论文标题: Recommendation as Generation: Unifying Personalized Video Generation and Recommendation at Industrial Scale
论文链接: arXiv:2606.25496v1
论文作者: Yanhua Cheng, Bo Wang, Haotian Zhang, Xinyuan Gao, Zhihui Yin, Ben Xue, Yongzhi Li, Jieting Xue, Ye Ma, Minquan Wang, Jiahui Li, Tianyu Xu, Zhiqiang Liu, Xiao Lin, Shiyang Wen, Changcheng Li, Liu Liu, Quan Chen, Peng Jiang, Kun Gai
机构名称: Kuaishou Technology;Beihang University
一句话总结: RaG 把短视频推荐从"在固定视频池里检索"改成"先生成用户兴趣 D-SIDs,再按兴趣生成个性化视频",并用跨域奖励学习把用户反馈、兴趣对齐和视频质量闭环优化到工业广告系统中。
背景与动机
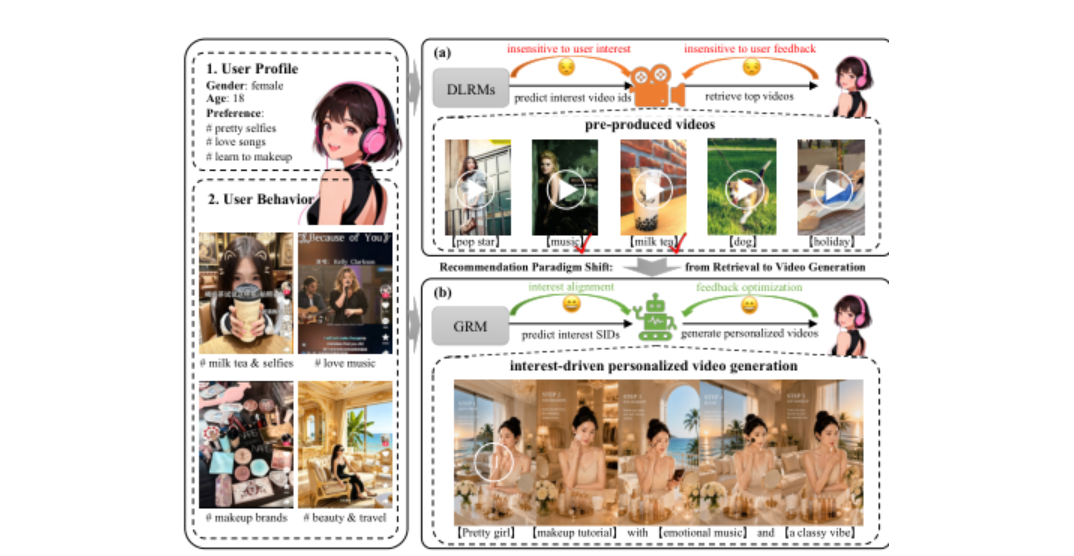
传统短视频推荐系统遵循 content-first 范式:视频先离线生产,推荐模型再从固定池中召回和排序。DLRM 类模型提升了匹配精度,GRM 类模型进一步把用户兴趣建模为 Semantic IDs 的自回归生成,但最终仍然只能检索已有内容。
论文指出这个范式的核心瓶颈是内容池上限:当用户兴趣落在长尾、动态或新颖语义上时,推荐模型只能选择"池子里最接近的视频",无法生成真正匹配该兴趣的新内容。另一方面,视频生成模型具备强语义可控性,但通常依赖人工 prompt、多阶段后处理和高计算成本,难以直接服务 4 亿 DAU 级推荐场景。
本文的关键 insight:用 Disentangled Semantic IDs(D-SIDs)作为推荐与生成的共享离散语义接口,让 GRM 预测"用户想看的内容语义和创意风格",再让生成系统直接把这些语义 ID 解码成个性化视频。
整体架构
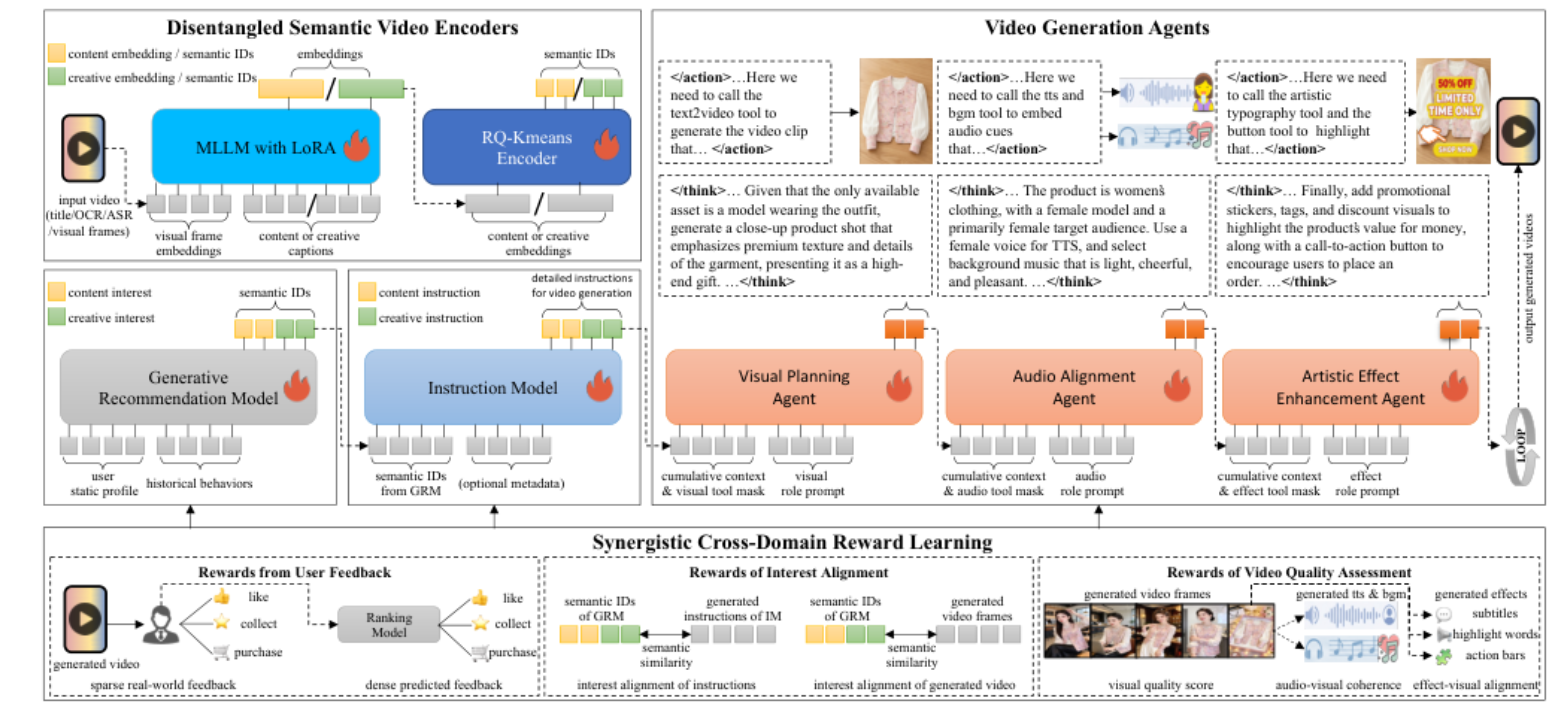
RaG 的端到端数据流是:输入视频与用户上下文 → Disentangled Semantic Video Encoders 把视频编码为内容 SIDs 与创意 SIDs → GRM 根据用户画像和历史行为自回归预测用户兴趣 D-SIDs → Instruction Model 将 D-SIDs 翻译为镜头级制作指令 → Video Generation Agents 分别完成视觉规划、音频对齐和艺术效果增强 → SCRL 用用户反馈、兴趣对齐和视频质量奖励联合优化全链路。
部署上,GRM 在线实时推理,D-SIDs 编码、Instruction Model 和 VGAs 走 nearline 生成;服务时根据 SID 缓存命中情况返回已有个性化视频或异步补齐缺失创意变体。
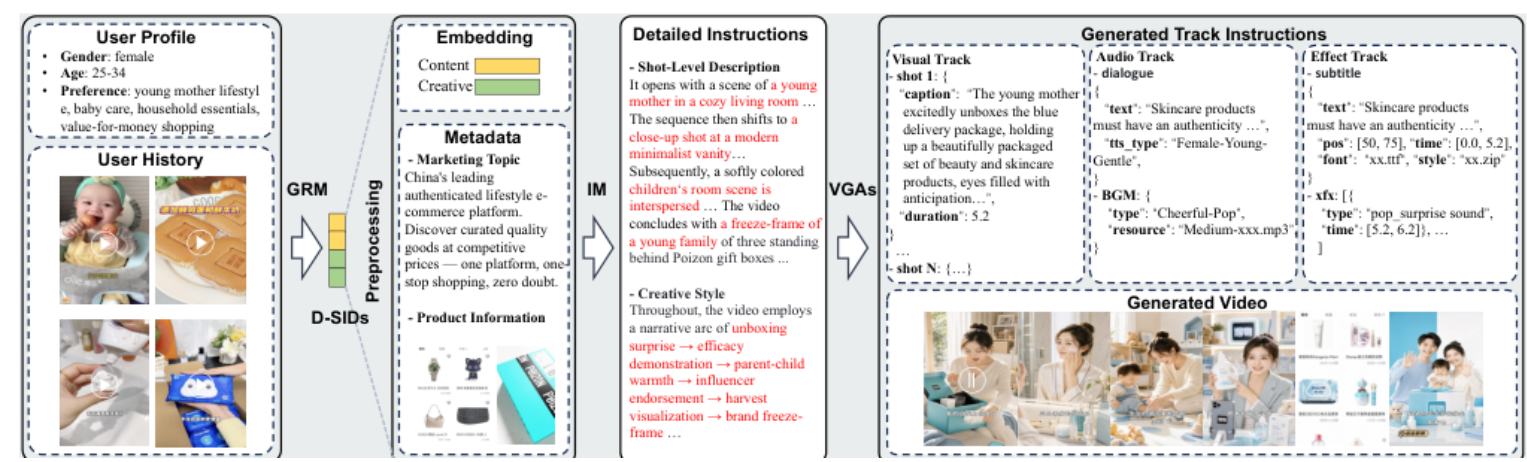
逐模块方案拆解
3.1 Disentangled Semantic Video Encoders
模块作用:把同一个视频拆成内容语义 与创意风格两类离散语义 ID,作为推荐模型和生成模型共用的接口。
输入:视频 v;输出:D-SIDs = [s_content^{1:L}; s_creative^{1:L}],其中每个 SID token 是离散 code index。
D - S I D s = E ( v ) = ( s c o n t e n t 1 , ... , s c o n t e n t L , s c r e a t i v e 1 , ... , s c r e a t i v e L ) D\text{-}SIDs = E(v) = (s_{content}^{1}, \ldots, s_{content}^{L}, s_{creative}^{1}, \ldots, s_{creative}^{L}) D-SIDs=E(v)=(scontent1,...,scontentL,screative1,...,screativeL)
变量说明:
-
v:输入视频,包含视觉帧以及标题、OCR、ASR 等文本信号。 -
E(·):Disentangled Semantic Video Encoder,由 Qwen2.5-VL-7B-Instruct 视觉编码器、文本 tokenizer、LoRA 适配和 RQ-KMeans 量化组成。 -
s_content^l:第l层内容语义 code,表示实体、主题、商品、场景等内容信息;取值范围为 codebook 索引,论文每层 codebook size 为 8192。 -
