一张图看懂机器学习全貌(附B站课程笔记整理)
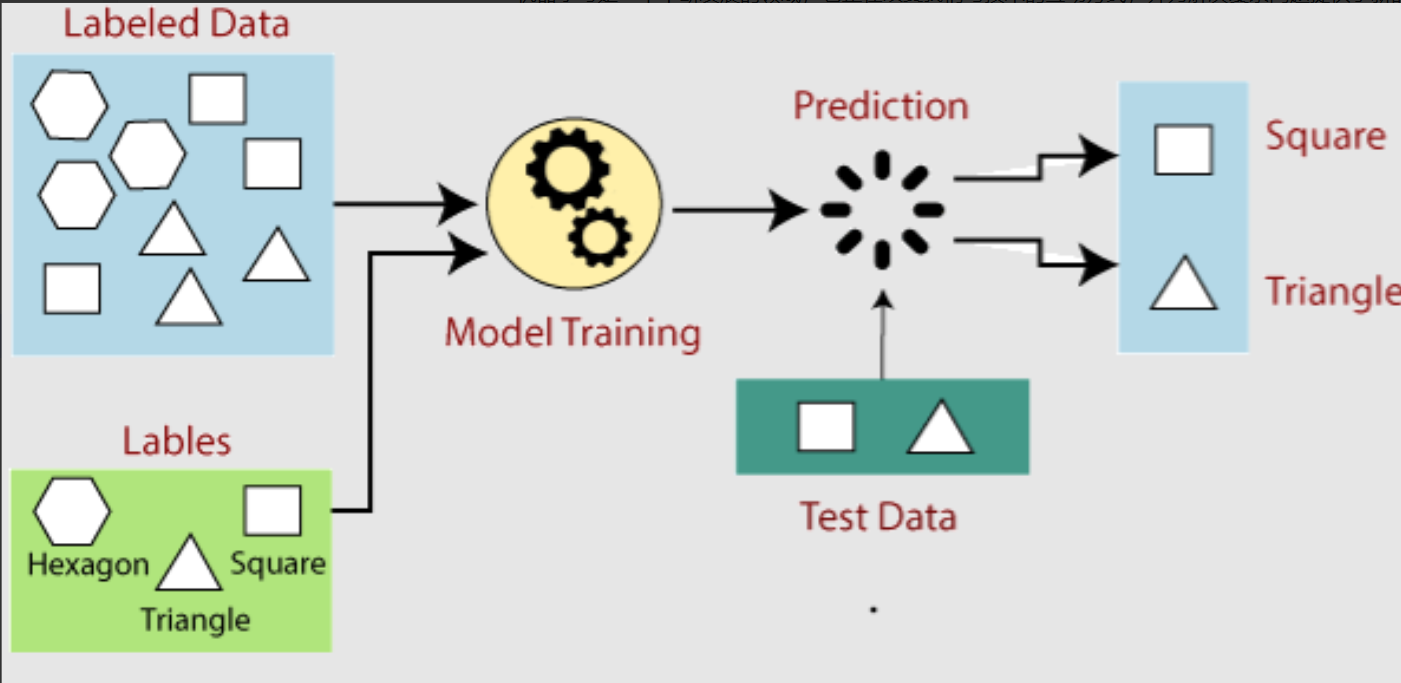
本文基于B站UP主谦行Aling的《人工智能通识·机器学习》课程笔记整理而成。从基础概念到核心算法,一文带你系统掌握机器学习入门全貌。
一、什么是机器学习?
1.1 传统编程 vs 机器学习
| 传统编程 | 机器学习 |
|---|---|
| 人把规则写清楚,机器按规则执行 | 给机器历史样本,让它自动提取规律 |
| 规则 + 数据 → 结果 | 数据 + 答案 → 模型 |
模型训练完成后,就能把学到的规律用于新样本预测:房价、销量、点击、欺诈、流失、图像分类......
