LeRobot:端到端机器人学习的全栈开源框架------从硬件驱动到模型训练部署的完整闭环
论文信息
标题 :LeRobot: An Open-Source Library for End-to-End Robot Learning
会议 :ICLR 2026
单位 :Hugging Face、University of Oxford
代码 :https://github.com/huggingface/lerobot
论文:https://arxiv.org/pdf/2602.22818.pdf
一、引言:搞机器人学习,为啥总在重复"造轮子"?
如果你曾经想入门机器人学习,大概率踩过这套连环坑:凑钱买了机械臂,发现没有现成Python驱动,得自己啃手册写串口通信;想跑最新的ACT算法,发现作者代码和你的硬件不兼容,改数据格式改到秃头;好不容易训完模型,部署时又发现模型推理太慢,机器人卡成PPT,连个方块都夹不稳。
一句话总结行业现状:机器人学习的生态太碎片化了。硬件驱动、数据采集、算法实现、部署推理,每一层都是各自为战的小圈子,换个机器人就得重写半套代码,大量精力都花在了工程适配而不是算法研究上。就像你买了台电脑,得自己焊主板、自己写操作系统、自己编译浏览器,最后才能上网------效率低到离谱。
而LeRobot这篇工作,就是冲着解决这个痛点来的。它做了机器人学习界的"通用操作系统":从最底层的电机控制,到中间的数据集格式,再到上层的SOTA算法和部署推理,一整套全给你打通了。不管你用的是几百块的入门机械臂,还是几十万的人形机器人,不管你想跑轻量的ACT还是大模型级别的π₀,都能用同一套API搞定。
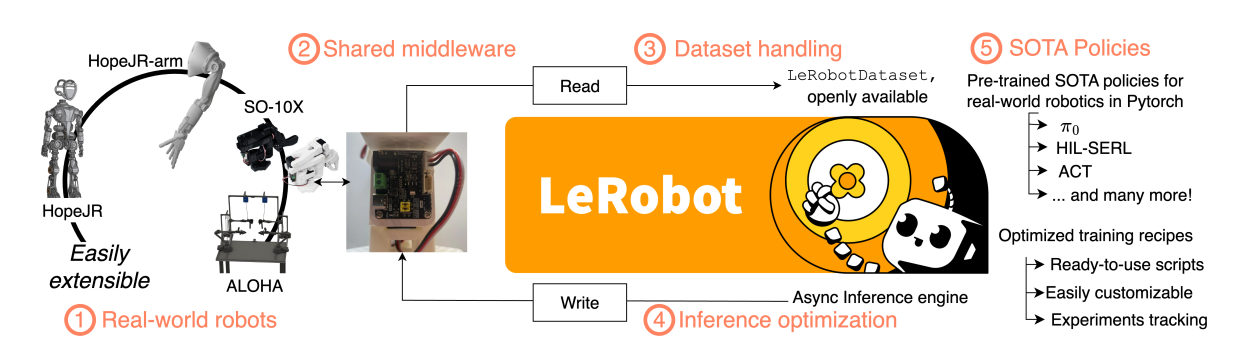
图1 LeRobot全栈架构总览
出处:原文Figure 1
解读:LeRobot纵向覆盖了机器人学习完整技术栈:底层是统一的硬件中间件,中间是标准化数据集与流式加载,上层是各类SOTA算法实现,最外层是优化的异步推理部署。开发者不用再在各个组件之间做适配,专注算法本身即可。
二、背景:从"手工建模"到"数据驱动"的范式革命
在讲具体设计之前,先快速梳理机器人领域的技术路线,这样你就能明白为什么这个库的出现这么重要。
2.1 两条技术路线:显式模型 vs 隐式模型
传统机器人走的是显式建模路线:工程师手动推导运动学公式、写碰撞检测算法、设计路径规划器,每一个细节都靠人精确定义。这套方法在工厂流水线这种结构化环境里很好用,但一放到家里、办公室这种非结构化环境就拉胯------你总不能给每个杯子、每双拖鞋都建个精确的3D模型吧?