s_creative^l:第l层创意语义 code,表示风格、节奏、氛围等创意属性;取值范围同样为 8192 个 code。 -
L:残差量化层数;实验中 D-SIDs 与 QARM 对齐使用 4 层 codebook。 -
D-SIDs:长度为2L的离散 token 序列,前L个为 content SIDs,后L个为 creative SIDs。
3.1.1 多模态表示学习
编码器先用视觉编码器抽取视频 token,再用内部 dense captioning 模型生成 factor-specific 文本描述。
H = F ( v ) , H ∈ R N × d H = F(v), \quad H \in \mathbb{R}^{N \times d} H=F(v),H∈RN×d
变量说明:
-
F(·):Qwen2.5-VL 原生视觉编码器。 -
H:视频视觉 token 序列。 -
N:视觉 token 数,覆盖视频的时空语义。 -
d:多模态隐藏维度。 -
H ∈ R^{N×d}:每行对应一个视觉 token 的d维表示。
D m = C a p M o d e l ( v , P R O M P T m ) , m ∈ { c o n t e n t , c r e a t i v e } D_m = \mathrm{CapModel}(v, \mathrm{PROMPT}_m), \quad m \in \{content, creative\} Dm=CapModel(v,PROMPTm),m∈{content,creative}
变量说明:
-
m:解耦因子,取值为content或creative。 -
D_content:内容描述,覆盖实体、主题等语义。 -
D_creative:创意描述,覆盖风格、节奏、氛围。 -
PROMPT_m:面向某一因子的提示词,用于约束 CapModel 输出对应类型的信息。
Q m = T ( D m ) , Q m ∈ R L m × d Q_m = T(D_m), \quad Q_m \in \mathbb{R}^{L_m \times d} Qm=T(Dm),Qm∈RLm×d
变量说明:
-
T(·):Qwen2.5-VL 的文本 tokenizer / embedding 模块。 -
Q_m:因子m的文本 token 表示。 -
L_m:文本描述 token 长度。 -
d:文本和视觉对齐后的隐藏维度。
z m = N o r m a l i z e ( V L M ( H , Q m ) ) , z m ∈ R d , ∥ z m ∥ 2 = 1 z_m = \mathrm{Normalize}(\mathrm{VLM}(H, Q_m)), \quad z_m \in \mathbb{R}^{d}, \quad \|z_m\|_2 = 1 zm=Normalize(VLM(H,Qm)),zm∈Rd,∥zm∥2=1
变量说明:
-
VLM(H,Q_m):Qwen2.5-VL 对视觉 token 与文本 token 的联合编码,论文取最后一层 last-token hidden state 作为 pooled 表示。 -
z_m:因子m的 L2 归一化多模态表示。 -
z_content:内容语义向量。 -
z_creative:创意属性向量。 -
||z_m||_2=1:归一化约束,便于后续相似度学习与量化。
训练时,每个因子使用对比损失,同时用正交约束减少内容与创意的泄漏。
L m = − log exp ( s i m ( z m i , z m j ) / τ ) ∑ k exp ( s i m ( z m i , z m k ) / τ ) \mathcal{L}_m = -\log \frac{\exp(\mathrm{sim}(z_m^i, z_m^j)/\tau)}{\sum_k \exp(\mathrm{sim}(z_m^i, z_m^k)/\tau)} Lm=−log∑kexp(sim(zmi,zmk)/τ)exp(sim(zmi,zmj)/τ)
变量说明:
-
L_m:因子m的对比学习损失。 -
z_m^i:batch 内第i个样本在因子m上的表示,shape 为R^d。 -
z_m^j:z_m^i的正样本表示,shape 为R^d。 -
z_m^k:候选样本表示,包含正样本和负样本。 -
sim(·,·):向量相似度函数。 -
τ:温度系数,用于控制 softmax 分布尖锐程度。
L o r t h = ∥ z c o n t e n t ⊤ z c r e a t i v e ∥ 2 2 \mathcal{L}{orth} = \| z{content}^{\top} z_{creative} \|_2^2 Lorth=∥zcontent⊤zcreative∥22
变量说明:
-
L_orth:内容表示与创意表示的正交约束。 -
z_content ∈ R^d:内容语义向量。 -
