Transformer原理
零.序列模型的基本思路与根本诉求
对于时间序列或文本数据而言,每个样本(时间点/字词)与样本之间均存在着高度的语义或逻辑关联。在序列数据中,众多的本质规律与底层逻辑都隐藏在其样本与样本之间的关联中。 序列算法的核心诉求就是要建立这种样本间的关联。总结众多序列模型(ARIMA、RNN、CNN)的经验,成功的序列架构都在使用加权求和的方式来建立样本间的联系。 Transformer 给出了"如何合理计算加权求和权重"的最佳答案------注意力机制。
-
ARIMA家族算法群
过去影响未来,因此未来的值由过去的值加权求和而成,以此构建样本与样本之间的关联。
AR模型:yt=c+w1yt−1+w2yt−2+⋯+wpyt−p+εtAR模型:y_t = c + w_1 y_{t-1} + w_2 y_{t-2} + \dots + w_p y_{t-p} + \varepsilon_tAR模型:yt=c+w1yt−1+w2yt−2+⋯+wpyt−p+εt
-
循环网络家族
遍历时间点/样本点,将过去的时间上的信息传递存储在中间变量中,传递给下一个时间点,以此构建样本和样本之间的关联。
RNN模型:ht=Wxh⋅xt+Whh⋅ht−1RNN模型:h_t = W_{xh}\cdot x_t + W_{hh}\cdot h_{t-1}RNN模型:ht=Wxh⋅xt+Whh⋅ht−1
LSTM模型:C~t=tanh(Wxi⋅xt+Whi⋅ht−1+bi)LSTM模型:\tilde{C}t = tanh(W{xi} \cdot x_t + W_{hi} \cdot h_{t-1} + b_i)LSTM模型:C~t=tanh(Wxi⋅xt+Whi⋅ht−1+bi)
-
卷积网络家族
使用卷积核扫描时间点/样本点,将上下文信息通过卷积计算整合到一起,以此构建样本和样本之间的关联。如下图所示,蓝绿色方框中携带权重www,权重与样本值对应位置元素相乘相加后生成标量,这是一个加权求和过程。

这三种本质都是以往样本加权求和得到新样本
一.注意力机制
1. 注意力机制的本质
nlp中序列内的样本指的就是词向量
**注意力机制本质上是一个帮助算法辨别信息重要性的计算流程。 它通过计算序列内样本与其他样本之间的相关性,来判断每个样本对于理解整个序列的"重要程度",并赋予能够代表其重要性的权重。**在 Transformer 中使用的是"自注意力机制(Self-Attention)",即核心计算的是序列内部自身词汇与词汇之间的相关性。向量的点积绝对值越大,代表两个样本越相关,其对整体语义的影响也就越重要。
面试考点:作为一种权重计算机制、注意力机制有多种实现形式。
- 经典的注意力机制(Attention):进行的是跨序列的样本相关性计算,这是说,经典注意力机制考虑的是序列A的样本之于序列B的重要程度。这种形式常常用于经典的序列到序列的任务(Seq2Seq),比如机器翻译;在机器翻译场景中,我们会考虑原始语言系列中的样本对于新生成的序列有多大的影响,因此计算的是原始序列的样本之于新序列的重要程度。
- 自注意力机制(Self-Attention):在Transformer当中我们使用的是自注意力机制,这是在一个序列内部对样本进行相关性计算的方式,核心考虑的是序列A的样本之于序列A本身的重要程度。
比如当前有序列A、序列B。
- 经典的注意力机制是用序列B的当前时间步,去和序列A的所有时间步进行相关性计算。
- 自注意力机制是用序列A的当前时间步,去和序列A自身的其他所有时间步进行相关性计算。
-
为什么要判断序列中样本的重要性?计算重要性对于序列理解来说有什么意义?
在序列数据当中,每个样本对于"理解序列"所做出的贡献是不相同的,能够帮助我们理解序列数据含义的样本更为重要,而对序列数据的本质逻辑/含义影响不大的样本则不那么重要。
以文字数据为例:
尽管今天下了雨,但我因为_________而感到非常开心和兴奋。
__________,但我因为拿到了梦寐以求的工作offer而感到非常开心和兴奋。
观察上面两句话,我们分别抠除了一些关键信息。很显然,第一个句子令我们完全茫然,但第二个句子虽然缺失了部分信息,但我们依然理解事情的来龙去脉。从这两个句子我们明显可以看出,不同的信息对于句子的理解有不同的意义。
在实际的深度学习预测任务当中也是如此:尽管今天下了雨,但我因为拿到了梦寐以求的工作offer而感到非常开心和兴奋。
假设模型对句子进行情感分析,很显然整个句子的情感倾向是积极的,在这种情况下,"下了雨"这一部分对于理解整个句子的情感色彩贡献较小,相对来说,"拿到了梦寐以求的工作offer"和"感到非常开心和兴奋"这些部分则是理解句子传达的正面情绪的关键。因此对序列算法来说,如果更多地学习"拿到了梦寐以求的工作offer"和"感到非常开心和兴奋"这些词,就更有可能对整个句子的情感倾向做出正确的理解,就更有可能做出正确的预测。当我们使用注意力机制来分析这样的句子时,自注意力机制可能会为"开心"和"兴奋"这样的词分配更高的权重,因为这些词直接关联到句子的情感倾向。
如果我们能够判断出一个序列中哪些样本是重要的、哪些是无关紧要的,就可以引导算法去重点学习更重要的样本,从而可能提升模型的效率和理解能力。
-
那样本的重要性是如何定义的?为什么?
自注意力机制通过计算样本与样本之间的相关性来判断样本的重要性,在一个序列当中,如果一个样本与其他许多样本都高度相关,则这个样本大概率会对整体的序列有重大的影响。
举例说明:
经理在会议上宣布了重大的公司______计划,员工们反应各异,但都对未来充满期待。
在这个例子中,我们抠除的这个词与"公司"、"计划"、"会议"、"宣布"和"未来"等词汇都高度相关。如果我们针对这些词汇进行提问:*公司做了什么?宣布了什么内容?计划是什么?未来会发生什么?会议上的主要内容是什么?*会发现所有这些问题的答案都围绕着这一个被抠除的词产生。
这个完整的句子是:经理在会议上宣布了重大的公司重组计划,员工们反应各异,但都对未来充满期待。
被抠掉的部分是重组 。重组这个词是整个句子的关键,而且也对其他词语的理解有着重大的影响。重组这个词很明显对整个句子的理解有重大影响,而且它也和句子中的其他词语高度相关。
如果抠掉的是:经理在会议上宣布了重大的公司重组计划,______反应各异,但都对未来充满期待。
虽然我们缺失了一些信息,但实际上这个信息并不太影响对于整体句子的理解,我们甚至可以大致推断出缺失的信息部分。
在序列数据中我们认为与其他样本高度相关的样本,大概率会对序列整体的理解有重大影响。因此样本与样本之间的相关性可以用来衡量一个样本对于序列整体的重要性。
-
样本的重要性(既一个样本与其他样本之间的相关性)具体是如何计算的?
