你的 Wiki 有多少"僵尸页"?有多少断链?有多少过期内容?
如果你回答不上来,你的 Wiki 正在悄悄腐烂。
这不是危言耸听。一个 AI Agent 持续维护的 Wiki,每 ingest 一批新资料,就有 10-20% 的已有页面需要更新。如果这些更新没跟上------旧的参数、过期的配置、被推翻的结论------读者打开一个页面,不知道哪些还适用、哪些已经过期。
LLM Wiki 设计了一套 12 项自动化检查,定期扫描全库,发现问题就标出来。这篇文章逐一拆解每项检查的设计逻辑、实现方法和真实案例。
先看效果:一次 Lint 扫描的输出
Agent 执行 lint 命令后,输出是这样的:
断链(Critical): 2 个。\[旧工具链]、\[传感器驱动]------这两个页面在 Wikilinks 中被引用但不存在。需要创建或修正链接。
孤岛页(Warning): 3 个。HI3519DV500_硬件原理分析、硬件设计知识提炼、OpenCV 移植参考------这 3 页入站链接为 0,在 Graph View 里看不到。
过期页面(Warning): 1 个。DDR4 接口设计------最后更新 2026-06-16,但大量关联页面(启动配置、BSP 编译)在 2026-06-20 后均有更新。可能部分信息过时。
标签异常(Info): alerts 标签不在 SCHEMA.md 分类体系中。应改为 debug 或新增到分类体系。
日志轮转(Info): log.md 当前 492 条,接近 500 条上限。建议近期轮转。
一次扫描,5 分钟,全部问题自动化发现。
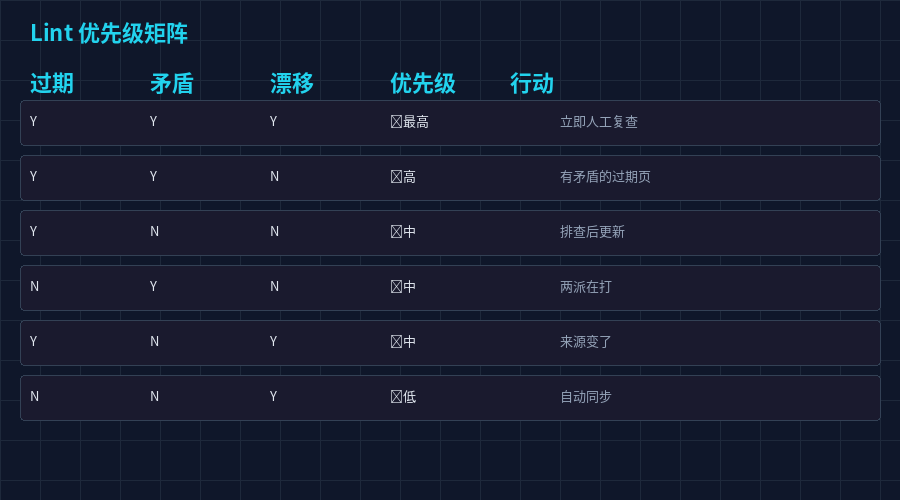
检查体系总览
| 优先级 | 检查项 | 检测内容 | 触发条件 |
|---|---|---|---|
| 🔴 Critical | 断链检测 | \[wikilinks] 引用了不存在的页面 | 即时 |
| 🔴 Critical | 死链检测 | 引用的外部 URL 返回 404 | 即时 |
| 🟠 High | 孤岛页检测 | 入站链接为 0 的内容页 | 即时 |
| 🟠 High | 过期检测 | 页面最后更新日期早于关联页面的更新日期 90 天以上 | 即时 |
| 🟡 Medium | 矛盾检测 | 两个页面标记了 contested:true 或同一主题不同结论 | 即时 |
| 🟡 Medium | 置信度检测 | confidence: low 的页面 | 即时 |
| 🟡 Medium | 单来源检测 | 只引用了 1 个来源但没有设置 confidence 字段 | 即时 |
| 🟡 Medium | 标签审计 | 使用了不在 SCHEMA.md 分类体系中的标签 | 即时 |
| 🟢 Low | 页面尺寸 | 超过 200 行的页面标记为"建议拆分" | 即时 |
| 🟢 Low | 索引完整性 | index.md 里列出但文件不存在的页面 / 文件存在但 index 没列出 | 即时 |
| 🟢 Low | 来源漂移 | raw/ 中 sha256 校验值变化的文件 | 即时 |
| 🟢 Low | 日志轮转 | log.md 超过 500 条 | 即时 |
深入五项核心检查
检查 1:断链检测------最致命的问题
原理: 提取全 Wiki 所有 \[wikilinks] 的目标页面名,与 filesystem 上实际存在的 .md 文件做差集。
代码思路(Agent 执行的逻辑):
- 遍历 entities/concepts/comparisons/ 下所有 .md 文件
- 提取文件名去掉 .md 后缀作为"实际页面列表"
