大家好,这里是办公智能体广场。在日常办公中,我们经常会遇到证件、票据、扫描件或文件夹中的图片需要整理成 PDF 的情况。很多时候,麻烦的不只是合并,而是要先分清哪些图片该放在一起、谁排前谁排后、每页放几张才整齐。人工一张张处理不仅耗时,也容易出错。
今天就介绍一个非常简单的方法,只需要用自然语言描述你的需求,就可以完成图片智能合并成PDF,自动识别分组关系、整理顺序,并生成版式更整齐的 PDF,特别适合处理证件材料、报销附件、扫描件归档等常见办公场景。
一、需求分析
图片合成 PDF 并不只是把几张图片拼在一起,很多时候更重要的是先分组、再排序,最后按合适的方式输出。不同场景下,用户想解决的问题也不一样。下面我介绍几个常见案例。
1、身份证正反面合并
把同一个人的身份证正反面自动配对,每人一组放到PDF的一页里面,上部分放正面,下部分放反面,方便提交和归档。
比如有原始身份证图片:
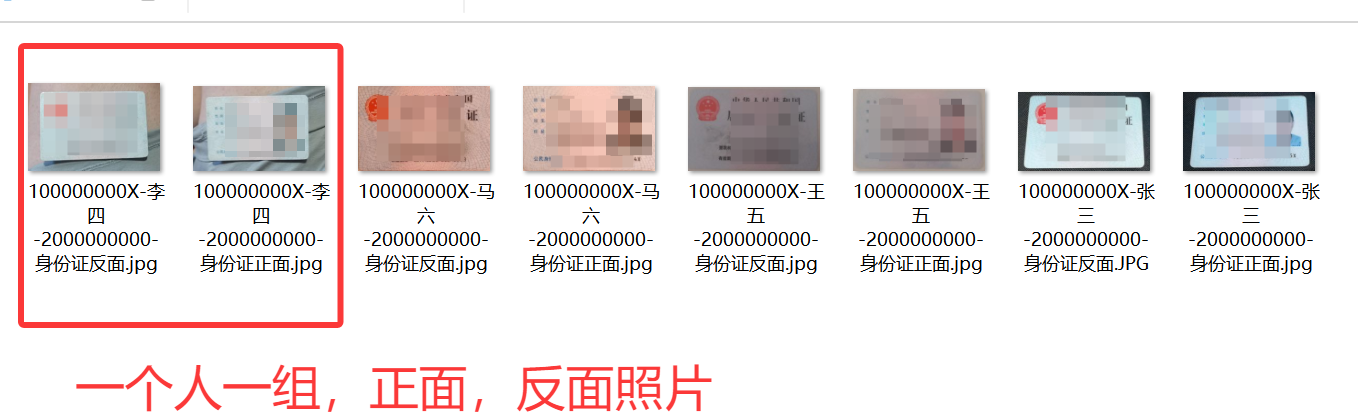
