ACL 2025杰出论文|删掉95%样本,长上下文评测还能保持0.97相关
论文与代码链接:
• 论文:arXiv 2505.19959,https://arxiv.org/abs/2505.19959
• ACL Anthology:Outstanding Paper,https://aclanthology.org/2025.acl-long.560/
• 代码与数据:GitHub,https://github.com/MilkThink-Lab/MiniLongBench
长上下文能力已经成为大模型竞赛里最昂贵、也最难被稳定评估的一环。问题在于,评测本身也越来越像一次小型训练任务:长文本、多任务、大量样本,再叠加模型推理成本,最后变成研究者很难频繁运行的"重型仪器"。
中山大学的研究者在 ACL 2025 Outstanding Paper《MiniLongBench》中给出了一个反直觉答案:长上下文评测不一定要保留那么多样本。通过对 LongBench 进行压缩,他们构建了 MiniLongBench,一个只包含237个测试样本、覆盖6大任务类别和21个细分任务的低成本长上下文理解基准。更关键的是,论文在超过60个LLM上的分析显示,MiniLongBench 的平均评测成本降到原来的4.5%,同时与 LongBench 结果保持0.97的平均排名相关系数。换句话说,它试图回答的不是"能不能少测一点",而是"少测很多以后,模型排序还靠不靠谱"。
长上下文评测,为什么会变贵
Long Context Understanding,简称 LCU,指的是模型处理数千乃至数万 token 上下文的能力。问答、论文阅读、长报告摘要、代码仓库理解,都依赖这种能力。
但长上下文基准天然有一个成本问题:每个样本都很长,每次推理都要消耗大量 token 和显存。LongBench 作为经典长上下文理解基准,包含近5000个测试样本,覆盖单文档问答、多文档问答、摘要、few-shot learning、合成任务和代码补全等场景。
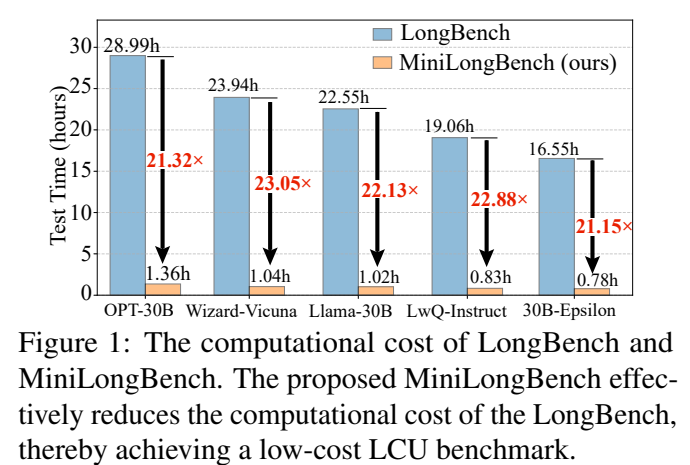
