参考https://www.rethink.fun/
来源
以这个仓库的源码为基准,这也是之前解读的教程的配套仓库,提供了一个基于transformer架构的LLM基础实现,可训练。
https://github.com/RethinkFun/DeepLearning/blob/master/chapter15/transformer.py
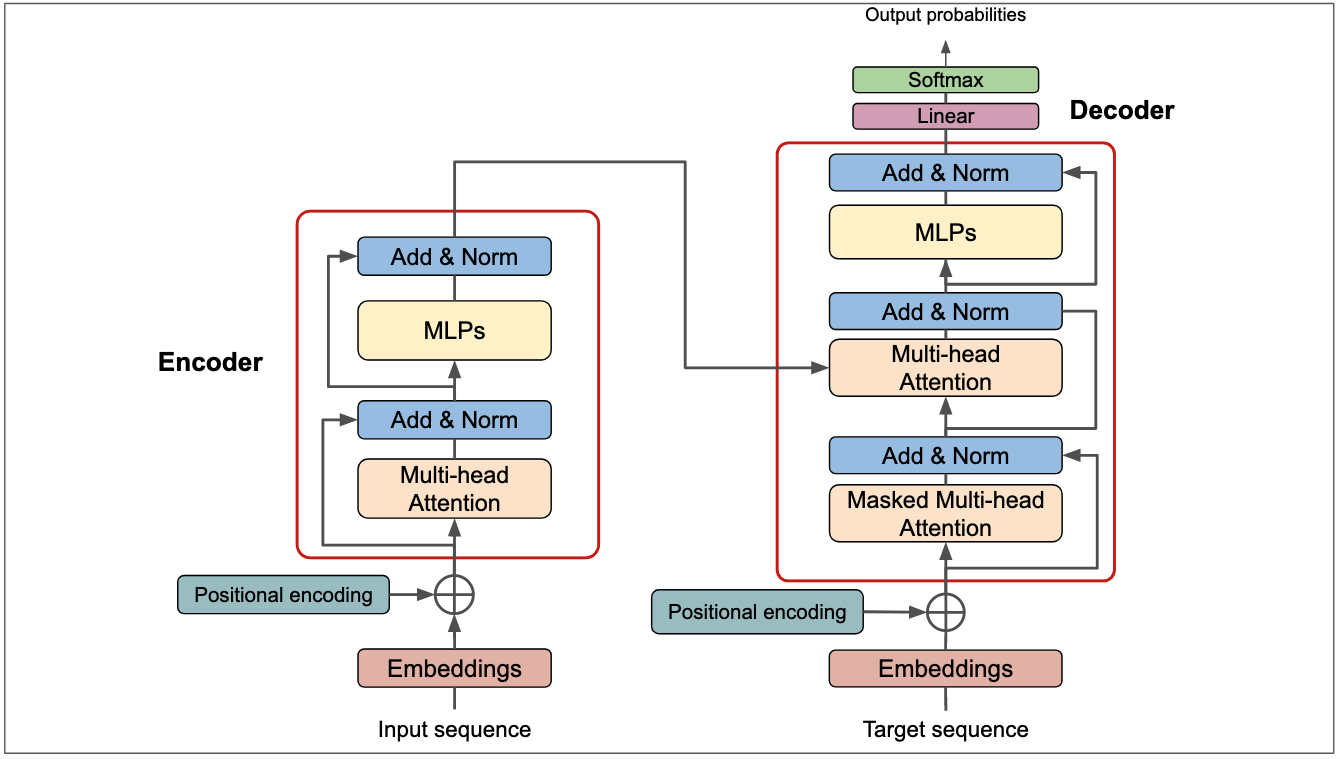
MHA
这个项目的代码高度模块化,我们一个个看。首先是最关键的多头注意力MHA模块
def attention(query, key, value, mask, dropout: nn.Dropout):首先实现一个标准注意力模块attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)这就是QKTdk\frac{QK^T}{\sqrt{d_k}}dk QKTattention_scores.masked_fill_(mask == 0, -1e9)训练时,为了防止模型作弊,用掩码让每个预测只能看到前缀,不能看到即将预测的token,处理方法是softmax前把需要盖住的位置设为负无穷,经过softmax注意力分数就变成0了,加权求和隐状态的时候权重为0的token不会产生影响,就实现了把后面的token盖住return (attention_scores @ value), attention_scores返回加权求和得到的隐状态,和注意力分数矩阵。注意这里的shape是(batch, h, seq_len, seq_len),这也能调用矩阵乘法吗?的答案是可以的,torch接口会默认最后两个维度是矩阵,前面的维度全部展平,看成一个batch批量计算矩阵乘法query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1, 2)forward里实现的是多头注意力,需要先对数据拆分成多头,这里用个view语法,传入我们想要的shape,类似于reshape操作。再把seqlen和head维度调换,这样可以看成batchhead个经典的seqlenhiddendim注意力,调用经典attentio计算x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)最后把多头的答案拼接起来,恢复
py
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model # embedding特征大小
self.h = h # 头的个数
# 确保d_model可以被h整除
assert d_model % h == 0, "d_model 不能被 h整除"
self.d_k = d_model // h # 每个头特征大小
self.w_q = nn.Linear(d_model, d_model, bias=False) # Wq
self.w_k = nn.Linear(d_model, d_model, bias=False) # Wk
self.w_v = nn.Linear(d_model, d_model, bias=False) # Wv
self.w_o = nn.Linear(d_model, d_model, bias=False) # Wo
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, mask, dropout: nn.Dropout):
# 获取d_k的值。
d_k = query.shape[-1]
# Q乘以K的转置,除以根号下d_k。
# (batch, h, seq_len, d_k) --> (batch, h, seq_len, seq_len)
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
# 给mask为0的位置填入一个很大的负值,这样在进行softmax,注意力就为0。
attention_scores.masked_fill_(mask == 0, -1e9)
# 进行softmax,归一化。得到注意力权重
# (batch, h, seq_len, seq_len)
attention_scores = attention_scores.softmax(dim=-1)
if dropout is not None:
attention_scores = dropout(attention_scores)