上面有4个人, 那么就会合成4个PDF ,每个PDF打开如下:

不一定是上下排版,也可以左右, 取决于你的提示词描述!
上面效果的提示词描述为:
身份证正反面自动配对,每人一组,上面是正面,下面是反面2、按报销单号分组合成
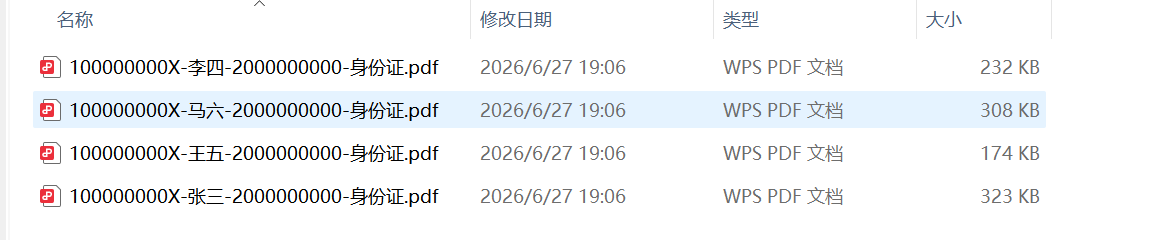
报销附件通常是混在一起的,用户需要按报销单号自动分组,让同一个单号的材料合成到一个PDF里面。
比如,有如下原始图片数据:

合成的结果就有4个PDF, 每一个PDF 有上面的一组内的图片,如下:

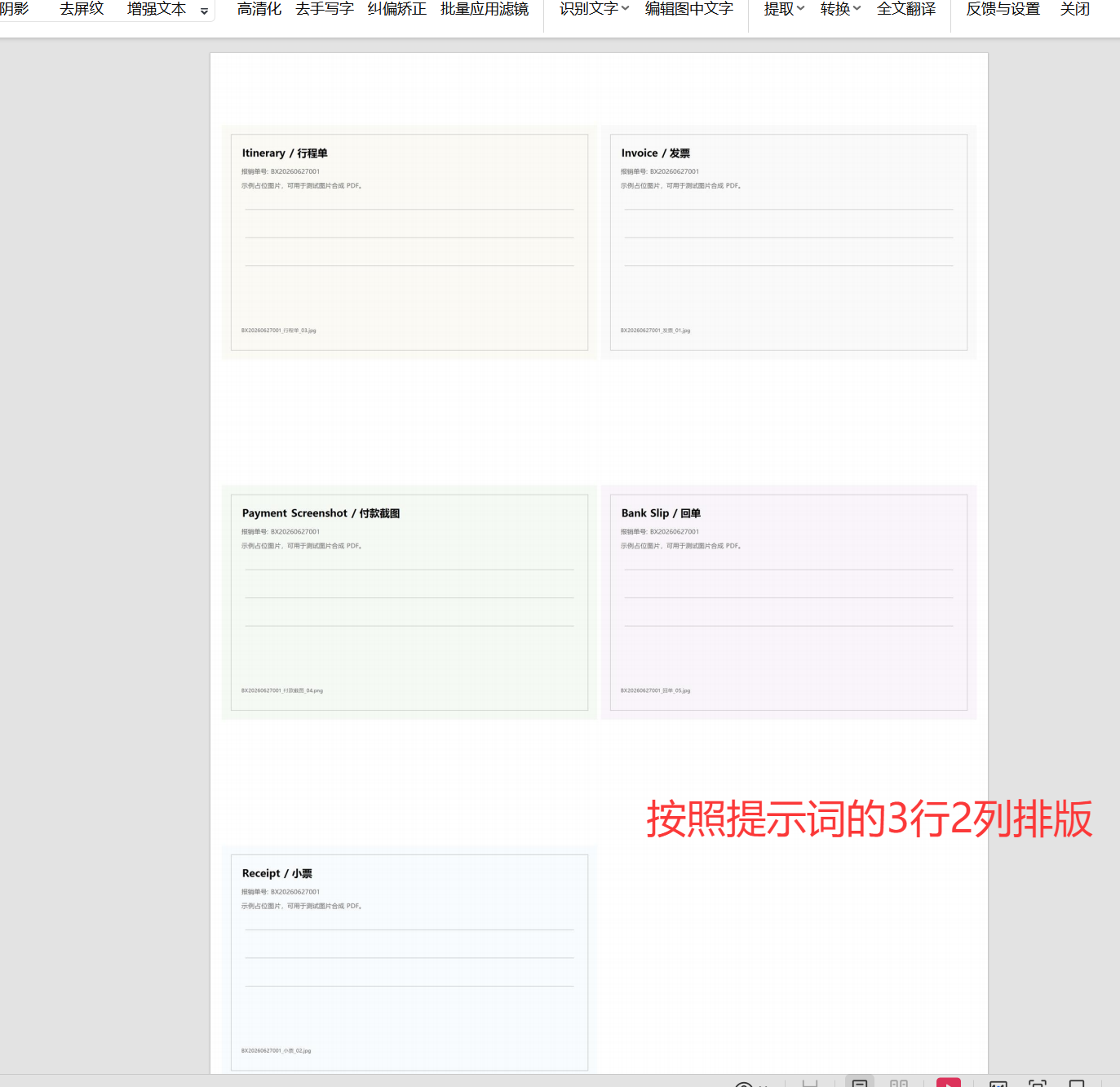
上面效果的提示词描述为:
按报销单号分组, 同一个单号的在一页里面,3行2列3、按文件夹合成
有些图片本身就放在不同文件夹中,让每个文件夹里面的图片合成一个 PDF,方便批量整理。
如下文件夹:
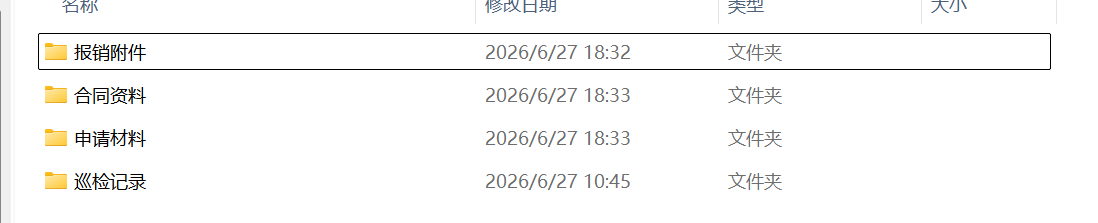