- 遍历所有页面的正文,提取所有
[[...]]中的目标名 - 差集 = 被引用但不在实际页面列表中的名字
真实案例: 我的 Wiki 早期有 \[UE 配置] 和 \[VDEC 配置] 两个 wikilinks,但对应的页面从未创建。Agent 在 lint 时发现并标记------要么补建,要么把 wikilinks 改成纯文本。
影响: 断链不只是"点不开"。在 Obsidian Graph View 里,断链是一个只有出箭头的虚线------读者以为那里有一个节点,但点了之后是"找不到页面"。这比没有链接更糟。
检查 2:孤岛页检测------最隐蔽的问题
原理: 建立入站链接映射表,入站为 0 的就是孤岛。
实施细节: 不同于断链检测只看"能不能点开",孤岛检测关注"有没有人指向它"。排除 index/log/SCHEMA 三个元页面后,任何内容页面如果入站为 0,就有问题。
我的孤岛案例: 27 个内容页中 3 个孤岛。其中 2 个是独立参考文档(硬件原理分析、硬件设计提炼)------内容高度自包含,不需要大量入站链接。1 个是 OpenCV 移植页面------它链了其他页面但别人没回链,需要补充 backlinks。
判断逻辑: 孤岛不等于"该删"。Agent 标记孤岛后,我逐个判断:内容独立 → 保留但标记 low-priority;需要交叉引用 → 执行 backlink 同步。
检查 3:过期检测------时间是最隐蔽的杀手
原理: 对比页面 updated 日期与关联页面的最后更新日期。如果 A 页面的更新时间比所有关联 B 页面的更新时间都早 90 天以上,A 可能过期。
具体算法:
- 对每个页面,找到所有通过 wikilinks 互联的"邻居页面"
- 取邻居页面中最新的 updated 日期
- 如果本页面 updated 日期 < 邻居最新日期 - 90 天 → 标记过期
真实案例: DDR4 接口设计最后更新于 2026-06-16。它的邻居页面中,启动配置最后更新于 2026-06-20,BSP 编译系统更新于 2026-06-23。DDR4 接口比它的所有邻居都至少老 4 天------不严重,但值得检查是否遗漏了更新。
为什么 90 天? 对于工程类 Wiki,90 天是一个合理的"过期间隔"------技术文档通常 3 个月内有实质更新。对于快速变化领域(AI 模型评估),建议缩短到 30 天。
检查 4:来源漂移------raw/ 文件被改了
原理: raw/ 目录的每个文件在摄入时记录了 sha256 哈希值。Lint 时重新计算并对比------如果哈希变了,说明原始来源被修改了。
场景: 一份在线文档,你摄入时是 v1.0。3 个月后作者更新了 v1.1,你再次爬取。sha256 变了------Agent 对比新旧内容,更新引用了这份来源的 Wiki 页面。
为什么重要: 如果 raw/ 悄悄变了但 Wiki 没更新,读者看到的就是过时结论。sha256 漂移检测让这种"悄悄过时"变得可发现。
检查 5:标签审计------分类体系不能腐烂
原理: 提取全 Wiki frontmatter 中所有 tags,与 SCHEMA.md 中定义的有效标签列表做差集。
真实案例: 我早期有一次 Agent 给一个页面打了 alerts 标签。alerts 不在 SCHEMA.md 的 25 个标签体系中。Lint 发现后,Agent 把它改成了 debug(排查和告警相关的正规标签)。
为什么标签审计重要: 一个标签不在分类体系中,意味着任何按标签搜索的查询都找不到这个页面。它成了一座"隐形的孤岛"------入站链接正常,但标签搜索对它无效。
