原文链接:Pytorch-Mint
部分内容参考如下:
Mac安装与加速配置
- Mac M4
bash
conda create -n pytorch_learn python=3.11
conda activate pytorch_learn
# https://pytorch.org/
pip3 install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/cpu
# 验证
python
>>> import torch
>>> print(torch.__version__)
2.14.0.dev20260620
>>> print(torch.device("mps"))
mps- MPS加速配置
- PYTORCH_ENABLE_MPS_FALLBACK = '1'
- 作用:开启算子自动降级
- MPS不支持的运算,自动切CPU执行,避免代码直接报错崩溃;设为0则遇到不兼容算子直接终止程序。
- PYTORCH_MPS_HIGH_WATERMARK_RATIO = '0.8'
- 作用:限制MPS统一内存占用上限
- 0.8代表最多占用整机内存80%,超出阈值自动释放张量,防止内存爆满、电脑卡顿闪退。
python
# 使用注意
# 两行代码必须写在所有import torch代码最前面才能生效
import os
os.environ['PYTORCH_ENABLE_MPS_FALLBACK'] = '1'
os.environ['PYTORCH_MPS_HIGH_WATERMARK_RATIO'] = '0.8'
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print("Device:", device)
mint = Mint().to(device) # Mint() 定义的模型名称,使用mps加速数据迭代载体
Dataset
Dataset 是一个抽象类,所有数据集都需要继承这个类
所有子类都需要重写 getitem 的方法,这个方法主要是获取每个数据集及其对应 label,还可以重写长度类 len
python
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path) # 构建索引列表
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
# use
print("ants len:"+str(len(ants_dataset))) # ants len:124
print("bees_len:"+str(len(bees_dataset))) # bees_len:121
print("all_len:"+str(len(train_dataset))) # all_len:245
img,label = train_dataset[100] # 可通过范围内的索引数字进行获取数据
img.show()
print(label)Dataloader
通俗来说:拿 Dataset 当货源,自动一批一批打包、打乱、多线程搬运给模型。
python
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(
dataset=test_data, # 数据集对象(train_set/test_set)
batch_size=64, # 每批图片数量
shuffle=True, # 是否打乱数据
num_workers=0, # 多线程加载
drop_last=False. # 末尾不足一批是否丢弃
)
# 测试数据集中的第一张图片及其target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("logs")
for epoch in range(2): # 轮次,测试shuffle
step = 0
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()TensorBoard的使用
TensorBoard 是 PyTorch/TensorFlow 配套可视化工具,用来直观查看训练损失、指标、参数、计算图等训练日志。
- add_image()
- tag:TensorBoard图片分类标签,区分不同图像组
- img_tensor:图像数据,支持数组、张量,像素值域01或0255
- global_step:训练步数,作为图像横轴索引
- dataformats:图像维度格式,可选CHW、HWC、HW
- walltime(可选):自定义记录时间,缺省自动生成
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
import torch
writer = SummaryWriter("logs") # 文件名
image_path = "./dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
# 方式1:numpy数组(HWC)
img_array = np.array(img_PIL)
writer.add_image("test_np", img_array, 1, dataformats="HWC")
print(type(img_array))
print(img_array.shape)
