Claude Code 动态工作流:一个任务一套专属 Harness
Claude Code · 2026-06-02 · 5min · Thariq Shihipar and Sid Bidasaria
上周,Claude Code 上线了动态工作流(dynamic workflows)。现在,Claude 可以在运行中自己写专属的 Harness,根据具体任务来定制。
默认的 Claude Code Harness 是为编码场景设计的,但很多其他类型的任务也能用------事实证明,这些任务本质上和编码差不多。不过有一类特殊任务,需要在 Claude Code 之上构建自定义 Harness 才能达到最佳效果,比如研究(Research)、安全分析(security analysis)、Agent 团队(agent teams)或代码审查(Code Review)。
Workflows 让你动态创建基于 Claude Code 构建的 Harness,Claude 就能更自然地解决这些问题。你还可以把 workflows 分享给别人复用。
下面是我第一次用动态 workflows 的经验和心得,帮你把这个能力用起来。注意,最佳实践还在摸索中:动态 workflows 通常消耗更多 tokens,最适合复杂、高价值的任务。
示例提示词
先看几个示例提示词,感受一下 workflows 能做些什么:
"这个测试大约每 50 次运行会失败 1 次。设置一个 workflow 来复现它。提出关于竞态条件的相互竞争的理论,不要停,直到只有一个理论能在证据中存活下来。"
"使用 workflow,检查我过去 50 个会话,挖掘出我反复犯的错误,并将那些重复出现的问题转化为 CLAUDE.md 规则。"
