
请君浏览
-
- 前言
- [一、TCP 协议段格式------20 字节的结构化契约](#一、TCP 协议段格式——20 字节的结构化契约)
-
- [1.1 六个标志位------TCP 的六种"表情"](#1.1 六个标志位——TCP 的六种"表情")
- [1.2 Linux 内核中的 TCP 头部](#1.2 Linux 内核中的 TCP 头部)
- [1.3 TCP 选项------报文段头部的"扩展槽"](#1.3 TCP 选项——报文段头部的"扩展槽")
- 二、确认应答与超时重传------可靠性的两大基石
-
- [2.1 序列号与确认号:TCP 的对话语言](#2.1 序列号与确认号:TCP 的对话语言)
- [2.2 超时重传------当 ACK 没有回来](#2.2 超时重传——当 ACK 没有回来)
- [2.3 RTO 如何确定------指数退避](#2.3 RTO 如何确定——指数退避)
- 三、连接管理------三次握手、四次挥手与状态机
-
- [3.1 三次握手------为什么不是两次也不是四次](#3.1 三次握手——为什么不是两次也不是四次)
- [3.2 TCP 完整状态机](#3.2 TCP 完整状态机)
- [3.3 四次挥手------为什么比握手多一次](#3.3 四次挥手——为什么比握手多一次)
- [3.4 TIME_WAIT------为什么等 2MSL](#3.4 TIME_WAIT——为什么等 2MSL)
- [3.5 CLOSE_WAIT------代码 BUG 的指示灯](#3.5 CLOSE_WAIT——代码 BUG 的指示灯)
- [3.6 同时打开与同时关闭------状态机的两个"彩蛋"](#3.6 同时打开与同时关闭——状态机的两个"彩蛋")
- 四、滑动窗口与流量控制------从"停等"到"流水线",按对方的胃容量上菜
-
- [4.1 为什么需要滑动窗口](#4.1 为什么需要滑动窗口)
- [4.2 窗口中的丢包------快重传](#4.2 窗口中的丢包——快重传)
- [4.3 窗口大小与吞吐量](#4.3 窗口大小与吞吐量)
- [4.4 流量控制------按对方的胃容量上菜](#4.4 流量控制——按对方的胃容量上菜)
- [4.5 延迟应答与捎带应答------让 ACK 更高效](#4.5 延迟应答与捎带应答——让 ACK 更高效)
- [五、拥塞控制------TCP 的公德心](#五、拥塞控制——TCP 的公德心)
-
- [5.1 发送窗口 = min(拥塞窗口 cwnd, 接收窗口 rwnd)](#5.1 发送窗口 = min(拥塞窗口 cwnd, 接收窗口 rwnd))
- [5.2 拥塞控制的四个阶段](#5.2 拥塞控制的四个阶段)
- 六、面向字节流与异常处理------粘包根源与连接消亡
-
- [6.1 面向字节流------TCP 的"粘包"根源](#6.1 面向字节流——TCP 的"粘包"根源)
- [6.2 TCP 异常处理------连接如何意外消亡](#6.2 TCP 异常处理——连接如何意外消亡)
- 七、实战与工程------抓包、连接池与面试拷打
-
- [7.1 tcpdump 实战------亲眼看到报文段](#7.1 tcpdump 实战——亲眼看到报文段)
- [7.2 生产实践------TCP 连接池与短连接优化](#7.2 生产实践——TCP 连接池与短连接优化)
- [7.3 面试高频:用 UDP 实现可靠传输](#7.3 面试高频:用 UDP 实现可靠传输)
- 总结
- 尾声
前言
在 TCP Socket 编程中,我们用了
listen、accept、connect、read、write,感受了 TCP 带来的可靠性------数据不会丢、顺序不会乱、连接确认建立后才开始发送。但这些可靠性不是免费的。TCP 为此付出的代价是协议层最复杂的实现:确认应答、超时重传、滑动窗口、流量控制、拥塞控制、四次挥手状态机、TIME_WAIT......本篇从传输层协议视角深挖 TCP 的内核机制。我们不再写代码,而是回答更根本的问题:TCP 报文段长什么样?序列号和确认号是如何工作的?什么叫"三次握手"------为什么不是两次也不是四次?滑动窗口和拥塞窗口有什么区别?TIME_WAIT 为什么等 2MSL?读完本文,你将对 TCP 的理解从"会用 API"升级到"真正懂协议"。
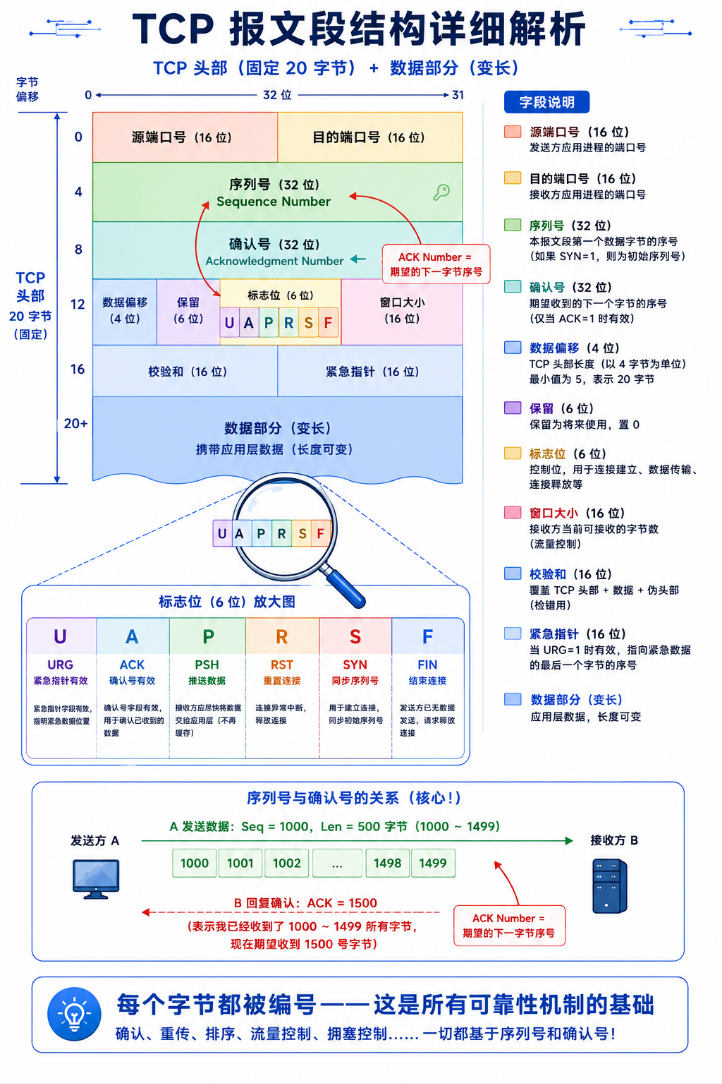
一、TCP 协议段格式------20 字节的结构化契约
在深入 TCP 协议头之前,有必要先回答一个根本问题:为什么 TCP 需要这么复杂的协议头,而 UDP 只需要 8 字节? 答案在于两者的设计目标完全不同。UDP 的设计目标是"最小化开销"------只要能区分不同的进程(端口号)就够了。TCP 的设计目标是"在不可靠的 IP 网络之上提供可靠的字节流传输"------这要求协议层自己处理丢包、乱序、流量控制,而每一项功能都需要在协议头中携带相应的控制信息。序列号(32 位)用来探测丢包和乱序,确认号(32 位)用来反馈接收状况,窗口大小(16 位)用来动态调整发送速率,六个标志位用来管理连接的生命周期。这 20 字节不是冗余,而是 TCP 承诺"不丢数据、不乱顺序、不超对方承受能力"的代价。理解了为什么每个字段存在,你就理解了 TCP 的每一个设计决策。
TCP 报文段 = 固定头部(20 字节)+ 选项(最多 40 字节)+ 数据。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