论文给出的一个直观数字是,在8张RTX 3090 GPU、batch size为1的设置下,一些模型跑完整个 LongBench 需要约15到30小时。对于需要反复调参、比较checkpoint、验证长上下文能力的研究团队来说,这种评测成本并不轻。
图1:论文 Figure 1,LongBench 与 MiniLongBench 的测试时间对比。
真正的切入点:LongBench里有多少冗余
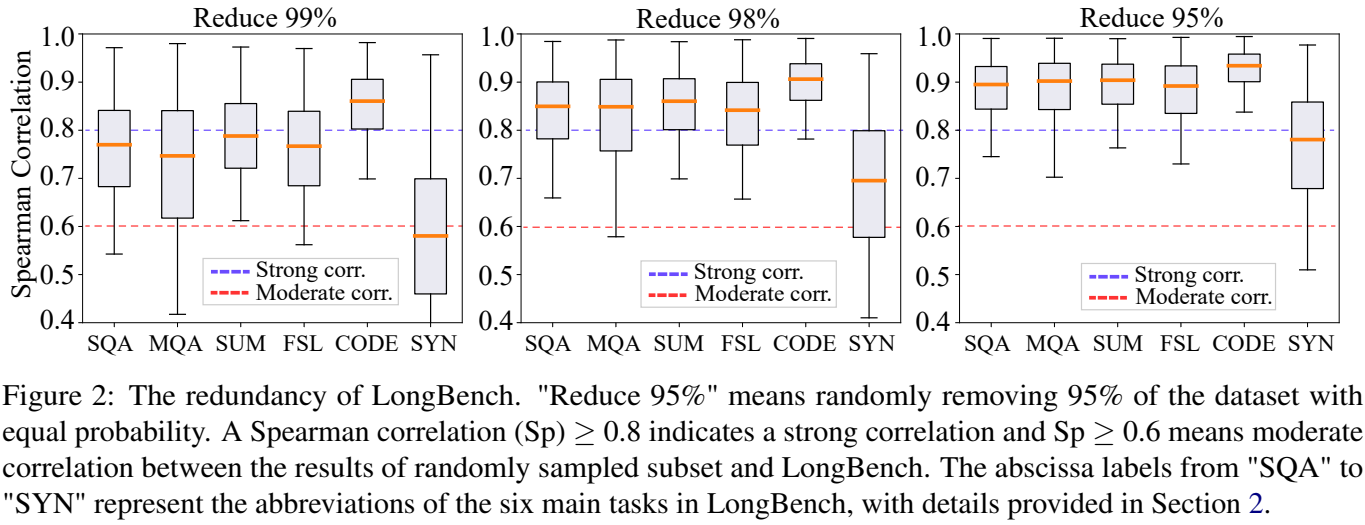
研究者首先做了一组随机采样实验:从 LongBench 不同任务类别中大量随机删除样本,再观察这些子集与完整 LongBench 评测结果之间的 Spearman 排名相关系数。
结果很有意思。即使随机移除95%、98%甚至99%的数据,仍然有一些子集可以和完整 LongBench 保持较强相关。这说明一个问题:长上下文基准里并非每个样本都同样关键,部分样本对模型排名的贡献存在重叠。
但随机删数据并不是解法。论文也指出,随机采样方差很大,可能偶尔抽到一个好子集,也很容易抽到一个破坏分布的子集。因此,MiniLongBench 的核心不在于"删",而在于"怎么选"。
方法:先压缩长文本,再学习样本代表性
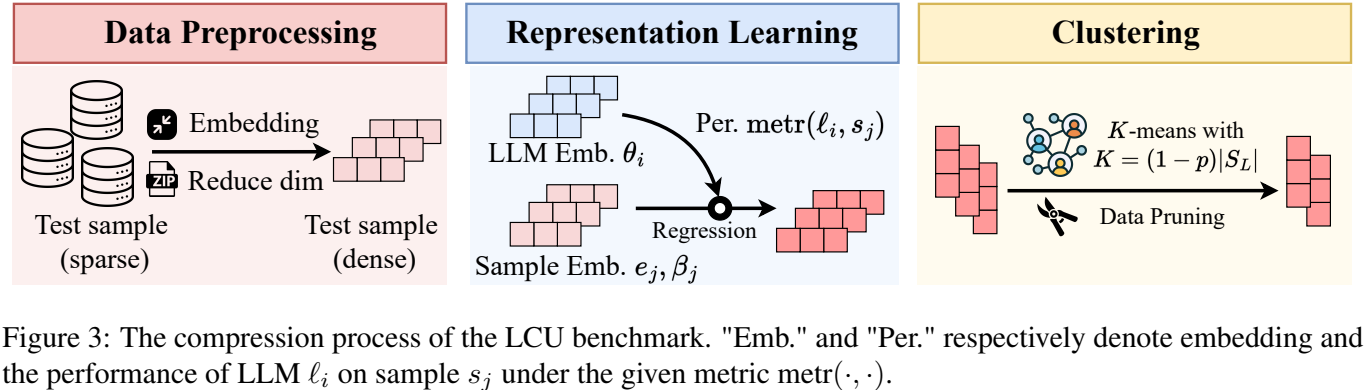
MiniLongBench 的构建流程可以拆成三步。
第一步是数据预处理。由于长文本里的有效信息高度稀疏,研究者先用文本编码器把样本转成向量,再通过PCA降维,把样本初始化为更稠密的低维表示。论文默认使用的表示维度是d=10。
第二步是表示学习。研究者借鉴类似 Item Response Theory 的思路,把"模型"和"测试样本"都映射到同一个性能空间里。直观理解,每个样本不只是一段文本,它还带有某种"区分模型能力"的属性:强模型和弱模型在它上面的表现差异,能帮助判断这个样本是否有代表性。
第三步是聚类。完成表示学习后,论文将样本表示进行 K-Means 聚类,并选取聚类中心作为代表性测试样本。最终得到的 MiniLongBench 只保留237个样本,但仍覆盖 LongBench 原本的6类任务和21个细分任务。