在NLP的世界中,序列数据中的每个样本都会被编码成一个向量,其中文字数据被编码后的结果被称为词向量,时间序列数据则被编码为时序向量。
计算样本与样本之间的相关性,本质就是计算向量与向量之间的相关性。向量的相关性可以由两个向量的点积来衡量。
-
如果两个向量完全相同方向(夹角为0度),它们的点积最大,这表示两个向量完全正相关;
-
如果它们方向完全相反(夹角为180度),点积是一个最大负数,表示两个向量完全负相关;
-
如果它们垂直(夹角为90度或270度),则点积为零,表示这两个向量是不相关的。
因此,向量的点积值的绝对值越大,则两个向量之间的相关性越强;若向量的点积值绝对值越接近0,则说明两个向量相关性越弱。
向量的点积就是两个向量相乘的过程,设有两个三维向量A\mathbf{A}A 和 B\mathbf{B}B,则向量他们之间的点积可以具体可以表示为:
A⋅BT=(a1,a2,a3)⋅(b1b2b3)=a1⋅b1+a2⋅b2+a3⋅b3 \mathbf{A} \cdot \mathbf{B}^T = \begin{pmatrix} a_1, a_2, a_3 \end{pmatrix} \cdot \begin{pmatrix} b_1 \\ b_2 \\ b_3 \end{pmatrix} = a_1 \cdot b_1 + a_2 \cdot b_2 + a_3 \cdot b_3 A⋅BT=(a1,a2,a3)⋅ b1b2b3 =a1⋅b1+a2⋅b2+a3⋅b3
最终得到一个标量。
在NLP的世界当中,我们所拿到的词向量数据或时间序列数据一定是具有多个样本(词向量)的。我们需要求解样本与样本两两之间的相关性,综合该相关性分数,我们才能够计算出一个样本对于整个序列的重要性。
在这里需要注意的是,在NLP的领域中,样本与样本之间的相关性计算、即向量的之间的相关性计算会受到向量顺序的影响。这是说,以一个单词为核心来计算相关性,和以另一个单词为核心来计算相关性,会得出不同的相关程度,向量之间的相关性与顺序有关。
举例说明:
假设我们有这样一个句子:我爱小猫咪。
- 如果以"我"字作为核心词,计算"我"与该句子中其他词语的相关性,那么"爱"和"小猫咪"在这个上下文中都非常重要。"爱"告诉我们"我"对"小猫咪"的感情是什么,而"小猫咪"是"我"的感情对象。"爱"和"小猫咪"与"我"这个词的相关性就很大。
- 但是,如果以"小猫咪"作为核心词,计算"小猫咪"与该剧自中其他词语的相关性,那么"我"的重要性就没有那么大了。因为不论是谁爱小猫咪,都不会改变"小猫咪"本身。这个时候,"小猫咪"对"我"这个词的上下文重要性就相对较小。
因此,假设数据中存在A和B两个样本,则我们必须计算AB、AA、BA、BB四组相关性才可以。在每次计算相关性时,作为核心词的那个词被认为是在"询问"(Question),而作为非核心的词的那个词被认为是在"应答"(Key),AB之间的相关性就是A询问、B应答的结果,AA之间的相关性就是A向自己询问、A自己应答的结果。
==相关性计算可以通过矩阵的乘法来完成。==假设现在我们的向量中有2个样本(A与B),每个样本被编码为了拥有4个特征的词向量。如下所示,如果我们要计算A、B两个向量之间的相关性,只需要让特征矩阵与其转置矩阵做点积就可以了:
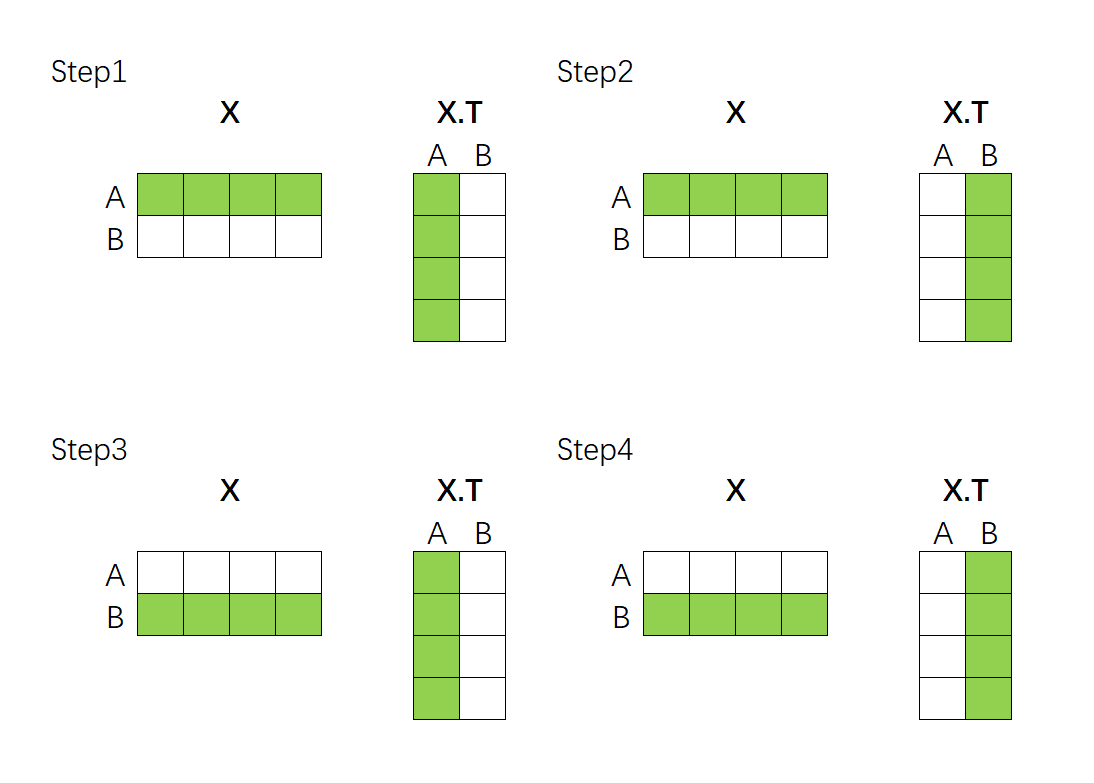
上述点积结果得到的最终矩阵是:
rAArABrBArBB\]\\begin{bmatrix} r_{AA} \& r_{AB} \\\\ r_{BA} \& r_{BB} \\end{bmatrix}\[rAArBArABrBB
该乘法规律可以推广到任意维度的数据上,如果是n个样本(即:n个时间步/词向量)的序列与自身的转置相乘,就会得到nxn结构的相关性矩阵,这些相关性矩阵代表着这一序列当中每个样本与其他样本之间的相关性。
相关系数的个数、以及相关性矩阵的结构只与样本的数量有关,与样本的特征维度无关。因此面对任意的数据,我们只需要让该数据与自身的转置矩阵相乘,就可以自然得到这一序列当中每个样本与其他样本之间的相关性构成的相关性矩阵了。
在实际计算相关性时,我们一般不会直接使用原始特征矩阵并让它与转置矩阵相乘,因为我们渴望得到的是语义的相关性,而非单纯数字上的相关性。因此在NLP中使用注意力机制的时候,我们往往会先在原始特征矩阵的基础上乘以一个解读语义的www参数矩阵,以生成用于询问的矩阵Q、用于应答的矩阵K以及其他可能有用的矩阵;就是把X⋅XTX{\cdot}X^TX⋅XT变成(X⋅wQ)⋅(X⋅wK)T(X{\cdot}{wQ}){\cdot}(X{\cdot}{wK})^T(X⋅wQ)⋅(X⋅wK)T,其中(X⋅wQ)(X{\cdot}{wQ})(X⋅wQ)就是Q{Q}Q矩阵,(X⋅wK)(X{\cdot}{wK})(X⋅wK)就是K{K}K矩阵。
在实际进行运算时,www是神经网络的参数,是由迭代获得的,因此www会依据损失函数的需求不断对原始特征矩阵进行语义解读,而我们实际的相关性计算是在矩阵Q和K之间运行的。使用Q和K求解出相关性分数的过程,就是自注意力机制的核心过程,如下图所示:
-
2. Transformer中的自注意力机制运算步骤
自注意力机制通过特征矩阵的线性变换与内积计算来完成样本间的加权聚合。
Step1: 通过词向量得到 Q、K、V 矩阵。
- 将原始特征矩阵分别乘以参数矩阵 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV,得到询问矩阵(Query, QQQ)、应答矩阵(Key, KKK)和信息值矩阵(Value, VVV)。
Step2: 计算QKTQK^TQKT相似度,得到相关性矩阵。
-
让QQQ和KTK^TKT进行点积,计算出序列中每个样本与其他样本之间的初始相关性得分。并除以dk\sqrt{d_k}dk (特征维度的平方根)进行标准化,避免维度过高导致点积数值过大。
-
注意:
-
dkd_kdk是QQQ 和 KKK 向量的特征个数(QQQ或 KKK矩阵有几列)
在单头注意力里面,如果WQW^QWQ 和 WKW^KWK没有压缩词向量维度的话,dkd_kdk就是词向量的特征个数。但在实际的 Transformer 模型(多头注意力)中,dkd_kdk并不直接等于原始输入词向量的维度(dmodeld_{model}dmodel)。
- 假设我们输入的词向量维度是 dmodel=512d_{model} = 512dmodel=512。
- Transformer 默认使用 8 个注意力头(Multi-Head = 8)。
- 那么为了并行计算,模型会将这 512 维切分成 8 份,分配给 8 个头。
- 所以,每个头里的 QQQ 和 KKK 向量的维度就是:dk=dmodelh=5128=64d_k = \frac{d_{model}}{h} = \frac{512}{8} = 64dk=hdmodel=8512=64。
这里 dkd_kdk 就是 64。它代表了参与每次点积运算的向量的实际长度。
-
除以 dk\sqrt{d_k}dk 是放在数值太大Softmax瞎做
-
Step3: Softmax函数归一化。
-
将相关性得分转化为 0,1 之间且行总和为 1 的概率分布,这就得到了真正的注意力权重。
-
将矩阵的每一行和变成1
Step4: 对样本进行加权求和。
- 将算出的权重矩阵与 VVV 矩阵相乘,完成对上下文信息的复合提取。
核心公式
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dk QKT)V
3.Transformer中的自注意力机制本质
举例一个序列中只有两个样本:A和B
r\mathbf{r}r是Step3: Softmax函数归一化后的结果,即softmax(QKTdk)softmax(\frac{QK^{T}}{\sqrt{d_k}})softmax(dk QKT)。
r=(a11a12a21a22),V=(v11v12v21v22) \mathbf{r} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix}, \quad \mathbf{V} = \begin{pmatrix} v_{11} & v_{12} \\ v_{21} & v_{22} \end{pmatrix} r=(a11a21a12a22),V=(v11v21v12v22)