'''
<class 'numpy.ndarray'>
(512, 768, 3)
'''
# 方式2:torch tensor
img_tensor = torch.tensor(img_array)
writer.add_image("test_tensor", img_tensor, 2, dataformats="HWC")
# 如果是模型标准 CHW 张量,不用写dataformats
img_chw = img_tensor.permute(2, 0, 1) #把最后一维通道 C 挪到最前面,维度变为 [C, H, W]
writer.add_image("test_CHW", img_chw, 3)
writer.close()- add_scalar()
- tag:曲线标识,区分各类指标
- scalar_value:待记录的指标数值 Y轴
- global_step:训练步数,曲线横轴坐标 X轴
- walltime(可选):自定义记录时间
- display_name(可选):指标展示别名
- description(可选):指标补充注释
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs") # 文件名
image_path = "./dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
# y=2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()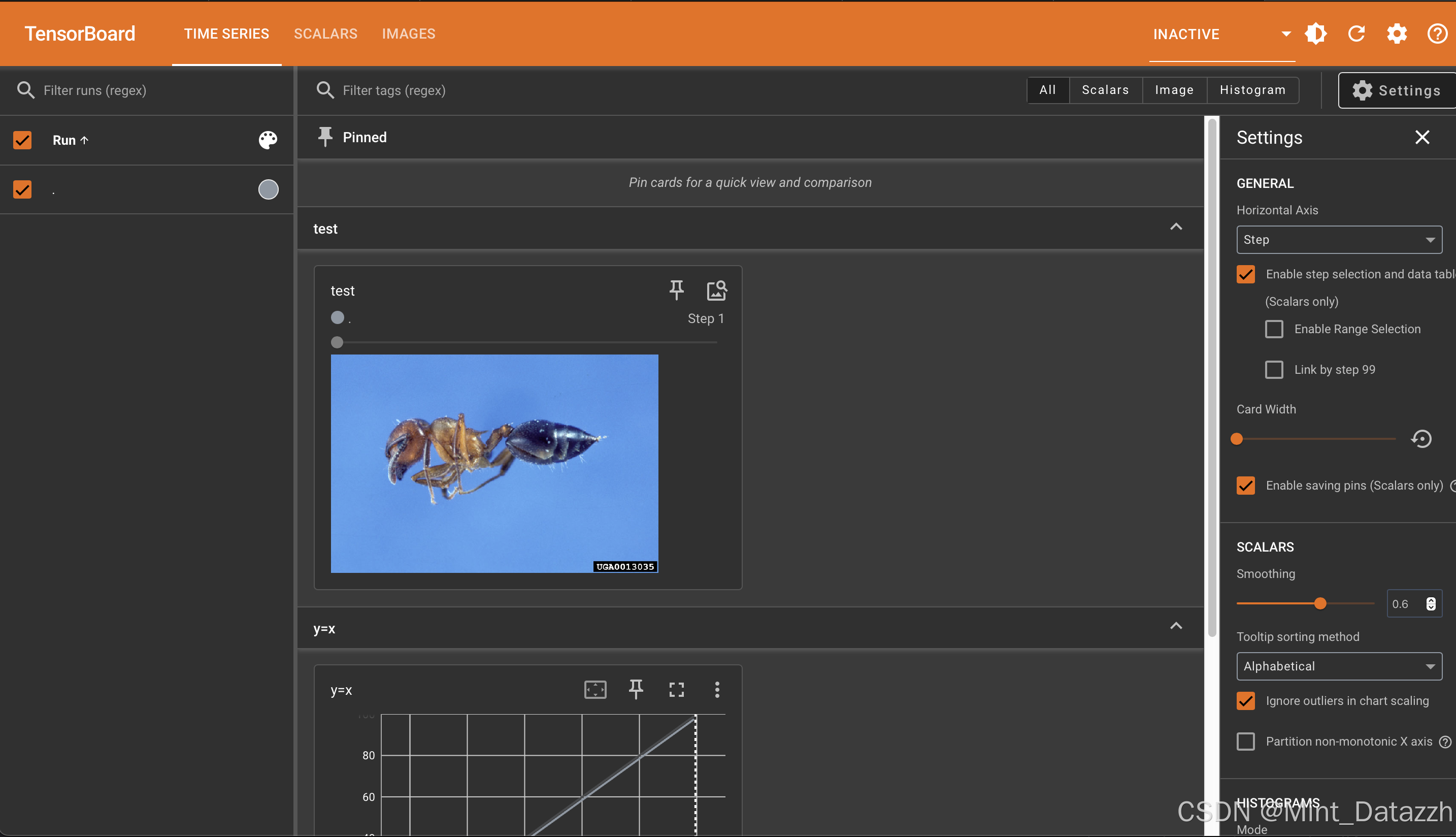
注:python 版本3.11
将 setuptools 降级到 59.8.0
tensorboard 2.20.0
tensorboard --logdir logs --port 6606 # 避免端口冲突
Transforms使用
ToTensor()
转化为张量
python
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "dataset/train/ants/707895295_009cf23188.jpg"
img = Image.open(img_path)
print("type:",img)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor() # 实例化ToTensor转换对象
tensor_img = tensor_trans(img) # 将PIL图片转为张量并归一化
print(tensor_img)
writer.add_image("Tensor_img", tensor_img)
writer.close()Normalize
- 统一数据分布,加快神经网络收敛、提升训练稳定;
- 很多 GAN、图像生成任务习惯用 -1,1 区间输入;
- 让正负数据均衡,激活函数效果更好。
- transforms.Normalize(mean, std, inplace=False)
python
trans_norm1 = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 操作本质是标准化,只是这组特殊均值方差让输出区间变成 [-1,1]。
trans_norm2 = transforms.Normalize([1, 3, 5], [3, 2, 1])
trans_norm3 = transforms.Normalize([0.1, 0.3, 0.2], [0.9, 0.3, 0.1])
img_norm1 = trans_norm1(tensor_img)
img_norm2 = trans_norm2(tensor_img)
img_norm3 = trans_norm3(tensor_img)
writer = SummaryWriter("logs")
writer.add_image("Tensor_norm_img", img_norm1,1)
writer.add_image("Tensor_norm_img", img_norm2,2)
writer.add_image("Tensor_norm_img", img_norm3,3)
writer.close()Resize()
用来修改图片尺寸,缩放图像。
python
print("前:",img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
print("后:",img_resize.size)
'''
前: (1182, 666)
后: (512, 512)
'''
tensor_trans = transforms.ToTensor()
img_resize_tensor = tensor_trans(img_resize)
writer = SummaryWriter("logs")
writer.add_image("Resize_img", img_resize_tensor,1)
writer.close()Compose()
把多个图像预处理操作按顺序打包,一次性执行。
- 参数 transforms_list:列表,存放所有预处理操作
- 执行逻辑:从左到右依次执行,前一个输出作为后一个输入
python
trans_compose = transforms.Compose([