# 注意力权重乘以V,得到更新后的embedding。
# (batch, h, seq_len, seq_len) --> (batch, h, seq_len, d_k)
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
# 通过3个全连接层,获取Q、K、V矩阵
query = self.w_q(q) # (batch, seq_len, d_model) --> (batch, seq_len, d_model)
key = self.w_k(k) # (batch, seq_len, d_model) --> (batch, seq_len, d_model)
value = self.w_v(v) # (batch, seq_len, d_model) --> (batch, seq_len, d_model)
# 对多头进行拆分
# (batch, seq_len, d_model) --> (batch, seq_len, h, d_k) --> (batch, h, seq_len, d_k)
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1, 2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1, 2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1, 2)
# 计算注意力
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
# 多个头合并
# (batch, h, seq_len, d_k) --> (batch, seq_len, h, d_k) --> (batch, seq_len, d_model)
x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
# 乘以输出层
return self.w_o(x)LayerNorm层归一化
公式和batchnorm类似,可训练参数依然是αβ\alpha \betaαβ,但是归一化遍历的维度是每隔词向量,而不是原本的batch
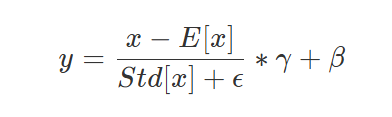
mean = x.mean(dim=-1, keepdim=True)mean方法默认会把一个维度压缩成一个元素,但这里所有位置都要减去mean,所以我们需要的是一个全部由均值组成的张量,所以强制保持原有维度。std标准差也同理- eps是为了防止分母为零,增加的小量,不更新
py
class LayerNormalization(nn.Module):
def __init__(self, features: int, eps: float = 10 ** -6) -> None:
super().__init__()
self.eps = eps
# 可学习权重
self.alpha = nn.Parameter(torch.ones(features))
# 可学习偏差
self.bias = nn.Parameter(torch.zeros(features))
def forward(self, x):
# x: (batch, seq_len, hidden_size)
# 保留维度来进行广播
mean = x.mean(dim=-1, keepdim=True) # (batch, seq_len, 1)
std = x.std(dim=-1, keepdim=True) # (batch, seq_len, 1)
# eps 是为了防止除0设置的很小的值
return self.alpha * (x - mean) / (std + self.eps) + self.bias位置编码
回忆一下,我们要实现的是这样的一个编码,都是三角函数,波长随着token位置增加而增加,同一个token内的各个维度波长相同
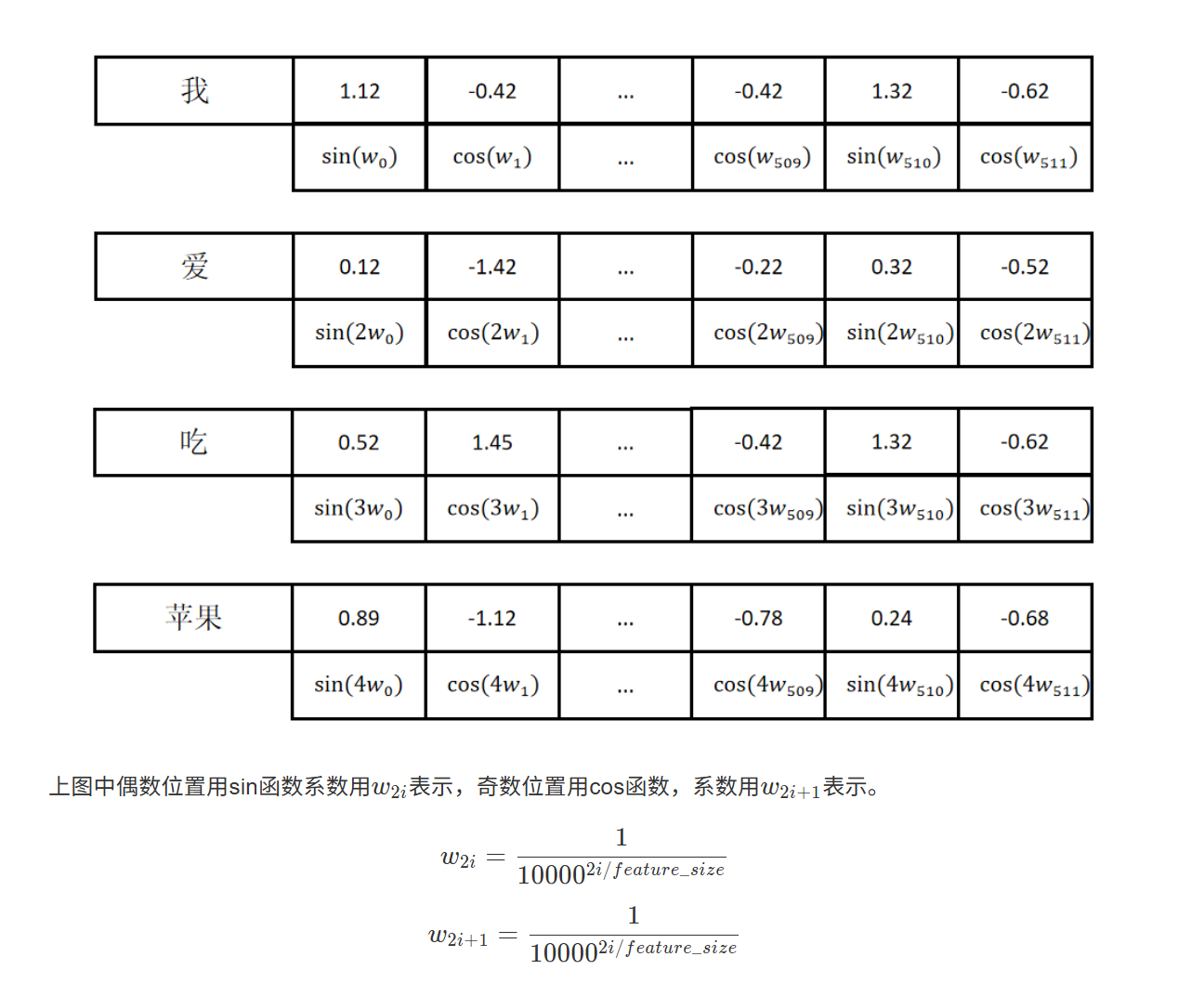