而机器人学习走的是隐式建模路线:不用人手动写规则,直接给机器人看大量演示数据,让它自己从数据里学"观测→动作"的映射。数据越多、算力越强,效果就越好,和CV、NLP领域的缩放定律是完全一致的逻辑。
2.2 两大核心学习范式
机器人学习主要分两大流派,LeRobot把两者都原生支持了:
强化学习(RL):试错中成长
机器人自己在环境里探索试错,靠奖励信号优化策略,核心目标是最大化累计期望奖励:
maxπJ(π)=maxπEτ∼π∑t=0Tγtrt \max _{\pi} J(\pi)=\max {\pi} \mathbb{E}{\tau \sim \pi}\left\\sum_{t=0}\^{T} \\gamma\^{t} r_{t}\\right πmaxJ(π)=πmaxEτ∼πt=0∑Tγtrt
符号解释:
- J(π)J(\pi)J(π):策略π\piπ的期望累计奖励,是我们要最大化的优化目标
- π\piπ:机器人的策略函数,输入观测状态、输出控制动作
- τ\tauτ:一条完整的交互轨迹,包含从任务开始到结束的所有状态、动作和奖励
- Eτ∼π\mathbb{E}_{\tau \sim \pi}Eτ∼π:对所有遵循策略π\piπ生成的轨迹求数学期望
- TTT:单条轨迹的最大时间步数
- γ\gammaγ:折扣因子,取值范围0,10,10,1,越远期的奖励权重越低,引导机器人尽快完成任务
- rtr_trt:第ttt个时间步机器人获得的即时奖励
通俗解释:这就像训狗狗做任务,做对了给零食(奖励rrr),反复试错之后,狗狗就会学会能拿到最多零食的动作序列。强化学习就是机器人版的"试错学习"。
LeRobot中支持HIL-SERL、TD-MPC等强化学习算法,适合有真实环境交互条件的场景。
模仿学习(IL):跟着专家学
更常用的是行为克隆(Behavioral Cloning, BC):直接学习人类专家的演示数据,不用设计奖励函数,也不用机器人自己瞎探索,安全又高效。核心是学习一个条件概率分布:
p(a∣s) p(a | s) p(a∣s)
符号解释:
- ppp:概率分布函数
- aaa:动作向量,比如机械臂的6个关节角度、夹爪开合度
- sss:观测状态,比如摄像头画面、关节位置传感器读数
- p(a∣s)p(a|s)p(a∣s):给定当前观测sss时,输出最优动作aaa的条件概率分布
通俗解释:这就像驾校教练带你开车,你盯着教练的操作,记住"看到弯道就打方向、看到红灯就踩刹车"。行为克隆就是让AI模仿人类专家的演示,学会同样的操作逻辑。
LeRobot中支持从单任务的ACT、Diffusion Policy,到多任务大模型π₀、SmolVLA在内的多种模仿学习算法。
2.3 行业痛点:碎片化严重拖慢进度
道理都懂,但落地起来难就难在生态割裂:
- 硬件中间件不统一:每个牌子的机械臂都有自己的SDK,换个机器人就得重写控制代码;
- 数据集格式混乱:ROS bag、TFDS、自定义JSON......各家数据格式都不一样,想混用数据得写一堆解析脚本;
- 算法实现难复现:论文代码大多是"实验室专属",换个环境就跑不起来,更别说迁移到真实硬件上。
LeRobot的核心价值,就是把这三层全部打通,用一套统一的框架覆盖全流程。
