一、环境准备:建表 + 10 万条测试数据
1、订单表结构
bash
CREATE TABLE `order_master` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '订单表主键ID',
`user_id` bigint unsigned NOT NULL COMMENT '用户ID',
`order_status` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '订单状态:0待付款 1已付款 2已发货 3已完成 4已取消',
`pay_amount` decimal(10,2) unsigned NOT NULL DEFAULT '0.00' COMMENT '支付金额',
`order_sn` varchar(32) NOT NULL COMMENT '订单编号',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`) COMMENT '初始单值索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单主表';2、批量生成 10 万条测试数据
注意:这种写法只是造测试数据用,正式环境不应采取这种写法
bash
DELIMITER $$ -- 把语句结束临时改成 $$,告诉 MySQL只有遇到 $$ 才算一段完整代码结束
CREATE PROCEDURE insert_order_data(IN data_count INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= data_count DO
INSERT INTO order_master(user_id, order_status, pay_amount, order_sn, create_time)
VALUES (
FLOOR(RAND() * 10000) + 1, -- 用户ID 1~10000 随机分布
FLOOR(RAND() * 5), -- 订单状态 0~4 随机
ROUND(RAND() * 1000, 2), -- 支付金额 0~1000元
CONCAT('OD', LPAD(i, 10, '0')), -- 订单号有序生成
DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 365) DAY) -- 近1年内随机创建时间
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 执行生成10万条数据(执行时间约10~30秒)
CALL insert_order_data(100000);3. Explain 核心判断指标
| 字段 | 核心判断标准 |
|---|---|
type |
性能从差到好:ALL(全表扫描) < index(全索引扫描) < range(范围扫描) < ref(等值匹配) < const(主键唯一匹配) |
key |
实际命中的索引名称,为 NULL 表示未走索引 |
key_len |
索引中实际使用的字节数,可判断用到了联合索引的几个字段 |
rows |
预估扫描的行数,数值越小性能越好 |
Extra |
关键标识:Using index(覆盖索引,无需回表)、Using filesort(文件排序,性能差)、Using where(需回表过滤) |
二、联合索引核心优化