z_creative ∈ R^d:创意属性向量。 -
z_content^T z_creative:两类表示的内积;值越小,跨因子泄漏越少。
L = L c o n t e n t + γ 1 L c r e a t i v e + γ 2 L o r t h \mathcal{L} = \mathcal{L}{content} + \gamma_1 \mathcal{L}{creative} + \gamma_2 \mathcal{L}_{orth} L=Lcontent+γ1Lcreative+γ2Lorth
变量说明:
-
L:Disentangled Semantic Video Encoder 的总训练目标。 -
L_content:内容因子的对比损失。 -
L_creative:创意因子的对比损失。 -
γ_1:创意因子损失权重。 -
γ_2:正交约束权重。
3.1.2 离散语义量化
连续表示 z_m 通过 Residual Quantization K-Means 独立量化,得到适合 GRM 自回归预测的离散 code 序列。
e m = ∑ l = 1 L c m l ( s m l ) ≈ z m , e m ∈ R d e_m = \sum_{l=1}^{L} c_m^l(s_m^l) \approx z_m, \quad e_m \in \mathbb{R}^{d} em=l=1∑Lcml(sml)≈zm,em∈Rd
变量说明:
-
e_m:因子m的量化重构向量,shape 为R^d。 -
c_m^l(·):因子m在第l层的 codebook lookup 函数。 -
s_m^l:因子m在第l层的离散 code index,取值范围为[1,8192]。 -
L:残差量化层数。 -
z_m ∈ R^d:被量化的原始连续表示。
D - S I D s = s c o n t e n t 1 : L ; s c r e a t i v e 1 : L D\text{-}SIDs = s_{content}\^{1:L}; s_{creative}\^{1:L} D-SIDs=scontent1:L;screative1:L
变量说明:
-
s_content^{1:L}:长度为L的内容 code 序列。 -
s_creative^{1:L}:长度为L的创意 code 序列。 -
[;]:序列拼接操作。 -
D-SIDs:长度为2L的离散语义序列,用作推荐与生成之间的统一 latent interface。
3.2 Generative Recommendation Model
模块作用:根据用户画像和历史行为,生成代表用户未来兴趣的 D-SIDs,而不是直接检索视频 ID。
输入:用户上下文 c_user,包含 profile 与多粒度行为序列;输出:长度为 2L 的兴趣 D-SIDs。
p ( D - S I D s ∣ c u s e r ) = ∏ t = 1 2 L p ( s t ∣ s < t , c u s e r ) p(D\text{-}SIDs \mid c_{user}) = \prod_{t=1}^{2L} p(s_t \mid s_{<t}, c_{user}) p(D-SIDs∣cuser)=t=1∏2Lp(st∣s<t,cuser)
变量说明:
-
c_user:用户上下文,包含年龄、性别、地区、设备类型等静态 profile,以及曝光、点击、观看时长、转化等历史行为。 -
s_t:第t个 SID token;当t≤L时属于内容 SIDs,当t>L时属于创意 SIDs。 -
s_<t:当前 token 之前已生成的 SID 前缀。 -
2L:完整 D-SIDs 序列长度。 -
p(s_t | s_<t,c_user):GRM 在用户上下文和历史 SID 前缀条件下预测下一个 SID 的概率。
论文附录说明 GRM 类似 GR4AD:SID token 先经稀疏 embedding table,再投影到 768 维 latent space;核心是 7 层 Transformer decoder,hidden size 768,FFN size 3072,12 attention heads,vocabulary size 8192,并使用 FlashAttention。
D - S I D s = E ( v ) → p ( D - S I D s ∣ c u s e r ) → v ^ = G ( D - S I D s ) D\text{-}SIDs = E(v) \rightarrow p(D\text{-}SIDs \mid c_{user}) \rightarrow \hat{v} = G(D\text{-}SIDs) D-SIDs=E(v)→p(D-SIDs∣cuser)→v^=G(D-SIDs)
变量说明:
-
E(v):把历史或目标视频编码为 D-SIDs 的编码器。 -
