深度学习方向需要指导的朋友请私信!!!
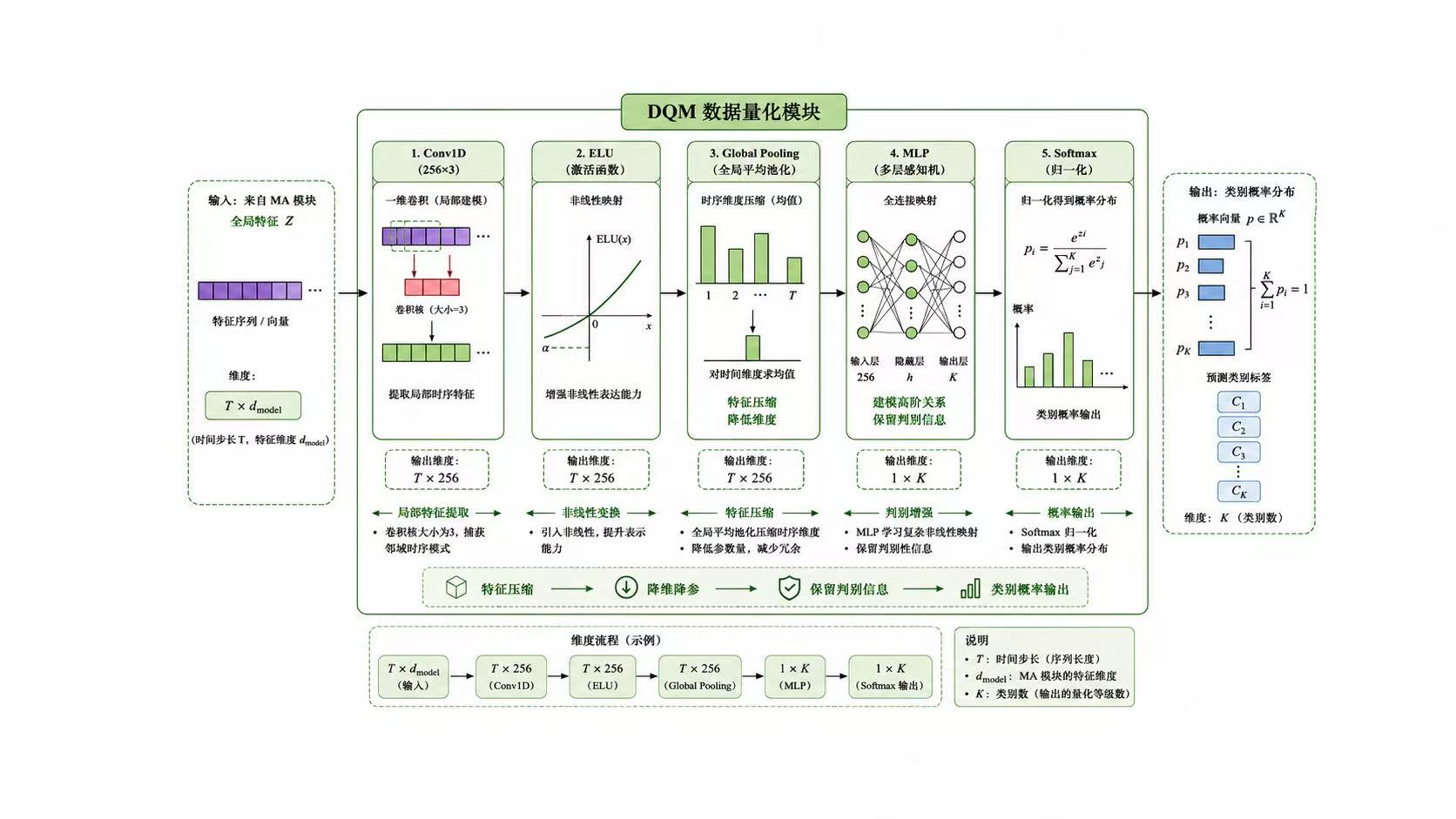
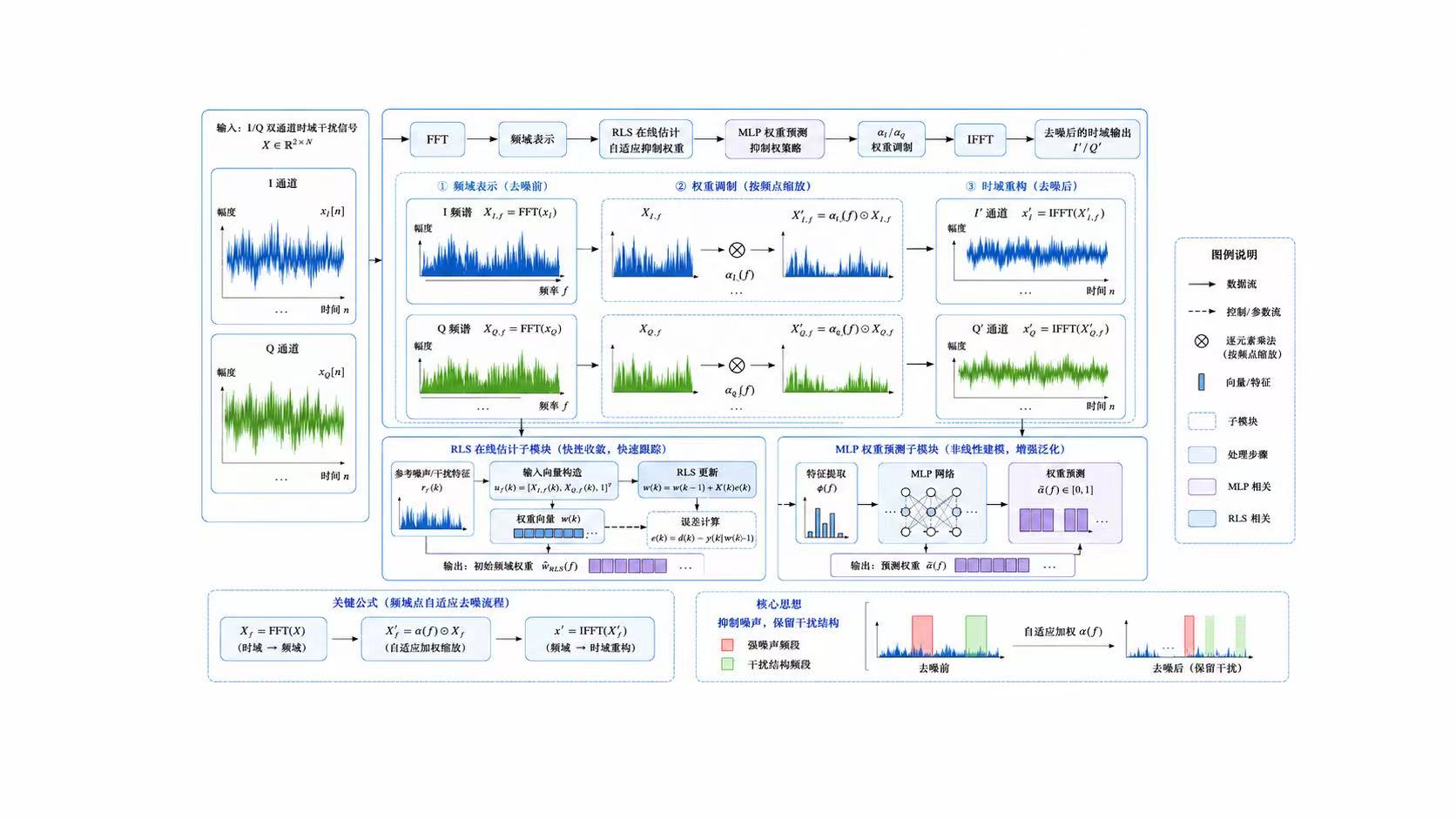
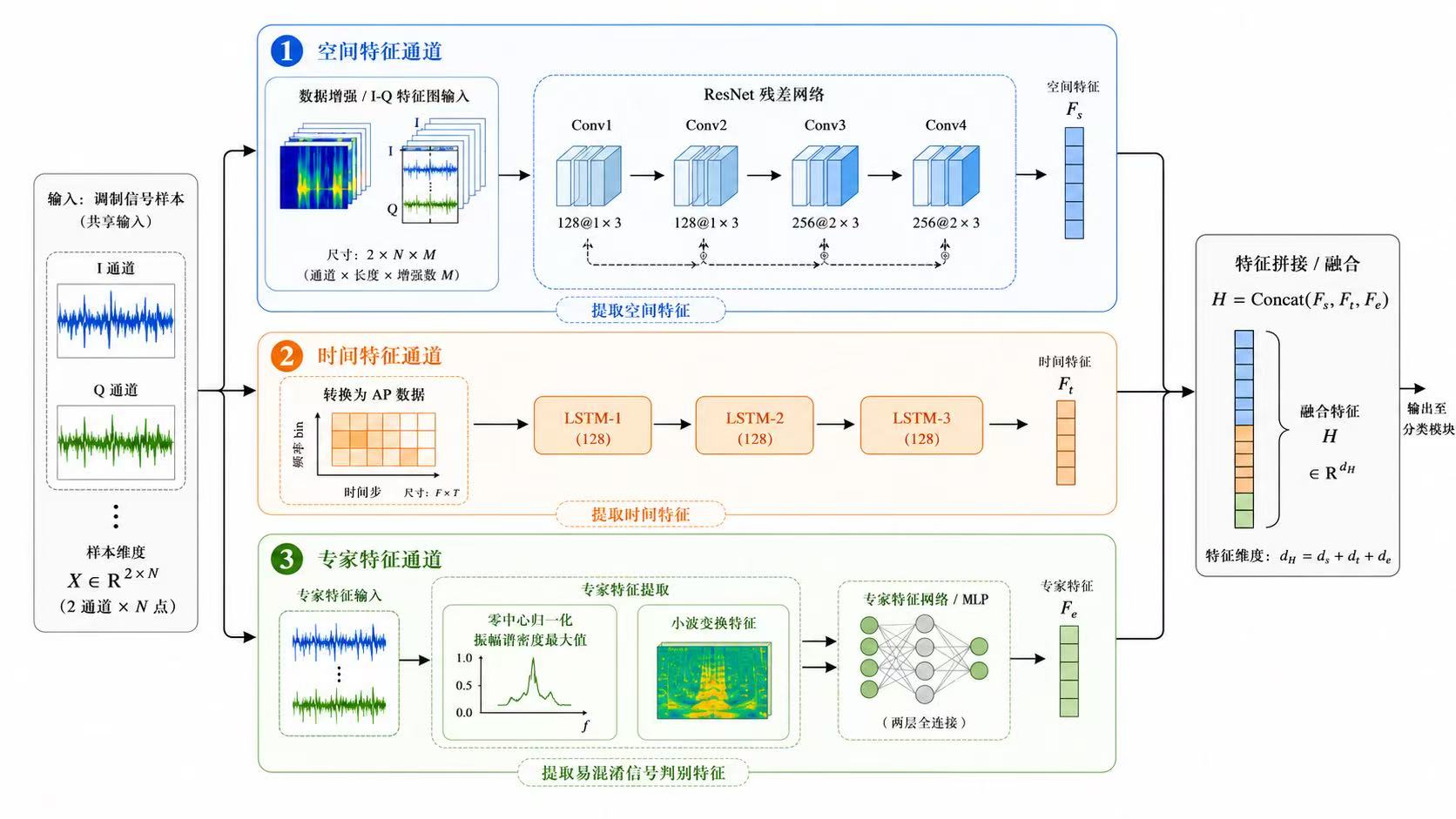
