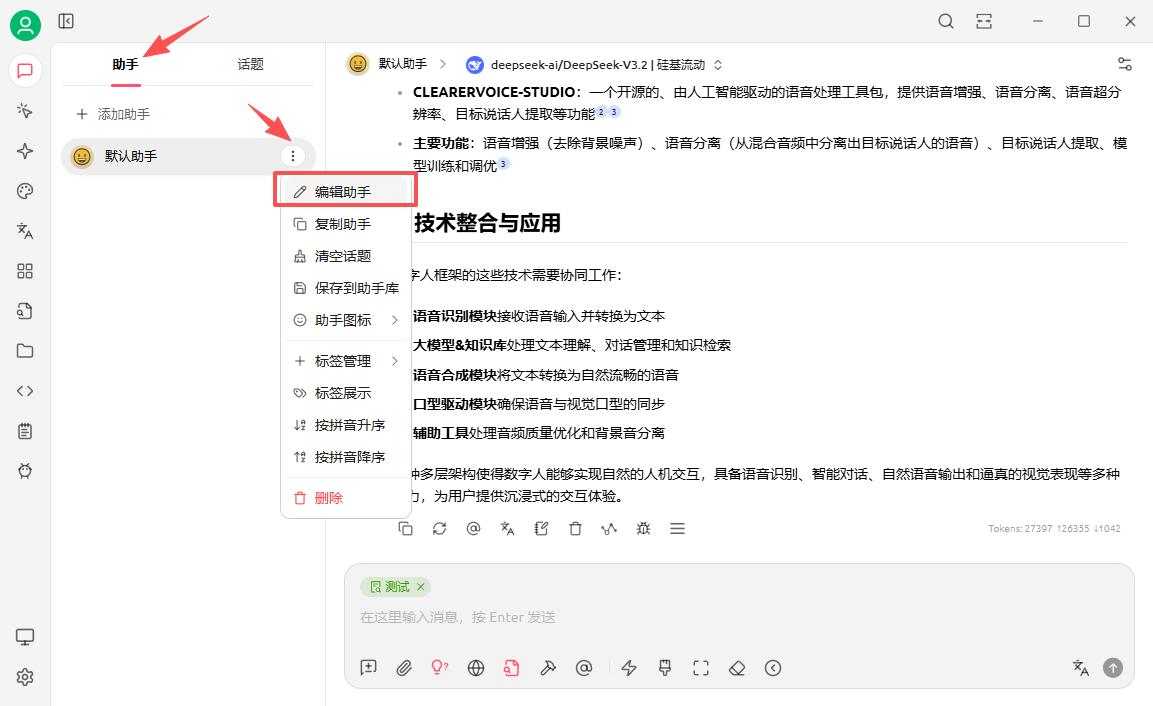
知识库官方教程:知识库教程
一、设置嵌入模型
支持的嵌入模型:嵌入模型
Huggingface上会定期更新嵌入模型排行榜,排名不是越高越好,根据自己场景选择:huggingface
1.1 本地模型
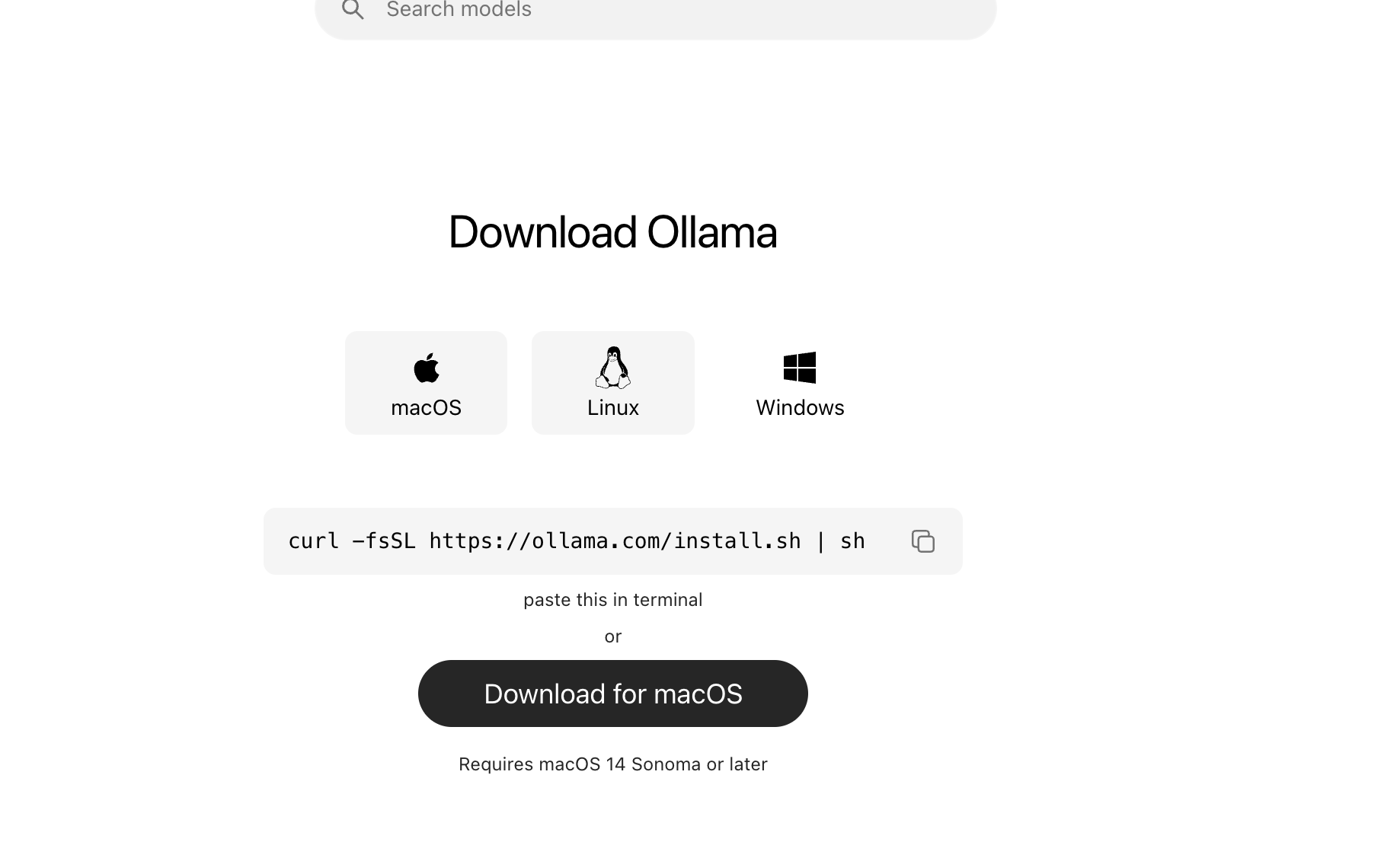
如果电脑性能比较好,对数据保密性要求很高的,可以考虑安装ollama部署嵌入模型:下载ollama
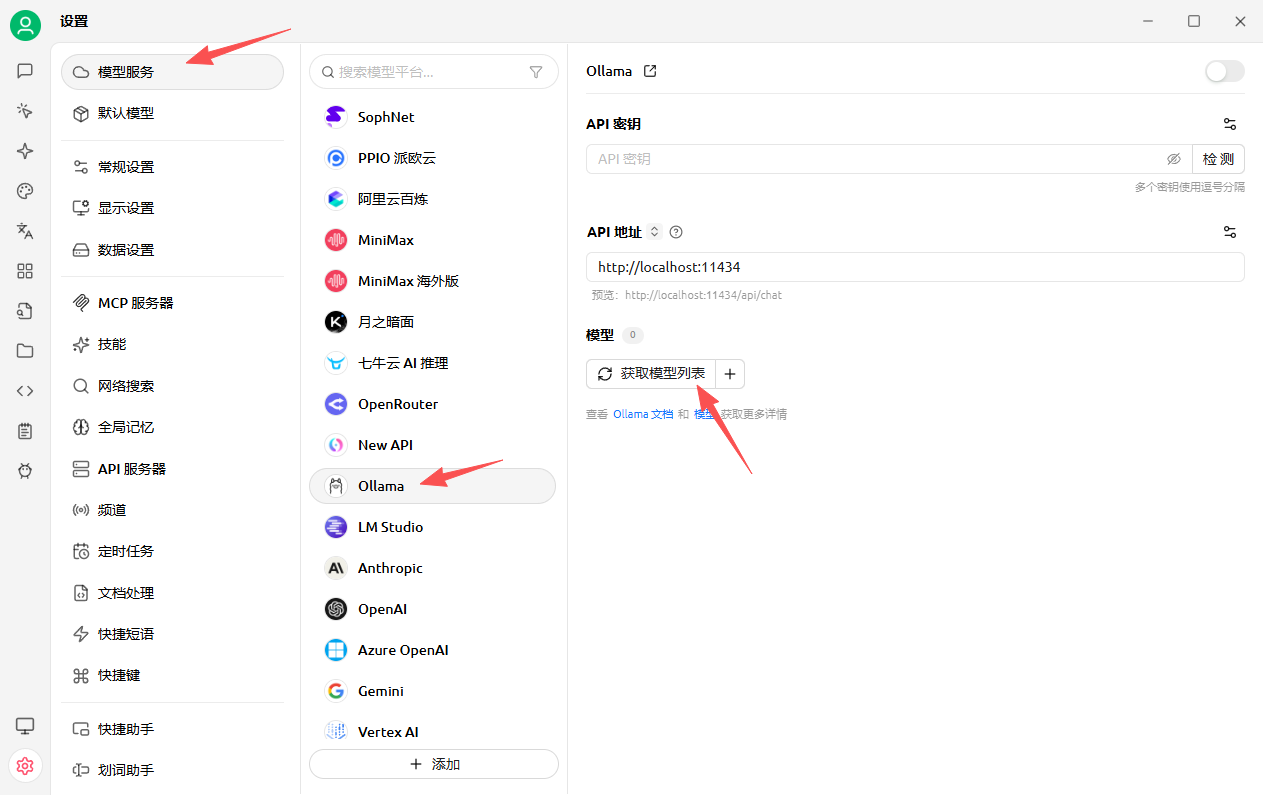
可以在 模型->Embedding 页面选择想要安装的嵌入模型:
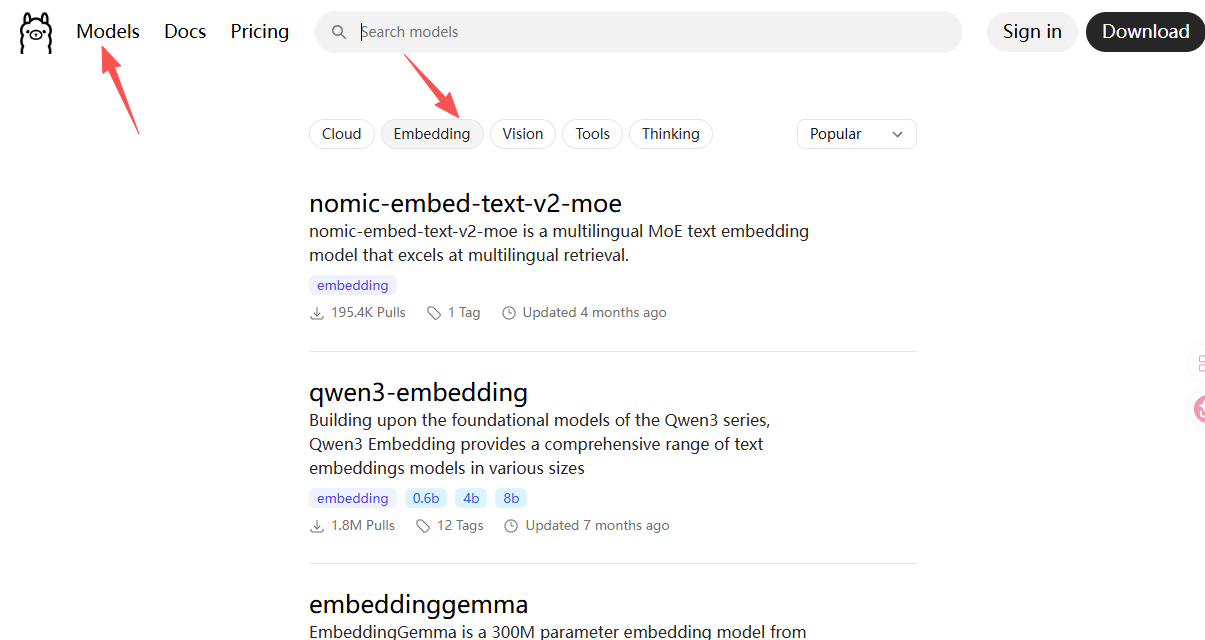
这里以最通用的bge-m3 为例,打开cmd,输入以下命令进行下载安装:
bash
ollama pull bge-m3然后在模型服务里选择ollama获取模型列表:
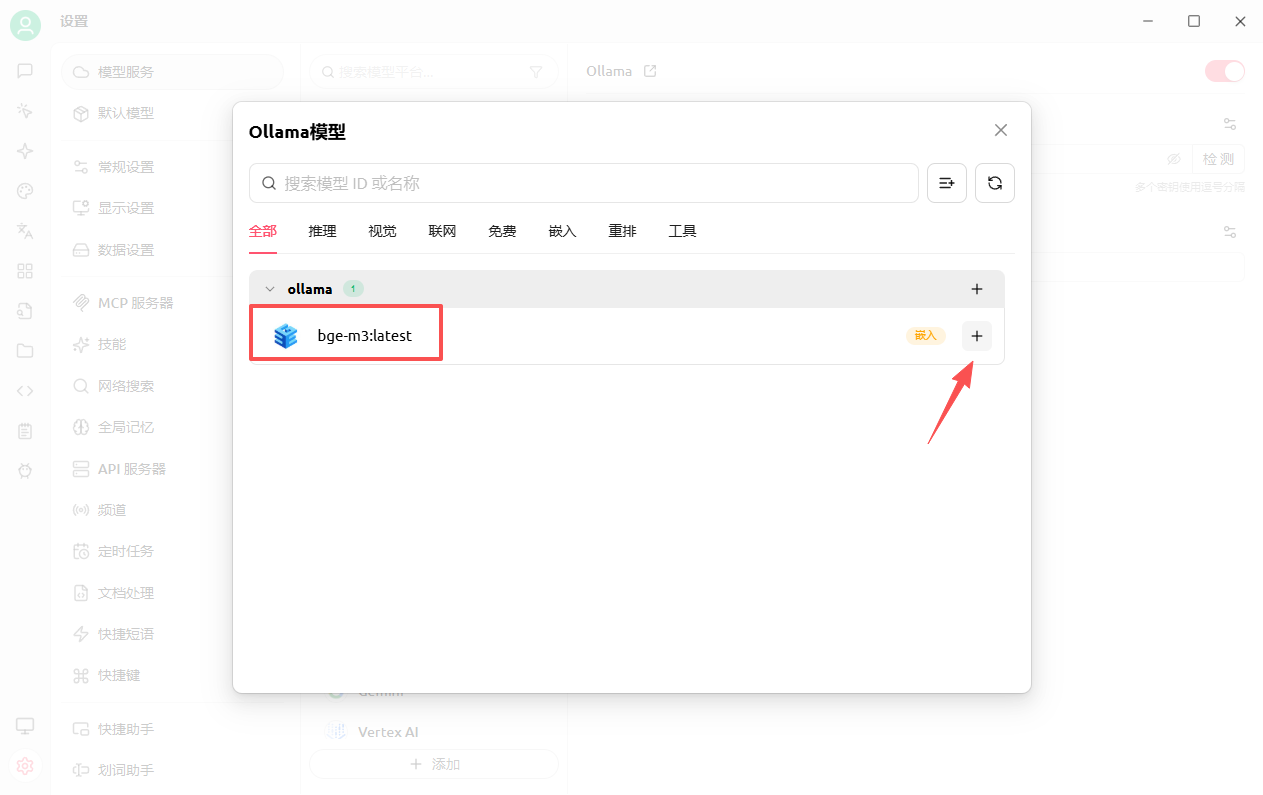
1.2 第三方在线模型
没有硬件条件的小伙伴也可以使用第三方在线模型,这里以硅基流动平台为例,可以登录进行添加。登陆后会自动获取API密钥,如果没有获取,也可以手动访问获取。
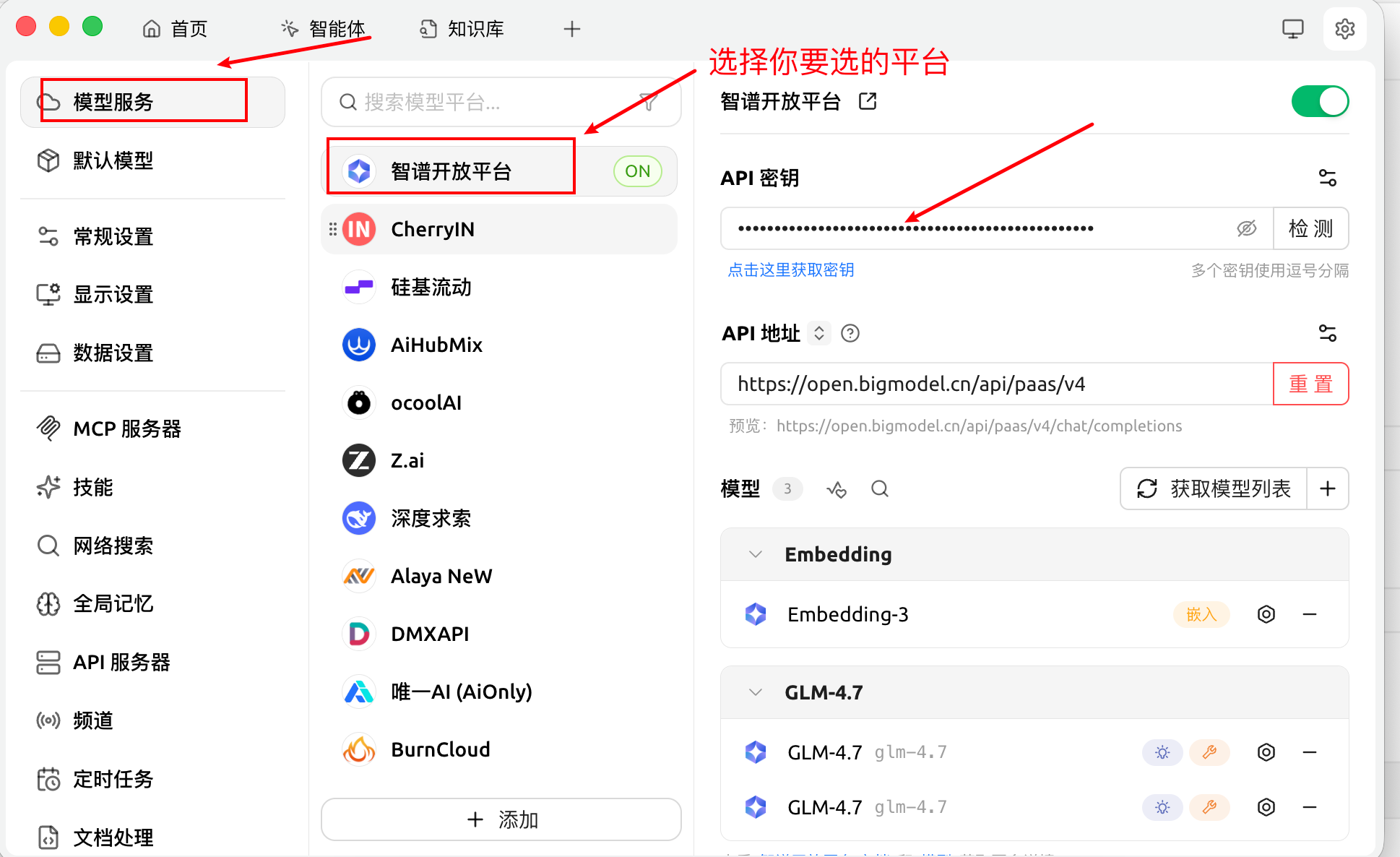
然后获取模型列表,在里面找到嵌入模型:
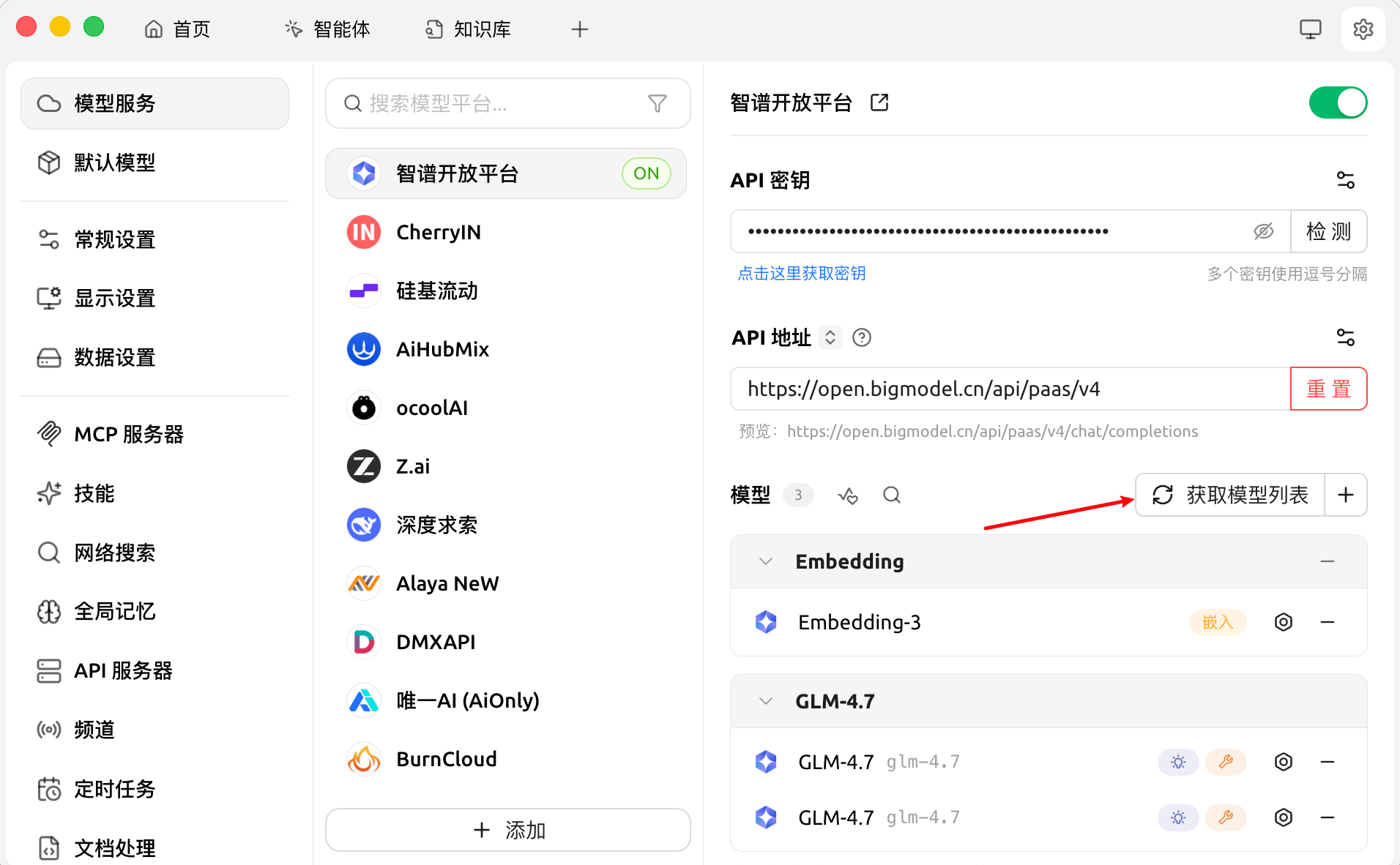
二、创建知识库
以下是知识库入口:
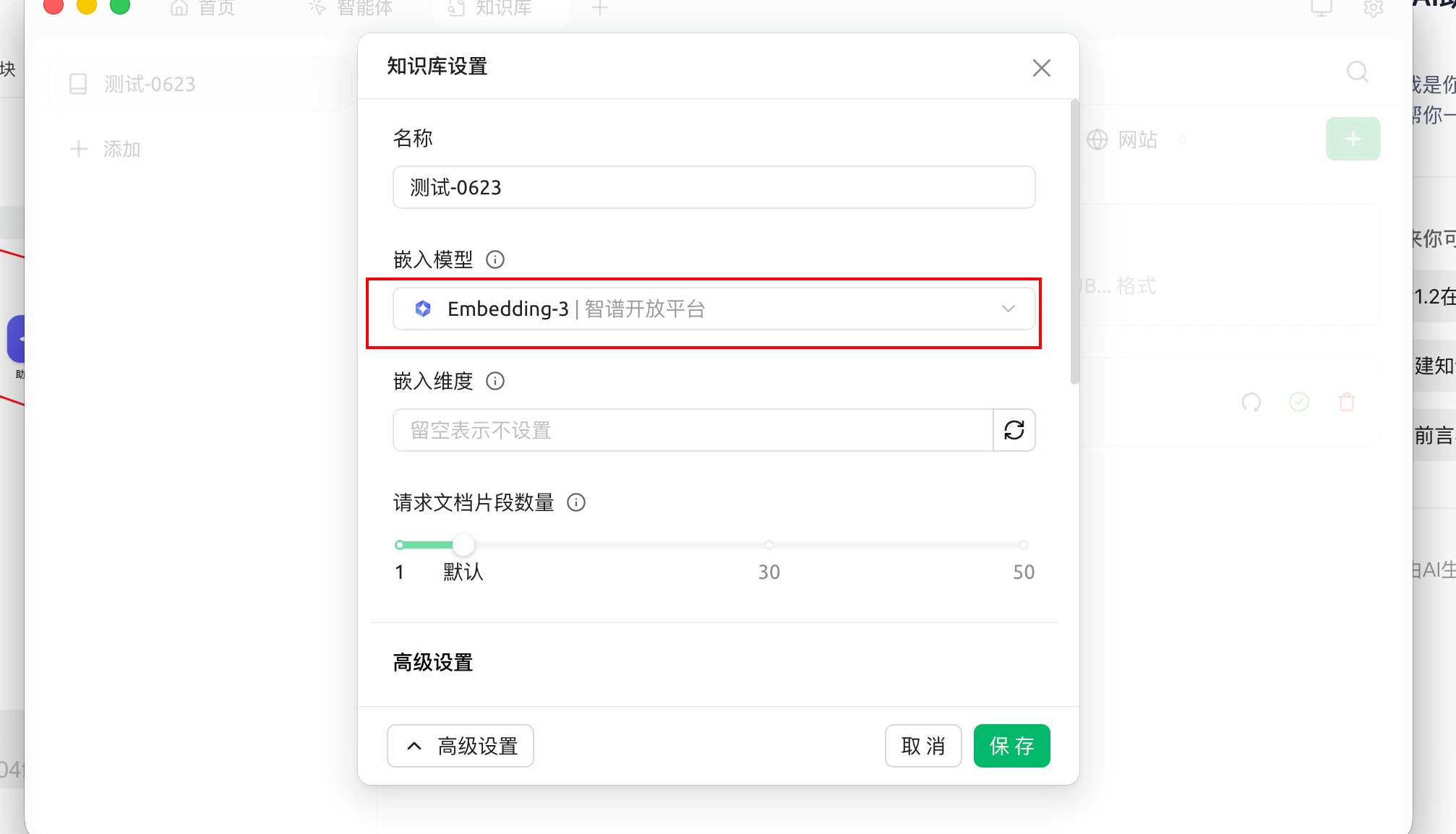
输入知识库的名称并添加嵌入模型,以 embedding-3 为例,即可完成创建:
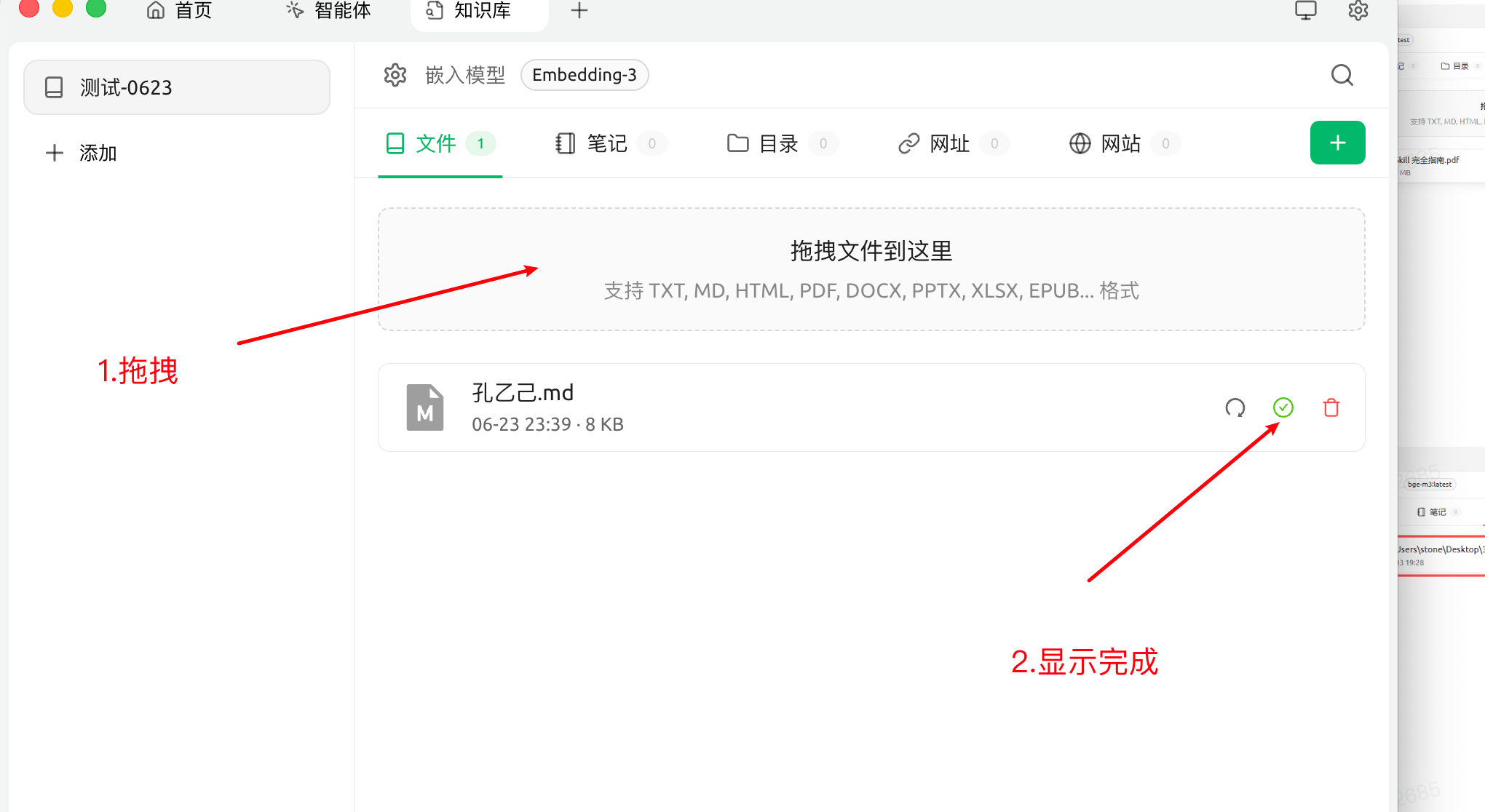
创建完成后可以拖拽文件进行导入,导入完成后会显示状态。如果导入失败,可以检查一下文档格式是否合规、嵌入模型是否配置好。
我出现过401等等问题,排查后发现是以下问题:
- 我的token apikey欠费了;
- 我用的coding plan或者订阅资源包的apikey;
以上两种方式是用不了嵌入模型的。