场景 1:最左匹配原则验证 & 基础字段顺序优化
需求:查询指定用户的指定状态的订单,SQL 如下:
bash
SELECT * FROM order_master WHERE user_id = 666 AND order_status = 1;最开始的状态:
bash
EXPLAIN SELECT * FROM order_master WHERE user_id = 666 AND order_status = 1;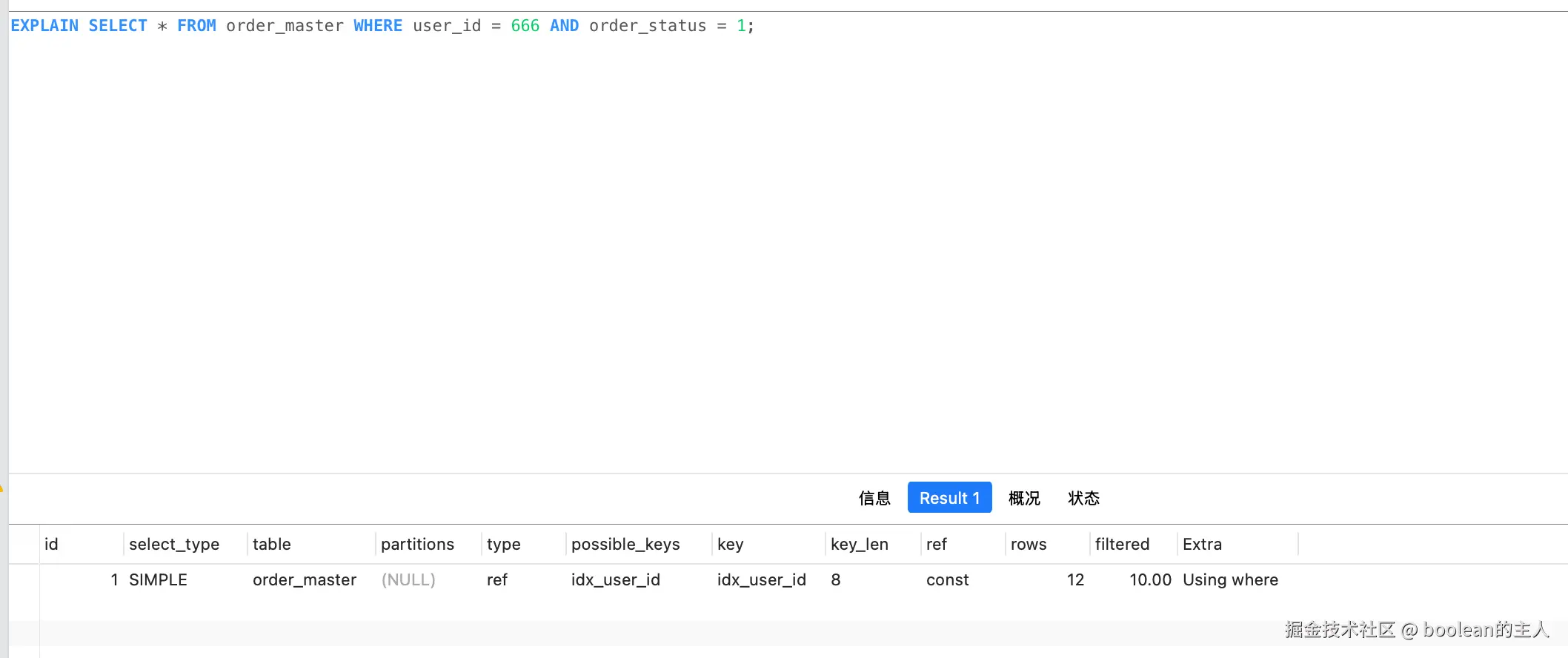
问题分析:
- 仅命中单列索引
idx_user_id,key_len=8(仅用到user_id字段,bigint 占 8 字节) - 扫描出 user_id=666 的 12 条数据后,还需要回表逐个过滤
order_status,Extra 出现Using where
优化方案:创建联合索引,删除单索引,按最左匹配设计
bash
ALTER TABLE `order_master` ADD INDEX `idx_user_order_status`(`user_id`, `order_status`) USING BTREE,DROP INDEX `idx_user_id`优化后 Explain 验证
bash
EXPLAIN SELECT * FROM order_master WHERE user_id = 666 AND order_status = 1;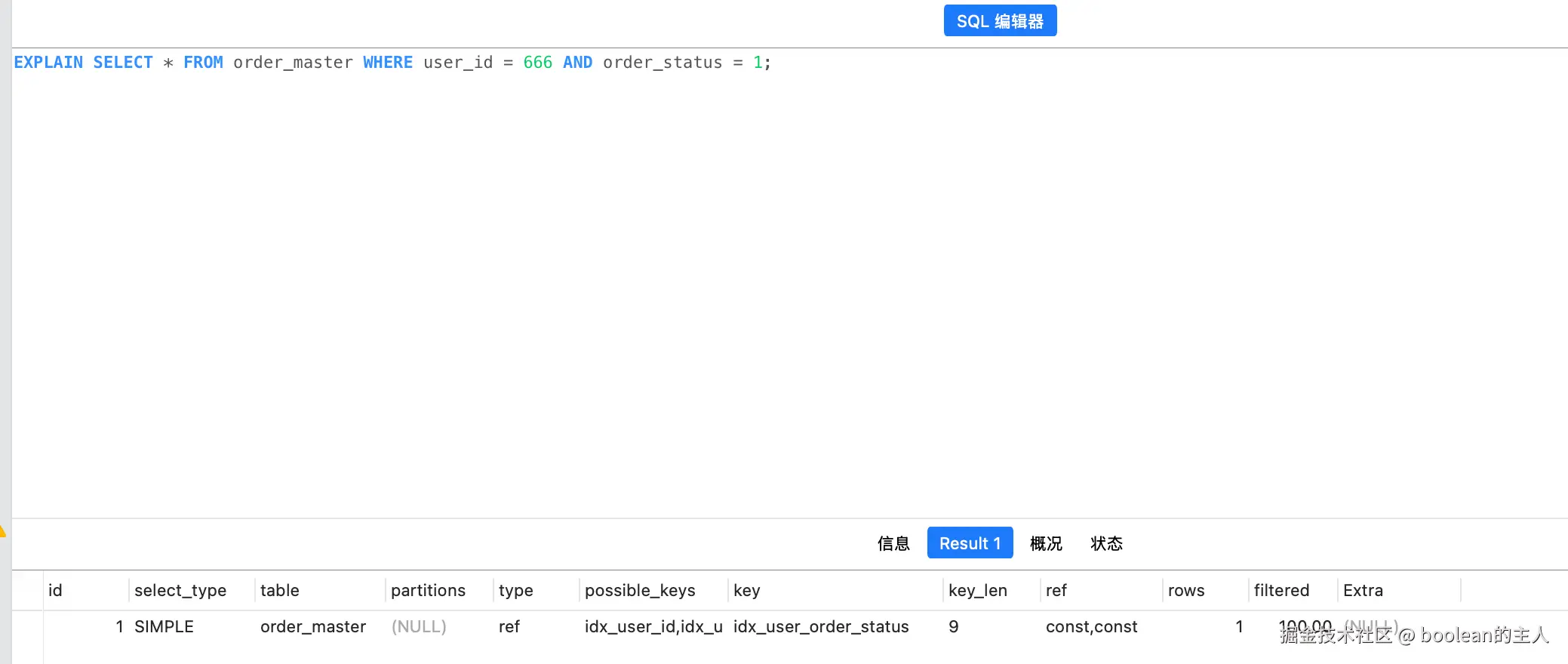
优化效果说明:
key_len=9=user_id(8字节)+order_status(1字节),两个字段都用到了索引过滤- 扫描行数从 12 行降到 1 行,无需回表二次过滤,Extra 无