├───────────────┴───────────────┼───────────────┴───────────────┤
│ 源端口号 (16) │ 目的端口号 (16) │
├───────────────────────────────┼───────────────────────────────┤
│ 32 位序列号 (Sequence Number) │
├───────────────────────────────┼───────────────────────────────┤
│ 32 位确认序列号 (ACK Number) │
├─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┼─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┤
│ 头部长度 │保留│U│A│P│R│S│F│ │ 紧急指针 (16) │
│ (4) │(6) │R│C│S│S│Y│I│ 窗口大小 (16) │ │
│ │ │G│K│H│T│N│N│ │ │
├─────────┴────┴─┴─┴─┴─┴─┴─┴─┴─────────────────┴──────────────────┤
│ 16 位校验和 (Checksum) │
├─────────────────────────────────────────────────────────────────┤
│ 16 位紧急指针 (Urgent Pointer) │
├─────────────────────────────────────────────────────────────────┤
│ 选项 (Options, 最多 40 字节,可选) │
└─────────────────────────────────────────────────────────────────┘| 字段 | 位宽 | 含义 | 备注 |
|---|---|---|---|
| 源端口号 | 16 位 | 发送进程端口 | 与 UDP 一致 |
| 目的端口号 | 16 位 | 接收进程端口 | 与 UDP 一致 |
| 32 位序列号 | 32 位 | 本报文段所发送数据的第一个字节的序号 | TCP 核心机制------每个字节都有编号 |
| 32 位确认序列号 | 32 位 | 期望收到对方下一个报文段的第一个字节序号 | "序号 N-1 之前的我都收了,下次从 N 开始发" |
| 头部长度(doff) | 4 位 | TCP 头部有多少个 4 字节(32 位字) | 最小 5(20 字节),最大 15(60 字节) |
| 保留位 | 6 位 | 保留供未来扩展 | 目前全 0 |
| 6 位标志位 | 6 位 | URG/ACK/PSH/RST/SYN/FIN | 每个标志位控制一种 TCP 行为 |
| 窗口大小 | 16 位 | 接收方当前可用的接收缓冲区大小 | 流量控制的核心------"我能吃多少" |
| 校验和 | 16 位 | 校验首部+数据的完整性 | TCP 的校验和是强制计算(UDP 可选) |
| 紧急指针 | 16 位 | 标识紧急数据在报文段中的偏移量 | 仅 URG=1 时有效,现代应用很少使用 |
1.1 六个标志位------TCP 的六种"表情"
| 标志位 | 全称 | 含义 | 何时设置 |
|---|---|---|---|
| SYN | Synchronize | 请求建立连接,同步初始序列号 | 三次握手的第一、第二步 |
| ACK | Acknowledgment | 确认号字段有效 | 连接建立后几乎所有报文段都带 ACK |
| FIN | Finish | 请求断开连接,不再发送数据 | 四次挥手 |
| RST | Reset | 强制重置连接 | 收到不存在的连接的报文、端口未监听等异常 |
| PSH | Push | 提示接收方尽快将数据交给应用层,不要缓存 | 发送方认为数据应立即被应用层处理 |
| URG | Urgent | 紧急指针字段有效 | 带外数据(极少使用) |
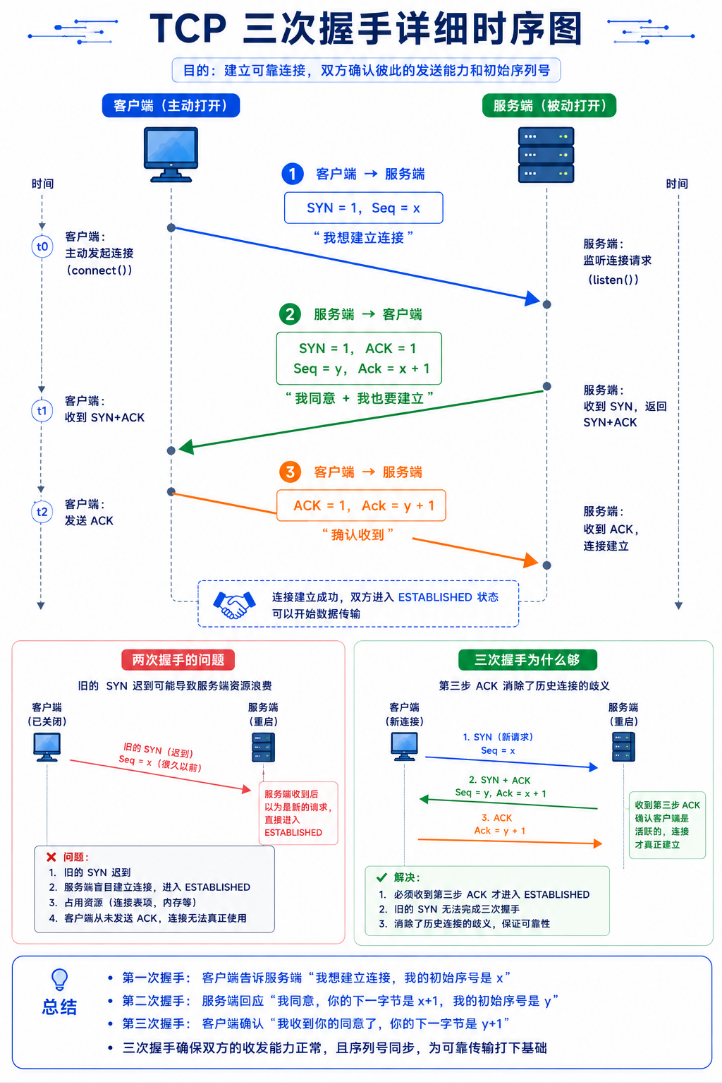
ACK 是一个特殊的标志------除了第一个 SYN 报文(纯 SYN,不带 ACK),TCP 连接中几乎所有后续报文都带着 ACK。理解了这个,你就理解了为什么"三次握手"的第二步是 SYN+ACK(两个标志位同时置 1):回复客户端的 SYN 的同时,也确认自己收到了 SYN。
1.2 Linux 内核中的 TCP 头部
cpp
// linux kernel: include/linux/tcp.h
struct tcphdr {
__be16 source; // 源端口号
__be16 dest; // 目的端口号
__be32 seq; // 32 位序列号
__be32 ack_seq; // 32 位确认序列号
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4, // 保留位
doff:4, // 头部长度(4 字节为单位)
fin:1, // FIN 标志位
syn:1, // SYN 标志位
rst:1, // RST 标志位
psh:1, // PSH 标志位
ack:1, // ACK 标志位
urg:1, // URG 标志位