"使用 workflow,翻阅 Slack 过去六个月的 #incidents 频道,找出那些没人提过 ticket 的重复根因。"
"拿我的商业计划书,运行一个 workflow,让不同的 agent 从投资人、客户和竞争对手三个角度分别拆解它。"
"这里有一个包含 80 份简历的文件夹,使用 workflow 对它们进行排名,选出适合后端岗位的人选,并复核前十名。然后使用 AskUserQuestion 工具就评分标准对我进行面试。"
"我需要给这个 CLI 工具取个名字。使用 workflow 头脑风暴一堆候选名,然后运行一个锦标赛决出前三名。"
"使用 workflow,把我们的 User 模型在所有地方重命名为 Account。"
"使用 workflow,仔细检查我的博客草稿,对照代码库验证每一个技术论断,我可不想发布任何错误的内容。"
动态 workflows 的工作原理
动态 workflows 执行一个 JavaScript 文件,里面有一些特殊函数,用于派生和协调 Subagent:

动态 workflows 也能用标准的 JavaScript 函数,比如 JSON、Math 和 Array,来处理数据。
特别值得了解的是,动态 workflows 可以决定 agent 用哪些模型,以及 subagent 是否在自己的工作树(worktree)中运行------这让 Claude 能自己选需要多大智能和隔离级别。
如果 workflow 被中断(比如用户操作或退出终端),恢复会话后可以从断点继续执行。
为什么需要动态 workflows