合成4个PDF 。每个PDF 里面有文件夹的图片。我就不截图描述了。
提示词:
按文件夹合并4、同一份材料按顺序合成
像多页扫描件、合同页、申请材料这类图片,用户需要按顺序合成为一个完整 PDF,而不是乱序拼接。
如下图片:
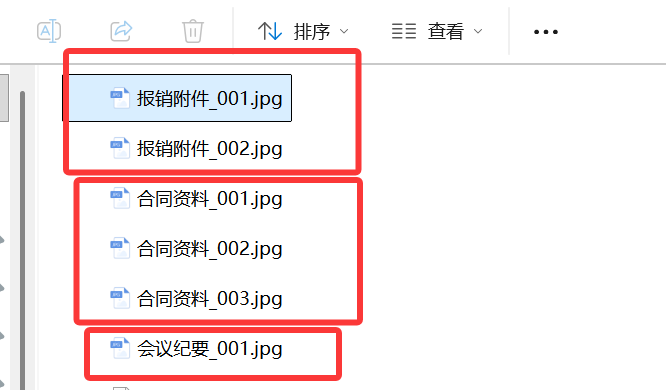
上面就会合成3个PDF 。每个PDF里面按后面的编号顺序来排版图片。
提示词:
同一份材料的图片,按顺序合成一个 PDF。二、实现方案一:小白上手
打开鲸闲办公智能体广场,找到 "图片合成PDF",如图:
**获取: 宫中&浩气: "老罗软件"。**然后将待合成的图片或者文件夹输入,还有描述你的任务提示词,如下:
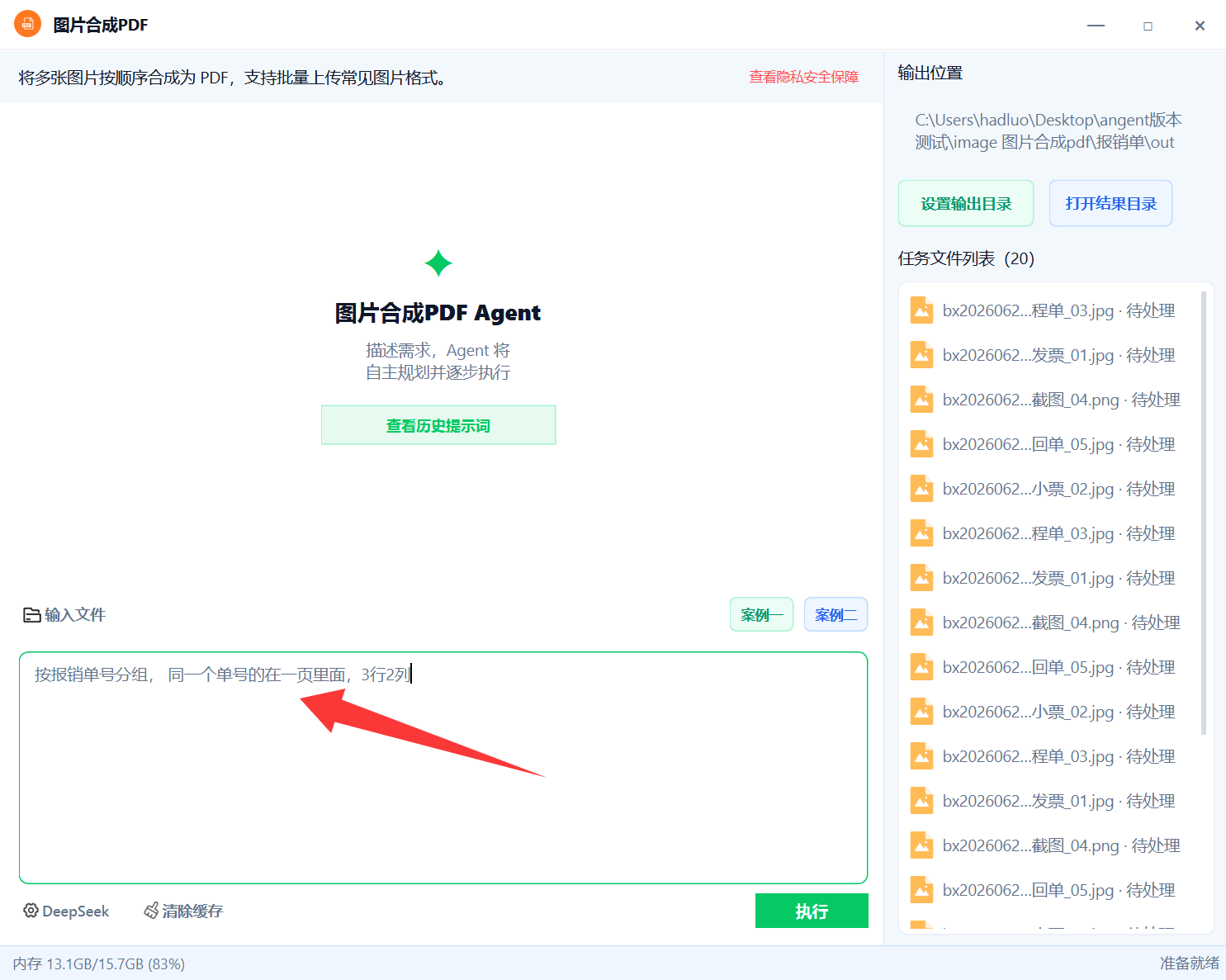
点击执行,智能体就会自主的规划任务,然后完成你的需求! 注意: 图片数据是没有泄露的,不可能还解析了图片内容!! 请放心使用!