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)这先实现了一个一维,元素是一个等差数列的tensor,然后增加一个维度,把原本的每个元素变成一行,这是为了后面广播的时候自动拓展。div_term = torch.pow(10000.0, -torch.arange(0, d_model, 2, dtype=torch.float) / d_model) # (d_model / 2)计算相位的分母,注意到分母指数也是递增的,仍然生成一个等差数列。相邻奇偶位置的指数相同,所以只用生成长度是隐藏层一半的等差数列,这可以通过arrage里设置步长为2实现。最后套一个指数pe[:, 0::2] = torch.sin(position * div_term)套三角函数,对于所有sin,只存在于奇数位,我们用0::2的方式访问偶数位的切片,这其实就是一个srat:🔚:step,从偶数0开始,步长为2,不设置end默认遍历到最后。sin内部,是(seqlen,1),(1,dim)相乘。根据广播规则都会广播到(seqlen,dim),类似于向量外积。pe = pe.unsqueeze(0)增加一个维度,在0位置,这样shape相当于增加了一个batch=1,后面可以和所有数据累加时广播x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)forward里除了位置编码,还有残差链接,也就是先加上输入本身,这其实就是说位置编码是直接叠加在原始词向量上的。然后切片,是因为前面构造的pe张量,seqlen是变长的,这里为了能存下初始设置为maxseqlen,但这里我们加法时可能不是全都用得上,故结束设置为shape1也就是seqlen
py
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
# 创建一个空的tensor
pe = torch.zeros(seq_len, d_model) # (seq_len, d_model)
# 创建一个位置向量
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
# 计算分母
div_term = torch.pow(10000.0, -torch.arange(0, d_model, 2, dtype=torch.float) / d_model) # (d_model / 2)
# 偶数位调用sin
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数为调用cos
pe[:, 1::2] = torch.cos(position * div_term)
# 增加batch维度
pe = pe.unsqueeze(0) # (1, seq_len, d_model)
# 注册位置编码为一个buffer,这个tensor不会参与训练,但是会随同模型一起被保存或者迁移到GPU。
self.register_buffer('pe', pe)
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)
return self.dropout(x)FFN全连接层
两层线性层,中间有一个dropout,两层中间的维度不是d_model而是d_ff,一般会放大,得到更广的表示空间
py
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
# (batch, seq_len, d_model) --> (batch, seq_len, d_ff) --> (batch, seq_len, d_model)
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))Add&Norm
就是LayerNorm基础上增加一层残差链接,然后再增加一个dropout。并且支持传入一个sublayer,这会在norm后add前被调用。
py
class ResidualConnection(nn.Module):
def __init__(self, features: int, dropout: float) -> None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))Encoder编码器
首先是一个EncoderBlock,定义编码器的基本单元,把前面的FFN Norm Attn组装起来,然后多次重复
self.self_attention_block = self_attention_block解耦合,没有直接调用前面的类,而是用传进来的函数指针,这样后面更新FFN,Norm层了不用来修改这个编码器类,只用去修改调用接口时传入的函数指针self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(2)]定义多个残差连接,第一个传入的sublayer函数是自注意力,第二个传入的是FFN,这样就实现了Norm-Attn-Norm-FFN的传播for layer in self.layers:然后Encoder多次调用EncoderBlock,实现多次循环
py
class EncoderBlock(nn.Module):
