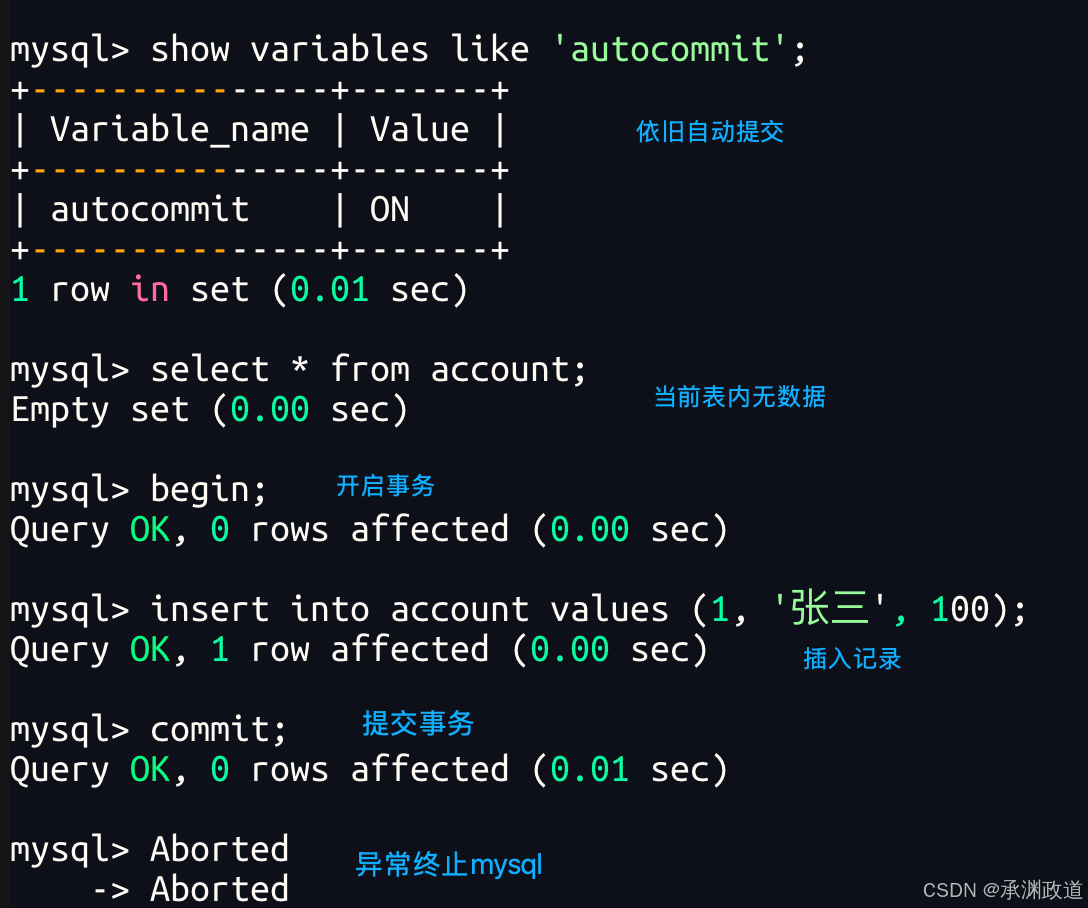
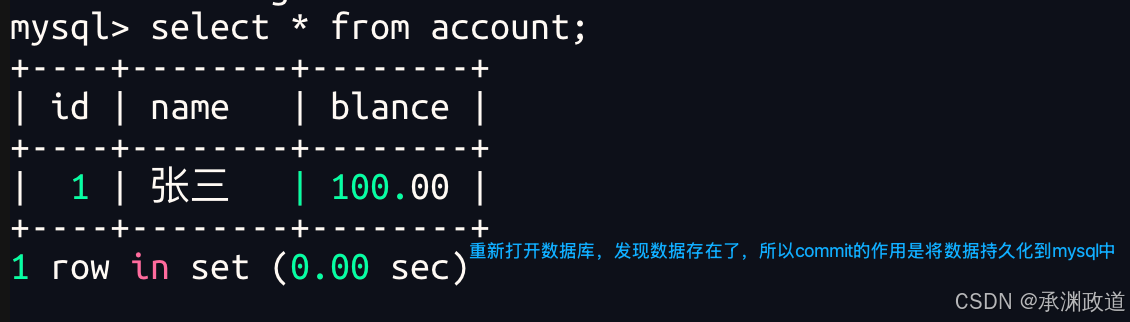
非正常演示3 - 对比试验.证明begin操作会自动更改提交方式,不会受MySQL是否自动提交影响
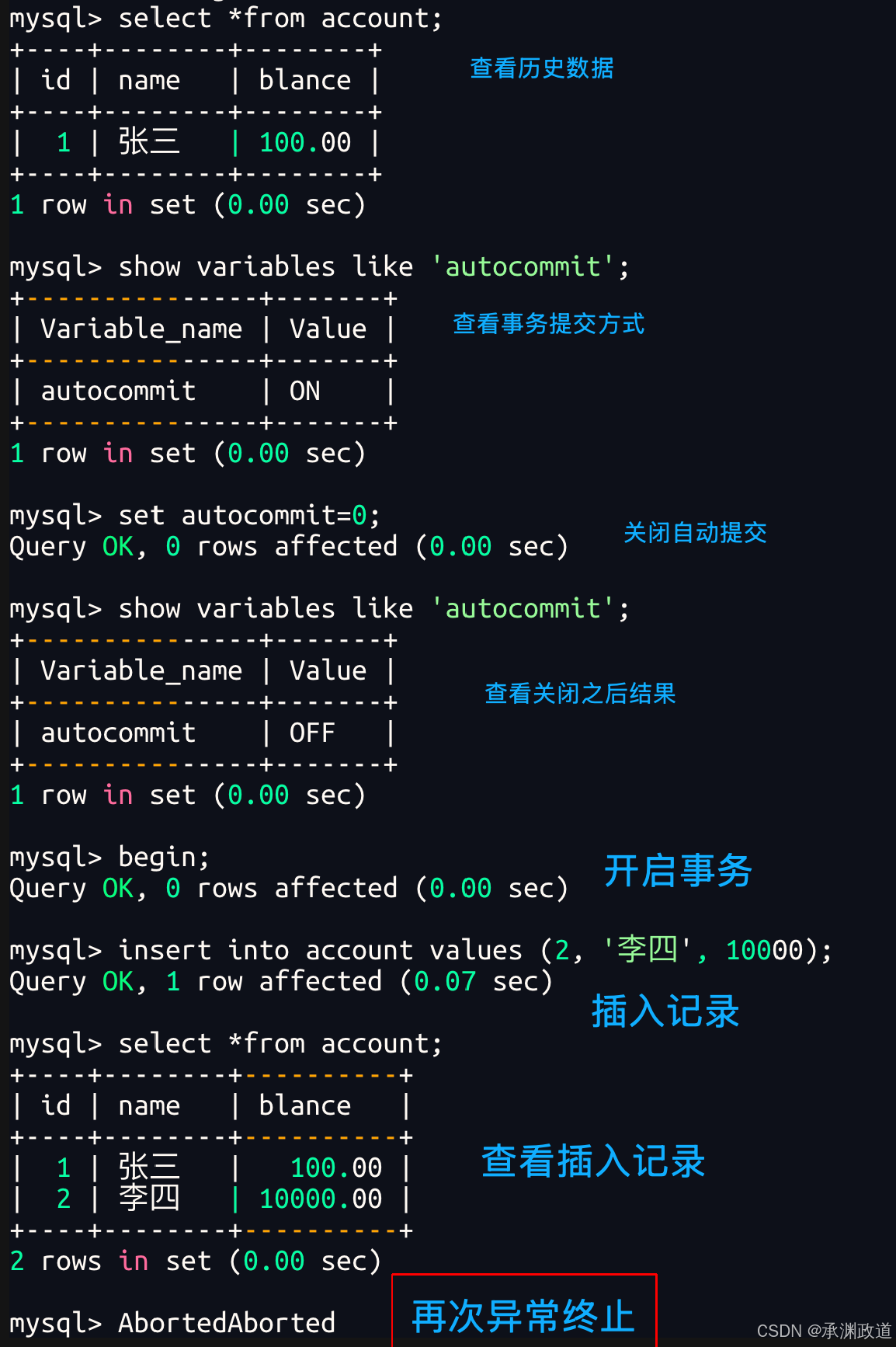

