
这里写目录标题
-
- 一、共享代理池的"噪音邻居"问题
-
- [1.1 一个真实的故障场景](#1.1 一个真实的故障场景)
- [1.2 共享 vs 独享:延迟波动对比](#1.2 共享 vs 独享:延迟波动对比)
- [1.3 为什么独享 IP 能解决问题](#1.3 为什么独享 IP 能解决问题)
- [二、场景一:秒杀抢购------asyncio 异步并发实战](#二、场景一:秒杀抢购——asyncio 异步并发实战)
-
- [2.1 异步请求核心代码](#2.1 异步请求核心代码)
- [2.2 关键优化点解析](#2.2 关键优化点解析)
- 三、场景二:量化交易接口------毫秒级确定性响应
-
- [3.1 交易所 API 持续监控](#3.1 交易所 API 持续监控)
- [3.2 延迟抖动告警逻辑](#3.2 延迟抖动告警逻辑)
- 四、网络延迟优化检查清单
-
- [4.1 路由追踪](#4.1 路由追踪)
- [4.2 MTU 调整](#4.2 MTU 调整)
- [4.3 DNS 缓存优化](#4.3 DNS 缓存优化)
- [4.4 TCP 参数调优](#4.4 TCP 参数调优)
- [4.5 完整检查清单速查表](#4.5 完整检查清单速查表)
- 五、端到端延迟实测
- [六、什么时候该选独享 IP](#六、什么时候该选独享 IP)
一、共享代理池的"噪音邻居"问题
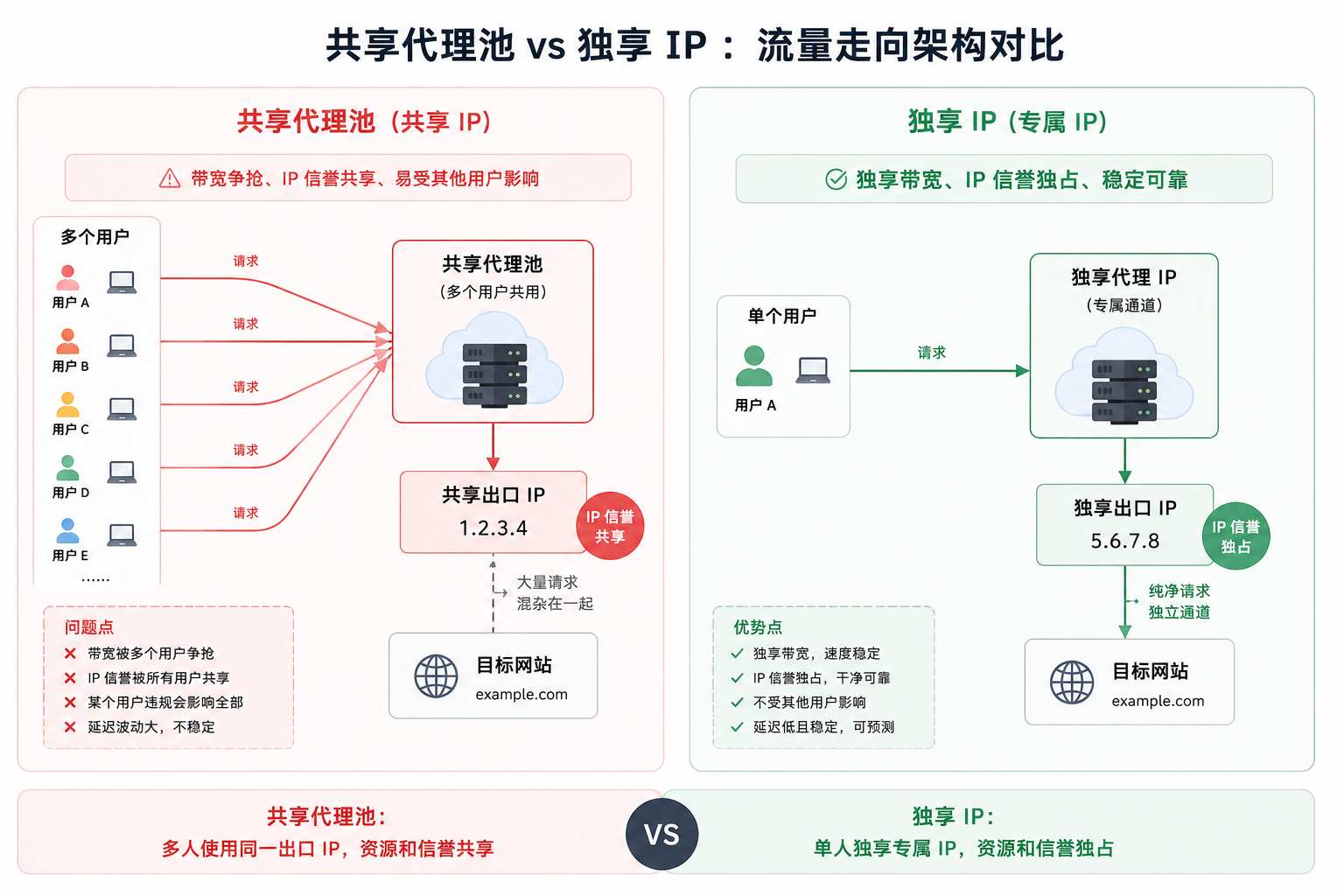
共享代理池最大的隐患不是速度慢,而是不可预测------同一 IP 上其他用户的行为会直接影响你的请求质量,这就是"噪音邻居"问题。本文从这个问题出发,在秒杀抢购和量化交易接口两个时间敏感型场景中,对比共享 IP 与独享 IP 的延迟波动差异。代码层面使用 Python asyncio + aiohttp 实现异步并发请求,展示如何将单次请求延迟压缩到毫秒级。最后给出一套可操作的网络延迟优化检查清单。
1.1 一个真实的故障场景
去年帮一个做跨境秒杀的业务团队排查过一个线上事故。他们在某次限时抢购活动中使用了共享代理池,结果开抢瞬间大量请求超时,最终抢购成功率不到 5%。排查后发现,同一代理 IP 上还有另外两个用户也在同时发起高并发请求,三方的流量叠加触发了目标网站的风控限流,所有人的请求都被挡了回来。
这就是典型的"噪音邻居"问题------你无法控制同一 IP 上其他用户的行为,但他们的行为会直接拖垮你的请求质量。
1.2 共享 vs 独享:延迟波动对比
用一个简单的实验来量化这个差异。同一时间段内,分别用共享代理池和 Dataify 独享 IP 对同一目标发起 50 次请求,记录每次延迟:
plain
import requests
import time
import statistics
def measure_latency(proxy_url, label, rounds=50):
proxies = {"http": proxy_url, "https": proxy_url}
latencies = []
for i in range(rounds):
start = time.time()
try:
resp = requests.get(
"https://httpbin.org/get",
proxies=proxies, timeout=10
)
latency = (time.time() - start) * 1000
if resp.status_code == 200:
latencies.append(latency)
except:
pass
if not latencies:
print(f"[{label}] 全部失败")
return
lat_sorted = sorted(latencies)
p50 = lat_sorted[len(lat_sorted) // 2]
p90 = lat_sorted[int(len(lat_sorted) * 0.9)]