三、实现方案二:Python脚本
用 Python 来批量处理图片并按文件夹合成 PDF,其实也是一个很实用的方案,尤其适合那些已经把材料按目录整理好,希望一次性批量生成 PDF 的朋友。
优势:
-
可以批量处理多个文件夹,适合一次整理大量图片材料
-
能按目录自动分组,每个文件夹生成一个独立 PDF
-
可以自定义排序、页面大小、每页排版数量等规则
-
免费开源,无需额外购买软件
-
支持本地运行,断网也能使用,数据更安全
劣势:
-
需要一定的 Python 基础
-
第一次使用需要安装依赖环境
-
如果还要做复杂分组、标题、备注、分页规则,脚本会越来越复杂
这里我给大家分享一个简单的 Python 脚本,用来把一个总目录下的子文件夹分别合成为 PDF,每个文件夹输出一个独立文件。
import os
from PIL import Image
# 总目录,里面每个子文件夹会生成一个 PDF
input_root = r"path\to\your\folders"
# 输出目录
output_folder = r"path\to\your\output"
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 支持的图片格式
image_exts = (".jpg", ".jpeg", ".png", ".bmp", ".webp")
def images_to_pdf(folder_path, output_pdf_path):
files = [
f for f in os.listdir(folder_path)
if f.lower().endswith(image_exts)
]
files.sort()
if not files:
print(f"跳过空文件夹:{folder_path}")
return
images = []
for file_name in files:
img_path = os.path.join(folder_path, file_name)
img = Image.open(img_path).convert("RGB")
images.append(img)
first_image = images[0]
rest_images = images[1:]
first_image.save(output_pdf_path, save_all=True, append_images=rest_images)
print(f"已生成:{output_pdf_path}")
for folder_name in os.listdir(input_root):
folder_path = os.path.join(input_root, folder_name)
if not os.path.isdir(folder_path):
continue
output_pdf_path = os.path.join(output_folder, f"{folder_name}.pdf")
images_to_pdf(folder_path, output_pdf_path)
print("所有文件夹处理完成!")使用时,先准备一个总目录,把每一组图片分别放进不同的子文件夹中。然后修改脚本里的输入目录和输出目录,运行后就会按文件夹分别生成 PDF。
这种方式比较适合"合同资料一份一个文件夹""申请材料一份一个文件夹""巡检照片一个点位一个文件夹"这类已经整理好目录结构的场景。脚本会把每个文件夹当作一组,自动输出成独立 PDF,省去手工一个个合并的麻烦。
不过,Python 脚本更适合有一定编程基础的用户。如果只是偶尔处理,或者希望直接用自然语言描述需求,让系统自动识别文件夹、自动分组、自动排版,那么后面的智能合成方案会更省心。
四、总结
面对大量图片整理成 PDF 的需求,真正麻烦的往往不是"合并"这一步,而是前面的分组、排序和版式整理。无论是用传统脚本,还是用更智能的本地工具,本质上都是在用工具替代重复劳动。对于已经按文件夹整理好的材料,可以用 Python 脚本批量合成;如果希望更灵活一点,通过自然语言描述需求就完成证件配对、票据分组、扫描件排序和文件夹合成,那么智能图片合成 PDF 的方式会更省心。选对方法之后,原本杂乱、耗时、容易出错的图片整理工作,就能更快、更规范地完成。