当默认的 Claude Code Harness 执行任务时,它得在同一个上下文窗口里同时做规划和执行。对很多编码任务来说这很高效,但碰到长时间运行、大规模并行、高度结构化或对抗性强的任务,就容易出问题。
原因是 Claude 在单个上下文窗口里待得越久,就越容易出现几种失效模式:
- 智能体惰性(Agentic laziness):Claude 在完成特别复杂的多部分任务之前就停下来,做了部分就说任务完成。比如安全审查处理了 50 项里的 35 项就停了。
- 自我偏好偏差(Self-preferential bias):Claude 倾向于偏爱自己的结果或发现,特别是被要求按某个标准来验证或评判这些结果时。
- 目标漂移(Goal drift):多次交互后,对最初目标的忠实度慢慢下降,尤其是经过上下文压缩之后。每次摘要都会丢信息,边界情况需求或"不要做 X"这类约束条件就可能丢失。
创建工作流(Workflow)有助于解决这些问题------通过编排多个独立的 Claude Subagent,让它们各自有独立的上下文窗口和聚焦的目标。
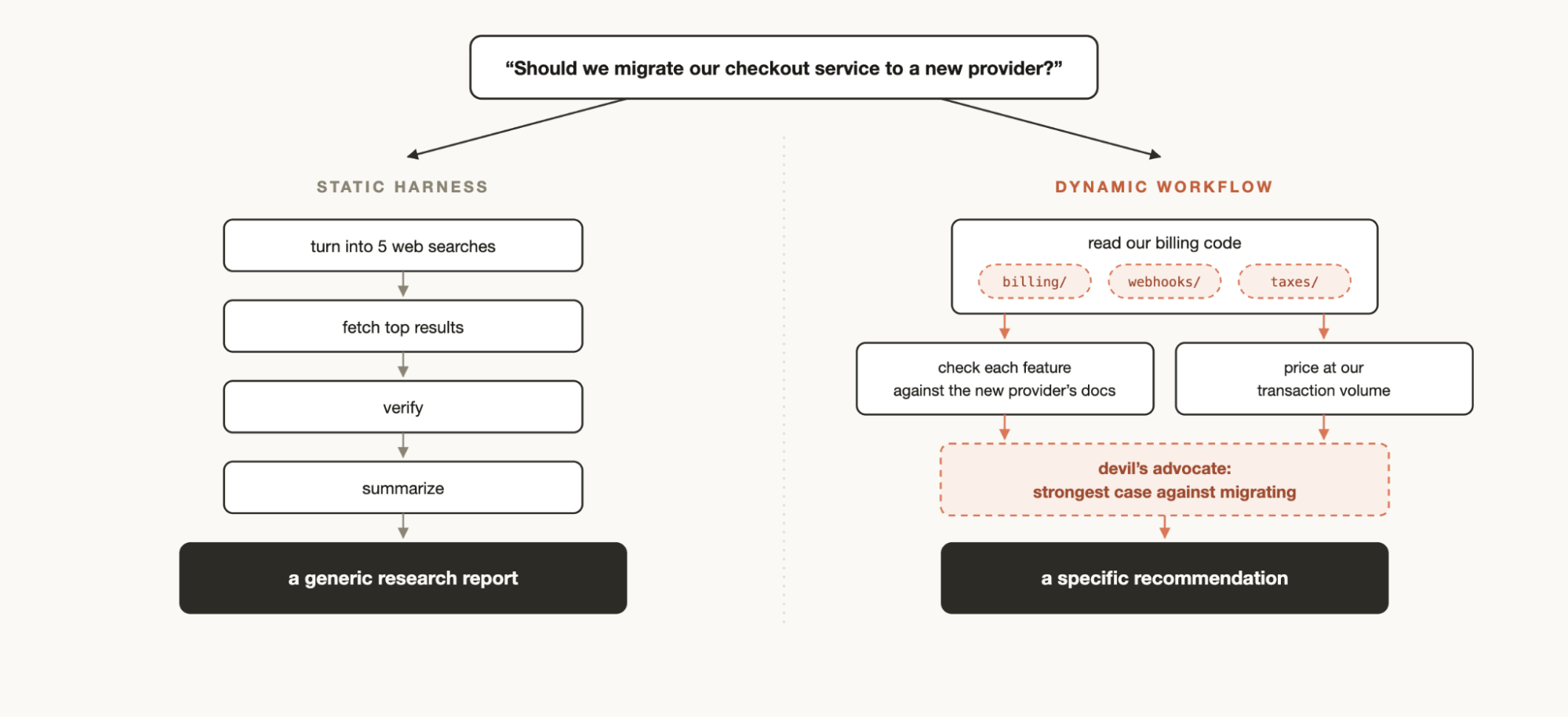
动态工作流 vs 静态工作流
你可能之前用 Claude Agent SDK 或 claude -p 创建过静态工作流来协调多个 Claude Code 实例。
但静态工作流需要覆盖所有边界情况,所以通常比较通用。有了 Claude Opus 4.8 和动态工作流,Claude 现在够聪明,能给你量身定制一个专用的 Harness。
使用动态工作流时的一些实用模式
你可以直接让 Claude 创建一个动态工作流来开始,或者用触发词"ultracode"来确保 Claude Code 创建一个工作流。