三、LeRobot的四大核心组件
LeRobot的设计围绕三个关键词:低门槛、可扩展、可复现。整个库分为四大核心模块,我们逐个拆解。
3.1 统一硬件中间件:一套API玩转所有机器人
最底层也是最硬核的部分,是LeRobot做的统一硬件抽象层。不用再对着每个机器人的SDK啃文档,不管你用的是几百块的入门款,还是几万的专业款,都用同一套Python API就能控制。
支持的硬件平台
目前LeRobot已经支持了8款不同类型的机器人,从单臂、双臂到人形、移动操作都有,价格跨度极大:
表1 支持的机器人平台成本一览
出处:原文Table 1a
| 机器人型号 | 类型 | 单台成本(约) |
|---|---|---|
| SO-100/101 | 单/双臂机械臂 | ~225美元(双臂约550美元) |
| LeKiwi | 移动操作机器人 | ~230美元 |
| HopeJR-Arm | 人形手臂+灵巧手 | ~500美元 |
| Koch-v1.1 | 单/双臂机械臂 | ~670美元(双臂约1346美元) |
| ALOHA | 双臂操作机器人 | ~21000美元 |
解读:最惊艳的是入门级机器人的价格------一千多人民币就能买一套SO-100机械臂,学生党、小团队也能玩得起真实机器人学习,不用再靠仿真凑数。
通俗解释:这就像USB接口,不管你插U盘、鼠标还是键盘,都是同一个口。LeRobot的中间件就是机器人界的"通用接口",上层代码不用管底下接的是什么牌子的电机。
中间件不仅能用来跑模型,还支持遥操作:你拿着主臂动,从臂就跟着动,用来采集演示数据特别方便。架构是高度可组合的,加新机器人只需要适配底层驱动,上层所有工具直接就能用。
3.2 LeRobotDataset:标准化的多模态机器人数据集
有了硬件,下一步就是采集数据。LeRobot设计了一套统一的数据集格式------LeRobotDataset,解决了机器人数据格式混乱的老大难问题。
格式设计核心特点
- 多模态原生支持:同时存储图像、关节角度、力传感器、任务文本描述等所有数据,不用分开存好几个文件;
- 自包含元数据:数据集自带机器人型号、采样帧率、传感器类型等信息,拿到手就能用,不用找配套说明文档;
- 流式加载支持:不用下载整个数据集,就能在线逐帧读取,小硬盘也能跑大数据集。
加载数据集的代码极简,几行就搞定:
python
from lerobot.datasets.lerobot_dataset import LeRobotDataset
from lerobot.datasets.streaming_dataset import StreamingLeRobotDataset
# 方式1:下载完整数据集到本地,支持随机访问
dataset = LeRobotDataset("lerobot/svla_so101_pickplace")
# 方式2:流式加载,边读边训,无需下载完整文件
dataset = StreamingLeRobotDataset("lerobot/svla_so101_pickplace")社区数据规模
这套格式推出之后,社区贡献爆发式增长。截至2025年9月,已经有超过16000个公开数据集,来自2200多位贡献者。不同机器人的社区数据量如下:
表2 主流机器人社区数据统计
出处:原文Table 1b
| 机器人型号 | 总下载量 | 数据集数量 | 总演示回合数 |
|---|---|---|---|
| Panda | 1,878,395 | 588 | 926,776 |
| xArm | 1,107,329 | 74 | 450,329 |
| WidowX | 832,177 | 100 | 214,117 |
| KUKA | 662,550 | 3 | 419,784 |
| SO-101 | 319,586 | 3,965 | 58,299 |
| SO-100 | 278,697 | 5,161 | 78,510 |
解读:Panda和xArm作为学术圈常用的工业级机械臂,总下载量最高;而SO-100/101虽然总下载量不算顶尖,但数据集数量最多------说明大量个人开发者和小团队在用低价机器人贡献数据,真正实现了"全民参与"。
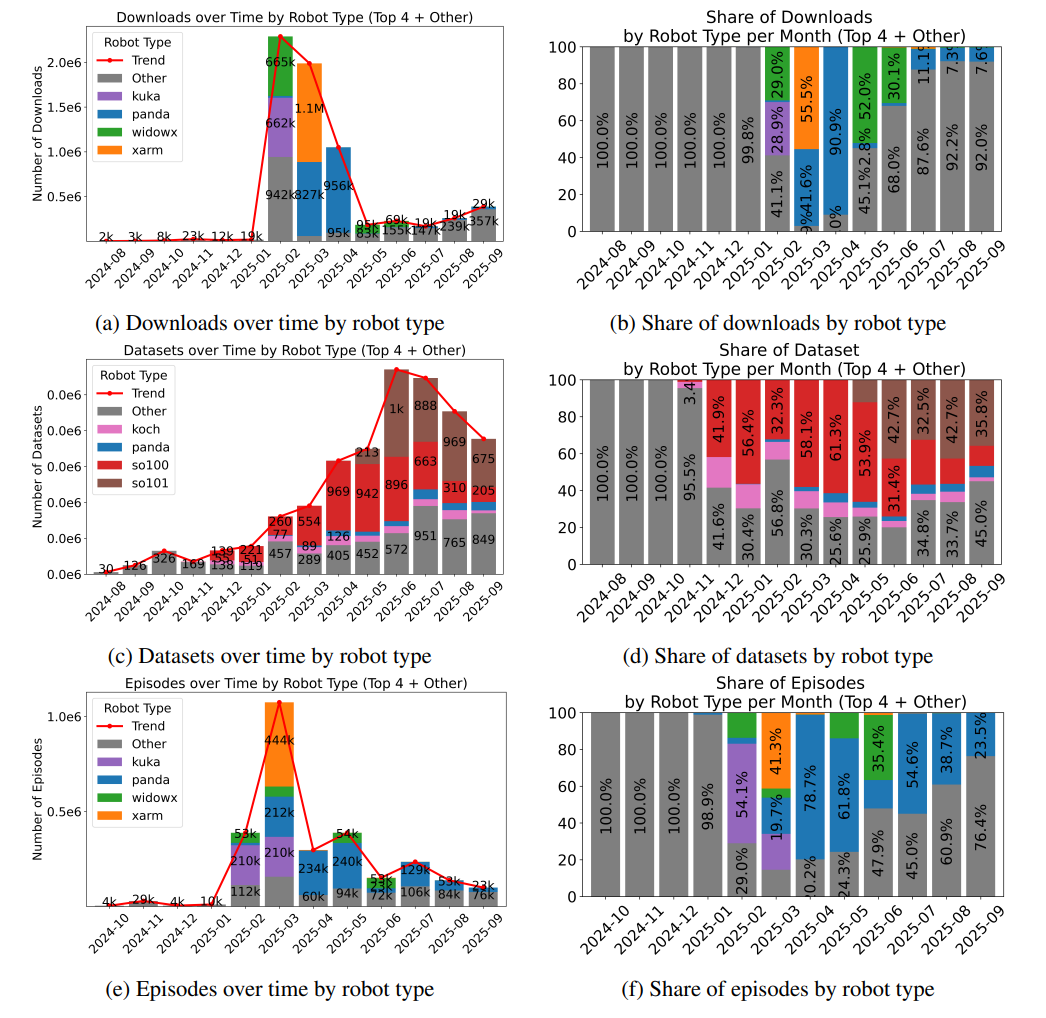
图2 社区数据集增长趋势
出处:原文Figure 5
解读:不管是下载量、数据集数量还是总回合数,都保持着高速增长。尤其是SO系列低价机器人的数据集占比超过50%,说明低门槛硬件+统一格式,极大地释放了社区的创造力。
通俗解释:这就像当年ImageNet统一了图像数据集格式,大家都按同一个标准生产数据,数据就能凑到一起训大模型。LeRobotDataset就是机器人领域的"ImageNet格式"。
3.3 算法库:开箱即用的SOTA模型
有了数据,下一步就是训模型。LeRobot集成了当前主流的机器人学习算法,纯PyTorch实现,和数据集格式无缝对接,不用自己写数据加载逻辑。
支持的算法覆盖两大范式,分类如下:
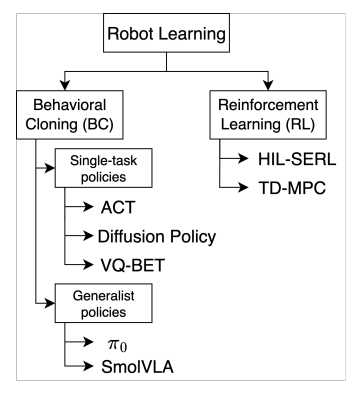
图3 LeRobot支持的算法体系
出处:原文Figure 6
解读:算法分为模仿学习和强化学习两大分支。模仿学习又分单任务专用模型和多任务通用模型,覆盖从轻量到大规模的所有需求。
各模型性能基准测试
不同模型的参数量、内存占用、推理延迟差别很大,适合不同的场景。论文里做了详细的跨平台基准测试:
表3 各模型峰值内存占用(FP32精度)
出处:原文Table 2
| 模型 | 参数量 | CPU内存 | MPS内存 | RTX 4090显存 | A100显存 |
|---|---|---|---|---|---|
| ACT | 52M | 817.4MB | 462MB | 211.24MB | 211.24MB |
| Diffusion Policy | 263M | 1.22GB | 224MB | 1.12GB | 1.12GB |
| SmolVLA | 450M | 1.69GB | 555MB | 1.75GB | 1.75GB |
| π₀ | 3.5B | 4.13GB | 97MB | 13.32GB | 13.32GB |
表4 各模型平均推理延迟(单位:毫秒)
出处:原文Table 3
| 模型 | 参数量 | CPU | MPS | RTX 4090 | A100 |