p(D-SIDs|c_user):用户兴趣的生成式建模分布。 -
G(·):后续由 Instruction Model 与 VGAs 组成的视频生成过程。 -
\hat{v}:按用户兴趣生成的新视频,不受固定内容池限制。
3.3 Instruction Model
模块作用:把离散 D-SIDs 翻译为可执行的镜头级视频制作指令,承接"推荐兴趣"与"可控生成"。
输入:D-SIDs 重构 embedding e_D-SIDs,可选商品/营销元数据 D_meta;输出:镜头级 instruction 序列 \hat{D}_{inst}。
教师监督来自 Gemini2.5 Pro 对视频和模板 prompt 的蒸馏。
D i n s t = G e m i n i ( v , P R O M P T i n s t ) = ( y 1 , y 2 , ... , y L i n s t ) D_{inst} = \mathrm{Gemini}(v, \mathrm{PROMPT}{inst}) = (y_1, y_2, \ldots, y{L_{inst}}) Dinst=Gemini(v,PROMPTinst)=(y1,y2,...,yLinst)
变量说明:
-
D_inst:目标镜头级脚本 token 序列。 -
v:输入视频。 -
PROMPT_inst:人工设计的 instruction 模板,用于约束教师模型生成镜头级描述。 -
y_t:第t个 instruction token。 -
L_inst:instruction 序列长度。
D-SIDs 先通过 reverse RQ-KMeans 重构成连续 embedding,再映射到 LLM 输入空间。
e D - S I D s = e c o n t e n t ; e c r e a t i v e ∈ R 2 × d e_{D\text{-}SIDs} = e_{content}; e_{creative} \in \mathbb{R}^{2 \times d} eD-SIDs=econtent;ecreative∈R2×d
变量说明:
-
e_content ∈ R^d:内容 SIDs 经 codebook 重构后的连续向量。 -
e_creative ∈ R^d:创意 SIDs 经 codebook 重构后的连续向量。 -
e_D-SIDs ∈ R^{2×d}:内容与创意两类向量的堆叠表示。
h D - S I D s = ϕ ( e D - S I D s ) ∈ R 2 × d ′ h_{D\text{-}SIDs} = \phi(e_{D\text{-}SIDs}) \in \mathbb{R}^{2 \times d'} hD-SIDs=ϕ(eD-SIDs)∈R2×d′
变量说明:
-
φ(·):可学习 projector。 -
h_D-SIDs:映射到 LLM 输入 embedding 空间后的 D-SIDs 表示。 -
d':Instruction Model 的 LLM hidden dimension。
Q m e t a = T ( D m e t a ) ∈ R L m e t a × d ′ Q_{meta} = T(D_{meta}) \in \mathbb{R}^{L_{meta} \times d'} Qmeta=T(Dmeta)∈RLmeta×d′
变量说明:
-
D_meta:可选元数据,例如商品信息、营销主题;无元数据时被 mask。 -
T(·):LLM 原生文本 tokenizer / embedding。 -
Q_meta:元数据 token embedding。 -
L_meta:元数据 token 长度。
D ^ i n s t = L L M ( h D - S I D s , Q m e t a ) \hat{D}{inst} = \mathrm{LLM}(h{D\text{-}SIDs}, Q_{meta}) D^inst=LLM(hD-SIDs,Qmeta)
变量说明:
-
LLM:论文中 Instruction Model 使用 Qwen3-8B。 -
\hat{D}_{inst}:模型生成的镜头级 production instructions,覆盖场景构图、镜头运动、时间节奏、电影化风格等。 -
h_D-SIDs与Q_meta:作为 prefix 条件输入 LLM。
L N T P = − ∑ t = 1 L i n s t log P ( y t ∣ y < t , h D - S I D s , Q m e t a ) \mathcal{L}{NTP} = -\sum{t=1}^{L_{inst}} \log P(y_t \mid y_{<t}, h_{D\text{-}SIDs}, Q_{meta}) LNTP=−t=1∑LinstlogP(yt∣y<t,hD-SIDs,Qmeta)
变量说明:
-
