定义
静态量化通常指在模型部署前,先用一批代表性校准数据统计各层激活值的范围,然后固定量化参数,把模型的权重和激活值从浮点数(如 FP32)转换为低精度整数(如 INT8)进行推理的方法。
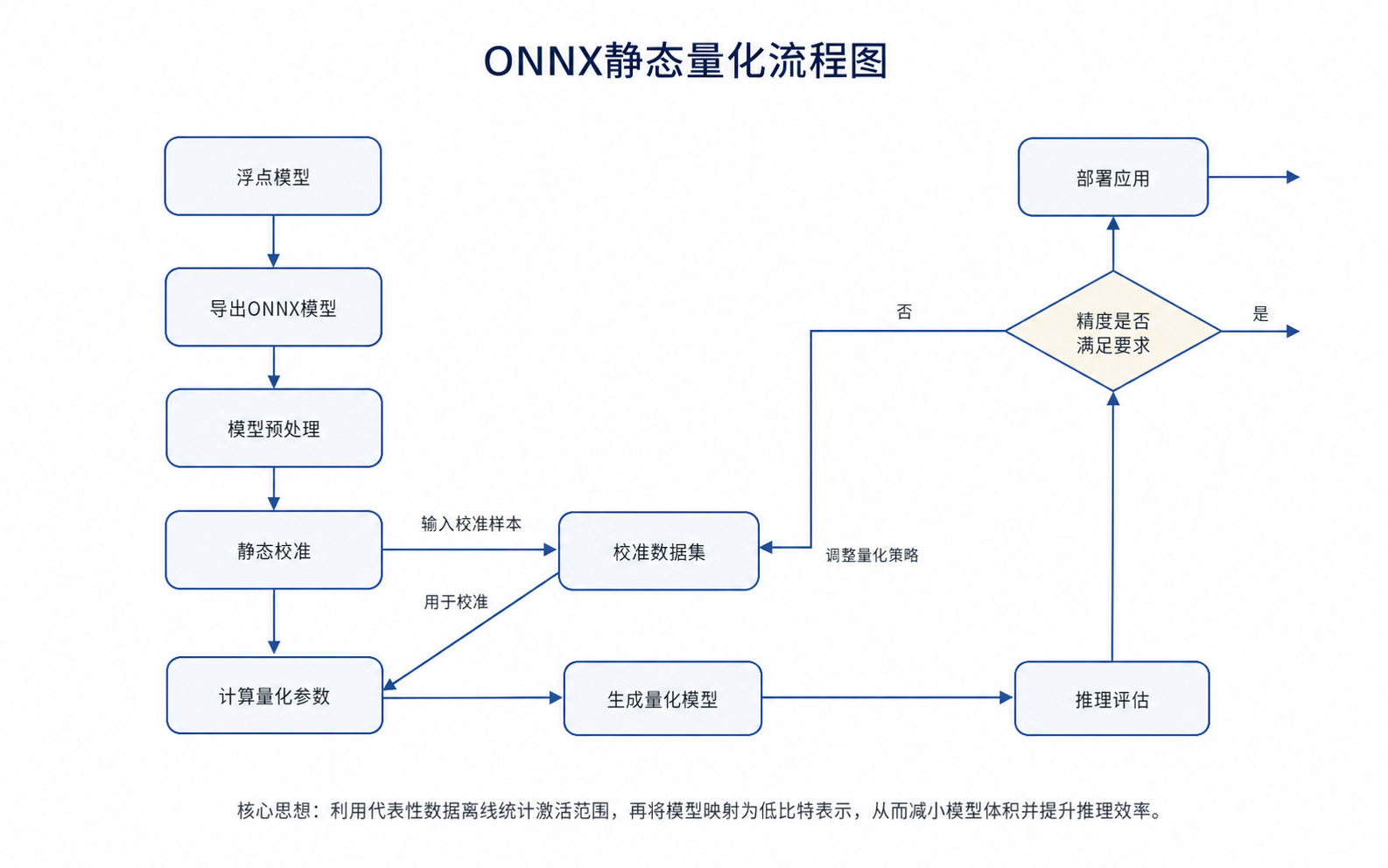
步骤
导出ONNX-FP32模型 → 模型预处理 → 校准数据集 → 静态校准 → 计算量化参数 → 生成 INT8 ONNX → ONNX Runtime 推理评估 → 精度满足则部署,不满足则回调策略
获取onnx计算图--model.graph
计算图就是把一次模型表示为"节点和边"的图结构,由于yolo、pytorch等主流平台导出的文件都各不相同,为了方便模型的评估优化,因此提出了计算图的概念以统一各个主流平台在模型计算过程中的结构化表示。
import onnx model = onnx.load("model.onnx") print(model.graph)计算图中通常有:
graph.input 模型输入
graph.output 模型输出
graph.node 所有计算节点/算子
graph.initializer 权重、bias、常量参数
graph.value_info 中间 tensor 的 shape/type 信息
量化中有一些常见的图类:训练图、推理图、优化图等,其实本质都是计算图,训练图表示在训练中的计算图,推理图表示在推理过程中使用的计算图,而优化图便是模型优化后的计算图。
模型输入--model.graph.input
import onnx model = onnx.load("model.onnx") graph = model.graph print(graph.input)模型的输入包含模型真正的输入,比如图像、token、时间序列等,同时也包含了模型的权重参数
模型权重参数--model.graph.initializer
import onnx model = onnx.load("model.onnx") graph = model.graph print(graph.initializer)model.graph.initializer中包含了模型的所有权重参数等,这个常常与上面的模型输入结合来输出模型真正的输入参数
model = onnx.load(str(onnx_path)) graph_inputs = {value.name for value in model.graph.input} # 获取onnx计算图里的所有的input名字 initializers = {value.name for value in model.graph.initializer} # 获取onnx模型里的所有initializer名字 real_inputs = sorted(graph_inputs - initializers) # 出去本身initializer得出的input参数
模型算子--model.graph.node
import onnx model = onnx.load("model.onnx") graph = model.graph for i, node in enumerate(model.graph.node): print(i) print("name:", node.name) # 名字 print("op_type:", node.op_type) # 类型 print("input:", node.input) # 输入 print("output:", node.output) # 输出 print()其可以用来查看模型有那些算子、检测是否有不支持的算子同时分析模型计算图连接关系,同时也可以检测伪量化节点用以判断量化是否成功。
yolo静态量化
首先需要训练一个yolo模型,这里的是一个yolo-obb模型。
转化为onnx-fp32模型
通常将yolo训练好后直接保存的模型pt文件中,即包含模型的结构,同时也包含了模型的权重、参数等,因此直接加载模型,然后使用model.export进行转化。
model = YOLO(str(model_path)) exported_path = model.export( format="onnx", imgsz=imgsz, opset=opset, simplify=simplify, batch=batch, nms=False )
model.export
该函数是yolo的导出接口,可以将yolo导出为不同格式的文件,由于参数过多,挑几个较为重要的参数进行说明。
使用 Ultralytics YOLO 进行模型导出 | Ultralytics 文档
format:导出格式
imgsz:导出时模型输入尺寸
opset:ONNX opset版本,用以决定导出的ONNX算子版本,需要注意的是如果后续需要转化为其他格式(如rknn、ncnn等)时,注意其对那个版本的ONNX算子兼容
simplify:是否使用
onnxslim简化 ONNX 导出的模型图,简化后要验证输出一致batch:导出时的批量处理大小
nms:在受支持时为导出模型添加非极大值抑制,一般不用于端侧部署
创建校准数据读取器
将转化好的onnx-fp32保存,然后处理校准图像集。构建一个图像批次迭代器,将图像分为每一张一个批次,对图像进行预处理,同时将每一个批次的图像按照图像的最高维度(N)来进行排列并返回一个数组。
def batched(items, batch_size): """将所有图像按batch_size分为不同批次""" for i in range(0, len(items), batch_size): batch = items[i:i + batch_size] while len(batch) < batch_size: # 避免最后一个批次数量不够,让最后一个元素复制以补齐 batch.append(batch[-1]) yield batch # 标识batch为一个生成容器,每一次返回只会返回当前批次的容器 class ImageCalibrationReader(CalibrationDataReader): """创建图像批次迭代器""" def __init__(self, image_paths, input_name, imgsz, batch_size): self.input_name = input_name self.imgsz = imgsz self.batch_size = batch_size self.image_paths = image_paths self.iterator = iter(self.make_batches()) # 图像批次迭代器 def make_batches(self): """生成输入图像批次序列""" for batch_paths in batched(self.image_paths, self.batch_size): # 逐个将所有批次中的每个图像都预处理后,再按批次组成一个数组 batch = np.concatenate( # 图像预处理 [preprocess_image(path, self.imgsz) for path in batch_paths], axis=0, ) yield {self.input_name: batch} # 按照字典形式返回 def get_next(self) -> Optional[Dict[str, np.ndarray]]: """获取迭代器下一批数据,没有则返回None""" return next(self.iterator, None) def rewind(self): """重新创建一个图像批次迭代器""" self.iterator = iter(self.make_batches()) reader = ImageCalibrationReader( image_paths=image_paths, # 校准图像的地址 input_name=input_name, # 图像传递的输入input数据,上文的input-initializer imgsz=imgsz, batch_size=batch, )
获取输入数据
def get_input_name(onnx_path): """获取图像传入的input数据""" model = onnx.load(str(onnx_path)) graph_inputs = {value.name for value in model.graph.input} # 获取onnx计算图里的所有的input名字 initializers = {value.name for value in model.graph.initializer} # 获取onnx模型里的所有initializer名字 real_inputs = sorted(graph_inputs - initializers) # 出去本身initializer得出的input参数 if not real_inputs: raise RuntimeError(f"未在该文件夹下找到模型: {onnx_path}") return real_inputs[0] # 得出图像传入的input数据该代码为自定义代码,其目的就是获取传入模型的真正输入数据,具体解释在上面已经讲解。