Using where - 修改where条件,验证最左匹配:
WHERE user_id = 666→ 结果:命中索引,key_len=8,说明命中最左匹配WHERE order_status = 1→ 结果:全表扫描,不命中索引(不满足最左前缀)- WHERE order_status = 1 AND user_id = 666 → 顺序调换了下结果:命中索引,key_len=9 ,因为MySQL 优化器会自动调整 WHERE 条件顺序,真正决定索引能否使用的是索引字段顺序,不是 SQL 书写顺序;
场景 2:等值在前、范围在后,解决索引截断问题
需求:查询已付款状态、金额大于 100 元的订单,SQL 如下:
bash
SELECT pay_amount,order_status FROM order_master WHERE pay_amount > 100 AND order_status = 1;错误索引设计举例(范围字段在前)
bash
ALTER TABLE `order_master` ADD INDEX `idx_amount_status`(`pay_amount`, `order_status`) USING BTREE执行 Explain:
bash
EXPLAIN SELECT pay_amount,order_status FROM order_master WHERE pay_amount > 100 AND order_status = 1;执行结果:
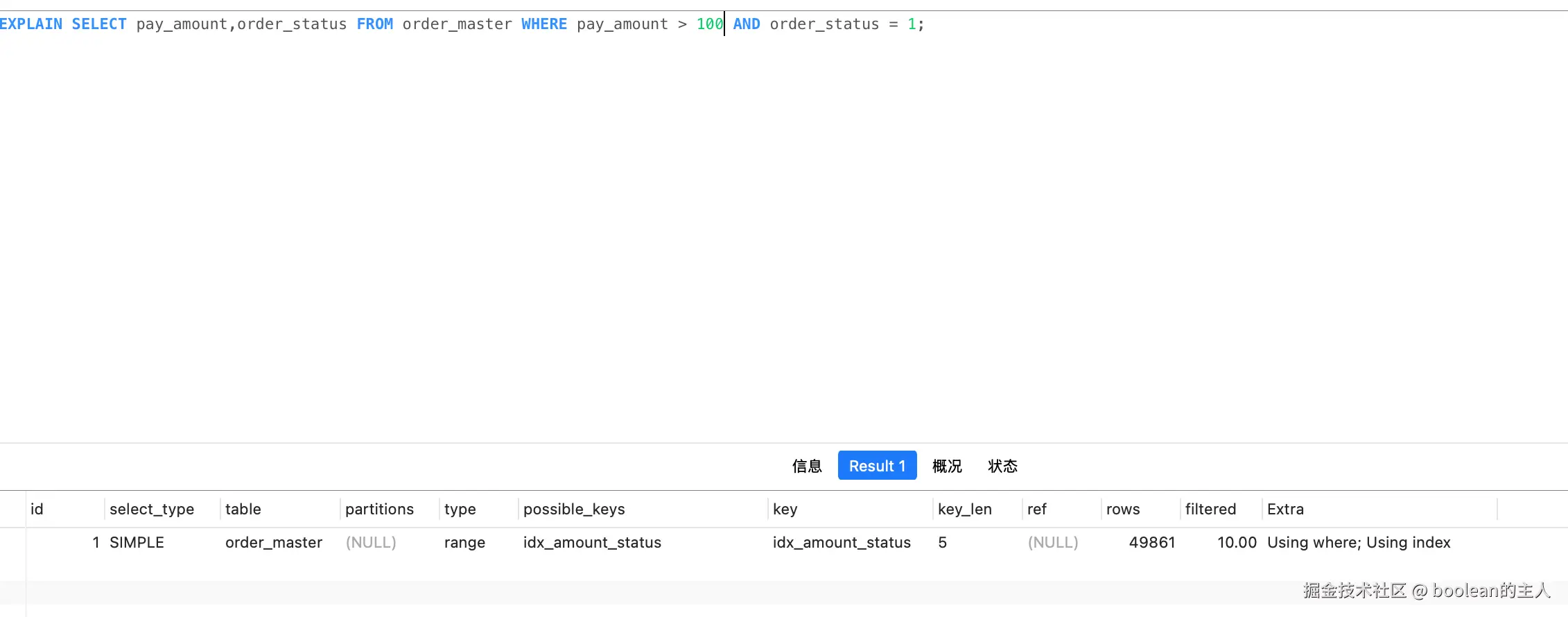
问题分析:
pay_amount是范围查询,会截断索引 ,后面的order_status完全无法使用索引key_len=5(说明仅用到 pay_amount 字段,decimal (10,2) 占 5 字节),order_status完全没生效- 扫描行数接近 5 万行,性能极差
优化索引方案:等值字段放前面,范围字段放后面
bash
ALTER TABLE `order_master` DROP INDEX `idx_amount_status`,
ADD INDEX `idx_status_amount`(`order_status`, `pay_amount`) USING BTREE优化后 Explain 验证
bash
EXPLAIN SELECT pay_amount,order_status FROM order_master WHERE pay_amount > 100 AND order_status = 1;执行结果
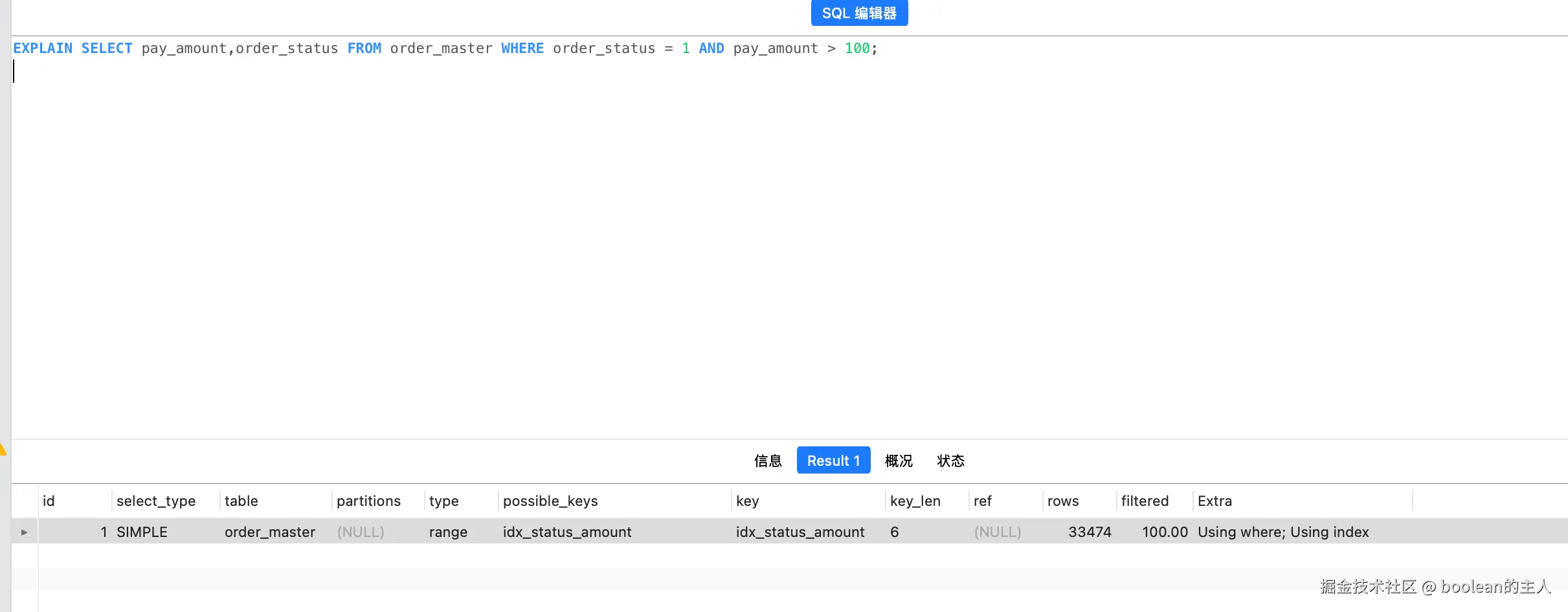
效果说明:
key_len=6=order_status(1字节)+pay_amount(5字节),两个字段都生效- 原索引
idx_amount_status(pay_amount,order_status):范围字段在前,仅过滤 pay_amount>100,order_status 无法走索引; - 新索引
idx_status_amount(order_status,pay_amount):先用 order_status=1 等值过滤,再在结果集内做 pay_amount 范围扫描; - 核心规则:所有等值查询字段全部放联合索引前部,范围查询字段统一放最后
场景 3:覆盖索引优化
需求:查询用户800 、状态=3的数据
bash