ece:1, // ECN-Echo(显式拥塞通知)
cwr:1; // CWR(拥塞窗口减小)
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4, res1:4, cwr:1, ece:1, urg:1, ack:1, psh:1, rst:1, syn:1, fin:1;
#endif
__be16 window; // 窗口大小
__sum16 check; // 校验和
__be16 urg_ptr; // 紧急指针
};看到
#if defined(__LITTLE_ENDIAN_BITFIELD)了吗?同一个结构体在小端和大端机器上的位域排列顺序不同------小端下 fin 到 urg 的顺序是反的。这就是 23 篇 UDP 中讲到的字节序问题在真实内核代码中的体现。
1.3 TCP 选项------报文段头部的"扩展槽"
TCP 头部的"选项"字段最多 40 字节,承载了多种扩展功能。以下是实践中最重要的几个:
① MSS(最大报文段长度)
在三次握手的 SYN 报文中协商------告诉对方"我能接收的最大报文段是多少":
SYN 报文中的 MSS 选项: MSS = 1460
含义: "我的网卡 MTU 是 1500,减去 IP头(20) + TCP头(20) = 1460,
每个报文段不要超过这个大小"为什么不是 1500?因为 IP 头和 TCP 头各 20 字节,真实数据只能用剩下的。MSS = MTU - IP头 - TCP头。协商 MSS 的目的是避免 IP 分片------分片会显著增加丢包概率和 CPU 开销。
② SACK(选择性确认)
标准 ACK 只能累积确认到第一个丢失的字节------丢了一个段,即使后面的段全到了也无法确认。SACK 允许接收方告诉发送方"我收到了 1001~2000 丢了,但 2001~3000 和 3001~4000 已经在了",发送方只需重传丢失的一个段:
普通 ACK: "我收到了 1~1000" (丢的 1001~2000 堵住了后面的确认)
SACK ACK: "我收到了 1~1000, 也收到了 2001~4000, 只缺 1001~2000"SACK 是 TCP 性能的重要优化------在高丢包率网络中(如移动网络、卫星链路),不用 SACK 会导致大量不必要的整窗口重传。
③ Timestamp(时间戳)
每个报文段带两个 32 位时间戳------发送方的时间戳(TSval)和回声时间戳(TSecr,回复对方的 TSval)。两大用途:
RTTM(往返时间测量): 比传统的内核定时器测量 RTT 更精确------每个 ACK 都携带 TSecr = 对应数据段的 TSval,发送方据此精确计算 RTT,优化 RTO 的计算。
PAWS(防止回绕的序列号): 32 位序列号在高速网络中可能"绕一圈"(一个序号分配两次)。时间戳区分新旧报文------即使序列号相同,时间戳不同也能判断这是新数据还是旧数据。
二、确认应答与超时重传------可靠性的两大基石
TCP 的可靠性是一个"承诺系统"------发送方承诺"我不丢你的数据",接收方承诺"我告诉你收到了什么"。两个承诺的实现依赖于两个机制:序列号(让接收方能判断"哪里丢了")和确认应答(让发送方能知道"对方收到了没有")。这听起来简单,但在工程实现中要处理无数边界情况:确认号本身可能丢失(导致发送方超时重传重复数据),数据可能比确认号先到达(导致接收方收到乱序数据需要暂时缓存),网络延迟可能剧烈波动(导致 RTO 算不准,过早重传浪费带宽,过晚重传增加延迟)。TCP 的确认应答机制之所以被称为"可靠性的基石",正是因为它在这无数边界情况下依然能让数据正确到达------靠的不是简单的"发一条确认一条",而是一整套精密的序号管理和重传策略。
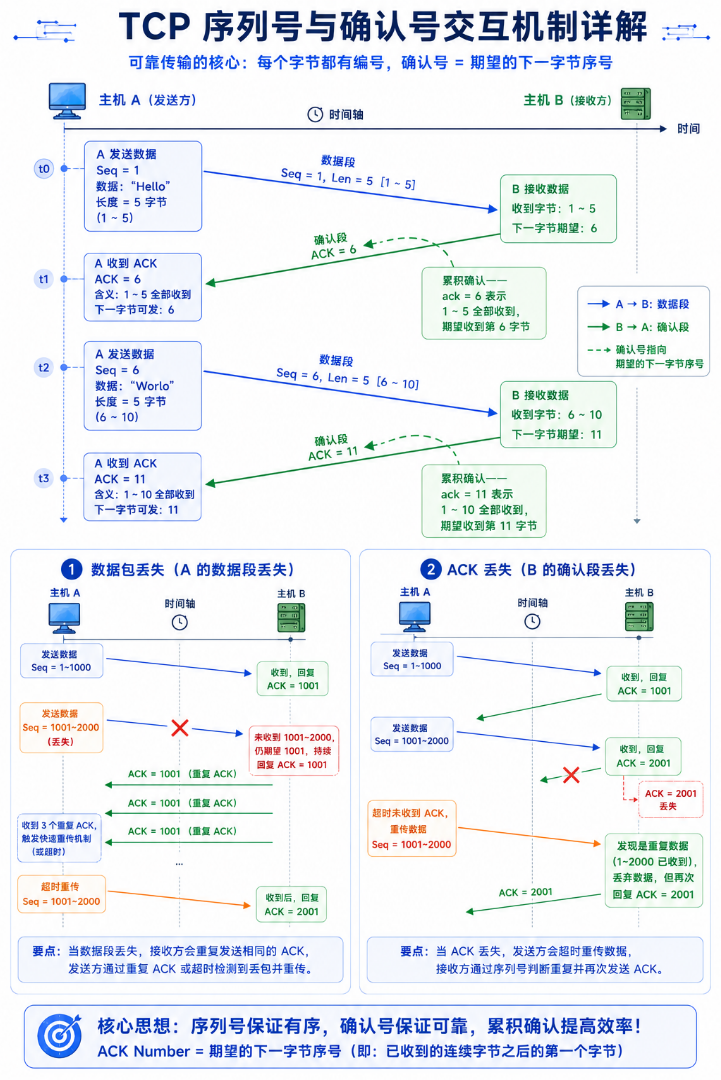
2.1 序列号与确认号:TCP 的对话语言
TCP 为每一个字节的数据都分配了序号。发送方每个报文段携带一个起始序列号(seq),接收方回复的 ACK 中携带确认号(ack = 已收到的最大连续序号 + 1):
主机 A 主机 B
| seq=1, 数据"Hello"(5字节) → |
| ← ack=6, 确认收到 1~5 |
| seq=6, 数据"World"(5字节) → |
| ← ack=11, 确认收到 6~10|确认号的意思是"下一次你从哪里开始发"------累积确认一次能确认之前所有连续到达的数据。如果中间丢了一个段,接收方会不断重复发相同的 ack------"我还在等那个序号"。
2.2 超时重传------当 ACK 没有回来
主机 A 发送数据后启动重传定时器。超时未收到 B 的 ACK,就重传那段数据。
两种丢包情况:
| 情况 | 描述 | TCP 如何应对 |
|---|---|---|
| 数据包丢了 | A 发的数据根本没到 B | A 超时后重传,B 收到后用序列号去重 |
| ACK 丢了 | B 收到了数据但 ACK 半路丢了 | A 超时重传,B 发现是重复数据(序列号已存在),丢弃但再发一次 ACK |
2.3 RTO 如何确定------指数退避
超时时间(RTO)不能拍脑袋定------太长影响效率,太短造成大量重复包。TCP 的做法是动态计算 + 指数退避:
| 重传次数 | 等待时间 | 说明 |
|---|---|---|
| 第 1 次 | RTO(Linux 以 500ms 为基本单位) | 首次超时 |