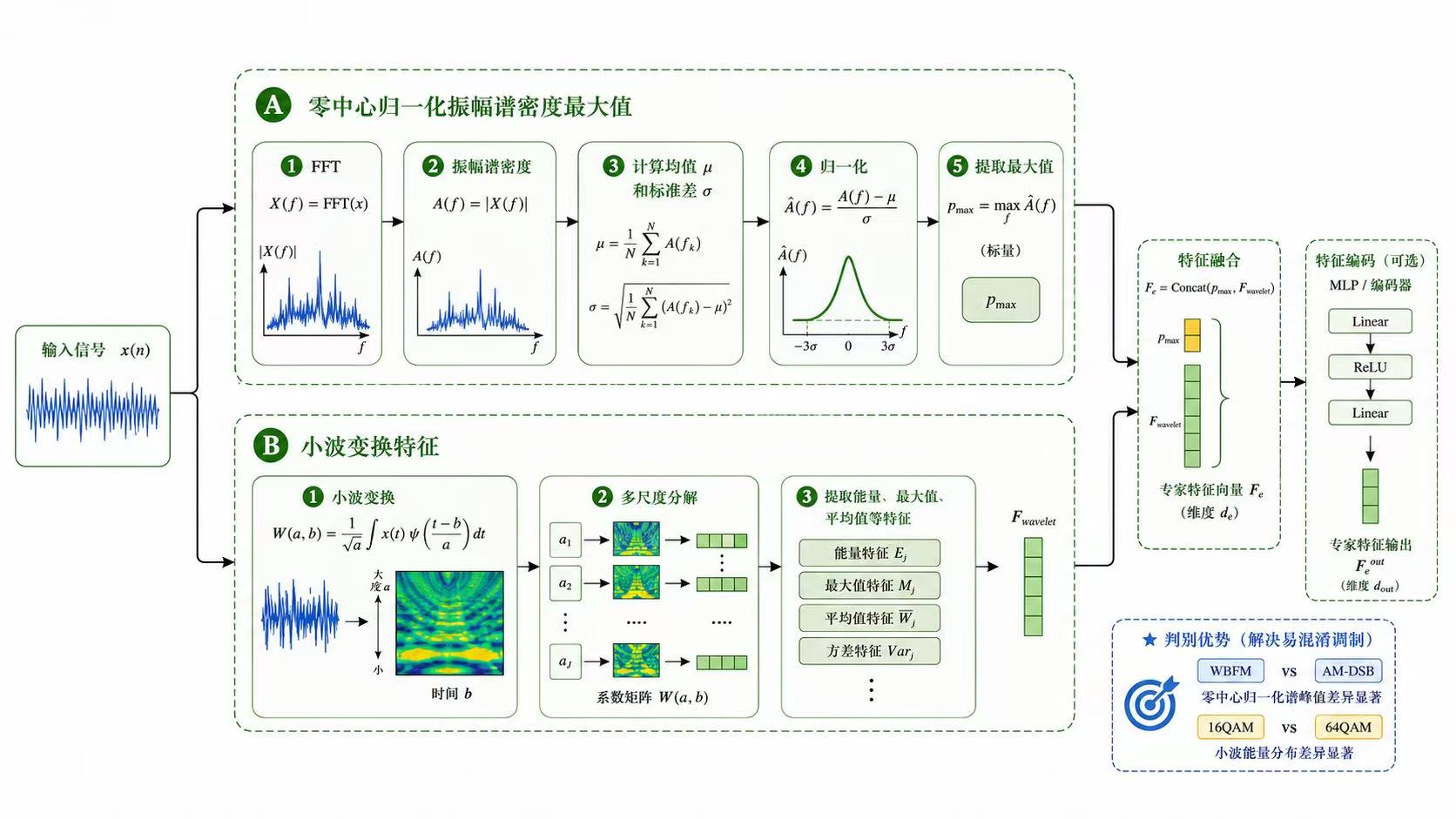
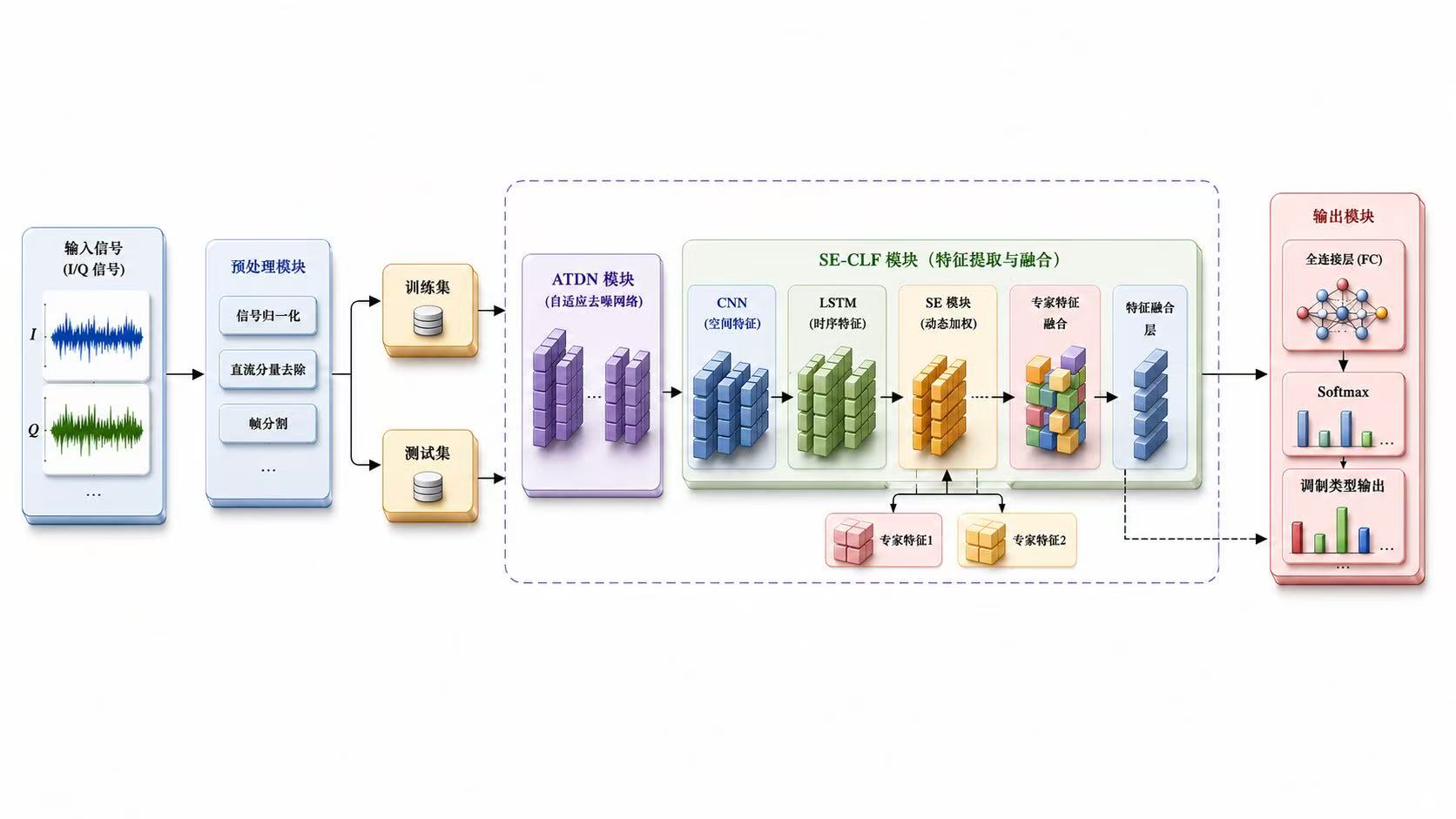
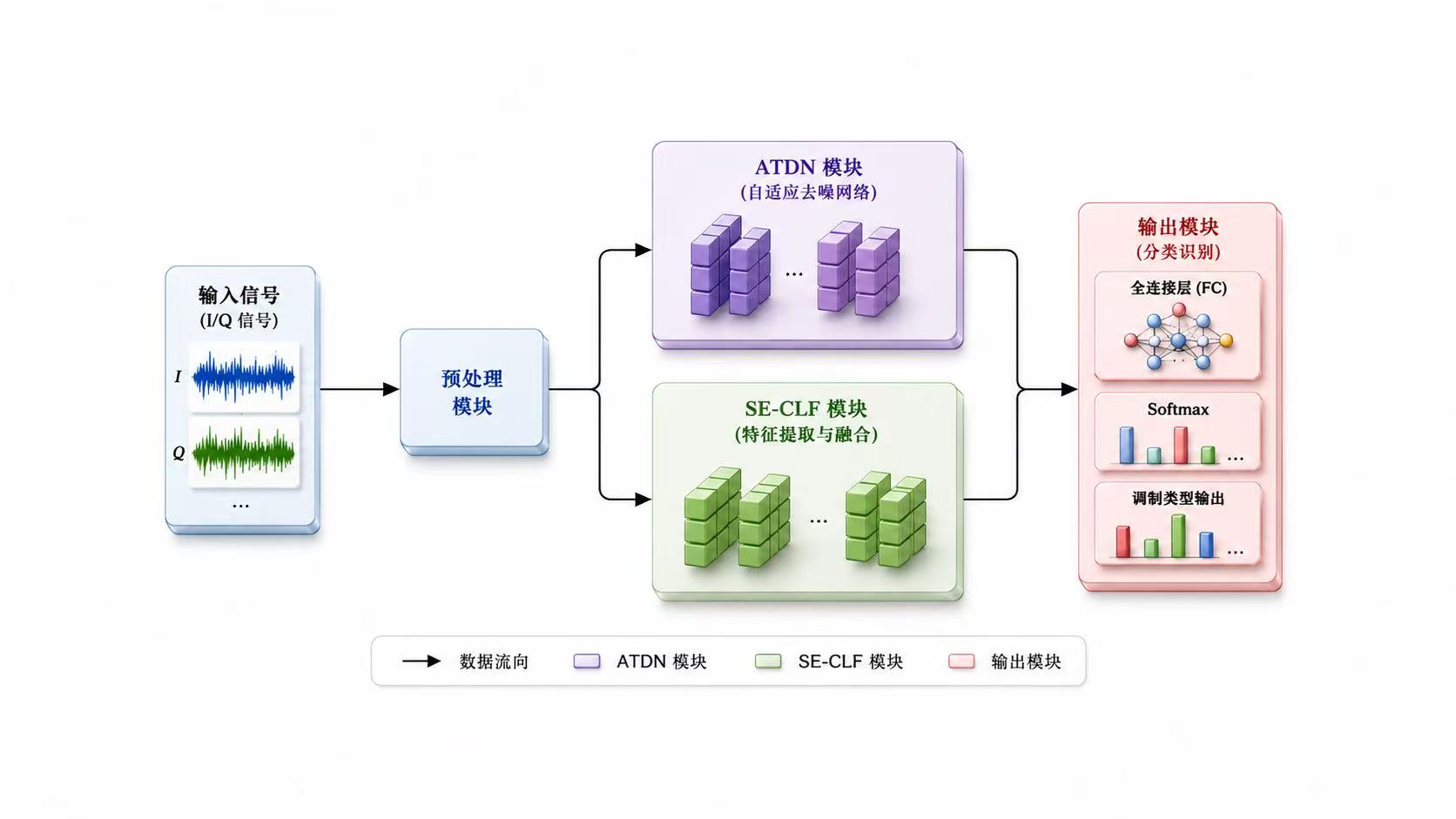
基于深度学习的调制信号分类识别算法在本科和研究生的领域内都算是小火的课题。