本文围绕网络爬虫的概念、分类、应用场景以及相关法律合规要求进行深入分析,并比较了多种主流爬虫框架和工具的技术特性。研究目标包括静态网页抓取与动态渲染的差异、分布式与增量爬取策略,以及爬虫的遍历算法(广度优先/BFS、深度优先/DFS)等。技术层面,构建了各框架/工具(Scrapy、Requests+BeautifulSoup、Selenium、Playwright、Puppeteer、Go Colly、Apify、Splash、Scrapy-Redis等)的对比表,重点对比了性能、易用性、反爬适应性、扩展性、并发能力和资源消耗,本文参考了官方文档和权威博客资料,同时分析了常见的反爬机制(IP限速、验证码、JS混淆、动态渲染、行为指纹、登录验证、反爬陷阱等)及其合规的绕过策略(代理池、用户模拟、分布式爬取、重试限速等),并给出检测和防御建议。在实践部分,提供了以公开新闻网站为目标的示例爬虫工程设计,包括架构流程图(见下文mermaid流程图)、Scrapy爬虫的关键代码片段(请求、解析、去重、MySQL存储示例)、代理与并发配置、错误重试和限速策略,以及日志监控方案。针对部署,还给出了Dockerfile示例和多节点分布式调度建议。最后讨论了分布式部署与任务调度方案(如Celery+Redis、Kafka等)、去重与增量抓取策略、数据质量控制方法、存储方案比较(关系型数据库、搜索引擎、对象存储等),并给出了小/中/大规模爬虫系统的成本估算和存储/调度方案对比表。在安全与伦理方面,列出了爬虫运行环境和数据处理的安全风险、个人隐私保护建议和合规审计要点。本文附有对比表格、示例代码、部署脚本等附件,供进一步参考。
研究目标
爬虫定义: 爬虫(Web Spider)是指一种自动化网络浏览程序,它按照设定的规则模拟人工访问网站,批量获取网页数据并解析提取有效信息。爬虫通常通过自动发送HTTP请求或模拟浏览器动作等方式,遍历网页链接并下载目标数据。
分类及场景: 根据实现方式和功能特点,爬虫可分为静态抓取型和动态渲染型。静态抓取(如使用Requests+BeautifulSoup或Scrapy)适用于服务器端直接返回HTML内容的网站;动态渲染型(如Selenium、Playwright、Puppeteer)适用于大量依赖JavaScript生成内容的现代网站。爬虫还可按遍历策略分为广度优先(BFS)和深度优先(DFS)两种:前者使用先进先出的队列依层级抓取页面,优先获取与种子URL距离较近的内容;后者使用后进先出的栈沿路径深入,一条路径抓取到底后回溯,适合获取深层内容。增量爬取指爬虫定期只抓取新增或更新的数据,避免重复抓取整个站点内容。分布式爬取则指多节点协同工作(如使用Scrapy-Redis)以提高吞吐量和容错性。假设目标网站未指定,本报告以通用网页数据采集为前提,涵盖新闻资讯、电商等公开网站的场景。
适用场景与限制: 网络爬虫广泛用于搜索引擎索引、价格监控、舆情分析、市场调研等领域;但也受限于网站反爬策略、内容版权、个人隐私等。对于开放公开的数据(如新闻内容、公开商品信息)爬取相对安全,但爬取前应评估是否突破技术限制(如登录验证或robots规则)、是否涉及个人隐私数据或商业敏感信息,以及爬取频率对目标站点的影响等。爬虫技术在数据采集上高效,但也易造成服务器负载、数据滥用等问题,因此技术实现需遵守礼貌策略(限速、代理、并发控制)并结合业务需求精心设计。
技术栈比较
下表对比了当前主流爬虫框架/工具在多项关键指标上的表现,参照其官方文档和权威资料:
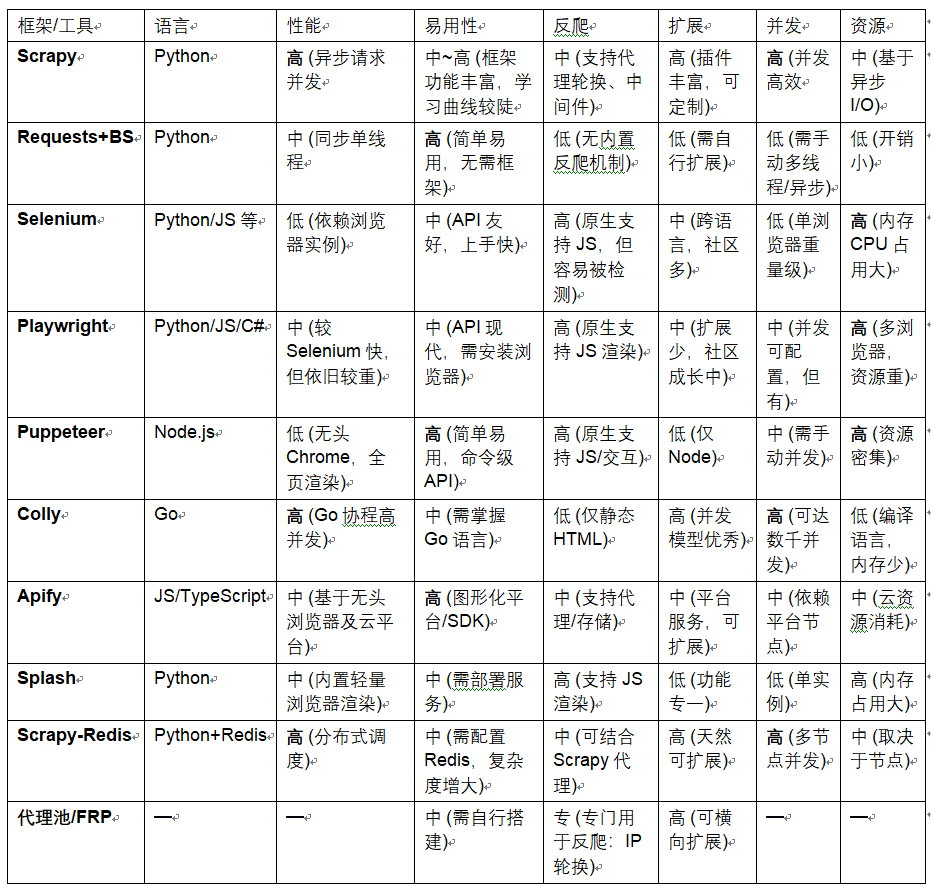