不过,了解动态工作流的运作方式,能帮你判断什么时候用,以及怎么通过提示词引导 Claude。
下面是 Claude 在构建工作流时可能用到的几种常见模式,也可以组合使用:
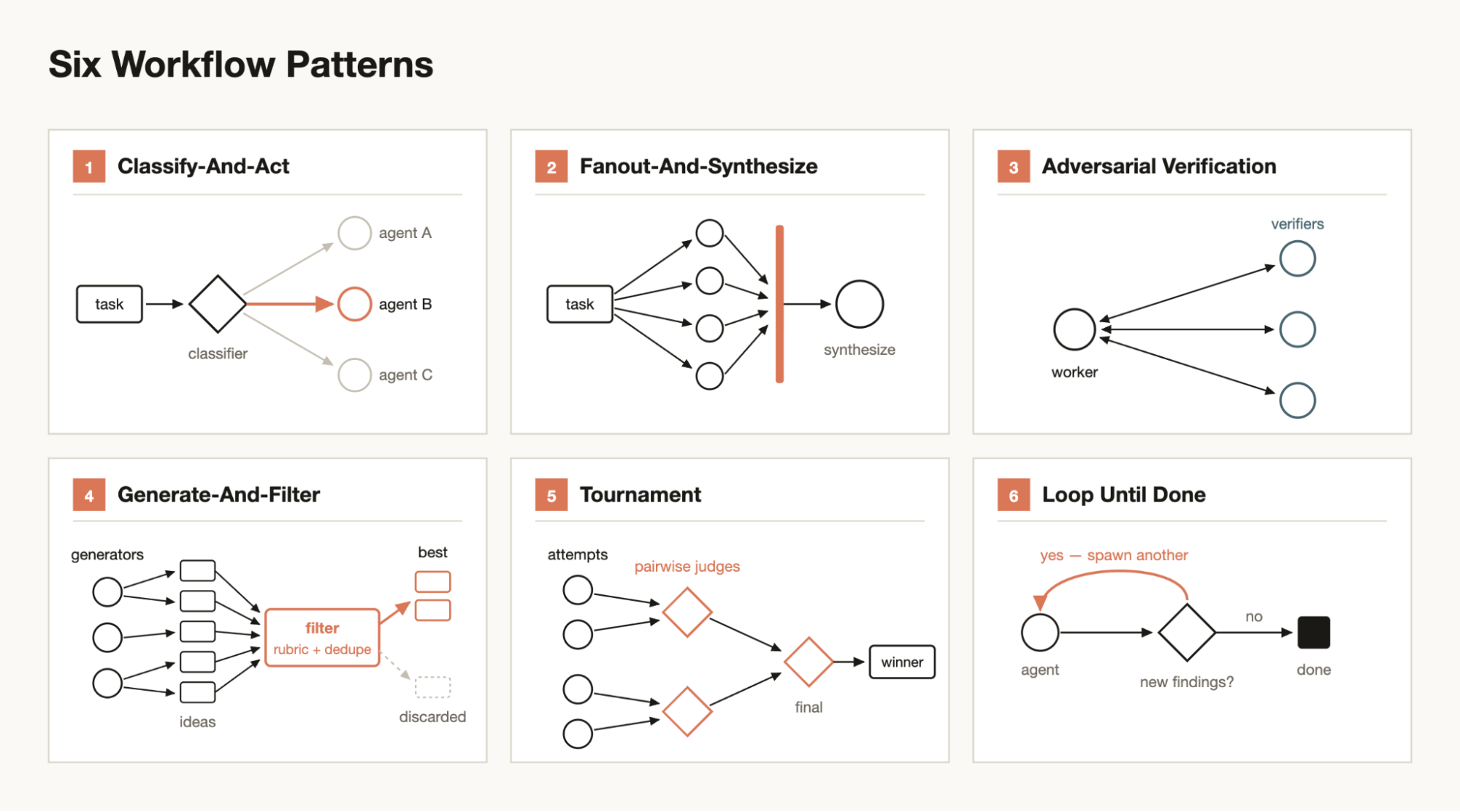
分类并执行(Classify-and-act)
用一个分类器 agent 判断任务类型,然后根据类型路由到不同的 agent 或行为。也可以在结尾用分类器来决定输出。
扇出并综合(Fan-out-and-synthesize)
把一个大任务拆成很多小步骤,每个步骤跑一个 agent,最后把结果综合起来。当小步骤很多,或者每个步骤需要独立的上下文窗口避免相互干扰时,这种方法特别有用。综合步骤是个屏障------它等所有扇出 agent 完成,然后把它们的结构化输出合并成一个结果。
对抗性验证(Adversarial verification)
对每个派生的 agent,再跑一个独立的派生 agent,按评判标准对其输出做对抗性验证。
生成并筛选(Generate-and-filter)
针对某个主题生成一系列想法,然后通过评判标准或验证来筛选,去重后只返回最高质量的、经过验证的想法。
锦标赛(Tournament)
不让 agent 分工,而是让它们相互竞争。派生 N 个 agent,每个用不同方法尝试完成同一任务。然后用评判 agent 做两两比较来评估结果,直到产生胜者。
循环直到完成(Loop until done)
对于工作量不确定的任务,循环派生 agent 直到满足停止条件(没有新发现,或日志里没有更多错误),而不是用固定轮次。