|---|---|---|---|---|---|
| ACT | 52M | 182.3±40.8 | 42.7±10.1 | 5.0±0.06 | 13.8±0.4 |
| Diffusion Policy | 263M | - | 3453.8±39.3 | 369.8±0.2 | 613.9±10.2 |
| SmolVLA | 450M | 2028.5±302.6 | 721.8±57.7 | 99.2±1.2 | 278.8±1.9 |
| π₀ | 3.5B | - | - | 209.4±2.8 | 569.0±2.9 |
解读:
- ACT是绝对的性价比之王:52M参数,4090上推理只要5毫秒,也就是200Hz帧率,几十条演示就能训出不错的效果,是目前社区最火的模型;
- Diffusion Policy效果好但慢,10步去噪就要几百毫秒,适合对延迟不敏感的桌面操作任务;
- 大模型比如π₀,35亿参数,需要高端显卡才能跑,但能支持多任务、自然语言指令控制;
- 低配置设备(比如笔记本CPU)只能跑轻量模型,大模型会直接超时。
通俗解释:这就像买车,ACT是小飞度,省油、提速快、好停车,日常代步神器;π₀是重卡,拉得多、功能强,但得有A本、烧得起油,适合专业运输场景。
从社区数据看,ACT也是绝对的主流:上传的模型里ACT占比最高,下载量也遥遥领先。毕竟对大多数人来说,能快速在自己的小机械臂上跑通、看到效果,才是最实在的。
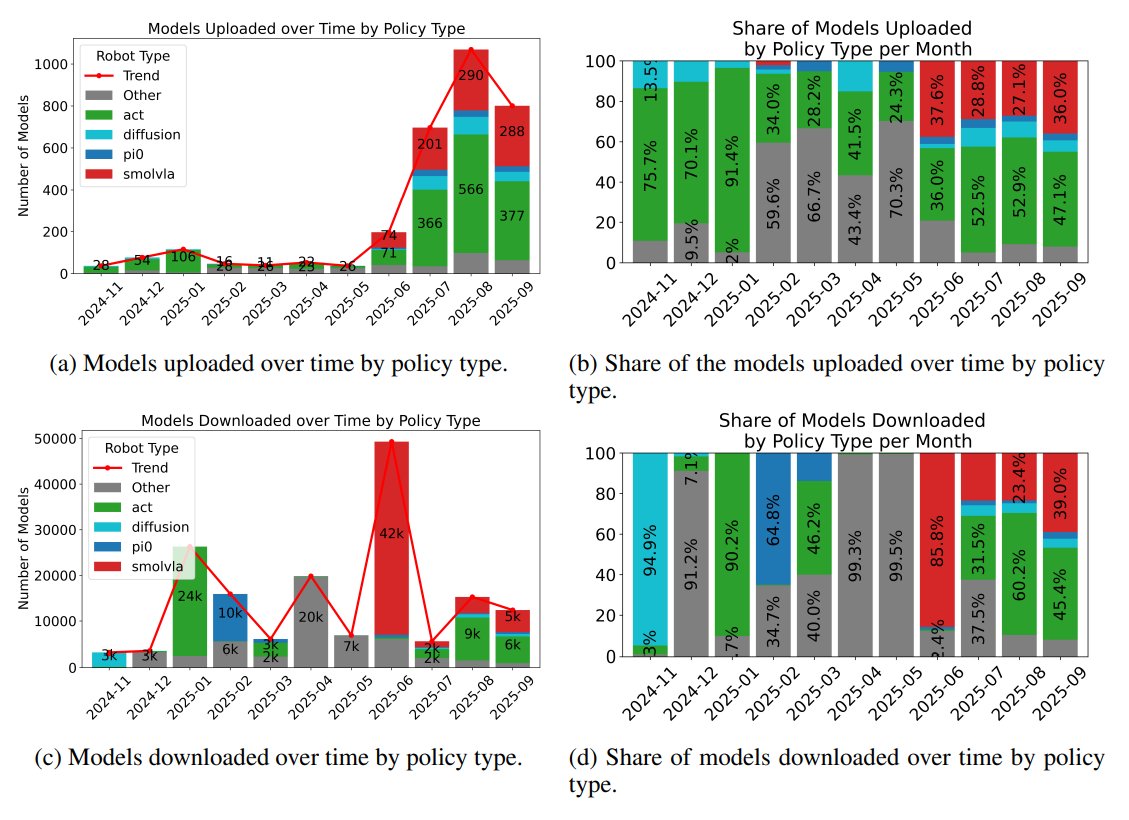
图4 社区模型上传与下载趋势
出处:原文Figure 7
解读:不管是上传的模型数量还是下载量,都在快速增长。ACT凭借轻量、易上手的特点,成为社区绝对的主流模型。
3.4 推理栈:异步解耦,让机器人丝滑不卡顿
模型训好了,部署又是一道坎。很多人都遇到过:模型推理要100毫秒,而机器人控制频率要求50Hz(20毫秒一次),直接跑的话机器人一卡一卡的,根本没法用。
LeRobot的推理栈专门解决了这个问题,核心是双重解耦 设计:
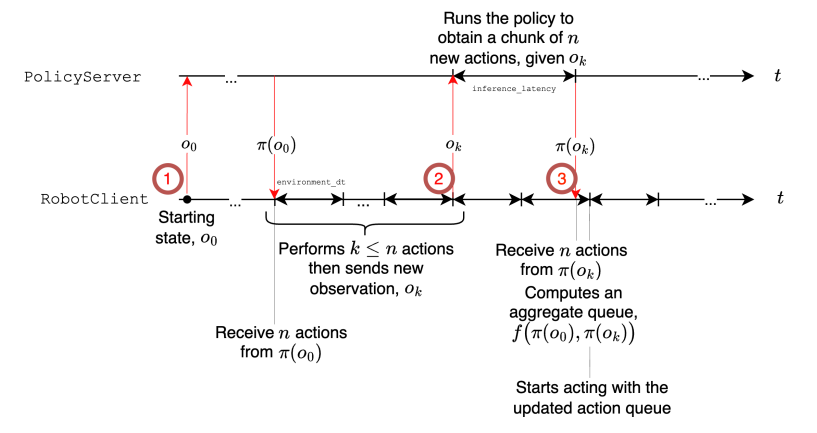
图5 异步推理架构示意
出处:原文Figure 8
解读:推理和控制在物理上可以分开跑在两台机器上,逻辑上用生产者-消费者模式异步执行。推理端一次性预测未来H步的动作块,控制端按固定频率逐个取用,中间重叠的部分用聚合函数融合。
1. 物理解耦
模型推理可以跑在远程服务器上,通过网络把动作发给机器人。机器人本体不用带高性能显卡,靠个小单片机就能跑控制,极大降低了机器人本体的成本和重量。
2. 逻辑解耦
用动作块(action chunk) + 生产者-消费者模式:
- 推理端(生产者):一次性预测未来H步的动作序列,扔到队列里;
- 控制端(消费者):按固定的控制频率,从队列里取动作执行;
- 两边异步跑,推理慢一点也没关系,只要队列里有动作,机器人就不会卡顿。
而且重叠的动作块还可以用自定义的聚合函数融合,比如滑动平均,让动作更平滑。
通俗解释:这就像视频网站的"预加载":你看第10秒的时候,后台已经在下载第20秒的内容了,所以不会卡。机器人控制也是一样,执行当前动作的时候,模型已经在算后面几步的动作了,全程丝滑不卡顿。