237个样本,覆盖什么
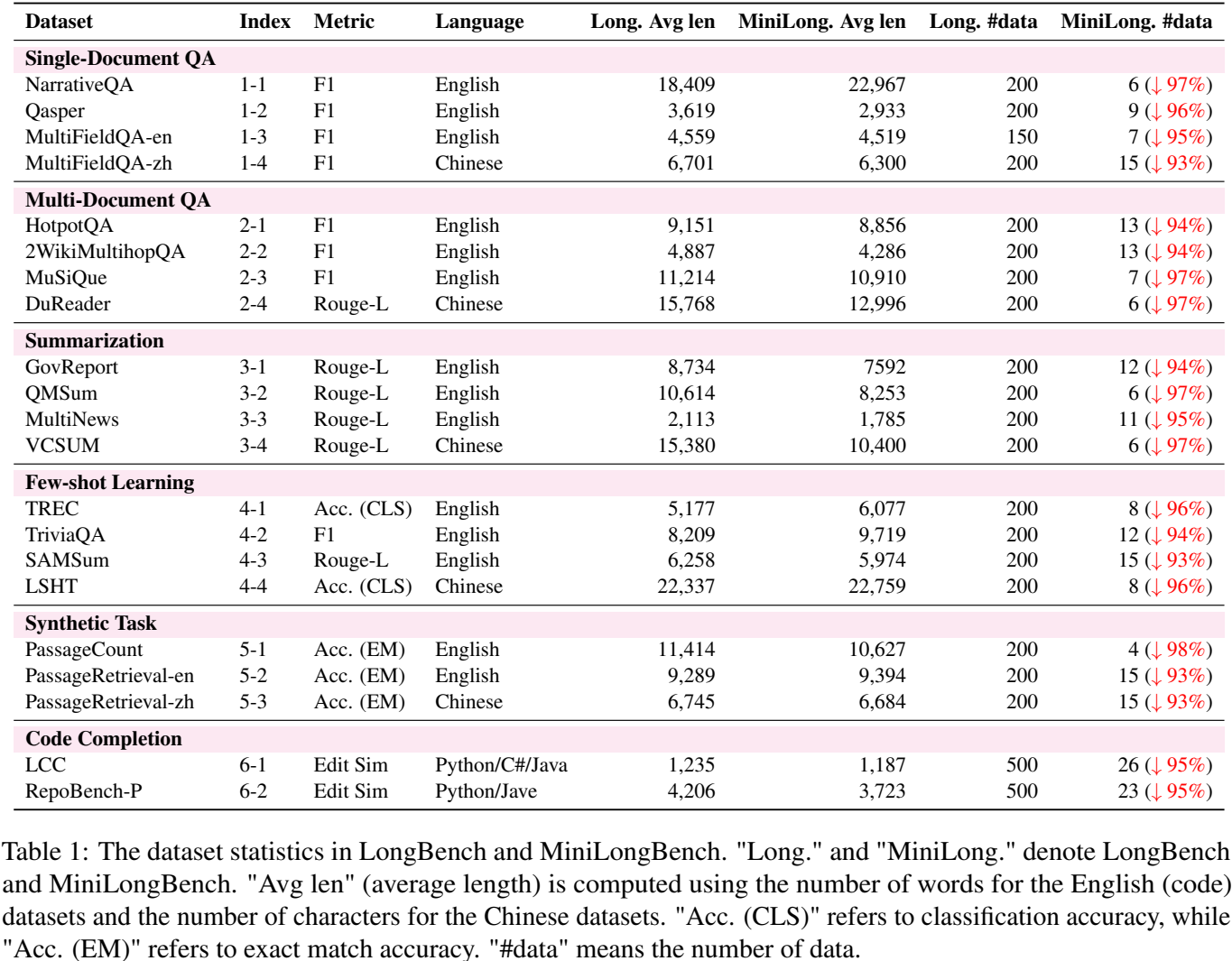
MiniLongBench 并不是只保留某几类容易评测的任务。根据论文 Table 1,它保留了 LongBench 的完整任务版图:单文档问答、多文档问答、摘要、few-shot learning、合成任务和代码补全。
从样本数量看,压缩力度非常大。例如 NarrativeQA 从200个样本压到6个,PassageCount 从200个压到4个,代码补全里的 LCC 从500个压到26个,RepoBench-P 从500个压到23个。整体上,它约减少了95%的样本量。
这也是 MiniLongBench 最需要被验证的地方:样本变少并不难,难的是任务覆盖和模型排序不能明显失真。
实验结果:成本降到4.5%,相关性保持0.97
论文在超过60个LLM上验证了 MiniLongBench 的有效性。其中20个模型参与构建过程,其他模型用于测试泛化。
直接使用 MiniLongBench 进行评测时,它与 LongBench 可以达到0.95左右的 Spearman 相关。进一步地,论文还提出一种估计方式:先在 MiniLongBench 的样本上测试新模型,再利用学习到的样本表示估计其在完整 LongBench 上的表现。这样相关性可以提升到0.97。
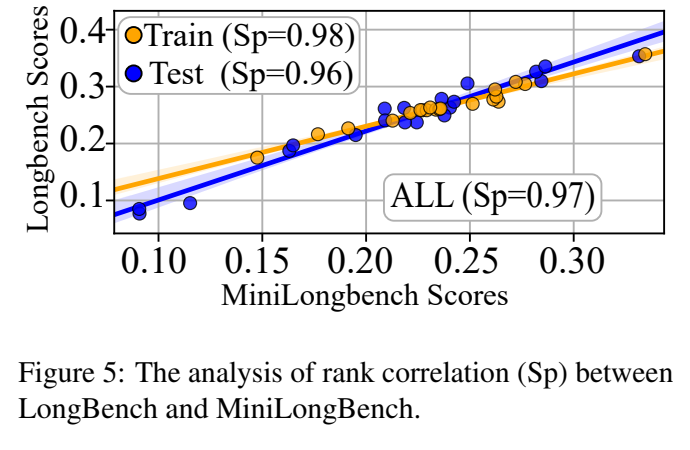
这意味着什么?在模型评测中,绝对分数当然重要,但很多时候研究者更关心模型之间的相对排名。只要排名高度一致,低成本基准就能成为日常迭代中的快速筛查工具。
论文还给出一个工程侧细节:用于估计完整 LongBench 分数的特征存储只需要约10MB;在笔记本上微调新模型表示向量的GPU时间约0.03秒。相比动辄数十小时的完整评测,这几乎可以忽略。
指标 LongBench MiniLongBench
样本规模 近5000个样本 237个样本
任务覆盖 6大任务、21个细分任务 保留6大任务、21个细分任务
平均评测成本 完整成本 约4.5%