L_NTP:next-token prediction 损失。 -
y_t:教师脚本的第t个 token。 -
y_<t:前缀 token。 -
P(·):Instruction Model 的自回归 token 概率。 -
h_D-SIDs:用户兴趣 D-SIDs 的连续条件表示。 -
Q_meta:商品和营销元数据条件。
训练分三阶段:先冻结 LLM 只训练 projector,使 D-SIDs 对齐语言空间;再联合微调 projector 和 LLM;最后用 Section 2.5 的奖励优化进一步提升语义保真和可控指令生成。
3.4 Video Generation Agents
模块作用:用多智能体结构替代单体生成器,按视觉、音频、效果的依赖顺序完成广告视频制作。
输入:Instruction Model 生成的 \hat{D}_{inst}、工具描述 D_tool、历史 agent 输出 O_<t、当前角色 prompt;输出:最终生成视频 V。
RaG 把视频生成建模为顺序决策过程。
a t ∼ π θ ( a t ∣ S t ) , S t + 1 = P ( S t , a t ) a_t \sim \pi_\theta(a_t \mid S_t), \quad S_{t+1} = P(S_t, a_t) at∼πθ(at∣St),St+1=P(St,at)
变量说明:
-
S_t:第t步 agent 状态。 -
a_t:当前 agent 选择的动作,表示视觉、音频或效果生成意图。 -
π_θ:共享参数的 agent policy。 -
P(·):确定性状态转移算子,把当前动作结果写入下一状态。 -
S_{t+1}:执行动作后的新状态。
状态被序列化为共享 prefix 与阶段相关 token。
S t = D \^ i n s t ; D t o o l ; O \< t ; P R O M P T r o l e S_t = \\hat{D}_{inst}; D_{tool}; O_{\
变量说明:
-
\hat{D}_{inst}:Instruction Model 输出的镜头级指令,作为所有 agent 共享的核心条件。 -
D_tool:可用工具描述,包括内部 text-to-video、image-to-video 模型,以及外部音频合成和视觉效果 API。 -
O_<t:前序 agent 的角色 prompt 与输出累计上下文。 -
PROMPT_role:当前角色提示词,用于激活 visual、audio 或 effect agent。
三个子 agent 使用同一个 Qwen2.5-32B backbone,共享参数,仅靠 role prompt、tool mask 和上下文区分角色。
π θ ( a t ∣ S t ) = { π v i s u a l , π a u d i o , π e f f e c t } ( a t ∣ S t ) \pi_\theta(a_t \mid S_t) = \{\pi_{visual}, \pi_{audio}, \pi_{effect}\}(a_t \mid S_t) πθ(at∣St)={πvisual,πaudio,πeffect}(at∣St)
变量说明:
-
π_visual:Visual Planning Agent,生成分镜、布局和时间边界。 -
π_audio:Audio Alignment Agent,生成与画面转场同步的 TTS 和 BGM。 -
π_effect:Artistic Effect Enhancement Agent,添加字幕、视觉特效、转场和 action bar。 -
θ:共享 backbone 参数。
三类 intent 由统一生成算子合成为最终视频。
V = G ( I v i s u a l , I a u d i o , I e f f e c t ) V = G(I_{visual}, I_{audio}, I_{effect}) V=G(Ivisual,Iaudio,Ieffect)
变量说明:
-
I_visual:视觉规划输出,包含 clip-level storyboard、scene segments、layout configurations、temporal boundaries。 -
I_audio:音频对齐输出,包含 speech、music 与场景转场的同步策略。 -
I_effect:艺术效果增强输出,包含 subtitles、visual effects、transitions、call-to-action elements。 -
G(·):统一视频生成算子。 -
V:最终生成的视频。
VGAs 采用 bounded reflection loop,按 Observe→Think→Act 迭代,最多两轮;同时由于 O_<t append-only,后续 agent 可复用前序 token 的 KV-cache,从而降低每次请求的增量推理成本。