1.2 核心概念辨析
-
样本(Sample):一条记录,如一个用户、一套房、一封邮件
-
特征(Feature):描述样本的输入变量(如面积、房间数)
-
标签(Label):希望模型预测的答案(如房价)
-
算法(Algorithm):学习方法,如线性回归、决策树
-
模型(Model):学习结果,如一组权重参数、一棵决策树
💡 关键认知 :机器学习的第一步,不是选算法,而是把问题翻译成"特征 → 标签"的学习任务。
二、学习路线与前置知识
掌握一定的基础是必需的,但无需成为专家。课程中涉及理论会提供 Just-in-Time 通俗讲解。
2.1 数学基础(三驾马车)
| 领域 | 核心内容 |
|---|---|
| 线性代数 | 向量与矩阵基础概念,加/减/点积/乘法 |
| 概率与统计 | 均值、方差、概率分布、贝叶斯定理 |
| 微积分 | 导数、偏导数含义及链式法则 |
2.2 编程技能栈
-
Python:机器学习的事实标准
-
Jupyter Notebook:适合边写边跑、实验可视化的开发环境
-
生态工具箱:
-
NumPy/Pandas------ 数据处理 -
Matplotlib/Seaborn------ 可视化 -
Scikit-learn------ 经典算法库
-
三、机器学习的三大分支
根据数据集是否带有标签,以及学习方式的不同,机器学习衍生出三大主要分支:
3.1 监督学习(Supervised Learning)
数据集中的每个数据点都包含标签(如已知房价),机器通过学习特征与标签的关系进行预测。
两大核心类型:
| 类型 | 说明 | 应用场景 | 代表算法 |
|---|---|---|---|
| 回归模型 | 预测连续数值型数据 | 房价预测、股票走势、温度预测 | 线性回归、决策树、随机森林、XGBoost |
| 分类模型 | 预测离散的分类型数据 | 图像识别、垃圾邮件检测、客户群体划分 | 感知器、逻辑回归、朴素贝叶斯、KNN、SVM |
3.2 无监督学习(Unsupervised Learning)
数据点不包含标签,机器需要自己在数据中寻找隐藏的结构或规律。
目标不再是预测某个具体的数值或类别,而是让模型自行探索发现数据内部隐藏的结构、模式或规律。
三大方向:
| 方向 | 核心作用 | 案例 |
|---|---|---|
| 聚类(Clustering) | 将数据集分组 | 电商百万用户精准营销------无干预自动划分用户画像 |
| 降维(Dimensionality Reduction) | 信息整合与特征重构 | 房价预测中合并"距离地铁米数""学校数量""商场个数"为综合地段评分 |
| 生成算法(AIGC) | 从数据中创造全新内容 | AI绘画(GAN)、生成虚拟人脸扩充训练集 |
3.3 强化学习(Reinforcement Learning)
在动态环境中通过不断试错,学习如何做出更优决策以获得最大奖励。
-
核心机制 :设定智能体(Agent),置于环境中采取动作,环境反馈奖励(Reward) 或惩罚(Penalty)
-
终极目标:探索出一套能获得最大长期累计奖励的策略
-
应用场景:自动驾驶、围棋(AlphaGo)、推荐系统、机器人控制
四、线性回归------最经典的基础模型
4.1 什么是线性回归?
线性回归(Linear Regression)是机器学习中最经典的模型之一,它通过构建线性方程来拟合数据的内在分布规律,从而实现对连续数值的预测。
⚠️ 重要误区 :线性 ≠ 直线!
