跨 GPU 硬件跑分工具 :测量 NVIDIA GPU 的实际可达性能指标,而非纸面峰值。
支持独立显卡(如 RTX 4070 )与集成式 Jetson 平台(如 Jetson Thor)。]
jetson thor测试数据
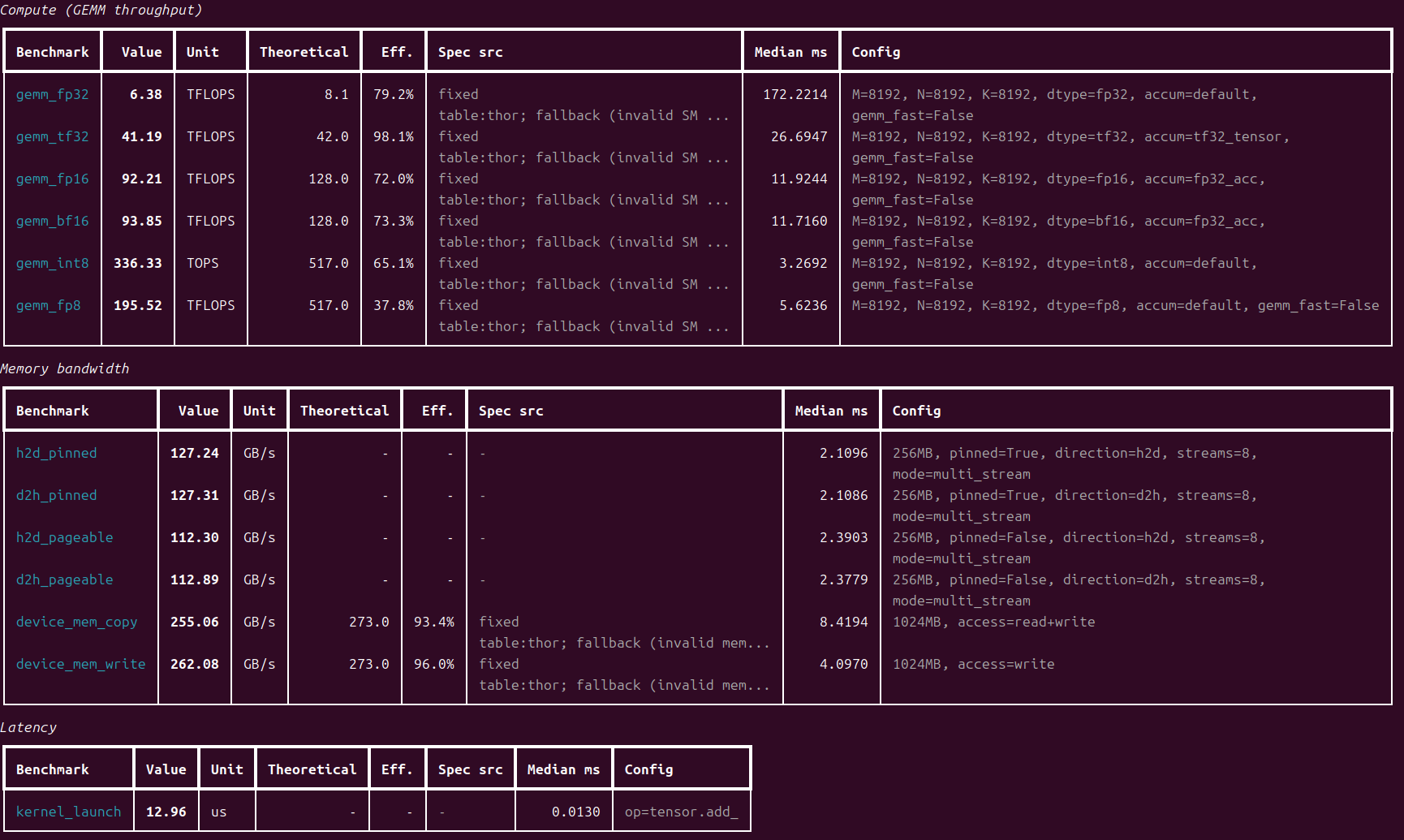
测量项
| 类别 | 跑分项 | 指标 | 说明 |
|---|---|---|---|
| compute | gemm_flops |
TFLOPS / TOPS | GEMM 吞吐,覆盖 fp32 / tf32 / fp16 / bf16 / int8 / fp8 |
| memory | host_device_bw |
GB/s | H2D / D2H 带宽(pinned 与 pageable 两种主存) |
| memory | device_mem_bw |
GB/s | GPU 本地显存/统一内存带宽(device copy 读+写、write-only) |
| latency | kernel_launch |
us | 单 kernel 启动/调度开销 |
效率列(Eff.)= 实测 / 理论峰值。理论峰值来源由 --spec-source 控制(见下)。
安装
通用依赖:Python ≥ 3.10 、PyTorch ≥ 2.0(CUDA 构建) 。SysPeek 本体与 PyTorch 的 CUDA 版本需与当前平台一致;桌面独显 与 Jetson 安装 PyTorch 的方式不同,见下表。
| 平台 | 典型设备 | 架构 | CUDA / JetPack | PyTorch wheel |
|---|---|---|---|---|
| 桌面 Linux + 独显 | RTX 4070 等 | x86_64 | CUDA 12.x(如 12.8) | cu128 |
| Jetson | Jetson Thor 等 | aarch64 | CUDA 13(JetPack 7+) | cu130 |
内存与带宽测试说明见 <docs/memory.md>。
桌面独显(如 RTX 4070,x86_64 + cu128)
bash
cd SysPeek
# 可选:一键 venv + 安装 SysPeek(不含 torch)
chmod +x scripts/setup_venv.sh
./scripts/setup_venv.sh
source .venv/bin/activate
# PyTorch(CUDA 12.8 示例,与驱动/CUDA 版本对齐)
pip install torch --index-url https://download.pytorch.org/whl/cu128
# 安装 SysPeek(若未跑 setup_venv.sh)
pip install -e .
# 验证
syspeek info
syspeek run手动 venv:
bash
python3 -m venv .venv
source .venv/bin/activate
pip install -U pip
pip install torch --index-url https://download.pytorch.org/whl/cu128
pip install -e .Jetson Thor(aarch64 + CUDA 13 / cu130)
Thor 运行在 JetPack 7+ / CUDA 13 上,请使用 cu130 索引,不要 在 Thor 上安装桌面用的 cu128 wheel。
bash
cd SysPeek
chmod +x scripts/setup_venv.sh
./scripts/setup_venv.sh
source .venv/bin/activate
# Jetson Thor:CUDA 13 → cu130
pip install torch --index-url https://download.pytorch.org/whl/cu130
pip install -e .
syspeek info # platform 应显示 jetson
syspeek runJetson 注意:
- 若 JetPack 已预装系统级 PyTorch,也可在 venv 中单独安装 与 JetPack CUDA 13 匹配 的
cu130wheel,避免混用cu128。 - 统一内存:建议减小 buffer,例如
syspeek run --transfer-mb 128 --device-mem-mb 256 --gemm-size 4096 - 理论峰值需在 Thor 真机标定后写入
theoretical.py(当前可能只显示实测、无 Eff.)。
方式 B:全局 / 用户目录安装
在对应平台装好 匹配的 PyTorch 后:
bash
cd SysPeek
pip install -e .方式 C:不安装,临时运行
bash
# 仍需当前 shell 能 import 到 CUDA 版 torch
PYTHONPATH=src python -m syspeek.cli info
PYTHONPATH=src python -m syspeek.cli run退出 venv:deactivate
用法
bash
# 查看设备/平台信息
syspeek info
# 列出全部跑分项
syspeek list
# 跑全部(默认)
syspeek run
# 只跑某些项 / 某些类别 / 某些 dtype
syspeek run --bench gemm_flops --dtype fp16 --dtype bf16
syspeek run --category memory
# 调整规模与迭代
syspeek run --gemm-size 8192 --transfer-mb 256 --device-mem-mb 1024 --warmup 10 --rep 50
# 导出 JSON(便于跨设备对比)
syspeek run -o result_4070.json
syspeek run --json > result.json常用选项
| 选项 | 说明 | 默认 |
|---|---|---|
--device |
CUDA 设备号 | 0 |
--bench |
指定跑分项(可重复) | 全部 |
--category |
指定类别 compute/memory/latency | 全部 |
--dtype |
限制 compute dtype(可重复) | 全部 |
--gemm-size |
方阵 M=N=K | 8192 |
--transfer-mb |
H2D/D2H 总传输大小 | 256 |
--transfer-streams |
并行 CUDA stream 数 | 8 |
--transfer-mode |
multi_stream / single / threaded |
multi_stream |
--device-mem-mb |
GPU 本地显存测试 buffer 大小 | 1024 |
--no-flush-l2 |
关闭 L2 flush | off |
--spec-source |
理论峰值来源:auto / fixed / auto-fallback |
auto-fallback |
-o/--output |
写 JSON 文件 | --- |
--json |
打印 JSON 到 stdout | off |
架构
分层设计,跑分项与平台解耦、可插拔注册:
SysPeek/
├── pyproject.toml
└── src/syspeek/
├── cli.py # CLI 入口(click)
├── reporting.py # rich 表格 / JSON 渲染
├── theoretical.py # 各设备理论峰值表(用于算效率,可编辑)
├── core/
│ ├── device.py # 设备检测(含 Jetson 判定)+ DeviceInfo
│ ├── timing.py # CudaTimer:CUDA event 计时 + warmup/rep + L2 flush
│ ├── result.py # BenchmarkResult / RunContext / TimingStats
│ └── registry.py # 跑分项注册表(按 name/category 过滤)
├── benchmarks/
│ ├── base.py # Benchmark 抽象基类