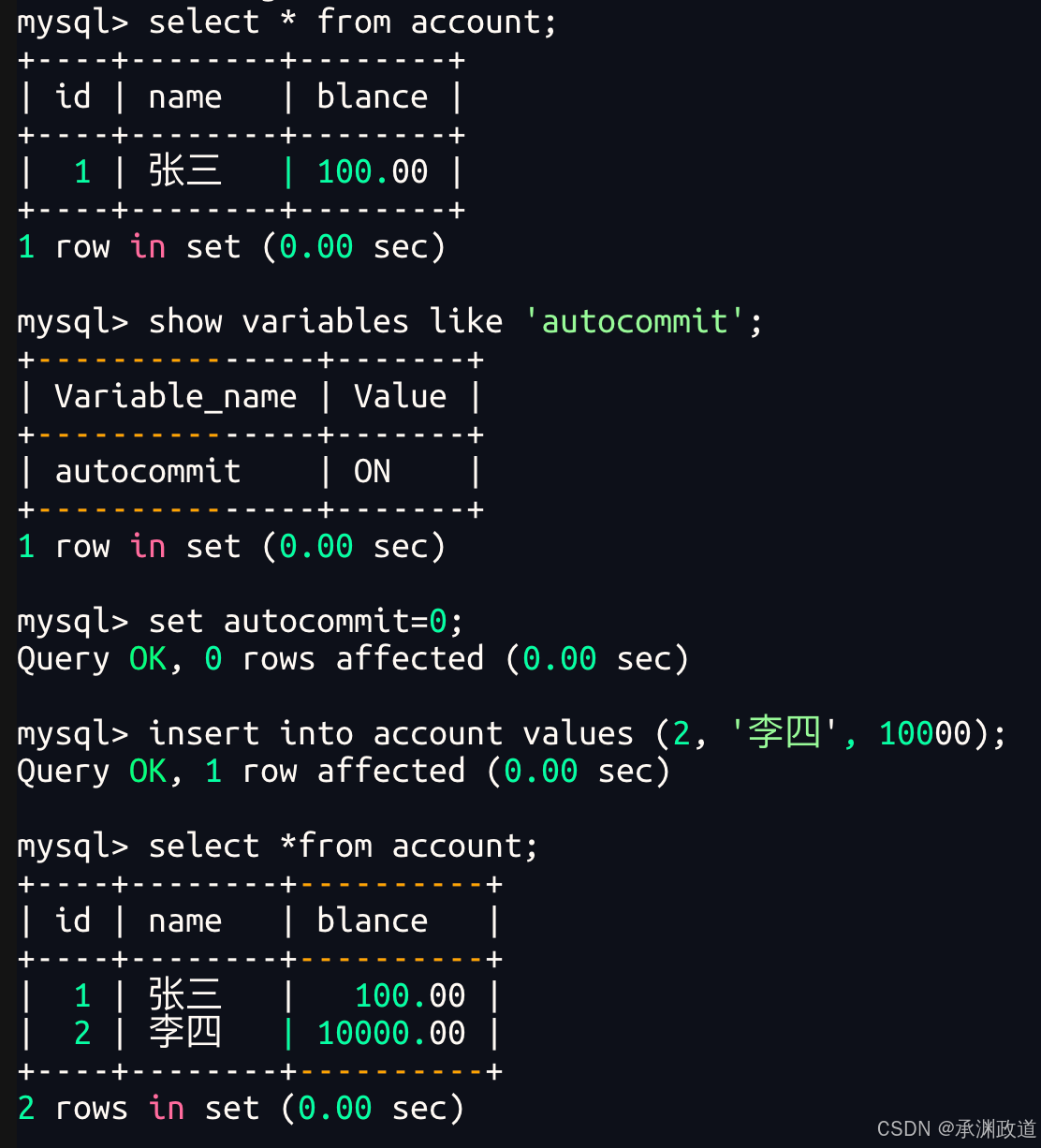
非正常演示4 - 证明单条SQL与事务的关系
实验一
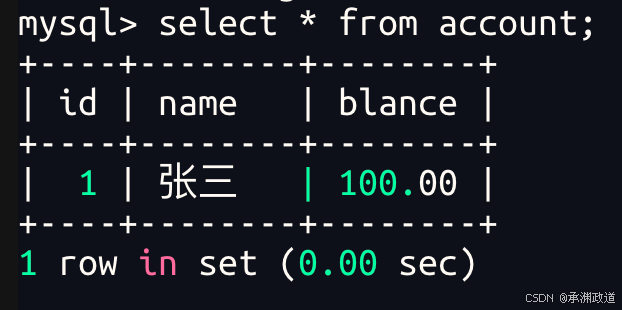
我们可以看到终端崩溃后,重新看表里面的内容就不一样了!