图像预处理
图像预处理必须和训练时图像预处理相同,而yolo-obb模型在训练时使用的预处理方法是yolo默认的预处理方法。
首先将图像等比例缩放,因此需要计算出比例大小,然后使用灰色来填充空白区域,再将图像颜色通道由cv2默认读取的BGR改为pytorch等常用的RGB,同时交换通道顺序,并对图像数据做归一化处理,最后扩展通道为NCHW。
def letterbox(image, new_shape): """resize + padding""" src_h, src_w = image.shape[:2] dst_h, dst_w = new_shape scale = min(dst_h / src_h, dst_w / src_w) # 计算图像比例 resized_w = int(round(src_w * scale)) resized_h = int(round(src_h * scale)) pad_w = dst_w - resized_w pad_h = dst_h - resized_h if (src_w, src_h) != (resized_w, resized_h): # 等比例缩放 image = cv2.resize(image, (resized_w, resized_h), interpolation=cv2.INTER_LINEAR) left = int(round(pad_w / 2 - 0.1)) right = int(round(pad_w / 2 + 0.1)) top = int(round(pad_h / 2 - 0.1)) bottom = int(round(pad_h / 2 + 0.1)) return cv2.copyMakeBorder( # 通过灰边padding image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114), ) def preprocess_image(path, imgsz): """预处理图像""" image = cv2.imread(str(path)) if image is None: raise ValueError(f"Failed to read image: {path}") image = letterbox(image, imgsz) # resize + padding image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR->RGB image = image.transpose(2, 0, 1) # HWC->CHW image = np.ascontiguousarray(image, dtype=np.float32) / 255.0 # 数字映射 return image[None, ...] # CHW->NCHW
排除检测头(看精度情况选择)
检测头在之前的文章中讲解过,其根据不同的模型其检测头也不同,都是检测头是模型最后的输出,如果对检测头进行量化可能会导致精度的暴跌。
在此之前,我试过不排除检测头,这导致我在测试模型时其精确度暴跌,因此需要排除检测头。
def find_detect_head_nodes_to_exclude(onnx_path, head_module_index, fallback_last_conv_count): """找出检测头中需要排除的onnx节点""" model = onnx.load(str(onnx_path)) named_nodes = [node for node in model.graph.node if node.name] # 获取onnx模型中所有的计算节点 if head_module_index is None: module_indices = [] for node in named_nodes: match = re.search(r"(?:^|/)model\.(\d+)(?:/|\.|$)", node.name) if match: module_indices.append(int(match.group(1))) # 将捕获结果的第一个分组即(\d+)加入module_indices if module_indices: head_module_index = max(module_indices) # yolo中的检测头一般是最后一个模块,因此取出最大module_indices if head_module_index is not None: # 有指定的检测头,则直接查找指定检测头,并返回该检测头下的所有计算节点 head_pattern = re.compile(rf"(?:^|/)model\.{head_module_index}(?:/|\.|$)") head_nodes = [node.name for node in named_nodes if head_pattern.search(node.name)] if head_nodes: return head_nodes # 如果找不到则直接返回最后fallback_last_conv_count个conv节点 conv_nodes = [node.name for node in named_nodes if node.op_type == "Conv"] if fallback_last_conv_count <= 0: return [] return conv_nodes[-fallback_last_conv_count:] nodes_to_exclude = find_detect_head_nodes_to_exclude( # 排除检测头的节点以防止精度的暴跌 onnx_path=fp32_path, head_module_index=head_module_index, fallback_last_conv_count=fallback_exclude_last_conv_count, )
正则表达式--re
上述代码中有一段正则表达式,即是通过一系列符号来表示一个或多个字符的表达式
# 遍历所有node.name查找符合pattern的内容 # ?:表示不捕获分组;^表示以字符串开头;|表示或者;(?:^|/)表示model前面要么是字符串,要么是/,且该结果不参与分组 # model\.表示model.;正则表达式中.表示任意字符 # (\d+)表示匹配一个或多个数字,并且该结果参与分组 # $表示以字符串结尾;(?:/|\.|$)表示model.数字 后面要么是/,要么是.,要么是字符串,且该结果不参与分组 match = re.search(r"(?:^|/)model\.(\d+)(?:/|\.|$)", node.name) # 因此其要搜索的是(1)model.(2)(3)的算子 # (1)表示多个字符串或者/;(2)表示一个或多个数字;(3)表示/或者.或者字符串 # 同时捕获出来的结果会将(1)、(2)和(3)进行分组,但是由于(1)和(3)不参与分组,因此只有model.字符本身和(2)
静态量化
静态一般直接使用onnx的静态量化的api接口,其源码如下:
onnxruntime/onnxruntime/python/tools/quantization/quantize.py at main · microsoft/onnxruntime
quantize_static( # 静态量化 model_input=str(fp32_path), model_output=str(int8_output), calibration_data_reader=reader, # 校准数据读取器 op_types_to_quantize=["Conv"], # 量化的算子 nodes_to_exclude=nodes_to_exclude, # 不量化节点 quant_format=QuantFormat.QDQ, # 使用QDQ量化格式 activation_type=activation_type, weight_type=QuantType.QInt8, calibrate_method=CalibrationMethod.MinMax, # 校准方法 per_channel=True, # 权重量化方式 )
主要参数
