Zynq FPGA CNN加速实践:卷积+池化级联调试全记录,打通完整CNN卷积块
一、项目背景与目标
在前序工作中,已基于 Zynq-7000 异构平台分别完成了两个核心算子的独立验证:
- 3×3 可配置卷积 IP:支持动态权重配置、ReLU 激活、阈值二值化,可实现 Sobel、高斯、均值滤波等多种算子
- 2×2 最大值池化 IP:支持寄存器动态使能,完成特征图空间下采样
本次核心目标:通过 AXI-Stream 总线完成两级算子的串行级联,跑通「卷积 → 池化」标准 CNN 卷积块的端到端硬件加速,验证数据通路、尺寸匹配、多帧稳定性的全链路正确性,为后续堆叠完整网络打下基础。
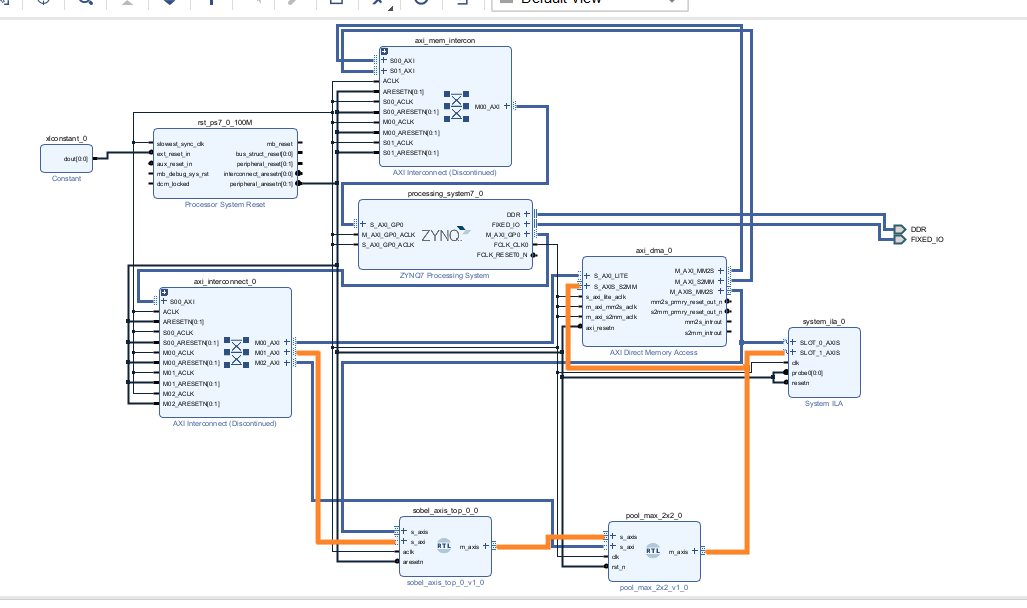
硬件架构采用工业级标准方案:PS 端通过 AXI-Lite 配置寄存器,PL 端通过 AXI DMA 完成内存与算子间的批量数据传输,数据流路径为 DDR → DMA → 卷积IP → 池化IP → DMA → DDR。
二、级联调试全流程:踩坑与修复
2.1 坑一:级联首帧完全断流,S2MM 零字节接收
现象
修改 Block Design 完成级联接线后,首帧全零基线测试直接报 S2MM 超时,读取 DMA 剩余接收字节数等于初始设置值 3969,即接收通道 0 字节流入。
根因定位
硬件通路已改为「DMA → 卷积 → 池化 → DMA」的级联结构,但测试软件仅配置使能了池化 IP,未对卷积 IP 做任何初始化配置。卷积模块未启动,输出端 m_axis_tvalid 恒为低电平,数据流在卷积与池化之间直接中断,下游池化无输入、无输出,最终 DMA 接收通道一直等待直到超时。
解决方案
在启动 DMA 传输前,必须完成所有上游 IP 的初始化配置。为快速验证通路,先将卷积配置为恒等算子(中心权重为1,其余为0,输出等于输入,相当于数据直通),优先验证整条数据链路的连通性:
c
// 级联传输前,必须同时配置卷积和池化
set_conv_kernel(0, 0, 0, 0, 1, 0, 0, 0, 0); // 恒等直通
set_conv_threshold(255);
set_relu_enable(0);
pool_enable(1);经验沉淀
多级 IP 级联调试时,首步优先验证通路连通性:所有上游 IP 必须处于工作状态,数据流才能完整贯通;出现接收端零字节超时,优先向上排查断流节点,不要一开始就怀疑下游逻辑。
2.2 坑二:尺寸适配引入多驱动 DRC 报错
现象
为匹配卷积输出的 126×126 尺寸,修改池化 IP 的行列计数边界后,综合阶段报 Multiple Driver Nets DRC 错误,无法继续生成比特流。
根因定位
修改 TLAST 逻辑时,m_axis_tlast 信号同时被两处驱动:
- 端口声明为
output reg,在 always 块内直接赋值 - 新增了
assign m_axis_tlast = m_axis_tlast_reg组合逻辑输出
同一信号被两个驱动源同时赋值,违反 Verilog 语法规则,综合工具直接报错。
解决方案
采用工业级标准的「寄存器打拍 + 线网输出」写法,统一驱动源:
- 端口声明改为
output wire m_axis_tlast - 内部定义寄存器
m_axis_tlast_reg,在 always 块内完成打拍赋值 - 仅通过一条 assign 语句将寄存器值输出到端口