二者相乘的结果如下:
Z(Attention)=(a11a12a21a22)(v11v12v21v22)=((a11v11+a12v21)(a11v12+a12v22)(a21v11+a22v21)(a21v12+a22v22))) \mathbf{Z(Attention)} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix} \begin{pmatrix} v_{11} & v_{12} \\ v_{21} & v_{22} \end{pmatrix} = \begin{pmatrix} (a_{11}v_{11} + a_{12}v_{21}) & (a_{11}v_{12} + a_{12}v_{22}) \\ (a_{21}v_{11} + a_{22}v_{21}) & (a_{21}v_{12} + a_{22}v_{22})) \end{pmatrix} Z(Attention)=(a11a21a12a22)(v11v21v12v22)=((a11v11+a12v21)(a21v11+a22v21)(a11v12+a12v22)(a21v12+a22v22)))
r的第一行第一列是AA的相关系数,r的第一行第二列是AB相关系数。
r的第二行第一列是BA的相关系数,r的第一行第二列是BB相关系数。
V\mathbf{V}V单纯提取了一下序列,如果WQW^QWQ 和 WKW^KWK压缩了词向量维度,V\mathbf{V}V也跟着压缩一下;V\mathbf{V}V和原始XXX含义上没有区别。
所以,Z(Attention)\mathbf{Z(Attention)}Z(Attention)的每一行,代表着对应样本在融合了全局上下文信息之后,所得到的全新、具备丰富语境的特征向量。本质上就是对原始特征(V\mathbf{V}V)进行了一次加权求和的重构。
如:Z\mathbf{Z}Z 的第一行(代表样本 A 的新特征): 它实际上等于a11v11,v12+a12v21,v22a_{11}v_{11}, v_{12} + a_{12}v_{21}, v_{22}a11v11,v12+a12v21,v22,也就是a11VA+a12VBa_{11}\mathbf{V}A + a{12}\mathbf{V}_Ba11VA+a12VB。
这说明:样本 A 的新特征,是由 A 自己的原始特征(VA\mathbf{V}AVA)和 B 的原始特征(VB\mathbf{V}BVB),按照 A 对它们的"注意力系数(a11,a12a{11}, a{12}a11,a12)"按比例混合而成的。
4. Multi-Head Attention 多头注意力机制
多头注意力(Multi-Head Attention)的核心是使用多组独立参数,让模型在不同的表示子空间里并行捕捉多重语义关系。
模型不仅使用一组 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV,而是并行生成 hhh 组(原论文为8个注意力头)。每组分别计算得到一个提取了特定语义关系的结果矩阵 ZiZ_iZi,最后将所有的 ZiZ_iZi 进行拼接(行数不变,相当于添加特征个数;但一般都会把词向量的特征平分给各个头,所以到最后词向量特征的个数应该没有变),再经过线性层映射,输出更丰富的特征表示。
假设有两个注意力头的例子:
- 头1的输出 Z_1 :
Z1=(z11z12z13z14z15z16) Z_1 = \begin{pmatrix} z_{11} & z_{12} & z_{13} \\ z_{14} & z_{15} & z_{16} \end{pmatrix} Z1=(z11z14z12z15z13z16)
- 头2的输出 Z_2 :
Z2=(z21z22z23z24z25z26) Z_2 = \begin{pmatrix} z_{21} & z_{22} & z_{23} \\ z_{24} & z_{25} & z_{26} \end{pmatrix} Z2=(z21z24z22z25z23z26)
- 拼接操作:
Zconcatenated=(z11z12z13z21z22z23z14z15z16z24z25z26) Z_{\text{concatenated}} = \begin{pmatrix} z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} \\ z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26} \end{pmatrix} Zconcatenated=(z11z14z12z15z13z16z21z24z22z25z23z26)
- MatMul (Matrix Multiplication:矩阵乘法)
- Scale 指的是公式中除以 dk\sqrt{d_k}dk 的这一步操作(dkd_kdk 是 Key 向量的特征维度)
二.Transformer的基本结构
Transformer的总体架构主要由两大核心部分组成:编码器(Encoder)与解码器(Decoder)。
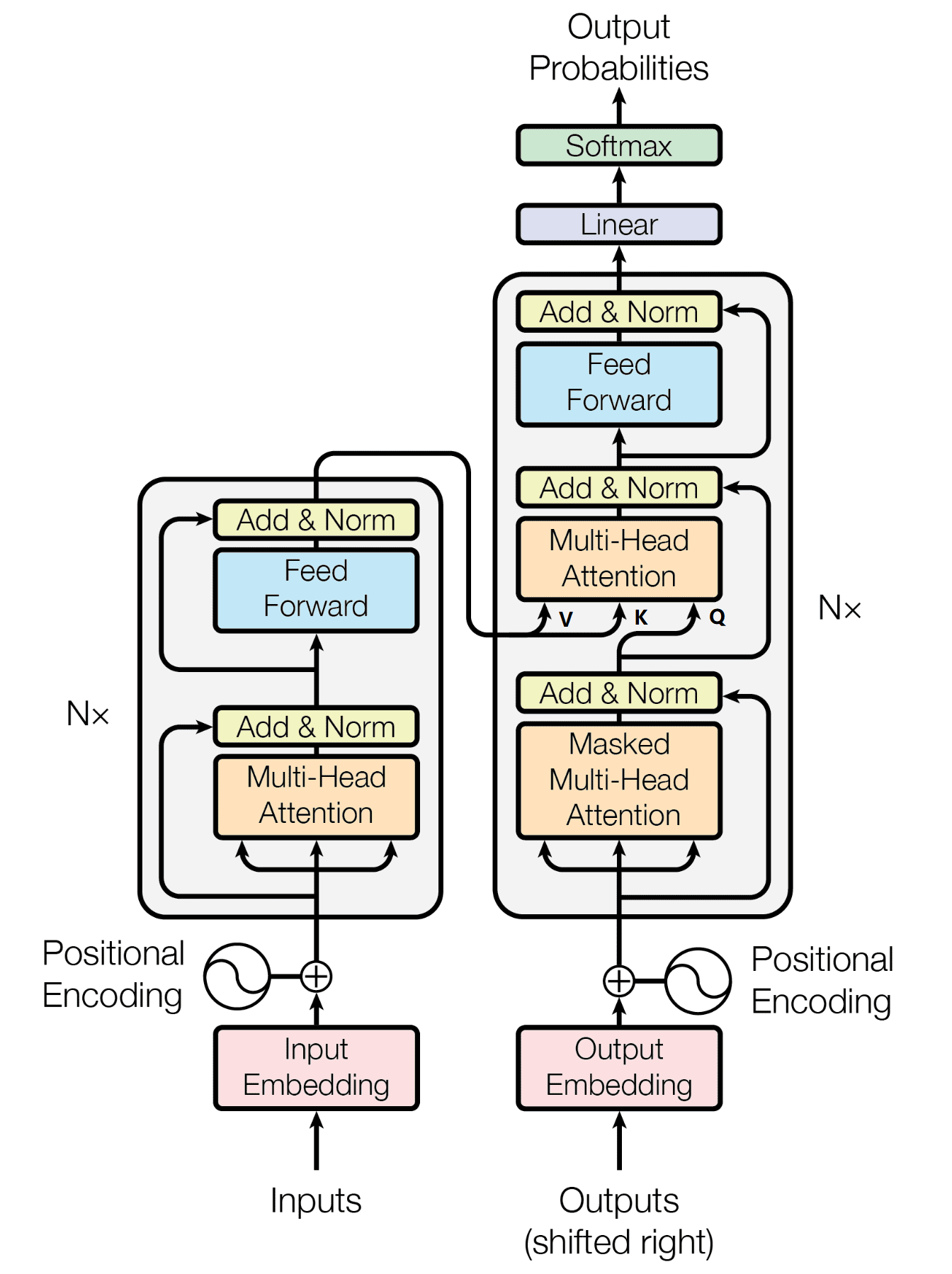
在Transformer中,编码是解读数据的结构,在NLP的流程中,编码器负责解构自然语言、将自然语言转化为计算机能够理解的信息,并让计算机能够学习数据、理解数据;而解码器是将被解读的信息"还原"回原始数据、或者转化为其他类型数据的结构,它可以让算法处理过的数据还原回"自然语言",也可以将算法处理过的数据直接输出成某种结果。
因此在transformer中,编码器负责接收输入数据、负责提取特征,而解码器负责输出最终的标签。当这个标签是自然语言的时候,解码器负责的是"将被处理后的信息还原回自然语言",当这个标签是特定的类别或标签的时候,解码器负责的就是"整合信息输出统一结果"。
1. Embedding层与位置编码技术
在信息进入解码器和编码器之前,我们首先要对信息进行Embedding和Positional Encoding两种编码,这两种编码在实际代码中表现为两个单独的层,因此这两种编码结构也被认为是Transformer结构的一部分。经过编码后,数据会进入编码器Encoder和解码器decoder,其中编码器是架构图上左侧的部分,解码器是架构图上右侧的部分。
(1).Embedding层
位于输入端,负责将离散的符号转化为高维连续向量,捕捉词与词之间的语义相似度。
(2).位置编码(Positional Encoding)
Transforme引入了正余弦位置编码,为每个位置生成独一无二的向量,并将其与Embedding向量直接相加,使模型能够同时感知语义和位置。随后输入到编码器和解码器。
添加位置编码(Positional Encoding),是因为Transformer没有内置的序列顺序信息,也就是说Attention机制本身会带来位置信息的丧失。
①.位置信息为什么重要,从哪里来?
位置信息就是顺序的信息,字符排列的顺序会影响语句的理解(如:屡战屡败和屡败屡战),我们说Transformer丧失了位置信息,意思是transformer并不理解样本与样本之间是按照什么顺序排列的(也就是不知道样本在序列中具体的位置)。
RNN和LSTM以序列的方式处理输入数据,即一个时间步一个时间步地处理输入序列的每个元素。每个时间步的隐藏状态依赖于前一个时间步的隐藏状态。这种机制天然地捕捉了序列的顺序信息。由于RNN和LSTM在处理序列时会保留前一时间步的信息并传递到下一时间步,所以它们能够内在地理解和处理序列的时间依赖关系和顺序信息。然而,与RNN和LSTM不同,Transformer并不以序列的方式逐步处理输入数据,而是一次性处理整个序列。Attention能够通过点积的方式一次性计算出所有向量之间的相关性、并且多头注意力机制中不同的头还可以并行,因此Attention与Transformer缺乏天然的顺序信息。