数学上,"线性"描述的是输入与输出之间按比例变化、可叠加的关系:
-
齐次性:f(ax) = a * f(x)
-
可加性:f(x + y) = f(x) + f(y)
几何解释:在一维空间中表现为一条直线;在高维空间中表现为平面或超平面。
4.2 "回归"一词的由来
"回归"(Regression)源于统计学家弗朗西斯·高尔顿 (Francis Galton)的经典研究。他观察到:身高极高或极矮的父母,其子女的身高往往会向群体平均值靠拢 ,这一现象被称为**"回归均值"**。
在机器学习领域,回归的概念被进一步引申:旨在通过数据建模变量间的映射关系,进而实现对连续数值的预测。
4.3 模型公式
最简单的线性回归模型只有一个特征(如房屋面积),预测公式为:
\\hat{y} = wx + b
| 符号 | 含义 | 示例 |
|---|---|---|
| y | 模型的预测值 | 预测房价 |
| x | 输入特征 | 房屋面积 |
| w | 权重(weight / 斜率) | 面积每增加1m²,房价变化多少 |
| b | 偏置(bias / 截距) | 当面积为0时的理论基准价 |
这里的 w 和 b 就是模型需要学习的参数。训练模型本质上就是搜索一组最合适的 w 和 b。
4.4 损失函数:衡量模型准不准
模型要找到最好的参数,首先得回答一个问题:当前这组参数到底好不好?
我们需要一种方法来度量预测值与真实值之间的偏差------这就是损失函数(Loss Function)。
均方误差(MSE)
MSE = \\frac{1}{n}\\sum_{i=1}\^{n}(\\hat{y}_i - y_i)\^2
计算步骤:
-
对每个样本,计算 预测值 − 真实值(即误差)
-
将误差取平方(消除正负号、放大较大误差)
-
对所有样本求平均
🎯 一句话概括 :预测值离真实值越远,损失越大。模型训练的目标,就是让损失函数的值尽可能小。
4.5 梯度下降:寻找最优参数
有了损失函数后,我们如何找到使损失最小的 w 和 b?答案是梯度下降(Gradient Descent)------沿着损失函数梯度的反方向迭代更新参数:
w := w - \\alpha \\cdot \\frac{\\partial L}{\\partial w}
其中 \\alpha 是学习率(learning rate),控制每步移动的大小。学习率太大会震荡不收敛,太小则收敛太慢。
4.6 数据预处理
在将原始数据送入模型前,通常需要进行以下处理:
-
缺失值处理:填充均值/中位数,或直接删除
-
标准化/归一化:将不同量纲的特征缩放到同一范围(如0~1或标准正态分布)
-
类别编码:将文本标签转换为数值(One-Hot Encoding、Label Encoding)
-
特征选择:剔除无关或冗余特征
4.7 过拟合与欠拟合
| 问题 | 表现 | 原因 | 解决方案 |
|---|---|---|---|
| 欠拟合(Underfitting) | 训练集和测试集误差都很高 | 模型过于简单 | 增加特征、使用更复杂的模型 |
| 过拟合(Overfitting) | 训练集误差低但测试集误差高 | 模型过于复杂/噪声干扰 | 正则化、Early Stopping、增加数据量 |
**Early Stopping(早停)**是一种有效的防过拟合策略:设置一个足够大的上限轮数,让算法自己找到最佳停止点。在XGBoost等集成模型中,当验证集误差连续多轮不再下降时自动停止训练。
五、逻辑回归------分类问题的基石
逻辑回归(Logistic Regression)虽然名字里带"回归",但实际上是一个二分类模型 。它在线性回归的基础上,通过 Sigmoid 函数 将输出映射到 (0, 1) 区间,表示属于正类的概率:
P(y=1\|x) = \\sigma(wx + b) = \\frac{1}{1 + e\^{-(wx+b)}}
核心特点:
-
输出可解释为概率值
-
决策边界可以是线性的
-
可扩展到多分类(Softmax)
-
广泛应用于信用评分、点击率预估等场景
六、决策树------直观易懂的树形模型