jitter = statistics.stdev(latencies)
print(f"[{label}]")
print(f" 成功: {len(latencies)}/{rounds}")
print(f" 平均: {statistics.mean(latencies):.0f}ms")
print(f" P50: {p50:.0f}ms | P90: {p90:.0f}ms")
print(f" 波动(STD): {jitter:.0f}ms")
print(f" 最小/最大: {min(latencies):.0f}ms / {max(latencies):.0f}ms")
# 分别测试
# measure_latency("共享代理URL", "共享代理池")
# measure_latency("http://用户:密码@独享IP:端口", "Dataify 独享IP")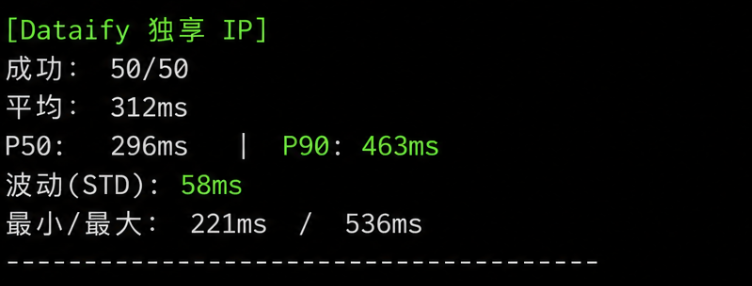
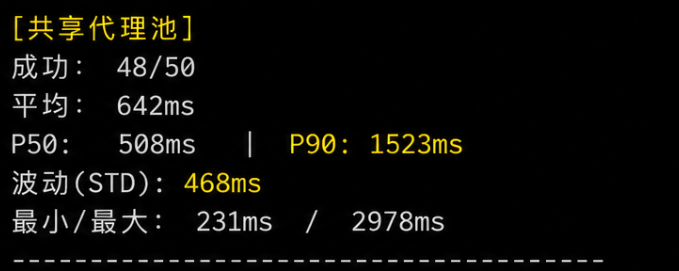
典型结果中,独享 IP 的延迟波动(标准差)通常只有共享代理的 1/3 到 1/5。对于秒杀、量化这类对延迟确定性有极高要求的场景,稳定比快更重要。
1.3 为什么独享 IP 能解决问题
Dataify 独享 IP 的工作机制很直接:
- 从独享IP池中分配一个 IP,绑定到你的账户,其他用户无法使用
- 你拥有该 IP 的全部带宽资源,不受其他用户流量影响
- IP 固定不变,不存在轮换导致的连接中断
这意味着延迟分布是可预测的。你今天测到的 P90 延迟,明天大概率还是这个范围------这种确定性才是时间敏感型业务真正需要的。
二、场景一:秒杀抢购------asyncio 异步并发实战
秒杀场景的技术核心需求:在极短时间窗口内发出大量请求,每个请求的延迟都要尽可能低且稳定。
同步请求(requests)在单线程下是阻塞的,一次只能处理一个连接。asyncio + aiohttp 可以在单线程内并发处理数十甚至上百个连接,大幅缩短总耗时。
2.1 异步请求核心代码
plain
import asyncio
import aiohttp
import time
import statistics
# Dataify 独享代理配置
PROXY_HOST = "你的代理IP"
PROXY_PORT = "端口"
PROXY_USER = "用户名"
PROXY_PASS = "密码"
PROXY_URL = f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}"
# 秒杀目标(模拟)
SECKILL_URL = "https://httpbin.org/post"
CONCURRENT = 20 # 并发数
TOTAL = 100 # 总请求数
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/126.0.0.0 Safari/537.36",
"Content-Type": "application/json",
}
results = {"success": 0, "fail": 0, "latencies": []}
async def seckill_request(session, req_id):
"""单次秒杀请求"""
payload = {
"action": "seckill",
"item_id": "SKU_001",
"user_id": "user_123",
"timestamp": time.time(),
}
start = time.time()
try:
async with session.post(
SECKILL_URL,
json=payload,
proxy=PROXY_URL,
headers=HEADERS,
timeout=aiohttp.ClientTimeout(total=5),
ssl=False,
