背景:本章节主要针对使用 LangChain/LangGraph 框架设计智能体,可能会遇到的问题,并剖析其原理。
不考虑 subgraph!!!
一、问题背景
许多开发者在设计智能体时,都会关注 Token / First Token / 耗时 / 长对话幻觉问题。 这些问题的本质其实是一个智能体(即 LangChain 的 create_agent API)上加载了太多系统提示词 sys_prompt 和 tool。 原因 :LangChain 的智能体在运行时,会把系统提示词和工具的描述统一加载到上下文中。太长的描述性文字、约定性文字、强制的规则,致使模型无法做出优先级评判,或是无法针对指定场景做出指定回应。 可能产生的影响:
- Token 飙增:对于对话任务来说,未经拆分职责的智能体所加载的提示词(Tool 的描述也会加载)过长。若用户只询问了"1+1=几"的简单问题场景,智能体不必要加载业务上的复杂提示词。
- 模型幻觉:大量提示词中,对不同场景下约定模型的输出规则,产生重叠或指代不清(对于私有化部署的小模型而言,会放大这一现象),导致工具调用混乱或不调用工具,从而产生幻觉。
- 耗时:同理,大量 Token 加载后,模型单个任务需要处理的耗时显著增加。
- ...
为了解决这些问题,我们通常会考虑对智能体进行职责拆分。
二、拆分的场景
2.1 类 skill 技能的拆分,LLM 智能路由
原理 :将不同职责的提示词、工具等统一定义为一个 langchain-agent(create_agent),并封装为 skill 节点。路由时:通过 LLM 判断进入到哪个节点。将二者都编排到 LangGraph 图中。
思想 :graph 图编排------外层首先过一个 LLM,依据提示词指定输出用户意图节点的标识完成路由,随后 graph 进入对应节点执行。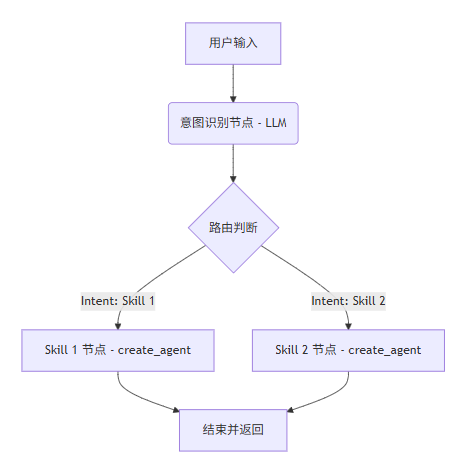
2.2 包装 Tool 拆分,依靠主 Agent 完成路由
原理 :将不同职责的提示词、工具等统一定义为一个 agent(create_agent),随后将调用智能体的方法/函数暴露出来,定义针对该智能体的 LangChain-Tool,描述中交代模型何时调用该 Tool。此 Tool 挂在外层与用户交互的主 Agent 上,完成拆分。
思想 :职责智能体封装为工具,主 Agent 依靠提示词(sys + Tool 描述)完成路由执行。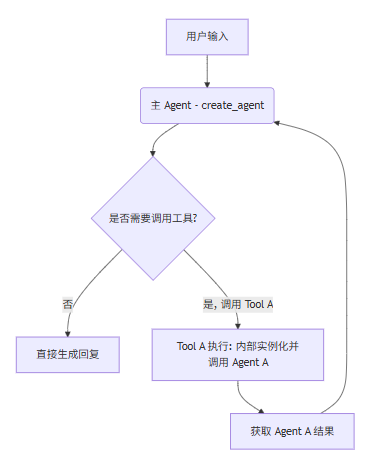
注意:以上是常见的两种设计思路,在落地实现时可能稍有不同,不过原理都大同小异。不考虑 subgraph 的前提!!!
三、为什么这样设计
我们先说一下包装 Tool 做拆分。
这个思路是什么?
