Text2SQL:让 Agent 自己写 SQL 自己查
你正在做了一个内部数据分析平台,产品经理说:"我想直接问问题就能看到数据,不想写 SQL了。"你说好,然后打开数据库,看了看那二十多张表、几十个字段,心想:这事要是 AI 能做不就爽歪歪?
用户说"上个月注册用户有多少",Agent 理解语义,自动生成一条 SELECT COUNT(*) FROM users WHERE ...,执行,把结果返回给用户。全程不需要人自己写 SQL。这个流程有个专门的名字,叫 Text2SQL:自然语言转 SQL。拆开来看,核心就是"翻译 + 执行"两件事。本文将实现一个最小可用的 Text2SQL Agent。
目录
- 整体流程
- 第一步:告诉模型表结构
- [第二步:让模型生成 SQL](#第二步:让模型生成 SQL)
- [第三步:执行 SQL 并返回结果](#第三步:执行 SQL 并返回结果)
- 安全问题
- 小结
整体流程
用户用自然语言说出问题,Agent 翻译成 SQL语句,然后执行,再把结果用自然语言总结回来。
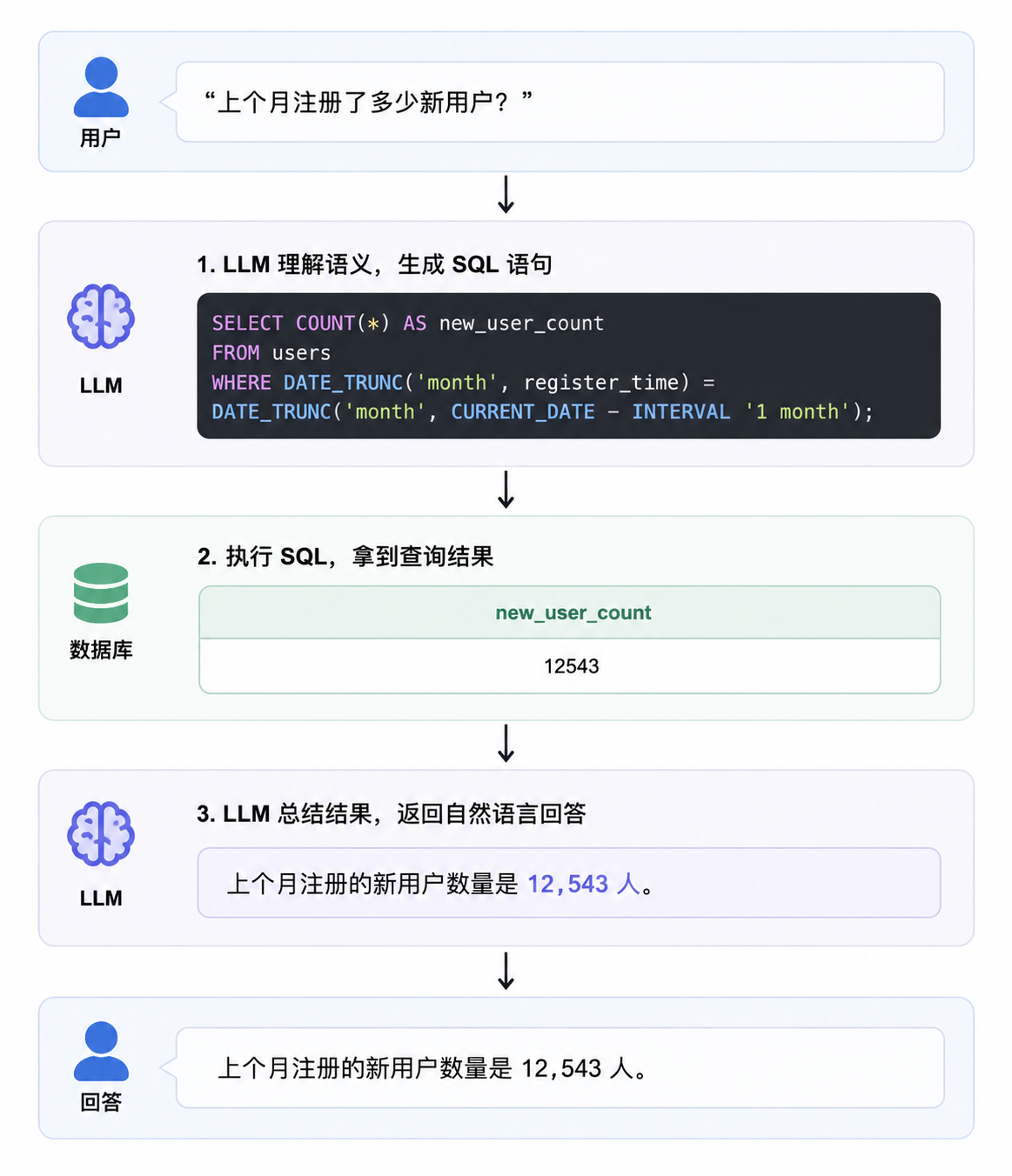
四个环节中,有两次 LLM 调用,一次数据库查询。其实就是给模型加一个"翻译工具"和一个"执行工具",和我们之前讲的 Tool Use 机制完全一样(见笔者主页)。
整个流程可以归纳为三步:
- 给模型看表结构:让AI知道数据库长什么样子
- 模型生成 SQL:根据用户的自然语言问题,生成对应的查询语句
- 执行 SQL 并返回:执行查询操作,用自然语言回复用户
第一步:告诉模型表结构
模型不知道你的数据库具体有哪些表、每个表有哪些字段。所以让他生成SQL之前得先把表结构告诉它。
在 Spring AI 中,我们可以用 @Tool 注解把"获取表结构"注册成一个工具,让模型在需要的时候主动调用。用 DatabaseMetaData 从数据库连接中动态读取表结构,比手动维护一份文本靠谱得多:
java
@Tool(description = "获取数据库表结构信息。在执行SQL查询前,应先调用此方法了解表结构," +
"以便生成正确的SQL语句。返回所有表的名称、列名、数据类型和注释。" +
"可传入表名查看指定表的结构。")
public String getDatabaseSchema(
@ToolParam(description = "可选,指定要查看的表名。不传则返回所有表的结构", required = false)
String tableName) {
try (Connection conn = dataSource.getConnection()) {
DatabaseMetaData metaData = conn.getMetaData();
StringBuilder sb = new StringBuilder("=== 数据库表结构 ===\n\n");
try (ResultSet tables = metaData.getTables(
conn.getCatalog(), conn.getSchema(),