使用场景
放开去想什么时候以及怎么让 Claude Code 创建动态工作流。我甚至发现工作流有时对非技术性工作更有用。
迁移和重构
Bun 用工作流从 Zig 重写为 Rust。具体可以看 Jarred 的 X 推文。
关键是把任务拆成一系列需要处理的步骤,比如针对调用点、失败的测试、模块等。为每个修复在工作树中派生一个 subagent 来执行修复,然后让另一个 agent 做对抗性审查,最后合并。考虑告诉 agent 别用资源密集型命令,这样不耗尽机器资源就能最大化并行度。
深度研究
我们在 Claude Code 里发布了深度研究技能(/deep-research),它用的就是动态工作流。具体来说,它会扇出网络搜索、获取来源、对抗性验证声明,最后综合成一份带引用的报告。
但你的研究目的可能不止于网络搜索。比如让 Claude 从 Slack 上下文里整理一份状态报告,或者深入探索代码库来研究某个功能的工作原理。
深度验证
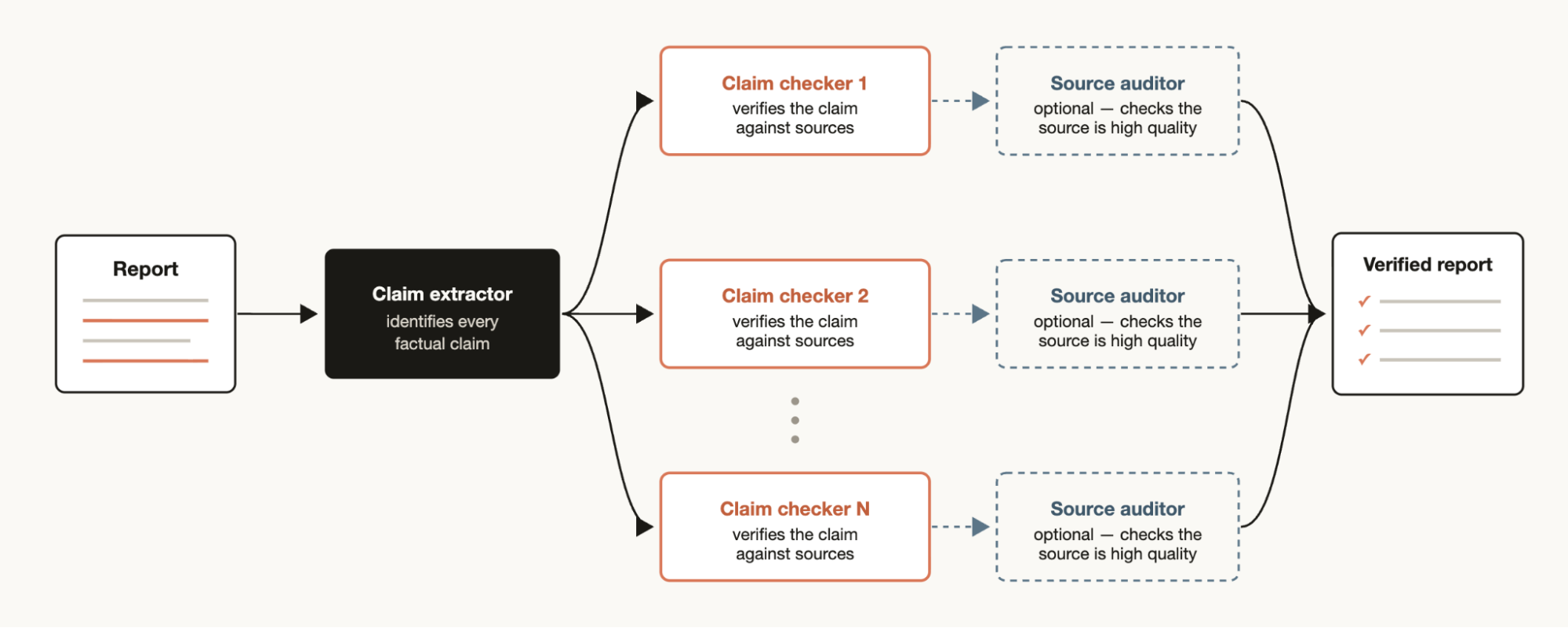
如果你有一份报告,需要核实里面引用的每一项事实主张的来源,可以创建一个工作流:由一个 agent 识别出所有事实主张,然后派生出 Subagent 逐一深入核查。也可以设一个验证 agent(Verification Agent)来检查来源 subagent,确保来源质量够高。
排序
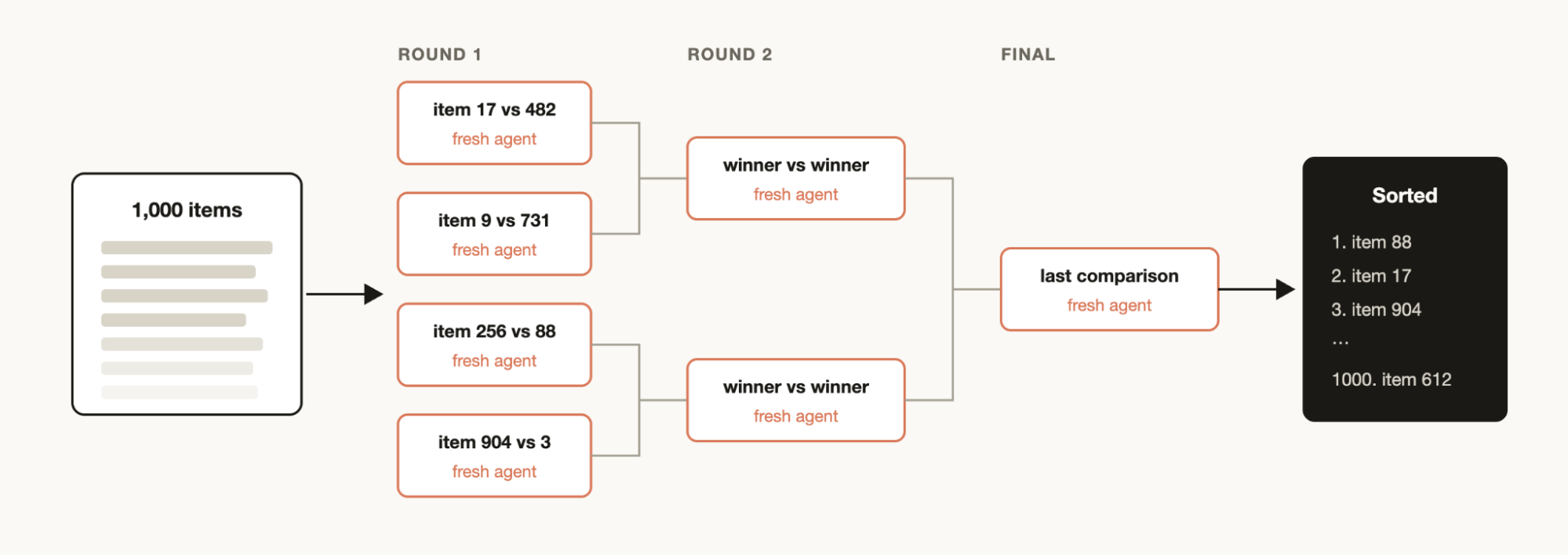