决策树(Decision Tree)是一棵从上到下的树状结构,通过一系列"是/否"判断对数据进行划分:
-
节点:一个特征的判断条件
-
分支:判断结果的走向
-
叶节点:最终的预测结果(分类标签或回归值)
优点:
-
✅ 完全符合人类直觉,结果可解释性强
-
✅ 不需要特征缩放
-
✅ 能处理混合类型的特征
缺点:
-
❌ 容易过拟合(单棵树深度不受限制时)
-
❌ 对数据中的微小变化敏感
七、随机森林------多树并行的力量
随机森林(Random Forest)采用 Bagging(Bootstrap Aggregating) 策略:
核心思想 :构建多棵决策树,每棵树基于不同的数据子集和特征子集 进行训练,最终通过投票(分类)或平均(回归) 得到最终结果。
| 特性 | 决策树 | 随机森林 | GBDT / XGBoost |
|---|---|---|---|
| 模型数量 | 1棵 | 多棵(并行) | 多棵(串行) |
| 集成策略 | 无 | Bagging: 投票/平均 | Boosting: 逐步累加 |
| 单棵树特点 | 可深可浅 | 深树(低偏差高方差) | 浅树(高偏差低方差) |
| 核心目标 | 基线模型 | 降低方差 | 降低偏差 |
| 过拟合风险 | 高 | 低 | 中等 |
sklearn 使用示例:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(
n_estimators=200, # 决策树数量
max_depth=10, # 每棵树的最大深度
random_state=42,
n_jobs=-1 # 用满CPU核心加速
)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)八、Boosting 模型------逐步纠错的进化之路
8.1 Boosting 思想
与 Bagging 的"并行投票"不同,Boosting 采用串行纠错的策略:
-
先训练一个弱模型
-
找出错分的样本,给它们更高的权重
-
再训练下一个模型,重点关注之前犯错的样本
-
重复上述过程,最终将多个弱模型加权组合
8.2 GBDT / XGBoost
GBDT(Gradient Boosting Decision Tree) 是 Boosting 思想与决策树的结合:
-
使用浅树(高偏差低方差)
-
通过梯度下降方向指导每轮新树的学习目标
-
逐步降低偏差
XGBoost 是 GBDT 的工业级优化版本:
-
更快的训练速度
-
内置正则化防止过拟合
-
支持缺失值自动处理
-
丰富的超参数调优空间
Early Stopping 防止过拟合:
from xgboost import XGBRegressor
xgb_es = XGBRegressor(
n_estimators=10000,
max_depth=5,
learning_rate=0.05,
early_stopping_rounds=20 # 20轮不提升就停止
)
xgb_es.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
verbose=50)
# 最佳迭代轮数: 1186, 最佳 MSE: 0.1939验证集 RMSE 会先快速下降然后趋于平缓,Early Stopping 恰好在最低点附近停下来。
8.3 三大 Boosting 框架对比
| 框架 | 特点 |
|---|---|
| XGBoost | 经典之作,文档丰富,社区成熟 |
| LightGBM | 微软出品,速度更快,内存更省 |
| CatBoost | Yandex 出品,对类别特征处理优秀 |
💡 实战建议:XGBoost / LightGBM / CatBoost 是工业级进化的代表,更快、更准、更易用。三者选其一即可应对大多数表格数据的竞赛和业务需求。
九、无监督学习------聚类与降维
9.1 K-Means 聚类
K-Means 是最经典的无监督学习算法,核心作用是将数据集分组。
工作原理:
-
随机初始化 k 个中心点(质心)
-
将每个样本分配给最近的质心
-
重新计算每个簇的质心位置
-
