本文基于
AI Mind项目的真实实现整理。GitHub:github.com/HWYD/ai-min...
对应代码版本:
v0.3.0线上链接:ai.hwyblog.cloud/instant-min...
AI Mind 是一个持续迭代中的 Next.js AI Chat 项目。从最基础的本地聊天开始,逐步加入流式协议、工具调用、MCP、Skill 和 Agent 能力。
如果你对这个项目感兴趣,或者这篇文章对你有一点帮助,也欢迎顺手到 GitHub 帮 AI Mind 点个 Star⭐,这会是对我继续更新很大的鼓励。
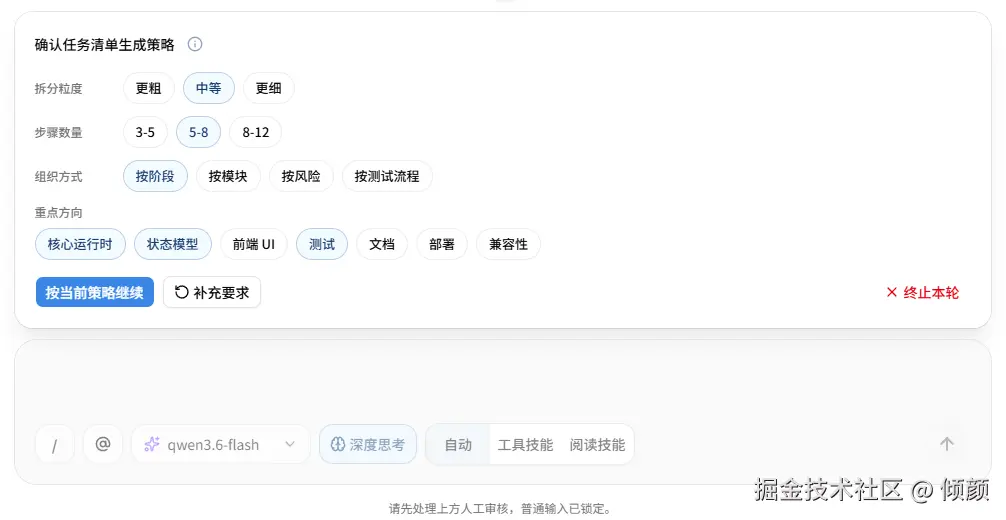
在 Agent 项目里,HITL 是一个很容易被低估的能力。
刚开始看,它好像只是"在页面上加一个确认按钮"。但真正落到 Agent 执行链路里,要考虑的问题会多很多:
Graph 在哪里暂停?
暂停时保存什么状态?
用户审核结果怎么校验?
恢复时从哪里继续?
会不会重复恢复?
恢复后的内容写回哪里?
数据库里记录业务状态,还是记录 Graph 状态?所以 v0.3.0 做的不是简单增加审核卡片,而是把"人可以介入 Agent 执行"这件事,整理成一套可暂停、可校验、可恢复、可防重复提交的执行协议。
1. HITL 是什么:让人进入 Agent 执行链路
HITL,全称是 Human-in-the-loop,通常可以理解成"人在环路中"。
普通 AI 对话里,用户一般只在开头输入需求,后面由模型一次性生成结果。
但 Agent 不太一样。它可能会经历多个阶段:
理解需求
制定策略
读取上下文
生成草稿
校验结果
必要时修订
输出最终产物这些阶段里,有些节点不适合完全交给模型自动决定。
比如:
生成前的策略是否合理?
模型是否应该继续修订?
当前草稿是否应该由用户直接接管?