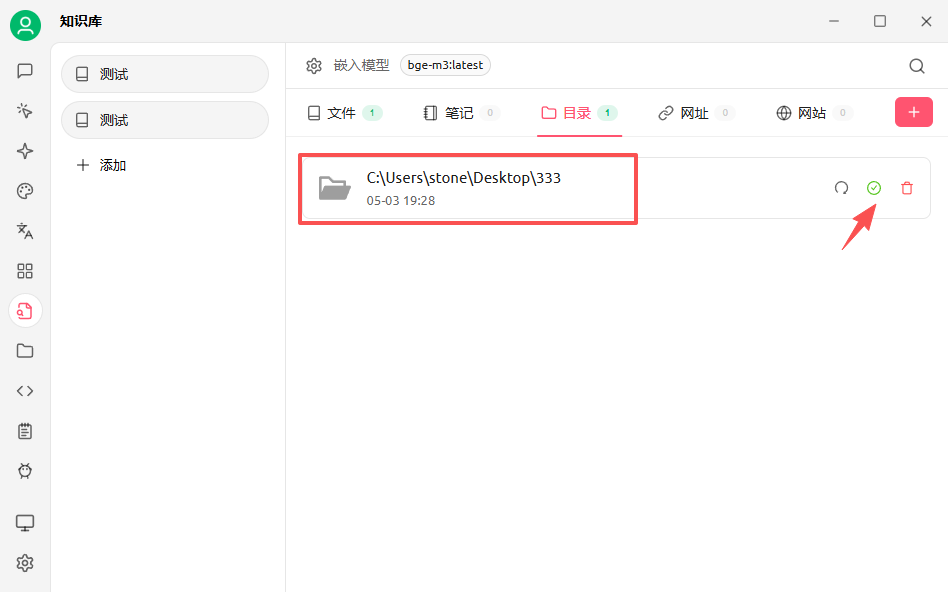
2.1 文件和目录导入
也支持将一整个目录进行导入,避免一个一个导入的麻烦:
2.2 笔记导入
2.3 网址和网站导入
这里以deepseek文档为例https://api-docs.deepseek.com/zh-cn/
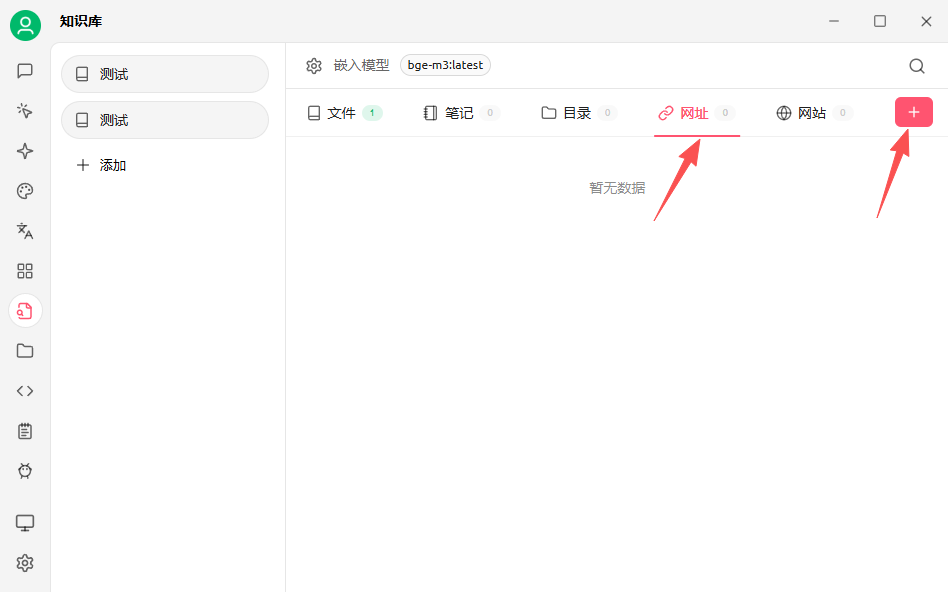
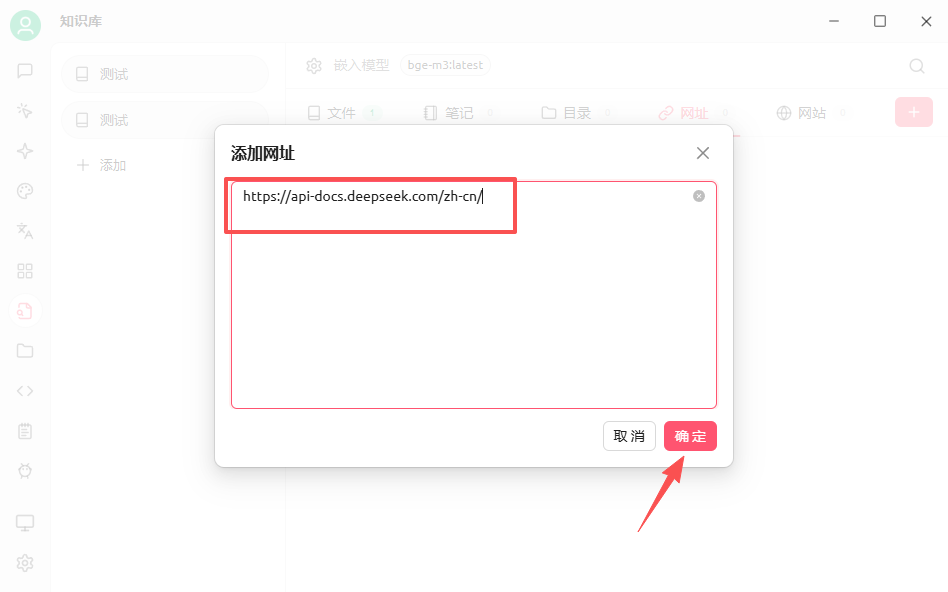
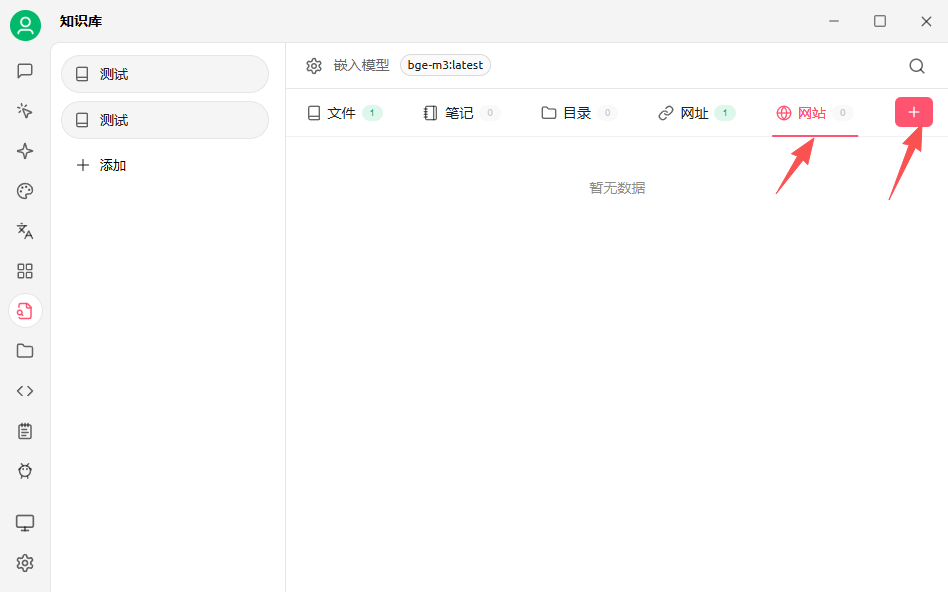
也可以添加站点地图,支持 xml 格式的站点地图,在网站后加/sitemap.xml可以获取到相关信息