②.为什么Transformer没有位置信息
相关性计算得到的结构只是相关性,没有位置信息。
Z(Attention)=(a11a12a21a22)(v11v12v21v22)=((a11v11+a12v21)(a11v12+a12v22)(a21v11+a22v21)(a21v12+a22v22))) \mathbf{Z(Attention)} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix} \begin{pmatrix} v_{11} & v_{12} \\ v_{21} & v_{22} \end{pmatrix} = \begin{pmatrix} (a_{11}v_{11} + a_{12}v_{21}) & (a_{11}v_{12} + a_{12}v_{22}) \\ (a_{21}v_{11} + a_{22}v_{21}) & (a_{21}v_{12} + a_{22}v_{22})) \end{pmatrix} Z(Attention)=(a11a21a12a22)(v11v21v12v22)=((a11v11+a12v21)(a21v11+a22v21)(a11v12+a12v22)(a21v12+a22v22)))
这种脚本只是人眼看的,模型计算不知道。
由于Transformer模型放弃了逐行对数据进行处理的方式,而是一次性处理一整张表单,因此它不能直接像循环神经网络RNN那样在训练过程中就捕捉到单词与单词之间的位置信息。
③.位置信息如何被告知给Attention/Transformer
为了解决位置信息的问题,Transformer引入了位置编码(positional encoding)技术来补充语义词嵌入。我们首先将样本的位置转变成相应的数字或向量,然后让位置编码的这个向量被加到原有的词嵌入向量embedding向量上,这样模型就可以同时知道一个词的语义和它在句子中的位置。
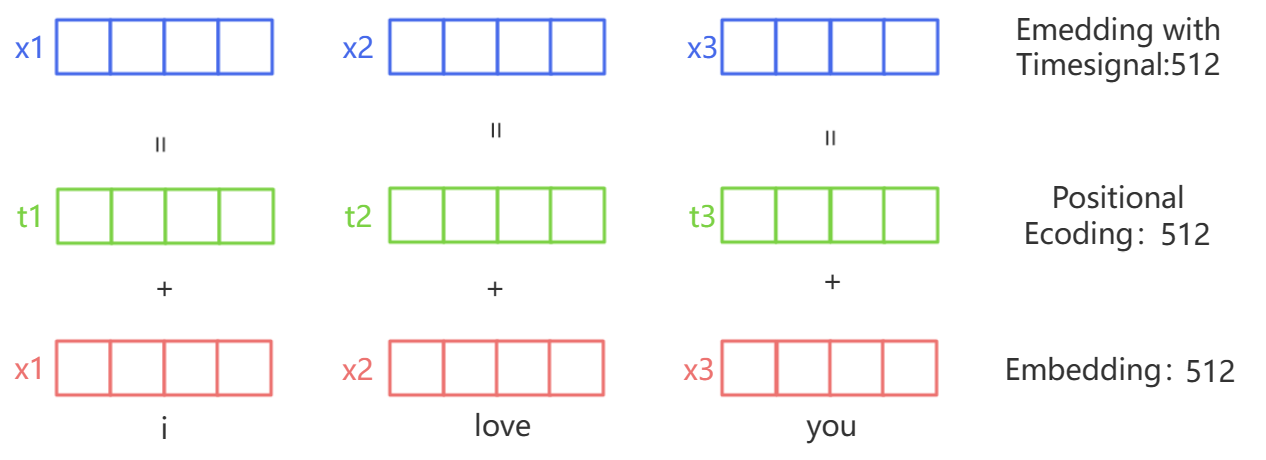
位置编码使用了一种特殊的函数,这个函数会为序列中的每个位置生成一个向量。对于一个特定的位置,这个函数生成的向量在所有维度上的值都是不同的。这保证了每个位置的编码都是唯一的,而且不同位置的编码能够保持一定的相对关系。在transformer的位置编码中,我们需要对每个词的每个特征值给与位置编码,所有这些特征位置的编码共同组合成了一个样本的位置编码。
例如,当一个样本拥有4个特征时,我们的位置编码也会是包含4个数字的一个向量,而不是一个单独的编码。因此,位置编码矩阵是一个与embedding后的矩阵结构相同的矩阵。
在Transformer模型中,词嵌入和位置编码被相加,然后输入到模型的第一层。这样,Transformer就可以同时处理词语的语义和它在句子中的位置信息。这也是Transformer模型在处理序列数据,特别是自然语言处理任务中表现出色的一个重要原因。
④.Transformer中的正余弦位置编码
正余弦编码是使用正弦函数和余弦函数来生成具体编码值的编码方式。对于任意的词向量(也就是数据中的一个样本),正余弦编码在偶数维度上采用了sin函数来编码,奇数维度采用了cos函数来编码,sin函数与cos函数交替使用,最终构成一个多维度的向量。
通过对不同的维度进行不同的三角函数编码,来构成一串独一无二的编码组合。这种编码组合与embedding类似,都是将信息投射到一个高维空间当中,只不过正余弦编码是将样本的位置信息(也就是样本的索引)投射到高维空间中,且每一个特征的维度代表了这个高维空间中的一维度。对正余弦编码来说,编码数字本身是依赖于样本的位置信息(索引)、所有维度的编号、以及总维度数三个因子计算出来的。
公式:
-
正弦位置编码(Sinusoidal Positional Encoding)
PE(pos,2i)=sin(pos100002idmodel)PE_{(pos, 2i)} = \sin \left( \frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}} \right)PE(pos,2i)=sin(10000dmodel2ipos)
-
余弦位置编码(Cosine Positional Encoding)
PE(pos,2i+1)=cos(pos100002idmodel)PE_{(pos, 2i+1)} = \cos \left( \frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}} \right)PE(pos,2i+1)=cos(10000dmodel2ipos)
参数:
-
pos代表样本在序列中的位置,也就是样本的索引(是三维度中的seq_len/time_step这个维度上的索引)
-
2i2i2i和2i+12i+12i+1分别代表embedding矩阵中的偶数和奇数维度索引(即: Embedding层输出的词向量的特征维度索引),当我们让i从0开始循环增长时,可以获得0,1,2,3,4,5,6...这样的序列。
-
d_{\\text{model}} 代表embedding后矩阵的总维度(即: Embedding层输出的词向量的特征数量)。
⑤.正余弦编码的意义
-
sin和cos函数值域有限,可以很好地限制位置编码的数字大小。
-
通过调节频率,我们可以得到多种多样的sin和cos函数,从而可以将位置信息投射到每个维度都各具特色、各不相同的高维空间,以形成对位置信息的更好的表示。即:各个特征维度用不同的三角函数。
-
通过独特的计算公式,我们可以让特征编号小的特征被投射到剧烈变化的维度上,并且让特征编号大的特征被投射到轻微变化、甚至完全单调的维度上;从而可以让小编号特征去捕捉样本之间的局部细节差异,让大编号特征去捕捉样本之间按顺序排列的全局趋势。
i{i}i越大,1100002idmodel\frac{1}{10000^{\frac{2i}{d_{\text{model}}}}}10000dmodel2i1 越大,三角函数频率越小,震荡越平缓。
不同特征维度iii的效果:
- 当 i 很小(维度靠前)时: 频率很高,波长很短。位置 pos 哪怕只移动一点点,函数值就会剧烈震荡。
- 当 i 很大(维度靠后)时: 频率极低,波长极长。即使位置 pos 变化很大,函数值也只会在周期内发生非常微弱平缓的改变。
-
其他好处
-
函数的周期性带来泛化性 :在模型训练过程中,我们可能使用的都是序列长度小于20的数据,但是当实际应用中遇到一个序列长度为50的数据,正弦和余弦函数的周期性意味着,即使模型在训练时未见过某个位置,它仍然可以生成一个合理的位置编码。它可用泛化到不同长度的序列。
-
不增加额外的训练参数:当我们在一个已经很大的模型(如 GPT-3 或 BERT}上添加位置信息时,我们不希望增加太多的参数,因为这会增加训练成本和过拟合的风险。正弦和余弦位置编码不增加任何训练参数。
-
即便是相同频率下的正余弦函数,也可以通过周期性带来部分的相对位置信息,可以比绝对位置信息更有效:正弦和余弦函数的周期性特征为模型提供了一种隐含的相对位置信息,使得模型能够更有效地理解序列中不同位置之间的相对关系。
-
2. Encoder(编码器)结构
Encoder作用是解构自然语言,将其转换为深层特征。
编码器(Encoder)结构包括两个子层:一个是多头的自注意力(Self-Attention)层,另一个是前馈(Feed-Forward)神经网络。
输入数据会先经过自注意力层,这层的作用是为输入数据中不同的信息赋予重要性的权重、让模型知道哪些信息是关键且重要的。接着,这些信息会经过前馈神经网络层,这是一个简单的全连接神经网络,用于将多头注意力机制中输出的信息进行整合。两个子层都被武装了一个残差连接(Residual Connection),这两个层输出的结果都会有残差链接上的结果相加,再经过一个层标准化(Layer Normalization),才算是得到真正的输出。在神经网络中,多头注意力机制+前馈网络的结构可以有很多层,在Transformer的经典结构中,encoder结构重复了6层。
最后一个encoder结构,会将矩阵传给每一个decoder结构。