重复步骤2-3直到收敛
应用场景:
-
🛒 电商用户分群:根据购买频次、消费金额等自动划分用户画像
-
🖼️ 图像压缩:从数十万种颜色中找出若干典型代表,减少存储空间
-
🔍 异常检测:识别偏离常规的数据点(异常访问、恶意攻击)
所谓聚类,就是在没有标签 的前提下,根据样本之间的相似性,将数据自动划分为若干组,使得同组内样本尽可能相似,不同组之间尽可能有差异。
9.2 PCA 降维------化繁为简的艺术
在实际业务中,我们常遇到包含成百上千个特征的数据集。当特征维度不断增长时,一系列问题随之而来,被称为维度灾难(Curse of Dimensionality):
| 问题 | 影响 |
|---|---|
| 计算成本急剧增长 | 参数量变大,导致严重的算力和时间开销 |
| 数据稀疏性与过拟合风险 | 高维空间数据变得稀疏,所需数据量呈指数级增加 |
| 距离度量失效 | 高维空间中任意两点距离趋于相等,KNN/K-Means等基于距离的算法几乎无效 |
| 多重共线性问题 | 特征之间存在强相关性(如"面积"与"房间数"),干扰模型评估 |
PCA(主成分分析)原理
PCA 通过线性变换将高维数据投影到低维空间,同时保留最大信息量:
-
标准化原始数据
-
计算协方差矩阵
-
求解协方差矩阵的特征值和特征向量
-
按解释方差率选取前 k 个主成分
-
构建投影矩阵 W,将数据变换到新空间
解释方差率公式: \\text{解释方差率} = \\frac{\\lambda_i}{\\sum_{j=1}\^n \\lambda_j}
一般根据累计解释方差率决定降到什么维度,选出前 k 大的特征值加起来除以总和,找到能超过阈值(如95%)的最小k。
案例:总方差和 = 372.6
-
PC1 解释率 ≈ 89.9%
-
PC2 解释率 ≈ 10.1%
-
前两个成分累计解释率达100% → 选择 k=2,将三维数据降到二维
十、机器学习全貌总结
10.1 一张图看懂机器学习
| 监督学习 | 无监督学习 | 强化学习 |
|---|---|---|
| 有标签:从输入学习到答案的映射 | 无标签:发现数据自己的结构 | 在环境中试错,用奖励塑造策略 |
| • 回归:房价、销量、温度 | • 聚类:K-Means、DBSCAN | • Agent / Environment |
| • 分类:垃圾邮件、流失预测 | • 降维:PCA、特征提取 | • Action / Reward / Policy |
| • 线性/逻辑回归、树模型、KNN、SVM | • 异常检测、生成建模 | • 游戏、机器人、推荐策略 |
10.2 机器学习通用五步法
无论什么任务,机器学习项目都可以遵循以下五步流程:
| 步骤 | 内容 | 关键动作 |
|---|---|---|
| 01 | 定义目标与指标 | 明确业务问题,选择合适的评估指标 |
| 02 | 清洗数据与特征 | 缺失值处理、特征工程、数据划分 |
| 03 | 训练、验证、测试 | 划分数据集,交叉验证,模型选择 |
| 04 | 处理欠拟合/过拟合 | 正则化、Early Stopping、集成学习 |
| 05 | 上线监控与重训 | 模型部署、性能监控、定期重训 |
🎯 一句话总结 :机器学习不是算法清单,而是"用数据解决问题"的完整工程方法。
十一、写在最后
本文涵盖了机器学习入门的完整知识体系:
-
基础认知:ML是什么?与传统编程有何区别?
-
三大分支:监督学习、无监督学习、强化学习
-
核心算法:线性回归 → 逻辑回归 → 决策树 → 随机森林 → XGBoost
-
无监督技术:K-Means 聚类 + PCA 降维
-
工程实践:数据处理、过拟合处理、模型评估、部署流程
下一步建议:
-
🔧 动手实践!用
sklearn在真实数据集上跑一遍这些算法 -
📚 深入阅读:《统计学习方法》(李)、《西瓜书》(周志华)、《Hands-On Machine Learning》(Aurélien Géron)
-
🎬 视频学习:B站搜索"谦行Aling 机器学习"
本文内容整理自B站UP主 谦行Aling 的《人工智能通识·机器学习》系列课程笔记,仅供学习交流使用。