tableName != null ? tableName : "%",
new String[]{"TABLE"})) {
boolean found = false;
while (tables.next()) {
found = true;
String tblName = tables.getString("TABLE_NAME");
String remarks = tables.getString("REMARKS");
sb.append("【表: ").append(tblName).append("】");
if (remarks != null && !remarks.isBlank()) {
sb.append(remarks);
}
sb.append("\n");
try (ResultSet columns = metaData.getColumns(
conn.getCatalog(), conn.getSchema(), tblName, "%")) {
while (columns.next()) {
String colName = columns.getString("COLUMN_NAME");
String typeName = columns.getString("TYPE_NAME");
int colSize = columns.getInt("COLUMN_SIZE");
String colRemarks = columns.getString("REMARKS");
String nullable = columns.getString("IS_NULLABLE");
sb.append(" - ").append(colName)
.append(": ").append(typeName)
.append("(").append(colSize).append(")");
if ("NO".equals(nullable)) {
sb.append(" [NOT NULL]");
}
if (colRemarks != null && !colRemarks.isBlank()) {
sb.append(" (").append(colRemarks).append(")");
}
sb.append("\n");
}
}
sb.append("\n");
}
if (!found) {
return "未找到" + (tableName != null ? "名为 '" + tableName + "' 的" : "") + "表";
}
}
return sb.toString();
} catch (Exception e) {
return "获取表结构失败: " + e.getMessage();
}
}模型拿到这个工具后,遇到用户提问,会先调用 getDatabaseSchema 了解数据库长什么样,然后再生成 SQL。这就是 Tool Use 的机制:模型输出结构化的工具调用请求,代码端负责执行。
第二步:让模型生成 SQL