每个Encoder块包含多头自注意力层和前馈网络,同时配置了如下关键组件:
(1).残差连接
残差连接(Residual Connection)是将子层的输入直接跨层累加到输出上的技术,输入输出矩阵形状一样,直接对应元素相加。 数学上体现为带有"1+"的梯度传递路径。它可以极其有效地避免深度神经网络中的梯度消失现象,提升模型训练的稳定性和效率。
(2).Layer Normalization层归一化
不同于针对批次归一化(BatchNorm),层归一化(LayerNorm)是独立对每个样本自身的所有特征维度进行归一化。 它在残差相加后执行,能够有效减轻内部协方差偏移(ICS),加速模型收敛,非常适合变化长度的文本序列任务。
(batch_size, seq_len, input_dimensions)
-
BatchNorm在batch_size维度上对每一个特征进行归一化。
具体计算方法:把这batch_size个句子中所有的词的每一个特征维特征全部抽出来,算出一个均值和方差,然后对这所有词的这一维度进行归一化。
-
LayerNorm在seq_len维度上对每一个样本进行归一化。
具体计算方法:单独拿出第每个句子的每一个词,将它自己的所有维度特征作为一个独立体,计算所有维度的均值和方差进行归一化。每个词、每个句子都是完全独立计算的,互不干扰。
各类Normalization的本质(了解即可)
LN是Normalization(规范化)家族中的一员,由Batch Normalization(BN)发展而来。
基本上所有的规范化技术,都可以概括为如下的公式:
hi=f(ai)hi′=f(giσi(ai−ui)+bi)h_i = f(a_i) {h_i}^{'}=f(\frac{g_i}{\sigma_i}(a_i-u_i)+b_i)hi=f(ai)hi′=f(σigi(ai−ui)+bi)
这个公式描述了Normalization技术中对于单个数据点aia_iai在某一层的激活值进行规范化的过程。这里是每个符号的含义:
- aia_iai :原始神经网络层的激活值或输出。
- fff :应用于规范化之后的值的激活函数。
- hih_ihi :应用激活函数 fff 之后的激活值,是规范化步骤之前的输出。
- hi′h_i'hi′ :最终的规范化输出值。
- σi\sigma_iσi :用于规范化过程中的尺度调整的标准差。
- uiu_iui :平均值。
- gig_igi :尺度参数。
- bib_ibi :偏置参数。
对于隐层中某个节点的输出为对激活值aia_iai 进行非线性变换f()f()f() 后的 hih_ihi先使用均值uiu_iui和方差 σi\sigma_iσi对aia_iai 进行分布调整。
如果以正态分布为例,就是把"高瘦"(红色}和"矮胖"(蓝紫色}的都调整回正常体型(绿色},把偏离y=0的(紫色}拉回中间来。
- 这样可以将每一次迭代的数据调整为相同分布,消除极端值,提升训练稳定性。
- 同时"平移"操作,可以让激活值落入f()f()f()的梯度敏感区间即梯度更新幅度变大,模型训练加快。
然而,在梯度敏感区内,隐层的输出接近于"线性",模型表达能力会大幅度下降。引入 gain 因子gig_igi 和 bias 因子 bib_ibi,为规范化后的分布再加入一点"个性"。
注: gig_igi和bib_ibi作为模型参数训练得到,uiu_iui和 σi\sigma_iσi在限定的数据范围内统计得到。
(3).Feed-Forward Networks前馈网络
所有单向传输数据的网络都是前馈网络
Transformer中的前馈网络是一个附加在每个注意力子层之后的两层全连接神经网络。前馈网络的作用是将多头注意力提取到的全局相关信息进行进一步的非线性融合与映射,强化模型对于复杂语义逻辑的拟合能力。
在现代深度学习架构中,特别是在Transformer模型中,前馈网络由两个线性变换组成,中间夹有一个激活函数,如ReLU或者GELU。具体结构可以表示为:
-
第一层线性变换:
z_1 = xW_1 + b_1
- xxx 是输入向量。
- W1W_1W1 和 b1b_1b1 是第一层的权重矩阵和偏置向量。
-
ReLU激活函数:
a_1 = \\text{ReLU}(z_1) = \\max(0, z_1)
- ReLU的作用是引入非线性,使得网络能够学习更复杂的函数映射。
- ReLU函数将输入中的负值置为零,正值保持不变。
-
第二层线性变换:
z_2 = a_1W_2 + b_2
- a1a_1a1 是经过ReLU激活后的中间表示。
- W2W_2W2 和 b2b_2b2 是第二层的权重矩阵和偏置向量。
- 最终输出 z2z_2z2 是前馈神经网络的输出。
合起来,前馈神经网络的完整表达式为: FFN(x)=max(0,xW1+b1)W2+b2 FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
(4).Encoder作用
Encoder作用是将输入序列转换为一系列语义表示,以便后续任务的处理和预测。
Encoder在最后使用的前馈神经网络可以说是以线性层结尾,它本身有激活函数,可以产生输出,因此Encoder编码器部分是可以单独使用的结构。在许多情况下,我们可以单独使用 Encoder 的输出来执行各种任务,而不需要 Decoder 解码器部分,下面是一些经典的场景
encoder走位特征提取器 :Encoder 的输出可以用作特征提取器,将输入序列转换为一系列有意义的特征表示。这些特征表示可以用于各种机器学习任务,如分类、聚类、序列标注等。
encoder生成类似autoencoder的语义表示 :Encoder 的输出可以被用来获取输入序列的语义表示。这些语义表示可以用于进行语义相似度计算、文本匹配、信息检索等自然语言处理任务。
序列到序列任务的编码器 :在一些序列到序列任务中,只需要对输入序列进行编码,而不需要生成输出序列。例如,文本摘要、问答系统中,只需将输入文本编码为一个语义表示,而无需生成摘要或答案。
预训练模型的基础部分:许多预训练模型,如BERT(Bidirectional Encoder Representations from Transformers}等,基于 Transformer Encoder 架构。在这些模型中,Encoder 的输出可以被用作下游任务的输入,从而提供丰富的语义信息。
具体地来说,有许多任务可以仅使用 Encoder 完成。以下是一些常见的例子:
情感分析 :情感分析任务旨在确定文本的情感倾向,如正面、负面或中性。在这种任务中,我们只需将输入文本编码为一个语义表示,然后通过该表示来预测文本的情感倾向,而不需要生成任何文本输出。
文本分类 :文本分类任务要求将文本分配到预定义的类别中。例如,垃圾邮件过滤、新闻分类等。在这种任务中,我们可以使用 Encoder 将输入文本编码为一个语义表示,然后通过该表示来进行分类预测。
命名实体识别 :命名实体识别任务要求在文本中识别和分类命名实体,如人名、地名、组织名等。在这种任务中,我们可以使用 Encoder 将输入文本编码为一个语义表示,然后通过该表示来对命名实体进行识别。
关系抽取 :关系抽取任务旨在从文本中提取实体之间的关系。例如,在医学文本中,从病历中抽取药物与疾病之间的关系。在这种任务中,我们可以使用 Encoder 将输入文本编码为一个语义表示,然后通过该表示来提取实体之间的关系。
文本生成的预训练:在预训练语言模型中,我们可以使用 Encoder 将输入文本编码为一个语义表示,然后利用这个语义表示来预测下一个词或者生成文本序列。这在自然语言生成任务中非常有用,如对话生成、摘要生成等。
3. Decoder(解码器)结构
解码器(Decoder)也是由多个子层构成的:第一个也是多头的自注意力层(此时由于解码器本身的性质问题,这里的多头注意力层携带掩码),第二个子层是普通的多头注意力机制层,第三个层是前馈神经网络。自注意力层和前馈神经网络的结构与编码器中的相同。注意力层是用来关注编码器输出的。同样的,每个子层都有一个残差连接和层标准化。在经典的Transformer结构中,Decoder也有6层。
(1).完整Transformer与Decoder-Only结构的数据流