他的主要思路就是使用不同的神经网络或者提出一个新的模块安插在神经网络中,使最终的最高准确率或者平均准确率提升。至于我们所追求的创新点,这需要我们在研一研二中阅读大量的文献来敲出点点火花,这其实并不容易。最后发论文其实画自己的网络架构图是非常重要的,网络架构图能显著影响读者对论文创新性和完整性的第一印象。
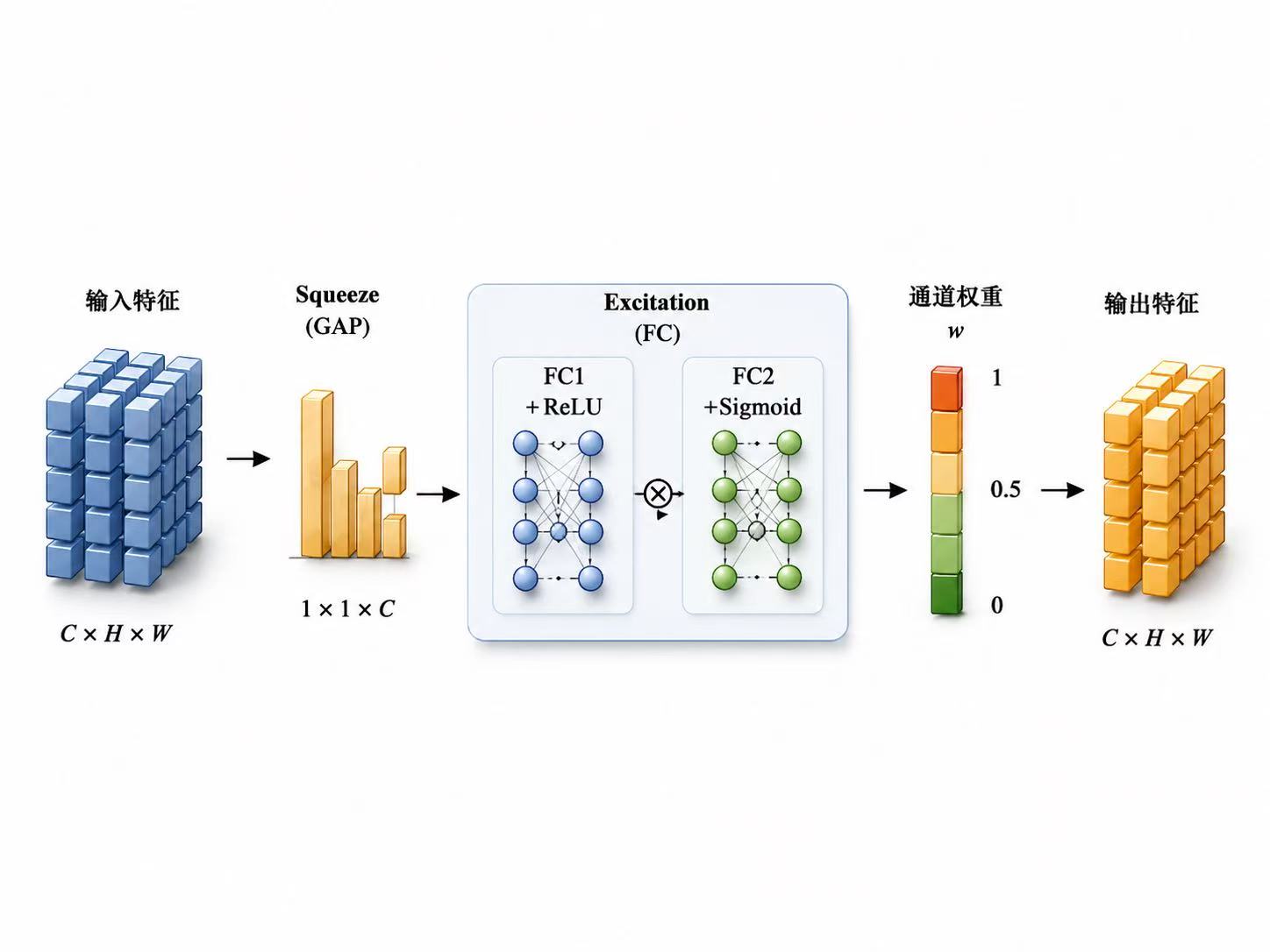
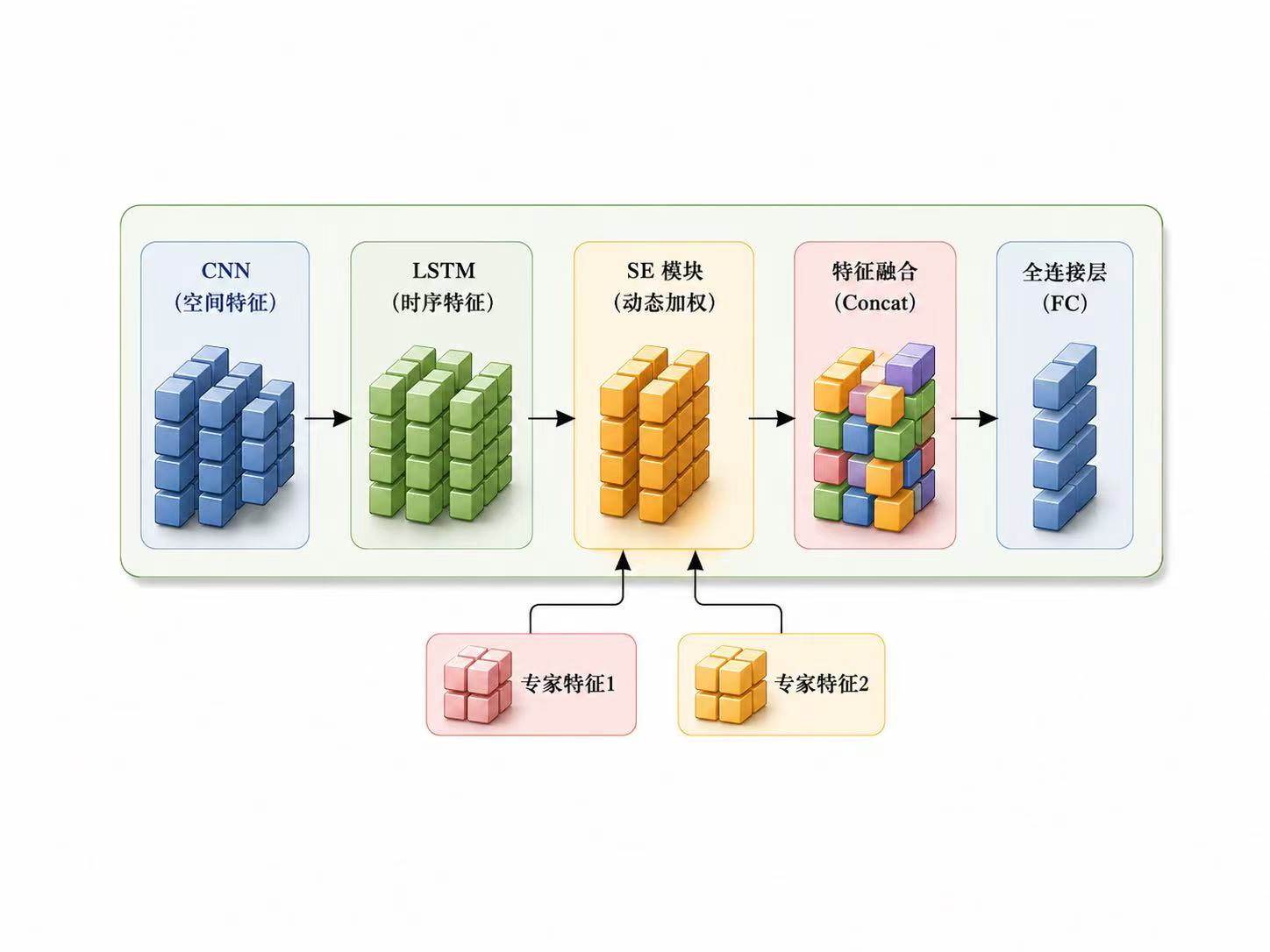
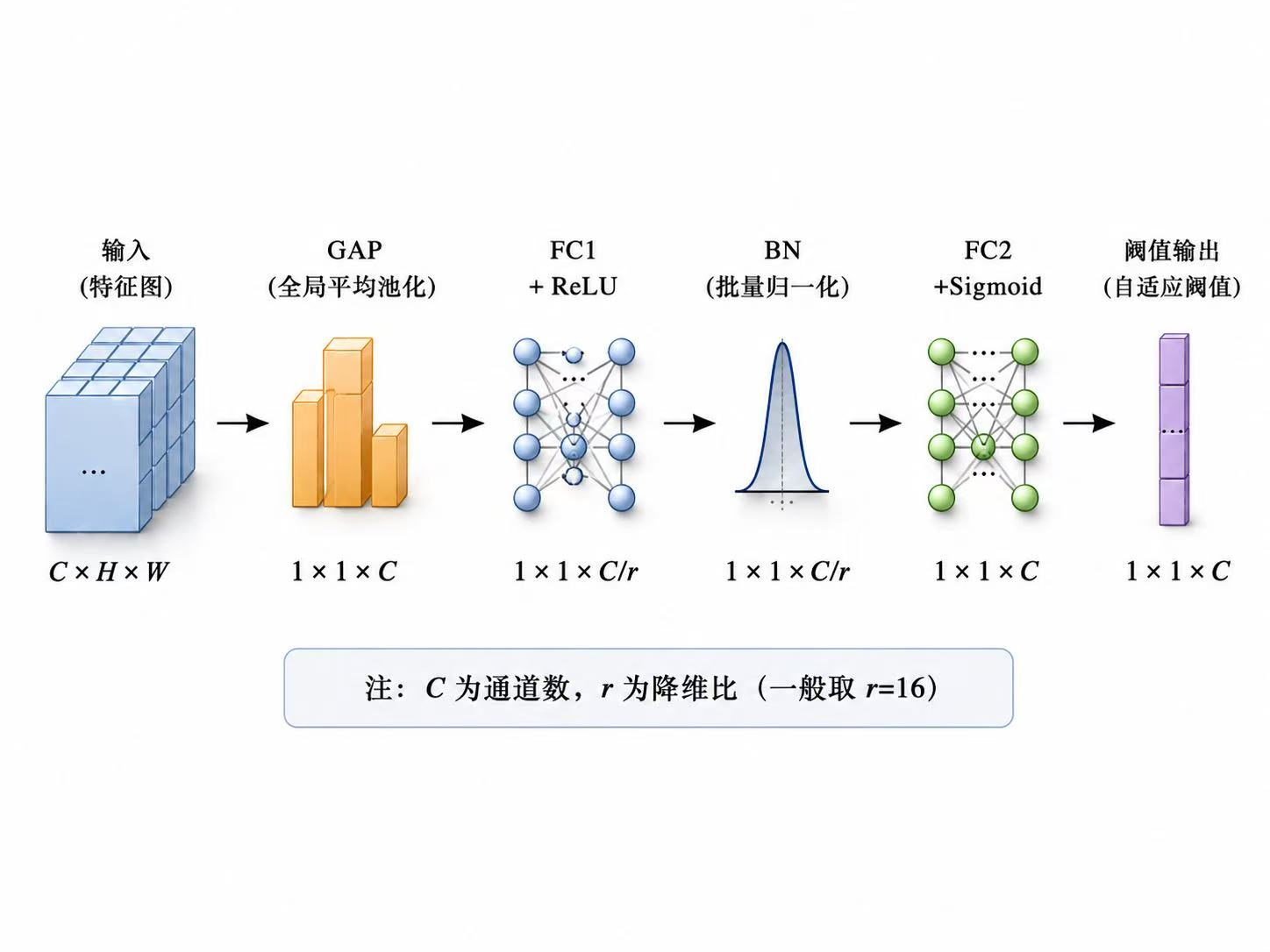