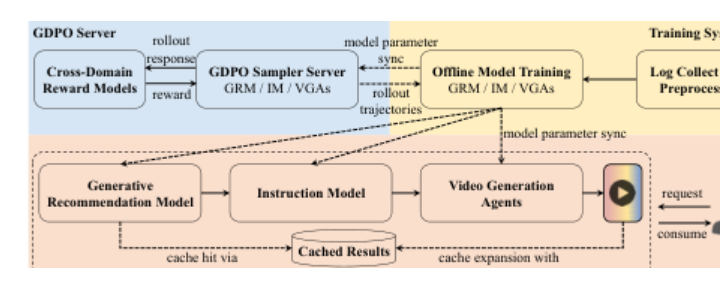
3.5 Latency-Aware Serving
模块作用:把高延迟视频生成接入实时推荐系统,同时控制成本。
系统将 GRM 放在线上实时链路,把 D-SIDs 编码、IM 和 VGAs 放在 nearline 链路。服务时围绕 content-SIDs 与 creative-SIDs 的缓存命中分两类处理:
-
content-SIDs 命中: 如果 creative-SIDs 也命中,直接返回缓存视频;如果只命中内容语义,先返回内容一致的视频,同时异步调度缺失创意变体。
-
content-SIDs 未命中: 返回最近邻 SIDs 对应的视频以满足实时消费,同时将未覆盖 SIDs 加入优先生成队列。
论文报告的生产延迟:D-SIDs nearline 约 4s,GRM online 约 100ms,IM nearline 约 2.5s,VGAs nearline 约 180s;因此缓存与 nearline 生成是工业化部署的必要条件。
训练目标/损失
RaG 的训练目标由三层组成:D-SIDs 表示学习损失、Instruction Model 的 next-token prediction 损失、以及 SCRL 的跨域奖励优化。前两类损失已在模块小节中给出,这里集中解释 SCRL。
4.1 跨域奖励定义
SCRL 使用三类奖励:视频质量、兴趣对齐、用户反馈。
R q u a l i t y = R v i s u a l + R a u d i o + R e f f e c t R_{quality} = R_{visual} + R_{audio} + R_{effect} Rquality=Rvisual+Raudio+Reffect
变量说明:
-
R_quality:视频质量总奖励。 -
R_visual:视觉质量奖励,评估审美、时空一致性、运动稳定性。 -
R_audio:音画对齐奖励,覆盖 TTS 同步与 BGM 一致性。 -
R_effect:效果质量奖励,评估字幕、高亮词、action bar 等视觉效果与画面的匹配。
R a l i g n = R i n s t r - a l i g n + R r e p - a l i g n R_{align} = R_{instr\text{-}align} + R_{rep\text{-}align} Ralign=Rinstr-align+Rrep-align
变量说明:
-
R_align:兴趣对齐总奖励。 -
R_instr-align:GRM 生成 D-SIDs 与 IM 生成 instructions 的语义一致性奖励。 -
R_rep-align:GRM 生成 D-SIDs 与最终生成视频表示之间的语义相似度奖励。
R f e e d b a c k = R r e a l + R p r e d R_{feedback} = R_{real} + R_{pred} Rfeedback=Rreal+Rpred
变量说明:
-
R_feedback:用户反馈奖励,是 SCRL 的主目标。 -
R_real:真实稀疏反馈,包括 click、like、collect、purchase 等。 -
R_pred:线上 ranking model 估计的稠密 engagement signal,用于缓解真实反馈稀疏和延迟问题。
4.2 约束式策略优化
论文不把多个 reward 简单加权,而是把用户反馈作为主目标,把兴趣对齐和视频质量作为约束。
R ( y i ) = R f e e d b a c k ( y i ) − ∑ c ∈ { a , q } λ c ( t ) R e L U ( τ c − R c ( y i ) ) R(y_i) = R_{feedback}(y_i) - \sum_{c \in \{a,q\}} \lambda_c(t)\mathrm{ReLU}(\tau_c - R_c(y_i)) R(yi)=Rfeedback(yi)−c∈{a,q}∑λc(t)ReLU(τc−Rc(yi))
变量说明:
-
y_i:policyπ_θ(·|x)对输入上下文x采样出的第i个候选。 -
R(y_i):用于策略优化的约束式组合奖励。 -
R_feedback(y_i):候选视频的用户反馈奖励。 -
c ∈ {a,q}:约束通道,a表示 interest alignment,q表示 video quality。 -
R_c(y_i):候选在约束通道c上的奖励。 -
τ_c:通道c的目标阈值,由 SFT baseline 的 held-out 分布校准。 -
λ_c(t):第t步的 Lagrangian multiplier,非负,并通过 PID-controlled rule 根据约束违反程度动态更新。 -