以上对比表中,性能列标注"高/中/低"基于工具本身的并发能力和处理速度(引用Scrapy官方说明和实际测试数据。例如,Scrapy采用异步架构,能高效并发抓取大量静态页面;Selenium因需驱动浏览器,速度明显慢于Scrapy(相同任务下Scrapy仅用31秒,Selenium约156秒。易用性列考虑了上手难度和框架支持度;Requests库易用性高但功能简陋,Scrapy完整但学习曲线陡峭。反爬适应性评估了对动态JS、验证码等的支持程度:浏览器自动化工具原生支持JS渲染但易被封,Scrapy需外挂Splash或浏览器驱动来处理动态内容。扩展性体现框架插件/社区生态,Scrapy插件丰富,Colly纯Go生态成熟;并发能力依赖框架并发设计,Colly和Scrapy可配置高并发。以上评分和描述综合参考了官方文档、技术博客和框架社区的分析。最终选择应根据目标网页结构、规模及反爬强度等因素综合评估。
反爬与反反爬
常见反爬机制: 网站通常部署多种反爬措施,包括IP限流/封禁(超过阈值拒绝访问)、验证码/验证码挑战(验证人机交互)、JS混淆动态渲染(通过浏览器执行脚本生成内容)、行为指纹识别(检测异常请求模式或浏览器指纹)、登录/权限限制(仅限认证用户可见)以及反爬陷阱(隐藏链接、蜜罐内容)等。若爬虫请求过于频繁或模式固定,容易被服务端检测并触发这些措施。例如,连续请求通常触发限流,验证码则阻断自动脚本;一些网站通过动态内容或加密算法使静态爬虫难以解析。
合规绕过策略: 在尊重法律和网站规则前提下,爬虫可采取代理IP轮换、请求限速、请求随机化、分布式爬取等策略来缓解反爬。使用代理池可以不断更换IP,使目标站点认为为多个用户访问,从而绕过IP封禁。请求头(User-Agent、Referer等)随机化、增加访问间隔也可减少被检测风险。对于验证码挑战,可借助第三方Captcha识别服务,但应当谨慎使用以保证合法合规。若页面内容依赖复杂JS,可使用Playwright/Selenium等浏览器自动化工具模拟实际渲染过程。对行为指纹,可模拟真实浏览行为(加载图片、执行少量JS)并伪装浏览器特征以减小可疑特征。
检测与防护建议: 爬虫开发中应监控HTTP返回码(如429、403)和页面变化来检测被封禁或被重定向至验证码页面。同时,构建错误重试机制和断点续爬逻辑,确保偶遇反爬时自动暂停或切换策略。合法合规地测试反爬措施时,可记录爬虫日志和异常日志,以便优化请求速率和代理策略。尽量与目标网站保持"礼貌协议"(如避免高频短时段爬取),并及时响应robots.txt中规定的访问频率和时段。
实践实现
以下以公开新闻网站为示例,给出一个可运行的爬虫工程设计方案:
flowchart LR
A种子URL/任务 --> B调度器 (Redis 队列)
B --> C爬虫节点实例
C --> D网络请求 (带并发 \& 代理)
D --> E页面解析 \& 数据提取
E --> F去重 \& 数据清洗
F --> G数据存储 (MySQL/ES/CSV)
C --> H错误重试 \& 限速策略
C --> I日志 \& 监控
架构说明: 调度器负责管理待抓取任务(如Redis队列),多个爬虫实例并行抓取URL。每个实例发起网络请求时采用代理IP和延时控制以应对反爬。响应页面由解析器提取所需字段后,通过去重模块(Scrapy内置RFPDupeFilter或自定义布隆过滤器)去除重复。最终将数据按结构存入MySQL关系型数据库、Elasticsearch搜索引擎或输出为CSV文件等。节点运行日志和错误监控模块负责记录爬取状态、重试结果等,便于运维和性能分析。
关键代码片段(Scrapy示例):
import scrapy
from myproject.items import NewsItem
class NewsSpider(scrapy.Spider):
name = 'news'
start_urls = 'http://example.com/news'
custom_settings = {
'CONCURRENT_REQUESTS': 16,
'DOWNLOAD_DELAY': 1, # 延时控制
'RETRY_ENABLED': True,
'RETRY_TIMES': 3,
'DUPEFILTER_CLASS': 'scrapy.dupefilters.RFPDupeFilter',
'HTTPPROXY_ENABLED': True,