本轮运行是否应该终止?HITL 要解决的就是:在关键节点暂停 Agent,让用户做一个受控决策,然后再让 Agent 从暂停点继续执行。
这和普通页面确认框的区别在于,Agent 的暂停需要真实进入执行系统:
Graph 要暂停
状态要保存
用户决策要校验
恢复时要回到同一条执行线程
后续输出还要接回原来的消息这也是 v0.3.0 的核心变化。
2. v0.3.0 的目标:让 Tasklist Agent 可以暂停、审核、恢复
在 v0.3.0 之前,AI Mind 的 Tasklist Agent 已经是一个受控单 Agent。
它不是开放式 Agent,不会自由调用工具、自由读取文件、自由写文件,也不会随意扩大执行范围。
它的入口很明确:
ruby
/tasklist + @docs://versions/*.md没有 HITL 的时候,它更像一条一次性执行流水线:
rust
用户发起 /tasklist
-> 读取版本方案
-> 判断方案是否足够
-> 决定 tasklist 拆分策略
-> 生成 tasklist 草稿
-> 校验草稿
-> 必要时修订
-> 输出最终产物这条链路能跑通,但用户只能在最终结果里看到 Agent 的判断。
如果中间策略方向不对,后面的草稿大概率也会跟着偏掉。
所以 v0.3.0 增加了两个审核点。
第一个是策略审核。
拆分策略确定后必须暂停。
用户审核后,Agent 才能继续生成 tasklist。用户可以选择:
approve:确认继续
edit:修改结构化策略后继续
reject:终止本轮运行
respond:给出反馈,让 Agent 重新生成策略第二个是修订审核。
它不是每次都出现,而是只有系统判断"确实需要立即修订"时才触发:
rust
存在需要立即修订的问题
-> 触发修订审核
不存在需要立即修订的问题
-> 不暂停,继续输出最终结果最终设计可以概括为:
策略必审
修订条件审
最多两轮受控修订这个取舍很重要。
HITL 不是让每一步都停下来问用户。过度暂停会破坏 Agent 的连续性,也会增加用户负担。
v0.3.0 只把人放在关键授权点上,剩下的流程仍然由受控 Graph 继续执行。
3. v0.2.4 的 GraphState 收口是前提
这里简单提一下前一个版本。
v0.2.4 做的是 Graph 单状态模型收口。
更早的迁移阶段里,Tasklist Agent 虽然已经接入 LangGraph,但内部还存在类似这样的过渡结构:
rust
GraphState
-> 旧 AgentState
-> 领域步骤
-> 旧 AgentState
-> GraphState 状态补丁这在迁移阶段可以降低风险,但到了 HITL / interrupt / resume 这一版,就会变得别扭。
因为恢复执行时必须回答一个问题:
checkpoint 恢复的到底是哪一份状态?
所以 v0.2.4 先把内部运行态收敛到 GraphState。到了 v0.3.0,审核决策、状态补丁、路由判断和 checkpoint resume 才能围绕同一份状态继续往下走。
一句话概括:
先收状态事实源,再做中断恢复。
4. HITL 的完整链路:从首次请求到恢复执行
没有 HITL 时,一次请求通常是这样:
rust
POST /api/chat
-> 创建 GraphState
-> 执行 Graph
-> 输出最终产物
-> 结束流式响应加入 HITL 后,这条链路会拆成两段。
第一段是首次执行,跑到审核节点后暂停:
shell
POST /api/chat
-> 识别 /tasklist
-> 创建 AgentRun
-> 创建 threadId
-> 选择 checkpointer
-> 执行 Graph
-> 进入审核节点
-> interrupt(payload)
-> 保存 checkpoint
-> 保存 AgentInterrupt
-> 输出审核卡片
-> 关闭本次 HTTP 响应这里的状态不是失败,也不是完成,而是暂停。
arduino
Graph 已经运行到审核点
当前 thread 的 checkpoint 已保存
业务状态进入 paused
前端展示审核卡片用户提交审核结果后,会发起恢复请求:
rust
POST /api/agent-runs/:runId/resume
-> 校验会话归属
-> 校验 run 状态
-> 校验是否存在待处理审核点
-> 校验审核决策是否合法
-> 消费当前审核点
-> 使用同一个 threadId 恢复 Graph
-> 继续后续节点
-> 输出最终产物或进入下一个审核点这就是 HITL 的核心链路。
恢复执行不是重新发起一次 Agent,而是回到同一个 Graph thread,从 checkpoint 对应的位置继续往下走。
5. LangGraph、后端、数据库、前端分别负责什么
HITL 不是某一层单独完成的能力。
在 v0.3.0 里,它至少涉及四层:
LangGraph
后端运行时
数据库
前端消息与审核交互每一层职责都要收清楚。
5.1 LangGraph 负责暂停和恢复 Graph
LangGraph 负责 Graph 层面的执行语义:
lua
执行节点
在审核节点触发 interrupt
通过 checkpointer 保存 checkpoint
通过 threadId 找到同一条执行线程
resume 后继续运行 Graph也就是说,LangGraph 解决的是:
arduino
Graph 运行到哪里了?