-
完整Transformer:Encoder 提取输入特征,将其传递给 Decoder;Decoder 结合之前已生成的输出与 Encoder 传来的特征,自回归地预测出下一个结果。
使用完整Transformer结构的任务:完整的Transformer结构通常用于需要将一个序列映射到另一个序列的任务,如:
-
机器翻译(Machine Translation}:
- 将源语言的句子翻译成目标语言的句子。例如将英文句子翻译成中文句子。
-
文本摘要(text Summarization}:
- 将长文本总结为简短的摘要,例如将新闻文章总结为简短的新闻标题。
-
图像字幕生成(Image Captioning}:
- 为给定的图像生成描述性的文字(图生文}
-
文本到语音(text-to-Speech, TTS}:
- 将文本转换为语音信号,比如将输入文本转换为自然的语音输出。
-
问答系统(Question Answering}:
- 根据上下文回答用户的问题,或者给定一段文本,回答其中提到的具体问题。
-
-
Decoder-Only结构:舍弃了 Encoder 环节,将输入上下文直接喂给 Decoder 处理,凭借极强的大规模预训练泛化能力完成所有理解与生成任务。
只使用decoder结构的任务:(通常被称为自回归模型或生成模型}适用于需要从部分输入生成完整序列的任务,如:
-
大语言模型(Language Modeling}:
- 任务描述:预测给定文本序列中的下一个词或字符,例如GPT系列模型用于生成连续的文本段落(当然,并不是所有的大语言模型都是decoder-only结构}。
-
文本生成(text Generation}:
- 任务描述:根据部分输入生成完整的文本,比如根据开头的一句话生成一篇文章或故事,根据部分诗句生成完整的诗歌。
-
代码补全(Code Completion}:
- 任务描述:根据部分输入代码生成完整的代码段。
-
对话生成(Dialogue Generation}:
- 任务描述:根据对话历史生成下一句回复。
-
问答系统(Question Answering}:
- 根据上下文回答用户的问题,或者给定一段文本,回答其中提到的具体问题。
这些任务利用Transformer的强大表示能力,通过不同的结构来适应不同的应用场景。完整的Transformer结构适合需要从一个序列转换到另一个序列的任务 ,一般我们会在需要高度依赖原始数据信息、尤其是需要语义的转译 的时候使用这种结构,因为Encoder会有非常好的语义和数据信息解析功能,可以帮助架构更好地吸收原始数据的信息;而只使用decoder结构的模型适合需要生成连续序列的任务,当我们更强调基于原有的信息基础上进行"创新、创造、续写",而对原有的数据的依赖程度不是那么高时,我们会选择decoder-only结构。
-
与Encoder不同的是,Decoder结构在不同的任务中承担不同的角色、存在不同的网络架构、不同的训练模式以及不同的数据流,因此我们需要理解不同的任务、才能知道Decoder结构究竟是什么样的。接下来,就让我来看看Transformer完整结构与Decoder-only结构下的具体情况。
(2).Encoder-Decoder结构中的Decoder
①.输入与teacher forcing
Decoder的输入是滞后1个单位的标签矩阵,我们要将真实标签输入给模型,并且让真实标签指导模型的学习与预测,这种让模型通过正确的标签来学习的流程在Transformer中被称之为是teacher forcing强制教学机制。
为了让 Decoder 在训练时也能高度并行化,也就是不让模型苦等上一步自己的预测结果,而是直接将真实的前置目标序列(标签)一次性输入进 Decoder,加速网络整体的迭代训练。
######<1>.shift right操作
首先,在序列到序列任务中,我们会将标签矩阵进行滞后操作(shift)。
pythonimport pandas as pd # 创建DataFrame df = pd.DataFrame({ "值": [0.1543, 0.2731, 0.3627, 0.4812, 0.5238] }) print(df) # 值 # 0 0.1543 # 1 0.2731 # 2 0.3627 # 3 0.4812 # 4 0.5238 print(df.shift(1)) #挪动一个位置,被叫做滞后1 # 值 # 0 NaN # 1 0.1543 # 2 0.2731 # 3 0.3627 # 4 0.4812当表现为编码前的序列时,就是从y1, y2, y3, y4变成NaN, y1, y2, y3, y4,因此这个过程也被叫做"向右滞后"(shift right),其实代表的是在序列的最前方腾挪出位置,将已有的序列向后挤。
<2>.起始和结束标记
起始标记(Start of Sequence,SOS)和结束标记(End of Sequence,EOS)在序列到序列(Seq2Seq)任务中起着重要的作用,特别是在自然语言处理(NLP)和机器翻译等任务中。
**在Transformer当中,我们一般会为解码器的输入标签添加起始标记"SOS"(start of sequence),并将这个起始标记作为标签序列的第一行,**最终构成"sos", y1, y2, y3, y4这样的序列。当进行embedding编码后,会呈现为
输入Decoder
标签矩阵
索引 y1 y2 y3 y4 y5 0 "sos" 0.5651 0.2220 0.5112 0.8543 0.1239 1 It 0.5621 0.8920 0.7312 0.2543 0.1289 2 was 0.2314 0.6794 0.9823 0.8452 0.3417 3 the 0.4932 0.2045 0.7531 0.6582 0.9731 4 best 0.8342 0.2987 0.7642 0.2154 0.9812 5 of 0.3417 0.5792 0.4821 0.6721 0.1234 6 times 0.2531 0.7345 0.9812 0.5487 0.2378 7 it 0.6523 0.1298 0.4576 0.9834 0.1876 8 was 0.2314 0.6794 0.9823 0.8452 0.3417 9 the 0.4932 0.2045 0.7531 0.6582 0.9731 10 worst 0.1543 0.9271 0.3821 0.6745 0.4823 11 of 0.3417 0.5792 0.4821 0.6721 0.1234 12 times 0.2531 0.7345 0.9812 0.5487 0.2378
起始标记(SOS)
- 标识序列的开始:SOS标记用于指示解码器开始生成序列。这在训练和推理过程中都非常重要。
- 初始化解码器:在解码阶段,解码器需要一个初始输入来开始生成输出序列。SOS标记作为解码器的第一个输入,帮助其启动生成过程。
- 模型一致性:通过在每个输出序列的开头添加SOS标记,模型在训练时可以学到序列生成的起点,从而在推理时保持一致的生成过程。
结束标记(EOS)
- 标识序列的结束:EOS标记用于指示生成的序列在何处结束。这对于模型在推理阶段停止生成非常重要。
- 控制生成长度:在没有固定长度的输出序列中,EOS标记告诉模型何时停止生成,而不需要生成固定数量的时间步。这使得模型可以处理变长序列。
- 训练终止条件:在训练过程中,模型学会在适当的时候生成EOS标记,从而正确地结束序列。
示例:
假设我们有一个输入序列和一个目标序列:
- 输入序列:
x = ["这", "是", "最", "好", "的", "时", "代"]- 目标序列:
y = ["it", "was", "the", "best", "of", "times"]在Seq2Seq任务的训练过程中,由于Decoder结构会需要输入标签,因此我们必须要准备三种不同的数据,并进行如下的处理:
- 编码器输入 :
x不需要添加起始标记和结束标记。- 解码器输入的标签:在目标序列前添加起始标记(SOS)。
- 解码器用来计算损失函数的标签:在目标序列末尾添加结束标记(EOS)。
处理后的序列就是:
- 编码器输入 :
["这", "是", "最", "好", "的", "时", "代"]- 解码器输入的标签 :
["SOS", "it", "was", "the", "best", "of", "times"]- 解码器用来计算损失函数的标签 :
["it", "was", "the", "best", "of", "times", "EOS"]
pythonimport torch import torch.nn as nn # 假设词汇表大小(包括特殊标记如SOS和EOS) vocab_size = 10 embedding_dim = 4 # 创建嵌入层 embedding_layer = nn.Embedding(vocab_size, embedding_dim) # 假设索引0是SOS,索引1是EOS SOS_token = 0 EOS_token = 1 # 目标序列的索引表示 target_sequence = [2, 3, 4, 5, 6] # 假设 "it", "was", "the", "best", "of" # 添加起始标记和结束标记 decoder_input = [SOS_token] + target_sequence decoder_output = target_sequence + [EOS_token] # 转换为张量 decoder_input_tensor = torch.tensor(decoder_input) decoder_output_tensor = torch.tensor(decoder_output) # 嵌入 embedded_decoder_input = embedding_layer(decoder_input_tensor) embedded_decoder_output = embedding_layer(decoder_output_tensor) print("Decoder Input (with SOS):", decoder_input_tensor) print("Decoder Output (with EOS):", decoder_output_tensor) print("Embedded Decoder Input:", embedded_decoder_input) print("Embedded Decoder Output:", embedded_decoder_output) # Decoder Input (with SOS): tensor([0, 2, 3, 4, 5, 6]) # Decoder Output (with EOS): tensor([2, 3, 4, 5, 6, 1]) # Embedded Decoder Input: tensor([[ 3.7656e-01, 8.9443e-01, -1.7710e-01, 1.4129e-01], # [-1.7985e+00, -1.0696e+00, 6.0779e-01, -1.4262e-01], # [-4.0414e-01, -4.4272e-01, 6.7027e-01, 1.7571e-01], # [ 1.3312e-01, 7.0182e-01, -1.7120e-03, -7.6345e-01], # [-2.5154e+00, 2.9685e-01, -2.8418e-02, -1.2903e+00], # [-6.9068e-01, 1.5934e+00, 8.2624e-02, -7.7207e-01]], # grad_fn=<EmbeddingBackward0>) # Embedded Decoder Output: tensor([[-1.7985e+00, -1.0696e+00, 6.0779e-01, -1.4262e-01], # [-4.0414e-01, -4.4272e-01, 6.7027e-01, 1.7571e-01], # [ 1.3312e-01, 7.0182e-01, -1.7120e-03, -7.6345e-01], # [-2.5154e+00, 2.9685e-01, -2.8418e-02, -1.2903e+00], # [-6.9068e-01, 1.5934e+00, 8.2624e-02, -7.7207e-01], # [-1.1910e+00, 3.3363e-01, -5.7365e-01, 1.4855e+00]], # grad_fn=<EmbeddingBackward0>)
<3>.teacher forcing
在序列模型的预测(比如时间序列的预测),有很多使用真实标签+特征一起来指导模型学习的操作;例如,时间序列中存在"带标签的滑窗"技术。"带标签的滑窗"是一种特征矩阵构建方法,它会将可以使用的那部分标签作为其中一个特征,和其他特征concat在一起构建特征矩阵。使用带标签的滑窗后,特征信息与标签信息会一起被输入给模型,模型将会结合特征和可使用的标签两部分信息来共同决策。像股票预测。
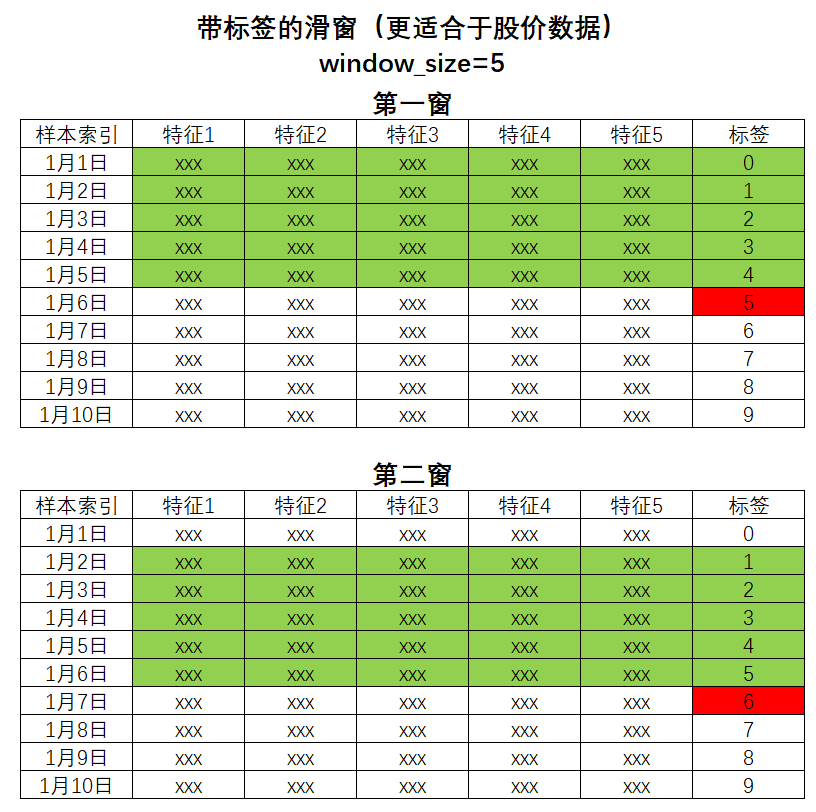
在Transformer中,这种对标签的使用从时间序列数据扩大到了任意序列数据(对时间数据而言,可使用的标签就是当前预测时间点之前所有的时间点;对文字数据,可使用的标签就是当前预测的文字位置之前的所有文字),并且将这种技巧从时间序列预测拓展到了序列到序列任务(seq2seq)。
**注意:时间序列任务是一种使用过去的信息来预测未来的任务,通常是利用一个序列的前半段数据来预测同一序列的后半段数据。这意味着时间序列预测更多地依赖于生成式模型,旨在根据已有数据生成未来的数据点。而Seq2Seq任务(序列到序列任务)并不总是遵循这种模式。**例如,在机器翻译任务中,模型的目标是将一个语言的句子转换成另一种语言的句子,这并不是通过预测同一序列的未来部分来实现的。因此,时间序列预测更接近于生成式任务,而不是典型的序列到序列任务。
-
时间序列任务/生成式任务:同一张表、过去预测未来
时间点 值 1 0.1543 2 0.2731 3 0.3627 4 0.4812 5 0.5238 -
Encoder-decoder下的seq2seq任务:两个序列大概率不是一张表,是用一张表去预测另一张表
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | |
因此在teacher force使用标签是需要将特征矩阵和标签矩阵的信息融合后再进行训练。以上面两张表单为例,设
原始序列x = "这","是","最","好","的","时","代"
真实标签y = "it", "was", "the", "best", "of", "times"
编码器输出的预测结果为yhat,添加过初始词/结束词、经过embedding的矩阵为ebd_X和ebd_y
那我们实际走的训练流程是:
第一步,输入ebd_X & ebd_y0 >> 输出yhat0,对应真实标签y0
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|--------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |第二步,输入ebd_X & ebd_y:1 >> 输出yhat1,对应真实标签y1
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|--------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |第三步,输入ebd_X & ebd_y:2 >> 输出yhat2,对应真实标签y2
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|--------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |......以此类推下去。