实验二
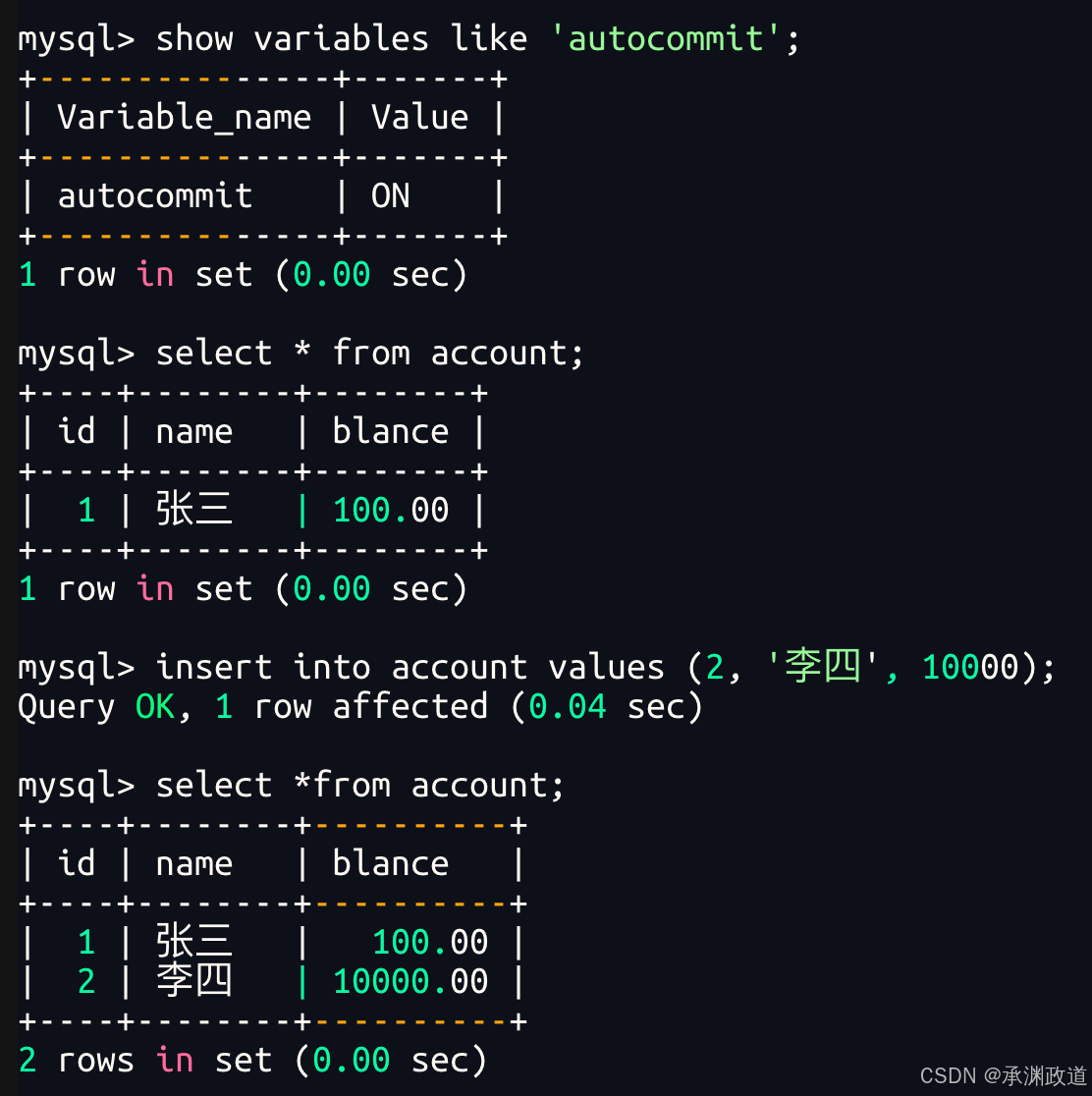
我们可以看到数据库崩溃后,重新登入并不影响,已经持久化.autocommit起作用,插入的数据依旧存在!
总结
事务常见操作方式主要包括:开启事务、提交事务、回滚事务、设置自动提交、使用保存点、设置隔离级别.
在MySQL中,常用事务控制语句包括 SET autocommit、START TRANSACTION、COMMIT、ROLLBACK 等;如果要做部分回滚,还可以使用保存点相关语句.
1.开启事务
常见写法:
sql
START TRANSACTION;也可以写:
sql
BEGIN;示例:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;开启事务后,后续SQL会进入同一个事务中,直到执行提交或回滚.
2.提交事务
提交事务使用:
sql
COMMIT;示例:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;COMMIT 表示确认本次事务中的所有修改,让数据正式生效.
3.回滚事务
回滚事务使用:
sql
ROLLBACK;示例:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
ROLLBACK;ROLLBACK 表示撤销当前事务中的修改,让数据恢复到事务开始前的状态.
4.自动提交
查看自动提交状态:
sql
SELECT @@autocommit;结果为 1 表示开启自动提交,结果为 0 表示关闭自动提交.
关闭自动提交:
sql
SET autocommit = 0;开启自动提交:
sql
SET autocommit = 1;开启自动提交时,通常每条 SQL 执行成功后都会自动提交;关闭自动提交后,需要手动执行 COMMIT 或 ROLLBACK.MySQL 文档也说明,默认会使用自动提交设置,每条 SQL 后会自动提交.
5.保存点操作
保存点可以理解为事务内部的"临时存档点".
创建保存点:
sql
SAVEPOINT sp1;回滚到保存点:
sql
ROLLBACK TO SAVEPOINT sp1;释放保存点:
sql
RELEASE SAVEPOINT sp1;示例:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
SAVEPOINT sp1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
ROLLBACK TO SAVEPOINT sp1;
COMMIT;这段代码的意思是:
第一条修改保留,第二条修改回滚,然后提交事务.
6.设置事务隔离级别
事务隔离级别用于控制多个事务并发执行时,彼此能看到什么数据.
常见写法:
sql
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;MySQL 常见隔离级别有四种:
| 隔离级别 | 含义 |
|---|---|
| 读未提交 | 一个事务可能读到其他事务未提交的数据 |
| 读已提交 | 一个事务只能读到其他事务已经提交的数据 |
| 可重复读 | 同一事务中多次读取同一数据,结果尽量保持一致 |
| 可串行化 | 隔离最严格,事务基本按顺序执行 |
示例:
sql
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
START TRANSACTION;
SELECT * FROM account WHERE id = 1;
COMMIT;MySQL 文档中也将事务隔离级别与 SET TRANSACTION 作为事务控制的重要内容.
7.隐式提交操作
有些 SQL 会导致事务被隐式提交,比如:
sql
CREATE TABLE
ALTER TABLE
DROP TABLE
TRUNCATE TABLE也就是说,即使你没有手动写 COMMIT,执行这些语句时,MySQL 也可能自动结束当前事务.官方文档说明,很多数据定义语言语句会隐式结束当前事务,效果类似在执行该语句前先做了一次提交.
所以事务中一般不建议混入建表、改表、删表这类操作.
一句话总结:
事务常见操作方式就是:先开启事务,执行多条业务 SQL,成功就提交,失败就回滚;复杂场景可以配合保存点、自动提交设置和隔离级别一起使用.
6.事务隔离级别
6.1如何理解隔离性1
- MySQL服务可能会同时被多个客户端进程(线程)访问,访问的方式以事务方式进行.
- 一个事务可能由多条SQL构成,也就意味着,任何一个事务,都有执行前,执行中,执行后的阶段.而所谓的原子性,其实就是让用户层,要么看到执行前,要么看到执行后.执行中出现问题,可以随时回滚.所以单个事务,对用户表现出来的特性,就是原子性.
- 但是,毕竟所有事务都要有个执行过程,那么在多个事务各自执行多个SQL的时候,就还是有可能会出现互相影响的情况.比如:多个事务同时访问同一张表,甚至同一行数据.
- 就如同你妈妈给你说:你要么别学,要学就学到最好.至于你怎么学,中间有什么困难,你妈妈不关心.那么你的学习,对你妈妈来讲,就是原子的.那么你学习过程中,很容易受别人干扰,此时,就需要将你的学习隔离开,保证你的学习环境是健康的.
- 数据库中,为了保证事务执行过程中尽量不受干扰,就有了一个重要特征:隔离性.
- 数据库中,允许事务受不同程度的干扰,就有了一种重要特征:隔离级别.