SELECT * FROM order_master WHERE user_id = 800 AND order_status = 3;普通联合索引状态(使用场景 1 的 idx_user_order_status索引)
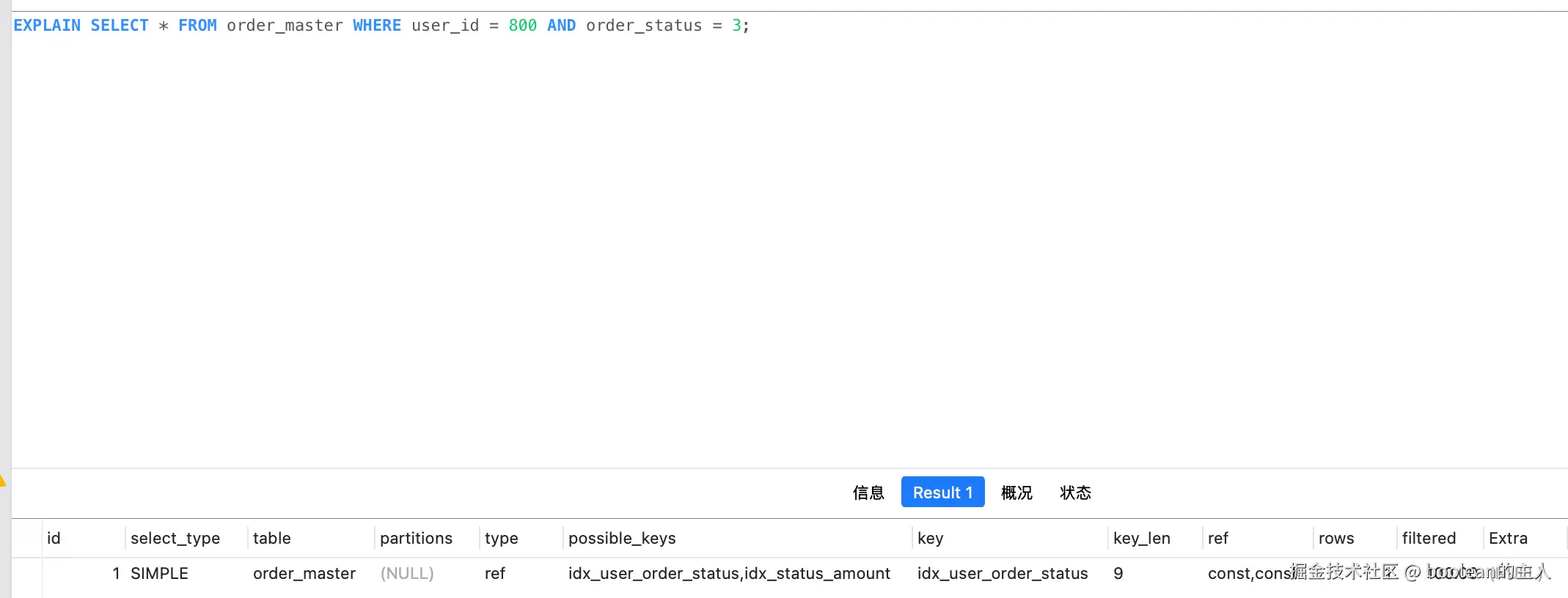
问题分析:
- idx_user_order_status 索引里只有
user_id、order_status,其他字段二级索引里根本没有,必须去主键聚簇索引里读取整行数据,也就是回表。 - MySQL5.7 环境下 Extra 没有
Using index就代表不是覆盖索引,必然要回表;
优化方案:指定查询索引中需要的字段,做成覆盖索引
bash
SELECT user_id,order_status FROM order_master WHERE user_id = 800 AND order_status = 3;explain测试执行结果
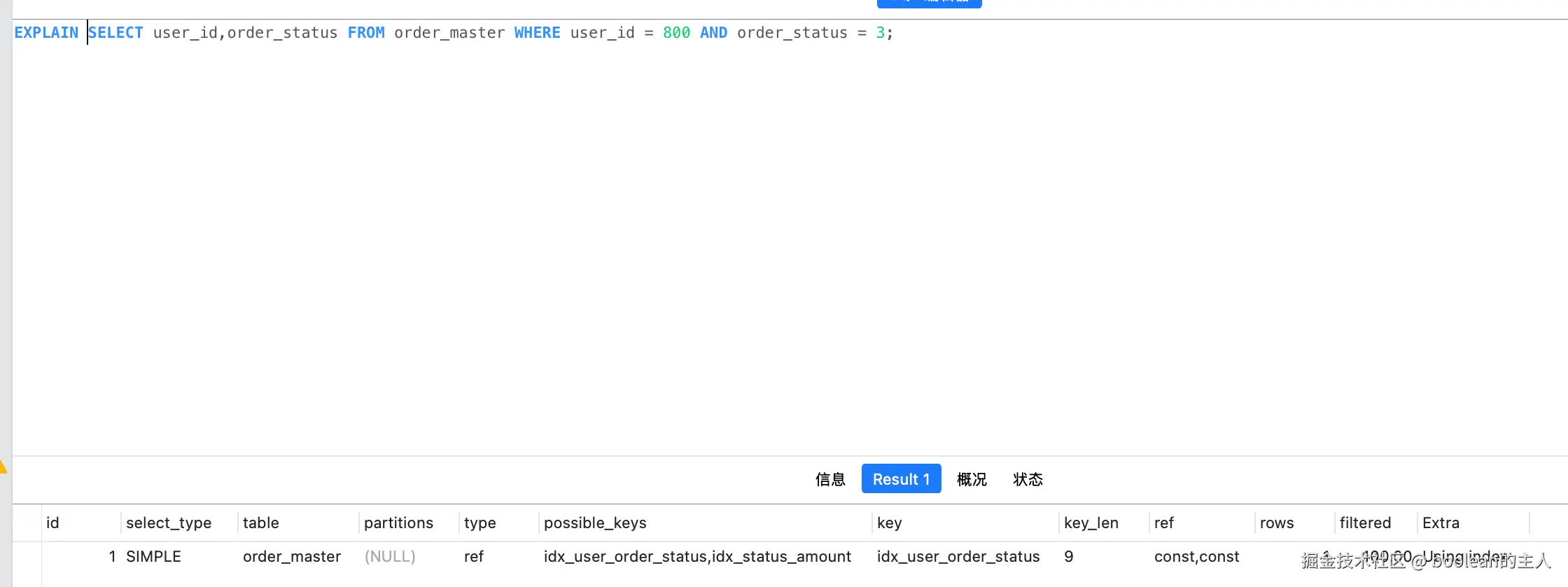
效果说明:
- Extra 出现
Using index,表示直接从索引中获取所有数据,无需回表 - 减少了回表的随机 IO,性能提升 2~10 倍,是列表查询、统计查询的首选优化方案;也就是我们常说的C端查询数据库,查询语句最好要指定字段;
- 注意:只适合查询少量字段,否则联合索引字段过多会导致索引体积过大;索引超过 3~5 列不推荐做覆盖索引。
场景 4:利用索引有序性,消除文件排序(Using filesort)
需求:查询指定用户的订单,按创建时间倒序排列:
bash
SELECT * FROM order_master WHERE user_id = 1000 ORDER BY create_time DESC;执行explain