参数 作用 model_input 原始 ONNX FP32 模型路径 model_output 量化后 ONNX 模型保存路径 calibration_data_reader 校准数据读取器 quant_format 量化格式,常用 QuantFormat.QDQ 或 QuantFormat.QOperator op_types_to_quantize 指定算子类型量化 per_channel 是否对权重做 per-channel 量化,通常精度更好 activation_type 激活值量化类型,如 QuantType.QInt8、QuantType.QUInt8 weight_type 权重量化类型,如 QuantType.QInt8、QuantType.QUInt8 nodes_to_quantize 指定具体哪些算子名称要量化 nodes_to_exclude 指定哪些算子名称不量化 calibrate_method 校准方法,如 MinMax、Entropy、Percentile
pytorch静态量化
首先获取pytorch训练好的模型pt/pth文件地址,我这里是一个LPRNet模型
转化为onnx-fp32模型
通常将训练好后直接保存的模型pth文件中,但是其与yolo不同的时,我们一般保存的是模型的权重文件(torch.save(model.state_dict(), filename)),因此其再加载中需要读取模型结构,然后严格按照模型结构分配给每一层权重。
# 转化onnx-fp32格式参数 REEXPORT_FP32_ONNX = True # 是否转化onnx-fp32格式 TORCH_DEVICE = "cpu" ONNX_OPSET_VERSION = 18 ONNX_INPUT_NAME = "input" ONNX_OUTPUT_NAMES = ("output",) # 单输出,多输出需要更改 # LPRNet输入长度 INPUT_WIDTH = 94 INPUT_HEIGHT = 24 INPUT_CHANNELS = 3 model = LPRNet_model_94_24.build_lprnet() # 加载模型文件 checkpoint = torch.load(PTH_PATH, map_location=TORCH_DEVICE) # 读取权重文件 state_dict = extract_state_dict(checkpoint) # 取出模型参数字典 model.load_state_dict(state_dict, strict=True) # 将权重加载进入模型文件中 model.to(TORCH_DEVICE) model.eval() # 创建输入张量 dummy_input = torch.randn( 1, INPUT_CHANNELS, INPUT_HEIGHT, INPUT_WIDTH, dtype=torch.float32, device=TORCH_DEVICE ) FP32_ONNX_PATH.parent.mkdir(parents=True, exist_ok=True) torch.onnx.export( model, dummy_input, str(FP32_ONNX_PATH), input_names=[ONNX_INPUT_NAME], output_names=list(ONNX_OUTPUT_NAMES), opset_version=ONNX_OPSET_VERSION, do_constant_folding=True )
取出模型参数字典--extract_state_dict
该函数为自定义的函数,其用处就是取出权重参数以便于后续加载进入模型结构中。
def extract_state_dict(checkpoint): """取出模型参数字典""" if isinstance(checkpoint, dict): for key in ("state_dict", "model_state_dict", "net", "model"): # 防止保存格式的不同,pth中包含了多个其他模块 value = checkpoint.get(key) if isinstance(value, dict): return value if checkpoint and all(torch.is_tensor(value) for value in checkpoint.values()): # checkpoint本身就是模型参数 return checkpoint raise TypeError("在检查点中未找到 state_dict")加入在pytorch训练时通过torch.save(model.state_dict(), filename)来保存的,那么直接返回checkpoint即可,但是这里为了具有一般性,因此还有pth模型文件中不仅保存了权重参数,同时还保存了训练轮数、模型结构、优化器等,因此需要通过字典对应的键来取出模型权重参数。
torch.onnx.export
该函数是pytorch的导出接口,可以将pth文件导出为o文件,由于参数过多,挑几个较为重要的参数进行说明。
model:要导出的pytorch模型
dummy_input:输入张量,必须和模型训练时输入张量形状一样,通常使用torch.randn创建一个即可
f:导出文件路径
input_names:导出后onnx输入节点名称
output_names:导出后onnx输出节点名称
opset_version:onnx算子版本
do_constant_folding:是否做常量折叠优化
training:导出训练图还是推理图,一般不改变,除非需要训练onnx模型
其中input_names和output_names都需要适应模型的输入输出个数,如果为多输入多输出,有几个输入/输出就应该是几维的列表。如果不知道有几个输入输出,可以看下面的获取输入数据的代码。
常量折叠优化就是把计算图里只依赖常量的计算提前算好,直接替换成结果。
创建校准数据读取器
将转化好的onnx-fp32保存,然后处理校准图像集。构建一个图像批次迭代器,将图像分为每一张一个批次,对图像进行预处理,同时将每一个批次的图像按照图像的最高维度(N)来进行排列并返回一个数组。
def batched(items, batch_size): """将所有图像按batch_size分为不同批次""" for i in range(0, len(items), batch_size): batch = items[i:i + batch_size] while len(batch) < batch_size: # 避免最后一个批次数量不够,让最后一个元素复制以补齐 batch.append(batch[-1]) yield batch # 标识batch为一个生成容器,每一次返回只会返回当前批次的容器 class ImageCalibrationReader(CalibrationDataReader): """创建图像批次迭代器""" def __init__(self, image_paths, input_name, imgsz, batch_size): self.input_name = input_name self.imgsz = imgsz self.batch_size = batch_size self.image_paths = image_paths self.iterator = iter(self.make_batches()) # 图像批次迭代器 def make_batches(self): """生成输入图像批次序列""" for batch_paths in batched(self.image_paths, self.batch_size): # 逐个将所有批次中的每个图像都预处理后,再按批次组成一个数组 batch = np.concatenate( # 图像预处理 [preprocess_image(path, self.imgsz) for path in batch_paths], axis=0, ) yield {self.input_name: batch} # 按照字典形式返回 def get_next(self) -> Optional[Dict[str, np.ndarray]]: """获取迭代器下一批数据,没有则返回None""" return next(self.iterator, None) def rewind(self): """重新创建一个图像批次迭代器""" self.iterator = iter(self.make_batches()) reader = ImageCalibrationReader( image_paths=image_paths, # 校准图像的地址 input_name=input_name, # 图像传递的输入input数据,上文的input-initializer imgsz=imgsz, batch_size=batch, )
