论文标题: NOVA: A Verification-Aware Agent Harness for Architecture Evolution in Industrial Recommender Systems
论文链接: https://arxiv.org/abs/2606.27243v1
论文作者: Shaohua Liu, Liang Fang, Yilong Sun, Shudong Huang, Qingsong Luo, Shaoxin Liu, Xiaoyang Chen, Dongqiang Liu, Chuangang Ma, Zhenzhen Chai, Henghuan Wang, Shijie Quan, Changyuan Cui, Zhangbin Zhu, Peng Chen, Wei Xu, Lei Xiao, Haijie Gu, Jie Jiang(Tencent Inc.)
一句话总结: NOVA 把工业广告推荐模型的架构演进建模为"架构梯度 + 多级验证"的闭环 Agent Harness,在候选结构进入昂贵训练和线上实验前拦截可运行但语义错误的 silent failure,并在腾讯工业广告系统中把 L3 文献到生产任务的 EPR 提升到 60.0%。
背景与动机
工业广告推荐模型的质量提升越来越依赖架构级演进:从 LR/FM/FFM,到 Wide & Deep、DeepFM、DCN,再到 DIN/DIEN/SIM、RankMixer、TokenMixer-Large、MixFormer,核心增益逐步从简单特征工程转向更强的 backbone 和交互机制。
现有自动化方法覆盖不足。AutoML 主要搜索学习率、hidden size、embedding 维度、层数等局部超参;通用 coding agent 主要以编译通过、单测通过为目标。但在推荐系统里,代码能跑不代表架构有效:候选修改可能保留张量 shape,却错误删除序列 mask、把 self-attention 退化成 MLP,或改坏 logit fusion 路径,形成论文定义的 silent failure。
NOVA 的核心 insight:把验证结果本身变成下一轮搜索信号,而不是只做后置过滤。失败候选的结构语义错误会被写入 trajectory memory,并作为 forbidden directions 注入下一轮 architecture gradient。
整体架构
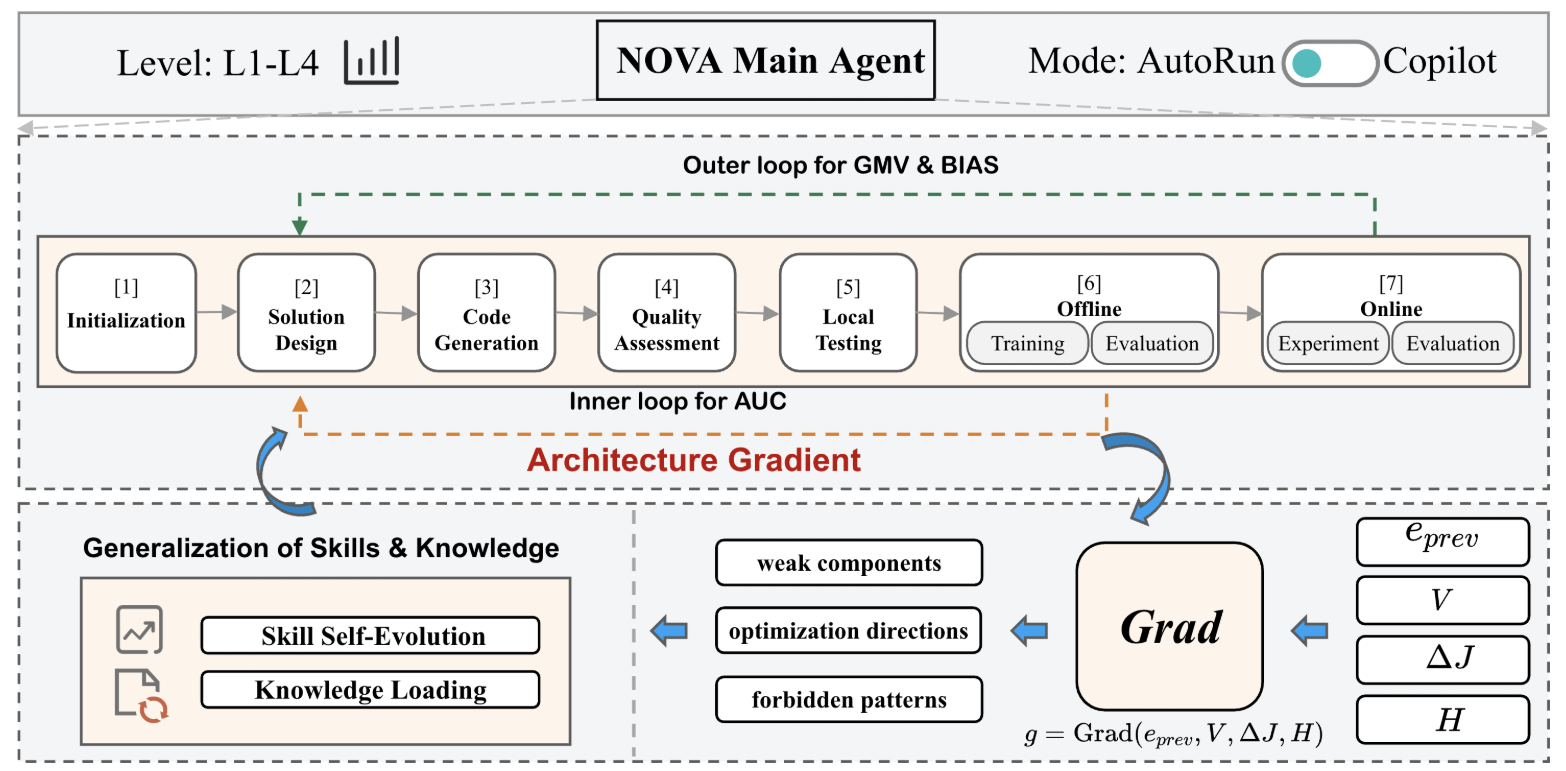
端到端流程:给定生产模型代码库 C、论文或知识源 P/KB、约束集合 Ω 和离线预算 N,NOVA 先确定任务等级 L1--L4 与执行模式 AutoRun/Copilot;随后 Main Agent 编排 Initialization → Solution Design → Code Generation → Quality Assessment → Local Testing → Offline Training & Evaluation → Online Experiment & Evaluation 七个阶段。离线内环以 AUC 作为 J_offline 搜索可行候选,线上外环以 GMV/Bias 作为 J_online 验证最终候选。
关键数据流:
-
输入: 初始生产架构
A_0=(G_0,φ_0,F_0),其中G_0是模型图,φ_0是结构超参,F_0是特征配置。 -
候选生成: 根据当前 architecture gradient
g_t和轨迹记忆H_t生成至多K个架构修改e_t。 -