暂停时状态怎么保存?
恢复时怎么从同一个 thread 继续?但它不负责业务系统的问题。
比如:
arduino
这个 run 属于谁?
用户有没有权限恢复?
当前审核点是否已经被消费?
审核决策是否在允许范围内?
前端应该更新哪一条消息?
当前 run 应该展示 paused 还是 completed?这些需要后端运行时和业务数据库处理。
5.2 后端运行时负责把 Graph 能力变成业务流程
后端运行时的职责,是把 LangGraph 的 interrupt / resume 能力包装成一个业务上可控的 Agent 运行流程。
首次请求时,后端需要:
识别 Tasklist Agent 入口
创建 AgentRun
生成 threadId
选择 checkpointer
执行 Graph
捕获 interrupt
持久化 AgentInterrupt
向前端输出审核卡片
关闭当前响应恢复请求时,后端需要:
arduino
校验 run 是否存在
校验会话归属是否匹配
校验 run 是否处于 paused
校验是否存在待处理审核点
校验审核决策是否合法
校验 agentVersion / graphVersion 是否匹配
消费待处理审核点
调用 resume 继续执行 Graph
把后续输出写回原助手消息这里最关键的是:后端不能把前端提交的审核结果直接透传给 Graph。
用户提交的是外部输入。外部输入进入 Agent 执行链路前,必须先经过服务端校验。
否则 HITL 会变成另一个自由指令入口。
5.3 数据库负责业务状态和 checkpoint
数据库里有两类状态。
第一类是业务状态,由 Prisma 管理:
agent_runs
agent_interrupts它们关心的是:
arduino
这个 run 当前是什么状态?
现在有没有待处理审核点?
这个 run 属于哪个会话?
对应哪条助手消息?
用户提交了什么审核决策?
是否已经恢复过?
最终结果是 completed、blocked、rejected 还是 failed?第二类是 Graph checkpoint,由 LangGraph 的 PostgresSaver 管理。
它关心的是:
arduino
GraphState 快照是什么?
thread checkpoint 在哪里?
恢复时如何继续执行 Graph?这两类状态不能混在一起。
可以这样理解:
checkpoint 让 Graph 知道从哪里继续。
AgentRun 让业务系统知道谁能继续、能不能继续、继续后是什么状态。所以 v0.3.0 没有把完整 GraphState 存进 AgentRun,也没有试图用 checkpoint 替代业务 run 查询。
PostgresSaver 和 Prisma 共用同一个 PostgreSQL 实例,但职责边界是分开的。
5.4 前端负责审核交互和原消息续写
前端负责的是交互和展示。
执行到审核点后,前端需要展示审核卡片。
在待处理审核期间,输入框要禁用:
arduino
不能发起新消息
不能重新生成上一轮
只能提交当前审核决策
或者拒绝当前 run用户提交审核决策后,前端进入恢复中状态,等待后端继续返回流式内容。
这里还有一个重要体验细节:
resume 后不能新建一条助手消息,而应该继续更新原来的助手消息。
因为从用户视角看,这不是一轮新的对话,而是同一轮 Agent 执行:
rust
开始执行
-> 中间暂停
-> 用户审核
-> 继续执行
-> 输出结果所以后续执行轨迹、产物和最终文本都应该继续合并到原助手消息里。
这样用户看到的是一条完整的 Agent 执行过程,而不是两条断开的回复。
6. 审核节点为什么必须无副作用
这是实现 HITL 时非常关键的一点。
LangGraph interrupt 有一个重要语义:
lua
resume 后,会从触发 interrupt 的节点起点重新执行。这意味着审核节点不能在 interrupt 前做不可重复的副作用。
所以 v0.3.0 对审核节点的边界要求很严格:
vbscript
不调用模型