四、仿真环境支持
虽然LeRobot主打真实机器人,但也没忘了仿真------毕竟算法基准测试还是得靠仿真,公平又省钱。
目前原生支持两个主流仿真基准:
- LIBERO:侧重终身学习和任务泛化,有空间、物体、目标等不同维度的任务套件,用来测试模型的跨场景迁移能力;
- MetaWorld:侧重元学习和快速适配,包含50个不同的操作任务,有MT10/MT50多任务套件和ML10/ML45元学习套件。
有了仿真支持,你可以先在仿真里调算法、跑对比实验,效果好了再迁移到真实机器人上,省时间又省成本。
五、社区生态与真实案例
LeRobot最厉害的地方不是技术本身,而是它拉起了一个快速增长的开源社区,真正降低了机器人学习的门槛。
这里有个很有趣的真实案例:国外一名高中生,用攒零花钱买的SO-100机械臂,靠LeRobot一周就跑通了抓取方块的任务,还把自己的数据集和模型上传到了社区,被几百人下载使用。放在五年前,这是想都不敢想的事------那时候玩机器人学习,起码得是高校实验室的配置,个人根本玩不起。
从社区数据里能看到几个明显的趋势:
- 下沉趋势明显:低价机器人的数据集增长最快,机器人学习正在从高校实验室走向普通开发者;
- 算法向轻量化倾斜:社区里用得最多的不是最复杂的大模型,而是简单好用的ACT;
- 开源协作生效:大家贡献的数据和模型可以互相复用,形成了正向循环------数据越多,模型越好;模型越好,越多人愿意贡献数据。
六、局限与未来展望
当然,LeRobot也不是完美的,论文里自己也坦诚了几个核心局限:
- 硬件覆盖还不够全:目前只支持8款机器人,离"万物互联"还差得远,不过2025年一年就从3款涨到了8款,增长速度很快;
- 算法覆盖有待扩充:主流算法都有了,但还有很多小众算法没集成,靠社区贡献慢慢补;
- 推理优化空间大:现在还没做量化、图编译这些底层优化,大模型推理速度还有很大提升空间。
不过这些都是可以靠社区迭代解决的问题。LeRobot的架构设计得很开放,加新硬件、加新算法都很方便,未来大概率会像Hugging Face Transformers一样,成为机器人学习领域的事实标准。
七、核心代码示例
7.1 从零训练ACT模型(极简版)
用LeRobot训练一个ACT抓取模型,核心代码不到100行:
python
import torch
from lerobot.datasets import LeRobotDataset
from lerobot.policies import ACTPolicy
from torch.utils.data import DataLoader
# 1. 加载公开数据集
dataset = LeRobotDataset("lerobot/svla_so101_pickplace")
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4)
# 2. 初始化ACT策略网络
policy = ACTPolicy(
state_dim=14, # 机器人状态维度(关节角度+夹爪状态)
action_dim=7, # 动作维度
hidden_dim=512,
n_heads=8,