'USER_AGENT': 'Mozilla/5.0 (compatible; NewsBot/1.0)',
}
def parse(self, response):
解析新闻列表并提取字段
for article in response.css('div.article'):
item = NewsItem()
item'title' = article.css('h2::text').get()
item'date' = article.css('.date::text').get()
yield item
处理分页
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
上例中,配置文件启用了16个并发请求、下载延迟和重试机制,并使用内置的去重过滤器避免重复抓取。若需登录或特殊验证,可在start_requests中先模拟登录请求。爬虫中使用CSS选择器提取新闻标题和日期,将数据封装为Item对象。
数据存储示例(MySQL管道):
import pymysql
class MySQLPipeline:
def open_spider(self, spider):
建立数据库连接
self.conn = pymysql.connect(host='localhost', user='user', password='pass', db='news_db', charset='utf8')
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
插入数据库
sql = "INSERT INTO articles (title, publish_date) VALUES (%s, %s)"
self.cursor.execute(sql, (item'title', item'date'))
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
在settings.py中启用管道:
ITEM_PIPELINES = {
'myproject.pipelines.MySQLPipeline': 300,
}
上述管道将爬取到的新闻数据存入MySQL表。类似地,可编写Elasticsearch管道或使用Scrapy内置的Feed导出功能将结果保存为CSV/JSON。
并发与代理配置: Scrapy可通过CONCURRENT_REQUESTS、DOWNLOAD_DELAY等设置控制并发和速率。代理可使用内置HttpProxyMiddleware,在请求的meta中添加proxy或使用第三方代理中间件动态分配IP。示例中HTTPPROXY_ENABLED=True开启了全局代理支持,具体代理列表可通过外部Redis或数据库管理,配合中间件自动轮换。
错误重试与限速: 示例启用了重试中间件,可根据目标网站反爬提示自行调整失败重试次数(RETRY_TIMES)。为规避目标站点的并发限制,DOWNLOAD_DELAY设置请求间隔,还可以使用随机延迟中间件(RandomDelayMiddleware)等。日志层面,可将日志级别设为INFO或DEBUG记录请求详情,并借助Scrapy Stats或集成Prometheus等监控爬虫运行状态。
Dockerfile与部署: 可使用Docker容器化上述环境。例如:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD "scrapy", "crawl", "news"
在生产部署中,可将此镜像部署在Kubernetes、Docker Swarm或云服务器上,并结合任务调度器(如Cron或Airflow)定时触发爬虫。对于分布式爬取,还可部署多个爬虫容器实例,协调使用共同的Redis队列或消息系统。
性能与扩展