你可能有一个待排序的列表,需要按某种你相信 Claude Code 擅长评估的定性指标来排列,比如按缺陷严重程度给工单排序。但如果在一个 prompt 里对 1000 多行排序,质量会下降,上下文也不够。更好的做法是用锦标赛方式------一个由两两比较 agent(pairwise-comparison agents)组成的流水线(比较判断比绝对评分更可靠),或者并行分桶排序后再合并。每次比较都是一个独立 agent,所以确定性循环(deterministic loop)只持有赛程表,上下文里只保留运行顺序。
记忆与规则遵循
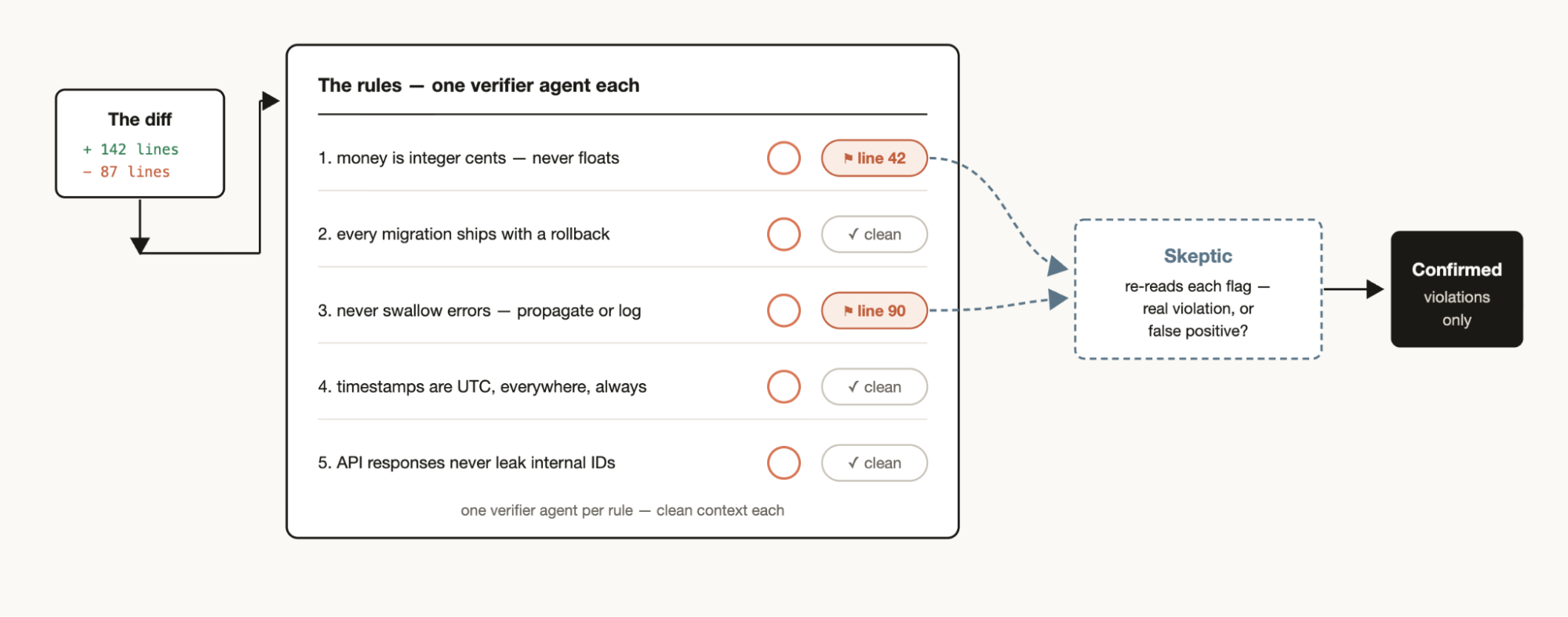
如果你有一套特定规则,发现 Claude 即使写进 CLAUDE.md 也还是会遗漏或难遵守,可以创建一个包含规则列表的工作流,由验证 agent(Verifier Agents)逐条检查------每条规则对应一个验证器。同时创建一个持怀疑态度的 subagent 来审查这些规则,确保它们合理,有助于避免太多误报。
反向模式同样有效:从你最近的会话记录和代码审查评论里,挖掘那些你反复指出的修正点,用并行 agent 做聚类,然后对抗性验证每个候选规则(这条规则能不能阻止真正出现过的错误?),最后把幸存下来的规则提炼回 CLAUDE.md。
根因调查
调试时,最好的方式是提出多个独立的假设并逐一验证。但如果只用单个上下文窗口,Claude 可能会陷入自我偏好偏差。
工作流可以从互不重叠的证据中派生 agent 来生成假设,从结构上避免这个问题。比如分别为日志、文件和数据设置独立的 agent。每个假设随后可以由一组验证者和反驳者(Verifiers and Refuters)组成的评审团来检验。
这不只适用于代码。工作流同样可以用于销售(三月份销售额为什么下滑?)、数据工程(这条流水线为什么失败?)或任何事后复盘场景。