def __init__(self, features: int, self_attention_block: MultiHeadAttentionBlock,
feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
# 定义多头自注意力模块
self.self_attention_block = self_attention_block
# 定义全连接模块
self.feed_forward_block = feed_forward_block
# 定义两个Add & Norm模块
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(2)])
def forward(self, x, src_mask):
# 第一个残差连接,跳过多头注意力模块
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
# 第二个残差连接,跳过全连接模块
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, features: int, layers: nn.ModuleList) -> None:
super().__init__()
# 传入的6个EncoderBlock
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, mask):
# 依次调用6个EncoderBlock
for layer in self.layers:
x = layer(x, mask)
# 输出前进行Layer Norm
return self.norm(x)Decoder解码器
仍然是先定义DecoderBlock,然后再多个重复,形成完整解码器
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(3)])这里有三层残差链接,传入的sublayer分别是自注意力,交叉注意力,FFN,和编码器相比多了一个交叉注意力x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))自注意力,qkv输入都是相同的x,也就是x自己和自己计算注意力。x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output,encoder_output, src_mask))交叉注意力,q还是解码器输入x,kv都来自编码器输出。也就是在翻译的时候,不止注意自己当前写的翻译(解码器处理),还注意原文(编码器处理)
py
class DecoderBlock(nn.Module):
def __init__(self, features: int, self_attention_block: MultiHeadAttentionBlock,
cross_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock,
dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
# 交叉注意力模块的Q矩阵来自Decoder,K,V矩阵来自Encoder的输出
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output,encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module):
def __init__(self, features: int, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)数据读入
用torch自带的dataset
for src, trg in zip(src_lines, trg_lines):把输入输出打包在一起构造数据,每一个数据最后都是(输入,输出)这样的src_ids = [BOS_ID] + self.src_tokenizer(src) + [EOS_ID]开头结尾增加特殊token,中间用tokenizer生成token序列if len(src_ids) <= max_len and len(trg_ids) <= max_len:后面为了能批量计算,会把长度不足的序列补到一个统一长度,所以设置一个最大序列长度,把不超过的补到这个长度,超过的数据不要。这个阈值不能太大,否则为了照顾少数超长序列,会给短序列加上过多的占位符,影响结果。def collate_fn(batch):一次处理一个batch的数据,打包src_pad = nn.utils.rnn.pad_sequence(src_batch, batch_first=True, padding_value=PAD_ID)用torch接口填充padding位,这里会自动对齐最长的序列,填充符号使我们定义的PAD_ID
