ANN
需求分析
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。该数据为二手手机的各个性能的数据,最后根据这些性能得到4个价格区间,作为这些二手手机售出的价格区间。主要包括:

我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用0、1、2、3来表示,所以该问题也是一个分类问题。
python
"""
案例:ANN实现手机价格预测
基于手机的20个特征->预测手机的价格区间(4个),可以使用机器学习/深度学习
步骤:
构建数据集
搭建神经网络
模型训练
模型测试
增加:损失曲线 + 准确率曲线可视化
"""
import torch # PyTorch框架, 封装了张量的各种操作
from torch.utils.data import TensorDataset # 数据集对象. 数据 -> Tensor -> 数据集 -> 数据加载器
from torch.utils.data import DataLoader # 数据加载器.
import torch.nn as nn # neural network, 封装了神经网络的各种操作
import torch.optim as optim # 优化器
from sklearn.model_selection import train_test_split # 训练集和测试集的划分
import matplotlib.pyplot as plt # 绘图
import numpy as np # 数组(矩阵)操作
import pandas as pd # 数据处理
import time
from torchsummary import summary
from sklearn.preprocessing import StandardScaler
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
#todo:1.定义函数,构建数据集
def create_dataset():
#加载csv文件
data = pd.read_csv('./data/手机价格预测.csv')
#获取x特征列,y标签列
x,y = data.iloc[:,:-1],data.iloc[:,-1]
#把特征列转为浮点型
x = x.astype('float32')
y = y.astype('int64')
#切分训练集测试集,参1:特征,参2:标签,参3:测试集占比,参4:随机种子,参5:样本的分布,参考y的类别进行抽取数据
x_train,x_valid,y_train,y_valid = train_test_split(x,y,test_size=0.2,random_state=3,stratify=y)
# 优化①:数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_valid = transfer.transform(x_valid)
# 构建数据集,转换为pytorch的形式
train_dataset = TensorDataset(torch.from_numpy(x_train), torch.tensor(y_train.values))
valid_dataset = TensorDataset(torch.from_numpy(x_valid), torch.tensor(y_valid.values))
#返回结果 输入特征数(20) 输出特征数(4)
return train_dataset, valid_dataset, x_train.shape[1], len(np.unique(y))
#todo:2.搭建神经网络
class PhonePriceModel(nn.Module):
def __init__(self,input_dim,output_dim):
super().__init__()
# 优化②:增加网络深度
# 1. 第一层: 输入为维度为 20, 输出维度为: 128
self.linear1 = nn.Linear(input_dim, 128)
# 2. 第二层: 输入为维度为 128, 输出维度为: 256
self.linear2 = nn.Linear(128, 256)
# 3. 第三层: 输入为维度为 256, 输出维度为: 512
self.linear3 = nn.Linear(256, 512)
# 4. 第四层: 输入为维度为 512, 输出维度为: 128
self.linear4 = nn.Linear(512, 128)
# 5. 输出层: 输入为维度为 128, 输出维度为: 4
self.linear5 = nn.Linear(128, output_dim)
def forward(self,x):
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
x = torch.relu(self.linear3(x))
x = torch.relu(self.linear4(x))
output = self.linear5(x)
return output
#todo:3.模型训练
def train(train_dataset, valid_dataset, input_dim, output_dim):
#创建数据加载器
train_loader = DataLoader(train_dataset,batch_size=16,shuffle=True)
valid_loader = DataLoader(valid_dataset,batch_size=16,shuffle=False)
model = PhonePriceModel(input_dim,output_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=1e-4)
epochs = 50
# 保存绘图数据
train_loss_list = []
val_loss_list = []
train_acc_list = []
val_acc_list = []
for epoch in range(epochs):
# -------- 训练阶段 --------
model.train()