│ ├── compute_flops.py # GEMM FLOPS(多 dtype,OOM 自适应缩小)
│ ├── memory_transfer.py # H2D / D2H(pinned / pageable)
│ ├── memory_device.py # GPU 本地显存 copy / write 带宽(GDDR/LPDDR)
│ └── latency.py # kernel 启动延迟
└── platforms/
├── base.py # Platform 抽象
├── desktop.py # 独显(nvidia-smi 遥测,PCIe 链路标注)
└── jetson.py # Jetson(统一内存语义、INA3221 功耗读取)设计要点:
- 跑分项自注册 :每个
Benchmark声明name/category,importsyspeek.benchmarks即注册;CLI 通过注册表发现与过滤,新增跑分项无需改 CLI。 - 平台抽象:跑分逻辑设备无关;平台层只负责差异化标注(H2D 链路名称、理论峰值来源、功耗遥测)与告警 note。
- 计时 :统一
CudaTimer(CUDA event + warmup/rep + 可选 L2 flush),与hpc_bench风格一致;带宽类跑分关闭 L2 flush 避免干扰。 - 效率 :理论峰值由
--spec-source决定来源;结果中Spec src列与 JSON 的theoretical_source/theoretical_detail标明每条指标的具体来源。
理论峰值来源(--spec-source)
| 模式 | 行为 |
|---|---|
auto |
运行时推导:SM 数 × cores/SM × nvidia-smi 最大 SM 时钟 → FP32;fp16/bf16 按 cuBLAS FP32 累加路径乘系数;显存带宽 = 位宽(smi 或型号 hint)× 内存时钟 |
fixed |
仅使用 theoretical.py 中手工录入的 _TABLE(如 RTX 4070,通常基于厂商 Boost Clock 规格) |
auto-fallback(默认) |
先 auto,该指标推导失败则回退 fixed |
JSON 每条结果含 theoretical_source(auto / fixed)与 theoretical_detail(推导公式或表项 key)。
平台说明
- RTX 4070(独显) :H2D/D2H 走 PCIe;
device_mem_bw测 GDDR6X 显存带宽。- H2D/D2H 理论值 :按 GPU 的 PCIe 规格(4070 为 Gen4 x8 ≈ 15.75 GB/s/方向)显示;你测到 ~18 GB/s(pinned)说明已接近或达到链路上限,再开多 stream 提升空间有限。
- pageable 传输 CPU 会参与页锁定/拷贝,CPU 占用高是正常现象;默认 multi_stream 可略提高 pageable 带宽,但仍低于 pinned。
- 可选
--transfer-mode threaded用多 CPU 线程提交 copy,主要改善 pageable 场景。 - 注意:
gemm_flops的 fp16/bf16 走 cuBLAS 默认 FP32 累加路径,消费级 Ada 上该路径峰值约为 FP16/FP16-累加峰值的一半,理论值已按此校准。
- Jetson Thor(集成 GPU) :GPU 与 CPU 共享 LPDDR,H2D/D2H 不经 PCIe,反映的是内存子系统带宽(工具会在 note 中提示);显存从系统内存划分,注意 buffer 大小留余量。理论峰值待在真机上标定后填入
theoretical.py。
扩展
- 新增跑分项 :在
benchmarks/继承Benchmark,实现run(),在benchmarks/__init__.py注册。 - 新增设备理论值 :在
theoretical.py的_TABLE增加一条(key 为设备名/型号子串)。 - 新增平台 :在
platforms/继承Platform,在get_platform()加入判定。
License
MIT