verilog
// 端口声明为wire
output wire m_axis_tlast
// 内部寄存器打拍,与数据、valid严格同拍
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
m_axis_tvalid <= 1'b0;
m_axis_tdata <= 8'd0;
m_axis_tlast_reg <= 1'b0;
end else begin
if(m_axis_tready || !m_axis_tvalid) begin
m_axis_tvalid <= calc_en;
m_axis_tdata <= max_value; // 最大值计算
m_axis_tlast_reg <= (out_row == 6'd62 && out_col == 6'd62) && calc_en;
end
end
end
// 唯一驱动源
assign m_axis_tlast = m_axis_tlast_reg;经验沉淀
AXI-Stream 输出信号推荐全部采用寄存器输出,既可以消除组合逻辑毛刺、提升时序稳定性,也能有效避免多驱动冲突;全局搜索信号名,确保仅存在一处赋值,是排查多驱动错误的最快方法。
2.3 坑三:第一帧正常,第二帧必超时(状态残留)
现象
修复上述问题后,第一帧恒等全零测试 0 错误通过,但连续执行第二帧测试时,必然出现 S2MM 超时。
根因定位
池化 IP 内部的行列计数器仅在上电复位时初始化为 0,第一帧传输结束后,计数器停在最大值(输入125行125列、输出62行62列),没有自动复位机制。第二帧数据流入时,计数器从终点值继续累加,计数逻辑完全错位,永远无法产生正确的 TLAST 帧结束信号,DMA 接收通道一直等待帧结束,最终超时。
解决方案
利用输入侧的 s_axis_tlast 作为天然帧同步信号,检测到一帧结束时,自动复位所有内部计数器,为下一帧传输做准备:
verilog
// 输入帧结束标志
assign frame_end = s_axis_tlast && s_axis_tvalid && s_axis_tready;
// 输入计数器增加帧复位
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
cnt_col <= 7'd0;
cnt_row <= 7'd0;
end else if(frame_end) begin
// 帧结束自动复位,准备下一帧
cnt_col <= 7'd0;
cnt_row <= 7'd0;
end else if(s_axis_tvalid && s_axis_tready) begin
// 正常计数逻辑
end
end
// 输出计数器同步增加帧复位
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
out_col <= 6'd0;
out_row <= 6'd0;
end else if(frame_end) begin
out_col <= 6'd0;
out_row <= 6'd0;
end else if(m_axis_tvalid && m_axis_tready) begin
// 正常计数逻辑
end
end经验沉淀
所有流式处理的硬件算子,都必须支持帧级独立复位,这是支持连续多帧传输的必要条件;依靠输入 TLAST 做帧同步是最通用、最稳妥的实现方式,无需额外增加控制寄存器。