| 第 2 次 | 2 × RTO | 翻倍 |
| 第 3 次 | 4 × RTO | 继续翻倍 |
| 超过阈值 | --- | TCP 认为对端不可达,强制关闭连接 |
指数退避的意义:如果网络出了大问题(光缆被挖断),快速重传只会加剧网络负担。退避给了网络恢复的时间。
三、连接管理------三次握手、四次挥手与状态机
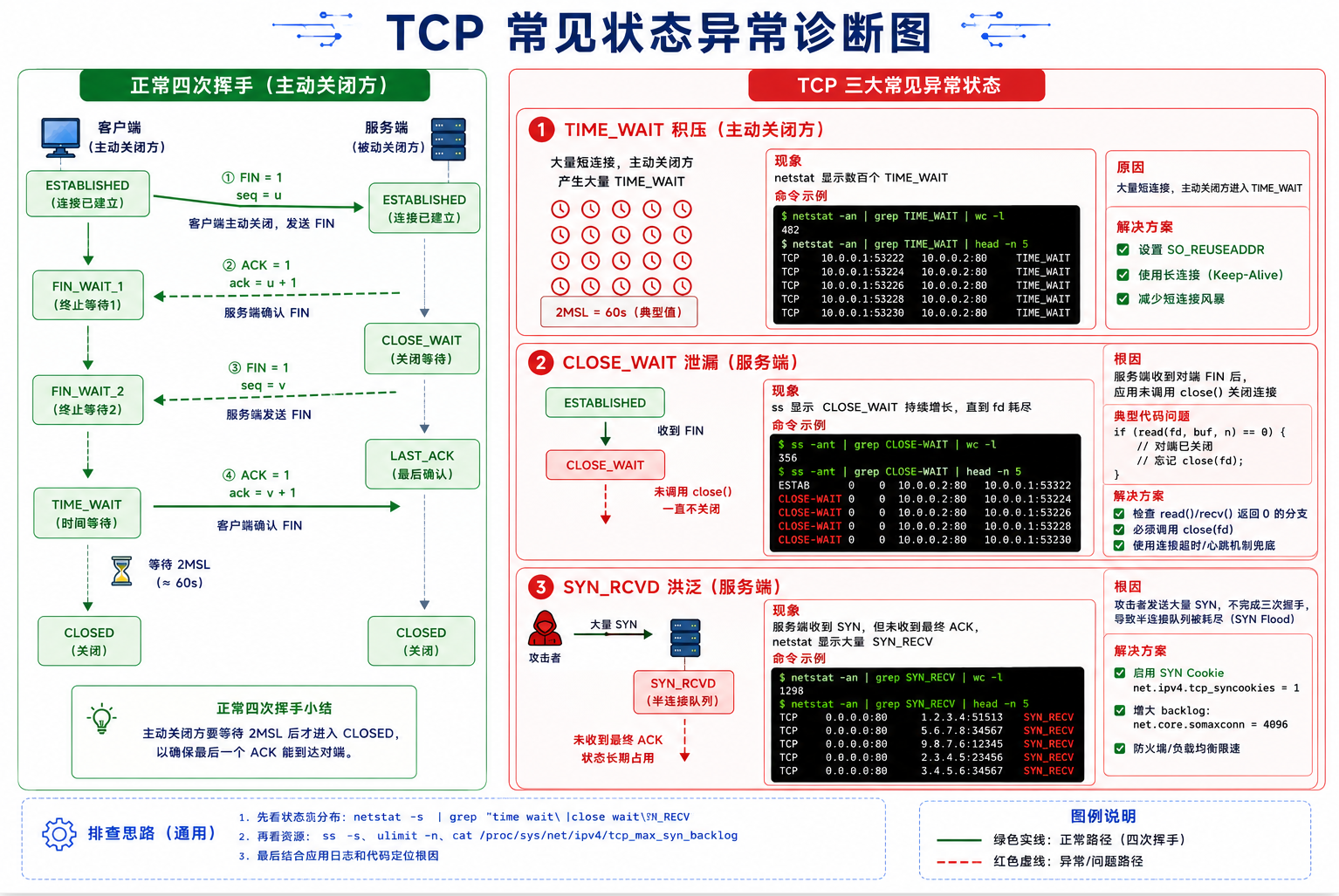
TCP 的连接管理可能是整个网络协议栈中被问到最多的面试题。理解三次握手和四次挥手,不只为了面试------它直接决定了你排查 ss 命令输出时的诊断速度。当你看到 SYN_RCVD 大量积压,你知道是服务端收到了 SYN 但没有收到后续 ACK(可能是 SYN Flood 攻击);看到 TIME_WAIT 大量积压,你知道是大量短连接主动关闭后的正常现象(默认持续 60 秒);看到 CLOSE_WAIT 不消失,你知道是服务端代码忘了 close socket。每一个状态对应着一条报文在处理流程中的精确位置------这就像医生看血液化验单,每个异常指标都指向一个具体的病灶。而这种诊断能力的前提,是你能把 TCP 状态机印在脑子里。
3.1 三次握手------为什么不是两次也不是四次
CLIENT (主动打开) SERVER (被动打开)
CLOSED LISTEN (调用listen)
SYN_SENT (调用connect) |
| seq=x, SYN=1 → |
| SYN_RCVD
| ← seq=y, SYN=1, ACK=1, ack=x+1
ESTABLISHED ESTABLISHED
| seq=x+1, ACK=1, ack=y+1 → |三步各自的含义:
| 握手 | 方向 | 做了什么 | 为什么重要 |
|---|---|---|---|
| 第 1 次 | 客户端→服务端 | SYN=1, seq=x | "我想建立连接,我的初始序列号是 x" |
| 第 2 次 | 服务端→客户端 | SYN=1, ACK=1, seq=y, ack=x+1 | "我收到了,我同意建立,我的初始序列号是 y" |
| 第 3 次 | 客户端→服务端 | ACK=1, ack=y+1 | "确认服务端的 SYN"------防止已失效的连接请求被误接受 |
为什么不是两次? 网络中存在"已失效的连接请求报文"------客户端发了一个 SYN(seq=x),超时后又发了一个新的 SYN(seq=z),新连接成功了。但旧 SYN 迟到了------如果只握手两次,服务端收到旧 SYN 后直接进入 ESTABLISHED 分配资源等待数据。客户端根本不知道这个连接,资源白白浪费。
为什么不是四次? 第二次握手时 SYN 和 ACK 可以合并在同一个报文段中(SYN+ACK)。不需要分开发。
3.2 TCP 完整状态机
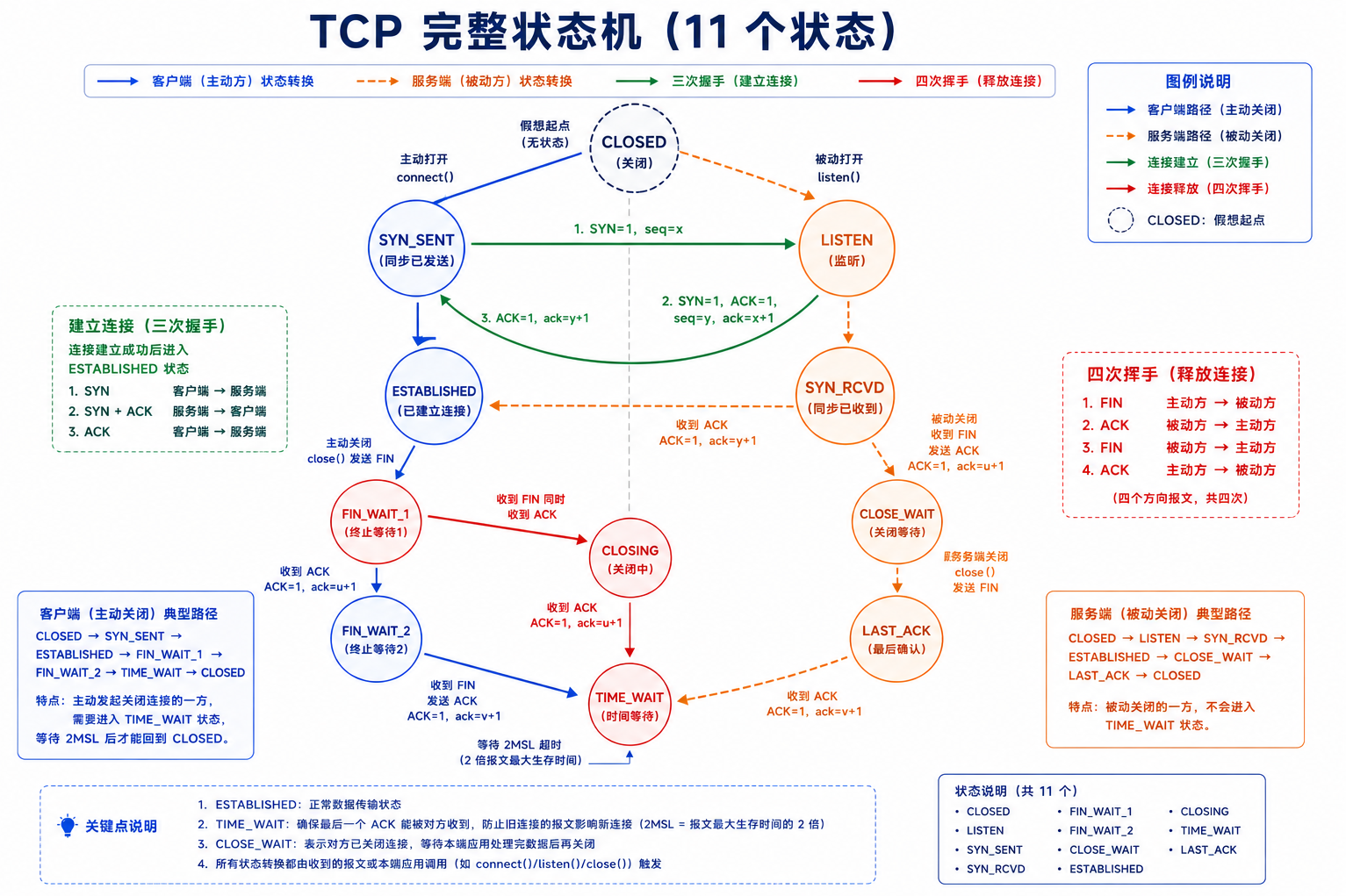
服务端路径:
CLOSED → LISTEN(调用listen) → SYN_RCVD(收到SYN, 回复SYN+ACK)
→ ESTABLISHED(收到客户端ACK) → CLOSE_WAIT(收到客户端FIN, 回复ACK)
→ LAST_ACK(服务端调用close, 发FIN) → CLOSED(收到客户端ACK)客户端路径:
CLOSED → SYN_SENT(调用connect) → ESTABLISHED(收到SYN+ACK, 回复ACK)
→ FIN_WAIT_1(调用close, 发FIN) → FIN_WAIT_2(收到服务端ACK)
→ TIME_WAIT(收到服务端FIN, 回复ACK, 等待2MSL) → CLOSED状态机看似复杂,核心只有两条线:握手建立线 和挥手关闭线 。分开理解就清晰了。CLOSING 状态发生在双方同时调用 close 时(各自发了 FIN 都还没收到对方的 ACK),极少见。
3.3 四次挥手------为什么比握手多一次
主动关闭方 (A) 被动关闭方 (B)
ESTABLISHED ESTABLISHED
FIN_WAIT_1 → seq=u, FIN=1 → |
| CLOSE_WAIT
FIN_WAIT_2 ← ACK=1, ack=u+1 ← |
| LAST_ACK ← seq=v, FIN=1
TIME_WAIT → ACK=1, ack=v+1 → CLOSED
(等2MSL)→CLOSED挥手比握手多一次的根本原因:TCP 是全双工的------A 说"我不说了"(FIN),B 可能还有话要说。 所以断开分两步:先关 A→B 的方向(A 发 FIN,B ACK),再关 B→A 的方向(B 发 FIN,A ACK)。中间的 CLOSE_WAIT/FIN_WAIT_2 就是"半关闭"状态------一个方向已关,另一个方向还在传数据。
"男女朋友分手"类比:A 说"分手吧"(FIN),B 说"知道了让我缓缓"(ACK),B 收拾完心情说"好,我同意分手"(FIN),A 说"祝你幸福"(ACK)。和三次握手比,挥手中间多了一个"让 B 也开口说分手"的环节。
3.4 TIME_WAIT------为什么等 2MSL
实验:
$ ./tcp_server 9090 & # 启动服务器
$ ./tcp_client 127.0.0.1 9090 # 客户端连接后自动退出
$ kill %1 # 关闭服务器
$ ./tcp_server 9090 # 立即重启 → bind error: Address already in use!