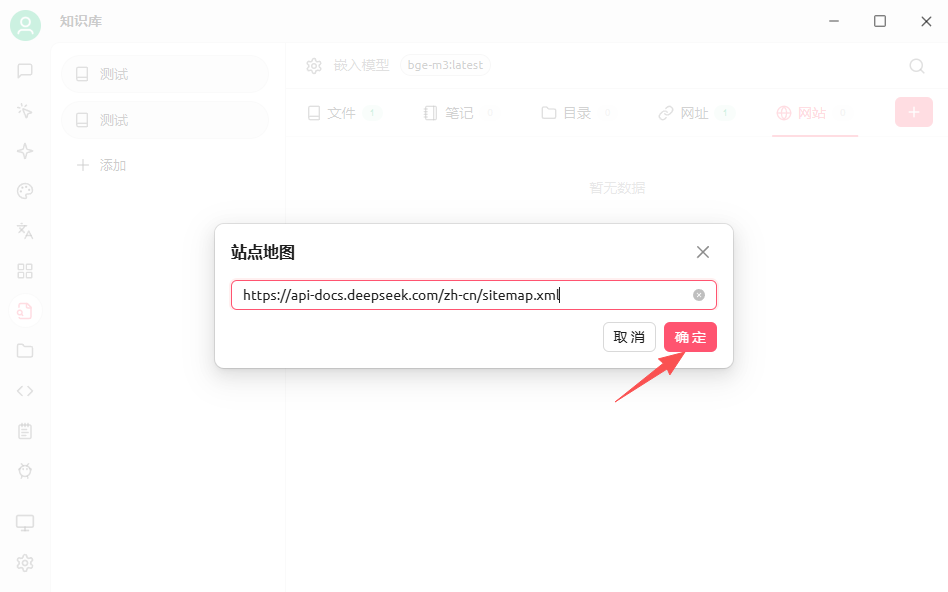
一般网站都会提供sitemap,如deepseek的https://api-docs.deepseek.com/zh-cn/sitemap.xml
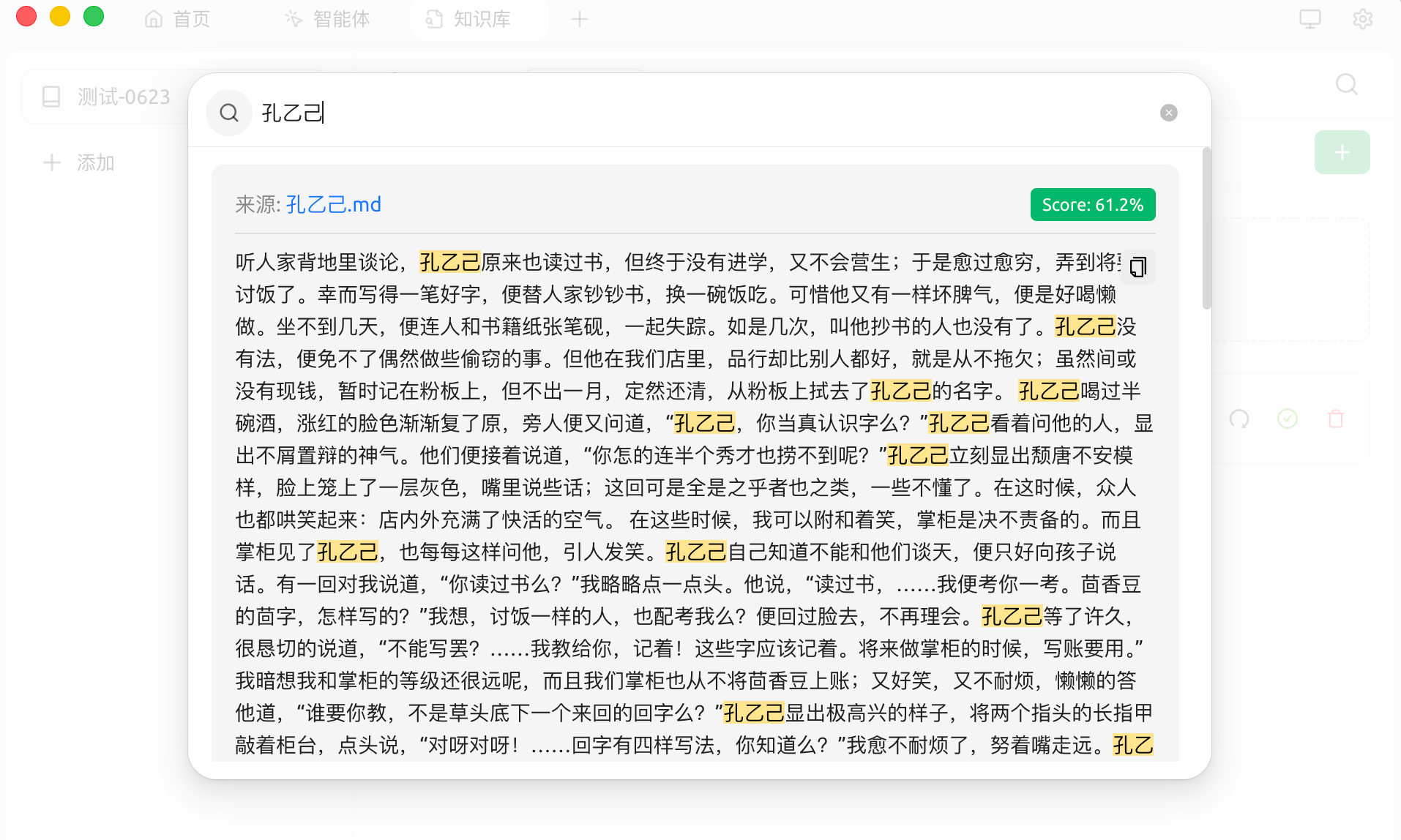
三、命中测试
可以在知识库中进行搜索测试,看看实际命中效果:
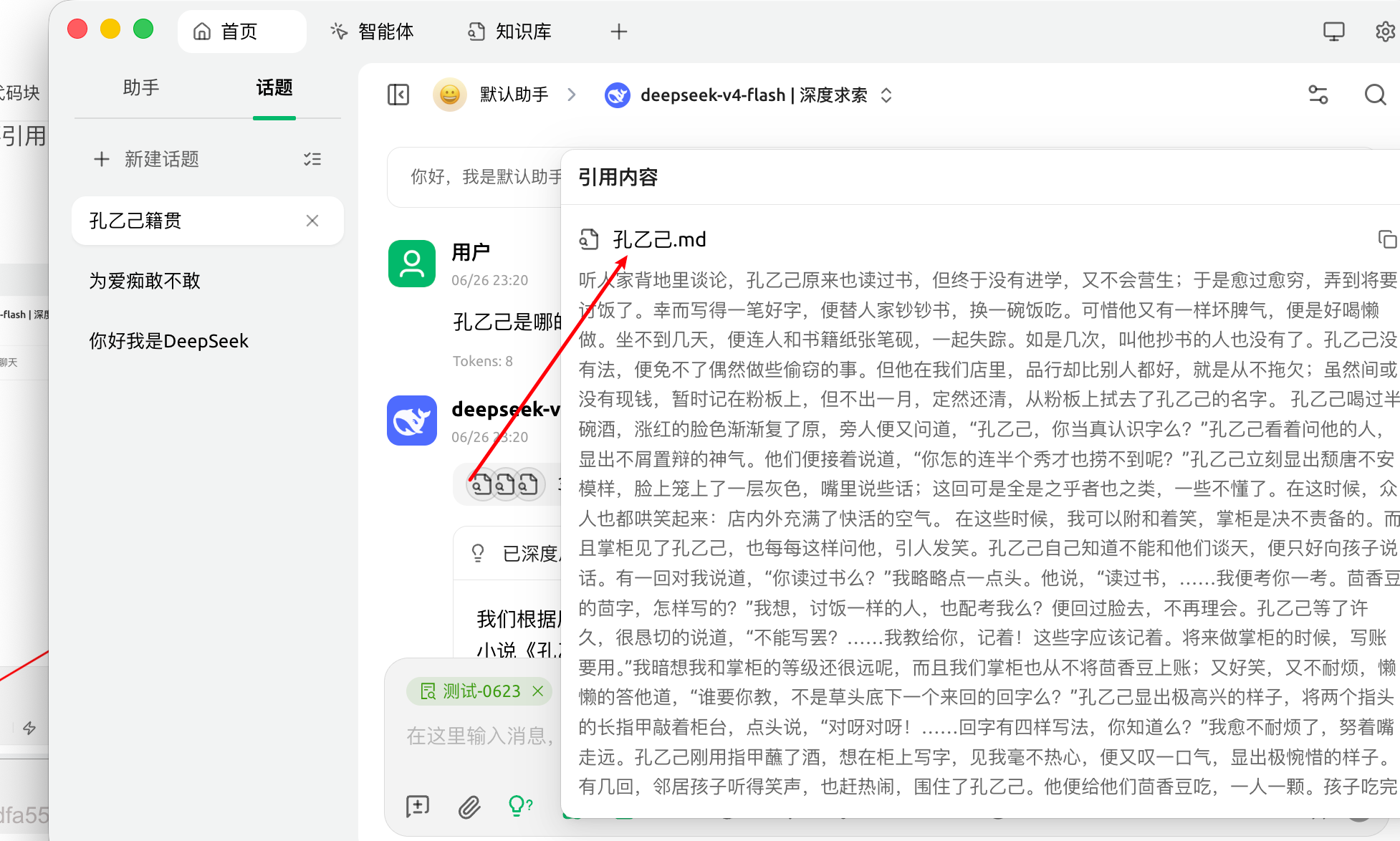
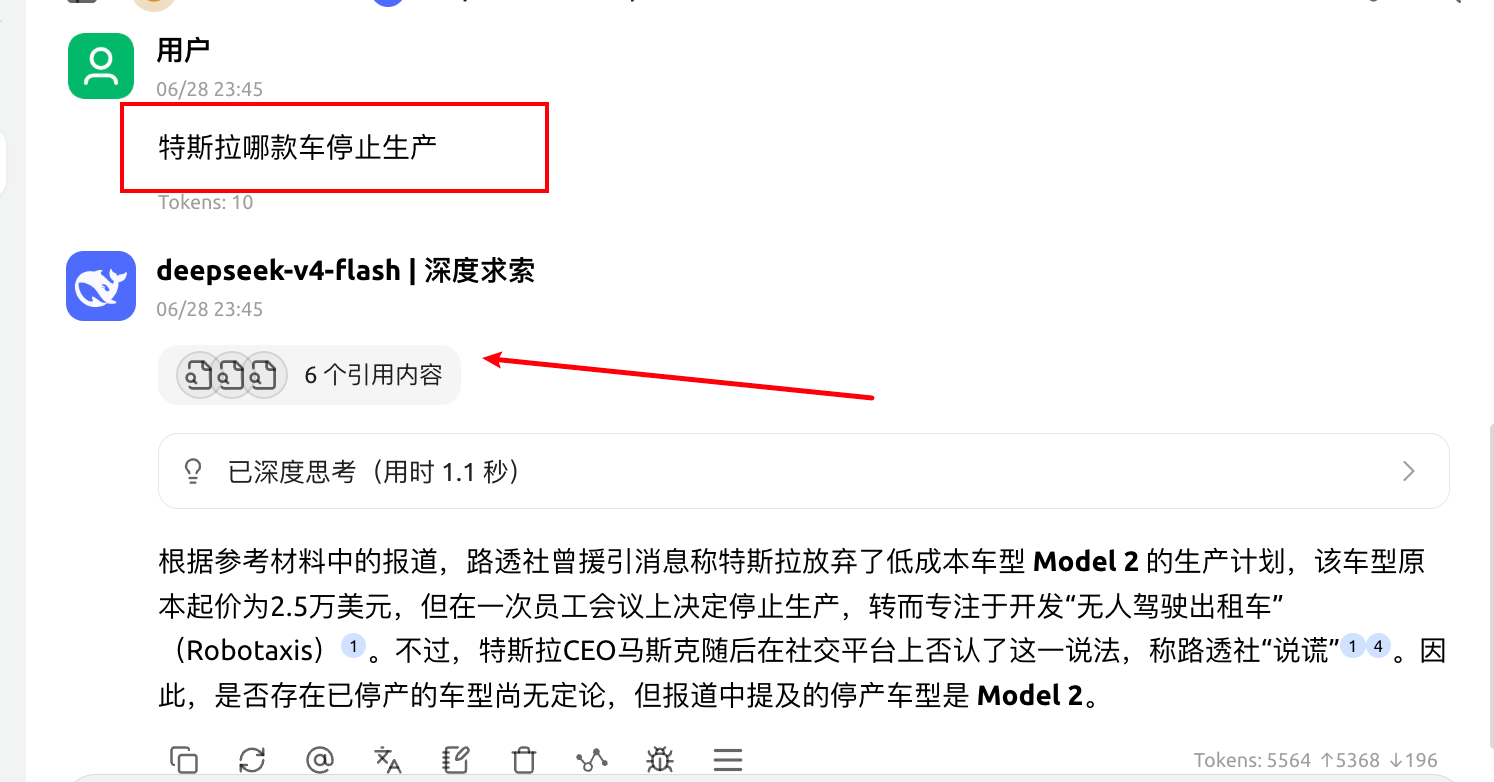
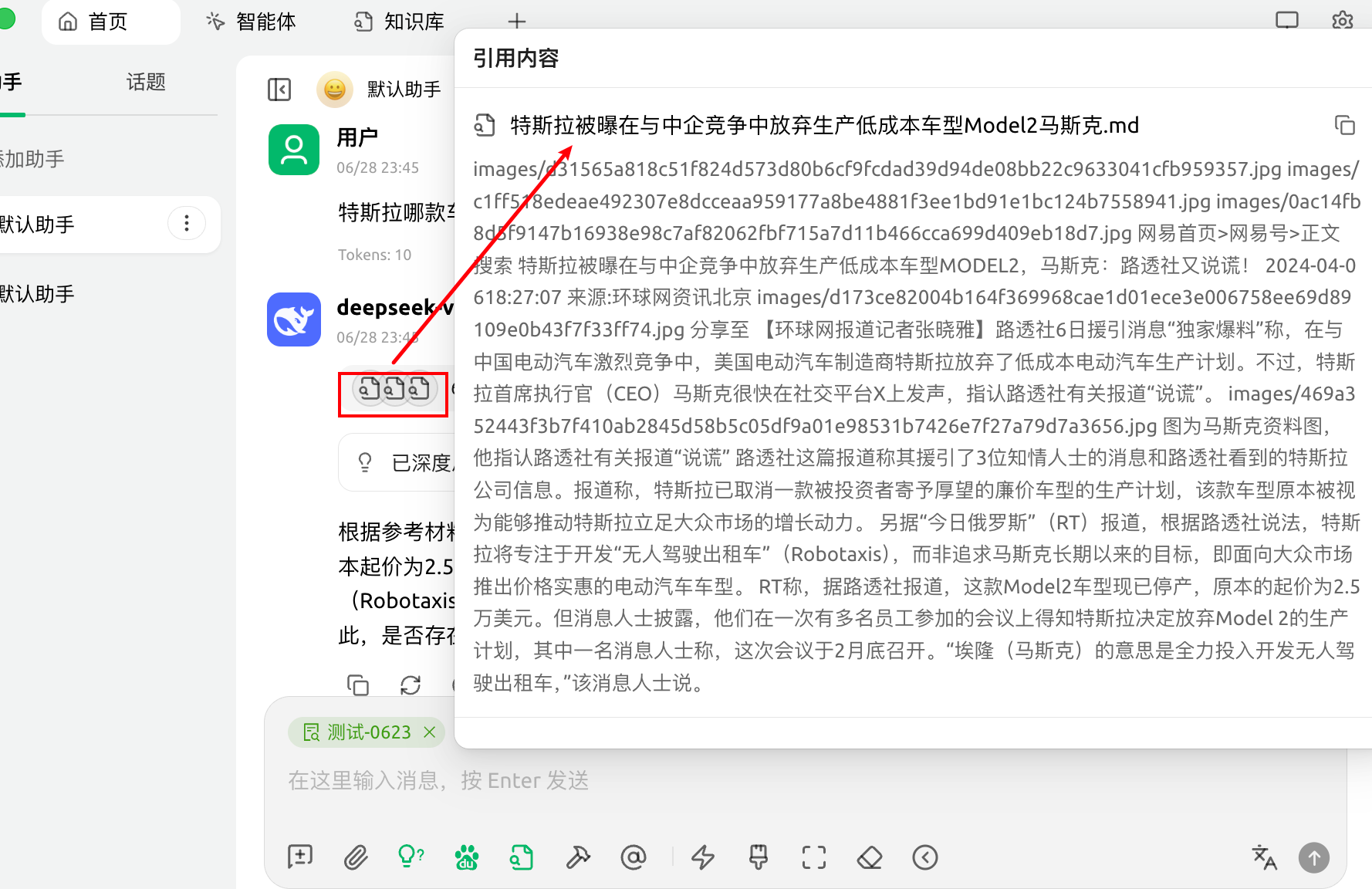