ReLU(τ_c - R_c(y_i)):只有当奖励低于阈值时才产生惩罚。
阈值按 baseline 分布设置。
τ c = μ c b a s e + k c σ c b a s e \tau_c = \mu_c^{base} + k_c \sigma_c^{base} τc=μcbase+kcσcbase
变量说明:
-
μ_c^{base}:SFT baseline 在验证集上通道c奖励的均值。 -
σ_c^{base}:SFT baseline 在验证集上通道c奖励的标准差。 -
k_c:严格度系数。论文中 VGAs 对τ_a与τ_q都取k_c=1.1;IM 对τ_a取k_a=0.8;GRM 对τ_a取k_a=0.3,且 IM/GRM 省略视频质量约束。
GDPO 对候选组内 reward 做相对优势归一化。
A i = R ( y i ) − μ ( Y ) σ ( Y ) + ϵ A_i = \frac{R(y_i) - \mu(Y)}{\sigma(Y) + \epsilon} Ai=σ(Y)+ϵR(yi)−μ(Y)
变量说明:
-
A_i:候选y_i的 group-relative advantage。 -
Y={y_1,...,y_K}:同一输入上下文下采样出的候选集合。 -
μ(Y):候选集合奖励均值。 -
σ(Y):候选集合奖励标准差。 -
ε:数值稳定项,避免分母为 0。
最终策略目标锚定 frozen SFT policy π_ref。
L G D P O = − E ( x , y i ) A i log π θ ( y i ∣ x ) π r e f ( y i ∣ x ) \mathcal{L}{GDPO} = -\mathbb{E}{(x,y_i)}\leftA_i \\log \\frac{\\pi_\\theta(y_i\|x)}{\\pi_{ref}(y_i\|x)}\\right LGDPO=−E(x,yi)Ailogπref(yi∣x)πθ(yi∣x)
变量说明:
-
L_GDPO:GDPO 策略优化损失。 -
x:输入上下文,可对应用户兴趣、D-SIDs 条件或生成任务条件。 -
y_i:候选输出。 -
π_θ:待优化策略。 -
π_ref:冻结的 SFT 参考策略。 -
A_i:候选的组相对优势。 -
论文实现中保留 importance-sampling ratio clipping 与 KL regularization,只是在正文公式中省略。
实验分析
5.1 在线 A/B 测试
实验部署在快手真实广告平台,重点评估 D-SIDs 对生成式推荐的贡献,以及 SID-driven personalized video generation 带来的额外收益。指标为相对生产基线的广告收入提升。
| 方法 | Rev. vs. DLRM baseline | Rev. vs. GRM baseline |
|---|---|---|
| DLRM baseline | -- | -- |
| GRM baseline | +3.526% | -- |
| GRM + D-SIDs | +4.460% | +0.902% |
| RaG: GRM + D-SIDs + IM + VGAs + SCRL | +5.462% | +1.870% |
结论:D-SIDs 将 GRM 相对 DLRM 的收益从 +3.526% 提升到 +4.460%,说明内容语义与创意语义解耦能改进兴趣 latent space;完整 RaG 相比强 GRM baseline 仍提升 +1.870%,这部分收益来自直接生成个性化视频,而不是固定池检索。
5.2 D-SIDs 质量
论文从 embedding 语义检索质量和 SID 离散化质量两方面评估 D-SIDs。
| 方法 | R@1 | R@5 | R@10 | Cpr. / Col. |
|---|---|---|---|---|
| VLM2Vec-V2 | 0.485 | 0.690 | 0.756 | -- |
| QARM | 0.541 | 0.812 | 0.893 | 1.14 / 18.24% |
| Qwen2.5-VL-7B | 0.769 | 0.948 | 0.977 | -- |
| Ours: D-SIDs | 0.896 | 0.985 | 0.994 | 1.02 / 2.62% |
| Improvement | +16.5% | +3.9% | +1.7% | -10.5% / -15.6pp |
结论:D-SIDs 在 R@1 上相比最强 baseline Qwen2.5-VL-7B 提升 +16.5%;相比 QARM,compression error 从 1.14 降到 1.02,collision rate 从 18.24% 降到 2.62%,说明解耦量化后的 SID 空间更紧凑、更少冲突。
5.3 VGAs 与工作流 baseline 对比