验证级联: 先过结构语义门与本地可执行门,再进入离线 AUC 评估。
-
反馈更新: 把验证诊断
V_t、指标变化ΔJ_t、失败模式写回H_t,生成下一轮g_{t+1}。 -
线上验证: 从离线轨迹中选择
A_off^*,用 5% 生产流量做 A/B,观测 GMV 和 pCVR bias。
逐模块方案拆解
3.1 架构状态与可行修改空间
模块作用:把生产推荐模型的"可被 Agent 修改的对象"形式化为离散、受约束的架构状态。
输入:生产代码库 C、论文源 P、静态知识库 KB、数据 D、预算 B。输出:候选架构 A_t ∈ A_Ω。
A t = ( G t , ϕ t , F t ) A_t=(G_t,\phi_t,F_t) At=(Gt,ϕt,Ft)
变量说明:
-
A_t:第t轮候选架构,离散对象;可理解为 batch 之外的全局模型状态。 -
G_t:模型计算图,包含 token interaction、attention、fusion、residual 等拓扑结构。 -
φ_t:结构超参数集合,例如 token count、token dimension、RankMixer 层数;shape 可写成φ_t ∈ R^{d_φ},其中d_φ为可调结构变量数。 -
F_t:特征配置集合,包含特征增删、分组、feature-to-token mapping;shape 可写成F_t ∈ {0,1}^{M}或结构化 schema,M为候选特征/路由项数量。
一次候选修改定义为:
A t + 1 = A p p l y ( A t , e t ) A_{t+1}=\mathrm{Apply}(A_t,e_t) At+1=Apply(At,et)
变量说明:
-
e_t ∈ E:第t轮架构修改,可能是结构超参调整、特征增删、sequence modeling 升级、模块替换或论文结构迁移。 -
E:可选修改空间,不是连续向量空间,而是受工程约束的离散操作集合。 -
Apply(·):把修改e_t应用到当前架构A_t的构造函数,输出新候选A_{t+1}。
可行域约束为:
A Ω = { A ∣ A s a t i s f i e s Ω } A_\Omega=\{A\mid A\ \mathrm{satisfies}\ \Omega\} AΩ={A∣A satisfies Ω}
变量说明:
-
Ω:硬约束集合,包含接口兼容、张量 shape 一致、dtype 一致、特征可用性、训练框架兼容、serving 兼容、latency、参数量/FLOPs 预算。 -
A_Ω:满足生产约束的候选集合;NOVA 只允许Apply(A_t,e_t) ∈ A_Ω的修改进入后续流程。
3.2 Architecture Gradient 搜索信号
模块作用:把上一轮修改、验证诊断、指标变化和轨迹记忆聚合成下一轮搜索方向,替代不可用的标准反向传播梯度。
输入:上一轮修改 e_{t-1}、验证诊断 V_t、离线指标变化 ΔJ_t、轨迹记忆 H_t。输出:架构梯度 g_t。
g t = G r a d ( e t − 1 , V t , Δ J t , H t ) g_t=\mathrm{Grad}(e_{t-1},V_t,\Delta J_t,H_t) gt=Grad(et−1,Vt,ΔJt,Ht)
变量说明:
-
g_t:第t轮 architecture gradient,是结构化文本/规则/诊断信号,不是可微梯度;包含 weak components、optimization directions、forbidden patterns。 -
