我们知道,AdaBoost最后生成的强分类器可以认为是一个加法模型,即:
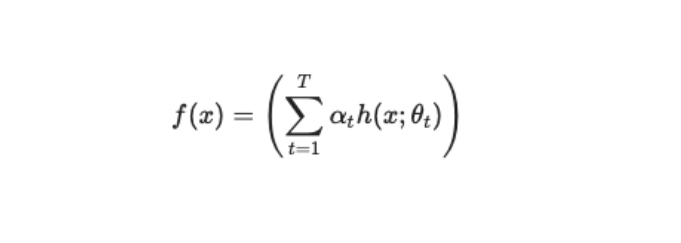
其中,f(x) 表示最终的强分类器,h(X ; θt ) 表示第 t 个弱分类器,θt 是该分类器的参数,αt 是该分类器的权重。
学习这个模型可以最小化损失函数,但是这个问题非常复杂, 前向分步算法是用来解决这个优化问题。它通过从前向后每次学习一个基函数和系数,然后逐步逼近优化目标函数。
在 AdaBoost 中,优化的损失函数是指数损失函数,如下:
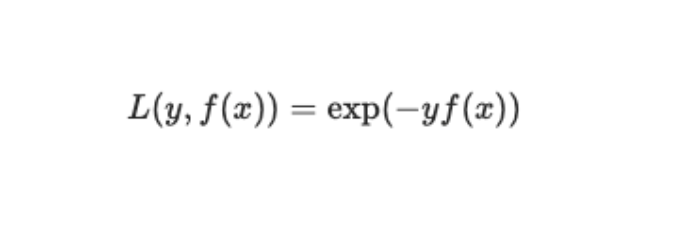
其中,y∈{−1, +1} 表示样本的真实标签,f(x) 表示模型的预测值。
通过优化目标,可以反过来推出 αt 的取值和上一种理解相同,如下:
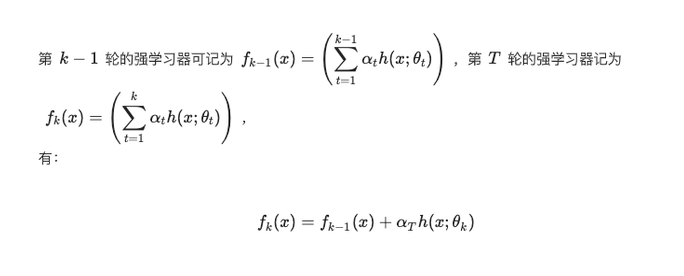
在优化最小化指数函数的时候,在第 k 步时,有:

然后我们考虑如何计算 αt ,αt 是基本分类器的权重,它的计算如下:
- 计算 Gt 在训练集上样本加权后的分类误差率:
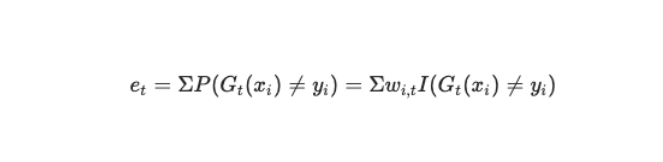
- 取自然对数
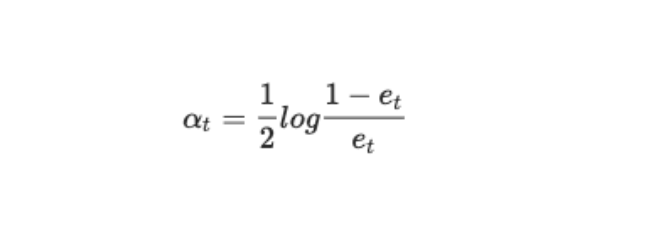
第二步的公式怎么来的呢?
这是因为我们希望正确分类的样本的权重比上错误分类的样本的权重恰好是正确率和错误率的比值的反比,如果用上面的式子的话,就有
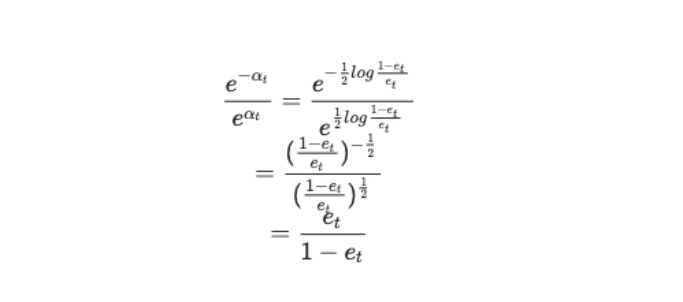
假设两个弱分类器 a 和 b ,ea = 0.8 和 eb = 0.1 ,在这两种情况下,正确分类的样本的权重比上错误分类的样本的权重分别是 8 : 2 和 1 : 9 。前一种情况的错误率很高,也就是大部分都是误分类的样本时,这时反而会提高分类正确的样本的权重。
AdaBoost 算法在得到最终的分类器时,会对之前所有的分类器进行加权。以上面的分类器为例,a 和 b 的 α 的比值:
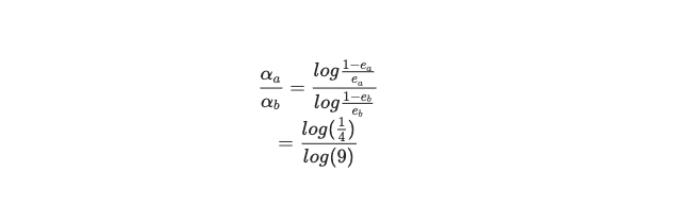
可知 log(4/1) 是负数,log (9) 是正数,此处可以看出,分类性能越好的分类器,计算出的权重会更大,对最终结果影响的程度越高。