$ netstat -an | grep 9090
tcp 0 0 127.0.0.1:9090 127.0.0.1:55123 TIME_WAIT -TIME_WAIT 要等 2MSL 的两个根本原因:
| 原因 | 详细解释 |
|---|---|
| ① 保证最后一个 ACK 可靠到达 | 如果第四次挥手的 ACK 丢了,服务端超时后会重发 FIN。如果客户端 ACK 发出后立即进入 CLOSED,重发的 FIN 到达时会收到 RST(连接不存在)。等待 2MSL 确保 ACK 即使丢失也有时间重传 |
| ② 让旧连接的所有迷路报文消失 | 2MSL 后,网络上所有属于这个五元组的"迷路报文"都已超时被丢弃。新的同名连接不会收到旧连接的数据 |
MSL 在 RFC1122 中规定为 2 分钟,但 Linux 默认 60 秒。查看你的系统:
cat /proc/sys/net/ipv4/tcp_fin_timeout。大量短连接服务端用SO_REUSEADDR避免 TIME_WAIT 导致的端口积压。
3.5 CLOSE_WAIT------代码 BUG 的指示灯
在 TCP 服务器中故意删除 close(client_fd):
bash
$ ss -tanp | grep 9090
LISTEN 0 5 0.0.0.0:9090 0.0.0.0:* users:(("./server"))
CLOSE_WAIT 0 0 127.0.0.1:9090 127.0.0.1:49958 users:(("./server"))CLOSE_WAIT = 服务端收到了客户端的 FIN,但自己还没调用 close。 线上出现大量 CLOSE_WAIT,一定是代码 BUG------服务端在 read 返回 0 后忘了 close socket。对照四次挥手图:服务端卡在了 CLOSE_WAIT→LAST_ACK 这一步。
3.6 同时打开与同时关闭------状态机的两个"彩蛋"
同时打开(Simultaneous Open): 两个主机同时向对方发起 connect------这时会有四次握手(各发一个 SYN,各收到一个 SYN+ACK 后进入 ESTABLISHED),双方都进入 SYN_SENT → SYN_RCVD → ESTABLISHED 路径。虽然罕见,但 RFC 793 规定了这一行为,TCP 实现必须支持。
同时关闭(Simultaneous Close): 双方同时调用 close------各自发送 FIN 后进入 FIN_WAIT_1,收到对方的 FIN(而非 ACK)后进入 CLOSING 状态(这就是 CLOSING 出现的唯一场景),然后各自回复 ACK 并进入 TIME_WAIT。CLOSING 是 TCP 状态机中最罕见的状态。
四、滑动窗口与流量控制------从"停等"到"流水线",按对方的胃容量上菜
4.1 为什么需要滑动窗口
停等协议下,每发一个段等一个 ACK,吞吐量 = 段大小 / RTT。当 RTT=100ms 时,无论带宽多大,吞吐量都上不去。滑动窗口让发送方可以连续发送多个段不等 ACK,吞吐量提升窗口大小倍。
停等模式: |发1|---等ACK1---|---|--|发2|---等ACK2---|
滑动窗口: |发1|发2|发3|发4| |等ACK1| |发5|...
└─ 窗口大小=4 ─┘ 收到ACK1后窗口右滑一格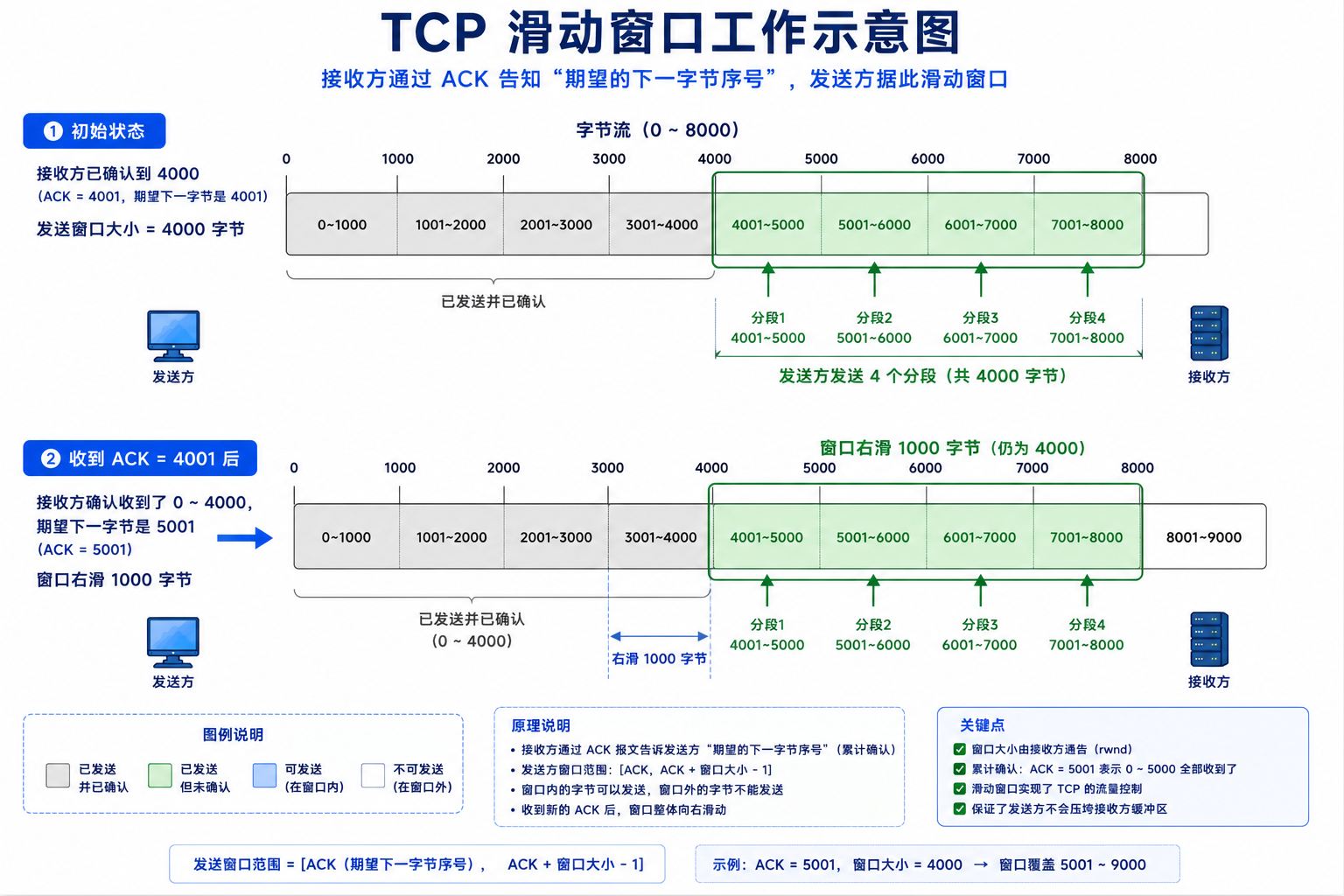
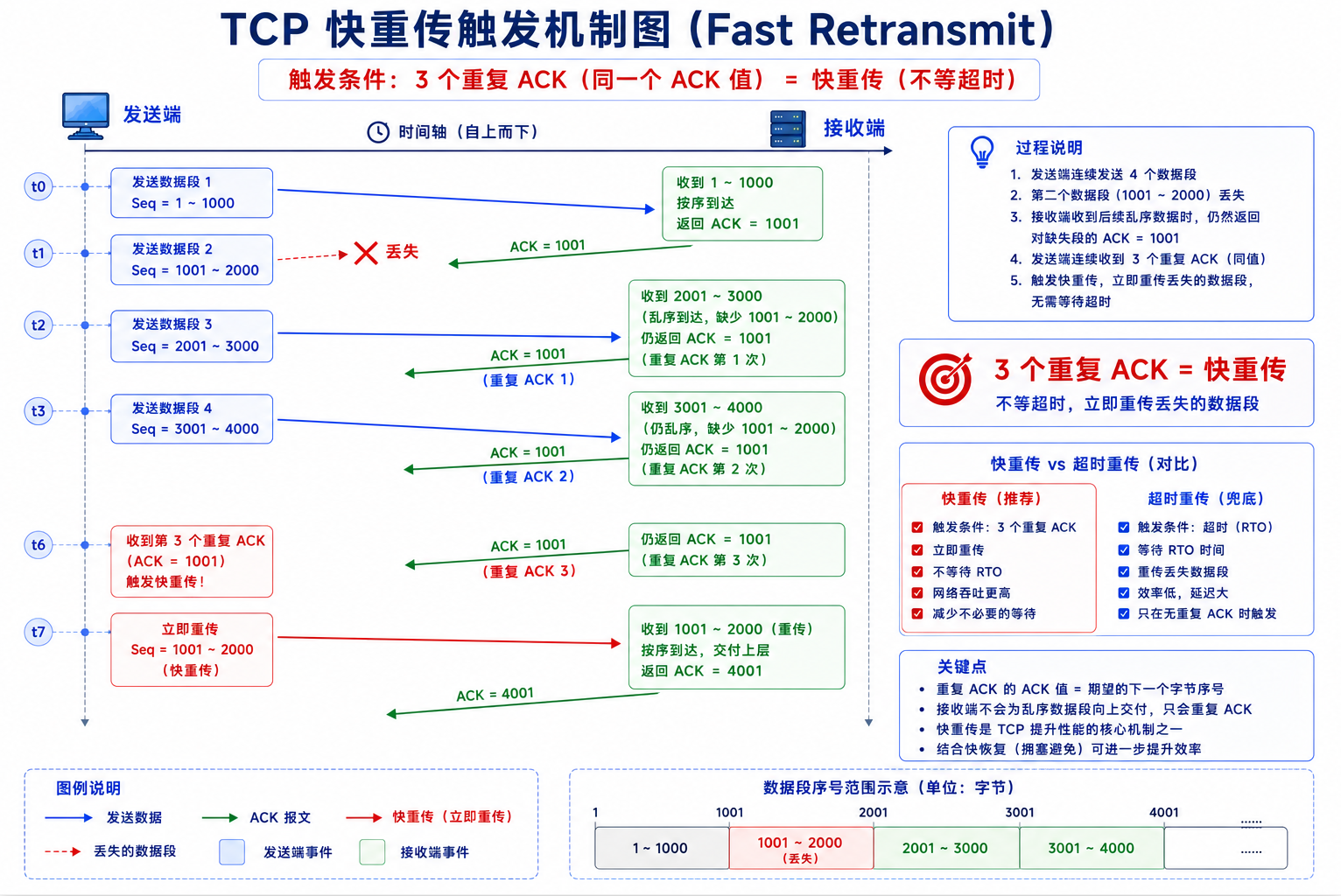
4.2 窗口中的丢包------快重传
情况一:ACK 丢了------后续 ACK 通过累积确认覆盖了丢失的那个,不需重传。
情况二:数据包丢了------接收方收到不连续的数据后,反复回复"我还在等 XX 号":
A 发了 1~1000, 1001~2000(LOST!), 2001~3000, 3001~4000
B 收到 1~1000 → ACK=1001
B 收到 2001~3000 → 仍回复 ACK=1001 ← 第一个重复ACK
B 收到 3001~4000 → 仍回复 ACK=1001 ← 第二个重复ACK
...