很多人做调制信号分类时,只关注网络层数和最终准确率,但更深层的问题其实是:模型到底学到了什么。I/Q信号不是普通的一维序列,它本质上是复基带信号,里面同时包含幅度、相位、频谱结构和时间演化规律。因此,CNN、LSTM、注意力机制、专家特征并不是随便堆上去的,而是分别对应不同的信号先验:CNN更擅长捕捉局部波形和频谱纹理,LSTM更适合建模调制信号随时间变化的动态依赖,注意力机制则用于判断哪些时间片段或特征通道对分类结果更关键。真正好的网络设计,不是模块越多越强,而是每个模块都能对应信号本身的物理含义。
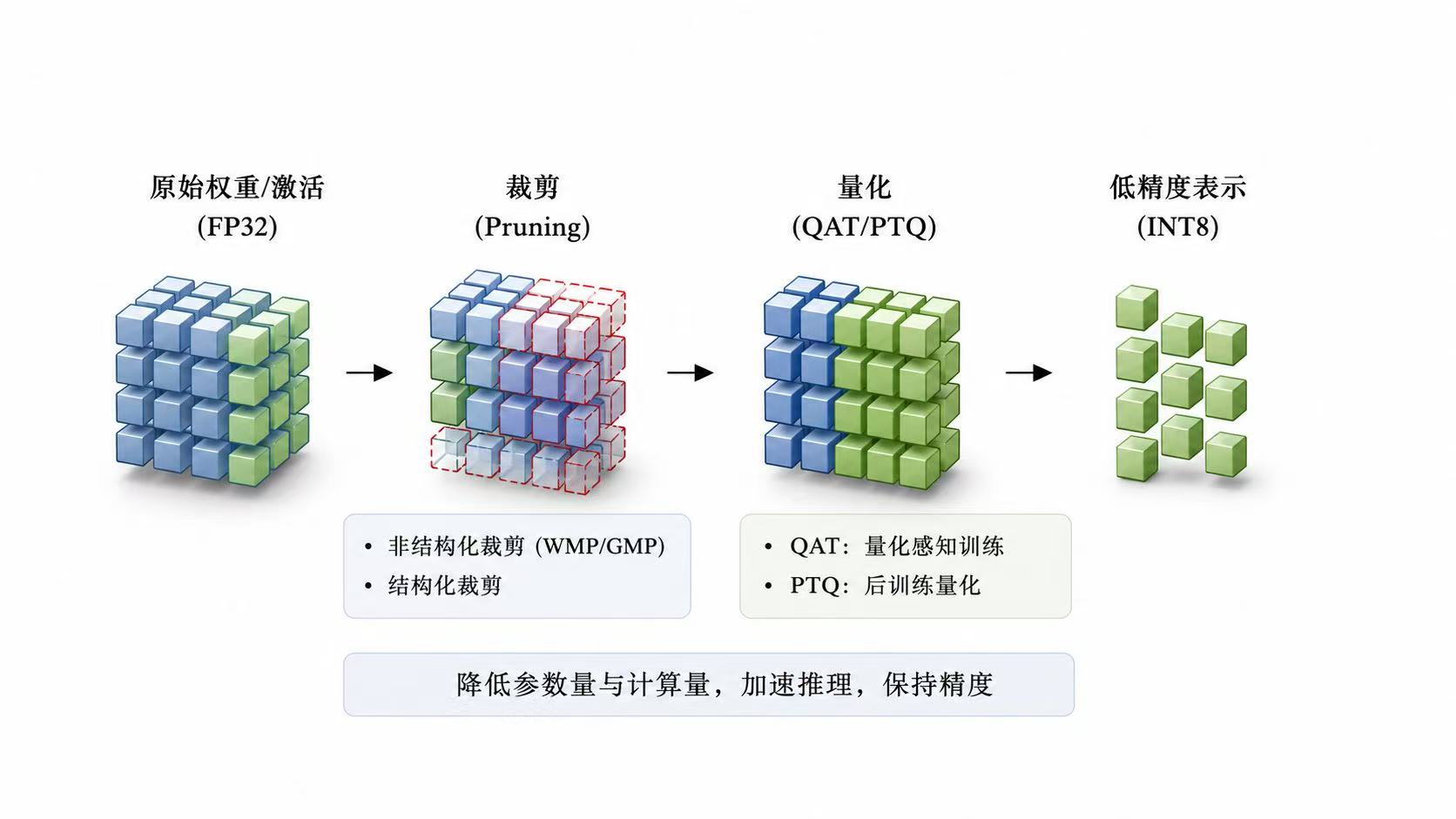