| 指标 | Workflow Baseline | VGAs | Improvement |
|---|---|---|---|
| Automated Score | 62.4 / 62.0 | 71.3 / 76.0 | +14.3% / +22.6% |
| Automated Win Rate | 28.7% | 70.1% | +41.4pp |
| User Study Win Rate | 34.4% | 52.9% | +18.5pp |
结论:相比固定顺序的"instruction generation → rough-cut → fine-cut"工作流,VGAs 的层级推理与 bounded reflection 提升了跨模态规划一致性;两轮以内反思在保持相近延迟的同时显著提升自动评价和人工偏好。
5.4 奖励消融
| 奖励组件 | 评估指标 | Base → Ours |
|---|---|---|
| R_visual | Automated Win Rate | 29.3% → 50.7% (+21.4pp) |
| R_audio | Automated Win Rate | 24.0% → 48.0% (+24.0pp) |
| R_effect | Automated Win Rate | 22.7% → 41.3% (+18.6pp) |
| R_visual + R_audio + R_effect | Automated Win Rate | 37.3% → 56.0% (+18.7pp) |
| R_align | Interest Alignment Score | 0.707 → 0.828 (+17.1%) |
结论:视觉、音频、效果三类质量奖励各自能提升对应质量指标;加入兴趣对齐奖励后,Interest Alignment Score 从 0.707 提升到 0.828,说明质量奖励和对齐奖励互补:前者保证感知质量,后者保证生成内容确实贴合用户兴趣。
5.5 Instruction Model 配置与效率
Instruction Model 的 decoding fidelity 随训练数据和模型容量增加而提升:8B 模型从 100K 样本的 0.7760 提升到 1M 样本的 0.8096;32B 模型 1M 样本达到 0.8212。论文最终采用 8B + 1M 作为默认配置,原因是它在生成保真度和部署成本之间更平衡。
| 组件 | 部署方式 | Latency |
|---|---|---|
| D-SIDs | Nearline | 约 4s |
| GRM | Online | 约 100ms |
| IM | Nearline | 约 2.5s |
| VGAs | Nearline | 约 180s |
结论:GRM 可满足实时推荐链路,VGAs 是主要延迟瓶颈;论文通过 nearline 生成、SID-indexed cache、KV-cache reuse 和层级服务策略把高成本生成系统接入实时广告推荐。
优势与局限
优势:
-
统一接口清晰: D-SIDs 把视频表示拆成内容语义与创意语义,既能被 GRM 预测,也能被生成链路消费,解决推荐与视频生成之间表示不一致的问题。
-
从检索范式转向生成范式: RaG 不再受固定内容池限制,能根据用户兴趣直接生成个性化视频;在线 A/B 相比强 GRM baseline 仍有 +1.870% 广告收入提升。
-
工业部署路径完整: 论文不是只提出模型结构,还给出了 online GRM、nearline IM/VGAs、SID 缓存、KV-cache reuse、latency-aware serving 的生产架构。
-
奖励设计符合业务目标: SCRL 把用户反馈作为主目标,把兴趣对齐和视频质量作为约束,避免简单 reward 加权导致目标冲突或尺度不稳。
-
多智能体生成更可控: VGAs 将视觉规划、音频对齐和艺术效果拆开,但共享 backbone,兼顾专业分工与推理复用。
局限:
-
仍非实时生成: 论文明确指出 RaG 当前服务 nearline 而不是 real time;VGAs 约 180s,是主导延迟瓶颈。
-
生成系统复杂度高: RaG 依赖 D-SIDs 编码、GRM、IM、VGAs、SCRL、缓存和服务调度多个模块,生产维护成本高于传统召回排序链路。
-
视频生成成本仍需摊销: 系统依赖 SID-indexed cache 和异步生成队列,说明对长尾、冷启动或频繁变化创意的覆盖存在成本压力。
-
评估集中在广告场景: 主要在线收益来自快手广告平台,论文未证明同样收益可直接迁移到非广告短视频推荐或其他内容生态。
-
论文后续方向明确依赖加速: 作者提出未来需要将 Instruction Model 融入 VGAs,并通过模型蒸馏和推理优化进一步加速,才能走向 on-the-fly personalized generation。