其实是利用了 LangChain 官方推荐的思想:模型封装工具。这个很大的好处是,在对 LangGraph 的了解不太深入的前提下,只利用简单的 LangChain-Tool-API 完成,同时也能优化上述提到的那些问题。 但这种方法只适用于初期设计智能体开发的场景。首先:
- 主 Agent 无法控制进入 Tool 之后的 query 是什么:因为与用户交互的是主 Agent,内部分析后判断需要调用工具,但无法直接透传用户交互的原生语言。使得主 Agent 只能通过上下文进行判断。这就导致了在整个环节,模型内部的运行始终对我们不可见,以及区分记忆的问题。
- 捡了西瓜,又丢了西瓜:职责智能体内部的提示词虽然好维护,但仍需关注它被包装的 Tool 的描述,以及主 Agent 路由提示词的设计。这在某些用户交互的精细化场景下,可能对 Prompt 字数反而没有好的提升。
接下来我们再讨论一下类 skill 模式 + LLM 路由的场景。
这种场景其实可以通过代码实现编排,但逻辑较为复杂,我们通常会使用 LangGraph,保证用户交互的流程是可追溯的。
乍一看这种场景其实也能完成我们想要的效果。事实上我通过测试发现,确实性能、Token 都维持在接受范围内。
但唯一一个不好的是,在使用 LangGraph 后,整体的流程几乎被打散了,因为我们引入了LLM 智能路由。
很多人对路由这个问题,都有不同的见解。比如规则引擎、同义词匹配等方式也都能路由到正确的节点。其实我的理解,最好还是使用 LLM,这一点会很大程度上降低模型的幻觉问题,因为它可以按照提示词输出我们想要的标识,从而进入该节点完成对应职责。
对于幻觉而言,我认为这种是最好的解决思路。
那它有什么问题呢?
- 图节点因为自定义智能体,导致消息机制被阻断 :这个问题比较难理解。因为 LangGraph 本身是有一套消息传播机制的,尤其是涉及到多智能体的场景。使用 LLM 并编排进 graph 节点后,此时我们创建的智能体(
create_agent)被编排到 LLM 路由后的节点。这将导致消息流在我们创建的智能体处被打断。
四、LangGraph 的流传播机制
为什么消息流会被打断?
我们需要深入剖析 LangGraph 的流传播机制。
在 LangGraph 中,图的状态流转和事件冒泡是强依赖于节点边界的。当一个节点被定义为一个普通的 Python 异步函数时,对于主图来说,这个函数就是一个"黑盒"。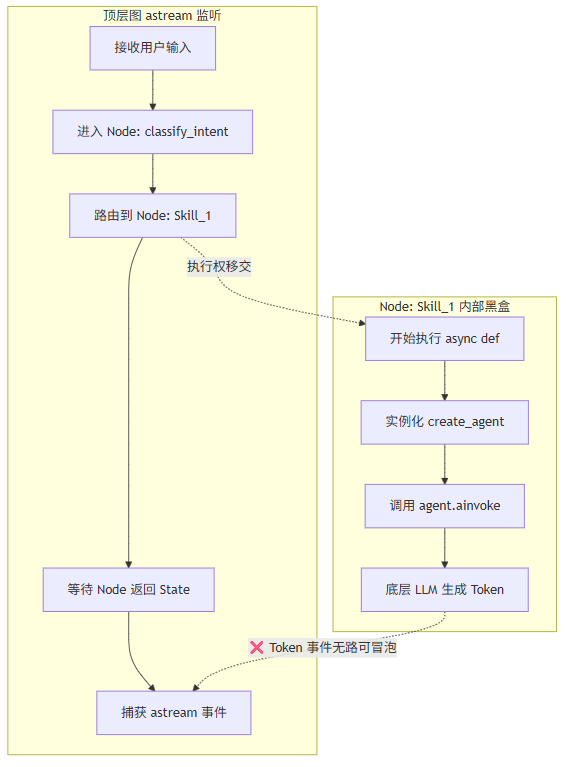
如上图所示,当我们在 Skill_1 节点内部使用 create_agent 并通过 await agent.ainvoke() 调用时,会发生以下情况:
- 回调上下文未透传 :顶层
astream(stream_mode="messages")生成的流式回调监听器,并没有自然地注入到create_agent的底层模型中。因为主图只负责把状态传给节点函数,而节点函数内部又建立了一个独立的执行环境。 - 状态更新掩盖流式输出 :由于使用了
ainvoke(阻塞调用),节点必须等待内部 Agent 彻底生成完毕,才会把最终结果作为一个完整的AIMessage通过return返回给主图。这就导致主图收到的是一次性的状态更新(updates模式),而不是细粒度的逐 Token 流(messages模式)。 - 消息流被打断的表象 :用户在前端体验到的就是"打字机效果失效",AI 的回复要么是一大段突然跳出,要么因为状态合并机制,把历史上下文错误地暴露出来。 总结 :LangGraph 的流式传播机制依赖于图节点的原生特性。在"不考虑 subgraph 纯嵌套"的前提下,如果我们强行在图节点内部通过函数包裹并
ainvoke一个独立的 Agent,就会破坏 LangGraph 默认的回调透传链路,导致消息机制被阻断。这是我们在采用"类 skill 拆分 + LLM 路由"架构时,必须面对并通过额外手段(如显式透传config、或改写为astream手动消费)去修补的核心痛点。