6.2隔离级别
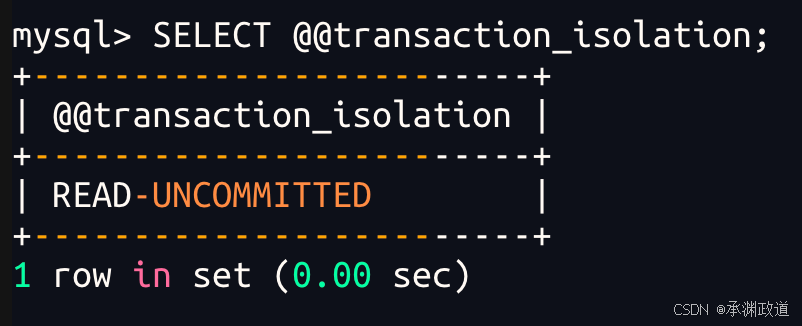
- 读未提交【Read Uncommitted】: 在该隔离级别,所有的事务都可以看到其他事务没有提交的
执行结果.(实际生产中不可能使用这种隔离级别的),但是相当于没有任何隔离性,也会有很多
并发问题,如脏读,幻读,不可重复读等,我们上面为了做实验方便,用的就是这个隔离性. - 读提交【Read Committed】 :该隔离级别是大多数数据库的默认的隔离级别(不是MySQL 默认的).它满足了隔离的简单定义:一个事务只能看到其他的已经提交的事务所做的改变.这种隔离级别会引起不可重复读,即一个事务执行时,如果多次select,可能得到不同的结果.
- 可重复读【Repeatable Read】: 这是 MySQL 默认的隔离级别,它确保同一个事务,在执行
中,多次读取操作数据时,会看到同样的数据行.但是会有幻读问题. - 串行化【Serializable】: 这是事务的最高隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决了幻读的问题.它在每个读的数据行上面加上共享锁.但是可能会导致超时和锁竞争
(这种隔离级别太极端,实际生产基本不使用)
隔离级别如何实现:隔离,基本都是通过锁实现的,不同的隔离级别,锁的使用是不同的.常见有,表锁,行锁,读锁,写锁,间隙锁(GAP),Next-Key锁(GAP+行锁)等.不过,我们目前现有这个认识就行,先关注上层使用.
事务隔离级别 用来控制:多个事务同时执行时,一个事务能不能看到另一个事务正在修改的数据.
隔离级别越高,数据越安全;但并发性能通常越低.
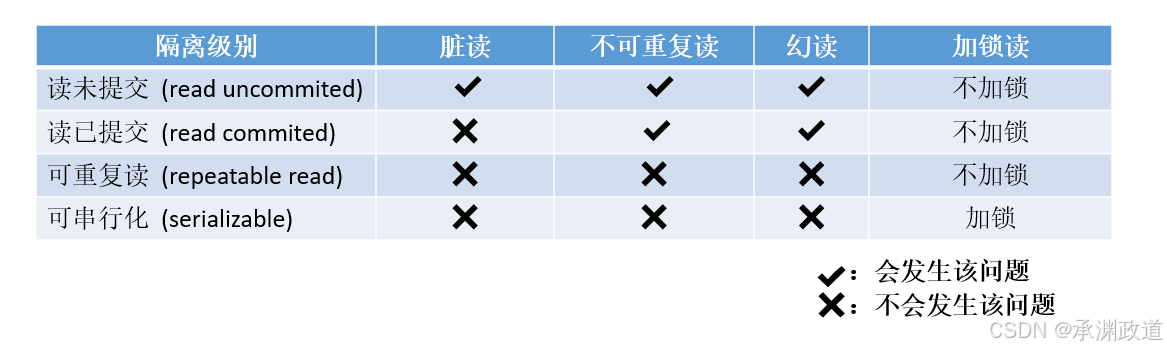
1.四种事务隔离级别
| 隔离级别 | 说明 | 可能出现的问题 |
|---|---|---|
| 读未提交 | 可以读到其他事务还没提交的数据 | 脏读、不可重复读、幻读 |
| 读已提交 | 只能读到其他事务已经提交的数据 | 不可重复读、幻读 |
| 可重复读 | 同一个事务中多次读取同一数据,结果保持一致 | 理论上可能幻读 |
| 串行化 | 事务基本按顺序执行,隔离最严格 | 性能最低,并发能力差 |
MySQL InnoDB 默认隔离级别是:
sql
REPEATABLE READ也就是:可重复读.
2.三个并发问题
1)脏读
一个事务读到了另一个事务还没有提交的数据.
例如:
text
事务 A:把余额从 1000 改成 500,但还没提交
事务 B:读到了余额 500
事务 A:回滚,余额恢复成 1000这时事务 B 读到的 500 就是脏数据.
读未提交会出现脏读.
2)不可重复读
同一个事务中,两次读取同一条数据,结果不一样.