e_{t-1}:上一轮实际采用或失败的修改。 -
V_t:验证诊断,包含 shape、mask、feature mapping、attention direction、logit fusion、本地执行错误等信息。 -
ΔJ_t:离线目标变化,论文中主要是 AUC 变化;标量。 -
H_t:当前任务内轨迹记忆,记录历史修改、失败、诊断、metric feedback;可视为长度为t的序列H_t=[h_0,...,h_{t-1}]。
NOVA 根据 g_t 选择下一步修改:
e t ∗ ∈ arg max e ∈ E S c o r e ( e ; g t , H t ) s . t . A p p l y ( A t , e ) ∈ A Ω e_t^*\in \arg\max_{e\in E}\ \mathrm{Score}(e;g_t,H_t)\quad \mathrm{s.t.}\quad \mathrm{Apply}(A_t,e)\in A_\Omega et∗∈arge∈Emax Score(e;gt,Ht)s.t.Apply(At,e)∈AΩ
变量说明:
-
Score(e;g_t,H_t):候选修改与当前梯度方向、历史成功/失败经验、约束裕量的匹配分数。 -
e_t^*:本轮被选中的架构修改。 -
约束项保证修改后的候选仍处于生产可行域
A_Ω。
3.3 七阶段 Agent Workflow
模块作用:把 architecture-gradient update 落地成生产研发流程,由 Main Agent 协调多个专业阶段。
输入:任务描述、初始架构 A_0、候选数 K、预算 N。输出:离线最优且可线上验证的候选 A^*。
C a n d t = P r o p o s e ( A t , g t , H t ) , ∣ C a n d t ∣ = K \mathrm{Cand}_t=\mathrm{Propose}(A_t,g_t,H_t),\quad |\mathrm{Cand}_t|=K Candt=Propose(At,gt,Ht),∣Candt∣=K
变量说明:
-
Cand_t:第t轮候选修改集合,shape 为长度K的离散列表。 -
K:每轮最多生成的候选数。 -
Propose(·):Solution Design / Code Generation 结合当前梯度生成候选。
s u r v i v o r s t = { e ∈ C a n d t ∣ V s e m ( A p p l y ( A t , e ) ) . f a i l = F a l s e ∧ V l o c a l ( A p p l y ( A t , e ) ) . f a i l = F a l s e } \mathrm{survivors}t=\{e\in \mathrm{Cand}t\mid V{sem}(\mathrm{Apply}(A_t,e)).fail=\mathrm{False}\land V{local}(\mathrm{Apply}(A_t,e)).fail=\mathrm{False}\} survivorst={e∈Candt∣Vsem(Apply(At,e)).fail=False∧Vlocal(Apply(At,e)).fail=False}
变量说明:
-
survivors_t:通过结构语义门和本地执行门的候选集合,长度不超过K。 -
V_sem:结构语义验证器,检查 feature-to-token mapping、mask semantics、attention direction、logit fusion、shape/dtype。 -