四、引用知识库回复
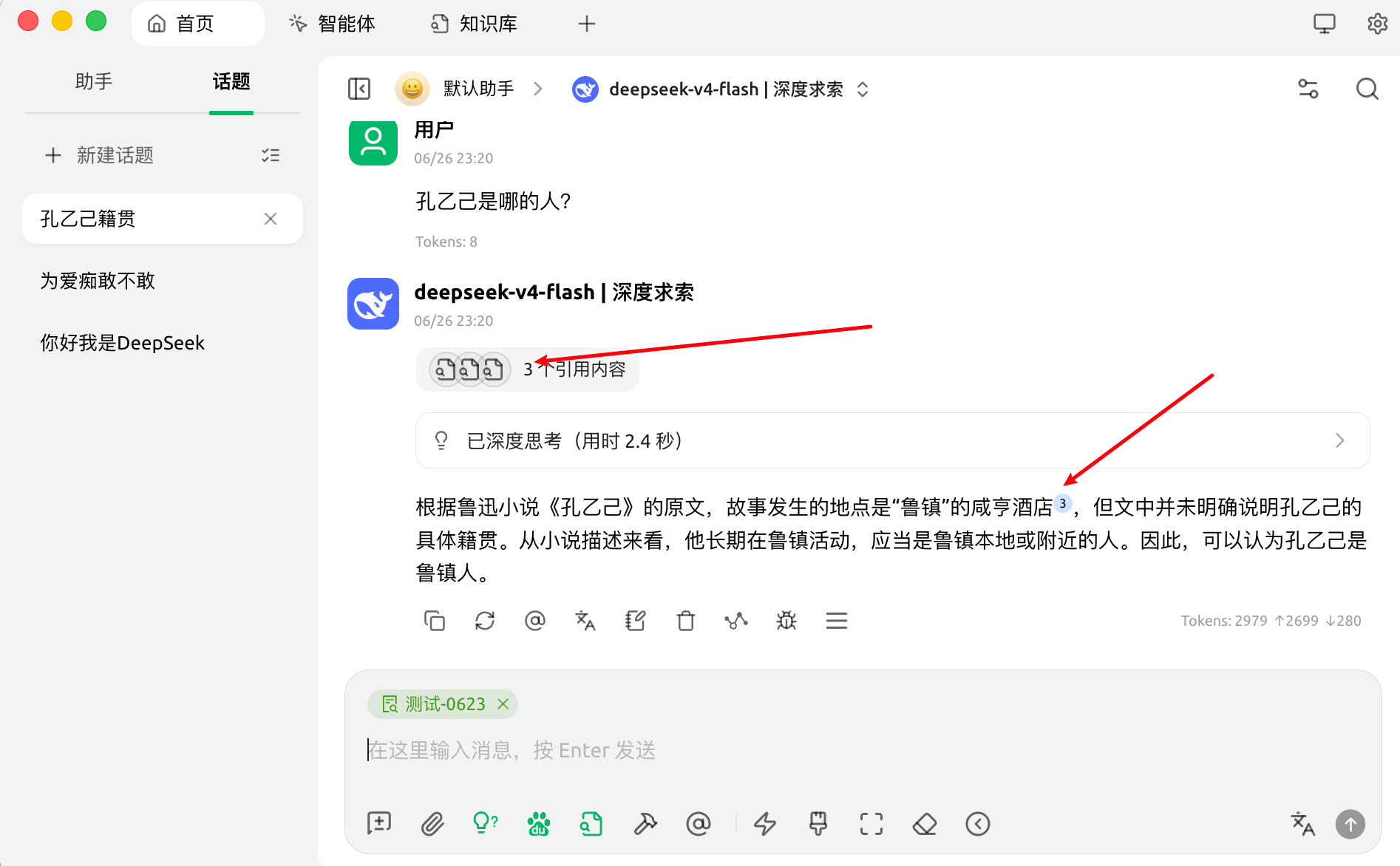
在对话页面,选择知识库图标,选择需要引用的知识库。模型回答之后,可以通过引用内容查看调用情况。
五、文档预处理
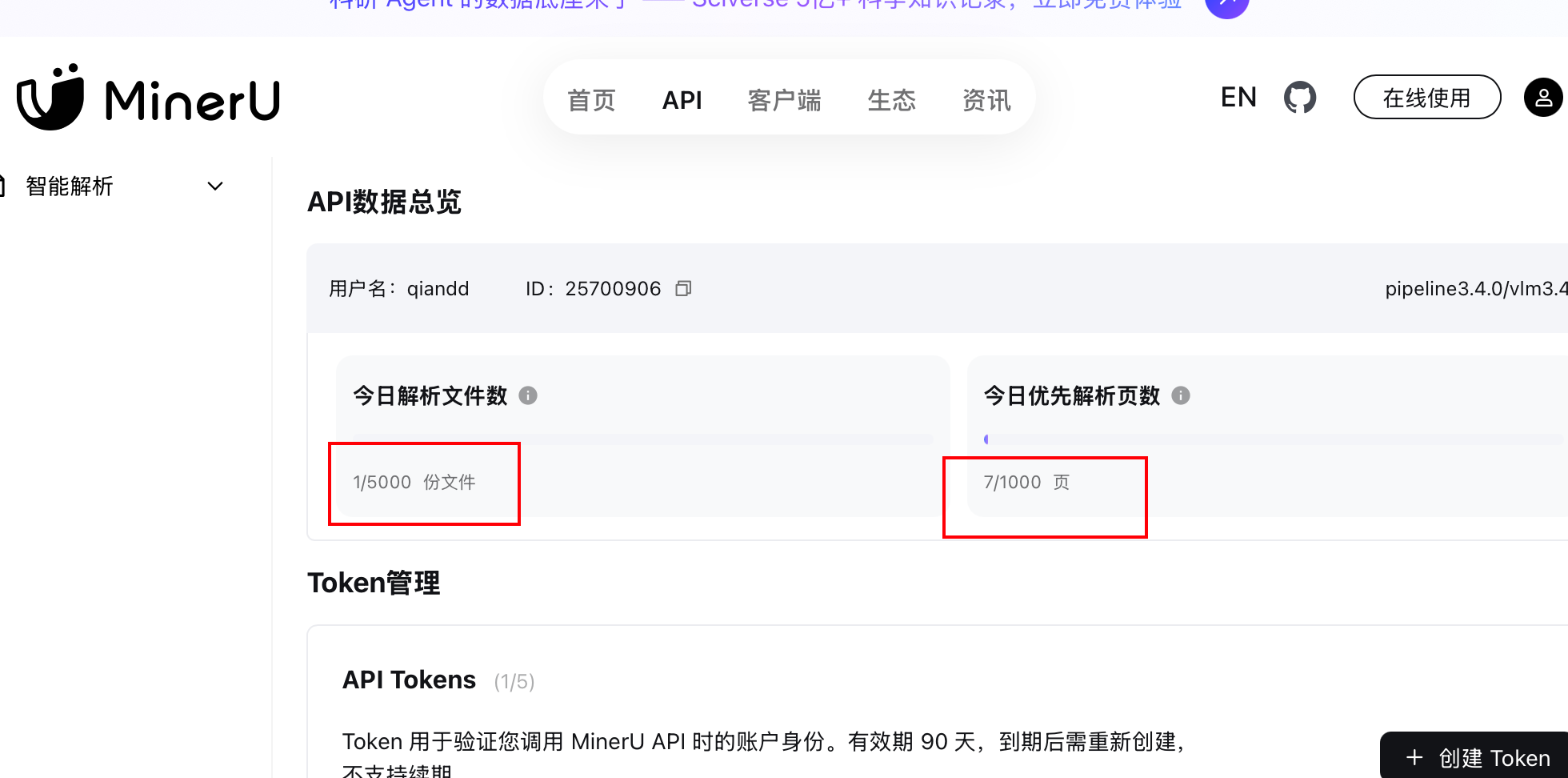
如果对知识库文档处理要求比较高,例如复杂版式、表格、数学公式、图片等,可以考虑使用第三方文档预处理服务。MinerU单日上限5000份,单文件≤200页,高优每日1000页免费额度。
MinerU是什么?
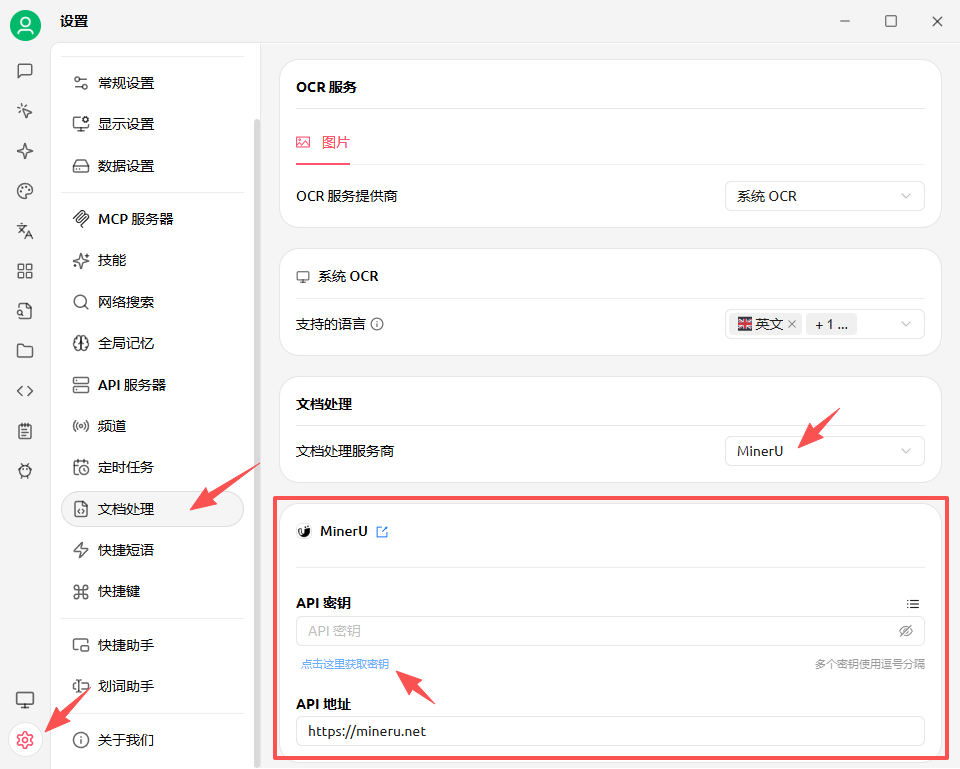
然后在知识库中手动设置MinerU:
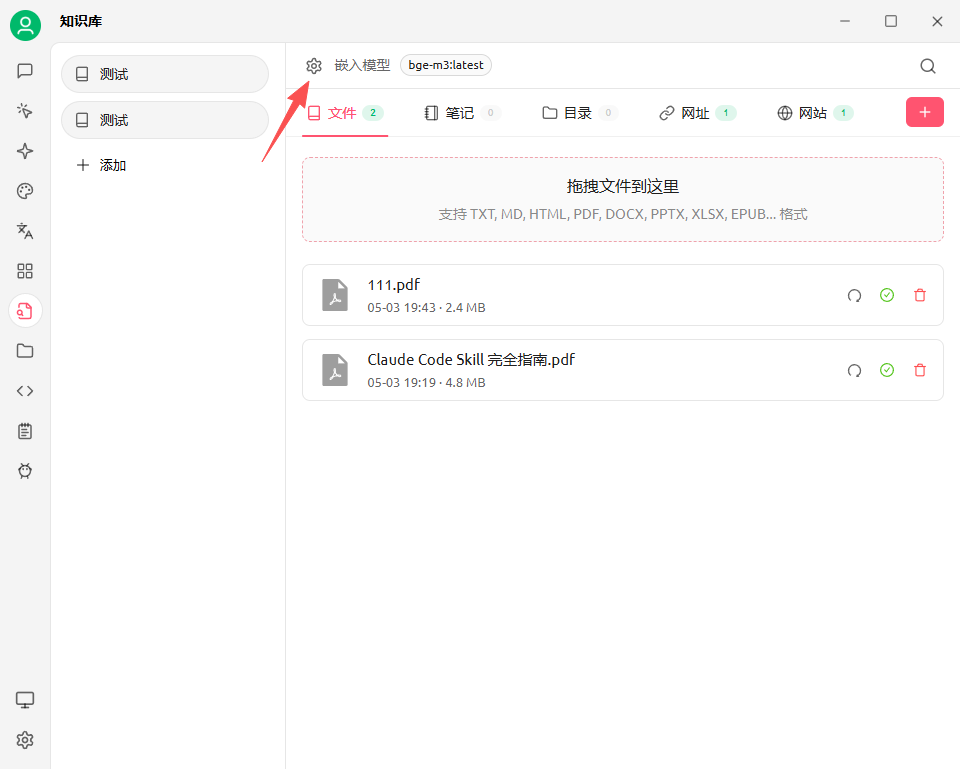
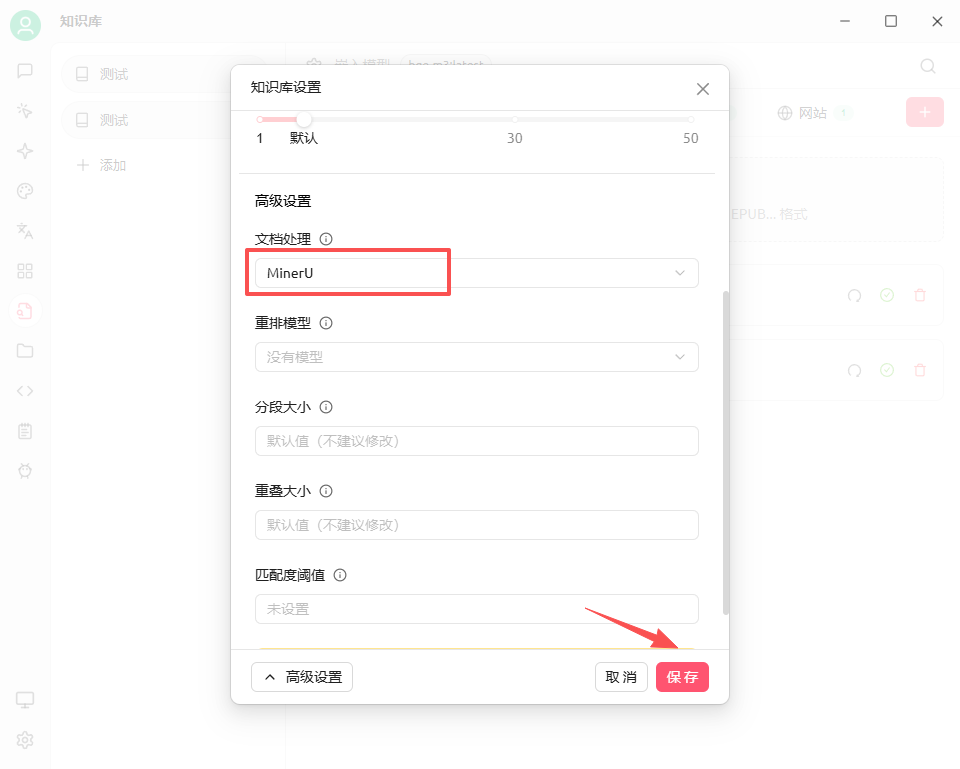
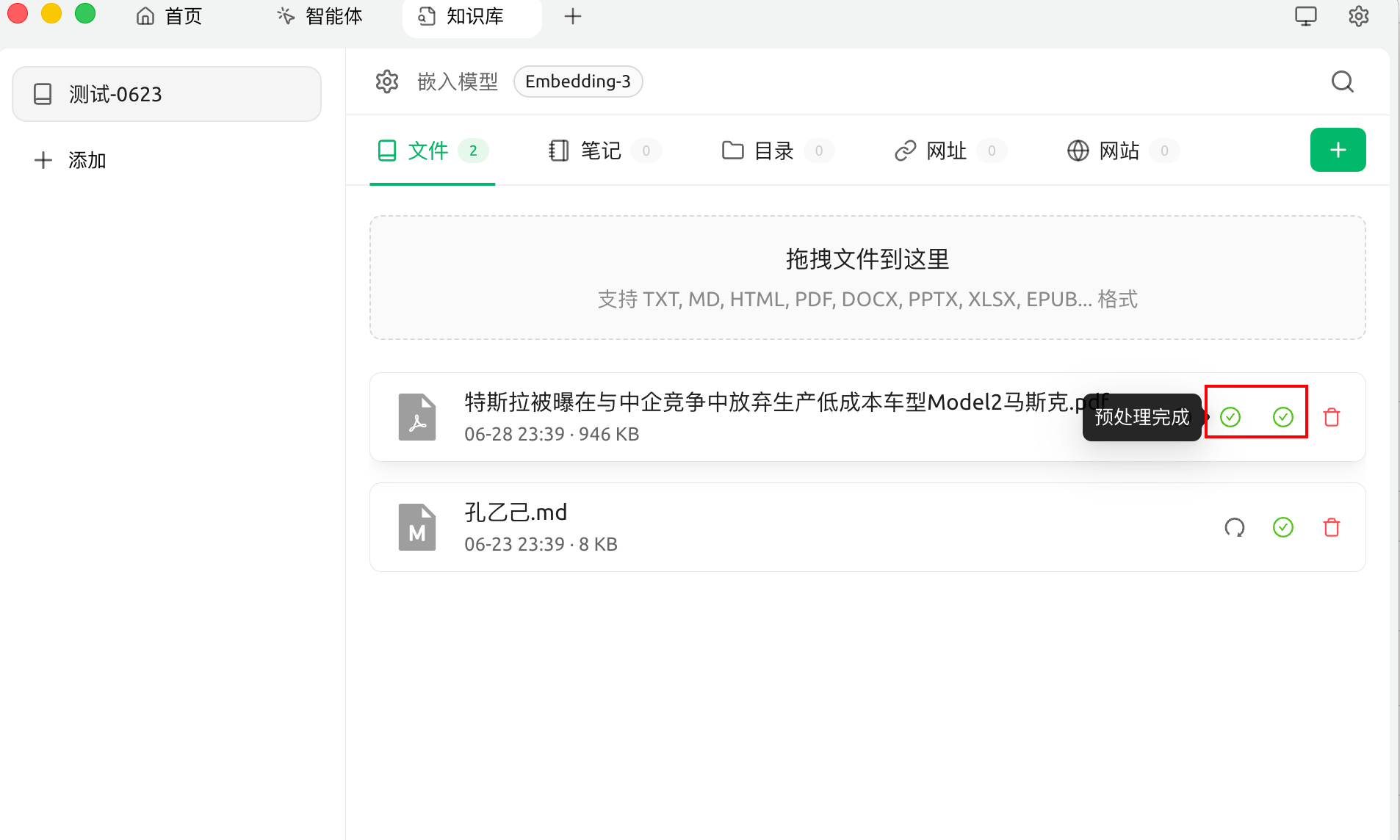
然后就可以重新处理文档,处理完毕后,就多了一个√,第一个是预处理,第二个是嵌入:
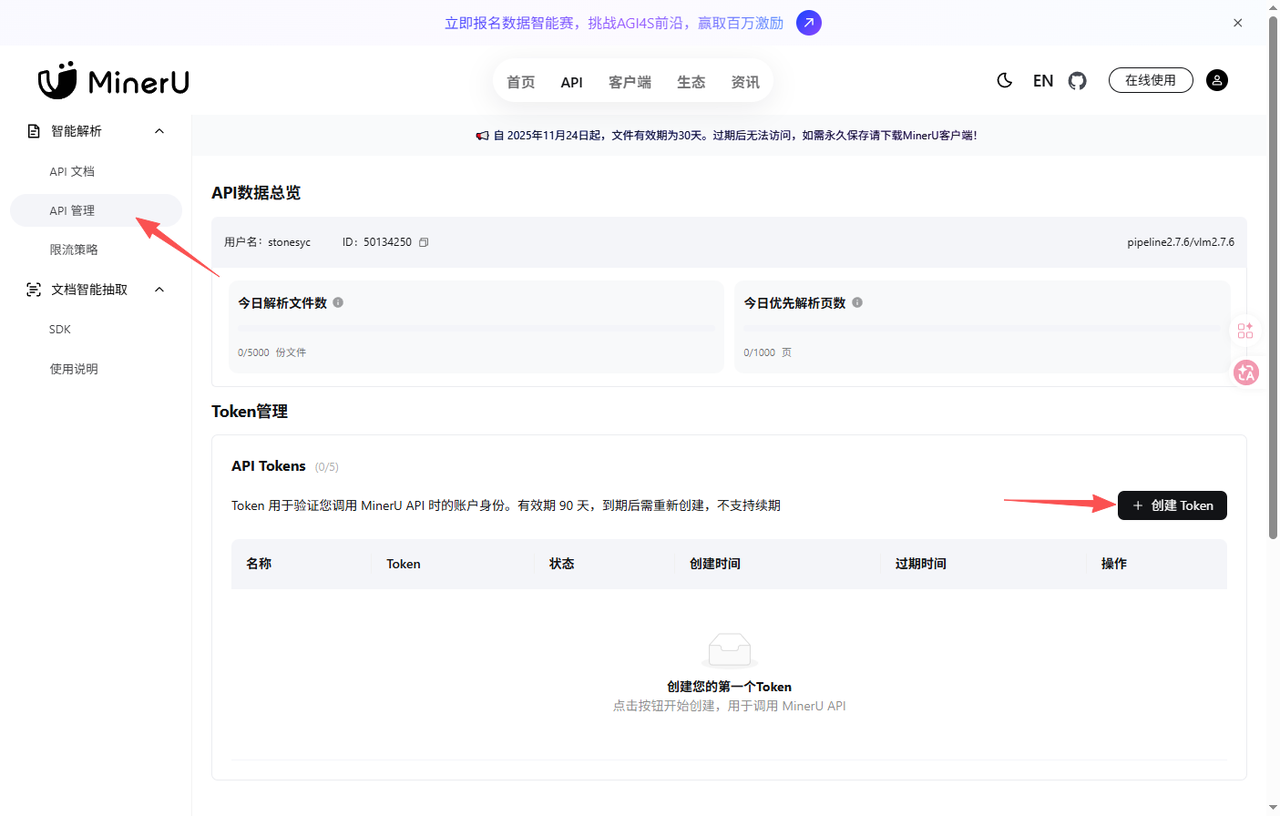
然后就可以在MinerU后台查看到调用量:
试一下效果:
结果正确,与我pdf中的一致。
六、重排模型
当使用嵌入模型进行文档检索时,有时候并不理想,我们需要重排模型将检索得到的文本块进行精排序,以提高大模型回答的准确性。