获取输入数据
def infer_single_input_name(model_path): """从一个onnx模型里自动推断输入节点的名字""" model = onnx.load(str(model_path)) # 加载模型 initializer_names = {value.name for value in model.graph.initializer} # 获取onnx模型里的所有initializer名字 # 筛选真正的输入 inputs = [ value for value in model.graph.input if value.name not in initializer_names ] # 判断输入是否为1个,不是则报错 if len(inputs) != 1: names = ", ".join(item.name for item in inputs) raise ValueError( f"这个模型有{len(inputs)}个inputs: {names}." ) return inputs[0].name # 返回输入的名字该代码为自定义代码,其目的就是获取传入模型的真正输入数据,具体解释在上面已经讲解。
图像预处理
图像预处理必须和训练时图像预处理相同,这个具体的处理步骤可以直接使用训练时的代码。
def preprocess_lprnet_image(image_path, width, height): """图像预处理""" img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR) if img is None: raise ValueError(f"读取图像失败: {image_path}") h, w, c = img.shape filename = os.path.basename(image_path) parts = filename.split('-') # 解析外接矩阵坐标 loc_part = parts[2] corners = loc_part.split('_') lt = corners[0].split('&') # 左上 rb = corners[1].split('&') # 右下 x1 = min(int(lt[0]), int(rb[0])) x2 = max(int(lt[0]), int(rb[0])) y1 = min(int(lt[1]), int(rb[1])) y2 = max(int(lt[1]), int(rb[1])) # 执行裁剪 x_min = min(x1, x2) x_max = max(x1, x2) y_min = min(y1, y2) y_max = max(y1, y2) x_min, y_min = max(0, x_min - 12), max(0, y_min - 12) x_max, y_max = min(w, x_max + 12), min(h, y_max + 12) img = img[y_min:y_max, x_min:x_max] # 尺寸变化 img = cv2.resize(img, (width, height), interpolation=cv2.INTER_LINEAR) img = img.astype('float32') img -= 127.5 img /= 128.0 img = img.transpose(2, 0, 1) # HWC -> CHW return img[None, ...].astype(np.float32)
排除检测头(看精度情况选择)
检测头在之前的文章中讲解过,其根据不同的模型其检测头也不同,都是检测头是模型最后的输出,如果对检测头进行量化可能会导致精度的暴跌。但是这里无需对排除检测头。
静态量化
静态一般直接使用onnx的静态量化的api接口,其源码如下:
onnxruntime/onnxruntime/python/tools/quantization/quantize.py at main · microsoft/onnxruntime
quantize_static( # 开始静态量化 model_input=str(FP32_ONNX_PATH), model_output=str(INT8_ONNX_PATH), calibration_data_reader=reader, op_types_to_quantize=["Conv"], quant_format=QuantFormat.QDQ, activation_type=ACTIVATION_TYPE, weight_type=WEIGHT_TYPE, calibrate_method=CALIBRATION_METHOD, per_channel=PER_CHANNEL, )
主要参数
参数 作用 model_input 原始 ONNX FP32 模型路径 model_output 量化后 ONNX 模型保存路径 calibration_data_reader 校准数据读取器 quant_format 量化格式,常用 QuantFormat.QDQ 或 QuantFormat.QOperator op_types_to_quantize 指定算子类型量化 per_channel 是否对权重做 per-channel 量化,通常精度更好 activation_type 激活值量化类型,如 QuantType.QInt8、QuantType.QUInt8 weight_type 权重量化类型,如 QuantType.QInt8、QuantType.QUInt8 nodes_to_quantize 指定具体哪些算子名称要量化 nodes_to_exclude 指定哪些算子名称不量化 calibrate_method 校准方法,如 MinMax、Entropy、Percentile
总结
其实可以发现,主流模型导出onnx-int8的步骤都相差不大,都是相同的步骤,需要注意的是模型中那些结构需要排除不量化。除了上述的介绍以外,还需要注意以下问题。
先做 FP32 基线
在导出fp32模型时,不管后续要导出什么格式,都需要对模型进行一个验证,如果这一步就出现精度的暴跌,那说明fp32的导出是有问题的
导出onnx-fp32模型是量化时的第一步,无论后续导出rknn、ncnn还是tflite等格式,都先导出onnx-fp32,然后再导出对应格式的fp32,最后再量化为int8。
校准输入必须等同真实推理输入
这个和前文中提到的一样,需要注意输入的维度和预处理的方法都要和训练时一样,否则精度也会暴跌。
onnx-fp32转化后最好做 shape inference / graph preprocessing
当onnx-fp32模型转化完成,同时校准了fp32的基线后,还需要对其做shape inference / graph preprocessing。
在模型较为复杂,同时转化后的onnx-fp32精度没有问题时,先使用quant_pre_process来做graph preprocessing,但是当其精度不达标,则不进行图层优化,但是如果精度还是有问题的话,则转回来使用shape_inference.infer_shapes_path做shape inference。
from onnxruntime.quantization.shape_inference import quant_pre_process quant_pre_process( input_model_path="model_fp32_raw.onnx", output_model_path="model_fp32_preprocessed.onnx", ) from onnxruntime.quantization.shape_inference import quant_pre_process quant_pre_process( input_model_path="model_fp32_raw.onnx", output_model_path="model_fp32_shape_only.onnx", skip_optimization=True, ) import onnx from onnx import checker, shape_inference checker.check_model("model_fp32_raw.onnx") shape_inference.infer_shapes_path( "model_fp32_raw.onnx", "model_fp32_shape.onnx", check_type=True, strict_mode=False, data_prop=True, ) checker.check_model("model_fp32_shape.onnx")