V_local:本地可执行验证器,检查 import、operator availability、runtime shape、dtype cast、traceback repair。 -
fail:布尔标志;True表示候选被拦截,不进入昂贵训练。
3.4 Silent-Failure-Aware Verification Cascade
模块作用:在候选进入离线训练和线上实验前,用逐级验证拦截"能跑但语义错"的候选,并把失败模式反馈给下一轮。
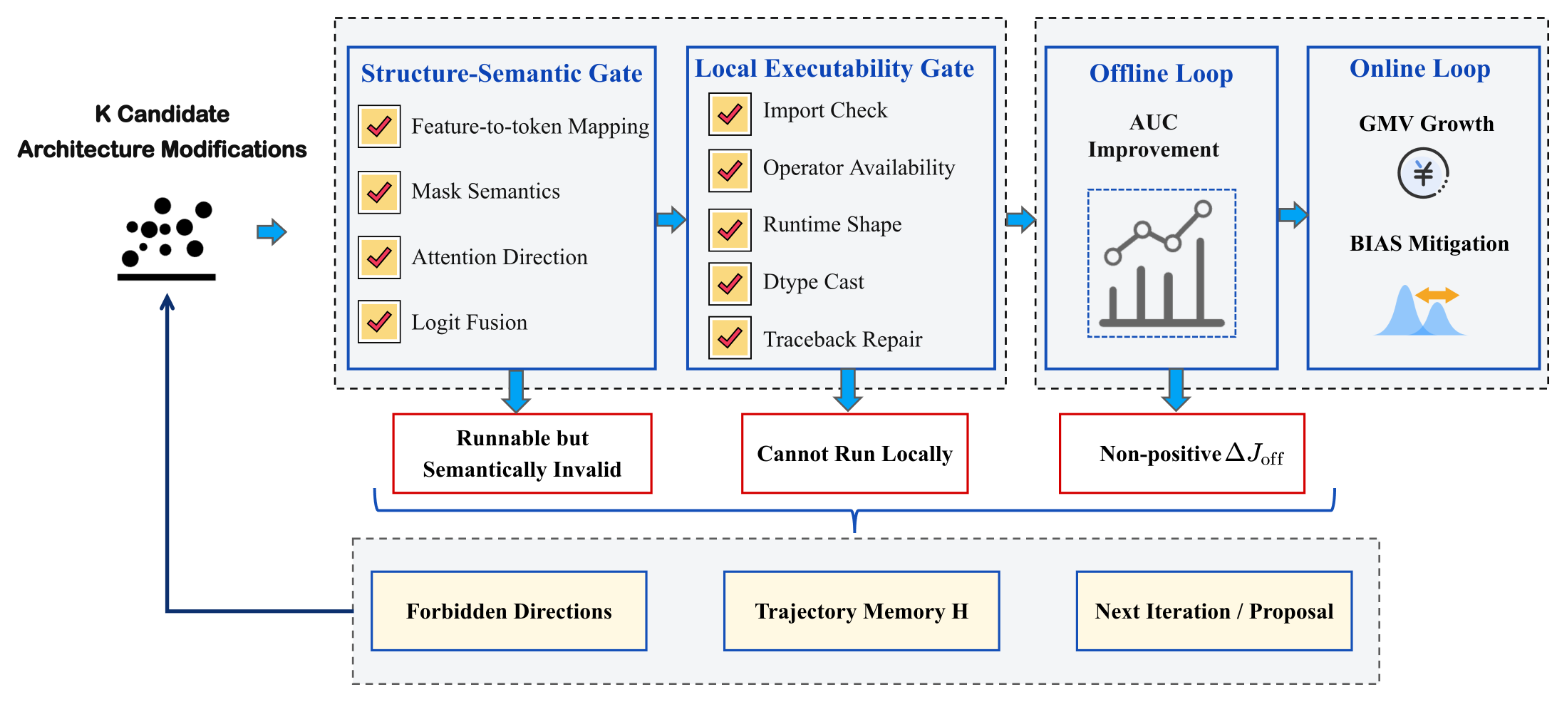
验证级联包含四层:
-
Structure-Semantic Gate: 检查特征到 token 的映射、mask 语义、attention 方向、logit fusion。
-
Local Executability Gate: 检查 import、算子可用性、runtime shape、dtype cast、traceback repair。
-
Offline Loop: 用 AUC 改善判断候选是否真正有效。
-
Online Loop: 用 GMV growth 与 Bias mitigation 判断生产效果。
失败反馈写入轨迹记忆:
H ← H ∪ { ( e , r s e m , ⊥ ) } o r H ← H ∪ { ( e , r l o c a l , ⊥ ) } H\leftarrow H\cup\{(e,r_{sem},\bot)\}\quad \mathrm{or}\quad H\leftarrow H\cup\{(e,r_{local},\bot)\} H←H∪{(e,rsem,⊥)}orH←H∪{(e,rlocal,⊥)}
变量说明:
-
H:轨迹记忆,存放历史候选与诊断。 -
e:失败候选修改。 -
r_sem:结构语义检查结果,例如 mask 方向错误、feature routing 错误。 -
r_local:本地执行检查结果,例如 import 失败、runtime shape 错误。 -
⊥:失败标记,表示该候选没有进入有效 metric feedback。
如果所有候选都在训练前被拒绝:
g t + 1 = G r a d ( f a i l e d m o d i f i c a t i o n s , d i a g n o s t i c s , Δ J f a i l , H ) g_{t+1}=\mathrm{Grad}(\mathrm{failed\ modifications},\mathrm{diagnostics},\Delta J_{fail},H) gt+1=Grad(failed modifications,diagnostics,ΔJfail,H)
变量说明:
-
ΔJ_fail:负向 sentinel 信号,表示当前轮没有有效候选通过验证。 -
diagnostics:本轮失败诊断集合,shape 为长度K的结构化列表。 -
g_{t+1}:下一轮梯度,包含从失败模式中提取的 forbidden directions。
3.5 L1--L4 任务等级与 AutoRun/Copilot 控制
模块作用:根据任务复杂度和技能覆盖范围决定修改范围与是否需要人类确认。
| Level | 任务类型 | 典型任务 | 模式 |
|---|---|---|---|
| L1 | Atomic structural tuning | 调整单一架构变量,例如 RankMixer 层数或 token dimension | AutoRun |