例如:
text
事务 A:第一次读取余额 = 1000
事务 B:把余额改成 800,并提交
事务 A:第二次读取余额 = 800事务 A 两次读取结果不同,这就是不可重复读.
读已提交可能出现不可重复读.
3)幻读
同一个事务中,两次范围查询,查到的记录数量不一样.
例如:
text
事务 A:查询余额大于 1000 的用户,有 3 条
事务 B:新增一条余额 2000 的用户,并提交
事务 A:再次查询余额大于 1000 的用户,变成 4 条像"凭空多出来一条数据",所以叫幻读.
3.各隔离级别解决了什么问题?
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能出现 | 可能出现 | 可能出现 |
| 读已提交 | 避免 | 可能出现 | 可能出现 |
| 可重复读 | 避免 | 避免 | MySQL InnoDB 中大多数场景可避免 |
| 串行化 | 避免 | 避免 | 避免 |
4.MySQL 中查看隔离级别
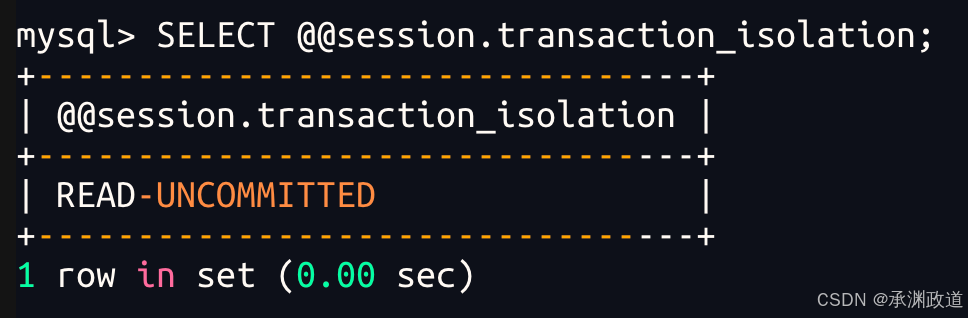
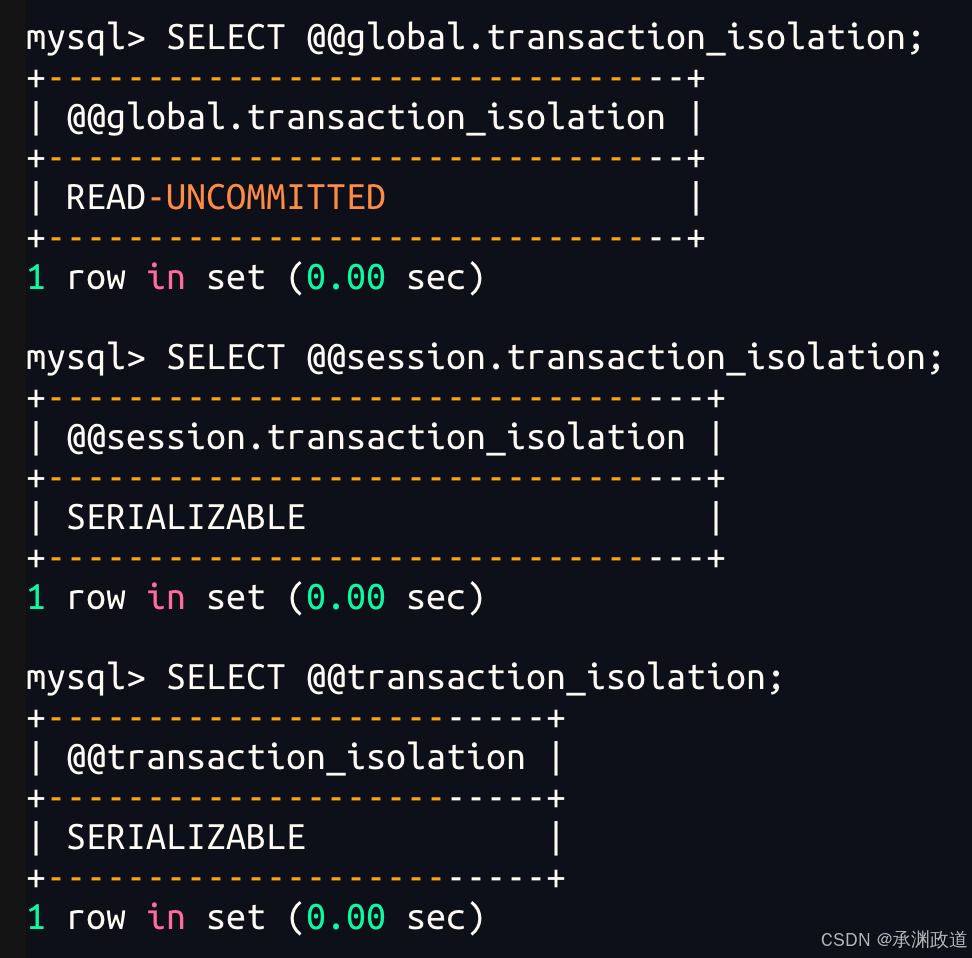
查看当前会话隔离级别:
sql
SELECT @@session.transaction_isolation;查看全局隔离级别:
sql
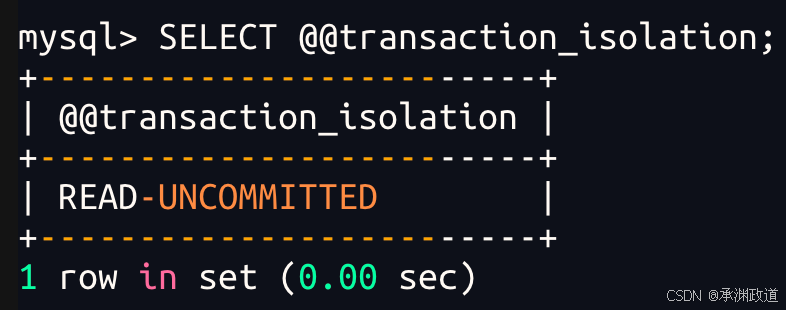
SELECT @@global.transaction_isolation;也可以直接查看当前连接:
sql
SELECT @@transaction_isolation;5.设置事务隔离级别
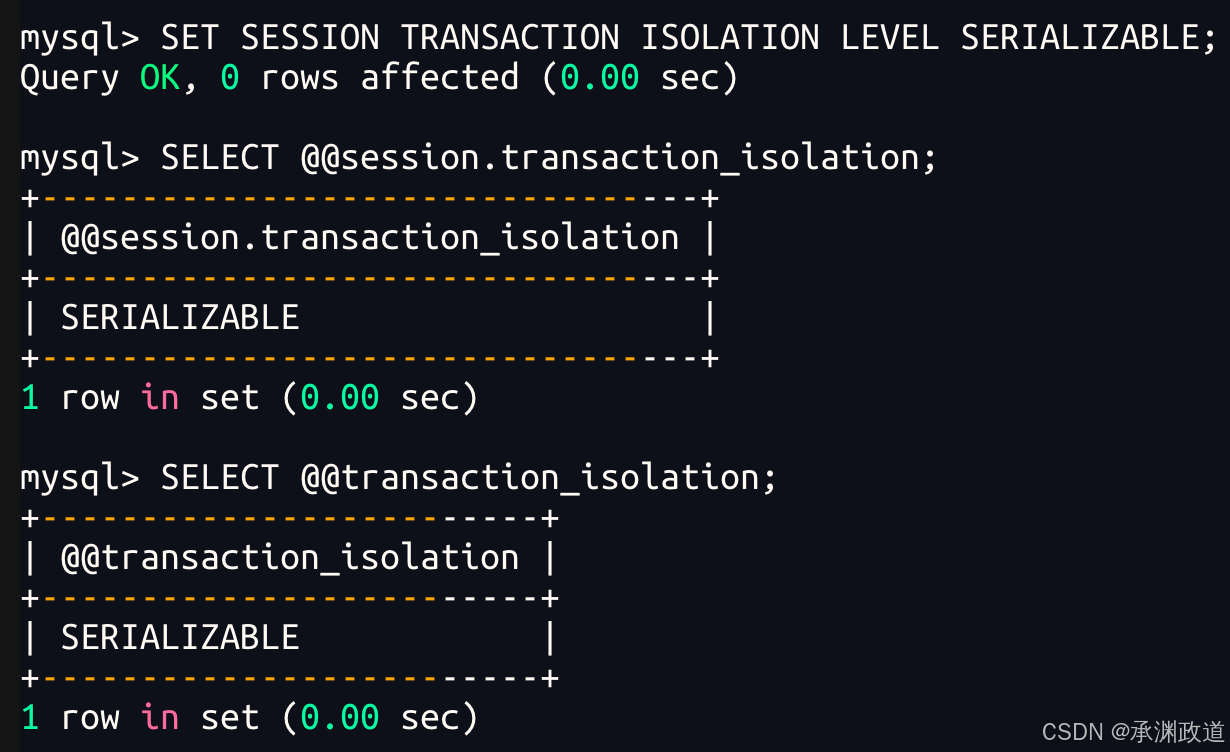
设置当前会话:
sql
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
sql
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
sql
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
sql
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;设置全局隔离级别:
sql
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;注意:全局设置通常只影响新连接,不会立刻影响当前已经打开的连接.
一句话总结
事务隔离级别就是数据库用来控制并发事务之间"能看到什么数据"的规则.
隔离级别越低,并发性能越好,但数据异常风险越高;隔离级别越高,数据越安全,但并发性能越差.