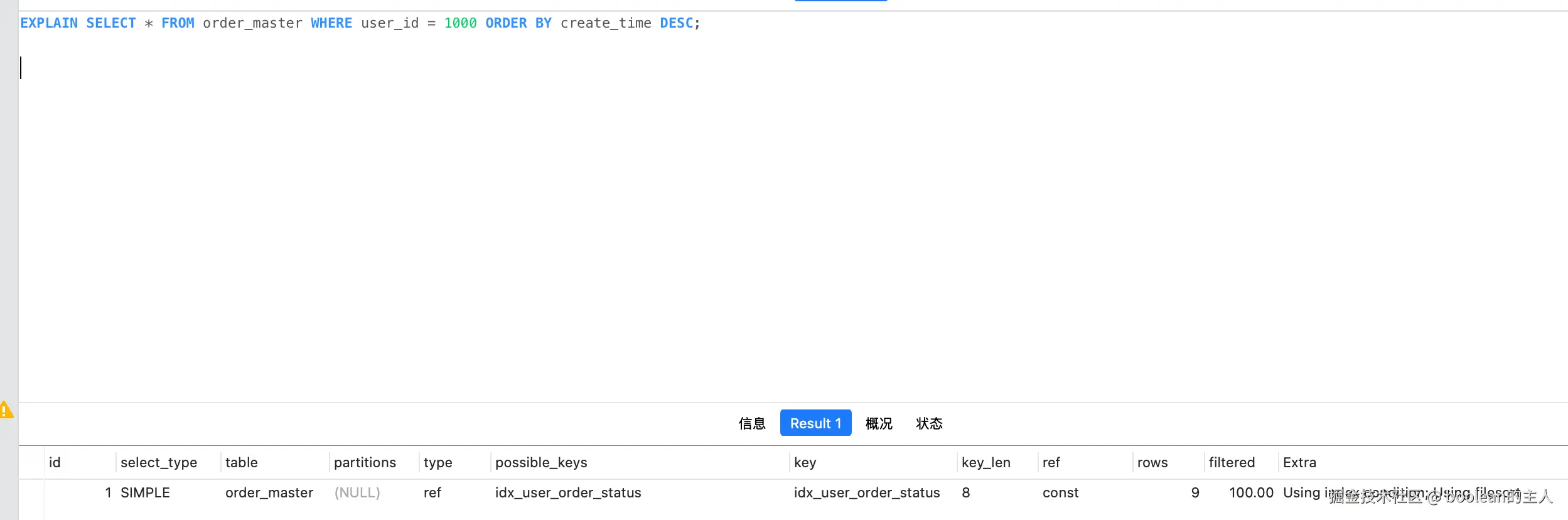
问题分析:
- Extra 出现
Using filesort,表示 MySQL 需要把结果集在内存 / 磁盘中进行排序,数据量大时性能暴跌; - 使用场景 1 的 idx_user_order_status索引 ,key_len=8说明只用到了user_id字段索引,只能过滤数据,无法提供排序能力;
优化方案:添加排序字段联合索引末尾,利用索引天然有序
bash
ALTER TABLE `create_table`.`order_master`
ADD INDEX `idx_user_createtime`(`user_id`, `create_time`) USING BTREE添加索引后 Explain 验证
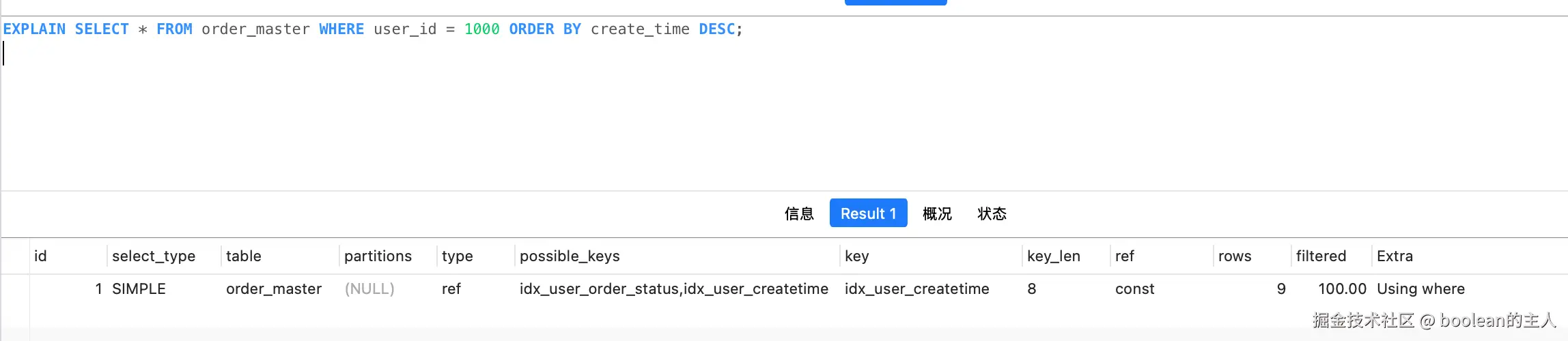
效果说明:
Using filesort消失,直接利用联合索引的有序性返回排序后的数据- 多字段排序注意事项:排序方向必须和索引定义一致,否则无法利用索引排序
- 反例:
ORDER BY user_id ASC, create_time DESC无法利用idx(user_id, create_time)排序 - MySQL 8.0 支持降序索引,可创建
idx(user_id ASC, create_time DESC)适配混合排序 - 注意:如果 WHERE 条件过滤后数据量很大,即使有排序索引,MySQL 优化器也可能放弃索引排序、选择 filesort
- 反例:
场景 5:规避索引失效:字段字符型,查询值是数字导致失效
业务需求:通过订单号查询订单(注意:订单号是字符串类型):