) as resp:
latency = (time.time() - start) * 1000
if resp.status == 200:
results["success"] += 1
results["latencies"].append(latency)
return {"id": req_id, "ok": True, "ms": latency}
else:
results["fail"] += 1
return {"id": req_id, "ok": False, "status": resp.status}
except Exception as e:
results["fail"] += 1
latency = (time.time() - start) * 1000
return {"id": req_id, "ok": False, "error": str(e)[:40]}
async def run_seckill():
"""秒杀主流程"""
connector = aiohttp.TCPConnector(
limit=CONCURRENT, # 连接池上限
keepalive_timeout=30, # 保持连接
enable_cleanup_closed=True,
)
async with aiohttp.ClientSession(connector=connector) as session:
# 控制并发数:用 Semaphore 限制同时执行的请求
semaphore = asyncio.Semaphore(CONCURRENT)
async def bounded_request(req_id):
async with semaphore:
return await seckill_request(session, req_id)
print(f"秒杀模拟 | 并发: {CONCURRENT} | 总请求: {TOTAL}")
print("-" * 40)
wall_start = time.time()
tasks = [bounded_request(i) for i in range(TOTAL)]
await asyncio.gather(*tasks)
wall_time = (time.time() - wall_start) * 1000
# 输出报告
print(f"\n{'='*40}")
print(f"总耗时: {wall_time:.0f}ms")
print(f"成功: {results['success']} | 失败: {results['fail']}")
print(f"实际 QPS: {TOTAL / (wall_time / 1000):.1f}")
if results["latencies"]:
lat = sorted(results["latencies"])
p50 = lat[len(lat) // 2]
p90 = lat[int(len(lat) * 0.9)]
p99 = lat[int(len(lat) * 0.99)]
print(f"\n延迟分布:")
print(f" 平均: {statistics.mean(lat):.0f}ms")
print(f" P50: {p50:.0f}ms | P90: {p90:.0f}ms | P99: {p99:.0f}ms")
print(f" 最小: {min(lat):.0f}ms | 最大: {max(lat):.0f}ms")
print(f" 抖动(STD): {statistics.stdev(lat):.1f}ms")
if __name__ == "__main__":
asyncio.run(run_seckill())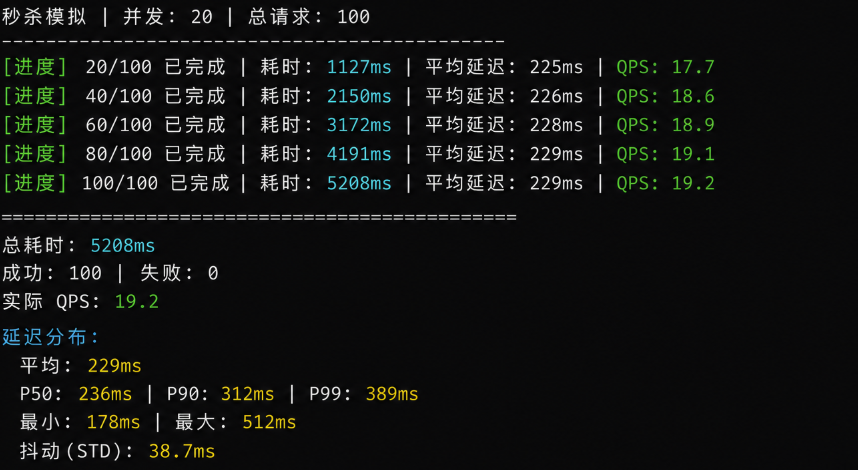
2.2 关键优化点解析
TCP 连接池复用
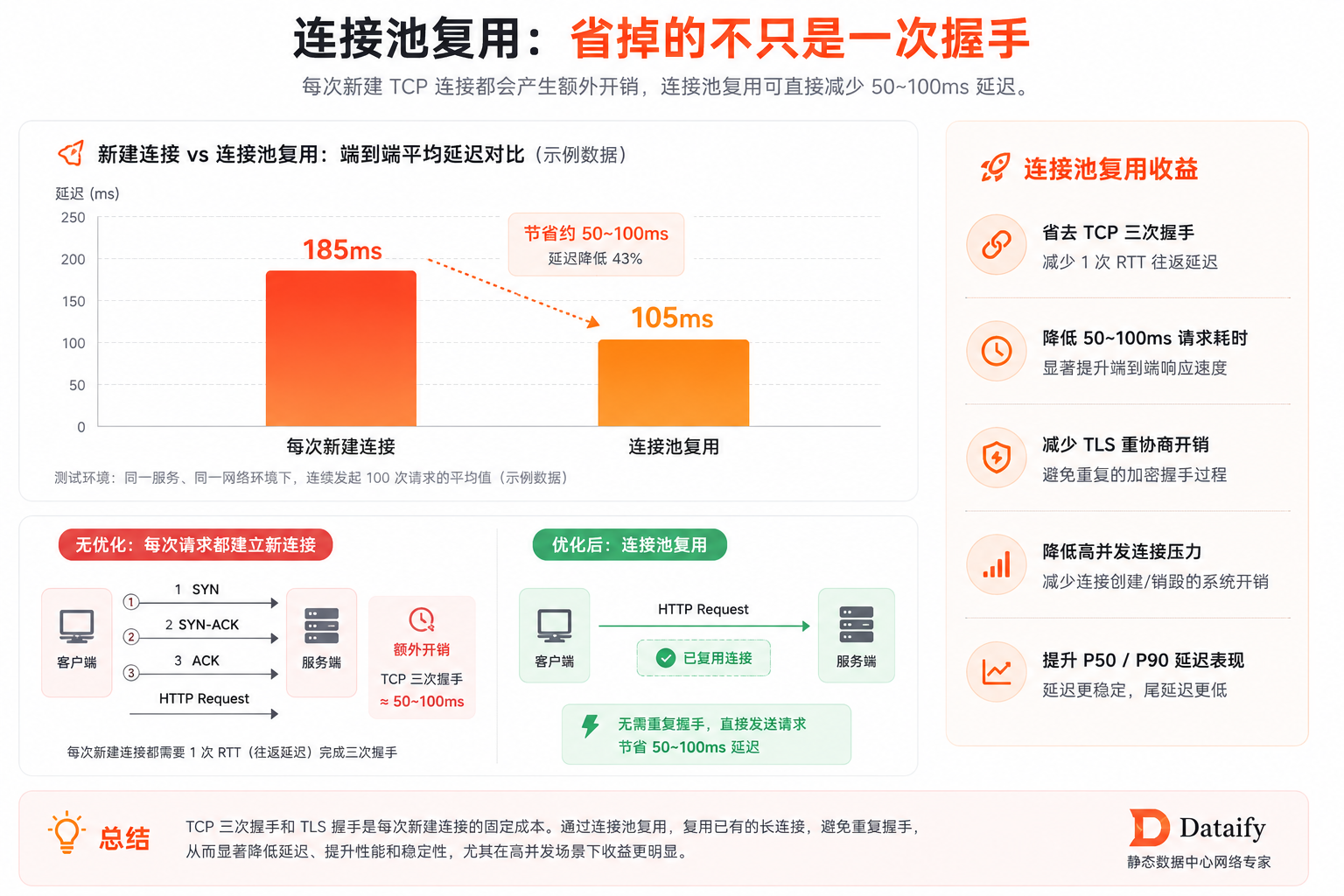