transforms.Resize((512, 512)), # 第一步:缩放
transforms.ToTensor() # 第二步:转张量
])
img_out = trans_compose(img)
trans_totensor = transforms.ToTensor()
img_img = trans_totensor(img)
writer = SummaryWriter("logs")
writer.add_image("Compose_img", img_img,0)
writer.add_image("Compose_img", img_out, 1)
writer.close()RandomCrop()
- 对图像随机裁剪:在原图中随机选取一块指定尺寸区域截取,属于数据增强,用于训练集,提升模型泛化能力。
RandomCrop(size, padding=0, pad_if_needed=False, fill=0, padding_mode="constant")
- size:裁剪尺寸,int为正方形,(H,W)为矩形
- padding:边缘填充,int四边等宽,(l,t,r,b)四边独立设置
- pad_if_needed:原图小于裁剪尺寸时自动填充
- fill:填充像素,灰度单数值,RGB传三元组
- padding_mode:填充模式
- constant:纯色填充(默认)
- edge:复制边缘像素
- reflect、symmetric:镜像填充
python
trans_random = transforms.RandomCrop((250, 150))
trans_compose_2 = transforms.Compose(
[trans_random, trans_totensor]
)
for i in range(10): # 随机裁剪10处
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)torchvision
torchvision 是 PyTorch 生态系统中专门用于计算机视觉任务的扩展库,它提供了以下核心功能:
- 预训练模型:包含经典的 CNN 架构实现(如 ResNet、VGG、AlexNet 等)
- 数据集工具:内置常用视觉数据集(如 CIFAR10、MNIST、ImageNet 等)
- 图像变换:提供各种图像预处理和数据增强方法
- 实用工具:包括视频处理、图像操作等辅助功能
1. 数据获取
python
import torchvision
from jupyter_builder.jupyterlab_semver import test_set
train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False,download=True)2.查看图片数据信息
python
print(test_set[0])
print(test_set.classes)
'''
(<PIL.Image.Image image mode=RGB size=32x32 at 0x111891890>, 3)
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
'''3.数据集转化tensor类型
python
from torchvision import transforms
dataset_transform = transforms.Compose([
transforms.ToTensor(),
])
train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False,transform=dataset_transform,download=True)nn.Module
1.模型定义与使用
python
from torch import nn
import torch
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__() #继承父类
def forward(self, x): # 前向传播
output = x+1
return output
mint = Mint()
x = torch.tensor(1.0)
output = mint(x)
print(output) # tensor(2.)2.卷积层 Conv2d
python
conv = nn.Conv2d(
in_channels=3, # 输入通道
out_channels=16, # 输出卷积核数量=输出通道
kernel_size=3, # 卷积核3×3
stride=1, # 滑动步长
padding=1, # 四周补0圈数
dilation=1, # 空洞卷积扩张
groups=1, # 分组卷积
bias=True # 是否加偏置
)
python
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
# 获取数据
dateset = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset=dateset, batch_size=64)
# 定义模型
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__()