→ A 连续收到 3 个重复 ACK(共 4 个同值 ACK)
→ A 触发快重传:不等超时,立刻重传 1001~2000快重传触发条件:连续收到 3 个相同的 ACK。 不依赖超时定时器,通过重复 ACK 推断丢包。这是 TCP Reno 的标准行为,显著减少了丢包恢复的延迟。
4.3 窗口大小与吞吐量
带宽时延积(BDP)= 带宽 × RTT。 要让 TCP 跑满带宽,窗口必须 ≥ BDP:
带宽: 100Mbps = 12.5MB/s
RTT: 100ms = 0.1s
BDP = 12.5MB/s × 0.1s = 1.25MB
→ 窗口至少 1.25MB 才能跑满 100Mbps。低于此值,"网速"被窗口大小卡住。4.4 流量控制------按对方的胃容量上菜
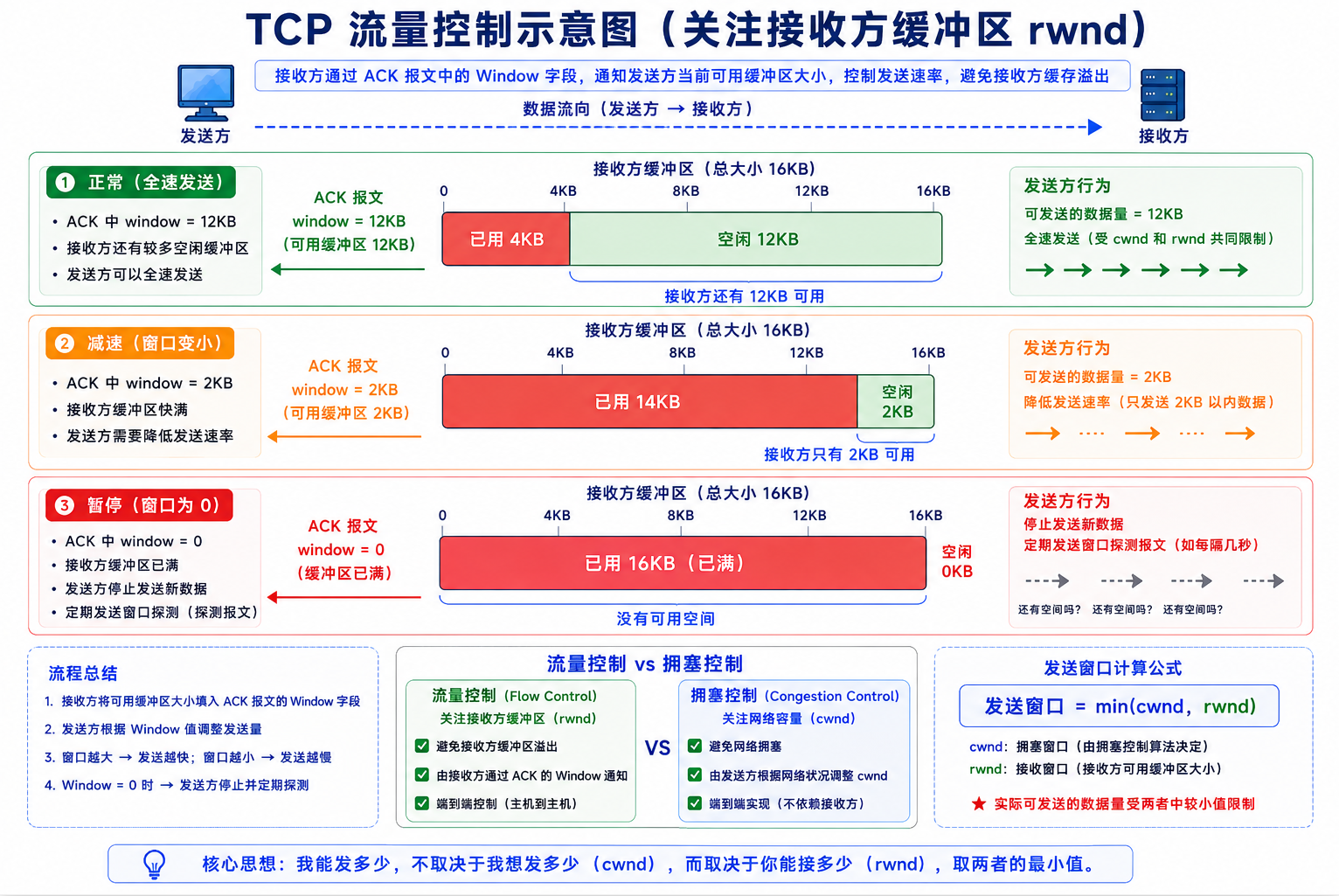
流量控制 ≠ 拥塞控制。流量控制关注接收方 的缓冲区,拥塞控制关注整个网络。
TCP 首部中 16 位"窗口大小"字段,就是接收方每次 ACK 中实时通知的可用缓冲区大小:
B 的接收缓冲区: [████████░░░░░░░░░░] (已用 8KB/共 16KB)
B 回复的 ACK 中: window = 8KB
A 看到 window=8KB → 最多再发 8KB,之后必须等 B 更新 window| B 的状态 | window | A 的行为 |
|---|---|---|
| 缓冲区很空 | 12KB | 正常发送 |
| 缓冲区快满 | 2KB | 减速 |
| 缓冲区满 | 0 | 停发,但定期发窗口探测报文问"能收了吗?" |
16 位窗口字段最大 65535 ≈ 64KB。高带宽高延迟网络需要更大的窗口------TCP 选项中的窗口缩放因子(Window Scale)在握手时协商,实际窗口 = 窗口字段 × 2^(缩放因子),最大可达 1GB。
4.5 延迟应答与捎带应答------让 ACK 更高效
延迟应答------窗口更大的 ACK
接收方不立刻回 ACK,等一会儿------希望应用层在此期间把数据消费了,这样 ACK 中 window 能更大:
立刻应答: window=4KB
延迟 200ms 后应答: window=12KB(应用层消费了 8KB)延迟约束(两条件都需满足):
| 约束 | 规则 | 说明 |
|---|---|---|
| 数量限制 | 每收到 N 个报文段应答一次 | N 通常取 2 |
| 时间限制 | 不超过最大延迟时间 | 通常 200ms |
捎带应答------ACK 搭数据顺风车
客户端问"How are you",服务端回"Fine, thanks"------这本身就是一个报文同时承载了"确认收到你说的话"(ACK)和"我的回复"(data)。合二为一,减少一次往返。
五、拥塞控制------TCP 的公德心
如果流量控制是 TCP 对接收方的体贴("你吃不下我就不喂了"),拥塞控制就是 TCP 对整个互联网的公德心("路上堵了我就慢点开")。流量控制是端到端的------只涉及通信的双方。拥塞控制是全局性的------发送方通过观察 ACK 的到达模式(有没有丢包?重复 ACK 频率?ACK 到达时间的变化?)来推断 整个网络的拥堵状态,然后自觉"踩刹车"。没有任何一个路由器直接告诉发送方"我快撑不住了"(ECN 机制可以,但部署不普遍),TCP 完全是靠间接信号来猜测------这就像你在高速公路上开车,看不到前方是否堵车,只能通过前车的刹车灯和车速变化来判断。拥塞控制算法的核心挑战在于:如何从有限的信号(丢包、延迟变化)中准确推断网络状态,并做出既不激进也不保守的响应。
5.1 发送窗口 = min(拥塞窗口 cwnd, 接收窗口 rwnd)
| 机制 | 关注谁 | 控制变量 | 问题 |
|---|---|---|---|
| 流量控制 | 接收方 | rwnd(接收窗口) | "对方吃不下" |
| 拥塞控制 | 整个网络 | cwnd(拥塞窗口) | "路上的路由器撑不住" |
5.2 拥塞控制的四个阶段
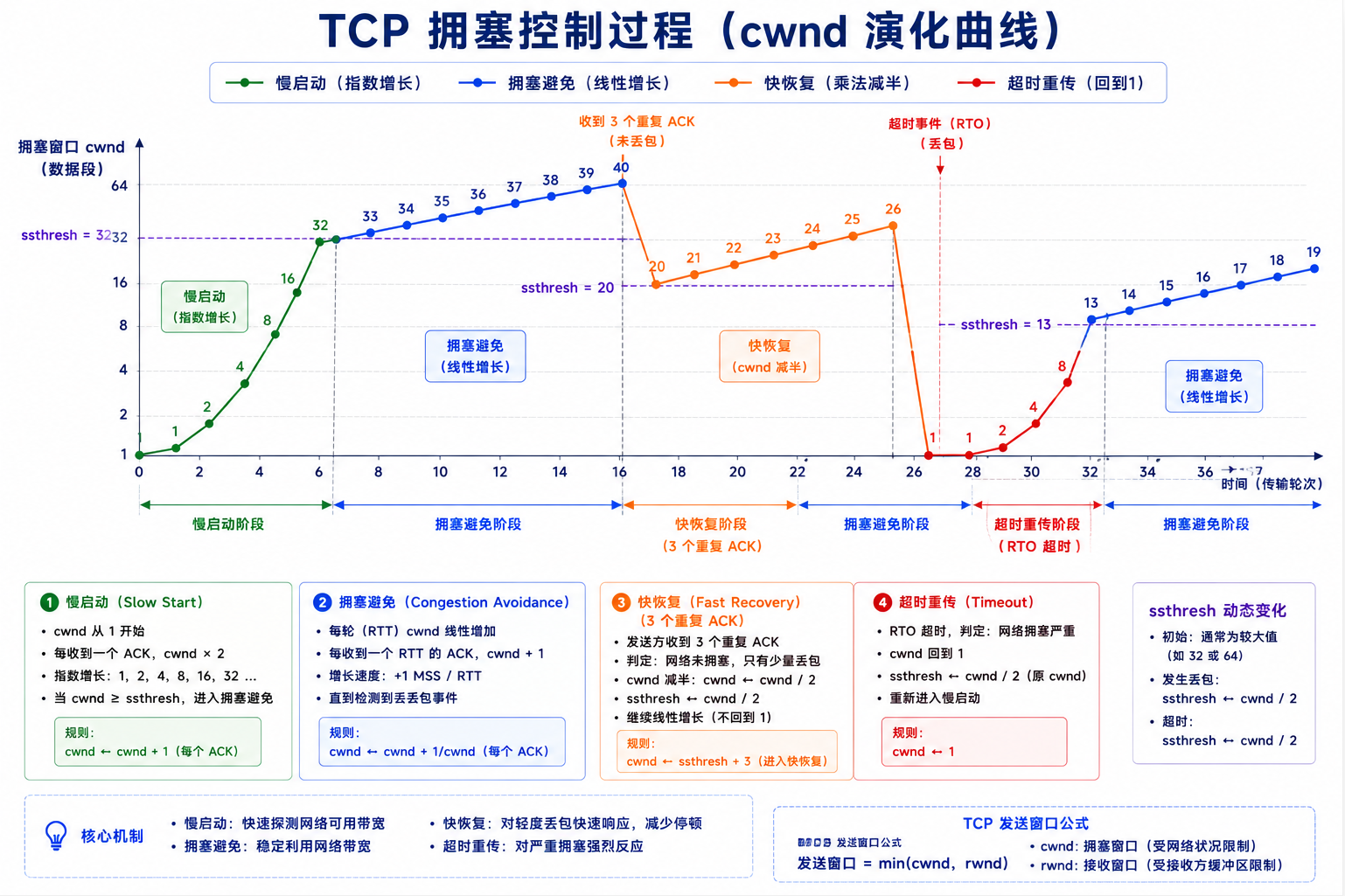
阶段一:慢启动------cwnd 从 1 MSS 开始,每收到一个 ACK 加 1 → 指数增长(每个 RTT 翻倍)------"慢"是指起点低,不是增长慢。
阶段二:拥塞避免------cwnd ≥ ssthresh 后改为线性增长(每 RTT +1 MSS)------在接近网络容量时小心试探。
阶段三:快恢复(收到 3 个重复 ACK)------少量丢包,ssthresh = cwnd/2,cwnd = ssthresh + 3×MSS,然后线性增长。
阶段四:超时 (定时器触发重传)------大量丢包,ssthresh = cwnd/2,cwnd = 1 MSS------重头开始慢启动。
拥塞控制是 TCP 最精妙的设计------它在"尽可能快地把数据传完"和"不给网络造成过大负担"之间寻找动态平衡。就像恋爱中的热度曲线------开始轰轰烈烈(慢启动),逐渐趋于平静(拥塞避免),偶尔吵架降温(快恢复),彻底分手重来(超时,cwnd 回 1)。
六、面向字节流与异常处理------粘包根源与连接消亡
6.1 面向字节流------TCP 的"粘包"根源
TCP socket 在内核中有发送缓冲区 和接收缓冲区 。正因为这两个缓冲区存在,write 和 read 不是一一对应的:
- write 3 次、每次 10 字节 → 对方可能 read 1 次拿到 30 字节,也可能 read 6 次每次 5 字节
- TCP 没有 UDP 那样的"报文长度"字段------站在应用层角度,收到的就是一串连续字节流
粘包只在 TCP 中存在。UDP 不存在粘包------每次 recvfrom 返回一条完整数据报。
三种解决方案在 21 篇(应用层协议)中已详细实现:固定长度、长度前缀 Encode/Decode、分隔符。此处不再重复。
6.2 TCP 异常处理------连接如何意外消亡
| 异常 | TCP 的处理 |
|---|---|
| 进程终止 | 内核自动关闭所有 fd,发送 FIN------与正常 close 无异 |
| 机器重启 | 同进程终止------操作系统正常关闭所有 socket |