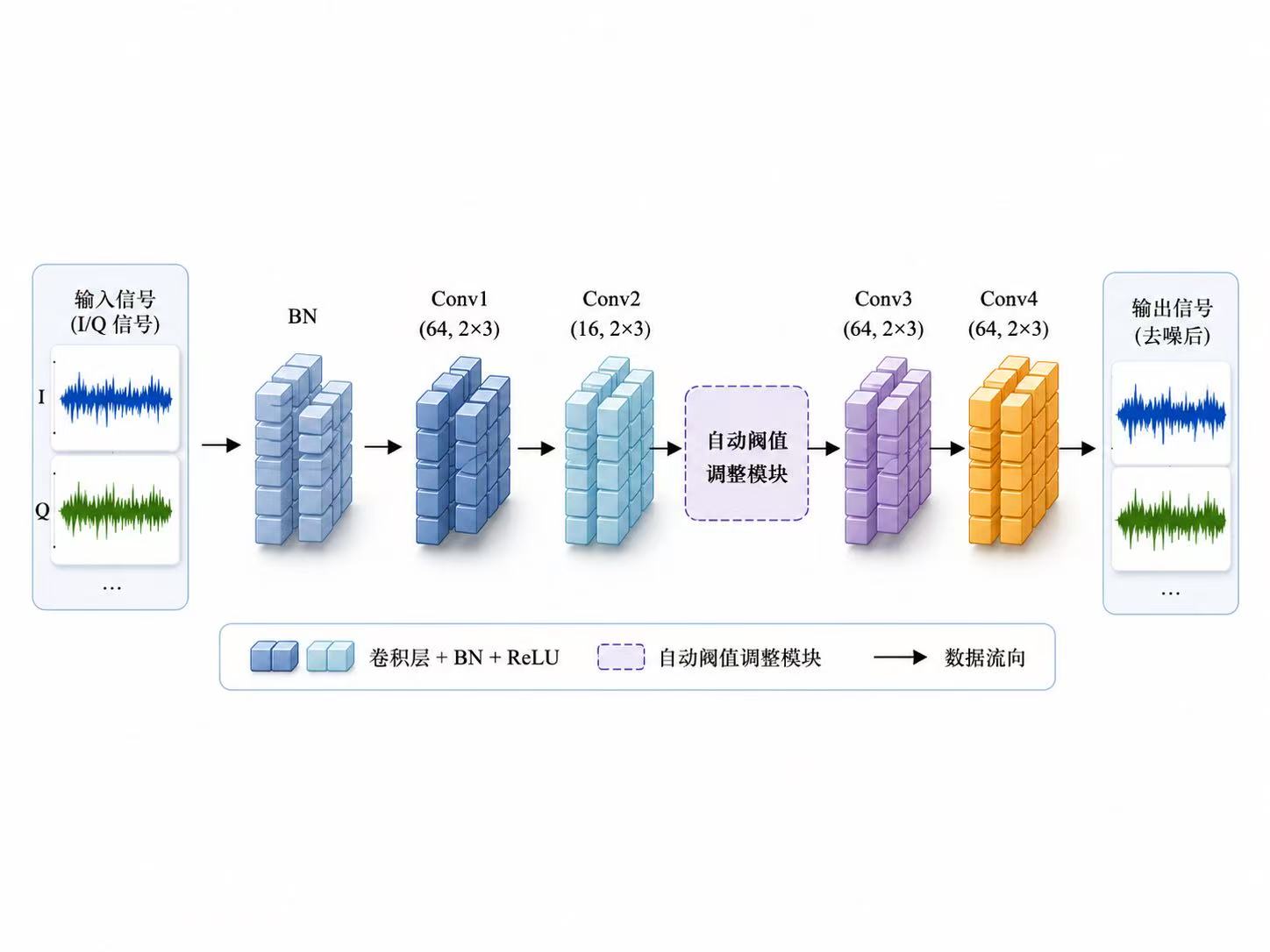
另一个容易被忽略的问题是,低信噪比条件下的识别难点并不只是"噪声大",而是噪声会改变特征分布,使训练阶段学到的判别边界在测试阶段失效。因此,自适应去噪、通道注意力、专家特征融合和裁剪量化这些方法,本质上都在解决同一个问题:如何在噪声干扰、类别混叠和计算资源受限之间取得平衡。去噪模块负责提高输入质量,注意力模块负责筛选关键特征,专家特征负责补充深度网络难以稳定学习的先验信息,而裁剪量化则让模型从"能跑出高精度"进一步走向"能低成本部署"。这也是调制识别算法从单纯追求准确率,逐渐转向鲁棒性、可解释性和工程可部署性的原因。