self.conv1 = Conv2d(in_channels=3,
out_channels=6,
kernel_size=3,
stride=1,
padding=0)
def forward(self,x):
x = self.conv1(x)
return x
mint = Mint() # Mint((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)))
# 卷积使用
step = 0
writer = SummaryWriter("logss")
for data in dataloader:
img, tag = data
output = mint(img)
writer.add_images("input", img, step) # torch.Size([64, 3, 32, 32])
output = torch.reshape(output,(-1,3,30,30)) # 写入必须3通道
writer.add_images("output", output, step) # 原先:torch.Size([64, 6, 30, 30])
step+=1
writer.close()3.最大池化层的使用
- 作用
- 下采样:缩小特征图宽高,减少计算量、参数量
- 保留关键特征、降低冗余,轻微抑制过拟合
- 不改变通道数(输入 C = 输出 C)
一句话核心区别:
- 卷积:创造新特征,通道可变,有可训练权重
- 池化:压缩现有特征,通道不变,无任何参数
python
pool = nn.MaxPool2d(
kernel_size=2, # 池化窗口大小
stride=2, # 滑动步长,常用等于kernel_size
padding=0, # 边缘补0
dilation=1, # 空洞池化,极少用
ceil_mode=False # True向上取整输出尺寸,默认向下取整
)
python
import torch
from torch import nn
from torch.nn import MaxPool2d
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape) # torch.Size([1, 1, 5, 5])
mint = Mint()
output = mint(input)
print(output)
# tensor([[[[2, 3],[5, 1]]]])4.非线性激活
- 例如:nn.ReLU(inplace=False)
- False:新建张量存结果,不修改原数据
- True:原地运算,省内存,会覆盖输入
python
from torch import nn
from torch.nn import ReLU, Sigmoid
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__()
self.relu = ReLU(inplace=True)
self.sigmoid = Sigmoid()
def forward(self,x):
output = self.relu(x)
output2 = self.sigmoid(x)
return output,output2
dataset = datasets.CIFAR10("./dataset", train=False, transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
mint = Mint()
relu_out,sigmoid_out = mint(input)
print(relu_out)
print(sigmoid_out)
'''
tensor([[[[1., 0.],
[0., 3.]]]])
tensor([[[[0.7311, 0.5000],
[0.5000, 0.9526]]]])
'''
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
img, tag = data
output1,output2 = mint(img)
writer.add_images("relu_out", output1, step)
writer.add_images("sigmoid_out", output2, step)
step += 1
writer.close()5.线性层
- nn.Linear(in_features, out_features, bias=True)
- in_features:单个样本输入总数字个数 batch=2, 通道6, 高5, 宽5 6 × 5 × 5 = 150
- out_features:输出多少个数字
- bias=True:是否加偏置,默认开启,一般不改
将输入的全部特征做线性加权融合,输出对应类别分值。
- torch.flatten(input, start_dim=0, end_dim=-1)
- input:待展平张量
- start_dim:从第几维开始摊平,图像网络常用 start_dim=1(保留 batch 维)
- end_dim:结束维度,默认最后一维
x.shape=2,6,5,5
torch.flatten (x,1).shape → 2,150
python
import torch