py
class TranslationDataset(Dataset):
## 初始化方法,读取英文和中文训练文本。然后给每个句子前后增加<bos>和<eos>。 为了防止训练时显存不足,对于长度超过限制的
## 句子进行过滤。
def __init__(self, src_file, trg_file, src_tokenizer, trg_tokenizer, max_len=100):
with open(src_file, encoding='utf-8') as f:
src_lines = f.read().splitlines()
with open(trg_file, encoding='utf-8') as f:
trg_lines = f.read().splitlines()
assert len(src_lines) == len(trg_lines)
self.pairs = []
self.src_tokenizer = src_tokenizer
self.trg_tokenizer = trg_tokenizer
index = 0
for src, trg in zip(src_lines, trg_lines):
index += 1
if index % 100000 == 0:
print(index)
# 每个句子前边增加<bos>后边增加<eos>
src_ids = [BOS_ID] + self.src_tokenizer(src) + [EOS_ID]
trg_ids = [BOS_ID] + self.trg_tokenizer(trg) + [EOS_ID]
# 只保留输入和输出序列token数同时小于max_len的训练样本。
if len(src_ids) <= max_len and len(trg_ids) <= max_len:
self.pairs.append((src_ids, trg_ids)) # <-- 直接保存token id序列
def __len__(self):
return len(self.pairs)
def __getitem__(self, idx):
src_ids, trg_ids = self.pairs[idx]
return torch.LongTensor(src_ids), torch.LongTensor(trg_ids)
## 对一个batch的输入和输出token序列,依照最长的序列长度,用<pad> token进行填充,确保一个batch的数据形状一致,组成一个tensor。
@staticmethod
def collate_fn(batch):
src_batch, trg_batch = zip(*batch)
src_lens = [len(x) for x in src_batch]
trg_lens = [len(x) for x in trg_batch]
## 注意,Transformer里的tensor,设置batch_frist=True。
src_pad = nn.utils.rnn.pad_sequence(src_batch, batch_first=True, padding_value=PAD_ID)
trg_pad = nn.utils.rnn.pad_sequence(trg_batch, batch_first=True,padding_value=PAD_ID)
return src_pad, trg_pad, src_lens, trg_lens构造掩码
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, src_len)输入数据,对于填充位不计算注意力tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, tgt_len)输出同理tgt_sub_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=tgt.device)).bool() # (tgt_len, tgt_len)自回归训练时的掩码,生成一个下三角全1,其余全0矩阵,这样训练时可以让每次有效的仅仅是当前的前缀,当前预测到的位置后面的token注意力都无效,防止模型作弊
py
def create_mask(src, tgt, pad_idx):