6.3查看与设置隔离性
查看全局隔级别
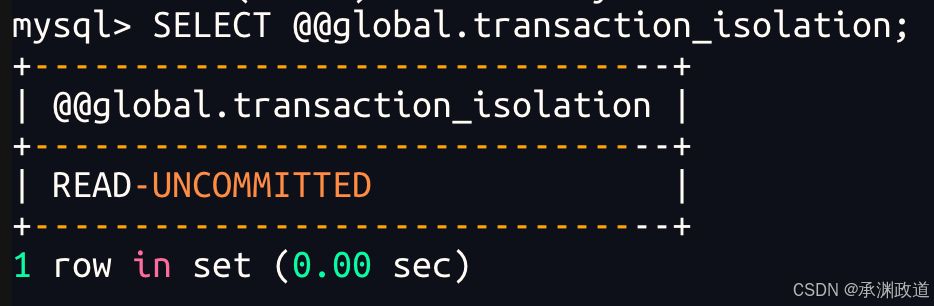
查看会话(当前)全局隔级别
设置当前会话 or 全局事务隔离级别语法
SET SESSION \| GLOBAL TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE };
设置当前会话隔离级别,只影响当前连接,不影响其他连接
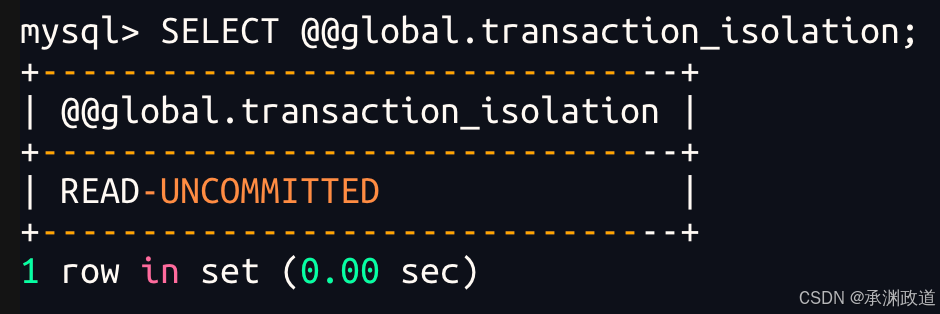
设置全局隔离级别,之后新创建的会话会受到影响

6.4读未提交【Read Uncommitted】
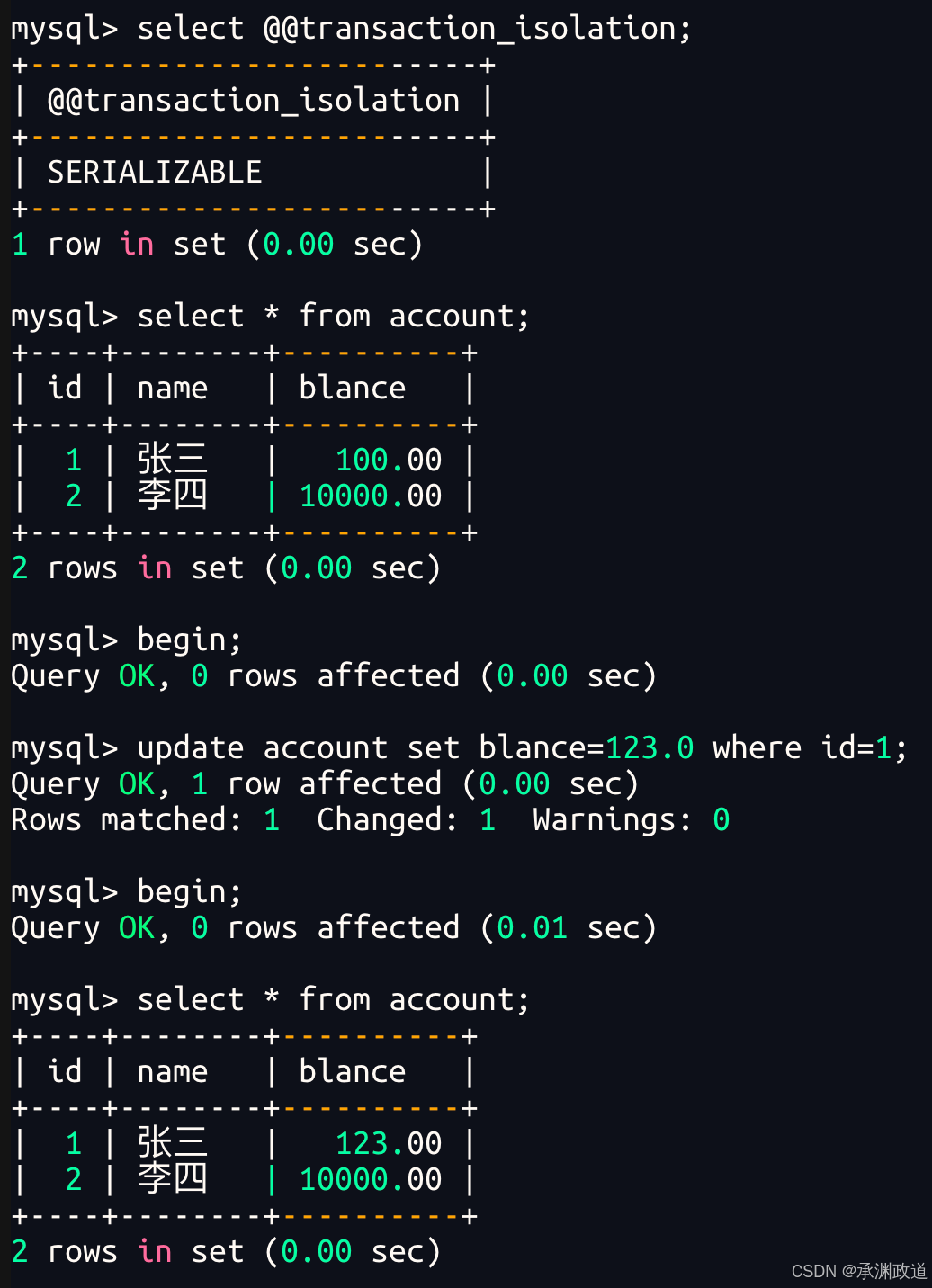
一个事务在执行中,读到另一个执行中事务的更新(或其他操作)但是未commit的数据,这种现象叫做脏读(dirty read).