| 机器掉电/网线断开 | ① 对方有写入操作时立即发现,发 RST。② 即使无写入,TCP 保活定时器也会定期探测。③ 应用层自身心跳(如 QQ 定期 ping)是真正的快速检测手段 |
TCP 保活定时器通常间隔 2 小时------这就是为什么断网后 QQ 不会立刻显示"离线",应用层自己实现的心跳才是秒级检测。
七、实战与工程------抓包、连接池与面试拷打
7.1 tcpdump 实战------亲眼看到报文段
没有比抓包更直观的方式了。以下是一次完整 TCP 连接的 tcpdump 输出解析:
bash
$ sudo tcpdump -i lo port 9090 -S -vvv
# === 三次握手 ===
# 1. 客户端 → 服务端: SYN
14:30:01.123456 IP localhost.55123 > localhost.9090:
Flags [S], seq 123456789, win 65535,
options [mss 65495,sackOK,TS val 12345 ecr 0,nop,wscale 7]
# 2. 服务端 → 客户端: SYN+ACK
14:30:01.123789 IP localhost.9090 > localhost.55123:
Flags [S.], seq 987654321, ack 123456790, win 65535,
options [mss 65495,sackOK,TS val 67890 ecr 12345,nop,wscale 7]
# ↑ S. = SYN + ACK
# 3. 客户端 → 服务端: ACK (握手完成)
14:30:01.124012 IP localhost.55123 > localhost.9090:
Flags [.], ack 987654322, win 512
# ↑ . = ACK
# === 数据传输 ===
# 4. 客户端发送 "hello"
14:30:01.125000 IP localhost.55123 > localhost.9090:
Flags [P.], seq 123456790:123456795, ack 987654322, win 512, length 5
# ↑ P. = PSH + ACK (PSH 表示催促应用层立即读取)
# 5. 服务端回应 "server echo# hello"
14:30:01.125500 IP localhost.9090 > localhost.55123:
Flags [P.], seq 987654322:987654340, ack 123456795, win 512, length 18
# === 四次挥手 ===
# 6. 客户端 → 服务端: FIN (客户端主动关闭)
14:30:02.000000 IP localhost.55123 > localhost.9090:
Flags [F.], seq 123456795, ack 987654340, win 512
# ↑ F. = FIN + ACK
# 7. 服务端 → 客户端: ACK (确认收到 FIN)
14:30:02.000200 IP localhost.9090 > localhost.55123:
Flags [.], ack 123456796, win 512
# 8. 服务端 → 客户端: FIN (服务端也关闭)
14:30:02.001000 IP localhost.9090 > localhost.55123:
Flags [F.], seq 987654340, ack 123456796, win 512
# 9. 客户端 → 服务端: ACK (最后确认)
14:30:02.001200 IP localhost.55123 > localhost.9090:
Flags [.], ack 987654341, win 512
# 客户端进入 TIME_WAIT,服务端收到后进入 CLOSED逐条对照:
| 序号 | 方向 | 标志 | 对应状态机转换 | seq 变化 |
|---|---|---|---|---|
| 1 | C→S | S | CLOSED→SYN_SENT / LISTEN→SYN_RCVD | seq 初始=123456789 |
| 2 | S→C | S. | SYN_RCVD / SYN_SENT→ESTABLISHED | ack=seq+1 |
| 3 | C→S | . | 握手完成 | 双方 ESTABLISHED |
| 4 | C→S | P. | 数据发送 | seq 递增 length 字节 |
| 5 | S→C | P. | 数据回复 | ack 更新为已确认位置 |
| 6 | C→S | F. | ESTABLISHED→FIN_WAIT_1 | FIN 占用一个序列号 |
| 7 | S→C | . | FIN_WAIT_1→FIN_WAIT_2 / ESTABLISHED→CLOSE_WAIT | ack=FIN的seq+1 |
| 8 | S→C | F. | CLOSE_WAIT→LAST_ACK | 服务端发 FIN |
| 9 | C→S | . | LAST_ACK→CLOSED / FIN_WAIT_2→TIME_WAIT | 最后 ACK |
自己写 TCP 服务器时,启动
tcpdump在另一个终端观察------看到的就是你亲手创建的 TCP 连接的真实生命轨迹。这是学 TCP 最快的方法。
7.2 生产实践------TCP 连接池与短连接优化
为什么 HTTP/1.1 引入长连接
HTTP/1.0 时代,每个 HTTP 请求(一个图片、一个 CSS、一个 JS)都要建立一个新的 TCP 连接------每个连接完整的"三次握手 + 数据传输 + 四次挥手"。一个网页有 50 个资源就等于 50 次握手 + 50 次挥手:
HTTP/1.0 短连接模式:
请求1: SYN→SYN+ACK→ACK→GET→RESP→FIN→ACK→FIN→ACK (≈4 RTT + TIME_WAIT)
请求2: SYN→SYN+ACK→ACK→GET→RESP→FIN→ACK→FIN→ACK (再来一遍)
...50 个资源 = 50 × (3 RTT 握手 + 2 RTT 挥手) = 250 RTT 只是建立和关闭连接!