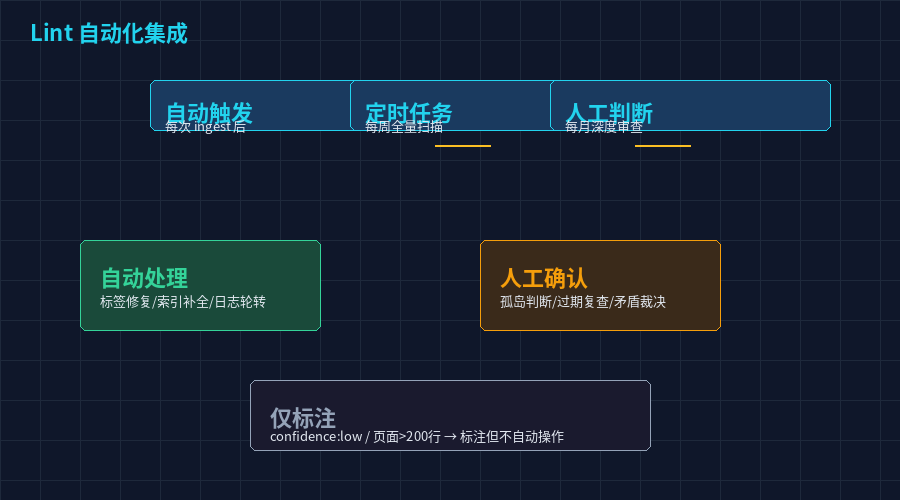
Lint 的自动化集成
Lint 不应该是一个"想起来就跑一下"的手动操作。它应该嵌入 Wiki 的维护流程中。
我的集成方式:
每次 batch ingest 完成后,自动触发一次 lint 扫描。Agent 在写完 log.md 的最后一条记录后,紧接着跑 lint。这保证了每批新资料入库后,潜在的问题(断链、过期、孤岛)能立刻被发现。
为什么不在 ingest 过程中跑? 因为 ingest 中最容易产生断链------Agent 先建了新页面 A,A 里引用了还在计划中的页面 B。如果这时跑 lint,B 会被标记为断链。但实际上 B 的建页操作在队列里还没执行。正确的顺序是:全部建页和更新操作完成 → 跑 backlink 同步 → 最后跑 lint。
Lint 报告的处理:
Agent 不自动修复 lint 发现的问题------只标记。因为有些"问题"可能不是问题:
- OpenCV 交叉编译页面入站为 0------但它是一个高度专业化的移植指南,不需要回链
- BSP 编译系统 400+ 行------但它是"完整参考页面",有意设计为长页面
Agent 标记后,我人工判断:确认的问题让 Agent 修复,否定的问题加"ignore"标记到相关页面。
实战:用 Lint 发现真实问题
发现一:标签分歧。
早期 Wiki 里,同一个标签体系里出现了 debug 和 debugging 两个标签。原因是两批不同的 ingest,Agent 分别选择了不同的标签。Lint 发现后,统一为 debug。
发现二:过期数据。
DDR4 接口设计页面里写"建议使用 CL=14 @ 2400MHz"。3 个月后原厂更新了设计指南,新版本推荐 CL=12。Lint 扫描时对比了 raw/ 中设计指南文件的 sha256------发现源文件变了。进一步对比,发现 CL 值的更新没同步到 Wiki。
发现三:断链。
Agent 在"外设接口总览"页面中写了 \[UE 配置],但对应的页面从未创建。原因是 ingest 时 Agent 判断"UE 配置只有 2 段话,不满足建页阈值",但忘了把 wikilink 改回纯文本。Lint 发现后修复。
给 Lint 加门槛
不是所有 lint 发现都需要人工处理。可以设置阈值:
自动处理:
- 标签不在分类体系中 → 自动查找最接近的已有标签替换
- index 条目缺失 → 自动补全
- 日志超过 500 条 → 自动轮转
人工确认:
- 孤岛页 → 判断是否需要回链还是独立文档
- 过期页 → 判断是否需要更新还是信息仍然有效
- 矛盾页 → 判断哪个版本正确
仅标注:
- confidence: low → 标注但不自动更新
- 页面尺寸 > 200 行 → 标注"建议拆分"但不自动拆
这个分级让 lint 从"所有问题都丢给用户"变成"自己能修的自己修,拿不准的才问用户"。
实践建议:Lint 的节奏
每次 ingest 后自动 lint。 我配置了 Agent 在每次批量摄入完成后自动执行一次 lint。摄入可能引入断链(新页面引用了计划建但忘了建的页面)、可能改变过期状态(新内容让旧页面看起来过时了)。
每周全量 lint。 独立于 ingest,每周跑一次全量扫描。主要关注来源漂移(外部文档可能被更新)和日志轮转(log.md 的膨胀)。
Lint 不是"修好就完了"。 每项发现都是一个学习机会------为什么产生了断链?是建页流程有漏洞还是命名不统一?为什么 confidence: low?是缺乏来源还是忘了标注?把 lint 反馈转化为 SCHEMA.md 规则更新,让同样的问题不再发生。