| L2 | Constraint-aware ScaleUp | 在参数量/FLOPs 预算下联合调整 token count、token dimension、RankMixer layers | AutoRun |
| L3 | Literature-to-production transfer | 把 TokenMixer-Large、AttentionRes、MixFormer、OneTrans 等论文模块迁移到生产模型 | AutoRun 或 Copilot |
| L4 | Open-ended innovation | 根据趋势、业务需求或历史证据提出新结构 | Copilot |
执行模式不是由等级单独决定,而由 skill-specification coverage 决定:覆盖充分的修改走 AutoRun;未覆盖或高风险决策走 Copilot。
训练目标 / 损失函数
论文没有提出一个新的可微训练 loss 来训练 Agent;NOVA 的"优化目标"分为离线内环目标和线上外环目标。
离线内环目标:
max A J o f f l i n e ( A ) = A U C ( A ) s . t . A ∈ A Ω \max_A\ J_{offline}(A)=\mathrm{AUC}(A)\quad \mathrm{s.t.}\quad A\in A_\Omega Amax Joffline(A)=AUC(A)s.t.A∈AΩ
变量说明:
-
A:候选推荐模型架构。 -
J_offline(A):离线评价目标,论文用 AUC 表示。 -
AUC(A):候选架构在离线训练/评估集上的 AUC。 -
A_Ω:满足生产硬约束的架构集合。
线上外环目标:
J o n l i n e ( A ) = ∑ i w i m i ( A ) , m i ∈ { G M V , B i a s } J_{online}(A)=\sum_i w_i\,m_i(A),\quad m_i\in\{\mathrm{GMV},\mathrm{Bias}\} Jonline(A)=i∑wimi(A),mi∈{GMV,Bias}
变量说明:
-
J_online(A):线上业务目标。 -
m_i(A):第i个线上指标;论文使用 GMV 和 Bias。 -
w_i:业务权重;对 lower-is-better 的 Bias 使用负权重。 -
i:线上指标索引。
工程有效性指标:
L P R = N p N g \mathrm{LPR}=\frac{N_p}{N_g} LPR=NgNp
变量说明:
-
LPR:Local Pass Rate,本地执行通过率。 -
N_g:生成候选数。 -
N_p:通过本地测试的候选数。
S F R = 1 − N + N p = N p − N + N p \mathrm{SFR}=1-\frac{N_+}{N_p}=\frac{N_p-N_+}{N_p} SFR=1−NpN+=NpNp−N+
变量说明:
-
SFR:Silent Failure Rate,本地能跑但离线无正收益的比例。 -
N_+:本地通过且ΔAUC > 0.001的候选数。
E P R = N + N g = L P R ⋅ ( 1 − S F R ) \mathrm{EPR}=\frac{N_+}{N_g}=\mathrm{LPR}\cdot(1-\mathrm{SFR}) EPR=NgN+=LPR⋅(1−SFR)
变量说明:
-
EPR:Effective Pass Rate,从生成候选到离线正收益的端到端成功率。 -