HTTP/1.1 长连接模式:
请求1: SYN→SYN+ACK→ACK→GET→RESP (连接保持)
请求2~50: 复用同一 TCP 连接,只需 1 RTT per 请求
关闭: FIN→ACK→FIN→ACK (只挥手一次)这就是为什么 HTTP/1.1 将
Connection: keep-alive设为默认------每个 TCP 连接节省约 3 RTT(一次握手)加 TIME_WAIT 的端口消耗。
TCP 连接池------复用连接的工程实践
服务端访问数据库、调用下游微服务时,不做每次请求都新建连接,而是预先建立 N 个 TCP 连接放在池子里------来了请求直接拿一个连接用,用完还回去。这就是连接池(Connection Pool):
cpp
// 连接池伪代码
class TcpConnectionPool {
std::queue<std::shared_ptr<TcpSocket>> _idle_conns;
std::mutex _mutex;
int _max_size = 10; // 最多 10 个连接
std::shared_ptr<TcpSocket> GetConnection(std::string server_ip, uint16_t port) {
std::lock_guard lock(_mutex);
if (!_idle_conns.empty()) {
auto conn = _idle_conns.front();
_idle_conns.pop();
return conn; // 复用已有连接,避免握手开销
}
auto conn = std::make_shared<TcpSocket>();
conn->Connect(server_ip, port); // 池子空时才新建
return conn;
}
void ReturnConnection(std::shared_ptr<TcpSocket> conn) {
std::lock_guard lock(_mutex);
_idle_conns.push(conn); // 用完归还,不是 close
}
};连接池的意义:将 TCP 握手的 RTT 开销分摊到所有请求上。池子里的 N 个连接在服务启动时建立,之后的千万次请求共享这 N 个连接------这就是为什么数据库连接池、Redis 连接池、gRPC 连接池是高性能服务端的标配。
7.3 面试高频:用 UDP 实现可靠传输
问:TCP 可靠,UDP 不可靠。如果让你用 UDP 实现可靠性,怎么做?
这道题的关键不在于你能不能列出 TCP 的各项机制(面试官自己也能列),而在于你是否理解为什么要"用 UDP 重新造 TCP" 。TCP 已经存在四十年了,如果它完美无缺,没有人会费劲在 UDP 之上重新实现可靠性。QUIC 选择 UDP 而非继续优化 TCP,根本原因是 TCP 的内核实现 ------TCP 协议栈实现在操作系统内核中,升级 TCP 需要升级整个操作系统(Windows、macOS、Linux、iOS、Android 全部要改),这在工程上几乎不可能。而 QUIC 运行在用户态------更新 QUIC 只需要更新浏览器或 App,不需要操作系统层面的任何改动。Chrome 每六周发布一个新版本,QUIC 的改进就能随 Chrome 更新覆盖数十亿用户,而 TCP 的改进(如 TCP Fast Open)从 RFC 到广泛部署需要十年。"内核态实现"这个看似技术性的选择,决定了 TCP 的演进速度被锁死在操作系统更新周期上------这才是 QUIC 选择 UDP 的深层原因。 技术选型不只是看技术本身,更要看技术的部署和演进路径。
答:把 TCP 的可靠性机制在应用层重做一遍:
- ① 序列号------保证有序到达
- ② 确认号------确认已收到的数据
- ③ 窗口字段------流量控制
- ④ 校验和------数据完整性
- ⑤ 超时重传------发送后启定时器,超时未 ACK 则重传
- ⑥ 滑动窗口------批量发送提高吞吐
- ⑦ 拥塞控制------动态调整发送速率
- ⑧ 连接管理------三次握手建立,四次挥手关闭
这就是 QUIC(HTTP/3 的传输层) 在做的事------在 UDP 之上重建了一套可靠传输,但比 TCP 做得更好:解决队头阻塞、0-RTT 连接建立、WiFi 切 4G 连接不中断。
总结
TCP 协议是互联网工程史上最成功的"妥协设计"。它不追求最优------最优的方案往往只存在于理论中------而是追求"在绝大多数网络条件下工作得足够好"。慢启动、拥塞避免、快重传、快恢复这些机制,没有一个是在 1974 年 TCP 最初设计时就包含的。它们是在 1986 年互联网第一次"拥塞崩溃"(congestion collapse)后,由 Van Jacobson 等人紧急补救进去的------那时伯克利到伯克利的网络吞吐量从 32Kbps 暴跌到 40bps,因为太多 TCP 连接在疯狂重传。TCP 的可靠性机制不是象牙塔里的理论推演,而是被真实的网络崩溃一次次"打补丁"打出来的------每一块补丁背后都是一次线上故障。理解了这个背景,你就能理解为什么 TCP 的代码如此复杂------它不是一次性设计出来的艺术品,而是四十年来在真实互联网上不断进化的产物。工程师修改协议,灾难驱动修改的优先级。 这个道理对任何做基础设施的人来说都值得记住。
TCP 的复杂性来自一个简单的追求:在不可靠的 IP 网络之上,提供可靠的字节流传输。 每一个可靠性机制的背后都有相应的代价:
| 可靠性机制 | 代价 |
|---|---|
| 确认应答 | 每个包都要 ACK------带宽开销 |
| 超时重传 | 丢包后等 RTO 时间------延迟 |
| 滑动窗口 | 需分配缓冲区存未确认数据------内存 |
| 流量控制 | 接收方慢时发送方必须降速------吞吐下降 |
| 拥塞控制 | 网络拥塞时 cwnd 骤降------性能波动 |
可靠性全景拼图:
| 分类 | 机制 | 解决的问题 |
|---|---|---|
| 数据完整 | 校验和 | 传输中损坏了怎么办 |
| 有序到达 | 序列号 + 排序 | 乱序了怎么重组 |
| 不丢数据 | 确认应答 + 超时重传 | 丢了怎么补救 |
| 接收方不溢出 | 流量控制(滑动窗口) | 发送太快撑爆对方缓冲区 |
| 网络不拥塞 | 拥塞控制(慢启动/拥塞避免/快恢复) | 发送太快撑爆网络 |
| 连接管理 | 三次握手 + 四次挥手 + TIME_WAIT | 怎么建立、怎么断开、断开后确保干净 |
| 性能优化 | 滑动窗口 + 延迟应答 + 捎带应答 + 快重传 | 可靠前提下尽可能快 |
| 基于 TCP 的应用层协议 | 典型端口 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| SSH | 22 |
| FTP | 21 |
| SMTP | 25 |
| Telnet | 23 |
动手试试
- 用
tcpdump抓取一次完整 TCP 连接(SYN → FIN),逐条报文对照状态机图验证状态转换:sudo tcpdump -i lo port 9090 -S -vvv -w tcp.pcap,启动你的 tcp_server 和 tcp_client,然后用 Wireshark 打开 pcap 文件查看每条报文对应的 seq/ack 变化。- 用
ss -tanp观察 TCP 服务器的 LISTEN → SYN_RCVD → ESTABLISHED → TIME_WAIT/CLOSE_WAIT 的完整状态变化。故意删除close(client_fd)观察 CLOSE_WAIT 泄漏------这就是线上最常见的 TCP 内存泄漏。- 修改系统参数观察效果:
echo 30 | sudo tee /proc/sys/net/ipv4/tcp_fin_timeout将 TIME_WAIT 从 60s 改为 30s,用ss -tan state time-wait观察 TIME_WAIT 数量的变化。- 修改代码中的
SO_REUSEADDR选项(注释掉),重启服务器验证"Address already in use"------然后恢复setsockopt,验证问题消失。
尾声
本章讲解就到此结束了,若有纰漏或不足之处欢迎大家在评论区留言或者私信,同时也欢迎各位一起探讨学习。感谢您的观看!