total_loss ,batch_num = 0.0,0
correct_train = 0
start = time.time()
for x,y in train_loader:
y_pred = model(x)
loss = criterion(y_pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
batch_num += 1
# 训练集准确率
pred_cls = torch.argmax(y_pred, dim=1)
correct_train += (pred_cls == y).sum().item()
train_loss = total_loss / batch_num
train_acc = correct_train / len(train_dataset)
# -------- 验证阶段 --------
model.eval()
val_total_loss = 0.0
val_batch = 0
correct_val = 0
with torch.no_grad():
for x,y in valid_loader:
y_pred = model(x)
loss = criterion(y_pred,y)
val_total_loss += loss.item()
val_batch += 1
pred_cls = torch.argmax(y_pred, dim=1)
correct_val += (pred_cls == y).sum().item()
val_loss = val_total_loss / val_batch
val_acc = correct_val / len(valid_dataset)
# 记录数据
train_loss_list.append(train_loss)
val_loss_list.append(val_loss)
train_acc_list.append(train_acc)
val_acc_list.append(val_acc)
print(f'epoch:{epoch+1},train_loss:{train_loss:.4f},val_loss:{val_loss:.4f},train_acc:{train_acc:.4f},val_acc:{val_acc:.4f},time:{time.time()-start:.2f}s')
print(f'\n\n模型的参数信息: {model.state_dict()}\n\n')
torch.save(model.state_dict(), './model/phone.pth')
# 绘制双图:损失 + 准确率
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# 损失曲线
ax1.plot(range(1, epochs+1), train_loss_list, label="训练损失", color="#e74c3c")
ax1.plot(range(1, epochs+1), val_loss_list, label="验证损失", color="#2980b9")
ax1.set_xlabel("迭代轮次 Epoch")
ax1.set_ylabel("Loss 损失值")
ax1.set_title("训练 & 验证损失变化曲线")
ax1.legend()
ax1.grid(alpha=0.3)
# 准确率曲线
ax2.plot(range(1, epochs+1), train_acc_list, label="训练准确率", color="#27ae60")
ax2.plot(range(1, epochs+1), val_acc_list, label="验证准确率", color="#8e44ad")
ax2.set_xlabel("迭代轮次 Epoch")
ax2.set_ylabel("Accuracy 准确率")
ax2.set_title("训练 & 验证准确率变化曲线")
ax2.legend()
ax2.grid(alpha=0.3)
plt.tight_layout()
plt.show()
return train_loss_list, val_loss_list, train_acc_list, val_acc_list
#todo:4.模型测试
def evaluate(valid_dataset,input_dim,output_dim):
model = PhonePriceModel(input_dim,output_dim)
model.load_state_dict(torch.load('./model/phone.pth'))
dataloader = DataLoader(valid_dataset,batch_size=16,shuffle=False)
correct = 0
model.eval()
with torch.no_grad():
for x,y in dataloader:
y_pred = model(x)
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum()
print(f'最终验证集准确率(Accuracy): {correct / len(valid_dataset):.4f}')
if __name__ == '__main__':
train_dataset, valid_dataset, input_dim, output_dim = create_dataset()
model = PhonePriceModel(input_dim, output_dim)
summary(model, input_size=(input_dim,))
# 传入验证集用于计算每轮指标并绘图
train(train_dataset, valid_dataset, input_dim, output_dim)
evaluate(valid_dataset,input_dim,output_dim)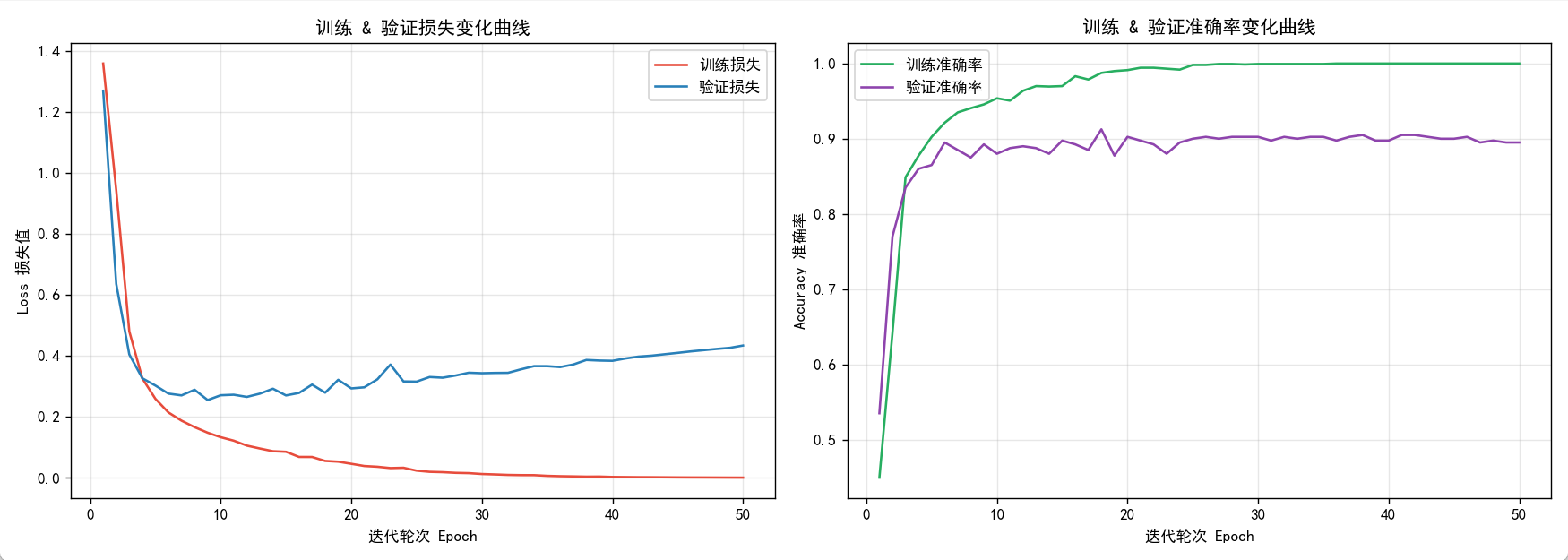
搭建CNN实现图像分类CIFAR10
python
"""
案例:
演示CNN的综合案例, 图像分类.