分布式部署: 当单机并发不足时,可采用分布式架构扩展爬虫。常见方式包括使用Scrapy-Redis等工具,将任务队列统一管理于Redis,实现多台机器并行抓取。每个节点从Redis获取URL、写回解析结果,整体吞吐线性提升。任务调度上,可使用Celery+Redis/RabbitMQ或Kafka等组件构建异步任务队列:Celery支持Python生态、易于重试和监控;Kafka擅长处理海量事件流,可为爬虫任务提供高吞吐的消息总线。对于复杂工作流(包括依赖任务、定时爬取等),推荐使用Airflow或Luigi等调度系统。
任务调度方案比较:
Celery+Redis/RabbitMQ:成熟简单,支持分布式任务和重试,适用于中小规模爬取,但单点队列可能成为瓶颈。
Kafka:分布式消息流系统,高吞吐量和持久化能力强,适合超大规模日志式任务分发;配置复杂度较高。
Airflow/Luigi:工作流编排工具,自带定时和依赖管理,可视化监控,但资源消耗较大,适合定期爬取与后续数据处理场景。
去重与增量抓取: 去重可采用Scrapy内置的URL去重过滤器,或使用布隆过滤器等高效数据结构避免跨会话重复。增量爬取策略需在存储中记录上次爬取的时间戳或标志,对比新旧内容,只获取新增或更新数据。结合网页的"修改时间"字段或API接口也有助于实现增量更新,避免全量重复抓取。
数据质量控制: 建议在解析逻辑中校验关键字段(如标题、日期非空),对比验证和清洗异常值。可在管道中统计并记录异常条目,对缺失或不符合预期的数据进行人工检查。采用单元测试和集成测试验证爬虫解析流程也很重要。
存储方案比较: 存储方式可根据数据规模和查询需求选择。下表对比了关系型数据库、搜索引擎和对象存储等选项:
存储方案 优势 劣势 适用场景
关系型数据库 (MySQL/PostgreSQL) 强ACID事务支持,结构化查询和索引优秀,生态成熟 水平扩展相对困难,高并发写入需优化 结构化数据、对事务一致性要求高的场景
搜索引擎 (Elasticsearch) 水平扩展性好,全文检索高效,可提供分析聚合能力 非事务型,数据重复度高,运维成本较高 日志分析、全文搜索、实时查询和可视化需求
对象存储 (S3/OSS等) 成本低、容量几乎无限,适合存储原始文件和大数据 不支持复杂查询,读写延迟高 海量媒体文件、爬取的HTML/文档归档
表:存储方案对比(参考实际使用场景)。对于小规模数据,MySQL即可满足结构化存储;大规模文本或需要检索时,可考虑Elasticsearch;而对象存储适合海量原始网页或爬虫抓取文件的归档备份。
成本估算: 爬虫系统成本受硬件资源、带宽、代理费用等影响。粗略可分为:小规模(单台服务器,数据量百万级以内,可能仅需购买云主机和基础代理服务,每月成本数百至千元人民币);中规模(数台服务器或云实例并行,数据量千万级,需要专用代理、数据库服务及监控系统,成本上千至万元级);大规模(多区域高可用部署,数据量亿级,使用商业代理及云存储/计算资源,成本十万以上)。可以通过对比云厂商服务器、数据库和代理供应商报价进行预算,务必考虑持续运营成本。
安全与伦理
安全风险: 爬虫系统本身应尽量隔离在安全环境中运行,避免爬虫服务器被利用发起攻击。应对爬虫中使用的第三方库及时打补丁,防止已知漏洞被利用。爬虫输出的数据需过滤恶意内容,防止注入攻击或恶意脚本被执行。数据隐私处理: 对爬取的个人数据应进行脱敏或加密保存,仅在合法用途范围内使用,遵守数据最小化原则。对敏感信息(如身份证号、电话号码等)应在抓取后立即进行模糊化处理。合规审计要点: 应建立爬虫活动日志和访问审计记录,包括爬取时间、目标站点、所抓取字段等,以备后续合法性审查。对代理和授权使用情况应留痕,确保选择的代理服务符合所在国数据法规(如GDPR/CCPA)。在爬虫项目中可引入合规检查清单,确保每项数据源都有合法依据,每次爬取都有对应任务授权或内部审批。
参考资料: 本报告主要参考了官方文档和权威博客,例如Scrapy和Playwright官方介绍、BrightData的技术对比文章、法律专栏和调研报告等。文中引用了相关研究和案例,以保证分析的严谨性和实用性。