有了表结构信息,模型就能根据用户的自然语言生成 SQL 了。这里的关键是:不要让模型直接回复用户,而是让它先输出 SQL,交给工具执行。
在 Spring AI 中,我们用 @Tool 注解注册一个 executeQuery 方法,并在描述里写清楚"这是执行 SQL 的工具"。模型看到工具列表后,遇到数据查询类的问题,就会自动调用它:
java
@Tool(description = "执行SQL查询语句。仅支持SELECT只读查询," +
"不支持INSERT/UPDATE/DELETE等写操作。" +
"执行前请先调用getDatabaseSchema了解表结构。")
public String executeQuery(
@ToolParam(description = "要执行的SQL SELECT语句,如 SELECT COUNT(*) FROM users") String sql,
@ToolParam(description = "最大返回行数,默认100,最大1000", required = false) Integer maxRows) {
// ... 实现见下文
}注意描述里的那句"仅支持 SELECT 只读查询"。这是安全策略,只让Agent执行查询等无风险操作。
第三步:执行 SQL 并返回结果
模型生成了 SQL,接下来就是真正连数据库执行查询。来看 executeQuery 的核心实现:
java
@Tool(description = "执行SQL查询语句。仅支持SELECT只读查询,不支持INSERT/UPDATE/DELETE等写操作。")
public String executeQuery(
@ToolParam(description = "要执行的SQL SELECT语句") String sql,
@ToolParam(description = "最大返回行数,默认100,最大1000", required = false) Integer maxRows) {
// 第一步:安全校验
String validationError = validateSql(sql);
if (validationError != null) {
return "=== 查询失败 ===\nSQL: " + sql + "\n错误: " + validationError;
}
// 第二步:确定返回行数上限
int limit = (maxRows != null && maxRows > 0)
? Math.min(maxRows, MAX_ALLOWED_ROWS) : defaultMaxRows;
try (Connection conn = dataSource.getConnection()) {
conn.setReadOnly(true); // 设置连接为只读
try (Statement stmt = conn.createStatement()) {
stmt.setQueryTimeout(queryTimeoutSeconds); // 设置查询超时
boolean hasResultSet = stmt.execute(sql);