但是当其精度不达标,则转回来使用shape_inference.infer_shapes_path做shape inference对吗
形状推理--shape inference
shape inference就是在不输入真实数据,只根据onnx图结构、算子属性、已知输入形状和常量,推导中间张量的形状/属性。
而onnx保存时通常不会保存中间张量的信息,从而导致在后续量化时,如果模型较为复杂时,其可能导致错量化、漏量化等问题。
import onnx from onnx import shape_inference, checker shape_inference.infer_shapes_path( "model_fp32.onnx", "model_fp32_shape.onnx", check_type=True, strict_mode=False, data_prop=True, ) checker.check_model("model_fp32_shape.onnx")data_prop=True 的意思是允许对有限算子做一些数据传播来帮助 shape 计算,比如某些 shape 常量能被继续传下去。
优化图预处理--graph preprocessing
graph preprocessing比上面的shape inference更加复杂,shape inference只会补全中间tensor的信息,但是不会改变中间的网络层结构,而graph preprocessing除了补全tensor的信息以外,还会:
-
constant folding
-
删除无用节点
-
融合部分算子
-
整理图结构
from onnxruntime.quantization.shape_inference import quant_pre_process quant_pre_process( input_model_path="model_fp32.onnx", output_model_path="model_fp32_preprocessed.onnx", )在graph preprocessing后还需要对新的onnx模型进行一次精度检验,没有问题后再进行下一步。
量化格式要看部署后端
由于onnx runtime和tensorRT常用的QDQ格式,但是某些CPU也会用Q0perator,同时TensorRT、NPU、OpenVINO 等后端对 per_channel、symmetric/asymmetric、U8S8/S8S8 支持也不一样。
不要盲目全图量化
模型中常常优先量化的算子为conv、MatMul、Gemm等,但是某些算子(如检测头、Softmax等)量化后可能会导致量化后精度暴跌。
检测头是否排除,最好靠敏感性实验
不是所有检测头都必须排除。建议从全量 INT8 开始测一次,再逐步排除 head、decode、最后输出层,看mAP恢复多少、速度损失多少。
校准算法也会影响掉点
常见的校准算法有 MinMax、Entropy、Percentile。检测模型遇到激活 outlier 时,Percentile 有时比 MinMax 稳。x86 CPU 上如果 U8S8 + per-channel 精度异常,可以试 reduce_range 或换数据类型组合。
最后一定在目标设备上测
ONNX Runtime 本地跑得快,不代表 TensorRT/NPU 上也最优。最终要看目标后端的 latency、吞吐、显存和 mAP。
注意点
除了关注上述的onnx转化,如果有特定的嵌入式板,也需要严格关注下面的一些信息。
算子支持不同
同一个 ONNX 模型,CPU 后端可能支持,某些 GPU/NPU 后端可能不支持某些算子。
量化格式支持不同
有的后端喜欢 QDQ 格式,有的喜欢 QOperator,有的只支持特定 INT8 算子。
数据类型支持不同
FP32、FP16、INT8 在不同硬件上的支持不一样。GPU 常见 FP16 加速,NPU 常见 INT8 加速。
动态 shape 支持不同
CPU 通常更宽容,嵌入式 NPU 往往更喜欢固定输入尺寸。
自定义算子
如果 ONNX 里有自定义 op,目标后端必须有对应实现。
总代码
yolo
from pathlib import Path import re import cv2 import numpy as np import onnx from onnxruntime.quantization import ( CalibrationDataReader, CalibrationMethod, QuantFormat, QuantType, quantize_static, ) from ultralytics import YOLO # 模型/图像地址 WEIGHTS_PATH = Path(r"E:\code\python\lincense_plate_recongsize\code\runs\obb_finetune_v2\yolo8_ccpd_patch\weights\best.pt") CALIB_DIR = Path(r"E:\code\python\lincense_plate_recongsize\code\calib_images") # 保存路径 FP32_OUTPUT = Path(r"E:\code\python\lincense_plate_recongsize\code\first_quat_yolo\weights\yolov8n-obb-fp32.onnx") INT8_OUTPUT = Path(r"E:\code\python\lincense_plate_recongsize\code\first_quat_yolo\weights\yolov8n-obb-int8.onnx") # 初始化参数 HEIGHT = 320 # 图像高 WEIGHT = 320 # 图像宽 BATCH = 1 # 图像批次 OPSET = 13 # 版本选择 MAX_CALIB_IMAGES = 338 # 最大校准图像数量 ACTIVATION_TYPE = "uint8" # onnx量化时的激活值量化类型 SIMPLIFY = False EXCLUDE_DETECT_HEAD = True # 是否排除检测头节点 HEAD_MODULE_INDEX = None # 检测头索引 FALLBACK_EXCLUDE_LAST_CONV_COUNT = 12 # 节点中需要排除的conv数量 IMAGE_SUFFIXES = {".jpg", ".jpeg", ".png", ".bmp", ".webp"} def normalize_imgsz(height, weight): """检查图像缩放长度正确性""" if isinstance(height, int) and isinstance(weight, int): return height, weight raise ValueError("输出有误,请检查图像长度") def list_images(image_dir, max_images): """获取所有校准图像地址""" paths = sorted( p for p in image_dir.rglob("*") # 递归查找所有image_dir下的子文件 # 该子文件必须为文件且后缀名在IMAGE_SUFFIXES中 if p.is_file() and p.suffix.lower() in IMAGE_SUFFIXES ) if not paths: raise FileNotFoundError(f"没有在该文件下找到所需要的校准图像: {image_dir}") return paths[:max_images] if max_images else paths def letterbox(image, new_shape): """resize + padding""" src_h, src_w = image.shape[:2] dst_h, dst_w = new_shape scale = min(dst_h / src_h, dst_w / src_w) # 计算图像比例 resized_w = int(round(src_w * scale)) resized_h = int(round(src_h * scale)) pad_w = dst_w - resized_w pad_h = dst_h - resized_h if (src_w, src_h) != (resized_w, resized_h): # 等比例缩放 image = cv2.resize(image, (resized_w, resized_h), interpolation=cv2.INTER_LINEAR) left = int(round(pad_w / 2 - 0.1)) right = int(round(pad_w / 2 + 