n_layers=4,
chunk_size=100, # 单次预测的动作块长度
)
optimizer = torch.optim.Adam(policy.parameters(), lr=1e-4)
# 3. 训练循环
policy.train()
for epoch in range(100):
total_loss = 0.0
for batch in dataloader:
# 组装观测:图像 + 机器人关节状态
observation = {"image": batch["image"], "state": batch["state"]}
action = batch["action"]
# 前向传播计算损失
loss = policy.compute_loss(observation, action)
# 反向传播更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch}, 平均损失: {total_loss / len(dataloader):.4f}")
# 4. 保存训练好的模型
torch.save(policy.state_dict(), "act_pickplace.pt")7.2 真实机器人部署推理
部署到SO-101真实机械臂上,也是几十行代码搞定:
python
import torch
from lerobot.robots import SO101Robot
from lerobot.policies import ACTPolicy
from lerobot.inference import AsyncInferenceEngine
# 1. 连接真实机器人
robot = SO101Robot(ip="192.168.1.100", control_freq=50)
# 2. 加载训练好的策略模型
policy = ACTPolicy(state_dim=14, action_dim=7, chunk_size=100)
policy.load_state_dict(torch.load("act_pickplace.pt"))
policy.eval()
# 3. 启动异步推理引擎(推理与控制解耦)
engine = AsyncInferenceEngine(
policy=policy,
robot=robot,
chunk_size=100,
control_freq=50,
)
# 4. 运行完整任务回合
engine.run_episode(max_steps=1000)写在最后
LeRobot这篇工作最大的意义,不是提出了什么惊世骇俗的新算法,而是它把机器人学习的门槛拉到了前所未有的低度。
以前做机器人学习,你得是懂硬件、懂软件、懂算法的全栈工程师,一个人干一个团队的活;现在,哪怕你是个只会Python的学生,花一千多买个机械臂,装个LeRobot,一周就能跑通最新的算法。
就像当年Arduino让人人都能玩硬件、TensorFlow让人人都能玩深度学习一样,LeRobot正在让"人人都能玩机器人学习"变成现实。当足够多的人能参与进来,数据和模型的飞轮转起来,机器人技术的爆发可能比我们想象的来得更快。