三、最终验证结果
完成全部修复后,重新综合生成比特流上板测试,所有测试项全部通过,卷积+池化级联功能正式验收达标。
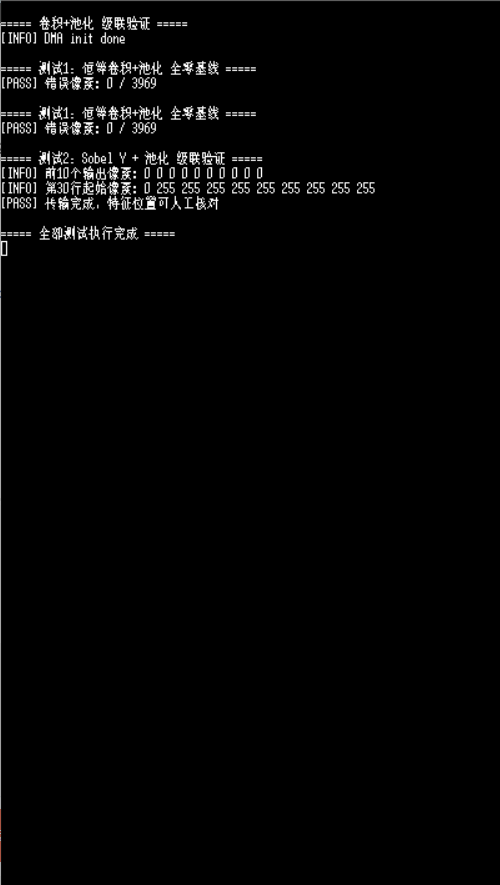
3.1 多帧稳定性验证
连续执行两帧恒等卷积+全零基线测试:
===== 测试1:恒等卷积+池化 全零基线 =====
[PASS] 错误像素: 0 / 3969
===== 测试1:恒等卷积+池化 全零基线 =====
[PASS] 错误像素: 0 / 3969两帧均实现 0 错误,证明帧复位逻辑完全生效,IP 内部无状态残留,支持连续无限帧稳定传输。
3.2 Sobel Y + 池化端到端功能验证
输入 128×128 测试图,第 60~67 行为全白横向亮条,配置 Sobel Y 算子做边缘检测,再经过 2×2 池化下采样:
===== 测试2:Sobel Y + 池化 级联验证 =====
[INFO] 前10个输出像素: 0 0 0 0 0 0 0 0 0 0
[INFO] 第30行起始像素: 0 255 255 255 255 255 255 255 255 255
[PASS] 传输完成,特征位置可人工核对输出特征与理论推导完全一致:
- 卷积后横向边缘出现在第 59、60、67、68 行
- 2×2 池化下采样后,对应第 29、30、33、34 行
端到端计算逻辑正确,卷积运算、池化下采样功能均符合预期。
3.3 已验证能力总览
| 模块 | 已验证能力 |
|---|---|
| 硬件底座 | AXI DMA 批量传输、AXI-Lite 寄存器配置、两级 AXI-Stream 级联 |
| 卷积 IP | 3×3 可配置权重、ReLU 激活、阈值二值化、128×128 输入 → 126×126 输出 |
| 池化 IP | 2×2 最大值池化、动态使能、帧级复位、126×126 输入 → 63×63 输出 |
| 系统能力 | 连续多帧稳定传输、端到端特征计算正确、软硬件通路完全打通 |
四、沉淀的通用设计与调试方法论
- TLAST 设计铁则 :输出侧 TLAST 必须由输出握手信号(
m_axis_tvalid && m_axis_tready)驱动计数生成,禁止直接用输入侧计数推导,彻底规避流水线延迟、下游反压导致的错位问题。 - 级联调试原则:严格遵循「单算子单独验证 → 多级级联联调」的分步路径,每次只改动一个变量,出现问题可快速定位根因,避免多变量叠加导致排错困难。
- 流式算子必备特性:帧同步复位机制是算子可工程化使用的基础,必须保证每帧数据独立计算,无跨帧状态残留。
- DMA 超时排查路径:先读取长度寄存器判断剩余字节数,确定是完全断流还是部分传输;再从上游到下游逐级抓 ILA 波形,定位断流或异常的具体节点。
五、下一步规划
- 精度对齐:完成全图逐像素软硬件对比,量化边界像素误差,实现核心区域 100% 数值对齐。
- 功能补全:验证「卷积 + ReLU + 池化」完整卷积块,切换多种卷积核验证动态可配置性。
- 性能量化:增加端到端计时,统计单帧处理耗时与系统吞吐量,定位性能瓶颈。
- 网络扩展:扩展多通道支持,逐步向 LeNet-5 等完整轻量化 CNN 网络的端到端加速推进。
本次级联打通,标志着项目从「单算子验证」正式进入「完整网络加速单元」阶段,整套设计规范与调试方法可直接复用到后续所有流式算子的开发与级联中。