回顾: 深度学习项目的步骤
1. 准备数据集.
这里我们用的时候 计算机视觉模块 torchvision自带的 CIFAR10数据集, 包含6W张 (32,32,3)的图片, 5W张训练集, 1W张测试集, 10个分类, 每个分类6K张图片.
你需要单独安装一下 torchvision包, 即: pip install torchvision
2. 搭建(卷积)神经网络
3. 模型训练.
4. 模型测试.
卷积层:
提取图像的局部特征 -> 特征图(Feature Map), 计算方式: N = (W - F + 2P) // S + 1
每个卷积核都是1个神经元.
池化层:
降维, 有最大池化和平均池化.
池化只在HW上做调整, 通道上不改变.
"""
# 导包
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor # pip install torchvision -i https://mirrors.aliyun.com/pypi/simple/
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
# 每批次样本数
BATCH_SIZE = 8
# 1. 准备数据集.
def create_dataset():
# 1. 获取训练集.
# 参1: 数据集路径. 参2: 是否是训练集. 参3: 数据预处理 -> 张量数据. 参4: 是否联网下载(直接用我给的, 不用下)
train_dataset = CIFAR10(root='./data', train=True, transform=ToTensor(), download=True)
# 2. 获取测试集.
test_dataset = CIFAR10(root='./data', train=False, transform=ToTensor(), download=True)
# 3. 返回数据集.
return train_dataset, test_dataset
# 2. 搭建(卷积)神经网络
class ImageModel(nn.Module):
# 1. 初始化父类成员, 搭建神经网络.
def __init__(self):
# 1.1 初始化父类成员.
super().__init__()
# 1.2 搭建神经网络.
# 第1个卷积层, 输入 3通道, 输出6通道, 卷积核大小3*3, 步长1, 填充0
self.conv1 = nn.Conv2d(3, 6, 3, 1, 0)
# 第1个池化层, 窗口大小 2*2, 步长2, 填充0
self.pool1 = nn.MaxPool2d(2, 2, 0)
# 第2个卷积层, 输入 6通道, 输出16通道, 卷积核大小3*3, 步长1, 填充0
self.conv2 = nn.Conv2d(6, 16, 3, 1, 0)
# 第2个池化层, 窗口大小 2*2, 步长2, 填充0
self.pool2 = nn.MaxPool2d(2, 2, 0)
# 第1个隐藏层(全连接层), 输入: 576, 输出: 120
self.linear1 = nn.Linear(576, 120)
# 第2个隐藏层 (全连接层), 输入: 120, 输出: 84
self.linear2 = nn.Linear(120, 84)
# 第3个隐藏层 (全连接层) -> 输出层, 输入: 84, 输出: 10
self.output = nn.Linear(84, 10)
# 2. 定义前向传播
def forward(self, x):
# 第1层: 卷积层(加权求和) + 激励层(激活函数) + 池化层(降维)
# 分解版.
# x = self.conv1(x) # 卷积层
# x = torch.relu(x) # 激励层
# x = self.pool1(x) # 池化层
# 合并版 池化 + 激活函数 + 卷积
x = self.pool1(torch.relu(self.conv1(x)))
# 第2层: 卷积层(加权求和) + 激励层(激活函数) + 池化层(降维)
x = self.pool2(torch.relu(self.conv2(x)))
# 细节: 全连接层只能处理二维数据, 所以要将数据进行拉平 (8, 16, 6, 6) -> (8, 576)
# 参1: 样本数(行数), 参2: 列数(特征数), -1表示自动计算.
x = x.reshape(x.size(0), -1) # 8行576列
# print(f'x.shape: {x.shape}')
# 第3层: 全连接层(加权求和) + 激励层(激活函数)
x = torch.relu(self.linear1(x))
# 第4层: 全连接层(加权求和) + 激励层(激活函数)
x = torch.relu(self.linear2(x))
# 第5层: 全连接层(加权求和) -> 输出层
return self.output(x) # 后续用 多分类交叉熵损失函数CrossEntropyLoss = softmax()激活函数 + 损失计算.