from torch import nn
from torch.nn import Linear
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transforms
dataset = datasets.CIFAR10("./dataset", train=False, transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, x):
output = self.linear1(x)
return output
writer = SummaryWriter("logs")
mint = Mint()
step = 0
for data in dataloader:
imgs, tags = data
imgs_linear = torch.reshape(imgs,(1,1,1,-1 )) # torch.Size([64, 3, 32, 32]) -> torch.Size([1, 1, 1, 196608])
imgs_flatten = torch.flatten(imgs)
print("经过reshape处理后,图片的shape:",imgs_linear.shape)
print("经过flatten处理后,图片的shape:",imgs_flatten.shape)
output_linear = mint(imgs_linear)
output_flatten = mint(imgs_flatten)
print("经过模型处理后(linear),输出的shape:",output_linear.shape)
print("经过模型处理后(flatten),输出的shape:",output_flatten.shape)
step += 1
break
writer.close()
# 经过reshape处理后,图片的shape: torch.Size([1, 1, 1, 196608])
# 经过flatten处理后,图片的shape: torch.Size([196608])
# 经过模型处理后(linear),输出的shape: torch.Size([1, 1, 1, 10])
# 经过模型处理后(flatten),输出的shape: torch.Size([10])Sequential
把多个网络层按顺序打包,不用在 forward 里逐层手写计算,简化代码。
数据会从上到下依次流过每一层。
python
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32, 32, 5, padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
mint = Mint()
print(mint)
input = torch.ones((64, 3, 32, 32))
output = mint(input)
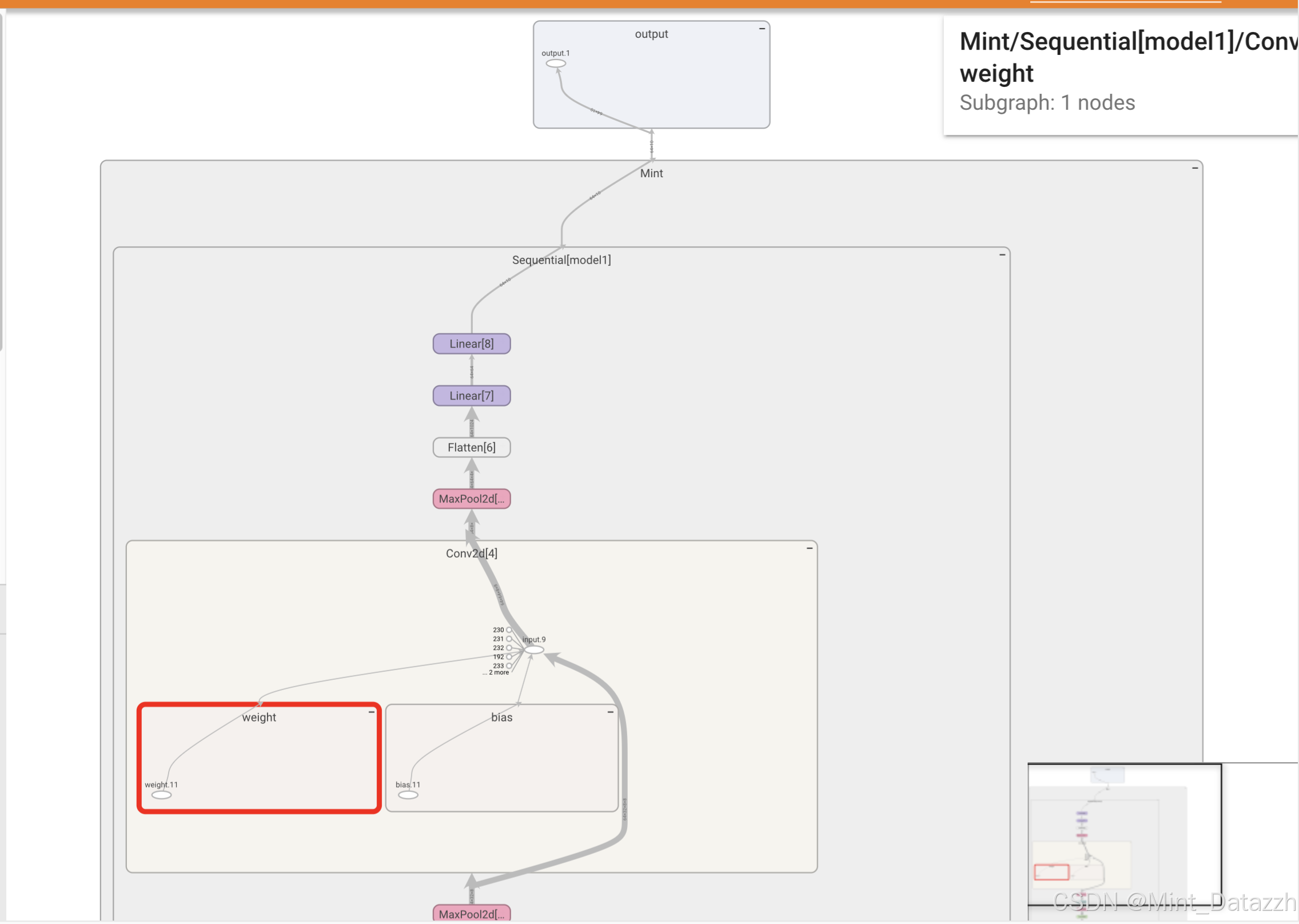
print(output.shape) # torch.Size([64, 10])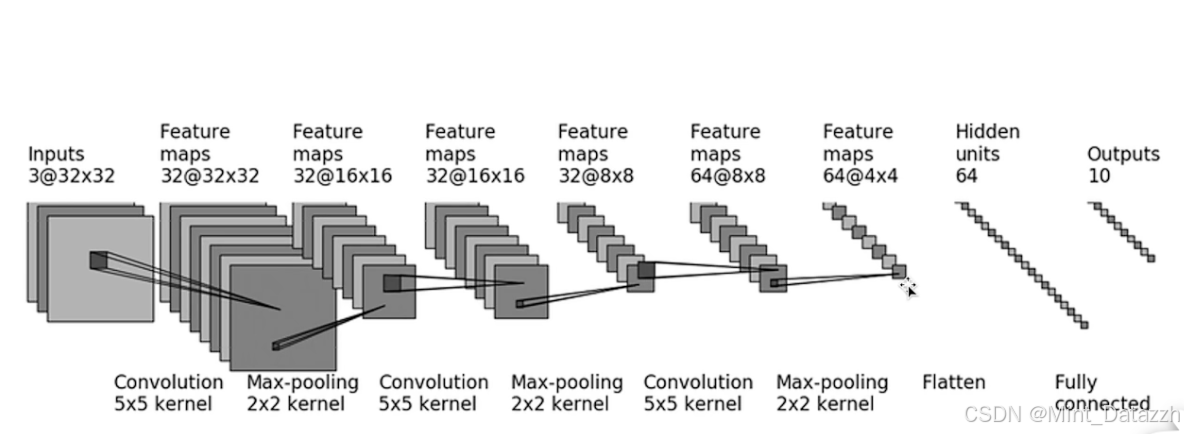
python
writer = SummaryWriter("logs")
writer.add_graph(mint, input)
writer.close()writer.add_graph(模型, 输入数据):把神经网络的计算结构图保存到 TensorBoard 日志,之后用 tensorboard 命令可视化网络层级。
损失函数
计算模型预测结果和真实标签之间的差距,数值越大代表预测越不准,用来指导模型反向更新参数。
L1 Loss
L 1 L o s s = 1 N ∑ i = 1 N ∣ y ^ i − y i ∣ L1Loss = \frac{1}{N}\sum_{i=1}^N \left|\hat{y}_i - y_i\right| L1Loss=N1i=1∑N∣y^i−yi∣
python
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5])
loss = L1Loss(reduction="sum") # or mean
result = loss(inputs, targets)
print(result) # tensor(2.)MSE 均方误差
M S E = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 MSE = \frac{1}{N}\sum_{i=1}^N (\hat{y}_i - y_i)^2 MSE=N1i=1∑N(y^i−yi)2
python
loss_mse = nn.MSELoss() # 计算预测值和真实标签差值的平方 平均值,衡量两者差距。
result_mse = loss_mse(inputs, targets)
print(result_mse) # tensor(1.3333)CrossEntropyLoss 交叉熵损失