bash
-- 给order_sn创建一个索引
ALTER TABLE `order_master`
ADD INDEX `idx_order_sn`(`order_sn`) USING BTREE
-- 错误写法:字符串字段传数字,触发隐式转换
SELECT * FROM order_master WHERE order_sn = 1234567890;执行Explain

问题分析:
order_sn索引完全失效- 原因:
order_sn是 varchar 类型,传入数字会触发隐式转换(CAST(order_sn AS SIGNED)),索引列上有函数则失效 - 直接使用全表扫描(之前刚进一家公司时,发现历史项目有个慢查询,排查后发现是手机号字段varchar,但是查询手机号码没有转字符型直接查询导致慢查询;在实际项目中手机号字段是一个特别容易出问题的点)
- 底层原理:MySQL 比较
INT = STRING:只转换右侧字符串常量,例如user_id='123'索引字段保持原生整数类型,B + 树有序结构可利用,索引不失效; 比较VARCHAR = NUMBER 例如order_sn=123:强制转换左侧索引字段,破坏索引排序,无法二分查找,索引失效。
优化方案:保持字段类型一致,避免隐式转换
bash
SELECT * FROM order_master WHERE order_sn = '1234567890';优化后 Explain 验证
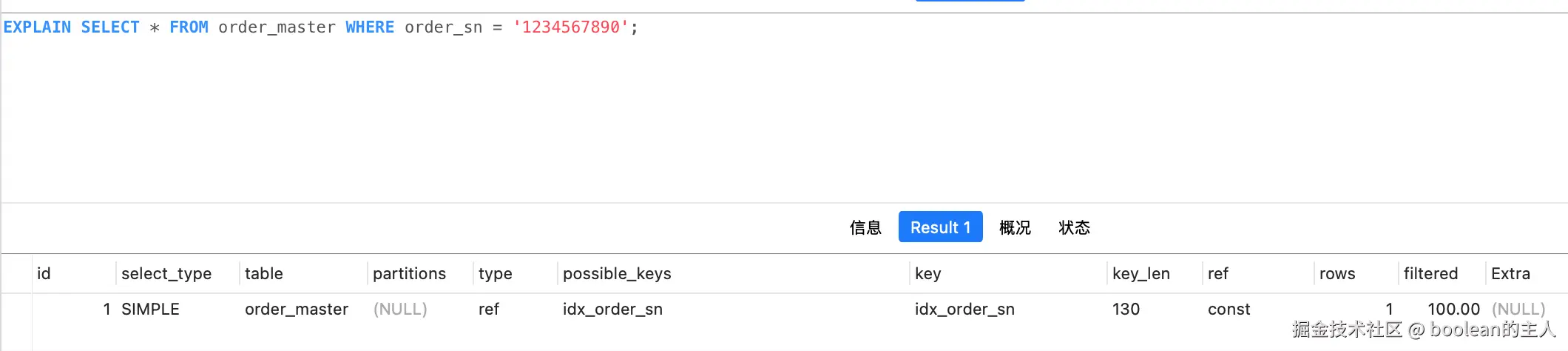
效果说明:
key=idx_order_sn、key_len=130,order_sn索引命中了- 扫描行数从 10 行降到 1 行,精准匹配;