0.1)) top = int(round(pad_h / 2 - 0.1)) bottom = int(round(pad_h / 2 + 0.1)) return cv2.copyMakeBorder( # 通过灰边padding image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114), ) def preprocess_image(path, imgsz): """预处理图像""" image = cv2.imread(str(path)) if image is None: raise ValueError(f"Failed to read image: {path}") image = letterbox(image, imgsz) # resize + padding image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR->RGB image = image.transpose(2, 0, 1) # HWC->CHW image = np.ascontiguousarray(image, dtype=np.float32) / 255.0 # 数字映射 return image[None, ...] # CHW->NCHW def batched(items, batch_size): """将所有图像按batch_size分为不同批次""" for i in range(0, len(items), batch_size): batch = items[i:i + batch_size] while len(batch) < batch_size: # 避免最后一个批次数量不够,让最后一个元素复制以补齐 batch.append(batch[-1]) yield batch # 标识batch为一个生成容器,每一次返回只会返回当前批次的容器 class ImageCalibrationReader(CalibrationDataReader): """创建图像批次迭代器""" def __init__(self, image_paths, input_name, imgsz, batch_size): self.input_name = input_name self.imgsz = imgsz self.batch_size = batch_size self.image_paths = image_paths self.iterator = iter(self.make_batches()) # 图像批次迭代器 def make_batches(self): """生成输入图像批次序列""" for batch_paths in batched(self.image_paths, self.batch_size): # 逐个将所有批次中的每个图像都预处理后,再按批次组成一个数组 batch = np.concatenate( [preprocess_image(path, self.imgsz) for path in batch_paths], axis=0, ) yield {self.input_name: batch} # 按照字典形式返回 def get_next(self): """获取迭代器下一批数据,没有则返回None""" return next(self.iterator, None) def rewind(self): """重新创建一个图像批次迭代器""" self.iterator = iter(self.make_batches()) def get_input_name(onnx_path): """获取图像传入的input数据""" model = onnx.load(str(onnx_path)) graph_inputs = {value.name for value in model.graph.input} # 获取onnx计算图里的所有的input名字 initializers = {value.name for value in model.graph.initializer} # 获取onnx模型里的所有initializer名字 real_inputs = sorted(graph_inputs - initializers) # 出去本身initializer得出的input参数 if not real_inputs: raise RuntimeError(f"未在该文件夹下找到模型: {onnx_path}") return real_inputs[0] # 得出图像传入的input数据 def find_detect_head_nodes_to_exclude(onnx_path, head_module_index, fallback_last_conv_count): """找出检测头中需要排除的onnx节点""" model = onnx.load(str(onnx_path)) named_nodes = [node for node in model.graph.node if node.name] # 获取onnx模型中所有的计算节点 if head_module_index is None: module_indices = [] for node in named_nodes: # 遍历所有node.name查找符合pattern的内容 # ?:表示不捕获分组;^表示以字符串开头;|表示或者;(?:^|/)表示model前面要么是字符串,要么是/,且该结果不参与分组 # model\.表示model.;正则表达式中.表示任意字符 # (\d+)表示匹配一个或多个数字,并且该结果参与分组 # $表示以字符串结尾;(?:/|\.|$)表示model.数字 后面要么是/,要么是.,要么是字符串,且该结果不参与分组 match = re.search(r"(?:^|/)model\.(\d+)(?:/|\.|$)", node.name) if match: module_indices.append(int(match.group(1))) # 将捕获结果的第一个分组即(\d+)加入module_indices if module_indices: head_module_index = max(module_indices) # yolo中的检测头一般是最后一个模块,因此取出最大module_indices if head_module_index is not None: # 有指定的检测头,则直接查找指定检测头,并返回该检测头下的所有计算节点 head_pattern = re.compile(rf"(?:^|/)model\.{head_module_index}(?:/|\.|$)") head_nodes = [node.name for node in named_nodes if head_pattern.search(node.name)] if head_nodes: return head_nodes # 如果找不到则直接返回最后fallback_last_conv_count个conv节点 conv_nodes = [node.name for node in named_nodes if node.op_type == "Conv"] if fallback_last_conv_count <= 0: return [] return conv_nodes[-fallback_last_conv_count:] def export_fp32_onnx(model_path, fp32_output, imgsz, opset, simplify, batch): """将模型从pt转化为onnx格式""" model = YOLO(str(model_path)) exported_path = model.export( format="onnx", imgsz=imgsz, opset=opset, simplify=simplify, dynamic=False, batch=batch, nms=False, ) fp32_path = Path(exported_path) if fp32_output: fp32_output.parent.mkdir(parents=True, exist_ok=True) if fp32_path.resolve() != fp32_output.resolve(): fp32_path.replace(fp32_output) fp32_path = fp32_output return fp32_path def