# mask <pad> token for encoder.
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, src_len)
# mask <pad> token for decoder.
tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(2) # (batch, 1, 1, tgt_len)
tgt_len = tgt.size(1)
# decoder mask 当前token后边的token。
tgt_sub_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=tgt.device)).bool() # (tgt_len, tgt_len)
# decoder 同时mask <pad> token, 以及当前token后边的token。
tgt_mask = tgt_pad_mask & tgt_sub_mask # (batch, 1, tgt_len, tgt_len)
return src_mask, tgt_mask训练主函数
tgt_input = tgt[:, :-1]训练时输入给解码器的序列,不包含最后一个位置tgt_output = tgt[:, 1:]训练时的label也就是预期输出。不包含第一个位置,相当于向右错位一维。这样0,i的输入,label是ti+1,正好是我们想训练的。src_mask, tgt_mask = create_mask(src, tgt_input, pad_idx)这里需要我们前面构造的掩码,尤其是解码器自回归训练掩码,是个下三角矩阵,这样前向传播时,第i个token能看到tgt_input的前i个token,可以在不泄露i+1,n的token的前提下,让第i个token预测下一个token。这样我们可以同时训练0,00,10,2...的前缀作为输入,预测下一个token的输出。一句长度为n的话可以当成n组数据训练loss = criterion(output, tgt_output)这里output是前向传播结果,记录每个token的概率。而tgt_output是一个具体token id,这里交叉熵函数会把token id当成标签下标,和前面的概率向量计算交叉熵。
py
def train(model, dataloader, optimizer, criterion, pad_idx):
model.train()
total_loss = 0
step = 0
log_loss = 0 # 用于每100步统计
for src, tgt, src_lens, tgt_lens in dataloader:
step += 1
src = src.to(DEVICE)
tgt = tgt.to(DEVICE)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
src_mask, tgt_mask = create_mask(src, tgt_input, pad_idx)
optimizer.zero_grad()
encoder_output = model.encode(src, src_mask)
decoder_output = model.decode(encoder_output, src_mask, tgt_input, tgt_mask)
output = model.project(decoder_output)
output = output.reshape(-1, output.shape[-1])
tgt_output = tgt_output.reshape(-1)
loss = criterion(output, tgt_output)
loss.backward()
optimizer.step()
total_loss += loss.item()
log_loss += loss.item()
if step % 100 == 0:
avg_log_loss = log_loss / 100
print(f"Step {step}: Avg Loss = {avg_log_loss:.4f}")
log_loss = 0 # 重置每100步的loss计数
return total_loss / len(dataloader)
def main():
# 超参数
SRC_VOCAB_SIZE = 16000
TGT_VOCAB_SIZE = 16000
SRC_SEQ_LEN = 128
TGT_SEQ_LEN = 128
BATCH_SIZE = 2
NUM_EPOCHS = 10
LR = 1e-4
# 数据集加载
train_dataset = TranslationDataset('valid_en.txt', 'valid_zh.txt',tokenize_en, tokenize_cn)
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=train_dataset.collate_fn)
# 构建模型
model = build_transformer(SRC_VOCAB_SIZE, TGT_VOCAB_SIZE, SRC_SEQ_LEN, TGT_SEQ_LEN).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LR)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_ID)