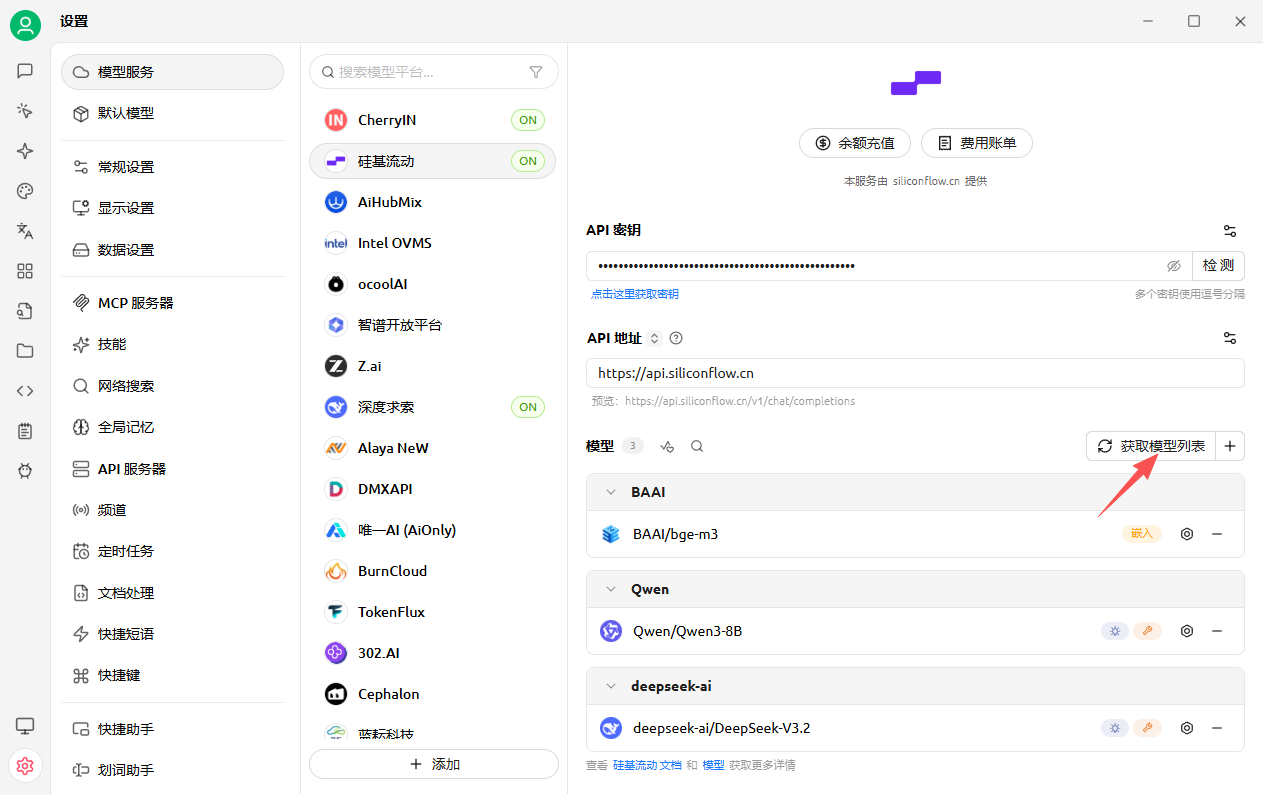
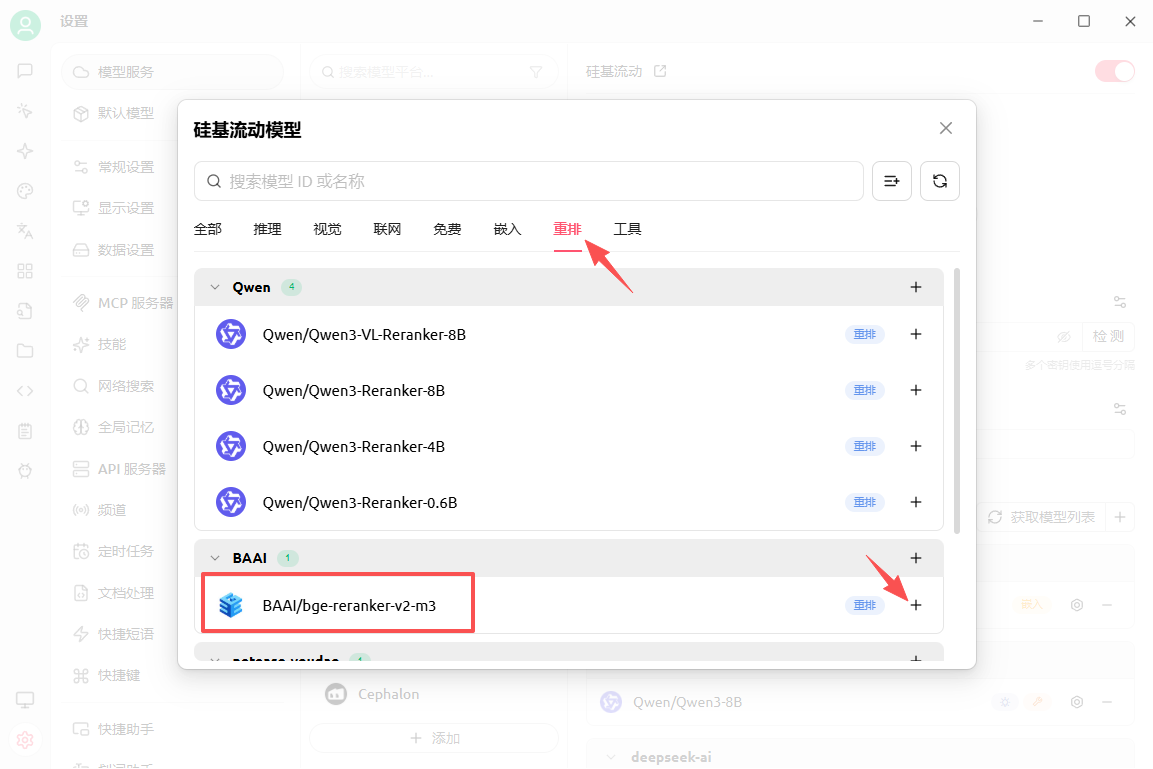
ollama目前版本暂未支持reranker API,只能使用在线重排模型。这里以硅基流动为例,点击获取模型列表,在里面找到重排模型:
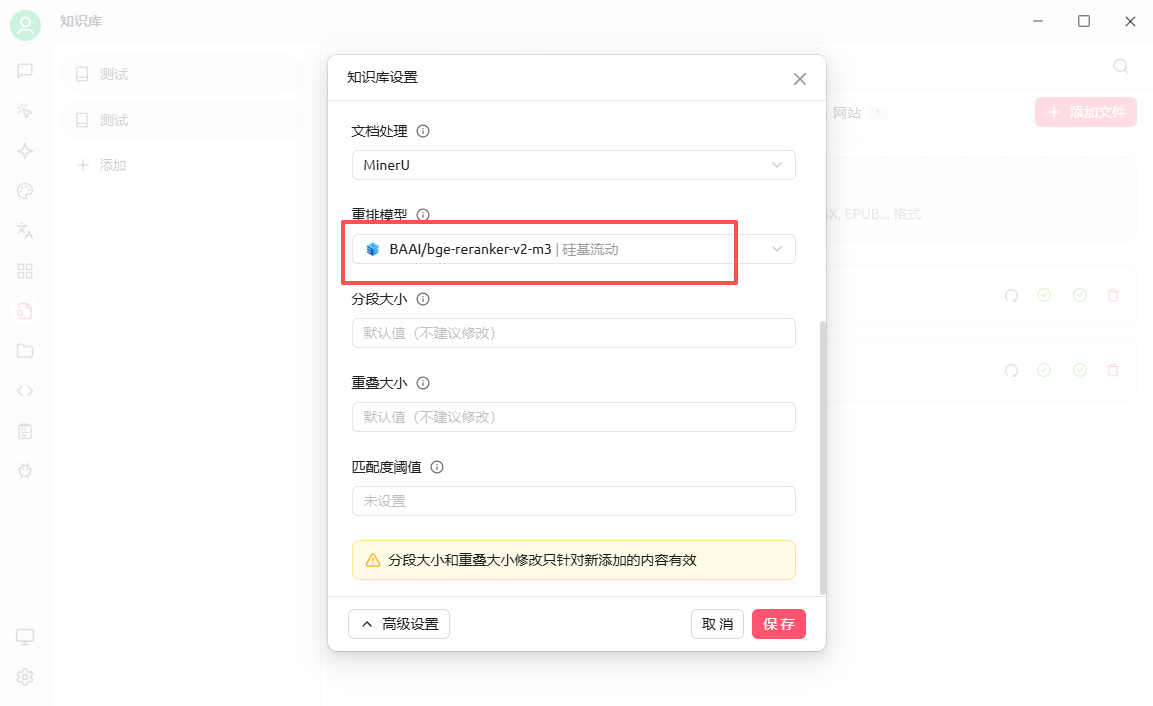
在知识库中,点击设置,在高级设置中选择重排模型:
6.1 简单介绍一下重排模型



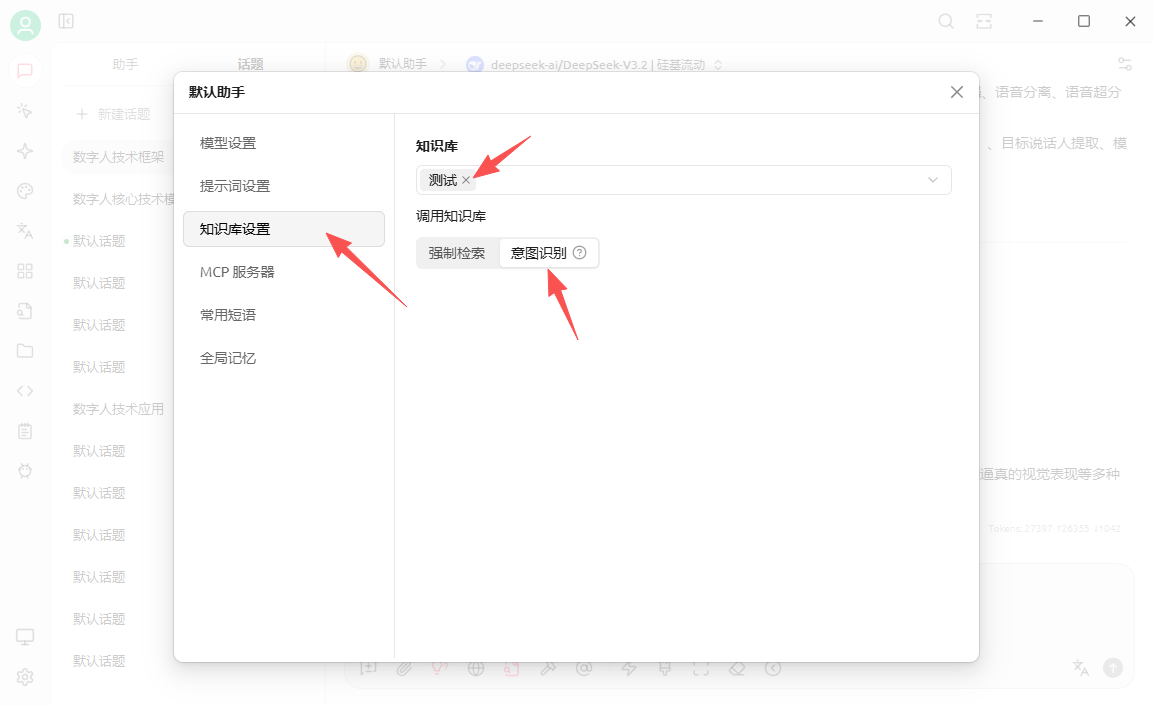
七、知识库意图识别
使用能力较强的模型时可以将知识库搜索模式修改为意图识别,意图识别可以更准确、广泛的描述您的问题。