==在这个流程中实现了【利用序列A(真实) + 序列B(真实)的前半段预测序列B的后半段】,这样的方式既没有泄露真实的标签,又能够为预测下一个词提供最大程度的准确的信息,这就是teacher forcing的本质。==在训练过程中,这个流程通过掩码自注意力机制+编码器-解码器注意力层合作的方式实现了并行,所以Seq2Seq任务在训练时实际上并不是按照时间步顺序来运行,反而呈现为一次性输入特征矩阵+标签矩阵后,一次性获得整个预测的序列。
然而在测试和推理过程中可就不一样。在测试和推理的过程中,我们并没有真实的标签矩阵,因此需要将上一个时间步预测的结果作为Decoder需要的输入。具体来看,在测试流程中:
第一步,输入 ebd_X & sos >> 输出时间步1的预测标签,对应真实标签y0
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | ➕ | 输入Decoder sos编码序列 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | ||-----------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|---------------------------------------------------------------------------------------------------------------------------------------------------|
| 预测出 ➡ | 当前时间步的 预测标签 yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|------|--------|--------|--------|--------|--------| | 1 | yhat | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 对应 ➡ | 真实标签 y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |第二步,输入ebd_X & yhat:1 >> 输出时间步2的标签,对应真实标签y1
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | ➕ | 输入Decoder:yhat预测标签 (加入上一个时间步的预测结果) | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | yhat | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | ||-----------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|---------------------------------------------------------------------------------------------------------------------------------------------------|
| 预测出 ➡ | 当前时间步的 预测标签 yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|------|--------|--------|--------|--------|--------| | 2 | yhat | 0.3074 | 0.8774 | 0.0364 | 0.0649 | 0.4704 | | 对应 ➡ | 真实标签 y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |第三步,输入ebd_X & yhat:2 >> 输出索引为3的标签,对应真实标签y1
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | ➕ | 输入Decoder:yhat预测标签 (加入上一个时间步的预测结果) | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | yhat | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | yhat | 0.3074 | 0.8774 | 0.0364 | 0.0649 | 0.4704 | ||-----------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|---------------------------------------------------------------------------------------------------------------------------------------------------|
| 预测出 ➡ | 当前时间步的 预测标签 yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|------|--------|--------|--------|--------|--------| | 3 | yhat | 0.2753 | 0.2921 | 0.4599 | 0.6449 | 0.1852 | | 对应 ➡ | 真实标签 y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |**这是一个自回归的流程。在实际代码实现时,这个过程是线性的、必须按照一个字、一个字的方式来预测,但Transformer本身并不提供像RNN和LSTM那样逐步处理样本的结构,因此推理流程中,我们需要写循环代码来完成推理的过程。每一步生成一个新词,并将其作为输入添加到序列中,直到生成结束标记 "EOS" 或达到最大长度为止。**这个流程会极大地限制生成类算法的预测速度,因此现在也有越来越多的技术来帮助我们改进这个环节,但是使用最多的依然是最经典的自回归策略。
②.Embedding与位置编码
同Encoder
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | | x1 | x2 | x3 | x4 | x5 | |-----|--------|--------|--------|--------|--------| | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 也 | 0.1032 | 0.1477 | 0.7023 | 0.7224 | 0.2768 | | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 最坏的 | 0.4263 | 0.4615 | 0.5169 | 0.7584 | 0.8388 | | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | | y1 | y2 | y3 | y4 | y5 | |-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------|--------|--------|--------| | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | it | 0.6523 | 0.1298 | 0.4576 | 0.9834 | 0.1876 | | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | the | 假设是英文翻译成中文的机器翻译任务,为了表达相同的语义,英文句子长度与中文句子长度都应该不受限制,尽量精准地表达;不同语言、不用序列之间的规律本来就各不相同,有的语言比较高效、有的语言则追求尽量详尽。 注意:输入到Decoder层中的sequence_length维度可以与输入到Encoder中的sequence_length维度不一致,但input_dimensions必须一样。 | |