if (!hasResultSet) {
return "=== 查询完成 ===\nSQL: " + sql + "\n该语句没有返回结果集";
}
try (ResultSet rs = stmt.getResultSet()) {
ResultSetMetaData meta = rs.getMetaData();
int columnCount = meta.getColumnCount();
// 读取数据,不超过 limit 行
List<String[]> rows = new ArrayList<>();
int rowCount = 0;
while (rs.next() && rowCount < limit) {
String[] row = new String[columnCount];
for (int i = 1; i <= columnCount; i++) {
Object val = rs.getObject(i);
row[i - 1] = val != null ? val.toString() : "NULL";
}
rows.add(row);
rowCount++;
}
boolean truncated = rs.next(); // 判断是否还有更多数据
return formatAsTable(sql, meta, columnCount, rows, truncated);
}
}
} catch (SQLException e) {
return "=== 查询失败 ===\nSQL: " + sql + "\n错误: " + e.getMessage();
}
}查询结果返回给模型后,模型会用自然语言总结结果,回复用户。比如用户问"上个月注册了多少新用户",模型生成 SQL 查到数字是 1523,然后回复:"上个月共有 1523 名新用户注册。"
在 Spring Boot 中注册这个工具,只需要把它交给 Spring AI 的 ToolCallbackProvider:
java
@Bean
public SqlTool sqlTool(DataSource dataSource) {
return new SqlTool(dataSource, 100, 30);
}Spring AI 会自动扫描 @Tool 注解,把 getDatabaseSchema 和 executeQuery 注册为模型可用的工具。模型看到工具列表后,遇到数据查询类问题,就会按顺序调用:先调 getDatabaseSchema 了解表结构,再调 executeQuery 执行 SQL。
跑一遍看看效果。假设 users 表有实际数据,流程大概是这样的:
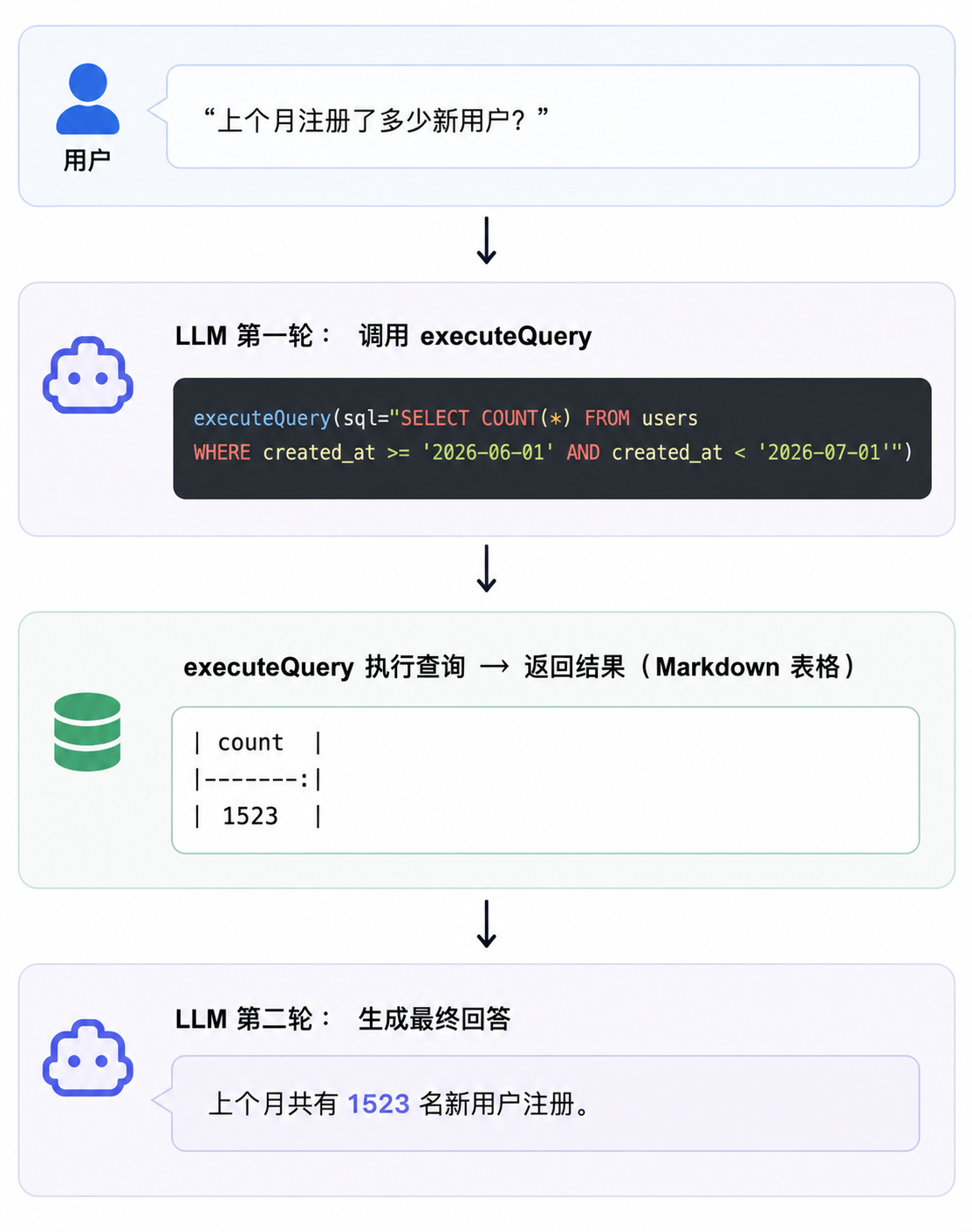
两轮 LLM 调用,一次数据库查询,搞定。
安全问题
讲到Text2SQL,有一个绕不开的话题:安全。
让模型生成 SQL 然后直接执行,万一模型生成了一条 DROP TABLE users 怎么办?或者生成了 DELETE FROM orders 呢?