不调用工具
不读取资源
不写数据库
不写文件
不发送产物
不依赖 request / writer / AbortSignal
只构造 interrupt payload
resume 后只解析审核决策
最后返回 GraphState 状态补丁原因很直接。
如果审核节点在 interrupt 前调用了模型,resume 时重新执行这个节点,就可能重复调用模型。
如果审核节点在 interrupt 前写了数据库,resume 时重新执行,就可能重复写入。
如果审核节点在 interrupt 前发送了产物,resume 时重新执行,就可能重复输出。
所以审核节点最好是一个很纯的节点:
scss
首次执行:
构造 payload
interrupt(payload)
恢复后重新执行:
接收审核决策
校验并转换为 GraphState 状态补丁可以简单概括为:
审核节点越纯,恢复语义越稳定。
7. 业务状态和 checkpoint 为什么必须分开
做 Agent resume 时,很容易把两个概念混在一起:
arduino
Graph checkpoint
业务 run 状态但它们解决的问题不同。
Graph checkpoint 解决的是技术恢复问题:
arduino
GraphState 保存在哪里?
恢复时从哪个 thread 继续?
LangGraph 能不能接着执行?业务 run 状态解决的是产品和后端控制问题:
arduino
这个 run 是不是 paused?
这个审核点是不是还在等待处理?
这个用户有没有权限提交审核决策?
是否重复恢复?
是否跨版本恢复?
最终是 completed、blocked、rejected 还是 failed?所以 v0.3.0 的分工是:
PostgresSaver:
负责 Graph checkpoint。
Prisma:
负责 AgentRun / AgentInterrupt 业务表。
AgentRunService:
负责状态迁移、所有权校验、版本校验、重复恢复防护。这样分层后,系统会清楚很多。
当 Graph 需要恢复执行时,找 checkpoint。
当后端需要判断用户能不能提交审核时,看 AgentRun / AgentInterrupt。
当前端需要展示待处理审核时,读业务 DTO,而不是直接读 checkpoint。
这也是这版里很重要的架构经验:
checkpoint 是技术恢复状态,AgentRun 是业务可见状态。
8. resume 如何避免重复提交:事务和行锁
恢复请求天然有并发风险。
比如:
用户连续点击两次
浏览器重试请求
网络抖动导致重复提交
两个恢复请求几乎同时到达如果没有保护,可能出现:
arduino
同一个审核点被消费两次
Graph 被恢复两次
生成两个产物
run 状态被写乱所以恢复阶段至少要保证:
rust
同一个待处理审核点只能被消费一次
run 从 paused -> resuming 是原子的
interrupt 从 pending -> decided 是原子的
审核决策写入和状态迁移在同一个事务内完成可以把它理解成一次"消费待处理审核点"的过程:
ini
begin transaction
1. 锁定当前 run 和待处理审核点
2. 确认 run.status = paused
3. 确认 interrupt.status = pending
4. 写入用户审核决策
5. interrupt.status = decided
6. run.status = resuming
commit事务提交成功后,才真正恢复 Graph:
使用同一个 threadId 继续执行 Graph在 PostgreSQL 里,这类并发保护可以通过事务 + 行锁实现,也可以通过带状态条件的更新实现。
重点不是具体锁写法,而是要保证一件事:
同一个待处理审核点,只有一个恢复请求能消费成功。
如果第二个请求进来时发现审核点已经不是 pending,或者 run 已经不是 paused,就应该直接失败,而不是继续恢复。