6.5读提交【Read Committed】
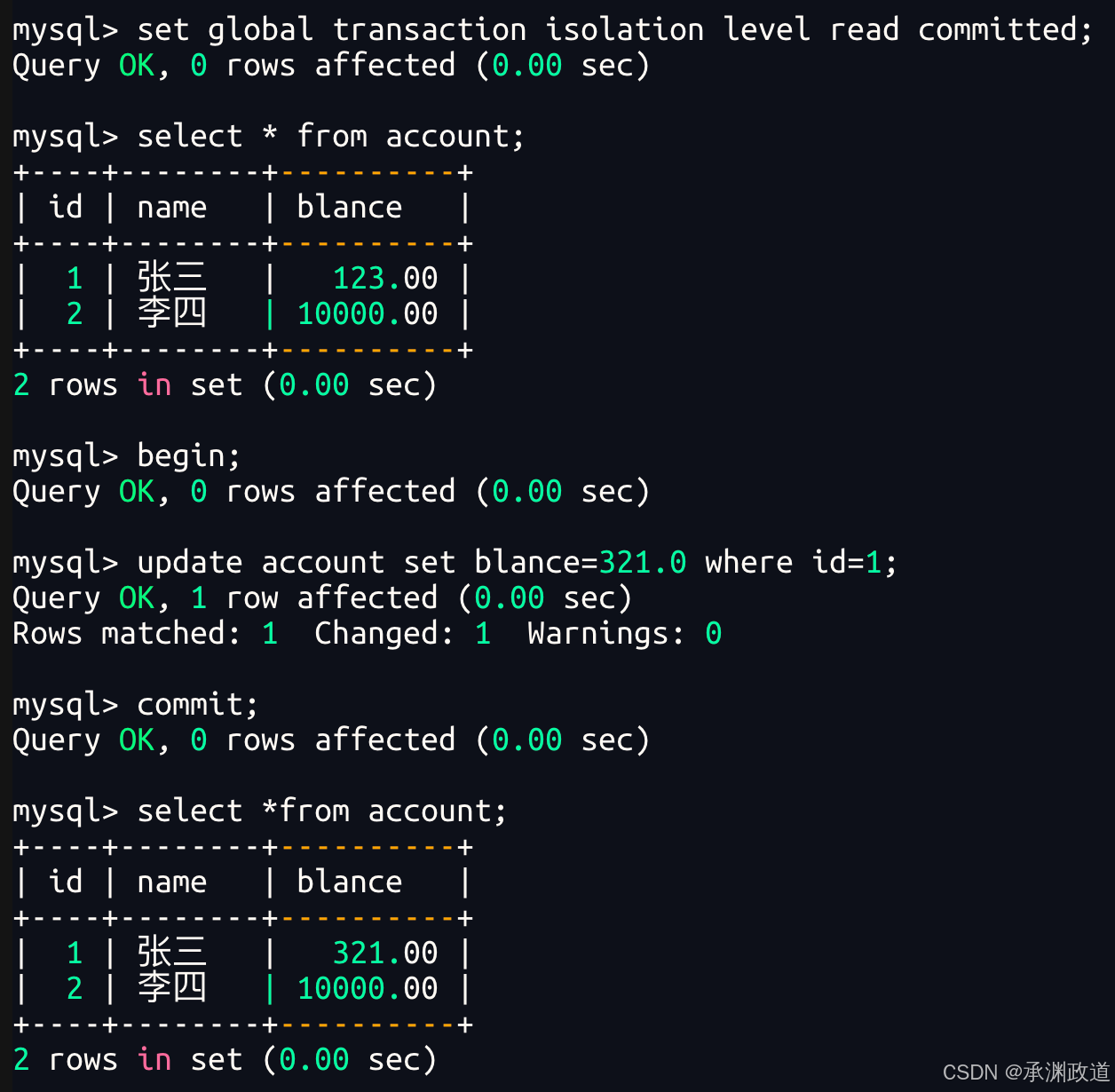
commit之后,看到了!但是,此时还在当前事务中,并未commit,那么就造成了,同一个事务内,同样的读取,在不同的时间段(依旧还在事务操作中!),读取到了不同的值,这种现象叫做不可重复读(non reapeatable read)
6.6可重复读【Repeatable Read】
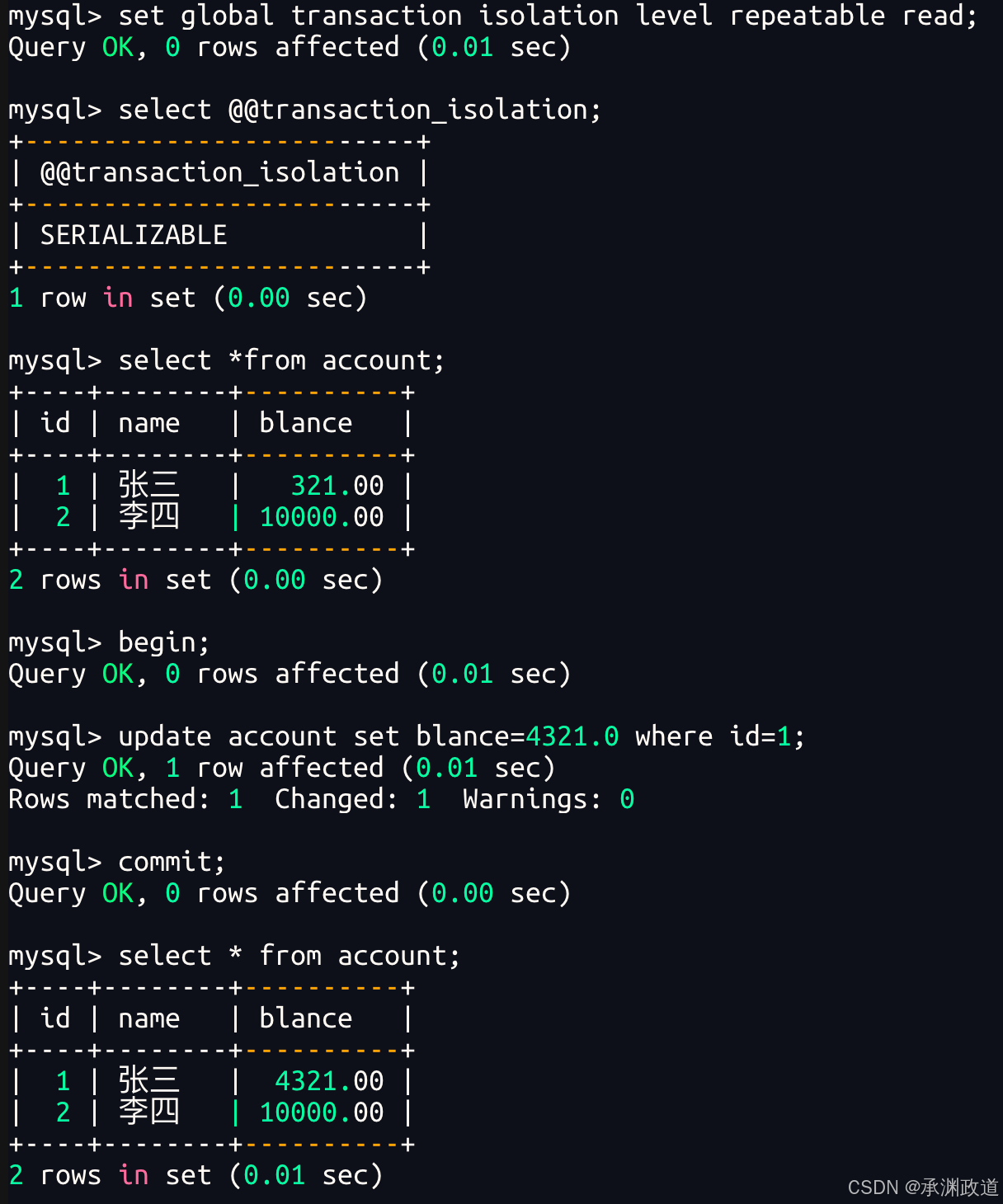
如果将上面的update操作,改成insert操作,会有什么问题?
多次查看,发现终端A在对应事务中insert的数据,在终端B的事务周期中,也没有什么影响,也符合可重复的特点.但是,一般的数据库在可重复读情况的时候,无法屏蔽其他事务insert的数据(为什么?因为隔离性实现是对数据加锁完成的,而insert待插入的数据因为并不存在,那么一般加锁无法屏蔽这类问题),会造成虽然大部分内容是可重复读的,但是insert的数据在可重复读情况被读取出来,导致多次查找时,会多查找出来新的记录,就如同产生了幻觉.这种现象,叫做幻读(phantom read).很明显,MySQL在RR级别的时候,是解决了幻读问题的(解决的方式是用Next-Key锁(GAP+行锁)解决的.这块比较难,有兴趣可以了解一下.