大规模分类筛选
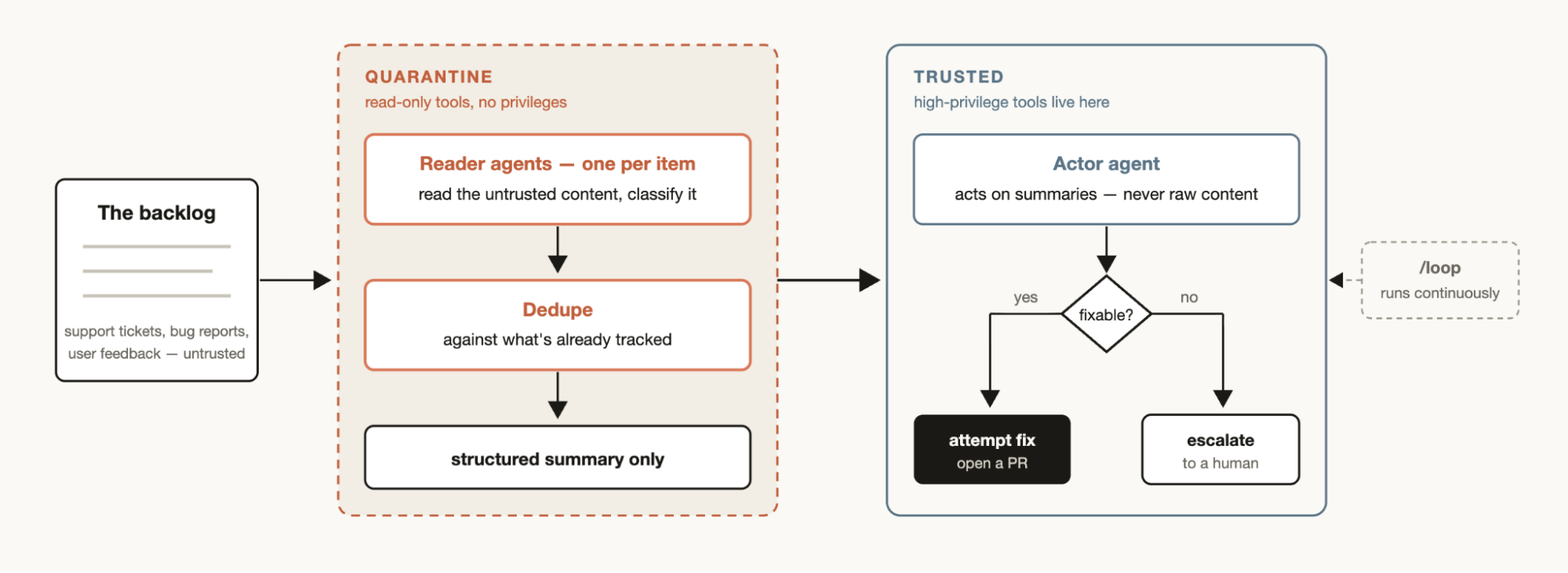
每个团队都有工单队列、Bug 报告或其他没法全人工处理的积压工作。
一个分类筛选工作流(Triage Workflow)会对每个条目做分类,和已有记录去重,然后采取行动。可能直接尝试修复,也可能升级给人工处理。
分类筛选工作流里一个有用的模式是"隔离"(quarantine)。禁止那些读取不受信任的公共内容的 agent 执行高权限操作,这些操作改由负责执行信息的 agent 来完成。
把分类筛选工作流和 /loop 配合使用,可以让 Claude 持续不断地执行这项任务。
探索与品味
你可以让 Claude 探索多种解决方案,同时给一个审查 agent 一套评分标准,说明什么样的方案算好方案。当审查 agent 认为所有标准都满足时,任务才算完成。你还可以基于评分标准,通过锦标赛方式对解决方案做排序或筛选。
评测
你可以通过在工作区里派生独立的 agent 来跑特定任务的轻量级评测,再派生出对比 agent,依据评分标准对具体输出做比较和打分。比如针对特定标准,对你创建的 skill 做评估和优化。
模型与智能路由
创建一个针对你任务场景调优的分类器 agent,由它决定用哪个模型。当任务涉及大量工具调用时,这特别有用------执行前先做一轮调研,能找出最适合这个任务的模型。
比如对于"解释认证模块的工作原理"这个任务,最佳模型的选择取决于认证模块的文件数量和代码库的结构。分类器 agent 可以完成调研,然后根据预期任务复杂度,把请求路由到 Sonnet 或 Opus。
何时不应使用动态工作流