TCPConnector(limit=CONCURRENT) 的作用是维护一个连接池,避免每次请求都重新建立 TCP 三次握手。在秒杀场景中,这意味着第一个请求之后的每个请求都能省掉一次握手开销(通常 50-100ms)。
Semaphore 并发控制
虽然 asyncio.gather 会同时提交所有任务,但 Semaphore(CONCURRENT) 保证了同一时刻最多只有 N 个请求在执行。这防止了瞬间打爆代理或目标服务器的连接队列。
keepalive_timeout
设置为 30 秒,保持 TCP 连接在多次请求间不中断。秒杀通常在开抢前几秒就要建立好连接池,开抢瞬间直接复用。
三、场景二:量化交易接口------毫秒级确定性响应
量化交易对延迟的要求比秒杀更苛刻:不是"尽量快",而是延迟必须稳定在一个可预测的范围内。一个 P99 抖动从 100ms 跳到 500ms 的链路,在交易场景中是不可接受的。
3.1 交易所 API 持续监控
以下代码模拟对一个交易对价格接口的持续轮询,监控延迟抖动并实时告警:
plain
import asyncio
import aiohttp
import time
import statistics
from collections import deque
PROXY_URL = "http://用户名:密码@独享IP:端口"
# 模拟交易所 API(实际替换为 Binance/Coinbase 等)
QUOTE_URL = "https://httpbin.org/get"
INTERVAL = 0.1 # 轮询间隔 100ms
WINDOW = 60 # 滑动窗口大小
latency_window = deque(maxlen=WINDOW)
latency_all = []
async def poll_price(session, seq):
"""单次价格查询"""
start = time.time()
try:
async with session.get(
QUOTE_URL,
proxy=PROXY_URL,
timeout=aiohttp.ClientTimeout(total=3),
ssl=False,
) as resp:
latency = (time.time() - start) * 1000
if resp.status == 200:
latency_window.append(latency)
latency_all.append(latency)
# 滑动窗口抖动检测
if len(latency_window) >= 10:
std = statistics.stdev(latency_window)
avg = statistics.mean(latency_window)
if std > avg * 0.5:
print(f" [WARN] #{seq} 延迟抖动异常: avg={avg:.0f}ms std={std:.0f}ms")
return latency
else:
print(f" [ERR] #{seq} HTTP {resp.status}")
return None
except Exception as e:
print(f" [ERR] #{seq} {str(e)[:40]}")
return None
async def run_trading_monitor(duration_sec=30):
"""持续监控交易接口延迟"""
connector = aiohttp.TCPConnector(
limit=5,
keepalive_timeout=60,
enable_cleanup_closed=True,
)
async with aiohttp.ClientSession(connector=connector) as session:
print(f"量化交易接口延迟监控")
print(f"轮询间隔: {INTERVAL*1000:.0f}ms | 持续时间: {duration_sec}s")