与完整评测排名相关 基准本身 平均Spearman 0.97
适用定位 全面评估 低成本快速估计
为什么不是简单随机采样
如果只看"删掉95%还能保持强相关"这个结论,很容易误以为随机抽样就足够了。但论文的分析恰恰说明,随机抽样有高方差。它能证明 LongBench 存在冗余,却不能稳定地产生一个可靠基准。
MiniLongBench 的关键在于引入模型表现记录,让样本选择和模型能力差异绑定起来。换句话说,它不是从数据集中随机挑代表,而是寻找那些最能区分模型长上下文能力的样本。
这就像考试命题。减少题量不难,难的是少数题仍然覆盖知识点,并且能区分不同水平的学生。MiniLongBench 做的,就是把这件事从人工经验转成一个可学习、可复现的压缩流程。
局限:压缩不是无损,也需要训练数据
这篇论文也没有把 MiniLongBench 描述成 LongBench 的完全替代品。作者在局限性中提到,构建压缩基准需要来自不同LLM的性能记录,而这些数据在实践中并不总是开源,获取它们仍然需要API成本或GPU资源。
此外,0.97的相关性很高,但不是1.0。这意味着 MiniLongBench 无法保证和 LongBench 在每个模型、每个任务上完全一致。论文也指出,摘要和合成任务上仍有进一步提升空间。
因此,更合理的使用方式可能是:把 MiniLongBench 当作高频、低成本的评测入口,用于快速筛查模型长上下文能力;而完整 LongBench 则继续承担低频、全面、最终确认的角色。
一个更现实的长上下文评测工具
过去一年,长上下文能力正在从"最大窗口长度"转向"真实理解能力"。但如果每次评测都要耗费十几到几十小时,长上下文研究本身就会被评测成本拖慢。
MiniLongBench 的价值,恰好在于把这个重型流程变轻。它不是宣称237个样本可以回答所有问题,而是证明:在长文本数据高度冗余的前提下,经过合适的表示学习和样本选择,评测成本可以被大幅压低,同时保留对模型排名的强刻画能力。
这对研究者和模型团队都很实用。它让长上下文能力不再只适合发布前跑一次"大考",也可以变成训练、对齐、上下文扩展过程中的日常体检。