6.7串行化【serializable】
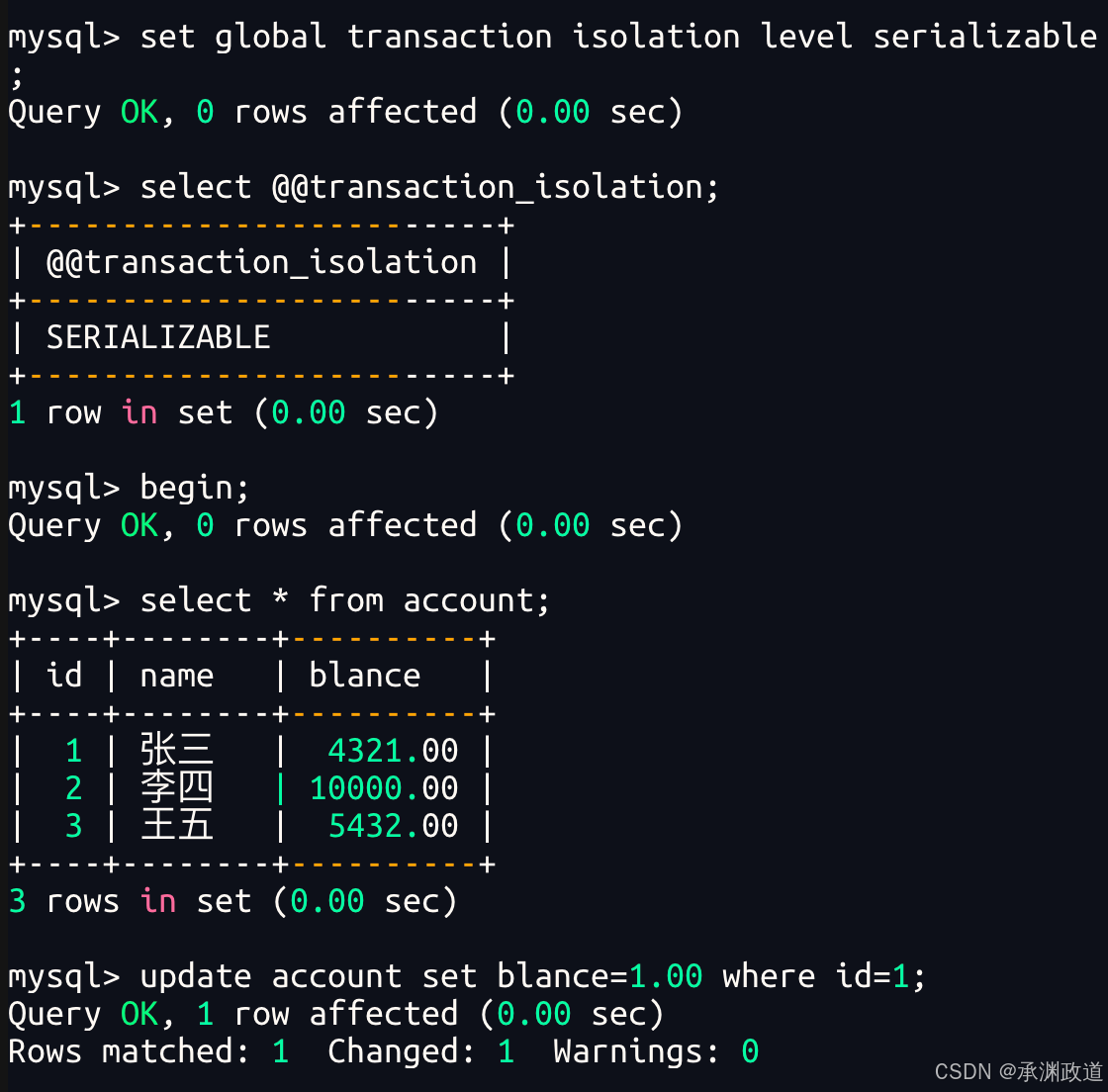
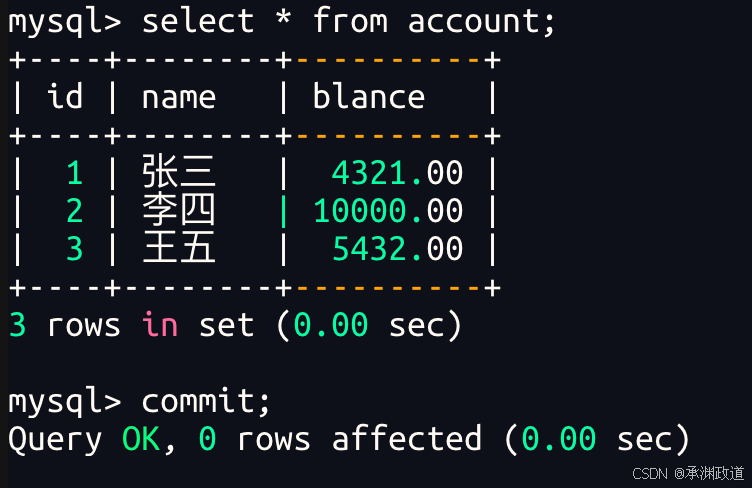
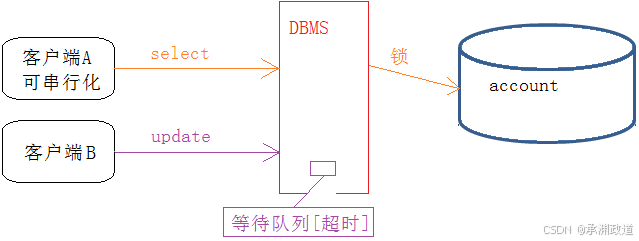
总结:
- 其中隔离级别越严格,安全性越高,但数据库的并发性能也就越低,往往需要在两者之间找一个平衡点.
- 不可重复读的重点是修改和删除:同样的条件,你读取过的数据,再次读取出来发现值不一样了幻读的重点在于新增:同样的条件,第1次和第2次读出来的记录数不一样.
- 说明: mysql 默认的隔离级别是可重复读,一般情况下不要修改.
上面的例子可以看出,事务也有长短事务这样的概念.事务间互相影响,指的是事务在并行执行的
时候,即都没有commit的时候,影响会比较大.
6.8一致性【Consistency】
事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态.当数据库只包含事务
成功提交的结果时,数据库处于一致性状态.如果系统运行发生中断,某个事务尚未完成而被迫中
断,而改未完成的事务对数据库所做的修改已被写入数据库,此时数据库就处于一种不正确(不一
致)的状态.因此一致性是通过原子性来保证的.其实一致性和用户的业务逻辑强相关,一般MySQL提供技术支持,但是一致性还是要用户业务逻辑做支撑,也就是,一致性,是由用户决定的.而技术上,通过AID保证C.
7.推荐阅读
如何实现事务的隔离性:https://www.jianshu.com/p/398d788e1083
Innodb中的事务隔离级别和锁的关系:https://tech.meituan.com/2014/08/20/innodb-lock.html
Mysql 间隙锁原理,以及Repeatable Read隔离级别下可以防止幻读原理:https://www.cnblogs.com/aspirant/p/9177978.html

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容
每日心灵鸡汤: 在向上的路上,遇见更好的自己!
人生从来不是一条笔直的路.有人在春风得意时看见远方,也有人在风雨兼程中学会坚强.真正决定一个人能走多远的,不是某一刻的顺境,而是在逆境中是否还愿意抬头,在平凡中是否依然相信奋斗的意义.生活不会总是鲜花铺路,也不会永远风平浪静.很多时候,所谓成长,就是在一次次跌倒后重新站起,在一次次失望后依旧热爱,在看清生活的真实之后,仍然选择认真生活.不要害怕暂时的慢,也不要否定当下的自己.山有顶峰,湖有彼岸,人生也有属于自己的节奏.只要方向是向前的,哪怕脚步小一点,也是在靠近更好的明天.把每一个普通的日子过扎实,把每一次微小的努力做到位.时间会把坚持酿成收获,也会把沉淀变成底气.愿你在平凡中坚守,在热爱中奔赴,在岁月的磨砺里,活成一个内心有光、脚下有路、眼里有希望的人.