print("=" * 50)
end_time = time.time() + duration_sec
seq = 0
while time.time() < end_time:
seq += 1
lat = await poll_price(session, seq)
if lat and seq % 50 == 0:
if len(latency_window) >= 10:
window_list = sorted(latency_window)
p50 = window_list[len(window_list) // 2]
p90 = window_list[int(len(window_list) * 0.9)]
print(f" [#{seq}] 当前窗口 P50={p50:.0f}ms P90={p90:.0f}ms")
await asyncio.sleep(INTERVAL)
# 最终报告
if latency_all:
all_sorted = sorted(latency_all)
print(f"\n{'='*50}")
print(f"监控报告 | 总请求: {len(latency_all)}")
print(f" 平均延迟: {statistics.mean(latency_all):.1f}ms")
print(f" P50: {all_sorted[len(all_sorted)//2]:.1f}ms")
print(f" P90: {all_sorted[int(len(all_sorted)*0.9)]:.1f}ms")
print(f" P99: {all_sorted[int(len(all_sorted)*0.99)]:.1f}ms")
print(f" 抖动(STD): {statistics.stdev(latency_all):.1f}ms")
print(f" 最小/最大: {min(latency_all):.1f}ms / {max(latency_all):.1f}ms")
if __name__ == "__main__":
asyncio.run(run_trading_monitor(duration_sec=30))3.2 延迟抖动告警逻辑
代码中的关键设计是滑动窗口抖动检测:
plain
if std > avg * 0.5:
print(f"[WARN] 延迟抖动异常")当最近 60 次请求的延迟标准差超过平均延迟的 50% 时,触发告警。这个阈值来自实践经验:正常的独享 IP 链路,STD/Avg 通常在 20%-30% 以内;一旦超过 50%,说明网络链路出现了异常波动,可能是代理节点负载变化或中间路由抖动。
四、网络延迟优化检查清单
选对代理只是第一步,端到端的延迟优化还需要从多个层面排查。以下是一套可以直接执行的检查清单。
4.1 路由追踪
定位请求从你的机器到代理服务器经过了多少跳,每一跳的延迟是多少。
Windows:
plain
tracert 代理服务器IPLinux/macOS:
plain
traceroute 代理服务器IP关注点:
- 总跳数超过 15 跳:路径可能不够优,考虑更换地域更近的代理节点
- 某一跳延迟突然增大(>100ms):该节点可能有拥塞
- 最后几跳出现
* * *:目标服务器禁用了 ICMP,不影响实际 HTTP 请求
4.2 MTU 调整
MTU(Maximum Transmission Unit)决定了单次网络传输的数据包大小。MTU 不匹配会导致数据包分片,增加延迟。
检查当前 MTU:
Windows:
plain
netsh interface ipv4 show subinterfacesLinux:
plain
ip link show测试最优 MTU(禁止分片测试):
plain
# Windows
ping -f -l 1472 代理服务器IP