for epoch in range(NUM_EPOCHS):
loss = train(model, train_dataloader, optimizer, criterion, PAD_ID)
print(f"Epoch {epoch+1}/{NUM_EPOCHS} - Loss: {loss:.4f}")
torch.save(model.state_dict(), "transformer.pt")推理主函数
with torch.no_grad():推理不需要反向传播,也就不需要梯度encoder_output = model.encode(src_tensor, src_mask)先计算一次解码器输出,后面重复使用for _ in range(max_len):不超过最大长度前一直生成decoder_output = model.decode(encoder_output, src_mask, trg_tensor, trg_mask)和训练时推理类似,也要传入前面生成的全部内容以及下三角maskpred_token = output.argmax(2)[:, -1].item()区别在于推理时,只有最后一token的预测是有意义的,取出概率最大的token的编号作为预测的下一个token,这是我们之前见过的贪心采样trg_indices.append(pred_token)预测结果加入推理输出列表,下一轮作为输入if pred_token == EOS_ID:如果预测出的是结束标志,则直接结束
注意到这里的推理其实有个很大的问题,推理是,每一轮预测出i个token,模型都会把这i个token前向传播一遍,计算出对于这i个token作为输入的下一个预测token是什么。但是每一轮推理最后只用了最后一个输入的输出token作为预测结果,因为前面的token的预测结果,之前就算过了,没有任何意义。
所以经典的KV Cache就是解决这个问题的,他的思路是
-
K、V(Key 和 Value):前文所有已经生成过的 Token,它们对应的 Key 向量和 Value 向量是永远不会再改变的。所以我们不需要重复计算它们,只需要把它们缓存(Cache)在显存里。
-
Q(Query):每一次循环,只有当前最新生成的这一个 Token 才有资格作为 Query 矩阵。
如果不做这个优化,随着你生成的句子越来越长,推理的时间复杂度是 O(N2)O(N^2)O(N2) 的(因为每次都要算一个 N×NN \times NN×N 的完整注意力矩阵)。一旦开启了 KV Cache 优化:
- 每次塞进模型的只有 1 个 Token(QQQ 为 1 行)。
- 它只和历史的 K,VK, VK,V 算一次矩阵乘法(算出一个 1×N1 \times N1×N 的条状注意力分数)。
- 它的时间复杂度直接被降到了 O(N)O(N)O(N)(线性级)。
py
def translate_sentence(sentence, max_len=100):
# Tokenize and convert to IDs
tokens = [BOS_ID] + sp_en.encode(sentence, out_type=int) + [EOS_ID]
src_tensor = torch.LongTensor(tokens).unsqueeze(0).to(DEVICE) # [1, src_len]
src_mask = create_mask(src_tensor, PAD_ID)
# Initialize target with <bos> token
trg_indices = [BOS_ID]
with torch.no_grad():
# Encode the source sentence
encoder_output = model.encode(src_tensor, src_mask)
# Generate translation token by token
for _ in range(max_len):
trg_tensor = torch.LongTensor(trg_indices).unsqueeze(0).to(DEVICE) # [1, current_trg_len]
# Create target mask
trg_mask = torch.tril(torch.ones((len(trg_indices), len(trg_indices)), device=DEVICE)).bool()
trg_mask = trg_mask.unsqueeze(0).unsqueeze(0) # [1, 1, trg_len, trg_len]
# Decode
decoder_output = model.decode(encoder_output, src_mask, trg_tensor, trg_mask)
output = model.project(decoder_output)
# Get the last predicted token
pred_token = output.argmax(2)[:, -1].item()
trg_indices.append(pred_token)
if pred_token == EOS_ID:
break
# Convert token IDs to text (skip <bos> and <eos>)
translated = sp_cn.decode(trg_indices[1:-1])
return translated