# 3. 模型训练.
def train(train_dataset):
# 1. 创建数据加载器.
dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 2. 创建模型对象.
model = ImageModel()
# 3. 创建损失函数对象.
criterion = nn.CrossEntropyLoss() # 多分类交叉熵损失函数 = softmax()激活函数 + 损失计算.
# 4. 创建优化器对象.
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 5. 循环遍历epoch, 开始 每轮的 训练动作.
# 5.1 定义变量, 记录训练的总轮数.
epochs = 20
# 5.2 遍历, 完成每轮的 所有批次的 训练动作.
for epoch_idx in range(epochs):
# 5.2.1 定义变量, 记录: 总损失, 总样本数据量, 预测正确样本个数, 训练(开始)时间
total_loss, total_samples, total_correct, start = 0.0, 0, 0, time.time()
# 5.2.2 遍历数据加载器, 获取到 每批次的 数据.
for x, y in dataloader:
# 5.2.3 切换训练模式.
model.train()
# 5.2.4 模型预测.
y_pred = model(x)
# 5.2.5 计算损失.
loss = criterion(y_pred, y)
# 5.2.6 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 5.2.7 统计预测正确的样本个数.
# print(y_pred) # 批次中, 每张图 每个分类的 预测概率.
# argmax() 返回最大值对应的索引, 充当 -> 该图片的 预测分类.
# tensor([9, 8, 5, 5, 1, 5, 8, 5])
# print(torch.argmax(y_pred, dim=-1)) # -1这里表示行. 预测分类
# print(y) # 真实分类
# print(torch.argmax(y_pred, dim=-1) == y) # 是否预测正确
# print((torch.argmax(y_pred, dim=-1) == y).sum()) # 预测正确的样本个数.
total_correct += (torch.argmax(y_pred, dim=-1) == y).sum()
# 5.2.8 统计当前批次的总损失. 第1批平均损失 * 第1批样本个数
total_loss += loss.item() * len(y) # [第1批总损失 + 第2批总损失 + 第3批总损失 + ...]
# 5.2.9 统计当前批次的总样本个数.
total_samples += len(y)
# break 每轮只训练1批, 提高训练效率, 减少训练时长, 只有测试会这么写, 实际开发绝不要这样做.
# 5.2.10 走这里, 说明一轮训练完毕, 打印该轮的训练信息.
print(f'epoch: {epoch_idx + 1}, loss: {total_loss / total_samples:.5f}, acc:{total_correct / total_samples:.2f}, time:{time.time() - start:.2f}s')
# break # 这里写break, 意味着只训练一轮.
# 6. 保存模型.
torch.save(model.state_dict(), './model/image_model.pth')
# 4. 模型测试.
def evaluate(test_dataset):
# 1. 创建测试集 数据加载器.
dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 2. 创建模型对象.
model = ImageModel()
# 3. 加载模型参数.
model.load_state_dict(torch.load('./model/image_model.pth')) # pickle文件
# 4. 定义变量统计 预测正确的样本个数, 总样本个数.
total_correct, total_samples = 0, 0
# 5. 遍历数据加载器, 获取到 每批次 的数据.
for x, y in dataloader:
# 5.1 切换模型模式.
model.eval()
# 5.2 模型预测.
y_pred = model(x)
# 5.3 因为训练的时候用了CrossEntropyLoss, 所以搭建神经网络时没有加softmax()激活函数, 这里要用 argmax()来模拟.
# argmax()函数功能: 返回最大值对应的索引, 充当 -> 该图片的 预测分类.
y_pred = torch.argmax(y_pred, dim=-1) # -1 这里表示行.
# 5.4 统计预测正确的样本个数.
total_correct += (y_pred == y).sum()
# 5.5 统计总样本个数.
total_samples += len(y)
# 6. 打印正确率(预测结果).
print(f'Acc: {total_correct / total_samples:.2f}')
# 5. 测试
if __name__ == '__main__':
# 1. 获取数据集.
train_dataset, test_dataset = create_dataset()
# print(f'训练集: {train_dataset.data.shape}') # (50000, 32, 32, 3)
# print(f'测试集: {test_dataset.data.shape}') # (10000, 32, 32, 3)
# # {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
# print(f'数据集类别: {train_dataset.class_to_idx}')
#
# # 图像展示
# plt.figure(figsize=(2, 2))
# plt.imshow(train_dataset.data[1111]) # 索引为1111的图像
# plt.title(train_dataset.targets[1111])
# plt.show()
# 2. 搭建神经网络.
# model = ImageModel()
# 查看模型参数, 参1: 模型, 参2: 输入维度(CHW, 通道, 高, 宽), 参3: 批次大小
# summary(model, (3, 32, 32), batch_size=1)
# 3. 模型训练.
# train(train_dataset)
# 4. 模型测试.
evaluate(test_dataset)