quantize_onnx( fp32_path, calib_dir, int8_output, imgsz, batch, max_calib_images, activation_type_name, exclude_detect_head, head_module_index, fallback_exclude_last_conv_count ): """量化onnx-int8格式""" input_name = get_input_name(fp32_path) # 得到图像传递的input数据 image_paths = list_images(calib_dir, max_calib_images) # 得到校准图像的地址 reader = ImageCalibrationReader( image_paths=image_paths, input_name=input_name, imgsz=imgsz, batch_size=batch, ) int8_output.parent.mkdir(parents=True, exist_ok=True) # 创建输出int8的输出文件夹,若已经存在则直接使用,上级目录不存在则一起创建 activation_type = ( # 选择onnx量化时的激活值量化类型 QuantType.QInt8 if activation_type_name.lower() == "qint8" else QuantType.QUInt8 ) nodes_to_exclude = [] if exclude_detect_head: nodes_to_exclude = find_detect_head_nodes_to_exclude( # 排除检测头的节点以防止精度的暴跌 onnx_path=fp32_path, head_module_index=head_module_index, fallback_last_conv_count=fallback_exclude_last_conv_count, ) print(f"Excluded FP32 head nodes: {len(nodes_to_exclude)}") quantize_static( # 静态量化 model_input=str(fp32_path), model_output=str(int8_output), calibration_data_reader=reader, # 校准数据读取器 op_types_to_quantize=["Conv"], # 量化的算子 nodes_to_exclude=nodes_to_exclude, # 不量化节点 quant_format=QuantFormat.QDQ, # 使用QDQ量化格式 activation_type=activation_type, weight_type=QuantType.QInt8, calibrate_method=CalibrationMethod.MinMax, # 校准方法 per_channel=True, # 权重量化方式 ) return int8_output def main(): imgsz = normalize_imgsz(HEIGHT, WEIGHT) fp32_path = export_fp32_onnx( model_path=WEIGHTS_PATH, fp32_output=FP32_OUTPUT, imgsz=imgsz, opset=OPSET, simplify=SIMPLIFY, batch=BATCH, ) int8_path = quantize_onnx( fp32_path=fp32_path, calib_dir=CALIB_DIR, int8_output=INT8_OUTPUT, imgsz=imgsz, batch=BATCH, max_calib_images=MAX_CALIB_IMAGES, activation_type_name=ACTIVATION_TYPE, exclude_detect_head=EXCLUDE_DETECT_HEAD, head_module_index=HEAD_MODULE_INDEX, fallback_exclude_last_conv_count=FALLBACK_EXCLUDE_LAST_CONV_COUNT, ) print(f"FP32 ONNX: {fp32_path.resolve()}") print(f"INT8 ONNX: {int8_path.resolve()}") if __name__ == "__main__": main()
pytorch
import os.path from pathlib import Path import LPRNet_model_94_24 import torch import numpy as np import cv2 import onnx from onnxruntime.quantization import ( CalibrationDataReader, CalibrationMethod, QuantFormat, QuantType, quantize_static, ) # 量化模型/图像地址 PTH_PATH = Path(r"E:\code\python\lincense_plate_recongsize\code\weights\lprnet_best.pth") CALIBRATION_IMAGE_DIR = Path(r"E:\code\python\lincense_plate_recongsize\code\calib_images") # 模型保存地址 FP32_ONNX_PATH = Path(r"E:\code\python\lincense_plate_recongsize\code\first_quat_LPRNet\weights\lprnet_fp32.onnx") INT8_ONNX_PATH = Path(r"E:\code\python\lincense_plate_recongsize\code\first_quat_LPRNet\weights\lprnet_int8.onnx") # 转化onnx-fp32格式参数 REEXPORT_FP32_ONNX = True # 是否转化onnx-fp32格式 TORCH_DEVICE = "cpu" ONNX_OPSET_VERSION = 18 ONNX_INPUT_NAME = "input" ONNX_OUTPUT_NAMES = ("output",) # 单输出,多输出需要更改 # LPRNet输入长度 INPUT_WIDTH = 94 INPUT_HEIGHT = 24 INPUT_CHANNELS = 3 # 校准图片数量 MAX_CALIBRATION_SAMPLES: int | None = 300 BATCH_SIZE = 1 RECURSIVE_SEARCH = False # 静态量化参数 ACTIVATION_TYPE = QuantType.QInt8 WEIGHT_TYPE = QuantType.QInt8 CALIBRATION_METHOD = CalibrationMethod.MinMax PER_CHANNEL = True IMAGE_SUFFIXES = {".jpg", ".jpeg", ".png", ".bmp", ".webp"} def extract_state_dict(checkpoint): """取出模型参数字典""" if isinstance(checkpoint, dict): for key in ("state_dict", "model_state_dict", "net", "model"): # 防止保存格式的不同,pth中包含了多个其他模块 value = checkpoint.get(key) if isinstance(value, dict): return value if checkpoint and all(torch.is_tensor(value) for value in checkpoint.values()): # checkpoint本身就是模型参数,一般是在训练模型时,使用torch.save(model.state_dict(), SAVE_FILE)保存的 return checkpoint raise TypeError("在检查点中未找到 state_dict") def export_pth_to_onnx(): """导出onnx-fp32格式""" if FP32_ONNX_PATH.exists() and not REEXPORT_FP32_ONNX: return model = LPRNet_model_94_24.build_lprnet() # 加载模型文件 checkpoint = torch.load(PTH_PATH, map_location=TORCH_DEVICE) # 