工作流是全新功能。虽然很多场景下效果超出预期,但不是所有任务都需要它,而且它可能消耗大量 Token。
最好创造性地用工作流,把 Claude Code 推向你之前没试过的方向。对于常规编码任务,先问问自己:它真的需要更多算力吗?比如大多数传统编码任务并不需要 5 人的评审小组。
构建动态工作流的技巧
提示工程
用上文介绍的技巧,给动态工作流写详细的提示,能产出最佳效果。
工作流不只能用于大型任务。你可以提示模型用"快速工作流",比如创建一个快速的对抗性评审来检验某个假设。
配合 /goal 和 /loop 使用
当用可重复的工作流时(比如分类、调研或验证),搭配 /loop 定期运行,用 /goal 设定硬性完成条件。
Token 用量预算
你可以给动态工作流设置显式的 Token 用量预算,限制任务消耗的 Token 数量。通过类似"用 10k Token"的提示就能设上限。
保存与分享动态工作流
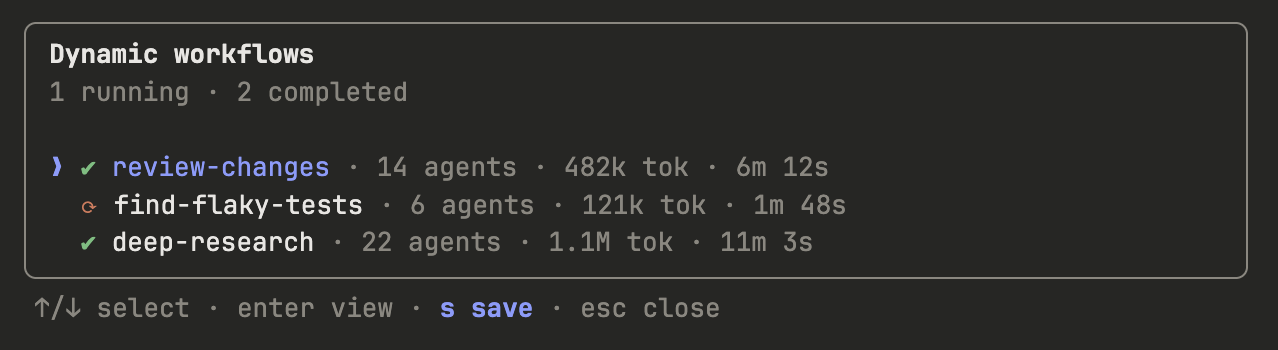
在工作流菜单里按"s"键可以保存工作流。可以检入到 ~/.claude/workflows 目录,或者通过 skill 分发。
要通过 skill 分享工作流,把 JavaScript 工作流文件放进 skill 文件夹,在 SKILL.MD 里引用它们。为了更灵活,你可以提示 Claude 把 skill 里的工作流当作模板,而不是要逐字执行的脚本。

探索的新起点
工作流是扩展 Claude Code 的一种新方式。我建议把它们当作探索 Claude 新用法的起点,帮你完成更多任务。关于怎么用好工作流,还有很大的探索空间。欢迎告诉我你的发现。
📖 更多内容请访问 原文链接