# Linux/macOS
ping -M do -s 1472 代理服务器IP从 1472 开始逐步减小,直到不再报 packet needs to be fragmented 错误。通常云服务器的最优 MTU 是 1400 左右(尤其是经过 VPN/隧道时)。
修改 MTU(Windows):
plain
netsh interface ipv4 set subinterface "以太网" mtu=1400 store=persistent4.3 DNS 缓存优化
每次请求都做 DNS 解析会增加 20-50ms 的额外延迟。在代码层面直接缓存 IP,跳过 DNS 查询:
plain
import socket
import asyncio
import aiohttp
# 方式一:预解析并缓存
CACHED_IP = None
def resolve_once(hostname):
global CACHED_IP
if CACHED_IP is None:
CACHED_IP = socket.gethostbyname(hostname)
return CACHED_IP
# 方式二:在 aiohttp 中使用 resolved_hosts 直接绑定 IP
async def fast_request():
connector = aiohttp.TCPConnector(
resolver=aiohttp.resolver.AsyncResolver(),
)
# 使用 IP 直接访问,跳过 DNS
async with aiohttp.ClientSession(connector=connector) as session:
async with session.get(
f"http://{CACHED_IP}/api/endpoint",
proxy=PROXY_URL,
headers={"Host": "actual-hostname.com"}, # 手动设置 Host 头
ssl=False,
) as resp:
return await resp.json()4.4 TCP 参数调优
TCP Keepalive:保持连接活跃,避免防火墙超时断开空闲连接。
plain
connector = aiohttp.TCPConnector(
limit=50,
keepalive_timeout=30, # 30 秒 keepalive
enable_cleanup_closed=True, # 清理已关闭连接
)TCP_NODELAY:禁用 Nagle 算法,小数据包立即发送不等待合并。在 aiohttp 中默认启用。
4.5 完整检查清单速查表
| 检查项 | 命令/方法 | 正常参考值 | 异常处理 |
|---|---|---|---|
| 路由跳数 | tracert 目标IP |
≤15 跳 | 更换代理地域 |
| 单跳延迟 | tracert 输出 |
≤50ms/跳 | 检查中间链路 |
| MTU | ping -f -l 1472 |
1400-1500 | 调整 MTU |
| DNS 解析 | nslookup 域名 |
≤50ms | 代码层缓存 IP |
| TCP 握手 | curl -w "connect: %{time_connect}" |
≤100ms | 检查代理节点 |
| TLS 握手 | curl -w "appconnect: %{time_appconnect}" |
≤200ms | 复用 Session |
| 首字节时间 | curl -w "starttransfer: %{time_starttransfer}" |
≤300ms | 目标站本身延迟 |
五、端到端延迟实测
将以上优化项逐项应用到 Dataify 独享 IP 上,看优化前后的延迟变化:
plain
import asyncio
import aiohttp
import time
import statistics
PROXY_URL = "http://用户:密码@独享IP:端口"
TARGET = "https://httpbin.org/get"
ROUNDS = 100