读取权重文件 state_dict = extract_state_dict(checkpoint) # 取出模型参数字典 model.load_state_dict(state_dict, strict=True) # 将权重加载进入模型文件中 model.to(TORCH_DEVICE) model.eval() # 创建输入张量 dummy_input = torch.randn( 1, INPUT_CHANNELS, INPUT_HEIGHT, INPUT_WIDTH, dtype=torch.float32, device=TORCH_DEVICE, ) FP32_ONNX_PATH.parent.mkdir(parents=True, exist_ok=True) torch.onnx.export( model, dummy_input, str(FP32_ONNX_PATH), input_names=[ONNX_INPUT_NAME], output_names=list(ONNX_OUTPUT_NAMES), opset_version=ONNX_OPSET_VERSION, do_constant_folding=True, ) def list_images(image_dir, max_images): """获取所有校准图像地址""" paths = sorted( p for p in image_dir.rglob("*") # 递归查找所有image_dir下的子文件 # 该子文件必须为文件且后缀名在IMAGE_SUFFIXES中 if p.is_file() and p.suffix.lower() in IMAGE_SUFFIXES ) if not paths: raise FileNotFoundError(f"没有在该文件下找到所需要的校准图像: {image_dir}") return paths[:max_images] if max_images else paths def preprocess_lprnet_image(image_path, width, height): """图像预处理""" img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR) if img is None: raise ValueError(f"读取图像失败: {image_path}") h, w, c = img.shape filename = os.path.basename(image_path) parts = filename.split('-') # 解析外接矩阵坐标 loc_part = parts[2] corners = loc_part.split('_') lt = corners[0].split('&') # 左上 rb = corners[1].split('&') # 右下 x1 = min(int(lt[0]), int(rb[0])) x2 = max(int(lt[0]), int(rb[0])) y1 = min(int(lt[1]), int(rb[1])) y2 = max(int(lt[1]), int(rb[1])) # 执行裁剪 x_min = min(x1, x2) x_max = max(x1, x2) y_min = min(y1, y2) y_max = max(y1, y2) x_min, y_min = max(0, x_min - 12), max(0, y_min - 12) x_max, y_max = min(w, x_max + 12), min(h, y_max + 12) img = img[y_min:y_max, x_min:x_max] # 尺寸变化 img = cv2.resize(img, (width, height), interpolation=cv2.INTER_LINEAR) img = img.astype('float32') img -= 127.5 img /= 128.0 img = img.transpose(2, 0, 1) # HWC -> CHW return img[None, ...].astype(np.float32) class LPRNetCalibrationDataReader(CalibrationDataReader): """创建图像批次迭代器""" def __init__(self, model_input_name, image_paths): self.model_input_name = model_input_name self.image_paths = image_paths self.index = 0 def reset(self): self.index = 0 def get_next(self): """生成输入图像批次序列获取下一批数据""" if self.index >= len(self.image_paths): return None batch_paths = self.image_paths[self.index: self.index + BATCH_SIZE] self.index += BATCH_SIZE batch = np.concatenate( [ preprocess_lprnet_image( image_path=path, width=INPUT_WIDTH, height=INPUT_HEIGHT ) for path in batch_paths ], axis=0, ) return {self.model_input_name: batch} def infer_single_input_name(model_path): """从一个onnx模型里自动推断输入节点的名字""" model = onnx.load(str(model_path)) # 加载模型 initializer_names = {value.name for value in model.graph.initializer} # 获取onnx模型里的所有initializer名字 # 筛选真正的输入 inputs = [ value for value in model.graph.input if value.name not in initializer_names ] # 判断输入是否为1个,不是则报错 if len(inputs) != 1: names = ", ".join(item.name for item in inputs) raise ValueError( f"这个模型有{len(inputs)}个inputs: {names}." ) return inputs[0].name # 返回输入的名字 def static_quantize_lprnet(): export_pth_to_onnx() # 将pth文件转化为onnx文件 if not FP32_ONNX_PATH.exists(): raise FileNotFoundError(FP32_ONNX_PATH) if not CALIBRATION_IMAGE_DIR.exists(): raise FileNotFoundError(CALIBRATION_IMAGE_DIR) input_name = infer_single_input_name(FP32_ONNX_PATH) # 获取输入名字 image_paths = list_images(CALIBRATION_IMAGE_DIR, MAX_CALIBRATION_SAMPLES) # 得到校准图像的地址 reader = LPRNetCalibrationDataReader( model_input_name=input_name, image_paths=image_paths, ) INT8_ONNX_PATH.parent.mkdir(parents=True, exist_ok=True) quantize_static( # 开始静态量化 model_input=str(FP32_ONNX_PATH), model_output=str(INT8_ONNX_PATH), calibration_data_reader=reader, op_types_to_quantize=["Conv"], quant_format=QuantFormat.QDQ, activation_type=ACTIVATION_TYPE, weight_type=WEIGHT_TYPE, calibrate_method=CALIBRATION_METHOD, per_channel=PER_CHANNEL, ) if __name__ == "__main__": static_quantize_lprnet()