CrossEntropy ( x , t a r g e t ) = − log ( e x t a r g e t ∑ i = 0 C − 1 e x i ) \text{CrossEntropy}(x, target) = -\log\left( \frac{e^{x_{target}}}{\sum_{i=0}^{C-1} e^{x_i}} \right) CrossEntropy(x,target)=−log(∑i=0C−1exiextarget)
- Softmax 子公式:将模型输出的任意正负原始得分,换算为区间 0~1、总和为 1 的各类别概率,用于分类判断。
Softmax ( x i ) = e x i ∑ k = 0 C − 1 e x k \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{k=0}^{C-1} e^{x_k}} Softmax(xi)=∑k=0C−1exkexi
python
x = torch.tensor([0.1, 0.2, 0.3]) # 预测分数
y = torch.tensor([1]) # 真实标签
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross) # tensor(1.1019)计算演示示例:输入得分 x = 0.1 , 0.2 , 0.3 x=0.1, 0.2, 0.3 x=0.1,0.2,0.3,真实标签 t a r g e t = 1 target=1 target=1
步骤 1:执行 Softmax,把原始得分转换为概率
-
对每个得分计算自然指数:
e 0.1 ≈ 1.105 , e 0.2 ≈ 1.221 , e 0.3 ≈ 1.350 e^{0.1} \approx 1.105,\ e^{0.2} \approx 1.221,\ e^{0.3} \approx 1.350 e0.1≈1.105, e0.2≈1.221, e0.3≈1.350
-
分母:所有指数结果求和
1.105 + 1.221 + 1.350 = 3.676 1.105 + 1.221 + 1.350 = 3.676 1.105+1.221+1.350=3.676
-
单项除以总和,得到各类别概率:
- 类别 0 概率: 1.105 ÷ 3.676 ≈ 0.300 1.105 \div 3.676 \approx 0.300 1.105÷3.676≈0.300
- 类别 1 概率: 1.221 ÷ 3.676 ≈ 0.332 1.221 \div 3.676 \approx 0.332 1.221÷3.676≈0.332(真实对应类别概率)
- 类别 2 概率: 1.350 ÷ 3.676 ≈ 0.368 1.350 \div 3.676 \approx 0.368 1.350÷3.676≈0.368
Softmax 作用:将无固定范围的模型原始得分,转换成取值 0~1、全部类别概率总和为 1 的标准概率值。
步骤 2:负对数计算交叉熵损失
仅取出真实类别对应的概率参与计算:
l o s s = − ln ( 0.332 ) ≈ 1.102 loss = -\ln(0.332) \approx 1.102 loss=−ln(0.332)≈1.102
优化器与反向传播
torch.optim 是 PyTorch 优化器工具包
作用:利用 loss.backward() 算出的梯度(grad),自动更新网络权重,让损失持续变小。
- SGD:手动统一学习率,靠 momentum 提速;调参要求高,泛化能力有时更好。
- Adam:自适应学习率,收敛更快,新手直接用;大部分图像分类、深度学习任务首选。
python
# SGD
optimizer = SGD(
params=mint.parameters(), # 必传:模型所有可训练权重
lr=0.01, # 必传:学习率,单次权重更新幅度
momentum=0.9, # 动量,缓解震荡、加速收敛
weight_decay=0.0001, # L2正则,防止过拟合
dampening=0,
nesterov=False # 是否开启Nesterov动量
)
# Adam
optimizer = Adam(
params=mint.parameters(),
lr=0.001, # 基础学习率,默认0.001
betas=(0.9, 0.999), # 一阶、二阶动量系数
eps=1e-8, # 防止分母除0,极小值
weight_decay=0.0001
)
python
import os
os.environ['PYTORCH_ENABLE_MPS_FALLBACK'] = '1'
import torch
from torch import nn, optim
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch.nn import CrossEntropyLoss
# MPS设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print("Device:", device)
class Mint(nn.Module):
def __init__(self):
super(Mint, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
dataset = datasets.CIFAR10(root='./dataset', train=True, download=False, transform=transforms.ToTensor())