模型虽然被 prompt 约束了"只生成 SELECT",但 prompt 不是铁板一块。精心构造的 prompt injection 可能绕过这个限制。
所以必须在代码层面做防护,不能只靠 prompt。来看 validateSql 方法的四道防线:
java
private String validateSql(String sql) {
if (sql == null || sql.isBlank()) {
return "SQL 语句不能为空";
}
String normalized = sql.strip().replaceAll(";+\\s*$", "").toUpperCase();
// 第一道防线:只允许 SELECT 和 WITH(CTE 查询)
if (!normalized.startsWith("SELECT") && !normalized.startsWith("WITH")) {
String firstToken = normalized.contains(" ")
? normalized.substring(0, normalized.indexOf(' ')) : normalized;
return "安全拦截 - 仅允许 SELECT 查询,检测到禁止的操作: " + firstToken;
}
// 第二道防线:禁止危险关键词(用正则精确匹配单词边界)
String[] forbiddenKeywords = {
"INSERT", "UPDATE", "DELETE", "DROP", "ALTER", "CREATE",
"TRUNCATE", "REPLACE", "MERGE", "GRANT", "REVOKE",
"EXEC", "EXECUTE", "CALL", "INTO OUTFILE", "INTO DUMPFILE",
"LOAD_FILE", "COPY", "PG_READ_FILE", "PG_WRITE_FILE"
};
for (String keyword : forbiddenKeywords) {
Pattern pattern = Pattern.compile("\\b" + keyword + "\\b");
if (pattern.matcher(normalized).find()) {
return "安全拦截 - 检测到禁止的关键字: " + keyword;
}
}
// 第三道防线:禁止注释(防止绕过检查)
if (normalized.contains("--") || normalized.contains("/*")) {
return "安全拦截 - SQL 中不允许包含注释";
}
return null; // 校验通过
}再加上 executeQuery 里的两道执行层防线:
| 防线 | 在哪 | 防什么 |
|---|---|---|
| 只允许 SELECT / WITH | validateSql | 阻止写操作 |
| 正则匹配危险关键词 | validateSql | 防止嵌套攻击,如 SELECT * FROM users; DROP TABLE users |
| 禁止注释符号 | validateSql | 防止绕过检查,如 SELECT * -- ; DROP TABLE users |
conn.setReadOnly(true) |
executeQuery | 数据库层面拒绝写操作 |
stmt.setQueryTimeout() |
executeQuery | 防止慢查询拖垮数据库 |
行数上限 MAX_ALLOWED_ROWS |
executeQuery | 防止全表扫描返回百万行数据 |
模型的输出永远不能被完全信任,所以必须在代码层面兜底。prompt 约束是第一层,validateSql 是第二层,数据库连接的 readOnly 是第三层。三层配合才靠谱。
小结
Text2SQL 的核心思想:把"理解问题"交给模型,把"执行查询"交给代码,两者通过 SQL 这个桥梁连接。
实现一个 Text2SQL Agent,本质上就是在 AgentLoop 的基础上注册两个工具:getDatabaseSchema 和 executeQuery。模型负责理解用户意图、生成 SQL,代码负责连接数据库、执行查询、安全检查。整个过程和 Agent 调用 bash 工具没有区别,模型输出工具调用请求,代码端查注册表、执行、返回结果。
唯一需要额外注意的是安全。模型的输出不能被完全信任,必须在代码层面做防护:validateSql 做关键词过滤,conn.setReadOnly(true) 在数据库层面拒绝写操作,setQueryTimeout 防止慢查询。prompt 约束是第一层,代码检查是第二层,数据库连接限制是第三层。三层都到位了,Text2SQL Agent 才能在生产环境安心使用。