PyTorch强化学习实战------整合DQN改进算法
-
- [0. 前言](#0. 前言)
- [1. 整合 DQN 改进算法](#1. 整合 DQN 改进算法)
- [2. 运行结果](#2. 运行结果)
- [3. 超参数调优](#3. 超参数调优)
- 相关链接
0. 前言
我们已经逐步实现了论文《Rainbow: Combining Improvements in Deep Reinforcement Learning》中提到的所有深度Q网络 (Deep Q-Network, DQN)改进技术,包括:
- N步 DQN:通过贝尔曼方程展开提升收敛速度与稳定性,及其局限性
- Double DQN:解决
DQN对动作价值的高估问题 - 噪声网络:通过权重噪声注入实现高效探索
- 优先回放缓冲区:揭示均匀采样并非最优训练策略
- Dueling DQN:通过网络架构改进匹配问题特性以加速收敛
- Categorical DQN:突破单一期望值框架,实现全分布建模
该论文的核心要义在于将这些改进技术组合验证效果。
1. 整合 DQN 改进算法
在本节示例中,我们并未使用 Categorical DQN 和 Double DQN------因为它们在当前测试环境中未展现出显著提升。我们也可以自行添加这些模块并更换游戏环境测试。在 dqn_rainbow.py 文件中首先定义融合了以下技术的网络架构:
Dueling DQN:网络将包含状态价值分布和优势分布的双路径结构。输出层通过求和运算合并两条路径,生成动作的最终价值概率分布。为确保优势分布均值为零,我们将从每个原子节点减去优势均值的分布Noisy networks:价值路径和优势路径中的线性层将采用带噪声的nn.Linear变体
除了网络架构的变化,我们将使用优先经验回放池存储环境转移样本,并根据均方误差损失按比例采样。最后,对贝尔曼方程执行 n 步展开。
2. 运行结果
下图展示了与经典 DQN 相比的平滑奖励曲线和步数统计。两者均显示游戏对局次数方面的显著提升:
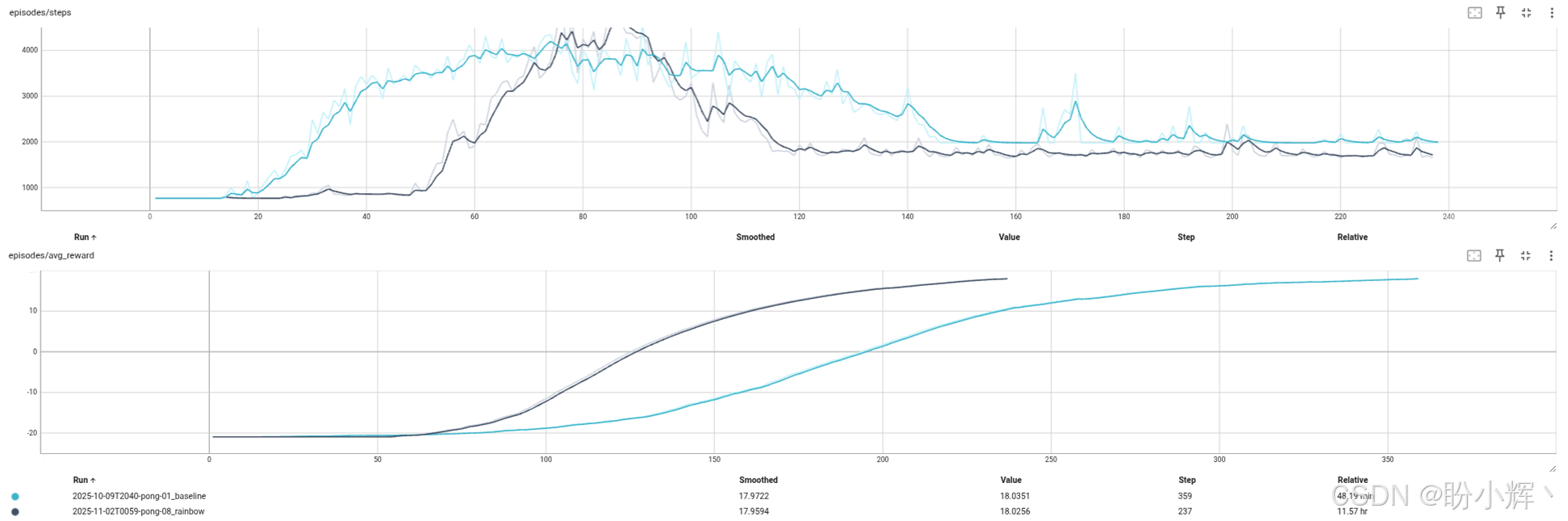
除了平均奖励值外,原始奖励曲线的变化趋势比平滑后的曲线更为明显。数据显示,我们的系统能在极短时间内(仅 100 局游戏后)从负收益迅速跃升至正收益,并几乎实现局局必胜。但平滑奖励值达到 +18 水平又额外消耗了 100 局游戏:

需注意的是,由于采用了更复杂的神经网络架构和优先经验回放缓冲机制,组合系统的运行效率低于基准版本。帧率监测图显示,系统初始帧率为 170 FPS,但随着缓冲区复杂度 O ( n ) O(n) O(n) 的上升,最终会降至 130 FPS。
3. 超参数调优
调优过程能够进一步改进组合系统成功解决游戏所需的局数。下图展示了基准组合系统与调优组合系统的对比曲线:

另一组调优效果对比图显示了原始游戏奖励值的变化。经调优后的系统仅用 40 回合游戏就开始持续获得最高分:
相关链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程
PyTorch强化学习实战(8)------Q学习详解与实现
PyTorch强化学习实战(10)------强化学习高级组件
PyTorch强化学习实战(11)------N步DQN(N-step DQN)
PyTorch强化学习实战(12)------Double DQN(DDQN)
PyTorch强化学习实战(13)------噪声网络(NoisyNet-DQN)
PyTorch强化学习实战(14)------优先经验回放机制