ΔAUC > 0.001:论文定义 AUC-positive 的阈值。
实验分析
实验设置:L2 ScaleUp 在生产 RankMixer-style backbone 上联合搜索 token_cnt、token_dim、RankMixer 层数,并保持模型大小在生产 baseline 的 ±10% 范围内;L3 Literature-to-Production 测试把 TokenMixer-Large 迁移到同一生产 backbone,要求保持 feature pipeline、张量 shape、训练稳定性和推理兼容性。数据来自生产广告推荐流量,覆盖一个月、十亿级用户-物品交互记录和超过一千个特征字段。所有 LLM 方法使用同一 base model Claude Sonnet 4.6。
主结果:NOVA 在 L2/L3 上取得最高 EPR
| 方法 | L2 LPR ↑ | L2 SFR ↓ | L2 EPR ↑ | L3 LPR ↑ | L3 SFR ↓ | L3 EPR ↑ |
|---|---|---|---|---|---|---|
| Human Expert Loop | 95.5% | 48.4% | 49.3% | 40.0% | 22.2% | 31.1% |
| OpenHands | 33.3% | 80.0% | 6.7% | 27.3% | 62.5% | 10.2% |
| ReActAgent-only | 37.5% | 66.7% | 12.5% | 25.0% | 71.4% | 7.1% |
| Optuna-TPE | 17.2% | 72.7% | 4.7% | -- | -- | -- |
| NOVA | 99.0% | 45.5% | 54.5% | 86.7% | 30.8% | 60.0% |
结论:L2 表面像超参搜索,但变量之间存在结构耦合,例如 token_cnt 必须与 token_dim 兼容;L3 则要求把论文结构转成生产可执行、语义正确的修改。NOVA 同时提升 LPR 并降低 SFR,因此 EPR 在 L2 达到 54.5%,在 L3 达到 60.0%。
消融:Architecture Gradient 不是简单日志,而是搜索知识
| Variant | Removed component | LPR ↑ | SFR ↓ | EPR ↑ |
|---|---|---|---|---|
| NOVA (full) | Full system | 86.7% | 30.8% | 60.0% |
| w/o Paper Reproduction | 去掉结构化论文分析与复现产物,只给原始文档和短任务描述 | 91.7% | 63.6% | 33.3% |
| w/o Solution Design | 去掉把论文架构映射到生产修改方案的规划步骤 | 81.8% | 77.8% | 18.2% |
| w/o Multi-Candidate Generation | 每轮只生成一个候选修改 | 66.7% | 61.1% | 25.9% |
| w/o Quality Assessment | 去掉本地测试和训练前的架构感知候选审查 | 71.9% | 69.6% | 21.9% |
| w/o Architecture-Gradient Feedback | 去掉迭代级诊断反馈到 architecture gradient | 87.5% | 57.1% | 37.5% |