# 扩大batch消除梯度震荡
dataloader = DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4,
pin_memory=False,
persistent_workers=True
)
mint = Mint().to(device)
loss_fn = CrossEntropyLoss()
optimizer = optim.Adam(mint.parameters(), lr=0.01). # 优化器
for epoch in range(20):
running_loss = 0.0
for img, label in dataloader:
img = img.to(device, non_blocking=True)
label = label.to(device, non_blocking=True)
optimizer.zero_grad() # 梯度清零(必须写,否则梯度会累加)
output = mint(img)
loss_cross = loss_fn(output, label)
loss_cross.backward()
optimizer.step(). # 更新权重,读取所有参数的 .grad,按照优化算法公式调整权重。
running_loss += loss_cross.item()
avg_loss = running_loss / len(dataloader)
print(f"epoch:{epoch}, avg loss:{avg_loss:.4f}")网络模型
1.加载网络模型
python
import torchvision
from torch import nn
from torchvision.models import VGG16_Weights
train_data = torchvision.datasets.ImageNet(
root='./dataset',
split='train',
transform=torchvision.transforms.ToTensor()
)
vgg_16_false = torchvision.models.vgg16(weights=None) # 不加载预训练权重,参数随机初始化
vgg_16_true = torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT) # 加载ImageNet预训练权重2.修改网络层
python
# 方法一:
vgg_16_true.classifier.add_module('fc1', nn.Linear(1000, 10)) # 1.新增,末尾追加
vgg_16_true.classifier[-1] = nn.Linear(4096, 10) # 2.修改
# 方法二:
cls_layers = list(vgg_16_false.classifier.children()) # 3.取出分类层列表
cls_layers[-1] = nn.Linear(4096, 10) # 修改:替换最后一层
cls_layers.insert(4, nn.BatchNorm1d(4096)) # 插入:在第3层后插入BN层(索引3后插入)
del cls_layers[-1] # 删除:删除最后一层
vgg_16_false.classifier = nn.Sequential(*cls_layers) # 重新封装为Sequential赋值回去3.网络模型的保存与加载
python
import torch
import torchvision
from torchvision.models import vgg16
vgg_16 = torchvision.models.vgg16(weights=None)
# 保存模型结构及其参数 + 加载模型
torch.save(vgg_16, './vgg_16.pth')
vgg_16_load = torch.load('./vgg_16.pth', weights_only=False)
# 只保存参数 + 加载模型
torch.save(vgg_16.state_dict(), "vgg16_params.pth")
new_model = vgg16(weights=None)
params_dict = torch.load("vgg16_params.pth")
new_model.load_state_dict(params_dict)
print(new_model)完整模型训练与验证
训练
python
import os
# MPS配置放最前面
os.environ["PYTORCH_MPS_LOW_WATERMARK_RATIO"] = "0.7"
os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"] = "0.8"
os.environ['PYTORCH_ENABLE_MPS_FALLBACK'] = '1'
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import torch.nn as nn