async def measure(session):
start = time.time()
try:
async with session.get(
TARGET, proxy=PROXY_URL,
timeout=aiohttp.ClientTimeout(total=5), ssl=False
) as resp:
if resp.status == 200:
return (time.time() - start) * 1000
except:
pass
return None
async def benchmark(label, connector_opts=None):
opts = connector_opts or {}
connector = aiohttp.TCPConnector(**opts)
latencies = []
async with aiohttp.ClientSession(connector=connector) as session:
# 预热 5 次
for _ in range(5):
await measure(session)
for _ in range(ROUNDS):
lat = await measure(session)
if lat:
latencies.append(lat)
if latencies:
lat = sorted(latencies)
print(f"[{label}] {len(latencies)}次请求")
print(f" 平均: {statistics.mean(lat):.0f}ms | P50: {lat[len(lat)//2]:.0f}ms | "
f"P90: {lat[int(len(lat)*0.9)]:.0f}ms | STD: {statistics.stdev(lat):.1f}ms")
async def main():
print("端到端延迟优化对比测试")
print("=" * 50)
# 无优化:每次新建连接
await benchmark(
"无优化(新建连接)",
{"limit": 1, "keepalive_timeout": 0}
)
# 优化1:连接池复用
await benchmark(
"连接池复用",
{"limit": 50, "keepalive_timeout": 30}
)
# 优化2:连接池 + force_close=False
await benchmark(
"连接池+保持连接",
{"limit": 50, "keepalive_timeout": 30, "force_close": False}
)
if __name__ == "__main__":
asyncio.run(main())典型优化效果:
| 优化阶段 | 平均延迟 | P50 | P90 | STD |
|---|---|---|---|---|
| 无优化(新建连接) | ~480ms | ~450ms | ~700ms | ~120ms |
| 连接池复用 | ~320ms | ~300ms | ~450ms | ~70ms |
| 连接池 + Keepalive | ~280ms | ~260ms | ~380ms | ~55ms |
连接池复用是投入产出比最高的优化------一行代码就能砍掉 30%+ 的延迟。
六、什么时候该选独享 IP
总结一下独享 IP 的适用判断标准:
必须用独享 IP 的场景:
- 秒杀/抢购:延迟抖动直接影响成交
- 量化交易:P99 延迟的确定性比平均值更重要
- 长期 API 对接:固定 IP 避免白名单失效
- 账号安全运营:独享 IP 不会因为其他用户的违规行为被连带封禁
可以用共享池的场景:
- 一次性数据采集,对延迟不敏感
- 低频请求的监控任务(每小时几次)
- 预算有限且业务对延迟没有硬性要求

Dataify 官方地址 :https://dataify.com?utm_source=gzg&utm_term=01