这一层防重入非常重要。因为用户看起来只是点了一个按钮,但后端实际执行的是一次状态迁移和 Graph 恢复动作。
9. 为什么 resume 要继续更新原助手消息
在普通聊天里,一次请求通常对应一条助手消息。
但 HITL 场景不同。
首次请求执行到 interrupt 时,这条助手消息还没有真正完成。它只是进入了 paused 状态。
如果恢复后新建一条助手消息,用户看到的会像这样:
第一条 Agent 消息暂停了。
第二条 Agent 消息又重新开始了。这会破坏 HITL 的语义。
因为真实发生的是:
rust
同一轮 Agent 执行
-> 中间暂停
-> 用户审核
-> 继续执行
-> 输出结果所以 v0.3.0 要做的是:
首次请求创建助手消息
执行到 interrupt 后,这条消息进入 paused
用户恢复后,这条消息进入 resuming
后续执行轨迹、产物、最终文本继续写回这条消息这样前端呈现出来的是一条完整的 Agent 执行轨迹:
rust
开始执行
-> 策略审核
-> 用户 approve / edit / respond
-> 继续生成
-> 可能进入修订审核
-> 再继续
-> 输出产物HITL 的前端目标不是"再生成一条回复",而是续写同一次 Agent 运行。
10. 这版刻意不做什么
v0.3.0 做了 HITL、checkpoint 和 resume,但它没有把 AI Mind 变成通用 Agent 平台。
这一版不做:
css
不支持刷新恢复 pending HITL
不做 Run History
不做 Time Travel
不做完整聊天消息持久化
不做多人审批
不做通用工具审批
不扩展普通聊天 / Reader Skill / Utility Skill / MCP
不把 Tasklist Agent 扩展成通用 Agent 平台其中最值得说明的是:不支持刷新恢复 pending HITL。
这一版支持的是同页暂停和恢复,不是完整会话恢复。
如果页面刷新后,只恢复一张审核卡片,但上方没有完整消息、执行轨迹和产物上下文,用户会看到一个错位状态。
真正的刷新恢复还需要:
消息持久化
执行轨迹重建
产物重建
待处理审核上下文重建
原助手消息重新绑定这些不是 v0.3.0 的重点。
所以这一版选择明确收口:
刷新视为放弃当前前端会话,用户需要重新发起
/tasklist。
这个边界看起来保守,但它能避免把半成品会话恢复包装成完整能力。
11. 总结:HITL 的核心是可恢复的受控执行协议
做完 v0.3.0 后,我对 HITL 的理解更清楚了。
它不是一个确认按钮,也不是一个前端弹窗。
在 Agent 运行时里,HITL 至少包含这些部分:
arduino
Graph interrupt
可序列化的 interrupt payload
结构化审核决策
PostgreSQL checkpoint
AgentRun / AgentInterrupt
会话归属校验
重复恢复防护
同 thread 恢复
原助手消息续写
明确的能力边界如果只做前端弹窗,Agent 并没有真正暂停。
如果只有 checkpoint,没有 AgentRun,业务系统不知道谁能恢复、能不能恢复。
如果只有 AgentRun,没有 checkpoint,Graph 无法从中断处继续。
如果没有事务和防重入,同一个审核决策可能被消费两次。
如果恢复后新建消息,用户看到的执行轨迹会断开。
所以我觉得 v0.3.0 的核心价值不是"给 Tasklist Agent 加了审核按钮",而是:
把"人可以介入 Agent 执行"这件事,变成一套可校验、可暂停、可恢复、可防重入的执行协议。
这也是受控 Agent 继续往前演进时很关键的一步。
项目地址
👉 GitHub:github.com/HWYD/ai-min...
👉 线上体验:ai.hwyblog.cloud/instant-min...
如果这篇文章或者 AI Mind 项目对你有所帮助,也欢迎顺手帮项目点个 Star⭐。这个支持对我来说很重要,也会让我更有动力继续整理后续版本的实现过程、设计取舍和踩坑复盘。