关键结论:去掉 Architecture-Gradient Feedback 后 LPR 仍有 87.5%,但 SFR 升到 57.1%,EPR 降到 37.5%。这说明系统仍能生成能跑的代码,却更容易产生架构无效的 silent failure;NOVA 的收益来自把失败诊断转成 forbidden directions,而不是只记录最终指标。
线上 A/B:GMV 提升且 pCVR bias 下降
| Objective | GMV | pCVR bias |
|---|---|---|
| task1 | +1.25% | −58.8% |
| task2 | +1.70% | −66.7% |
| task3 | +2.02% | −37.3% |
线上验证使用 L3 Literature-to-Production 中离线 AUC 最优的 TokenMixer-Large transfer candidate,在生产 pCVR 模型上以 5% 流量进行 request-level randomization A/B。三个 pCVR 目标的 GMV 分别提升 +1.25%、+1.70%、+2.02%,同时 pCVR bias 分别下降 58.8%、66.7%、37.3%。
生产代码修改案例
论文给出两个 L3 代表性案例:
-
参数高效变体: 直接复现 TokenMixer-Large 会使用四个 TokenMixer blocks、inter-residual connections 和 auxiliary loss;NOVA 找到更轻的 two-block 变体,约使用 43% dense parameters,同时保持接近的离线效果。
-
辅助损失修正: 初始迁移整体为正但 task1 lift 不足;NOVA 先尝试移除 auxiliary loss,发现伤害 task2/task3;随后用更小权重重引入 task1-specific auxiliary signal,并修正 task1 auxiliary-loss index、mask 掉 task3 的全局辅助目标,最终回到更优轨迹。
优势与局限
优势:
-
面向推荐架构语义,而非仅面向代码可运行。 NOVA 明确检查 feature-to-token mapping、mask semantics、attention direction、logit fusion 等推荐系统特有语义,减少 runnable-but-negative 候选。
-
把验证诊断变成搜索信号。 失败候选不会只被丢弃,而是写入
H并转成 forbidden directions,降低后续重复踩坑概率。 -
覆盖从低风险调参到高风险创新的任务谱系。 L1--L4 与 AutoRun/Copilot 让系统根据技能覆盖和风险决定自动化程度。
-
工业验证充分。 在腾讯大规模广告系统上,L2/L3 均取得最高 EPR,L3 线上 A/B 同时提升 GMV 并降低 bias。
局限:
-
语义门不能判断业务有效性。 论文明确指出 semantic gate 只判断结构语义与工程可行性,不能判断 semantically valid 修改是否带来业务收益;性能失败仍依赖离线和线上评估。
-
技能规格覆盖决定自动化边界。 未覆盖或高风险场景需要 Copilot,人类确认仍是边界条件。
-
实验域集中在工业广告推荐。 数据、特征规模、工程约束、GMV/Bias 指标都来自生产广告系统,论文没有证明该 harness 在非广告推荐或非推荐架构搜索中的同等效果。
-
LLM 基座能力被固定但没有跨模型展开。 实验统一使用 Claude Sonnet 4.6,以隔离 harness 设计效果;论文没有系统比较不同基座模型对 NOVA 的影响。