# 设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print("Device:", device)
# 数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset',train=True,transform=transforms.ToTensor(),download=False)
test_data = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=transforms.ToTensor(),download=False)
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练集的数据量为:{train_data_size}") # 50000
print(f"测试集的数据量为:{test_data_size}") # 10000
train_dataloader = DataLoader(train_data,batch_size=64,shuffle=True)
test_dataloader = DataLoader(test_data,batch_size=64,shuffle=False)
# 网络
class Mint(nn.Module):
def __init__(self):
super(Mint,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10),
)
def forward(self,x):
return self.model(x)
mint = Mint().to(device)
# 损失、优化器
loss_fn = nn.CrossEntropyLoss()
learning_rate = 0.01 # 1e-2 = 1 x (10)^(-2) = 0.01
optimizer = torch.optim.SGD(mint.parameters(),lr=learning_rate)
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
writer = SummaryWriter("logs")
for i in range(epoch):
print(f"----------第{i+1}轮训练-------")
mint.train()
# 训练
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = mint(imgs)
loss = loss_fn(output, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print(f"训练次数:{total_train_step},loss:{loss.item():.4f}")
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试
mint.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = mint(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(dim=1)==targets).sum()
total_accuracy += accuracy.item()
avg_test_loss = total_test_loss / len(test_dataloader)
print(f"整体测试集上的loss:{avg_test_loss:.4f}")
print(f"整体accuracy:{total_accuracy/len(test_dataloader):.4f}")
writer.add_scalar("test_loss", avg_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(mint.state_dict(),f"./mint_{i}.pth")
writer.close()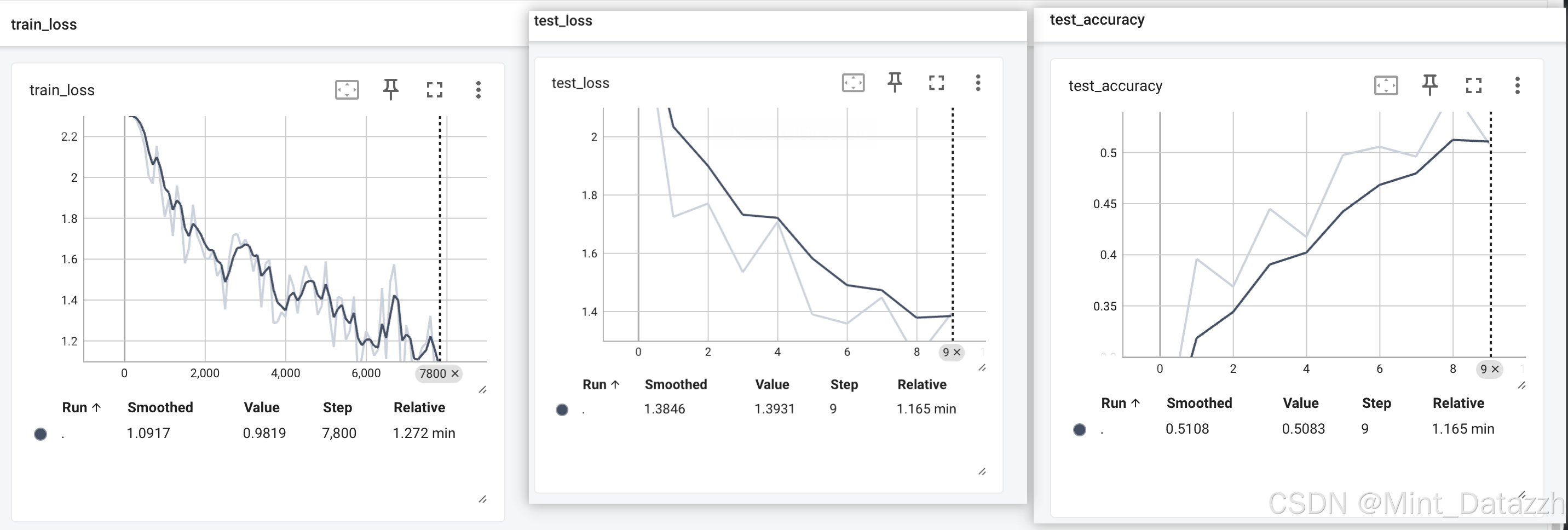
验证
python
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
class Mint(nn.Module):
def __init__(self):
super(Mint,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10),
)
def forward(self,x):
return self.model(x)
img = Image.open("./dog.png").convert("RGB")
model = Mint()
params_dict = torch.load('./mint_29.pth')
model.load_state_dict(params_dict)
trans_compose = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor()
])
input = trans_compose(img)
input = torch.reshape(input,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(input)
print(output)
print(output.argmax(1))